用户在线购买预测:一种基于用户操作序列和选择模型的方法
2016-08-31曾宪宇赵洪科王怡君陈恩红
曾宪宇 刘 淇 赵洪科 徐 童 王怡君 陈恩红
(中国科学技术大学计算机学院 合肥 230027)
用户在线购买预测:一种基于用户操作序列和选择模型的方法
曾宪宇刘淇赵洪科徐童王怡君陈恩红
(中国科学技术大学计算机学院合肥230027)
(zengxy@mail.ustc.edu.cn)
电商网站的兴起与用户在线购物习惯的形成,带来了海量的在线消费行为数据.如何从这些行为数据(如点击数据)中建模用户对相似产品的比较和选择过程,进而准确预测用户的兴趣偏好和购买行为,对于提高产品的购买转化率具有重要意义.针对这一问题,提出了基于用户行为序列数据和选择模型的在线购买预测解决方案.具体而言,1)使用行为序列效用函数估计用户在购买周期(session)中的最佳替代商品,然后对购买商品和最佳替代商品建立基于潜在因子的选择模型(latentfactorbasedchoicemodel,LF-CM),从而得到用户的购买偏好,实现对用户购买行为的预测.更进一步,为了充分地利用用户在每个购买周期的所有选择和比较信息,提高预测精度;2)提出了一种可以作用于购买周期内所有商品的排序学习模型(latentfactorandsequencebasedchoicemodel,LFS-CM),它通过融合潜在因子和行为序列的效用函数,提高了购买预测的精度;3)使用大规模真实数据集在分布式环境下进行了实验,并与参照算法进行了对比,证实了所提出的2个方法在用户在线购买预测上的有效性.
在线购买预测;选择模型;行为序列;序列效用;分布式平台
随着电子商务的迅猛发展,电商消费者规模与在线交易量呈现激增态势.根据第36次中国互联网络发展状况统计报告的数据,截止2015年6月,我国在线购物用户与网络支付用户规模均突破3.5亿.国内最大电商平台阿里巴巴集团的财报亦显示,其2014年全年成交量达2.3万亿元人民币,同比增长47%.然而,电子商务在为人们的生活带来便捷的同时,由于其所承载商品的类别丰富且营销方式多样,这些海量信息也为用户挑选所需商品增添了诸多困难[1-2].因此,借助技术手段准确分析用户购买行为,为用户决策或商家营销提供支撑,已成为当前面向商务智能的数据挖掘领域重要的研究问题,对于改善用户体验、提高电商收益具有重要意义.
在此背景下,协同过滤等定向推荐技术[3]应运而生,并广泛运用于各电商网站的营销系统中.这些传统的推荐技术主要分析用户的购买行为,并以此为依据推荐相似或者相关的商品供用户选择[4].然而,它们仅着眼于孤立的交易(购买)行为,却忽略了这些购买与用户其他类型的行为(如在购买时为了比较相似产品而进行的点击行为)之间的关联.因此,定向推荐技术往往能够分析出用户会购买哪一类型的产品,却不能精准预测用户在一个购买周期(session)内最终选择哪个商品进行购买.这里,购物周期包含用户购买产品过程中所发生的一系列针对多种相似的、竞争产品的点击、比较行为和最终所发生的购买行为所组成的用户行为序列.可以看出,因为在线购物网站商品的多样性,不同用户在不同购买周期所面临的选择都千差万别,而且在同一购买周期内的产品经常是同类型的、相似度很高的产品,造成了传统的推荐技术难以进行用户在线购买的预测.与此同时,在线购买预测对于提高电商网站经济效益(如预测和提高产品的购买转化率、帮助用户进行购买目标(选择集)的筛选)有着重要的意义,所以,如何利用购买周期所包含的产品比较和选择信息序列来描述用户的当前购买意图,准确预测用户将要发生的购买行为是本文所关注的核心问题.
针对在线购买预测的问题场景和购物周期的数据特性,本文提出了基于用户行为序列数据和选择模型[5]的在线购买预测方案.具体而言,本文分别设计了基于潜在因子的选择模型(latentfactorbasedchoicemodel,LF-CM)和基于潜在因子和行为序列效用的选择模型(latentfactorandsequencebasedchoicemodel,LFS-CM).在LF-CM模型中,通过引入机会成本的概念,分析用户行为序列,并使用行为序列效用函数估计用户在购买周期中的最佳替代商品(即在同一周期中,除去最终的购买选择外最可能购买的商品),从而对购买商品和最佳替代品建立选择模型,进而利用用户历史购买行为中同一周期内的商品比较选择信息,对用户当前的购买偏好进行排序学习.在LF-CM模型基础之上,为更好地利用购物周期所包含的所有产品选择和比较信息,还提出了一个可以融合潜在因子和行为序列的效用函数,作用于购买周期内所有商品的排序学习模型LFS-CM.相比于LF-CM模型,LFS-CM能够更充分地分析用户的选择行为,以提升预测精度.
最后,为验证本文所提算法,在国内最大的电商网站Tmall的真实数据集上,借助Tmall提供的大规模、分布式数据处理服务(opendataprocessingservice,ODPS)平台进行了分布式实验,并与该领域的多个参照算法进行了对比.实验结果证实了本文所提出的LF-CM和LFS-CM方法在用户在线购买预测上的有效性.
1 相关工作
与本文相关的工作主要分为2个方面:1)离散选择模型;2)在线购买预测.
1.1离散选择模型
离散选择模型是经济学中的重要概念,又称为定性选择模型(qualitativechoicemodel)[6].离散选择模型表示了从2个或者更多的离散候选项目(产品)中做出选择的过程.在可选项离散的情况下,研究的是选择“哪一个”的问题[7].经典的离散选择模型有逻辑回归(logisticregression,LR)[8]、Probit回归(probitregression)[9]等.离散选择模型将事件发生与否概率解释为特征变量的函数,可以由模型计算得到选择各个物品的概率而得到最终的结果.
由于其在决策建模上的有效性,离散选择模型被广泛应用于社会学、生物统计学、数量心理学、市场营销等多个领域[10].例如,市场调研人员使用选择模型研究用户的需求、预测商品的市场响应[6];交通管理人员使用选择模型来规划交通系统[11-12];社会学研究者使用选择模型来预测职业和训练项目[13].此外,离散选择模型还可用于描述一些新兴应用场景.例如,文献[14]提出了一种基于用户近期偏好的选择模型用于解决兴趣点(pointofinterest,POI)推荐;文献[15]提出了一种使用绝对距离和相对距离作为特征输入的选择模型来模拟用户在地图上进行餐馆选择过程的方法.
1.2在线购买预测
在线购买预测对于电商网站提高经济效益有着重要的意义,在工业界已经被广泛重视,Tmall与Recsys都曾举办过关于在线购买预测的比赛.大部分队伍使用了特征工程和模型融合的方法[16-18].这些方法首先提取出用户序列中与购买有关的特征,然后借助不同的模型(例如逻辑回归[8]、梯度提升决策树(GBDT)等)进行拟合训练及模型融合[19].例如,在Tmall举办的移动购买预测比赛中文献[17]首先使用训练数据得到多个GBDT模型,然后用其输出作为LR模型的输入,得到最终的预测结果.同时,相关问题在学术界也正被广泛的研究,例如,文献[20-22]使用社交信息,研究了在用户的选择与消费和社交因素之间的联系.
与此同时,推荐技术在某种程度上也可以解决购买预测问题[23].传统的推荐技术包括基于内容推荐[24]、协同过滤(ModelBasedCF[25],MemoryBasedCF[26])和混合推荐策略[27].然而,如在引言中所述,由于这些技术多着眼于孤立的用户交易(购买)行为,却忽略了这些购买与用户其他类型的行为(如在购买时为了比较相似的、竞争的同类型产品而进行的点击行为)之间的关联,因此虽然能够分析出用户在之后一段时间内可能会购买哪一类型的产品,却不能精准预测用户在一个购买周期内最终选择哪个商品.而本文引入购物周期和机会成本等概念,通过使用用户的操作行为序列建模用户在相似产品之间的比较信息,更加清晰地反应了用户的真实偏好,能够更有效地解决用户在线购买预测的问题.
2 预备知识
本节将首先介绍在线购买预测针对的场景和使用的数据形式,然后定义本文中涉及到的基本概念,最后对在线购买预测问题进行形式化描述.
2.1问题场景和数据描述
以Tmall为例,用户在进行在线购物时,会看到许多待选商品,在对这些商品进行比较和选择时,会产生一系列的行为序列数据,如点击(click)、收藏(collect)、加入购物车(cart)、和购买(buy)等,并被系统记录到用户操作日志中.例如,Tmall提供的日志数据样例如表1所示:

Table 1 Example of Original Records表1 原始数据示例
表1数据共包含6个字段,分别是用户(user)、交互商品(item)、商品品牌(brand)、商品类别(category)、用户操作类型(action)和时间戳(timestamp).每个用户的行为日志记录了此用户在Tmall平台上完整的行为数据.
为了更加方便地描述用户单次消费的选择情形,按照时间戳信息对用户行为序列进行划分,从而获得用户在线购物中的购买周期(session).本文采用以下的启发式方法进行购买周期划分:以每次的购买行为作为分割点,向此分割点之前的操作记录进行搜索,如果该记录与下一个操作之间的时间间隔小于设定的阈值(如若干小时),就将其归到该次购买商品所对应的周期中.需要注意的是,在该分割方法下,一个购买周期中只有一个被购买的产品.通过周期划分,可以得到每个用户在不同购买周期的行为序列,如表2所示:

Table 2 Example of Session Records表2 分段后的数据示例
例如,表2的第1行表示用户U1在购买周期S1中的产品操作序列为a,b,b,b,a,c,c,b,而他最终购买的是产品b.需要注意的是,为了简单起见,表2忽略了用户不同的操作类型click,cart和collect的差异,而将其视为统一的浏览(点击)操作,即本文主要关注于挖掘统一产品操作中的用户序列模式.
2.2相关概念
本文主要讨论用户在线购买商品的行为及其预测方法.在本文中,所有的用户构成的用户集合U表示为U={u1,u2,u3,…},所有的商品构成的商品集合I表示为I={i1,i2,i3,…}.在此基础之上,给出购买周期以及其他相关概念的形式化定义:
定义1. 购买周期(session).一个购买周期s表示一个用户在一定时间范围内经过对比和选择并最终产生购买行为的过程,可以表示为一个三元组s=(u,sq,ib).其中u∈U,表示该购买周期的用户;sq={ib1,ib2,ib3,…}表示用户在该购买周期内的商品操作序列,即表2中的ItemSequence字段的商品记录,ib∈sq表示用户在此次购买周期中经过比较和选择之后最终购买的商品.所有购买周期的集合记为S={s1,s2,…}.
定义2. 商品效用.为了量化用户对商品的购买意愿,在任一个购买周期s中,针对某一用户u,对每件商品i定义一个效用值ws,u,i=w(s,u,i),其表示该用户在当前购买周期中对于该商品价值的衡量.效用值越高,说明用户对商品价值的衡量越高,购买它的可能性也越大.
定义3. 机会成本.在购买周期s中,当用户购买了商品ib时,就意味着会放弃其他的商品.机会成本ws,u,io c即指该购买周期中放弃的所有商品所对应的最大效用值(是个估计值),而具有该最大效用值的产品io c被称为购买周期中的最佳替代商品,即:

最后,本文所研究的问题可总结为从用户所有的历史在线购买周期的序列模式中挖掘用户对商品的潜在兴趣和心理偏好,并根据当前购买周期中已出现的商品操作序列准确地预测用户可能购买的商品.形式化描述为:给定历史训练数据ST,从中学习到预测模型M;对于任意待预测的购买周期s=(u,sq,ib),在u和sq已知的情况下利用预测模型M预测出用户u在此次购买周期中最有可能购买的商品ib.
3 模型介绍
针对上述的研究问题,本文提出了2种排序选择模型:基于潜在因子的选择模型(LF-CM),及基于潜在因子和行为序列效用的选择模型(LFS-CM).具体而言,两者都借鉴了潜在因子模型中的潜在因子(latentfactor)概念,即通过对用户操作序列的分析,将用户和商品的属性分别映射到低维空间中(潜在因子).
基于潜在因子的选择模型(LF-CM)首先基于行为序列的特征设计出序列效用函数,接下来根据该效用函数计算购买周期内所有商品的预估效用值,从而在当前购买周期内确定最佳替代商品,然后在当前购买商品与最佳替代商品之间建立选择模型.因此,在单个购买周期内,LF-CM模型只需要在当前购买商品和最佳替代商品之间进行对比学习(潜在因子学习),从而可以有效地减少学习训练时间.
基于潜在因子和行为序列效用的选择模型(LFS-CM),将商品的潜在因子和在当前购买周期内的行为序列效用结合在一起表示商品的效用,并在当前购买商品和本周期所有候选的商品之间建立选择模型.相比于LF-CM模型,由于LFS-CM模型使用了购买周期内所有商品,因此能够更加充分地利用用户的比较和选择信息,提升模型的准确度.
3.1基于潜在因子的选择模型(LF-CM)
LF-CM模型是建立在当前购买商品和最佳替代商品之间的选择模型.它利用用户行为序列设计效用函数来估计购买周期内所购买商品的机会成本,从而锁定候选商品中的最佳替代品.
3.1.1商品效用函数
在实际的在线购买过程中,用户的选择取决于他对购买周期内商品的价值评估,即商品效用ws,u,i.本文借鉴潜在因子的思想,将商品对于用户的效用ws,u,i表示为代表用户的潜在因子向量pu与代表商品的潜在因子向量qi的内积,即:
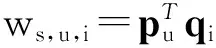
(1)
用户的偏好与商品特征越契合,即商品越符合用户的选择习惯,则其内积w越大;相反,商品越不符合用户的选择偏好,其效用值w就越小.Luce提出的选择公理(Luce’schoiceaxiom)说明了在商品集合中进行选择的方式:选择某一件商品的概率依赖于其在整个商品集合中的相对效用,相对效用越大,选取这件商品的概率就越大[8].
假定用户都是理性的,即他们会考虑到在进行决策时的机会成本和收益,最终选择效用不小于机会成本ws,u,io c的商品购买,即在任意购买周期s中,用户所购买商品ib的效用应当不小于最佳替代产品的效用(机会成本):
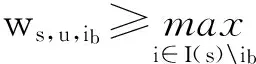
3.1.2确定最佳替代品
用户最终购买的产品ib是可观察到的,而最佳替代产品则是未知的(本周期内的所有候选商品都有可能),为了估计最佳替代产品必须首先得到商品效用(式(1)).然而,如果直接使用式(1)进行计算,则需要判断每个周期内所有候选商品的效用值.事实上,商品效用(用户的选择偏好)可以简单通过用户在每个购买周期内的行为序列来预估(不需要进行式(1)的因子相乘).在本文中,提出序列效用函数f(s,i)的概念,可以使用f(s,i)来对商品的效用进行预估.然后,LF-CM模型以该效用函数计算得到商品效用为依据,确定预估的机会成本以及相应的最佳替代品io c(除去购买商品ib外数值最大的序列效用函数对应的商品).使用这种预估商品效用的方法,在每个购买周期中只需要在购买商品和最佳替代商品之间利用式(1)建立选择模型.
本文设计的序列效用函数考虑2个影响商品选择的因素:
1) 商品在购买周期中出现的频率(frequency).直观上,一件商品在购买周期中出现的频率越高,说明用户对其越感兴趣,就有越大的可能性去选择购买这件商品.例如,购买周期的商品点击序列为{a,a,b,b,a,a,a,a,a},那么用户购买商品a的可能性应该高于购买商品b的可能性.
2) 点击与购买的时间间隔(recency).在一个购买周期中,用户最近点击的商品更有可能被选择.假定一个购买周期的点击序列为{a,a,a,b,c,b,a,b,b,b,b},那么商品b的购买概率应该高于商品a.因为在经过对比a,b,c之后,用户将重点放在了商品b上,所以用户对商品b的满意度可能更高.
综合frequency和recency因素,给出以下f(s,i)的具体定义形式.将购买周期s中用户的点击序列sq按照时间排序,其长度为N,sq从起始至结束各个位置分别编号为1,2,…,N,假定商品i出现的位置组成集合P(s,i),则在该购买周期中,商品i的序列效用函数可表示为
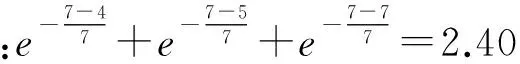
通过如上方式,可以计算得到购买周期内所有商品的序列效用f(s,i),从而预估出最佳替代商品io c.值得一提的是,对于f(s,i)的选择也可以是其他的形式,但都需要能够表现出序列的特征.
3.1.3基于潜在因子的选择模型(LF-CM)
在使用f(s,i)确定了每个购买周期中当前购买商品的最佳替代商品之后,便可以在当前购买商品与最佳替代商品二者之间建立比较选择模型.如下所示,其优化目标是在所有的购买周期中购买商品和最佳替代品的效用差的和最小:

(2)
其中,θ为w包含的参数.
将式(1)带入到式(2)中可得LF-CM最终所要优化求解的目标:
(3)
本文采用梯度下降法对式(3)进行求解.具体地,首先分别在固定qi和pu的情况下对式(3)进行求导:
(4)
(5)
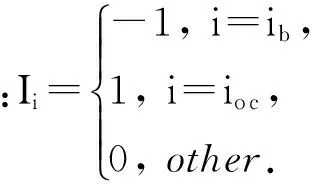
对pu和qi交替地进行更新优化:
(6)
(7)
其中,η为步长.
模型训练收敛后即得到用户和商品在隐特征空间的特征表示(pu,qi).需要注意的是,LF-CM模型虽然在每个购买周期中没有考虑非最佳替代品,但是一个购买周期中的非最佳替代品可能是另一个购买周期中的购买商品或者最佳替代品,因此,使用LF-CM仍可以得到所有商品的潜在信息.
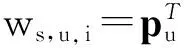
3.2基于潜在因子和行为序列的选择模型(LFS-CM)
LF-CM模型使用行为序列效用函数估计用户在购买周期中的最佳替代商品,并仅在当前购买商品和最佳替代品之间建立的选择模型.它可能存在3个方面的缺点:
1) 损失用户的部分比较选择信息.在线消费的过程中,用户不仅仅在最佳替代品和当前购买商品之间进行比较选择,而是所有购买周期中的商品都需要与当前购买商品进行比较;
2) 采用行为序列效用函数估计机会成本,确定最佳替代品有一定的风险,即行为序列效用函数f(s,i)并不一定能找到真正的最佳替代品;
3) 无法解决冷启动[28-29]问题.如果一个购买周期中的用户和出现的商品在历史记录中没有足够的训练数据,那么无法得到准确稳定的用户和商品的特征表示.
为了克服LF-CM模型的上述缺点,本节提出基于潜在因子和行为序列效用的选择模型(LFS-CM).LFS-CM模型采用效用函数:

(8)
式(8)在式(1)的基础上添加了行为序列效用函数f(s,i)项,并采用参数α调节潜在因子效用和行为序列效用的权重.
LFS-CM模型是在用户购买周期内所有候选商品和当前购买商品之间建立的选择模型:
(9)
类似地,LFS-CM模型也采用梯度下降法求解,pu和qi交替地进行优化:
(10)
(11)
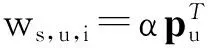
由于LFS-CM模型的效用函数包含潜在因子效用和行为序列效用2项,所以LFS-CM模型在一定程度上可以解决用户和商品的冷启动问题.因而,相比于LF-CM模型,LFS-CM模型能够更加充分、全面地利用用户的选择信息,进而提高预测精度.
4 实 验

Fig. 1 User and item count distribution.图1 用户与商品记录数分布
本文实验全部在Tmall提供的开放数据处理服务(ODPS)平台上完成.ODPS平台由阿里云自主研发,提供了针对TBPB级数据分布式处理能力,应用于数据分析、挖掘、商业智能等领域.该平台提供了SQL查询接口、MapReduce编程接口等服务.本文在该平台下利用上述工具以分布式的方式设计和实现了实验所用的算法,能够对大体量的数据进行处理,充分挖掘其中所包含的有价值信息,具有很好的扩展性.
4.1数据分析与预处理
实验数据采用了Tmall网站2013年4月至9月全部的用户行为记录,数据格式如表1所示.该数据集一共包含1 333 729 303条记录,涉及9 774 184位用户、8 133 507件商品.其中,绝大多数行为记录为点击行为,购买行为仅占不到1%.
图1展示了用户与商品涉及记录数的统计分布.其中横轴为记录数,纵轴为其数目,绝大部分的操作都在1 000次以内,其中每个用户的平均操作次数约为136,每个商品的平均操作次数约为164.从购买行为所占比例和商品、用户的平均操作次数的分布可以看出,该数据十分稀疏,且呈现显著的长尾特征,因此需要充分地利用用户行为序列的信息以对购买进行预测.
4.1.1数据预处理
首先对数据进行预处理:1)去除低频商品.为在一定程度上缓解冷启动问题,在实验中只选择保留出现次数在500以上的商品,约占全部商品的10%;2)划分购买周期.按照第3节中提到的方法进行划分,并选择2次操作的间隔阈值为12h.即若2次操作的间隔时间大于12h,则它们应当位于不同的购买周期中.同时,由于长度较短的购买周期购买行为存在较强的随机性,为了使模型的训练有效和准确,本文仅考虑长度(行为记录数)大于5的购买周期.表3展示了划分购买周期后的一些统计结果.

Table 3 Data after Pre-Processing表3 预处理后的数据
通过表3我们发现,在每个购买周期中,用户通常会比较超过4个商品并在其中进行选择购买,而每个商品的平均点击次数接近3次.由此可见,购买周期的序列中包含着丰富的比较和选择信息.
对于frequency,在每个购买周期中按照不同商品出现频次从大到小进行排序,然后得到购买的商品所占排位的百分比.
对于recency,在每个购买周期中按照不同商品出现的时间从后向前进行排序,然后得到购买的商品所占排位的百分比.
图2展示了所有购买周期中frequency和recency的分布.可以看出,无论是对于frequency还是recency,用户所购买的商品很大一部分都在前30%中,即用户倾向于购买在购买周期中出现频率更高和操作时间更近的商品.这为本文所采用的行为序列效用函数f(s,i)考虑recency和frequency因素提供了统计依据.
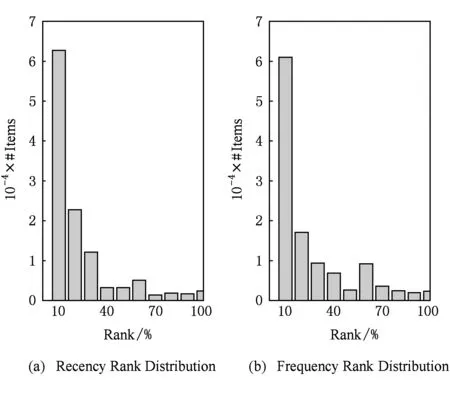
Fig. 2 Recencyfrequency rank of purchased items distribution.图2 购买商品所占排位的分布
4.2实验设置
本文在ODPS平台上按照分布式的方式[30-31]实现了所提出的LF-CM和LFS-CM两种选择模型以及其他几种对比方法.实验中,按照4∶1的比例将用户的购买周期集合划分为训练集和测试集,在训练集的购买周期中对模型参数进行学习和调整,然后在测试集中按照学习得到的参数对新购买周期的商品进行购买预测.
在LF-CM模型和LFS-CM模型中,本文通过比较设置正则化项参数λu=λi=0.01,用户和商品的特征维度设置为10,在计算过程中动态的调整步长来进行迭代训练,待收敛后得到用户和商品的特征向量(pu,qi).
4.2.1对比方法
为了验证所提出模型的效果,本文选取了7种方法作为对比实验.
1) 随机选择(Rand).对测试集中每个购买周期内出现的商品,随机地选取一个作为用户购买预测的结果.
2) 最流行商品(Pop).在训练集中统计每个商品被用户操作的次数,作为商品流行度的指标.然后对测试集的购买周期,推荐该购买周期中最流行的商品.
3) 基于用户的K近邻(KNN)[32].使用传统推荐系统中协同过滤的方法.具体地,在训练集中,按照用户购买的商品计算出用户之间的相似度.然后在测试集中用相似度计算每个商品可能会被购买的权重,最后按照权重的高低衡量商品购买概率.
4) 使用用户购买周期中所用商品进行排序学习(PQ)[33].在训练集中,使用购买周期中的所有商品进行学习,这实际上就是LFS-CM模型在α=1时的特殊情形.
5) 使用用户在购买周期中表现出的序列效用(FIS).根据用户购买周期的序列计算得到的f(s,i)作为商品效用,这实际上是LFS-CM模型在α=0的特殊情形.
6) 逻辑回归(LR)[8,34].为了与其他方法进行有效地对比,在LR模型中也使用了frequency和recency两类特征.第1类frequency特征包括商品在购买周期中出现的次数以及频率(相对次数);第2类recency特征包括商品在购买周期中最后出现的位次和相对位次(位次除以购买周期中的长度).将购买预测转化为二分类问题,购买周期中LR预测概率最大的商品即为购买商品.
7) 梯度提升决策树(GBDT)[35].与LR相同,使用frequency和recency特征.购买周期中预测概率最大的商品即为购买商品.
4.2.2衡量指标
实验中,按照每种方法计算出不同商品的效用值,分别选取效用值最高的1个(Top1)、2个(Top2)、3个(Top3)商品作为预测购买的结果.
本文使用召回率(Recall)和精度(Precision)作为衡量预测方法的预测准确性的指标,其计算公式分别为
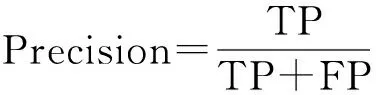
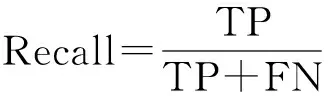
其中,TP为预测购买的商品数量;FP为预测购买而实际未被购买的商品数量.
4.3实验结果
本节从多个方面对实验结果进行展示和分析.首先,通过购买预测结果,再次验证LF-CM模型中使用行为序列效用函数 估计最佳替代品的有效性.然后,测试LF-CM模型的效用函数中权重参数α的影响,并得到α的最优取值.最后展示所提出的模型以及对比方法在预测准确性上的对比结果.
4.3.1f(s,i)估计最佳替代品的有效性
因为最佳替代商品不是可观测的,所以为了说明使用f(s,i)来估计最佳替代品的有效性,本文的验证方法如下:1)分别使用f(s,i)以及随机选取的方法选择购买周期中的其他商品作为最佳替代商品;2)在最佳替代商品和用户购买商品之间建立选择模型(使用的f(s,i)方法即为LF-CM);3)在测试集上通过购买预测的效果验证所选择的最佳替代品的准确性.表4给出了2种方法效果对比:
Table4EffectComparisonoftwoMethodsofSelectingthe
OptimumSubstitutes
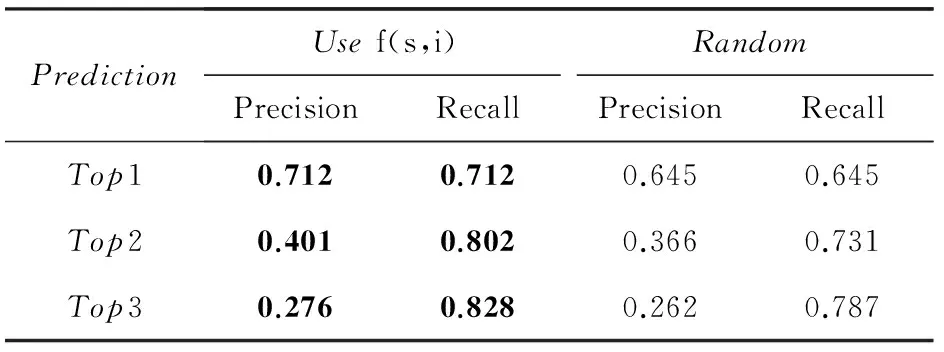
表4 2种选择最佳替代品方法的效果对比
从表4中可以看出相比于随机选择,使用f(s,i)来估计最佳替代品的购买预测结果在精度和召回率2种指标上都有着显著的提升,说明了使用行为序列效用函数f(s,i)估计最佳替代品的有效性.
4.3.2LFS-CM参数α的影响
为了测试LFS-CM模型对参数α的敏感性并得到最佳的α值,分别设置α= 0,0.2,0.4,0.6,0.8,1.0进行了Topk预测的实验.
如图3所示,在不同α的条件下,模型预测效果会有所差别,当α= 0.6时精度和召回率都有最好的效果,因此在后文与其他方法的对比实验中,LFS-CM模型的α参数设置为0.6.
4.3.3预测准确性结果对比
图4显示了LF-CM模型、LFS-CM模型以及对比方法(Rand,Pop,KNN,PQ,FIS,LR,GBDT)在精度和召回率2种指标上的对比结果.
可以看出,Rand和Pop两种方法的表现较差,因为它们并不能分辨出每个用户的个性化偏好;由于数据的稀疏性,以及同一购买周期内的产品的高度相似性,使得传统的KNN方法也不能很好地进行预测,在Top2和Top3上的预测效果甚至不如Pop方法;通过使用用户在购买周期中的偏好信息(frequency和recency),LR和GBDT在效果上有了显著的提升,由于GBDT相对LR模型本身的优势,GBDT取得了相对更高的预测准确度;同样考虑了用户的偏好和比较选择信息以后,LF-CM模型的预测精度相比于Rand,Pop,KNN三种方法有了大幅提升;PQ方法相对于LF-CM模型,由于使用了购买周期内全部商品的信息建立选择模型,使得预测效果有了更进一步的提升,说明了选择模型本身的合理性;而FIS使用了用户在购买周期中的recency和frequency时序行为特征得到效用函数,也取得了不错的表现;最后,LFS-CM模型充分利用了用户的选择和比较信息以及序列特征,在所有的方法中表现最好,即它可以最准确地预测用户购买偏好和行为.
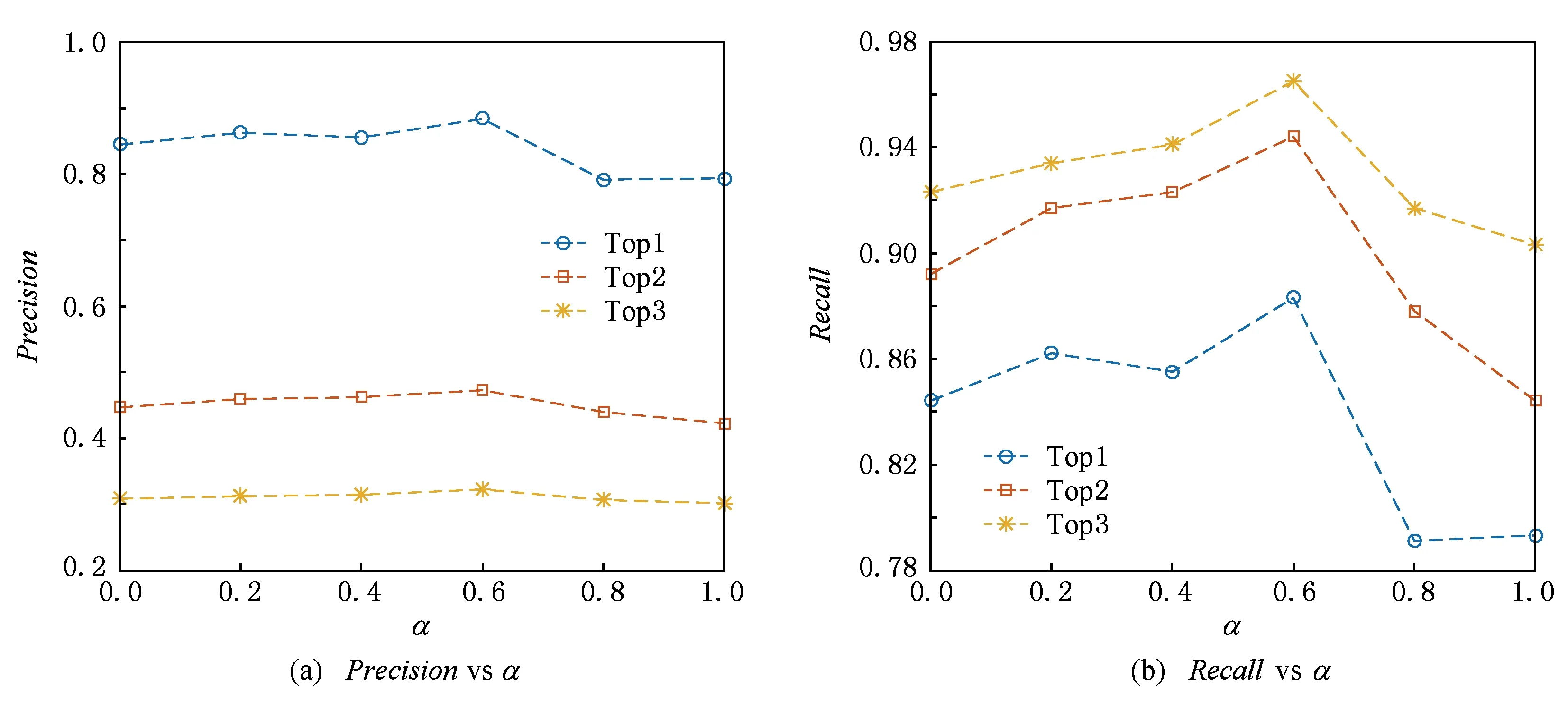
Fig. 3 Precision & Recall vs α.图3 精度和召回率随α变化情况
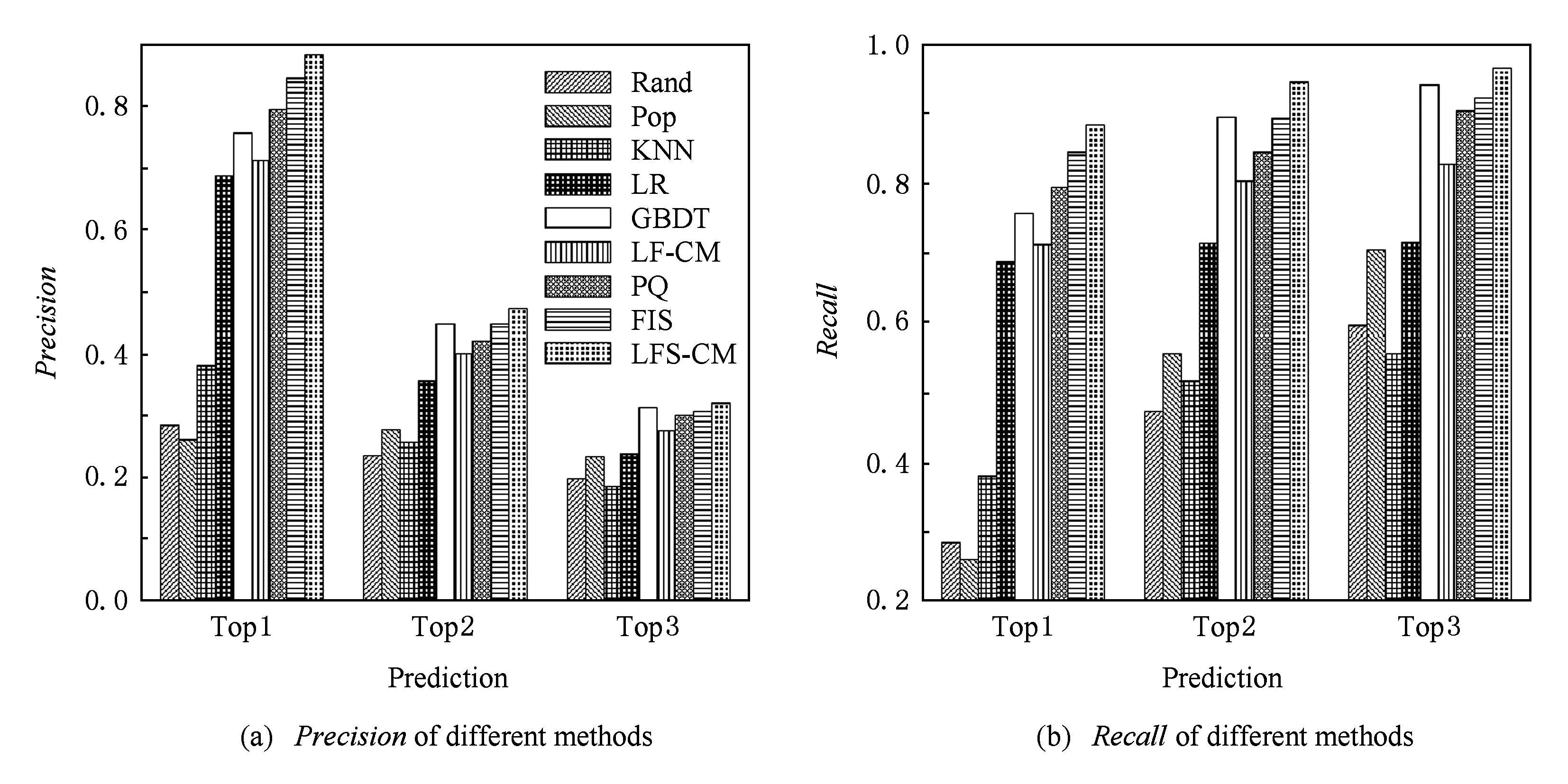
Fig. 4 Precision & Recall of different methods.图4 不同方法的精度和召回率对比
4.3.4时间复杂度分析
本节简单介绍所提算法的分布式实现过程,并分析相应的运行时间开销情况.在本文的算法设计中,将LF-CM和LFS-CM算法的实现都分为2个Map-Reduce过程:在第1个Reduce操作中对用户的潜在因子pu进行更新迭代;在第2个Reduce中对商品的潜在因子qi进行更新迭代.将这2次操作看做整个算法的一次完整迭代.
记n为所有购买周期的数目,k为周期平均长度.在一次迭代过程中LF-CM只考虑购买周期中的2个商品(购买的商品和最佳替代的商品),由式(6)(7)可以看出其需要计算n次;而LFS-CM模型(包括PQ算法,但不包括α=0的情况)考虑了购买周期中的所有商品,需要计算kn次,然而在实验中由于其他因素的影响(平台内部的任务调度、机器集群的网络状况、磁盘IO占用的时间等),这些方法的运行时间都大致相同.除了以上一些理论上分析的结果,我们也观察到使用3台机器、3个分布式结点的情况下:在数据集上训练时,LF-CM以及LFS-CM一次完整迭代需要的2次Map-Reduce作业用时都是在210s左右,10~15次迭代后基本趋于收敛;KNN,Rand,Pop等算法(不包括预处理)都是单次Map-Reduce作业,运行时间约在100s.而在测试集上,对任一个购买周期所有的方法基本上都可实时地给出预测结果.
5 总 结
本文主要研究电商网站中用户的在线购买行为预测问题.通过引入购物周期和机会成本等概念,试图将用户在相似商品之间的比较和选择行为进行建模,从而解决用户实时偏好和真实购买意图的理解问题.具体来说,本文首先将用户的行为序列分成了不同的购买周期,然后通过考虑商品对用户的效用情况,提出了针对所购买商品和最佳替代商品的、基于潜在因子的选择模型LF-CM,以及针对所有商品的、基于潜在因子和行为序列效用的选择模型LFS-CM两种算法,分别实现对用户购买行为的预测.本文使用了Tmall用户的购物行为日志对所提出的模型进行了验证,实验结果证实了所提出的方法在用户在线购买预测上的有效性.
在未来工作中,将重点关注更综合的描述模型,考虑更多的潜在因素.例如,目前本文中没有考虑到用户的不同类型操作行为(点击、购买和收藏)的不同作用,将在未来工作中加以区分;又如,考虑将商品的先验知识,如类别、价格等因素纳入建模,从而进一步提升模型预测的精度.
[1]RassinE,MurisP.Indecisivenessandtheinterpretationofambiguoussituations[J].PersonalityandIndividualDifferences, 2005, 39(7): 1285-1291
[2]LiuQ.etal.Miningindecisivenessincustomerbehaviors[C] //Procofthe15thIntConfonDataMining.Piscataway,NJ:IEEE, 2015: 281-290
[3]SarwarB,KarypisG,KonstanJ,etal.Item-basedcollaborativefilteringrecommendationalgorithms[C] //Procofthe10thIntConfonWorldWideWeb.NewYork:ACM, 2001: 285-295
[4]LindenG,SmithB,YorkJ.Amazon.comrecommendations:Item-to-itemcollaborativefiltering[J].IEEEInternetComputing, 2003, 7(1): 76-80
[5]LuceRD.Individualchoicebehavior:Atheoreticalanalysis[M].NorthChelmsford,Massachusetts:CourierCorporation, 2005
[6]TrainK.Qualitativechoiceanalysis:Theory,econometrics,andanapplicationtoautomobiledemand[M].Cambridge,Massachusetts:MITPress, 1986
[7]TalluriK,VanRyzinG.Revenuemanagementunderageneraldiscretechoicemodelofconsumerbehavior[J].ManagementScience, 2004, 50(1): 15-33
[8]HosmerJrDW,LemeshowS.Appliedlogisticregression[M].Hoboken,NJ:JohnWiley&Sons, 2004
[9]CappellariL,JenkinsSP.Multivariateprobitregressionusingsimulatedmaximumlikelihood[J].TheStataJournal, 2003, 3(3): 278-294
[10]HarrellFE.Regressionmodelingstrategies:Withapplicationstolinearmodels,logisticregression,andsurvivalanalysis[M].NewYork:SpringerScience&BusinessMedia, 2013
[11]TrainK.Avalidationtestofadisaggregatemodechoicemodel[J].TransportationResearch, 1978, 12(3): 167-174
[12]RammingMS.Networkknowledgeandroutechoice[D].Cambridge,MA:MassachusettsInstituteofTechnology, 2001
[13]FullerWC,ManskiCF,WiseDA.Newevidenceontheeconomicdeterminantsofpostsecondaryschoolingchoices[J].JournalofHumanResources, 1982, 17(4): 477-498
[14]LiXin,XuG,ChenE,etal.Learningrecencybasedcomparativechoicetowardspoint-of-interestrecommendation[J].ExpertSystemswithApplications, 2015, 42(9): 4274-4283
[15]KumarR,MahdianM,PangB,etal.Drivenbyfood:Modelinggeographicchoice[C] //Procofthe8thACMIntConfonWebSearchandDataMining.NewYork:ACM, 2015: 213-222
[16]ChenW,LiZ,ZhangM.Linearandnon-linearmodelsforpurchaseprediction[C] //Procofthe2015IntACMRecommenderSystemsChallenge.NewYork:ACM, 2015:No.9
[17]LiQ,GuM,ZhouK,etal.Multi-classesfeatureengineeringwithslidingwindowforpurchasepredictioninmobilecommerce[C] //Procofthe15thIntConfOnDataMiningWorkshop.Piscataway,NJ:IEEE, 2015: 1048-1054
[18]LiD,ZhaoG,WangZ,etal.Amethodofpurchasepredictionbasedonuserbehaviorlog[C] //Procofthe15thIntConfonDataMiningWorkshop.Piscataway,NJ:IEEE, 2015: 1031-1039
[19]RodriguezJJ,KunchevaLI,AlonsoCJ.Rotationforest:Anewclassifierensemblemethod[J].IEEETransonPatternAnalysisandMachineIntelligence, 2006, 28(10): 1619-1630
[20]ZhangY,PennacchiottiM.Predictingpurchasebehaviorsfromsocialmedia[C] //Procofthe22ndIntConfonWorldWideWeb.NewYork:ACM, 2013: 1521-1532
[21]TsuboiY,JatowtA,TanakaK.Productpurchasepredictionbasedontimeseriesdataanalysisinsocialmedia[C] //Procofthe2015IEEE//WIC//ACMIntConfonWebIntelligence.Piscataway,NJ:IEEE, 2015: 219-224
[22]WangY,LiJ,LiuQ,etal.Predictionofpurchasebehaviorsacrossheterogeneoussocialnetworks[J].TheJournalofSupercomputing, 2015, 71(9): 3320-3336
[23]SongQ,ChengJ,YuanT,etal.Personalizedrecommendationmeetsyournextfavorite[C] //Procofthe24thACMIntonConfonInformationandKnowledgeManagement.NewYork:ACM, 2015: 1775-1778

[25]SalakhutdinovR,MnihA.BayesianprobabilisticmatrixfactorizationusingMarkovchainMonteCarlo[C] //Procofthe25thIntConfonMachineLearning.NewYork:ACM, 2008: 880-887
[26]YuK,SchwaighoferA,TrespV,etal.Probabilisticmemory-basedcollaborativefiltering[J].IEEETransonKnowledgeandDataEngineering, 2004, 16(1): 56-69
[27]PennockDM,HorvitzE,LawrenceS,etal.Collaborativefilteringbypersonalitydiagnosis:Ahybridmemory-andmodel-basedapproach[C] //Procofthe16thConfonUncertaintyinArtificialIntelligence.SanFrancisco,CA:MorganKaufmann, 2000: 473-480
[28]LamXN,VuT,etal.Addressingcold-startprobleminrecommendationsystems[C] //Procofthe2ndIntConfonUbiquitousInformationManagementandCommunication.NewYork:ACM, 2008: 208-211
[29]YinP,LuoP,LeeWC,etal.Silenceisalsoevidence:Interpretingdwelltimeforrecommendationfrompsychologicalperspective[C] //Procofthe19thACMSIGKDDIntConfonKnowledgeDiscoveryandDataMining.NewYork:ACM, 2013: 989-997
[30]DingXiangwu,GuoTao,WangMei,etal.Aclusteringalgorithmforlarge-scalecategoricaldataanditsparallelimplementation[J].JournalofComputerResearchandDevelopment, 2016, 53(5): 1063-1071 (inChinese)
(丁祥武, 郭涛, 王梅, 等. 一种大规模分类数据聚类算法及其并行实现[J]. 计算机研究与发展, 2016, 53(5): 1063-1071)
[31]GemullaR,NijkampE,HaasPJ,etal.Large-scalematrixfactorizationwithdistributedstochasticgradientdescent[C] //Procofthe17thACMSIGKDDIntConfonKnowledgeDiscoveryandDataMining.NewYork:ACM, 2011: 69-77
[32]WangJ,DeVriesAP,ReindersMJT.Unifyinguser-basedanditem-basedcollaborativefilteringapproachesbysimilarityfusion[C] //Procofthe29thAnnualIntACMSIGIRConfonResearchandDevelopmentinInformationRetrieval.NewYork:ACM, 2006: 501-508
[33]RendleS,FreudenthalerC,GantnerZ,etal.BPR:Bayesianpersonalizedrankingfromimplicitfeedback[C] //Procofthe24thConfonUncertaintyinArtificialIntelligence.Arlington,Virginia:AUAI, 2009: 452-461
[34]JiangZhuoxuan,ZhangYan,LiXiaoming.LearningbehavioranalysisandpredictionbasedonMOOCdata[J].JournalofComputerResearchandDevelopment, 2015, 52(3): 614-628 (inChinese)
(蒋卓轩, 张岩, 李晓明. 基于数据的学习行为分析与预测[J]. 计算机研究与发展, 2015, 52(3): 614-628)
[35]FriedmanJH.Stochasticgradientboosting[J].ComputationalStatistics&DataAnalysis, 2002, 38(4): 367-378

ZengXianyu,bornin1991.MSccandidate.Hismainresearchinterestsincludedataminingandrecommendersystem.

LiuQi,bornin1986.PhD,associateprofessor.Hismainresearchinterestsincludedataminingandknowledgediscoveryindatabase,machinelearningmethodandapplication.

ZhaoHongke,bornin1988.PhDcandidate.Hismainresearchinterestsincludedatamining,internet-basedfinancesuchascrowdfundingandP2Plending.

XuTong,bornin1988.PhDcandidate,assistantresearcher.Hismainresearchinterestsincludesocialnetwork&mediaanalysis,mobilecomputing,recommendersystemandotherdataminingrelatedtechniques.

WangYijun,bornin1991.MSccandidate.Hermainresearchinterestsincludedataminingandrecommendersystem.

ChenEnhong,bornin1968.PhD,professorandPhDsupervisor.Hismainresearchinterestsincludedataminingandmachinelearning,socialnetworkanalysis,andrecommendersystems.
OnlineConsumptionsPredictionviaModelingUserBehaviorsandChoices
ZengXianyu,LiuQi,ZhaoHongke,XuTong,WangYijun,andChenEnhong
(School of Computer Science, University of Science and Technology of China, Hefei 230027)
Theriseofelectronice-commercesitesandtheformationoftheuser’sonlineshoppinghabits,havebroughtahugeamountofonlineconsumerbehavioraldata.Miningusers’preferencesfromthesebehaviorallogs(e.g.clickingdata)andthenpredictingtheirfinalconsumptionchoicesareofgreatimportanceforimprovingtheconversionrateofe-commerce.Alongthisline,thispaperproposesawayofcombiningusers’behavioraldataandchoicemodeltopredictwhichitemeachuserwillfinallyconsume.Specifically,wefirstestimatetheoptimumsubstituteineachconsumptionsessionbyautilityfunctionofusers’behavioralsequences,andthenwebuildalatentfactorbasedchoicemodel(LF-CM)fortheconsumeditemsandthesubstitutes.Inthisway,thepreferenceofuserscanbecomputedandthefutureconsumptionscanbepredicted.Onestepfurther,tomakefulluseofusers’informationofchoosingandimprovetheprecisionofconsumptionprediction,wealsoproposealearning-to-rankmodel(latentfactorandsequencebasedchoicemodel,LFS-CM),whichconsidersalltheitemsinonesession.Byintegratinglatentfactorsandutilityfunctionofusers’behavioralsequences,LFS-CMcanimprovethepredictionprecision.Finally,weusethereal-worlddatasetofTmallandevaluatetheperformanceofourmethodsonadistributedenvironment.TheexperimentalresultsshowthatbothLF-CMandLFS-CMperformwellinpredictingonlineconsumptionbehaviors.
onlineconsumptionprediction;choicemodel;behavioralsequence;sequenceutility;distributedplatform
2016-03-04;
2016-06-05
国家杰出青年科学基金项目(61325010);国家自然科学基金项目(61403358);科技惠民计划项目(2013GS340302);青年创新促进会会员专项基金项目(2014299);多媒体计算与通信教育部-微软重点实验室基金项目
刘淇(qiliuql@ustc.edu.cn)
TP391
ThisworkwassupportedbytheNationalScienceFundforDistinguishedYoungScholars(61325010),theNationalNaturalScienceFoundationofChina(61403358),thePlanofScienceandTechnologytoBenefitthePeople(2013GS340302),theSpecialFundfortheMemberofYouthInnovationPromotionAssociationofCAS(2014299),andthetheFundforMinistryofEducation(MOE)-MicrosoftKeyLaboratoryofUSTC.
