基于短时谱估计的语音增强改进算法
2016-09-01李真吴文锦任慧
李真,吴文锦,任慧
(1.中国传媒大学理工学部,北京 100024;2.视听技术与智能控制系统文化部重点实验室,北京 100024;3.现代演艺技术北京市重点实验室,北京 100024)
基于短时谱估计的语音增强改进算法
李真,吴文锦,任慧
(1.中国传媒大学理工学部,北京 100024;2.视听技术与智能控制系统文化部重点实验室,北京 100024;3.现代演艺技术北京市重点实验室,北京 100024)
语音在传输过程中受到来自周围环境、传输媒介等的干扰是不可避免的,这些干扰会严重影响语音接收时的质量,导致收到的语音信号不再是原始的纯净语音信号,而是带有各种干扰噪声的语音信号,这不仅影响语音的收听质量,也给后续的语音处理带来了一定的影响。因此对语音进行增强不可或缺。大部分传统的语音增强算法仅仅只通过改变语音的幅度,再叠加上原始的语音相位或者仅调整语音的相位再和未改变的幅度叠加来实现语音信号重建从而增强语音。本文提出了一个通过既改变语音信号的幅度又改变其相位的语音增强算法。通过使用客观语音质量测评(PESQ)和语谱图对用不同方法增强后的语音进行比较,验证了用本文方法得到的增强语音质量更佳。
语音增强;幅度谱;相位补偿
1 引言
语音通信是人类最重要、最有效、最便捷的通信方式,语音信号承载着不同的信息和情感,是人类互相交流和表达的重要媒介。然而,语音在传输过程中不可避免的会受到不同因素(环境、传输媒介、设备内部结构等)的干扰,使得接收到的语音变成带噪的语音,大大降低了语音质量。为了获得纯净的语音信号,就需要进行语音增强。
对于已有的语音增强算法,根据接收端所使用的麦克风数目可分为单通道语音增强算法和多通道语音增强算法,本文研究单通道语音增强算法。在单通道语音增强研究领域中目前的研究热点在于如何去除含噪语音信号中的噪声部分,尽力恢复原始的纯净语音信号,大致可分为基于短时谱估计、基于信号子空间[1][2]、基于语音生成模型[3][4]等语音增强算法。其中基于短时谱估计的语音增强算法应用最为广泛,其通过对带噪语音信号进行短时傅里叶变换后进行纯净语音幅度谱估计,结合带噪语音的相位之后进行短时傅里叶反变换,从而得到纯净语音估计。常用的有谱减法、维纳法和基于统计模型的短时谱估计语音增强算法。常用的估计算法有:最小均方误差估计、最大似然估计和最大后验概率估计。这些经典的语音增强算法是只改变带噪语音的幅度谱,而保持带噪语音的相位谱不变,二者生成一个新的复合频谱。Kamil Wójcicki 等提出改变带噪语音的相位谱,而不改变带噪语音的幅度谱[5],在所有信噪比情况下取得稳定的语音增强效果,在信噪比小于15dB时效果略差于logMMSE方法,但是在信噪比大于等于15dB时,相比于经典的MMSE或者logMMSE能取得更好的语音增强效果。
基于以上算法所存在问题,本文提出一种既改变带噪语音幅度谱又改变相位谱的语音增强算法。首先用经典的logMMSE增强算法进行带噪语音的幅度谱估计,之后再利用相位补偿方法估计带噪语音的相位谱,最后由二者结合组成符合频谱作为纯净语音的频谱估计。从而可以在任意信噪比情况下取得较好的语音增强效果。
2 短时幅度谱对数最小均方误差估计语音增强算法(logMMSE)
其中,Xk为带噪语音输出频域谱,νk由下式表示:
ξk指先验信噪比,表达式如下:
3 相位补偿语音增强算法
带噪语音信号是实信号,所以其傅里叶变换是共轭对称的,即Χ(n,k)=Χ*(n,N-k)
相位谱补偿函数定义如下:
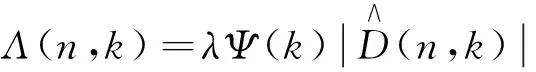
(4)
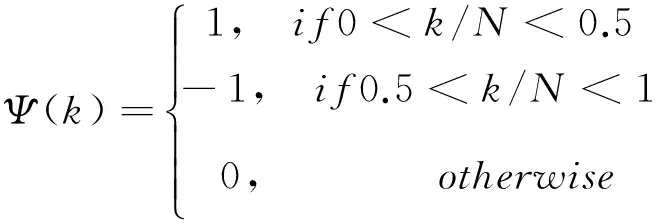
(5)
当信号的短时傅里叶变换后为非共轭矢量时,Λ(n,k)的值为0(当k=0和N为奇数,k=N/2时),原带噪语音频谱与相位补偿函数进行补偿得到
XΛ(n,k)=X(n,k)+Λ(n,k)
(6)
进一步得到补偿相位谱如下:
∠XΛ(n,k)=ARG[XΛ(N,K)]
(7)
补偿的相位谱与含噪语音的振幅谱结合就组成一个可调复合谱信号,表达式如下:
(8)
相位补偿算法矢量原理如图1所示。
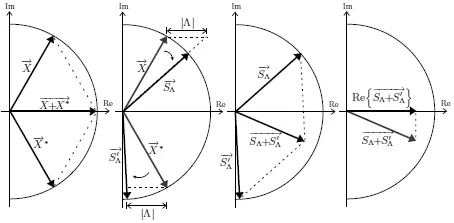
信号幅值改变很有限
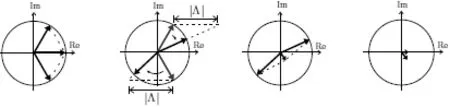
,信号幅值发生明显改变图1 相位补偿法矢量原理图
从上述矢量图可以看出,对于带噪语音信号的幅度谱越小则被补偿信号消弱的越明显,通常情况下,认为背景噪声和语音信号频率相比,低振幅的成分更多一些,所以这种算法能有效去除低振幅频率分量,即能比较好的去除噪声达到语音增强的目的。
4 幅度谱估计与相位补偿改进算法
基于幅度谱估计的语音增强算法因为没有对相位进行改变,仍保持带噪语音相位,所以增强效果受到一定限制,基于相位补偿的算法,因为只对相位进行补偿,没有改变带噪语音幅值,所以在低信噪比时增强效果受到限制,本文将两种算法进行结合,达到更好的语音增强效果。
首先对带噪语音进行分帧后加窗函数,然后进行傅里叶变换,得到其表达式如下:
(9)
再分别用相应算法对所得频谱的幅度和角度进行改进,用logMMSE算法改进幅度,得到改进的幅度表达式如下:
(10)
用相位补偿算法对相位进行补偿,得到新的相位表达式如下:
XΛ(n,k)=X(n,k)+Λ(n,k)
(11)
进一步得到补偿相位谱表达式如下:
∠XΛ(n,k)=ARG[XΛ(N,K)]
(12)
则改进后的频谱表达式如下:
(13)
上述过程的流程图如图2所示。
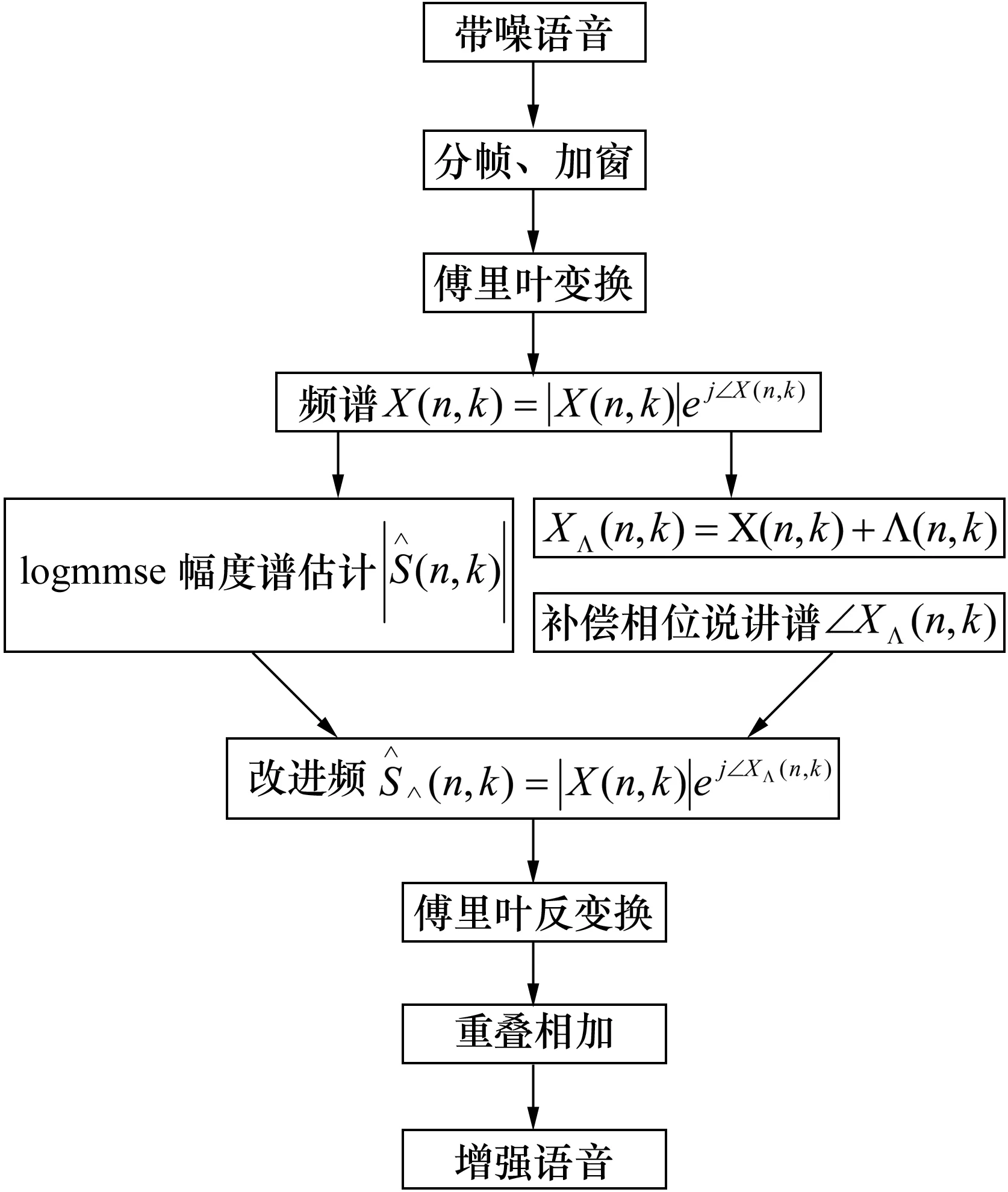
图2 幅度谱估计与相位补偿改进算法流程图
5 实验仿真与分析
实验所用的素材是NOIZEUS语料库中的语音,语料库中有8种不同信噪比的带噪语音,但是没有含白噪声的语音,我们在处理过程中生成了一系列信噪比(0db,5db,10db,20db)的含加性白噪声的语音(白噪声来自NIOSEX-92语料库)。我们使用不同方法对带噪语音进行增强实验,包括谱减法(SSUB),最小均方误差法(MMSE),相位补偿法(PSC)及本文提出的方法。通过客观语音质量测评(PESQ)和语谱图对不同方法进行比较。
在我们的实验中,分析窗函数使用的是汉明窗,帧持续时间设定为32ms,帧转换为4ms,快速傅里叶变换长度为1024个采样点,不对称函数(9)也在实验中有所应用,其中的λ=3.74。
语音增强实验的客观语音质量测评(PESQ)结果比较如下表1所示,语谱图分析结果比较如下图3所示。观察表1结果可以看出,相比于其他的增强方法,在四个信噪比情况下,本文提出的方法得分相较于其他方法要高,拥有最佳的增强效果。从图3结果也可以看出,本文提出的方法能更好的抑制噪声,语音增强效果也最为显著。
6 结论
本文提出了一种语音增强的新方法,该方法不再是单一的改变语音的幅度谱或相位谱,而是改变幅度谱的同时对相位谱进行相位补偿。从实验结果可以看出,本文方法优于其他的传统增强方法。该方法可用于需要抑制噪声的语音识别系统、语音通信系统等,能提高语音的质量和可懂性。

图3 不同方法增强NOIZUES语料库中信噪比为10dB的sp10语音的语谱图
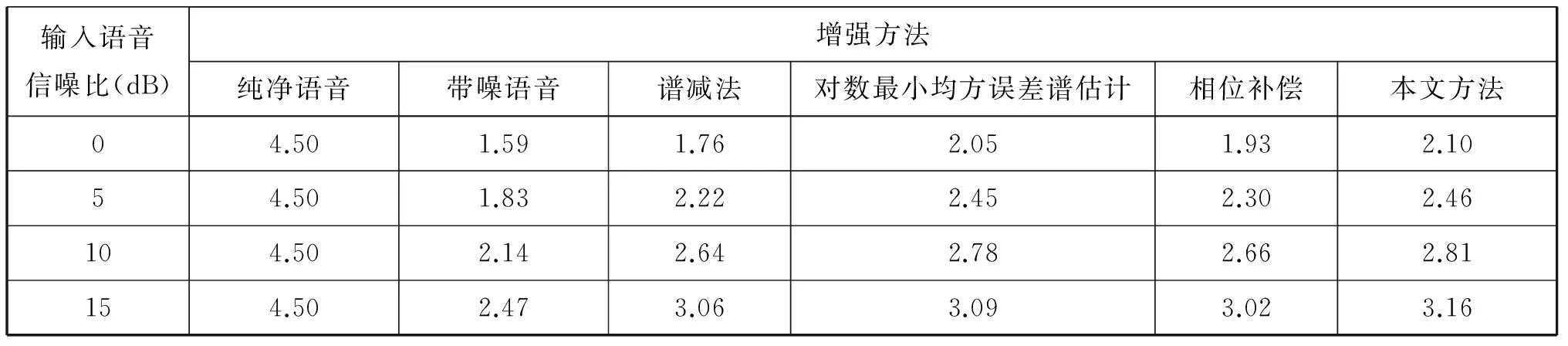
表1 logMMSE,PSC,SSUB和本文方法对带白噪声语音信号增强后的平均PESQ得分
[1]Dendrinos M,Bakamidis S,Carayannis G. Speech enhancement from noise:A regenerative approach[J]. Speech Communiation,1991,10(1):45-57.
[2]Jensen S H,Hansen P C,Hansen S D,Sorensen J A. Reduction of broadband noise in speech by truncated QSVD[J]. IEEE Transactions on Speech Audio Processing,1995,3(6):439-448.
[3]Lim S,Oppenheim A V. Enhancement and bandwidth compression of noisy speech[J]. Proceedings of IEEE,1979,67(12):1586-1604.
[4]Hansen J H,Clements M A. Constrained iterative speech enhancement with application to automatic speech recognition[D]. IEEE Transactions on Signal Processing,1991,39(4):795-805.
[5] Kamil Wójcicki,Mitar Milacic,Anthony Stark,James Lyons,Kuldip Paliwal. Exploiting Conjugate Symmetry of the Short-Time Fourier Spectrum for Speech Enhancement[A].IEEE Signal Process,Lett,2008,15:461-464..
[6] Ephraim Y,Malah D. Speech enhancement using a minimum mean square error short time spectral amplitude estimator[J]. IEEE Transactions on Acoustics,Speech,Signal Processing,1984,32(6):1109-1121.
[7] Ephraim Y,Malah D. Speech enhancement using a minimum mean square error log-spectral amplitude estimator[J]. IEEE Transactions on Acoustics,Speech,Signal Processing,1985,33(2):443-445.
(责任编辑:马玉凤)
Improved Algorithm of Speech Enhancement Basedon Short-time Spectrum Estimation
LI Zhen,WU Wen-jin,REN Hui
(1. Information Engineering School,Communication University of China,Beijing 100024;2. Key Laboratory of Acoustic Visual Technology and Intelligent Control System,Ministry of Culture,Beijing 100024;3. Beijing Key Laboratory of Modern Entertainment Technology,Beijing 100024)
Speech signals will be disturbed inevitably by environmental factors and transmission media during transmission. It leads to the lower quality of received speech,and the speech turns into noisy speech rather than the original clear speech,which can not only influence the voice receiving quality but also the post processing of speech. Hence,speech enhancement is very essential. Typical speech enhancement algorithms only modify the magnitude spectrum recombined with the unchanged phase spectrum or adjust the phase spectrum recombined with unchanged magnitude spectrum to reconstruct the enhanced speech signal. In this paper,a new method was proposed,which enhanced the speech by the way to change both magnitude spectrum and phase spectrum to get reconstructed speech that enhanced. The objective speech measure PESQ test and spectrogram analysis had proved that the proposed method earns outperformance among the typical algorithms.
speech enhancement;magnitude spectrum;phase spectrum compensation
2016-06-20
“十二五”国家科技支撑计划重大项目“演出呈现关键支撑技术研发与应用示范(项目编号:2012BAH38F00)”资助
李真 (1978- ),女(汉族),河北衡水人,中国传媒大学讲师. E-mail:lizhen@cuc.edu.cn
TN919
A
1673-4793(2016)04-0065-05
