基于改进LF算法的PPI网络聚类方法
2016-09-01胡嘉伟吴云志张友华
胡嘉伟,吴云志,乐 毅,张友华
(安徽农业大学 信息与计算机学院,合肥 230036)
基于改进LF算法的PPI网络聚类方法
胡嘉伟,吴云志,乐毅,张友华
(安徽农业大学 信息与计算机学院,合肥 230036)
研究蛋白质相互作用(Protein-Protein Interaction, PPI)网络是理解生命活动的重要途径之一,运用数据挖掘中的聚类分析方法去研究蛋白质相互作用已经成为生物信息学的热门领域.作为一种在PPI网络聚类分析中新兴的智能优化算法,蚁群聚类算法因其固有的简单性、灵活性和鲁棒性显示出了巨大应用潜力.将蚁群聚类算法应用到PPI网络聚类中,并进行了改进,提出了一种新的PPI网络聚类算法.算法引入边关联强度的概念并以边关联强度作为相似度参数,对蚁群聚类算法中的拾起/放下策略加以改进.算法在MIPS数据库中的PPI数据集上进行了聚类测试,实验结果表明新算法的聚类效果和运行效率都较为理想.
PPI网络;蚁群聚类算法;边关联强度;聚类分析
0 引 言
人类基因组测序的完成标志着一个新的生物学研究时代-后基因组时代的来临, 与此同时产生了海量的基因组测序数据,传统的生物学分析方法在大规格的基因组数据研究上已经显现出不足,运用数据挖掘中的聚类分析方法研究蛋白质相互作用日益成为生物信息学的研究热点[1].
近年来,因自身的简单性、灵活性和鲁棒性等优势的群智能优化算法在蛋白质网络聚类分析中得到了较好的应用前景.本文在Lumer和Faieta提出的LF蚁群聚类算法基础上引入边关联强度,对蚂蚁的拾起规则做了相应改进,进一步提出了改进的LF聚类算法,该算法在减少算法时间开销的同时还可提升对PPI网络的聚类效果.
1 基本理论
1.1蚁群聚类算法
Lumer和Faieta提出的蚁群聚类算法主要思想描述如下[2]:
将待聚类的数据随机分布在一个二维平面上,并随机产生虚拟蚂蚁,蚂蚁在平面移动的过程中会对自身所背负的数据信息与周围数据进行相似性判断,根据拾起放下策略判断拾起或放下数据,最终产生数据聚类效果.
该算法首先将数据随机分布在一个m×m的网格中,设蚂蚁所处的位置为r,能见度为S,蚂蚁在地点r观察要比对的对象i,对象在地点与周围物体的相似度计算公式为:
(1)
式中d(i,j)是i和j两个数据对象之间的空间距离,α为衡量相似程度的参数.在LF算法中,蚂蚁选择拾起或放下一个数据对象的概率如下式计算:
(2)
(3)
其中,式(2)、式(3)分别是计算蚂蚁拾起和放下数据的概率,k1、k2为两个常数.如上所示,LF算法需要随机产生一个概率与拾起或放下概率作比较,符合策略时才会执行相应的操作[3].
1.2边关联强度
在数据挖掘中,聚类分析通常以对象间距离或相似性度量为基础,目标是使类内紧密而类间稀疏.网络图结点间基于结构等价性的相似性度量应用最广泛的是Jaccard相似度,如式(4)所示:
(4)
Jaccard的假设认为:若网络图中2个结点间的公共邻接点越多,这2个结点在结构上越相似或相等.但当2个相邻结点的拓扑结构差异性较大时,该度量不能很好地反应结点之间的连接倾向性[4].如图1所示,图1中Jaccard(AB)均为2/9,但是明显可以看出图1(a)中的结点A、B在网络中更加紧密.
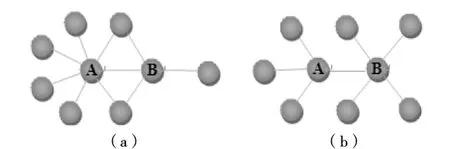
图1 2个网络实例
因此,对于不同的拓扑结构,王杰等人基于结点间的邻域定义了关联强度来描述网络图中结点之间边连接的紧密程度,其定义如下[5]:
对图G中的边uv∈E,假设结点度d(vi)≤d(vj),N(vi)、N(vj)分别为结点vi、vj的邻居集合,则边vivj∈E(G)的关联强度w(vivj)为:

(5)
w(vivj)的取值范围为[0,1],当vi与vj间不存在叶子结点且不存在任何共同邻居时w(vivj)=0,当结点vi和vj是对方的唯一邻居时,则w(vivj)=1.以图1为例,图1(a)中w(AB)=2/3,图1(b)中w(AB)=2/4,体现了两者在拓扑结构上的差异,以此使得聚类效果更加有效.
2 改进的蚁群聚类算法描述
2.1算法思想
根据对LF算法的描述,可知LF算法中的拾起和放下概率是随机的,蚂蚁在对数据进行拾起放下操作时可能会导致反复操作,这样会降低算法的运行效率,并且初始节点的选取,也会对算法的效率影响明显[6].
改进算法在LF算法思想的基础上,首先调整了蚂蚁对数据的拾起策略,从上文得知边关联强度能更好的反应聚类效果,且计算方式相对简单,因此采用了边关联强度来代替随机概率作为蚂蚁的拾起放下策略;其次在初始结点的选取上,蚂蚁的初始位置从较优数据中随机选取而来;最后考虑到PPI网络的小世界性,还对蚂蚁的移动范围(距离初始位置的距离)进行了控制.改进后的蚁群聚类算法步骤如下:
输入:PPI网络数据,图G=(V,E);参数L为蚂蚁的移动范围;ε为边关联强度设定的阈值.
输出:聚类结果.
(1)设有n个蛋白质结点,为每一个蛋白质结点进行编码,并统计各结点的度,蛋白质结点集合记为S=(s1,s2,…,sn),在初始蚂蚁的选取上,为了提高算法的效率而随机选择度比较高的结点si,i∈n;
(2)蚂蚁si的初始类记为Ci,Ci=(si).si可视范围记为NSi,在可视范围内计算各结点的边关联强度w(si,sj),sj∈NSi,若w(si,sj)≥ε,进行拾起操作,初始类进行扩充,Ci=(si,sj);
(3)当有结点被拾起时,蚂蚁移动至新结点的位置,蚂蚁的移动范围l++,进入判定条件l≤L是否成立:若成立,返回第(2)步,在新结点位置重新进行聚类操作;若不成立,转至第(4)步;
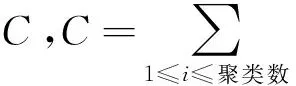
(5)调整ε的值,根据放下策略放弃部分稀疏点数据;
(6)产生最终聚类结果.
2.2算法时间复杂度
如上述所示,假设PPI网络的数据规模为N,在蛋白质聚类过程中每个蛋白质结点最少会被操作一次.每个结点在每次的聚类中都被操作一次但是都没有聚类成功的情况下,此时每个结点被操作了N次.因此算法的时间复杂度最大为O(N2),最小为O(N).
3 仿真实验及结果分析
3.1实验数据和实验环境
以MIPS数据库作为本实验的实验源数据,并以MIPS数据库提供的信息作为本实验的参照标准,来判断本文算法聚类结果的准确率及运行效率.标准库部分信息如表1所示.

表1 标准库信息
3.2评价准则
本文在对聚类结果进行评价的过程中,采用了如下三种比较常见的评价指标:覆盖率Coverage、正确率Percision和查全率Recall.假设P为算法预测的蛋白质模块,B为标准数据库中存在的蛋白质模块,m和n分别为算法聚类蛋白质数和标准数据库聚类蛋白质数.覆盖率Coverage表示最终被聚类的蛋白质数量占整个网络蛋白质个体百分比,正确率Percision表示模块P和B的交集结点个数占P中蛋白质结点个数的百分比,查全率Recall则表示模块P和B的交集结点个数占B中蛋白质结点个数的百分比.
(6)
(7)
(8)
如上式所示,Coverage越高,表明本次实验保留的蛋白质越多;Percision越高,表明模块内部的准确性越高;而Recall越高时,则表明本次实验预测出的有效蛋白质模块的数量越多.
3.3结果分析
本次实验需要控制的输入参数有L(蚂蚁的移动范围)、ε(边关联强度设置的阈值),由文献可知,蛋白质复合物内部的评价距离一般不超过2,网络中结点的特征路径评价长度小于5[7].因此,在这里将L的值设为5.为了观察ε值对聚类结果的影响,在实验中保持其他参数值不变,通过不断调整ε值,观察可知当ε值为0.2~0.4时,实验所得聚类的个数、聚类蛋白质数以及最大最小类与标准库的较为接近.
结合以上分析,本实验室将ε设为0.3,L设为5,将算法运行了20次,实验结果如表2所示;同时,我们选取现有的聚类算法,用相同数据库作了实验结果比较,对比图如表3所示.
表2 聚类结果

表3 聚类结果对比图
通过上述比较可以得知:对于蛋白质相互作用网络中的聚类分析,基于边关联强度的蚁群聚类优化算法可以有效找出聚类结果,而且算法的效率高,时间复杂度低.
4 结 论
本文提出的基于边关联强度的蚁群优化聚类算法可以应用在蛋白质相互作用网络中并能取得较好的聚类效果,时间空间复杂度得到了降低,但是在后续工作中还有优化的空间,以期能应用到更大规模的蛋白质相互作用网络.
[1] Aidong Zhang.Protein Interaction Networks [M].New York: Cambridge University Press, 2009: 44-47.
[2] Lumer E, Faieta B. Diversity and Adaptation in Populations of Clustering Ants[A].Proceedings of the 3rd International Conference on Simulation of Adaptive Behavior:From Animal to Animals [C]. Cambridge, MA: MIT Press, 1994: 499-508.
[3] 雷秀娟,黄旭,吴爽,等.基于连接强度的PPI网络蚁群优化聚类方法[J].北京:电子学报,2012,40(4): 695-702.
[4] 王杰,梁吉业,郑文萍,等.一种面向蛋白质复合体检测的图聚类方法[J].北京:计算机研究与发展,2015,52(8): 1784-1793.
[5] 牛永杰.LF算法中蚁群移动策略的研究[J].西安:航空计算技术,2013,43(4): 18-21.
[6] 金弟,刘大有,杨博,等.基于局部探测的快速复杂网络聚类算法[J].北京:电子学报,2011,39(11): 2540-2546.
[7] 李敏,王建新,陈建二,等.基于距离测定的蛋白质复合物识别算法[J].长春:吉林大学学报,2010,40(5): 1318-1323.
PPI Network Clustering Method Based on Improved LF Algorithm
HU Jia-wei,WU Yun-zhi,YUE Yi,ZHANG You-hua
(School of Information & Computer, Anhui Agricultural University, Anhui 230036, China)
Protein-Protein interactions network research is one the most important ways to understand of life activities. Using the clustering analysis method in data mining to study protein interactions has become popular in the field of bioinformatics. In PPI network clustering analysis, ant colony clustering algorithm as a new intelligent optimization algorithm, shows great potential for application because of its inherent simplicity, flexibility and robustness. Ant colony clustering is introduced into PPI network clustering, and is improved.A new PPI network clustering method is presented.This method modifies the pickup/drop rules of Ant colony algorithm by means of introducing the concept of edge intensity, which regards the edge intensity as similarity paramter to cluster the PPI network.Finally the algorithm is tested on the PPI data in MIPS database.The simulation results show that the new algorithm has better clustering effect and running efficiency.
PPI network; Ant colony clustering method; edge intensity; clustering analysis
2016-04-05
胡嘉伟(1991-),男,硕士研究生,研究方向:生物信息.
张友华(1966-),男,博士,教授,研究方向:农业信息工程.
TP301.6
A
1671-119X(2016)03-0056-04
