基于谱相减改进算法的语音增强系统的实现研究
2016-09-02覃贵礼罗云芳潘泽锴
覃贵礼, 罗云芳, 潘泽锴
(广西职业技术学院 计算机与电子信息工程系, 广西 南宁 530226)
基于谱相减改进算法的语音增强系统的实现研究
覃贵礼, 罗云芳, 潘泽锴
(广西职业技术学院计算机与电子信息工程系, 广西南宁530226)
针对数字通信网络中广泛应用的语音增强处理,在原有谱相减算法语音增强处理原理基础上改进该算法,并基于改进的谱相减算法采用MATLAB软件开发设计语音增强处理系统,经过测试表明系统能很好地实现带噪语音增强处理,声音的质量和可懂度提高效果显著。
谱相减改进算法;语音增强;信噪比;MATLAB
0 引言
随着人类制造出各种各样的机器,人与机器的交流慢慢地变成一种迫切的需求,人们的语音交流方式移植到人与机器之间并成了一种主流技术,也为人们提供了一种便利[1]。在数字技术发展和适应人们随时随地办公娱乐趋势的影响下,语音技术也得到了长足的发展,语音识别技术在人机交互的场合也得到了广泛的应用,在某些领域,机器已经能很好地理解人类语音的信息,准确的识别出人类语音的内容,并且经过数字信号处理的方式把获取的信息返回给执行机构完成相应的动作,从而实现人机交互的自然语言通信功能[2]。但在某些实际的应用中,传输距离和各种外界噪声因素会对传输的语言信号的强度和清晰度造成严重的干扰,同时受接收时各类硬件质量的影响,很多语音信号不能很好地识别,造成人机不能很好地交互。因此,利用数字技术把语音进行数字化处理以后,再利用语音处理算法对其进行增强处理,可提高语音的抗干扰性和可读性[3]。本文对语音信号的增强原理进行分析,设计了基于谱相减改进算法的语音增强系统,并详细阐述了系统的设计和实现方法。
1 谱相减改进算法实现语音增强的原理
1.1经典谱相语音增强减算法
经典的谱相减算法是在频域的范围内,语音的功率谱估计值使用带噪语音功率谱减去噪声的功率谱得到,语音的幅度通过对语音的功率估计开方得到,将其相位恢复后再采用逆傅立叶变换恢复时域信号,而在相位恢复中的相位信息包含在带噪语音当中[4]。
在经典谱相减算法数学建模中,s(m)、n(m)、和y(m)分别代表语音、噪声和带噪语音,Ss(ω)、Sn(ω)和Sy(ω)则表示短时谱,则带噪语音信号可以表示为:
y(m)=s(m)+n(m)(1)
对式(1)进行加窗处理并对其两边进行傅里叶变换可以得到:
Yw(ω)=Sw(ω)+Nw(ω)(2)
在原来假设s(m)中和n(m)是相互独立的个体,则根据式(2)可以得到原来的语音估值为:
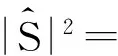
因为噪声是局部平稳的,故可以认为发音前的噪声与发音期间的噪声功率谱相同,因而可以利用发语音前的“寂静帧”来估计噪声。在语音的频域中,使用式(3)可以纯净语音的谱估计,实现简单的语音增强功能,但是实现的语音增强效果不是很明显,对于复杂的噪声无能为力。
1.2改进谱相减语音增强算法
根据谱相减算法实现语音增强的原理,其实现语音增强的数学表达式为:
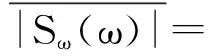
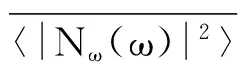
式中,m表示x的平均值,σ表示标准偏差。噪声的帧功率谱是在很宽的范围内随机变化的,变化频域帧功率谱中的最大值与最小值的比值很大,可以达到几个数量级,最大值与平均值之间的比值也很大,有倍。因此,在语音增强处理去噪时,会残留较大功率谱相关分量的一些剩余部分,这些剩余残留在频谱上会出现随机的尖峰,形成听觉上的残留噪声。
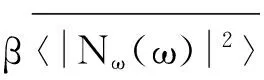
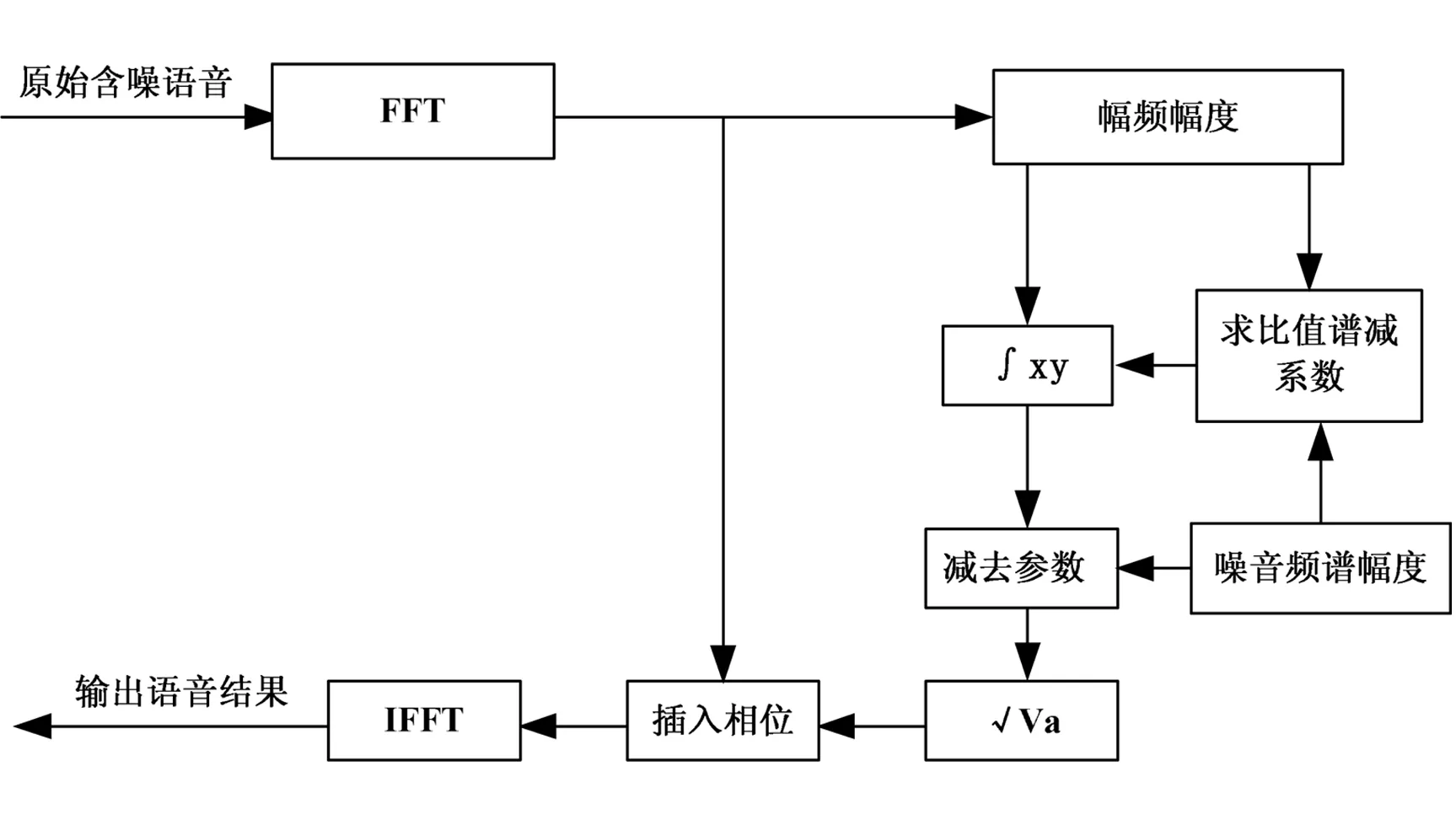
图1 谱相减改进算法实现语音增强原理图
结合式(4)和式(5)得到谱相减改进算法语音增强的计算式:
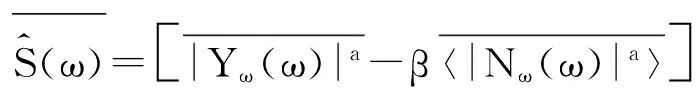
在谱相减语音增强算法计算模型中,通过改变a和β两个参数,能使算法在实现上具有很好的灵活性,通过灵活改变a和β参数的值正是谱相减语音增强处理算法改进的一种有效实现方式。本文即通过改变和参数的值进行谱相减语音增强处理算法的改进,并将改进后的算法用于语音增强处理[6]。算法模型中的参数表示谱减功率修正系数,取值越大,进行语音增强处理时,信噪比值越高,但同时也会加大原始语音信号的失真率。参数表示谱减噪声系数,它的取值会影响被减噪声功率谱值,β取值越大,增强处理后的语音音乐噪声越少,能在一定程度上更好的突出语音频谱,但同时也会加大原始语音信号的失真率。
计算模型中,当确定参数a和β的取值后,在利用算法模型进行语音增强处理过程中就一直不会改变,这与实际的语音增强处理不符,因为在语音增强处理过程中,需要在噪声频段中减去功率较大的噪声,实现提高信噪比的目的,而为了保证原始带噪语音中更多的清音,往往在带噪语音段中减去的噪声功率谱较小,实现提高增强处理后语音的可懂度。所以在实际的语音增强处理过程中应根据处理语音的频率段和语音帧动态调整a和β参数的取值。在处理的语音信噪比较低时,根据原始带噪语音帧频谱功率与噪声帧频谱功率的比值进行动态改变参数和值,语音处理后能较大程度的提高信噪比,同时又能最大程度的去除音乐噪声和减少语音的失真度,使增强处理后的语音更符合人耳听觉范围,保证语音增强处理的可懂度和清晰度。
2 基于谱相减改进算法语音增强系统的设计实现
系统的设计实现主要分为原始语音和噪声的准备,语音信号增强处理时输入语音信号的确定,对输入的语音信号进行增强处理程序功能实现等几部分。系统用于测试的原始语音采用格式8 kHz,16 bit,选取相对安静不带噪音的环境,利用单声道录制的一段纯净语音,时间大约5 s。系统设计利用MATLAB软件实现,语音读取使用wvaerda()函数完成,在语音开始之初截留一段纯净语言作为计算信噪比参考,其余部分加入由软件自带函数产生高斯白噪声,噪声频谱值取噪声帧中对应每一点的最小值作为被减噪声频谱值输入语音信号,取原始语言与倍的噪声之和,信噪比的随着值变化而发生变化[7]。
在整个系统设计包括两个部分:经典谱相减语音增强算法和改进谱相减语音增强算法处理,通过对比两个处理效果得出改进后算法的优越性。在经典谱相减语音增强算法中,利用原带噪语音的相位恢复到时域语音信号,从而得到处理后的语音信号,完成整个基于谱减法的语音增强过程,在系统处理中,经典谱相减发的工作流程图如图2所示。
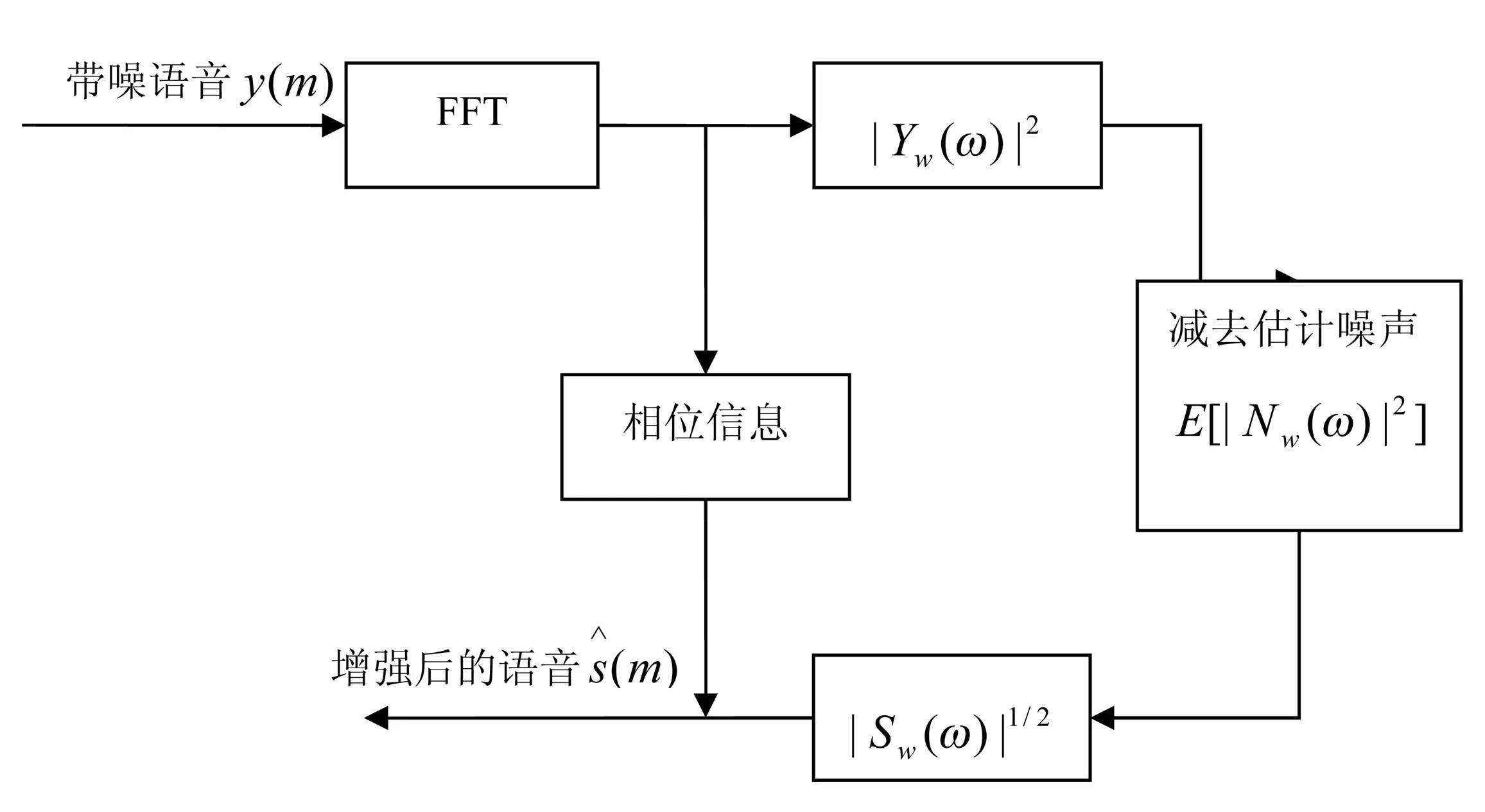
图2 经典谱相减算法语音处理设计流程图
改进谱相减语音增强算法语音信号的增强处理使用汉明窗函数实现,根据输入的语音的长度确定汉明窗的长度和平滑速度,由语言长度和每帧长确定程序最大循环次数M;而后进行傅里叶变换,由时域转换为频域以获得相角、幅值的变化,需要对每帧数据进行功率谱计算,而后对临近的几帧进行平滑处理,获取改进后的谱相减阀值a,β,确定功率因素补偿阀值,利用得到谱相减改进算法语音增强的乘积形式进行语音增强[8],使用傅里叶反变换获取阀值赋给序列相应段,经过M次循环处理,得到处理以后的声音,可以试听经过该算法改进以后的语音,基于谱相减改进算法的语音增强处理实现流程如图3所示。
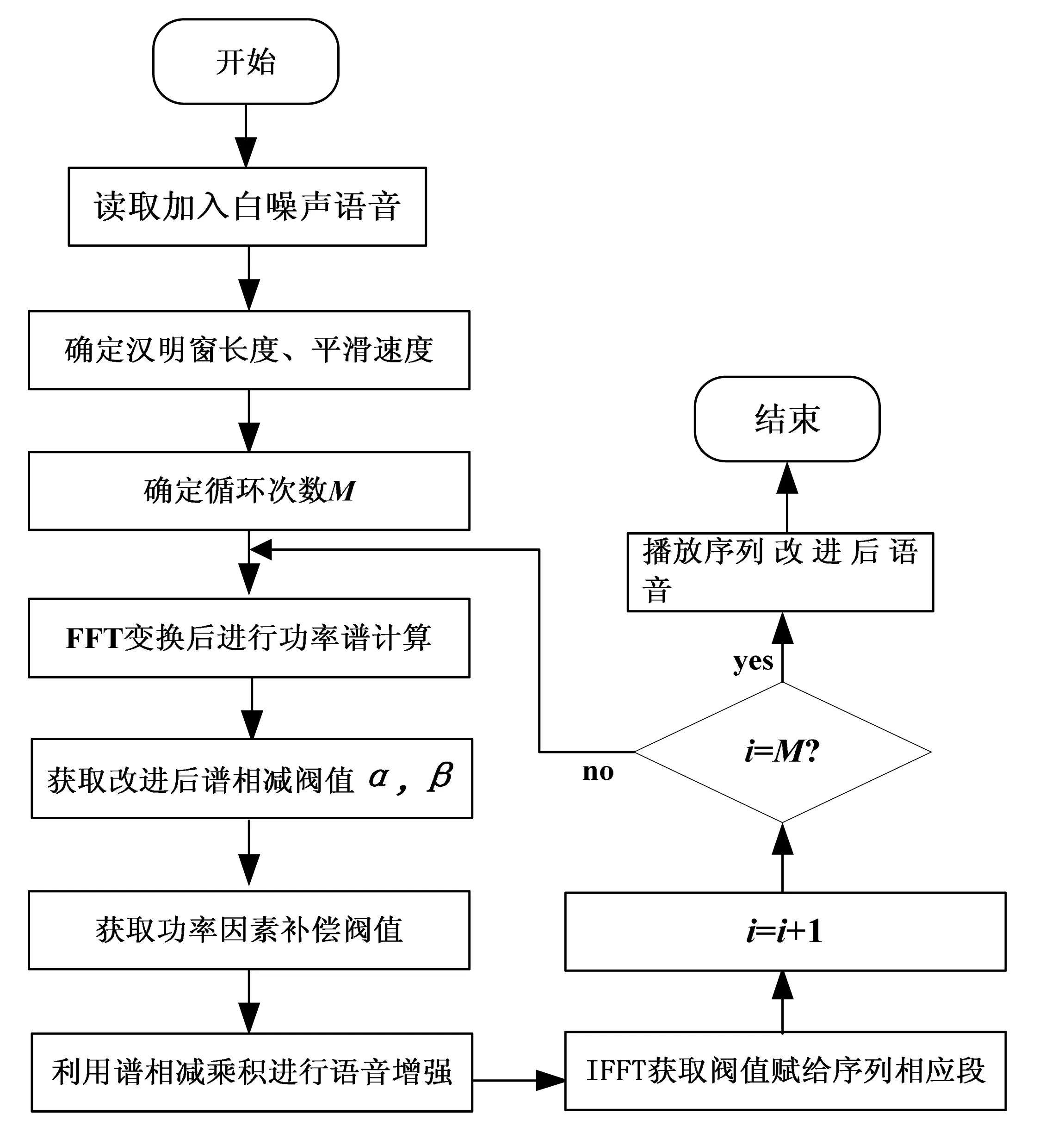
图3 谱相减改进算法语音增强处理实现流程
实现语音增强处理的程序功能以GUI界面设计,系统功能可以直观的演示原始语音波形和基于谱相减改进算法增强后语音波形情况对比,并且可以直接播放语音,对比语音前后变化情况。
3 系统测试和结果分析
完成基于谱相减改进算法的语音增强系统开发后,为了测试系统实现的功能和性能,进行测试实验。测试输入带噪语音样本由上述系统录制的时长大约为5 s的原始语音与产生m的倍高斯白噪声之和组成,将准备好的输入原始带噪语音样本在本系统进行播放,播放的语音波形如图4所示。
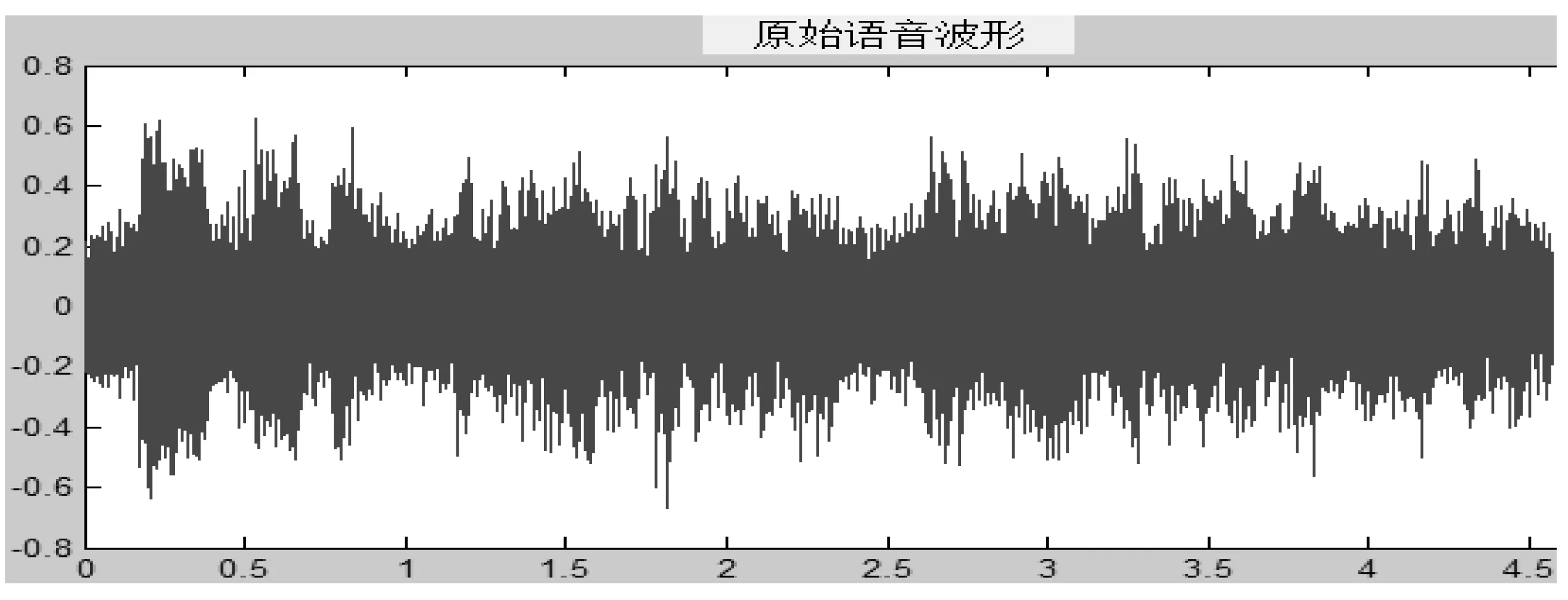
图4 原始语音波形
在系统测试中,输入时选取输入信噪比为15.6 dB,分别使用经典谱相减语音增强算法和改进谱相减语音增强算法对同样的带噪语音进行处理,处理的效果如图5所示。

图5 同样信噪比语音增强算法效果对比
对同样的样本,系统将原始带噪语音样本利用谱相减改进算法进行语音增强处理,根据不同的增强处理信噪比对语音增强处理后,设计选取信噪比为22.7 dB、43.4 dB对样本进行处理,语音播放的波形如图6所示。
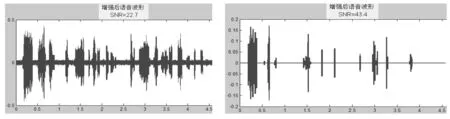
图6 改变信噪比语音增强后效果对比
通过对比经典谱相减语音增强算法和改进谱相减语音增强算法语音处理效果和不同信噪比的语音增强处理效果的图像,并且分别试听处理前后的语音,改进谱相减语音增强算法语音处理效果比经典谱相减语音增强算法有所改进,通过不断调整系数的方法,使得该改进算法获得更高的信噪比,经主观试听噪声减弱到不影响正常声音可以接受的范围,噪声得到了明显的抑制,噪声由原来的刺耳感觉变成柔和易于使人接受的声音。
在不断地测试中也发现,当信噪比取值过大,原始声音减幅值也显著下降,在噪声被滤波处理的同时,原来声音效果也会出现明显走样的情况,所以要多次测试,对比不同的效果,取得滤波效果最好,同时原始声音损失最小的信噪比取值。对比其他的处理方式,该算法在输入信噪比较低的情况下,增强处理后的语音输出信噪比明显提高,噪声滤波处理的效果已经凸显,原始的语音可较快的达到可读懂的范围。提高系数增大信噪比,语音滤波处理响应速度提高,语音增强处理的效果显著。
4 结论
适应数字化社会的不断发展,用数字化的方法对语音进行识别和增强的处理,这样的做法在很多领域得到应用,也是数字化通信网络通用的处理方式。本文在原有谱相减算法语音增强处理原理基础上改进该算法,并以此算法为基础,详细阐述利用MATLAB软件设计开发语音增强处理系统的实现方式。系统经过测试表明,能对输入的带噪语音样本,以不同的输入信噪比进行增强处理,处理后的语音噪声明显减少,同时语音可懂度得到了一定程序的提高。如果输入的原始噪声样本语音信噪比比较高,语音增强处理的效果更好,利用谱相减改进算法的语音增强系统,对带有噪声的语音完成数字处理从而实现增强的效果,有很好的现实作用。
[1]张雄伟,陈亮,杨吉斌.现代语音处理技术及应用[M].北京:机械工业出版社,2003:34-78.
[2]张勇,刘轶,刘宏.结合人耳听觉感知的两级语音增强算法[J].信号处理,2014,30(4):363-373.
[3]戴红霞,赵力.基于麦克风阵列的数字助听器语音增强技术[J].电子器件,2015,38(3):606-610.
[4]隋璐瑛,张雄伟,黄建军,等.基于码本学习的改进谱减语音增强算法[J].计算机工程与应用,2013,49(16):216-220.
[5]张贺,沈天飞,滕秋霞.基于级联式改进型谱减算法的语音去噪技术研究[J].工业控制计算机,2014,27(7):119-120,123.
[6]Wang Jizeng,Wang Chanfei.A New Speech Enhancement Method Based On Wavelet Packet Transform[J].2008International Congress on Image and Signal Processing,27-30May2008,Sanya,Hainan,China,be published by the IEEE and indexed in both EI and ISTP:317-321.
[7]张雪英.数字语音处理及MATLAB仿真[M].北京:电子工业出版社,2010:154-178.
[8]徐宁,何晨.语音信号增强算法研究与实现[J].仪表技术,2015(6):24-26,3.
[Key words]The improved spectral subtraction algorithm; speech enhancement; signal to noise ratio; MATLAB
[责任编辑刘景平]
Research and Implementation of the System of Speech Enhancement Based on the Improved Spectral Subtraction Algorithm
QIN Gui-li, LUO Yun-fang, PAN Ze-kai
(Department of Computer and Electronic Information Engineering, Guangxi Polytechnic,Nanning, Guangxi 530226, China)
Speech enhancement is widely applied in the digital communication network. An improved spectral subtraction algorithm of speech enhancement is proposed and a speech enhancement system is designed by the MATLAB based on this improved algorithm. Experimental results show that the system can well achieve speech enhancement with noise. The quality and intelligibility of sounds are all improved effectively.
TP391
A
1672-9021(2016)02-0073-06
覃贵礼(1976-),男,广西鹿寨人,广西职业技术学院计算机与电子信息工程系副教授,主要研究方向:电子技术和电气自动化技术。
2015-12-01
