一种新的语音和噪声活动检测算法及其在手机双麦克风消噪系统中的应用
2016-08-30章雒霏南京师范大学物理与科学技术学院南京210000
章雒霏 张 铭 李 晨(南京师范大学物理与科学技术学院南京210000)
一种新的语音和噪声活动检测算法及其在手机双麦克风消噪系统中的应用
章雒霏*张铭李晨
(南京师范大学物理与科学技术学院南京210000)
针对现有双通道语音活动检测(Voice Activity Detection,VAD)算法依赖于固定阈值难以在多种噪声环境下准确地检测语音和噪声,应用于手机消噪系统会造成语音失真或噪声消除不好等问题,该文提出一种基于神经网络的VAD算法,该算法以分频带能量差和归一化互通道相关为特征,采用神经网络对语音和噪声进行分类。在此基础上,将神经网络VAD与基于互通道信号功率比值的VAD相结合,提出一种新的适用于手机消噪系统的语音和噪声活动检测算法分别对语音和噪声进行检测,并以此进行噪声抑制处理,减少了消噪系统因VAD误判而造成的性能下降。实验结果表明,该处理方法在抑制背景噪声和减少语音失真等方面优于现有的消噪算法,对于方向性语音干扰也有很好的抑制效果。
语音活动检测;语音增强;神经网络
1 引言
说话人处于噪声环境中时,远端接听者往往会听到难以忍受的噪声[1],为了解决这个问题,现有手机集成了语音增强模块来提高语音质量。传统的单通道语音增强算法[26]-无法很好地处理非稳态噪声,而多通道算法[1,713]-在利用语音与噪声性质差异的同时也结合了两者的空间差异性,使得算法在非稳态噪声环境下性能得到很大改善。考虑到尺寸、功耗和计算复杂度等问题,手机主要使用的是双麦克风语音增强系统。
语音活动检测(Voice Activity Detection,VAD)可以从带噪语音信号中确定出语音的起始和结束位置,准确的VAD可以帮助消噪算法对噪声进行有效抑制同时尽可能地减少语音信号的失真。目前,各种单通道或者双通道的VAD算法已广泛地应用于手机消噪系统中。其中,基于双麦克风能量差(Power Level Differences,PLD)[1]及其改进的算法[1014]-具有较好的检测结果且复杂度低易于实现,因此得到了广泛的关注和研究。通话时,手机底部的主麦克风接收到语音信号能量远大于手机顶端的次麦克风接收能量,而噪声信号的能量基本相同。基于这样的特性,PLD算法通过对双麦克风信号的能量差设定阈值来区分语音和噪声,但其算法性能会受到麦克风增益,噪声种类和信噪比等因素的影响,在此基础上,文献[10]提出了基于双麦克风后验信噪比差异的VAD算法减少了麦克风增益的影响,文献[14]提出了基于PLD比率(PLD Ratio,PLDR)的算法提高了PLD算法的准确率。虽然上述算法在稳态及非稳态噪声环境中取得了一定效果,但难以同时保证语音和噪声检测的准确性,应用于手机消噪系统会造成语音失真,降低可懂度。
针对上述问题,本文提出了一种新的基于神经网络的VAD算法,该算法以分频带能量差和归一化互通道相关作为特征,采用神经网络对语音和噪声进行分类,不依赖于固定阈值,较现有的基于PLD的算法准确性更高。在此基础上,本文将神经网络VAD与基于互通道信号功率比值的VAD相结合,提出一种新的适用于手机消噪系统的语音和噪声活动检测算法,该算法分别对语音和噪声进行检测,减少了消噪算法因VAD的误判而造成的性能下降,与现有的双麦克风消噪算法相比,本算法能够更有效地抑制噪声,减少语音失真。
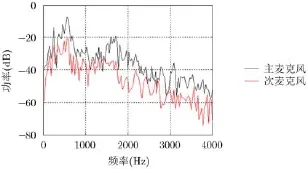
图1 双麦克风接收的带噪语音信号功率
本文第2节描述神经网络VAD的原理;第3节介绍结合神经网络VAD提出的语音和噪声检测算法及其在手机消噪系统中的应用;第4节给出实验结果和分析;第5节进行总结。
2 基于神经网络的语音活动检测算法
5 dB Babb le噪声环境下,双麦克风接收到的带噪语音信号功率如图1所示。
频域上双通道接收到的纯净语音信号的能量差几乎都在10 dB左右[1],而背景噪声存在时语音信号的某些频带受到噪声的污染能量差下降(如图1中1.0~1.5 kHz之间),但部分频带仍然保持着10 dB左右的能量差(如图1中1.5~2.5 kHz之间)。这些频带的能量差可以作为表征目标语音存在的特征,为了更好地利用这些频带的信息,本算法对频域进行划分,计算子带互通道能量差(sub-band power level difference)作为神经网络的特征,计算过程如式(1)。首先将时域信号转化到频域,得到两个通道在频域的信号:
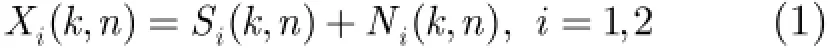
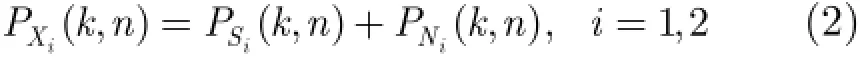
对每个子带(本算法按照MEL频带划分)计算互通道能量差的均值如式(3)所示。
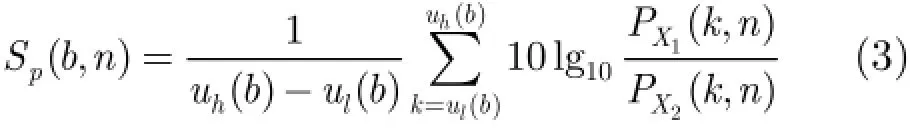
因为目标语音距主麦克风较次麦克风近,主麦克风早于次麦克接受到语音信号,而背景噪声到达麦克风的距离基本相等,时延较语音小,所以双通道时延也是区分语音和噪声的一个重要的特征,在本算法中,使用归一化的互通道相关函数来作为表征时延的特征,计算式为
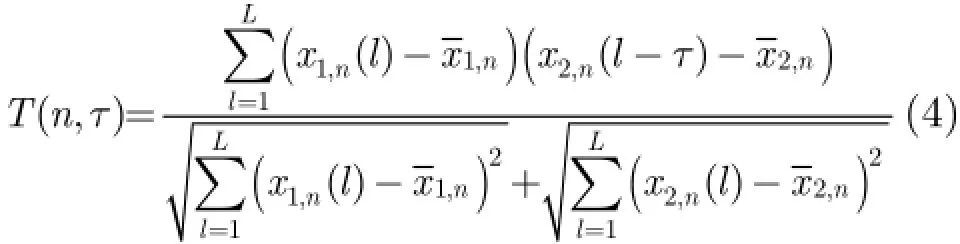
反向传播(Back Propagation,BP)神经网络是使用最为广泛的神经网络,在训练阶段,通过调整神经元之间连接的权值,BP神经网络可以完成输入和输出之间复杂的映射关系。本文使用的是3层的BP神经网络。其中输入层为提取的两个特征矢量,即分频带能量差和归一化互通道相关函数,输出层为对应的语音活动检测的标签(1:语音;0:噪声)。
3 手机双麦克风语音增强系统
双麦克风语音增强系统框图如图2所示,滤波器1将次麦克风信号作为参考,主麦克风信号作为输入,通过VAD检测信噪比较高的语音段控制滤波器调整参数将目标语音从次麦克风中滤除得到噪声信号。滤波器2将主麦克风信号作为参考,滤波器1输出噪声信号作为输入,通过噪声活动检测NAD(Noise Activity Detection)在噪声段控制滤波器调整参数将噪声信号从主麦克风的带噪语音信号中滤除得到增强语音信号。
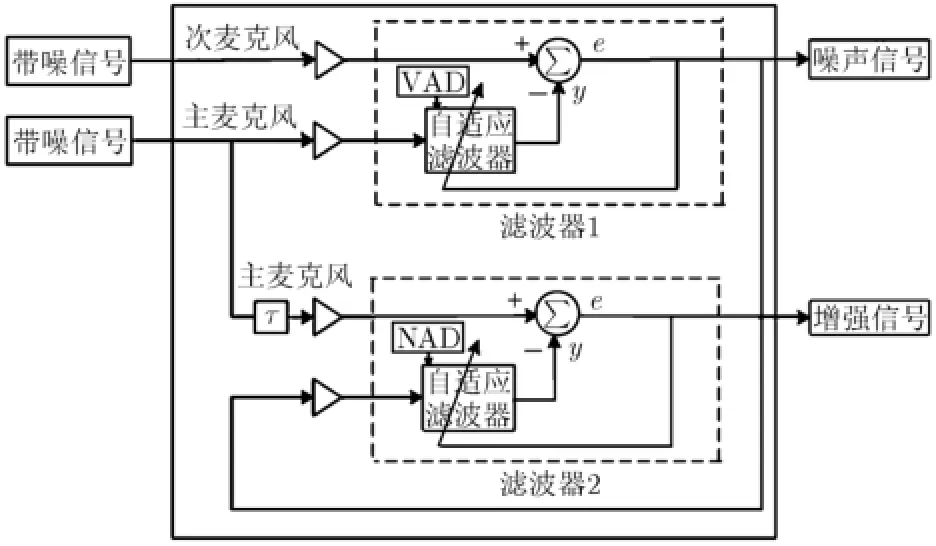
图2 手机双麦克风语音增强系统框图
实际上,滤波器1和滤波器2的参数分别模拟了语音和噪声信号在两个麦克风之间的传递函数,为了避免在信噪比较低的语音和噪声混合部分对滤波器参数进行调整造成滤波器参数与传递函数的失配,本文中,我们结合神经网络VAD提出一种新的语音和噪声活动检测算法,该算法通过VAD检测信噪比较高的语音段落控制滤波器1的参数调整,同时利用NAD检测噪声段落控制滤波器2的参数调整。
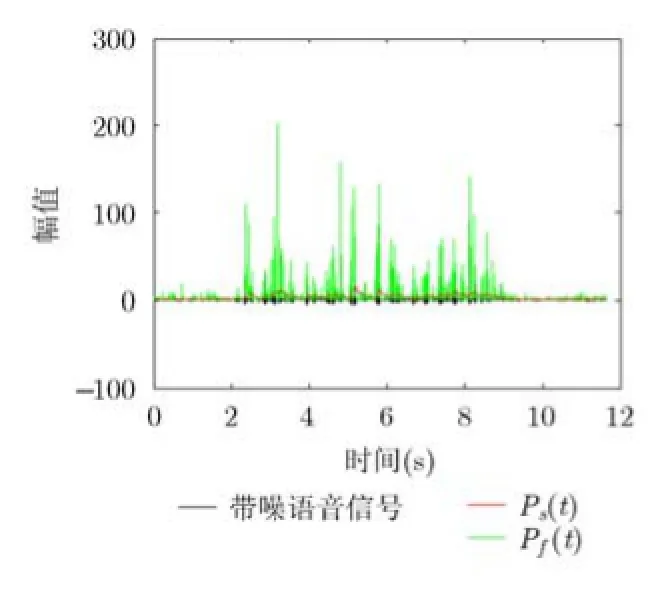
图3 不同平滑参数计算的互通道能量的比值
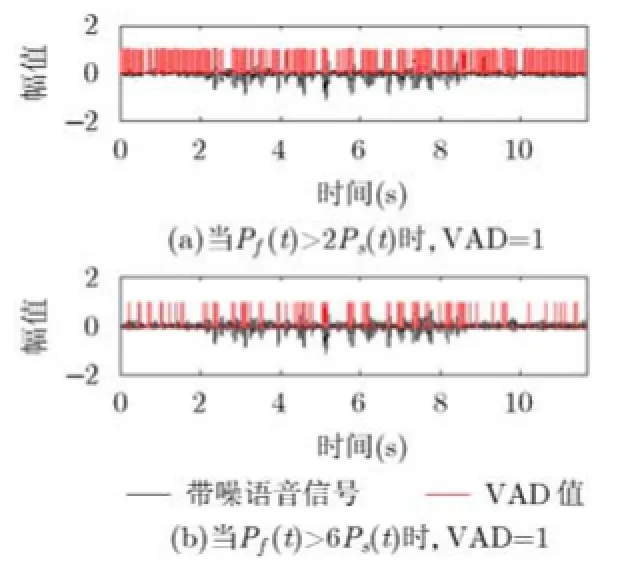
图4 5 dB Babble噪声下利用Pf(t)和Ps(t)判断语音信号
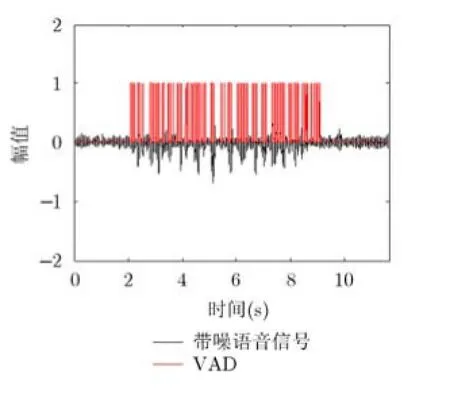
图5 VAD的结果
3.1语音活动检测(VAD)
现有的PLD算法通过设定固定阈值δ来区分语音和噪声。但是互通道功率比值的大小会因信噪比和噪声种类的改变而改变,固定的阈值无法得到准确结果。针对这一问题,本算法做了改进,采用不同的平滑参数α计算两个通道信号的功率。
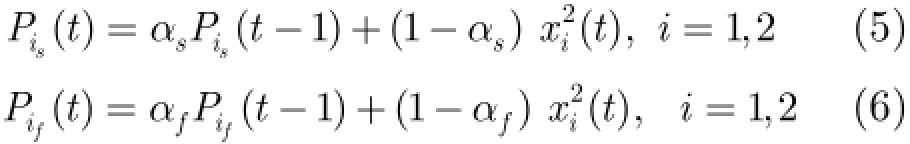
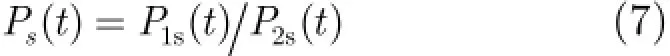
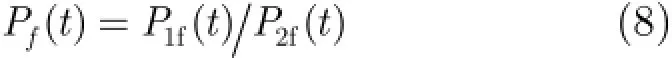
从图3中可以看出,语音存在的部分,短平滑计算的互通道功率比Pf(t)比长平滑计算的比值Ps(t)大得多,可以通过比较Pf(t)与Ps(t)的大小来确定语音信号存在且信噪比较高的时域采样点,但是通过调整判断阈值不能够完全地区分语音和噪声,如图4所示(VAD等于1表示语音信号),当设定Pf(t)>2Ps(t)的采样点为语音时,部分噪声被误判为语音,而提高阈值为Pf(t)>6Ps(t)时,虽然误判为语音的噪声减少了,但是语音检测的准确性也下降了。
基于神经网络的VAD可以准确地判断出语音存在的部分,将神经网络VAD结果和基于长和短时平滑计算的功率比值确定的语音存在且信噪比较高的部分相结合可以去除误判为语音的噪声采样点,5 dB babble噪声环境下的结果如图5所示。
3.2噪声活动检测NAD
将滤波器1输出的噪声信号与主麦克风中的带噪语音信号进行比较,因语音部分能量较大,当噪声信号与语音信号的能量相比时,比值会非常小,我们可以对噪声与带噪信号能量的比值设定阈值来确定噪声段,计算过程如式(9)和式(10):

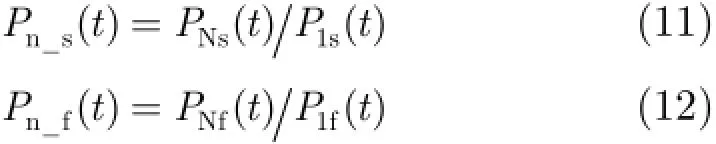
其中,ns()P t与nf()P t分别为长平滑和短平滑计算得到的噪声与主麦克风中带噪语音的功率比值,当语音存在的时候,噪声与语音的比值会接近于零,而噪声段的比值则较大且短平滑的值远远大于长平滑的比值,为了在噪声段增加长时与短时平滑功率比值的差距,我们对ns()P t再次进行平滑:
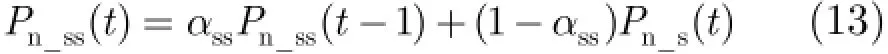
其中,nss()P t为对ns()P t进行再次平滑得到的功率比值,这里的平滑系数ssα根据神经网络VAD的结果进行调整,在语音段ssα为1保持nss()P t不变,在噪声段ssα为0.999迭代平滑计算nss()P t,经过再次平滑后的nss()P t在噪声段更为平缓,与nf()P t的差距更大,将nf()P t与nss()P t进行比较更有利于我们准确地判断出噪声采样点。
4 实验结果
实验使用手机长度为13 cm,在一个7.91× 7.31×4.85 m3的房间中进行测试,房间的混响为0.3 s,使用B&K HATS仿真头的人工嘴来播放目标语音信号,通过ACTS的8个喇叭噪声放音系统来模拟真实的噪声环境,人工头放置在圆点,8个喇叭以一个环形位于人工头的四周,距离人工头大约为2m。信号的采样率为8 kHz,帧长L=256,帧移M=128。实验选取100段语音,其中80段用于神经网络的训练,剩余20段用于验证神经网络的结果。选取6种常见的噪声环境,Babble,Car,Restaurant,O ffice,Street和方向性的语音干扰,信噪比分别为5 dB,10 dB和15 dB。神经网络采用MATLAB 2014a的神经网络工具箱。隐藏层为30个神经元,输入层到隐藏层采用tansig作为激活函数,隐藏层到输出层采用purline作为激活函数,最大迭代次数为2000次,学习步长为0.01,学习函数为traingdx。采用24个MEL频带计算子带互通道能量差,同时,选取时延从-10到+10每隔1个采样点计算归一化互通道相关。一共45个值作为神经网络的输入,输出层为对应的语音活动检测的标签(1:语音;0:噪声)。
首先对神经网络VAD算法的准确性进行验证,将该算法与基于PLD比率(PLDR)[14]的VAD算法进行比较。分别用3个性能指标来衡量语音活动检测的准确性,Psh为检测正确的语音信号帧/语音信号总帧数,Pnh为检测正确的噪声信号帧/非语音信号总帧数,Pgh为总的准确率。
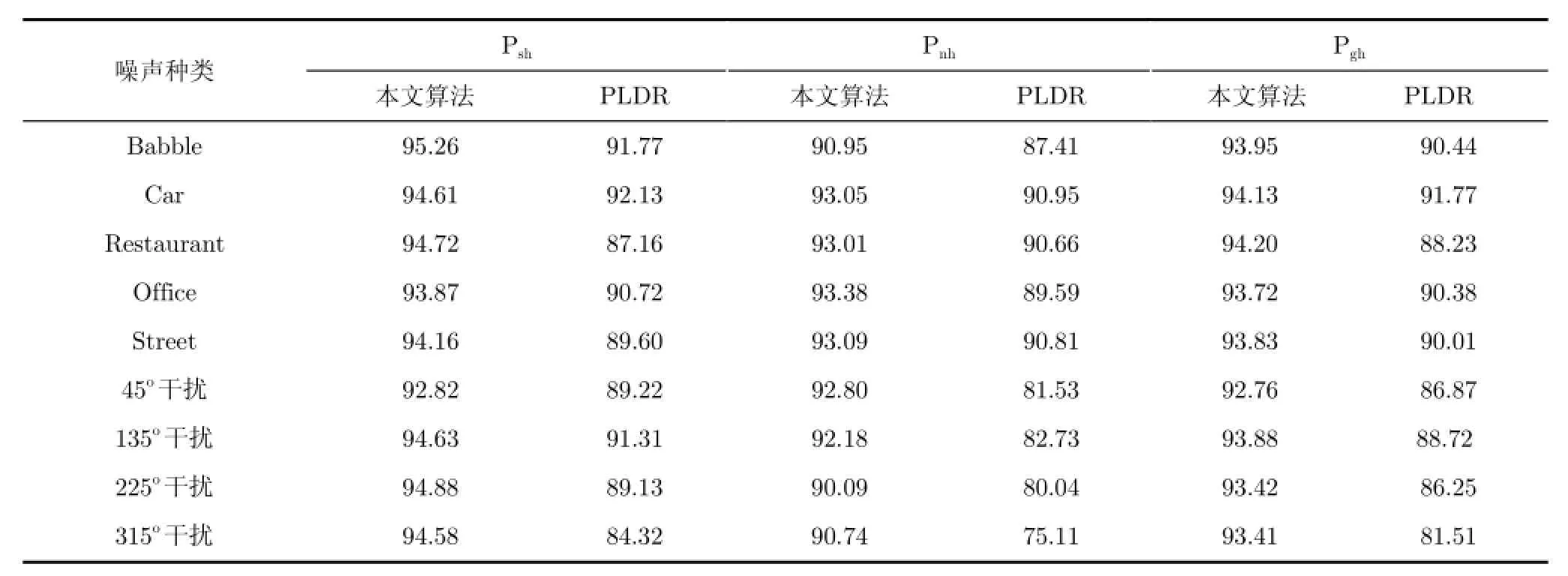
表1 10 dB信噪比噪声环境下,PLDR和本文算法的语音活动检测结果
从表1中可以看出,本文算法无论是在语音帧、噪声帧还是总的准确率方面都要优于PLDR算法。干扰人声也是手机通话中非常常见的一类噪声,但是,由于干扰人声是高度非平稳信号且具有方向性,现有的VAD算法无法很好地处理这类噪声。我们选取4个不同方位的语音干扰比较两个算法的性能。如表1所示,本文提出的算法利用了目标语音和干扰人声的空间差异来区分两者获得了准确的结果。而PLDR算法在干扰人声的噪声环境下性能有了很大的下降。
为了测试神经网络VAD在不同信噪比下的性能,我们分别选取5 dB,10 dB,15 dB的信噪比进行验证,结果如表2所示。从表2中可以看到,本文算法不依赖于固定的阈值,即使在5 dB这样的低信噪比下依旧可以取得很好的VAD结果,非常适合于手机的应用。
本文采用ACTS音频评价系统中的对数谱距离(Logistic Spectral Distance,LSD),客观质量评估(Perceptual Evaluation of Speech Quality,PESQ[15])和信噪比(SNR)分别对本文提出的语音增强算法和文献[1]提出的基于PLD的手机双麦克风语音增强算法的性能进行了衡量。
信噪比衡量了语音增强算法的噪声抑制效果。从表3中可以看出,本文提出的消噪算法相较于PLD算法有了很大的提升,特别是在5 dB信噪比的条件下,本文算法输出的信噪比均能够达到15 dB左右。为了验证算法对于方向性干扰人声的抑制效果,我们选取了45o方位入射的干扰人声,因为45o方位的干扰人声与目标语音的入射方位非常接近,传统的消噪算法很难对其进行有效的抑制,从结果中可以看出,本文算法对于45o方位的干扰人声也有很好的效果,而PLD算法的性能则大大地下降。
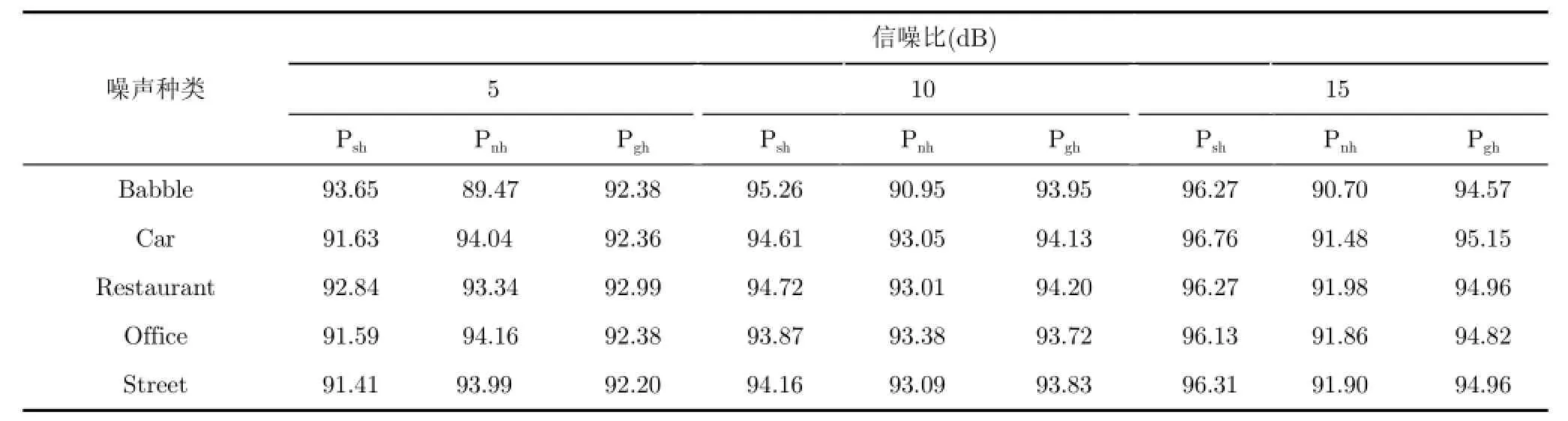
表2 不同信噪比环境下,本文算法的语音活动检测结果
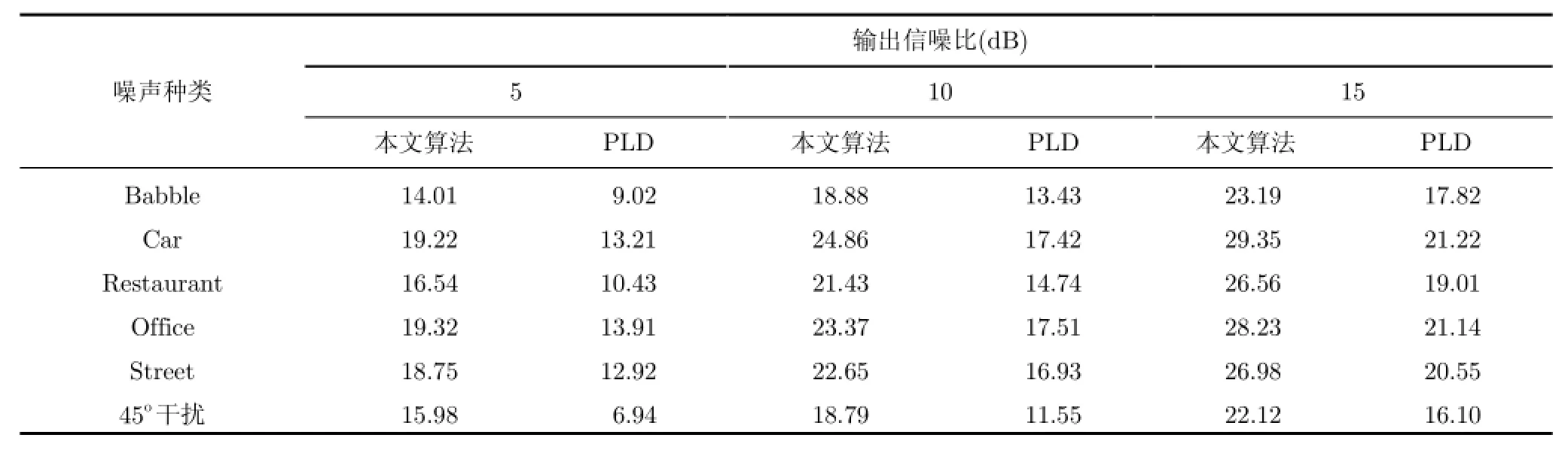
表3 在不同噪声和信噪比条件下经过语音增强处理之后的输出信噪比(dB)
语音的可懂度在手机的通信中非常的重要,消噪算法会带来一定程度的语音失真,LSD指标主要用来衡量增强语音的失真度,LSD值越大说明语音信号的失真越严重,越小表明语音信号失真越小,质量越接近于原始语音。表4给出本文算法与PLD算法增强处理后的LSD对比结果
从表4中可以看出,本文提出的消噪算法相较于PLD算法对语音信号的损失更小,说明经过本文算法处理的语音失真更小,语音质量更接近于原始语音信号,对于方向性的语音干扰也得到了较好的结果。
本文还采用PESQ来测试语音增强算法对语音客观质量的影响,PESQ的值越高说明语音质量越高。从表5中可以看出,与PLD的算法相比,本文提出的消噪算法的输出语音具有更好的语音质量,非正式的主观听觉测试与上述结果一致。
5 总结
本文提出了一种新的基于神经网络的VAD算法,结合两个表征目标语音空间特性的特征,即分频带能量差和互通道相关函数作为神经网络的输入训练神经网络进行语音活动检测。再将基于双通道功率比值的VAD结果与神经网络VAD的结果相结合,提出一种新的适用于手机消噪系统的语音和噪声检测算法,该算法分别对语音和噪声进行检测,减少了消噪系统因VAD的误判而造成的性能下降。实验结果表明,与现有的基于PLD的消噪算法相比,无论是VAD的准确率还是语音增强的效果均有了提升,避免了消噪算法对于语音信号的损害,提高了语音的可懂度,保证了手机通话的质量。
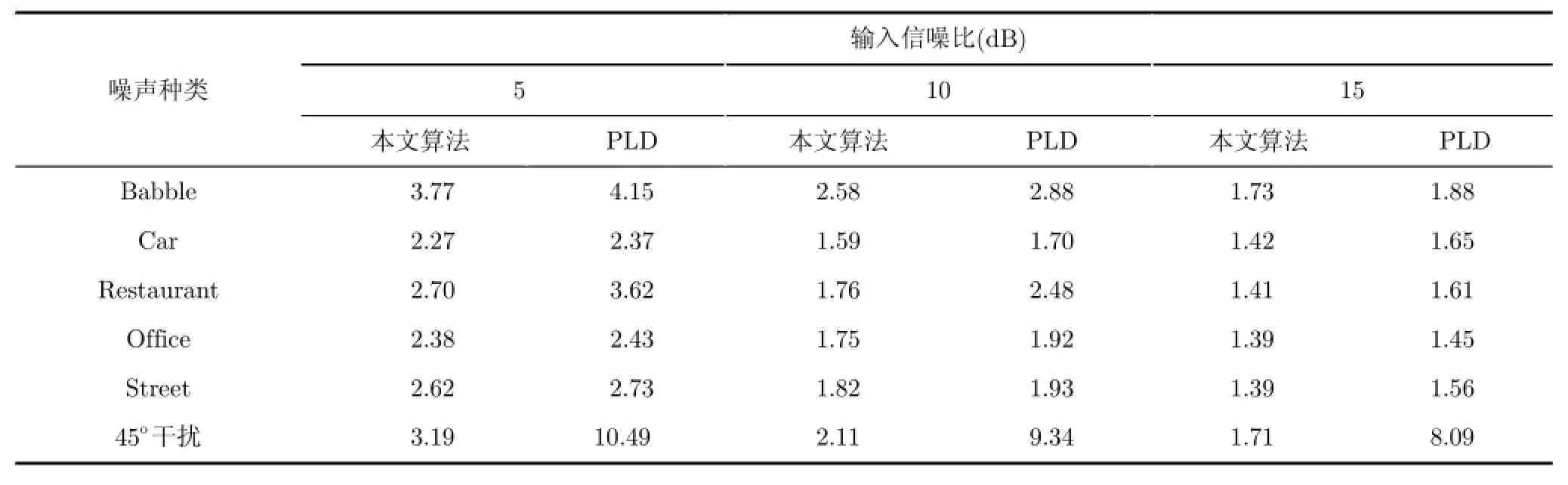
表4 本文算法与PLD算法增强处理后的LSD对比结果
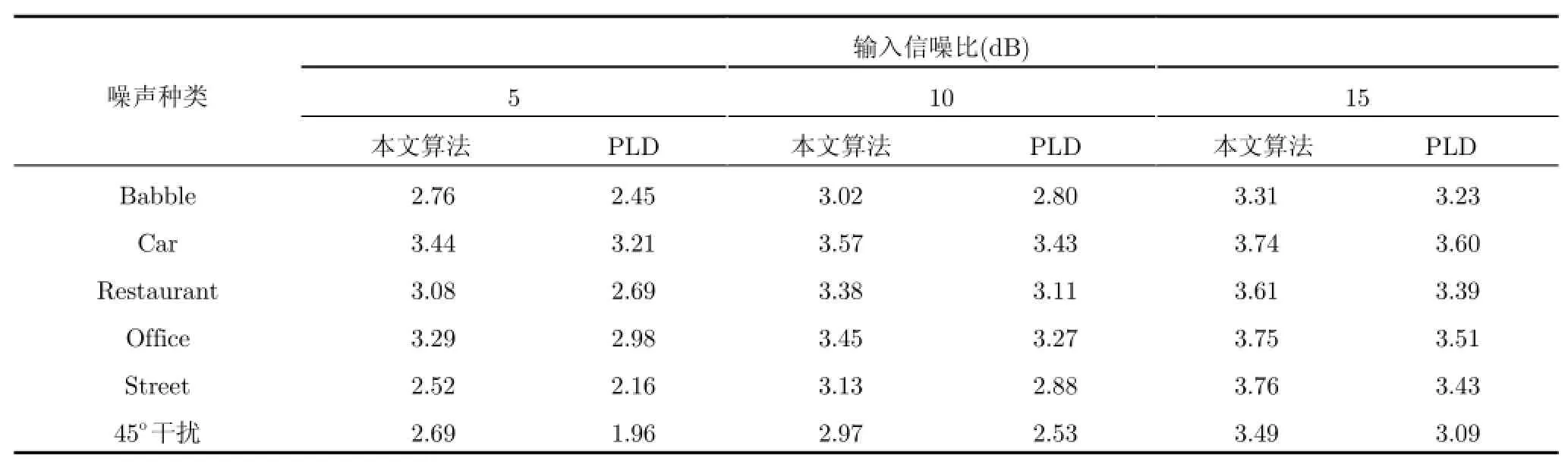
表5 不同信噪比和噪声条件下经过语音增强处理之后的PESQ
[1]JEUB M,HERGLOTZ C,NELKE C M,et al.Noise reduction for dual-m icrophone m ob ile phones exp loiting power level differences[C].IEEE International Con ference on Acoustics,Speech,and Signal Processing,Kyoto,2012: 1693-1696.doi:10.1109/ICASSP.2012.6288223.
[2]XU Y,DU J,and DA IL R.A Regression app roach to speech enhancement based on deep neural networks[J].IEEE Transactions on Audio,Speech,and Language Processing,2015,23(1):7-19.doi:10.1109/TASLP.2014.2364452.
[3]XU Y,DU J,and DAIL R.An experimental study on speech enhancement based on deep neural networks[J].IEEE Signal Processing Letters,2014,21(1):65-68.doi:10.1109/LSP. 2013.2291240.
[4]WANG Y X,NARAYANAN A,andWANG D L.On training targets for supervised speech separation[J].IEEE Transactions on Audio,Speech,and Language Processing,2014,22(12):1849-1859.doi:10.1109/TASLP.2014.2352935.
[5]王明合,张二华,唐振明,等.基于Fisher线性判别分析的语音信号端点检测方法[J].电子与信息学报,2015,37(6): 1343-1349.doi:10.11999/JEIT 141122.
WANGM inghe,ZHANG Erhua,TANG Zhenm in,etal.Voice activity detection based on Fisher linear d iscrim inant analysis[J].Journal of Electronics&Information Technology,2015,37(6):1343-1349.doi:10.11999/JEIT141122.
[6]郭海燕,李枭雄,李拟珺.基于基频状态和帧间相关性的单通道语音分离算法[J].东南大学学报(自然科学版),2014,44(6): 1100-1104.
GUO Haiyan,LI Xiaoxiong,and LI Nijun.Single-channel speech separation based on pitch state and interframe correlation[J].Journal of Southeast Un iversity(Natural Science Edition),2014,44(6):1100-1104.
[7]NELKE C,BEAUGEANT C,and VARY P.Dualm icrophone noise PSD estimation for mobile phones in hands-free position exp loiting the coherence and speech p resence probability[C].IEEE International Conference on Acoustics,Speech,and Signal Processing,Vancouver,2013:7279-7283. doi:10.1109/ICASSP.2013.6639076.
[8]YOUSEFIAN N,RAHMAN I M,and AKBARI A.Power level difference as a criterion for speech enhancement[C]. IEEE International Conference on Acoustics,Speech,and Signal Processing,Taipei,2009:4653-4656.doi:dx.doi.org/ 10.1109/ICASSP.2009.4960668.
[9]YOUSEFIAN N,AKBARI A,and RAHMANI M.Usingpower level difference for near field dual-microphone speech enhancement[J].Applied Acoustics,2009,70(11/12): 1412-1421.
[10]FU Z H,FAN F,and HUANG J D.Dual-m icrophone noise reduction for mobile phone application[C].IEEE International Con ference on Acoustics,Speech,and Signal Processing,Vancouver,2013:7239-7243.doi:10.1109/ ICASSP.2013.6639068.
[11]MEYER-BAESE U.Digital Signal Processing w ith Field Programmable Gate Arrays[M].Third Edition,Berlin Heidelberg:Springer,2007:298-305.
[12]RUBIO J E,ISHIZUKA K,SAWADA H,et al.Twom icrophone voice activity detection based on the hom ogeneity of the direction of arrival estim ates[C].IEEE International Con ference on Acoustics,Speech,and Signal Processing,Honolulu,2007:385-388.doi:10.1109/ICASSP. 2007.366930.
[13]ZHAO H C,LI L G,and LI L H,et al.Dual-m icrophone adaptive noise canceller w ith a voice activity detector[C]. IEEE Region 10 Sym posium,Kuala Lum pur,2014:551-554. doi:10.1109/TENCONSp ring.2014.6863095.
[14]CHOI JH and CHANG JH.Dual-m icrophone voice activity detection technique based on two-step power level difference ratio[J]IEEE Transactions on Audio,Speech and Language Processing,2014.22(6):1069-1081.
[15]HU Y,and LOIZHOU P C.Evaluation of ob jective quality measures for speech enhancement[J].IEEE Transactions on Audio,Speech,and Language Processing,2008,16(1): 229-238.
章雒霏:女,1990年生,博士生,研究方向为信号处理、语音增强、语音识别、语音定位.
张铭:男,1963年生,博士生导师,特聘教授,研究方向为信号处理、语音增强、语音识别.
李晨:女,1980年生,博士,研究方向为信号处理、语音增强、语音识别、语音定位.
A New Voice and Noise Activity Detection A lgorithm and Its App lication to Dual Microphone Noise Suppression System for Handset
ZHANG Luofei ZHANG M ing LIChen
(School of Physics and Technology,Nanjing Normal University,Nanjing 210000,China)
Existing dualm icrophone Voice Activity Detection(VAD)algorithms use normally a fixed threshold. The fixed threshold can not provide an accu rate VAD under various noise environmen ts.In such case,it causes voice quality degradation,particularly in handset app lications.This paper p roposes a new VAD algorithm based on Neural Network(NN).Both sub-band power level difference and inter-m icrophone cross correlation are used as features.Then the NN based VAD is combined w ith themethod of inter-m icrophone signalpower ratio to get a new voice and noise activity detection algorithm.Furthermore,the algorithm is used into noise suppression in handset to avoid performance degradation caused by VAD m isjudgment.Experimental results show that the p roposed m ethod provides better noise suppression performance and lower speech d istortion com pared to the existing method.
Voice Activity Detection(VAD);Speech enhancement;Neural Network(NN)
s:Program of Natural Science Research of Jiangsu Higher Education Institutions of China,Program of Science and Technology of Jiangsu(BE2014139)
TN912.35
A
1009-5896(2016)08-2020-07
10.11999/JEIT 151302
2015-11-23;改回日期:2016-04-12;网络出版:2016-05-31
章雒霏lincover@126.com
江苏省自然科学基金,江苏省声频技术工程重点实验室基金项目(BE2014139)
