基于支持向量机的低收入通勤者出行方式预测*
2016-08-29陈学武王海啸
程 龙 陈学武 杨 硕 王海啸
(东南大学城市智能交通江苏省重点实验室1) 南京 210096)(现代城市交通技术江苏高校协同创新中心2) 南京 210096)
基于支持向量机的低收入通勤者出行方式预测*
程龙1,2)陈学武1,2)杨硕1,2)王海啸1,2)
(东南大学城市智能交通江苏省重点实验室1)南京210096)(现代城市交通技术江苏高校协同创新中心2)南京210096)
为了研究支持向量机(SVM)在出行行为分析中的适用性,分析低收入通勤者的出行方式选择,构建了基于支持向量机的出行方式选择预测建模流程,并对模型求解.基于抚顺市居民出行调查数据,统计结果表明低收入通勤者与非低收入通勤者的社会经济属性特征和活动特征具有显著差异.选取分方式的分类预测准确率、总体分类预测准确率和平均绝对百分比误差3个指标,通过与传统的多项Logit模型对比,发现支持向量机对分类数据具有较好的拟合能力,出行方式选择的预测准确率更高.
出行方式选择;支持向量机;预测能力;低收入通勤者
0 引 言
研究分类变量选择较常用的方法是离散选择模型,但传统的统计建模方法有一定不足,如要求样本数据呈正态分布的假设、假设效用函数中自变量间呈线性关系等.当数据不能满足上述假设时,传统的建模方法得出的结论将会产生偏差.为了克服传统方法的不足,有学者提出非参数建模方法来分析交通选择问题,支持向量机(SVM)则是其中一种用于解决分类和回归问题比较新的方法[1],近年来被广泛应用于交通研究中.
Zhang等[2]运用支持向量机对高速公路短时交通流量进行预测,认为支持向量机能够克服数据过度拟合和局部极小解的问题,具有更好的预测能力.Chen等[3]基于加州I-880号公路的交通事故数据,发现支持向量机在交通事故检测方面具有较强的能力.Li等[4]证明支持向量机比传统负二项回归模型在事故严重等级预测方面的准确性更高,且收敛速率快.通过佛罗里达州326处高速公路分流区交通事故数据的分析,Li等[5]发现支持向量机在事故严重等级预测准确率比有序Probit模型高.可以看出,支持向量机在处理数据分类问题时,比传统的统计模型有较高的数据拟合能力[6].
以往的研究多聚焦在交通流预测、交通事故分析等,较少研究出行方式选择行为.低收入通勤者作为社会的构成的重要阶层,在“交通公平性”的背景下,研究低收入者的出行行为具有重要意义.本研究基于支持向量机分析低收入通勤者出行方式选择行为,探讨其在出行行为分析方面的适用性,以丰富和增强交通需求预测的基础理论.
1 数据来源及描述性统计
数据来自2014年10月29日(星期三)的辽宁省抚顺市居民出行调查.调查内容分为2部分:(1)家庭和个人特征;(2)被调查者的1天出行记录.在对调查数据校核和筛选后,最终获得了8 585个有效个体样本.经济合作与发展组织提出的国际贫困线标准为当地人均可支配收入的50%[7].由此,2014年抚顺市的贫困标准为1.4万元/年.然后基于职业属性,1 973个样本被识别为低收入通勤者.
通过对比,发现低收入和非低收入通勤者的社会经济属性和活动属性特征具有差异性,见表 1.低收入通勤者具有如下特征:家庭规模较大,小汽车拥有率较低,公交卡拥有率高,受教育水平较低;全日较少组织多个出行链,生存型活动(指上班和上学)时耗较长,机动化出行以公共交通为主,小汽车的出行比例较低.低收入和非低收入者选择自行车和电动车出行的比例都较低,这是因为抚顺市位于我国东北地区,受气候和地形地貌的限制(天气冷、道路坡度大),骑行环境较差.
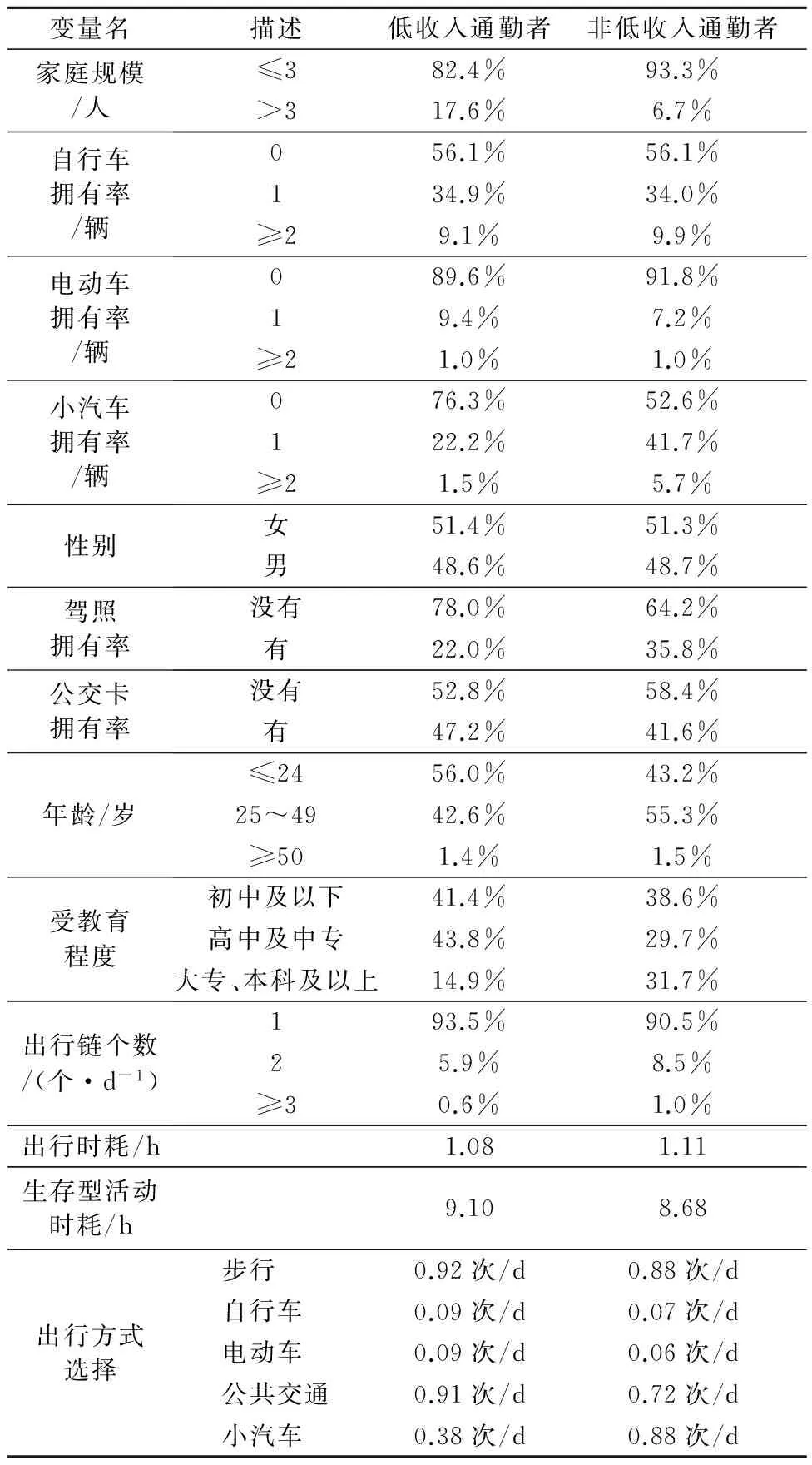
表1 社会经济属性和活动属性特征差异
由于本研究涉及个体社会经济属性、活动属性和方式选择之间的关系,变量数量众多,相互之间关系层次复杂,为了提高初始模型设定的准确性和有效性,需要对各变量间的关系进行显著性检验.表1中的离散变量有家庭规模,自行车、电动车、小汽车拥有率,性别,驾照和公交卡拥有率,年龄,受教育程度,出行链个数.连续变量有出行时耗和生存型活动时耗.卡方检验(Pearson’s chi-squared)用于检验离散变量与出行方式选择之间的显著性,单因素方差分析(ANOVA)用于检验连续变量与出行方式选择之间的显著性.从检验结果发现,表 1中的变量都与出行方式选择显著相关,因此在建模时均予考虑.
2 研究方法
2.1支持向量机
支持向量机是从观测样本数据出发运用统计学的方法,对样本数据规律进行学习,研究其内在的相互关联联系,同时利用该规律对未知数据进行预测估计.支持向量机的模型定义为特征空间上间隔最大的线性分类器,基本思想是寻找能够将全部训练样本点正确分类的最优分类面,同时保证距离该分类面最近的样本点与其间隔最大.学习策略是间隔最大化,最终转化为凸二次规划求解问题.
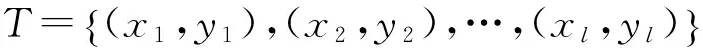
式中:w为分类面的法向量;b为常数项.
当训练样本集在低维空间不可分时,可以通过添加核函数K(xi,xj)将数据映射到高维空间中,以求解在原始空间中线性不可分的问题.当数据存在噪声,可引入非负松弛变量εi≥0和惩罚因子C作为综合权重来处理,则式(1)的最优化问题变为
2.2建模流程
基于支持向量机的低收入通勤者出行方式选择预测建模流程如下.
1) 选择影响低收入通勤者出行方式选择的变量,对数据进行预处理,构造训练样本数据集.基于变量间的相关性检验结果,表 1中的所有变量均作为预测模型的输入.

3) 构造优化问题,如式(2)所示,并对参数进行求解.
4) 求得最优解构建的决策函数,用测试样本数据集预测其他低收入通勤者出行方式选择结果.
模型建立后,采用5折交叉验证来评价模型精度.也就是将原始数据均分成5组,将每个子集数据分别做一次验证集,其余的4组子集数据作为训练集,这样会得到5个模型,用这5个模型验证集的分类准确率的平均值作为分类器的性能指标.5折交叉验证可以有效的避免过学习以及欠学习状态的发生,最后得到的结果具有说服力.
对训练样本集学习过程中,需要确定两个参数,即惩罚因子C和核函数参数r.采用网格搜索算法对参数寻优,网格搜索算法属于启发式算法,不必遍历区间内所有的参数组就能找到全局最优解,具有收敛速度快的特性.
3 分析结果
3.1支持向量机
使用LIBSVM软件包[8]来进行支持向量机模型的标定,事先将总体样本按照4∶1的比例随机分成训练样本集和测试样本集.为了减少数据随机分配产生的误差,做了6次试验以对低收入通勤者出行方式选择进行训练和测试.
以第1次试验为例,详细介绍SVM的训练和测试过程.首先按4∶1的比例将总体数据分成1 578个训练样本和395个测试集样本.然后,采用5折交叉验证和网格搜索法进行参数(C,r)寻优,最终结果见图 1.当训练集验证分类准确率最高时,C=147.033 4,r=0.006 8,此时的训练集验证分类准确率是62.29%.这样就得到了对训练样本学习过程的模型,该模型是一个结构体,由该结构体中参数可以得到决策函数,该决策函数将用于测试样本集数据的预测.
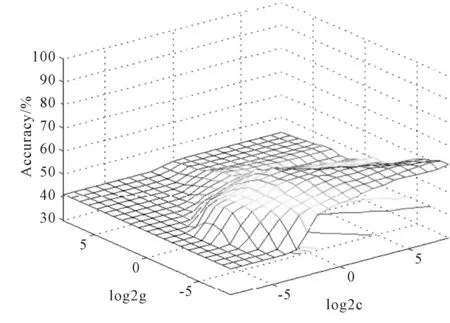
图1 支持向量机参数寻优结果
6次试验的分类准确率汇总情况见表 2.可以发现,支持向量机在训练样本集上分类准确率要大于测试样本集.训练样本数据分类准确率平均值是68.59%,测试样本数据分类准确率平均值是64.66%.此外,对于大样本量的数据,支持向量机有很好的分类能力,如步行和公共交通,两者在测试样本中分类准确率分别是68.96%和76.84%.但对于小样本量的数据,支持向量机的分类能力较差,如自行车和电动车,两者在测试样本中分类准确仅为16.34%和10.73%.这是因为支持向量机在工作过程中为提高整体分类准确率,会忽视小样本量数据提供的信息.这个问题广泛存在于多分类技术手段中,如分类树、人工神经网络和支持向量机[9].

表2 支持向量机的分类准确率
3.2与多项Logit预测能力的对比
为了对比支持向量机与多项Logit(MNL)模型在低收入通勤者出行方式选择的预测能力,基于相同的数据用MNL模型也做了6次试验,首先用训练样本数据对MNL模型中的参数求解,然后基于求解的参数模型对测试样本集中数据进行预测.选取3个指标进行对比,分别是分方式的分类预测准确率、总体预测准确率和平均绝对百分比误差.
1) 分方式的分类预测准确率是指某种交通方式预测准确的样本量占选择该交通方式总样本量的比例,结果见表 3.可以看出,各方式的平均预测准确率SVM均比MNL高,特别对于样本量较小的自行车和电动车两种出行方式,SVM准确率比MNL高很多,约10%,表明MNL模型在小样本量数据上分类能力更差.

表3 分方式平均预测准确率 %
2) 总体分类预测准确率是指所有交通方式预测准确的样本量占总体样本量的比例.SVM的总体分类预测准确率高于MNL,两者分别为64.66%和61.94%.此外,6次试验中SVM预测准确率的方差为1.67,而MNL的方差为4.82,说明SVM在出行方式选择方面的预测能力较为稳定,方差较小.
3) 平均绝对百分比误差为预测值与实际值的差值占实际值百分比的算术平均数,公式为
(3)
(4)
式中:PEi为第i种交通方式选择的百分比误差;n为交通方式种类,本研究有5种;Xi为第i种交通方式实际选择的样本数;Fi为第i种交通方式预测的样本数.指标对比结果见表 4,除第3次试验外,SVM的预测平均绝对百分比误差均小于MNL模型.而且从6次试验整体看,SVM的预测平均绝对百分比误差要小于MNL模型.

表4 平均绝对百分比误差 %
从3个指标的对比可以看出,支持向量机比MNL模型在出行方式选择的预测能力要好,支持向量机具有较高的处理数据分类问题的能力,在出行行为分析中具有较好的适用性.
4 结 束 语
基于抚顺市居民出行调查数据,发现低收入通勤者与非低收入通勤者的社会经济属性特征和活动特征具有显著差异.构建了基于支持向量机的出行方式选择预测建模流程,然后对低收入通勤者的出行方式选择行为进行分析,通过与MNL模型预测能力的对比,发现支持向量机在处理分类数据方面具有较高的拟合能力,在出行行为分析中具有较好的适用性.研究结论将为居民出行行为分析提供新的研究思路,丰富和增强交通需求预测分析的理论基础.但是,本研究仅分析了支持向量机与MNL模型预测能力的对比,以后的研究可进一步考虑与其他传统统计模型,如巢式Logit、混合Logit等的预测能力对比.
[1]郑文昌,陈淑燕,王宣强.面向不平衡数据集的SMOTE-SVM交通事件检测算法[J].武汉理工大学学报,2012,34(11):58-62.
[2]ZHANG Y L, XIE Y C. Forecasting of short-term freeway volume with v-support vector machines[J]. Transportation Research Record: Journal of the Transportation Research Board,2007,2024:92-99.
[3]CHEN S Y, WANG W, HENK J Z. Construct support vector machine ensemble to detect traffic incident[J]. Expert Systems with Applications,2009,36(8):10976-10986.
[4]LI X G, LORD D, ZHANG Y L, ME Y C. Predicting motor vehicle crashes using support vector machine models[J]. Accident Analysis and Prevention,2008,40(4):1611-1618.
[5]LI Z, LIU P, WANG W, et al. Using support vector machine models for crash injury severity analysis[J]. Accident Analysis and Prevention,2012,45:478-486.
[6]ALLAHVIRANLOO M, RECKER W. Daily activity pattern recognition by using support vector machines with multiple classes[J]. Transportation Research Part B: Methodological,2013,58:16-43.
[7]莫泰基.香港贫困与社会保障[M].香港:中华书局,1993.
[8]CHANG C C, Lin C J.LIBSVM: A library for support vector machines[EB/OL]. https://www.csie.ntu.edu.tw/~cjlin/libsvm/,2007.
[9]CHANG L Y, WANG H W. Analysis of traffic injury severity: an application of non-parametric classification tree techniques[J]. Accident Analysis and Prevention,2006,38(5):1019-1027.
Mode Choice Prediction of Low Income Commuters Based on Support Vector Machine
CHENG Long1,2)CHEN Xuewu1,2)YANG Shuo1,2)WANG Haixiao1,2)
(JiangsuKeyLaboratoryofUrbanITS,SoutheastUniversity,Nanjing210096,China)1)(JiangsuProvinceCollaborativeInnovationCenterofModernUrbanTrafficTechnologies,Nanjing210096,China)2)
To explore the applicability of support vector machine (SVM) in travel behavior analysis and shed light on mode choice of low income commuters, model specification scheme of mode choice prediction based on SVM is established. Statistics indicate that low income commuters have distinct socio-economic characteristics and activity characteristics from non-low income commuters based on the travel survey data of Fushun. SVM possesses high fitting ability on categorical data and provides better prediction accuracy of mode choice than traditional Multinomial Logit model from three indicators including the individual percentage of correct predictions, overall percentage of correct predictions and mean absolute percentage error.
mode choice; support vector machine; prediction ability; low income commuters
2016-07-07
U491.1
10.3963/j.issn.2095-3844.2016.04.010
程龙(1989- ):男,博士生,主要研究领域为从事交通出行行为分析与需求建模
*国家自然科学基金项目(51178109、51338003)、国家重点基础研究发展计划项目(973计划)(2012CB725402)资助
