煤炭大数据指数编制及经验模态分解模型研究
2016-08-29米子川姜天英
米子川,姜天英
(山西财经大学 统计学院,山西 太原 030006)
煤炭大数据指数编制及经验模态分解模型研究
米子川,姜天英
(山西财经大学 统计学院,山西 太原 030006)
基于开放性数据源、连续观测昨多变量数据编制的大数据指数,与传统的统计调查指数存在的差异不仅在于数据本身的无限扩张,而且在于编制方法以及分解研究的规则、模型方面的差异。在大数据背景下,率先尝试性地提出大数据指数的定义和数据假设,将“互联网大数据指数”引入煤炭交易价格指数综合编制太原煤炭交易大数据指数,从而反映煤炭价格的变动趋势;导入经验模态分解模型,对所编制的煤炭大数据指数进行分解研究,尝试比较与传统的统计调查指数的差异。研究表明:新编制的煤炭价格大数据指数要比太原煤炭交易价格指数更为敏感和迅速,能更好地反映煤炭价格的变动趋势。随着“互联网+”和大数据战略的逐渐普及,基于互联网大数据编制的综合指数会影响到更多领域,将成为经济管理和社会发展各个领域的晴雨表和指示器;与传统统计调查指数逐步融合、互补或者升级,成为宏观经济大数据指数的重要组成部分。
煤炭交易;大数据指数;EMD模型
一、引 言
“互联网+”是当今社会的操作系统,指数是宏观经济的晴雨表,基于“互联网+”大数据编制的统计指数则是新经济和新规则的仪表盘。2015年6月12日,基于“互联网+”的煤炭大数据平台在太原中国煤炭交易中心正式上线,标志着宏观产业环境的不断优化正在推动中国大数据产业链加速形成。近年来,众多互联网企业围绕大数据展开的技术研发、应用创新和产业探索取得了重要进展,能源、交通、制造业、通讯等传统行业都在积极利用大数据进行应用创新,大数据战略已经成为政府和社会各行业的战略共识。DanahBoyd等人认为大数据不仅带来了技术、学术和文化上的挑战,而且带来了产业升级和经济趋势的改变[1]。在此背景下,如何利用大数据并使其为国家治理、企业决策乃至个人生活服务,正在逐渐成为大数据应用价值的核心所在,而如何在大数据时代给予传统统计指数以新活力,从而使指数呈现“大数据特性”,则又成为大数据指数应用的基本阶梯和必然方向。DemchenkoY甚至认为大数据已经成为处理商业经济和科学问题的基础数据,以大数据为核心构建的数据框架是自然科学和社会科学研究的重要依据[2]。
二、大数据指数与统计调查指数的比较
一般认为,大数据指数是指以基于互联网的电子商务大数据、社交网络大数据和其他类型的社会经济大数据构造的综合指数,是反映社会经济现象发展变化的趋势和强度的一种新型指数,有充分性、敏捷性、连续性、灵活性和多维性等方面的特点。
大数据时代,各种基于大数据和复杂算法的市场指数相继出现,基于抽样调查的统计指数已不能全面反映经济社会的运行状况并对经济进行更加准确的预测。太原煤炭交易价格指数是山西煤炭交易市场的方向标,也是中国煤炭市场的晴雨表,目前也迎来了众多网络交易平台提供的海量数据所带来的挑战,因而面临着煤炭交易价格指数样本量少、数据不连续、存在一定时滞等问题。因此,如何在大数据背景下利用有效方法对煤炭交易数据进行筛选和处理,并且编制煤炭交易价格大数据指数,使之能及时准确地反映煤炭价格走势,实现煤炭价格的发现功能和指引功能,并对煤炭市场的变动发展做出前瞻性的预测,具有十分重要的意义。
统计学领域中对于大数据的研究,集中在2012年以来的学术交流、会议、报告和学术论文中,对于数据分析和统计指数的研究已经有了一定的成果。徐宗本院士等人认为,大数据的兴起带来了理论与实践范式、支撑技术、价值开发、产业与生态系统治理等多方面的重大挑战,需要在基础理论、工程技术和人才培养等各个层面上加以应对,还特别提出了大数据驱动的四个重要领域,其中包括大数据分析与处理的数学与计算基础,即可以认为大数据指数是这方面的重要应用之一[3];北京大学耿直教授在第十五次全国中青年统计科学研讨会上提出了将统计机构的数据作为金标准(即Goldstandard,指临床医学界用来诊断疾病的最可靠、最准确和最常用的标准,如组织病理学检验、手术发现、影像诊断等)和框架,对互联网数据进行矫正,将互联网数据作为补充资源对统计机构的数据进行实时更新,也许是解决问题的一个思路[4];王元卓等人提出由于网络大数据的复杂性、不确定性和涌现性,大数据的计算需要新的模式和范式[5];张崇等人研究了网络搜索数据与CPI的相关性,开始探索网络搜索数据与现实生活中的CPI之间可能存在的一种关联关系[6];李晓欣、乔晗、陈梦根等人都比较集中地研究了利用扫描数据编制CPI的方法,开始考虑利用行政管理的大数据尝试编制宏观经济指数,针对中国扫描数据的现状和政府价格统计的特点提出了一些利用扫描数据编制中国CPI的思路[7-9];李晋红、张朋程、刘满枝等人均提出了煤炭价格指数对于企业生产、投资判断以及预测价格走势具有重要意义,强调在大数据背景下对煤炭价格指数的研究显得尤为必要[10-12];郭洪伟基于网络大数据研究了消费者信心指数,并通过电商数据、消费者情绪数据等非结构化数据编制了消费者信息指数,这是大数据指数编制的一种尝试,有着重要的实践意义和应用价值[13]。
基于生活消费理论编制的阿里巴巴全网网购价格指数(aSPI),是反映阿里巴巴网购平台上总体消费价格水平变化的综合统计指数,是以叶子类目上月成交份额为权重计算的每月加权成交均价变动指数。它不仅包含了商品层面的一般价格变动,而且包含了消费者在叶子类目下消费结构变动的信息。该结构的变动衡量了消费者对同一基本分类下高价商品和低价商品的相对选择替代程度,且该选择由高价商品和低价商品的相对价格变动、季节性因素以及网购人群收入结构变动所驱动。同时,阿里巴巴还同步公布网购核心商品价格指数(alibabaShoppingPriceIndex-core,aSPI-core),这项指数是固定篮子价格指数,通过创新的筛选算法圈定阿里零售平台上近五百个基本分类下接近10万种核心商品作为固定“篮子”,每月追踪该篮子内商品和服务实际网购成交价格变化,以刻画网购主流商品和服务的一般价格波动,并从网络零售渠道反映宏观物价走势。然而,这种设计也存在一定的缺陷,即由于产品更新速度快,新产品从上市到畅销阶段存在一定的溢价,随着替代品的增加,溢价会逐渐降低,使固定篮子指数在长期有可能会低估消费支出成本的上升趋势。
大数据指数的编制是以传统统计调查指数为基础计算而来,但同时也有与传统统计调查指数诸多的不同之处。就目前网络大数据指数的发展情况,可将其总结定义为两大趋势:一是以新兴电商为代表的可连续更新的覆盖全部交易数据的微观指数,具有代表性的有阿里巴巴系列价格指数、百度指数、大数据300指数等;二是由于传统统计调查指数尚无法达到连续更新的特点,故考虑在统计调查指数的基础上将行政管理记录等大数据资源引入其中,使其具有大数据特性(见表1)。
三、煤炭大数据指数的编制
本文以太原煤炭交易价格指数为研究对象,同时引入“网络大数据指数”,包括煤炭价格、百度指数和原煤阿里指数,从而使其具有“大数据的特性”,构造太原煤炭价格大数据指数,将大数据指数与太原煤炭交易综合价格指数进行对比研究,得出验证性结论和研究建议。

表1 大数据指数与统计调查指数比较表
(一)数据选取
依据上文提到的三个变量:太原煤炭交易价格指数(X1t)、原煤阿里指数(X2t)和煤炭价格百度指数(X3t),其来源分别为中国(太原)煤炭交易中心、阿里指数和百度指数。数据周期为周数据,本文选取时间从2014年6月27日至2015年6月12日,共48周的数据进行建模分析(不包括法定节假日的数据)。尝试通过对煤炭大数据指数的编制来反映近一年煤炭交易价格的变动情况,从而探索煤炭大数据指数的适用性和不足。
(二)数据处理
1.数据标准化。由于太原煤炭交易价格指数、原煤阿里指数和煤炭价格百度指数三者数据的量纲不同,故首先对数据进行标准化处理。采用的方法是离差标准化,即使标准化后的数据落入[0,1]区间,采用的公式为:
(i=1,2,…,m;t=1,2,…,n)
(1)
其中xit表示原始数据,min{xit}表示原始数据中的最小值,max{xit}表示原始数据中的最大值,yit表示标准化后的数据,且其属于[0,1]区间。经过标准化处理后,三个变量数据均属于[0,1]区间,且基本上消除了量纲影响。
2.数据加权。数据的加权方法很多,由于本文新指标的特殊性,故以太原煤炭交易价格指数为基准,分别求原煤阿里指数和煤炭价格百度指数与太原煤炭交易价格指数的相关系数,并在此基础上确定三者的权重,具体计算方法为:
第一步:计算三个变量与太原煤炭交易价格指数的相关系数。通过相关系数的计算公式,所得结果为:r1=1,r2=0.32,r3=0.02(r1表示太原煤炭交易价格指数与自身的相关系数,r2表示太原煤炭交易价格指数与原煤阿里指数的相关系数,r3表示太原煤炭交易价格指数与百度煤炭价格指数的相关系数)。从相关系数中可以简要得出,以“煤炭价格”为搜索词的百度指数对太原煤炭交易价格指数的影响较原煤阿里指数的影响较小,这与原煤阿里指数为采购指数有关;而百度指数仅反映其搜索量的信息,表现为一种关注强度,但为了更为全面地反映大数据指数,将二者均包括在内进行计算。
第二步:确定权重。根据第一步中的相关系数,确定各序列的权重,即:
(2)
通过以上数据标准化和确定权重两个步骤,得到煤炭交易价格大数据指数。下文将对该指数进行建模,通过构建模型分析该指数的一些特征,并通过与统计调查指数的对比来反映该指数的优势。
四、基于组合模型和经验模态分解模型的建模分析
(一)新序列Yt的组合与分解
通过以上步骤对数据进行处理之后,可以得到一个新的序列Yt(=w1*X1t+w2*X2t+w3*X3t=P1t+P2t)。由于P1t(即w1*X1t)属于传统统计调查指数部分,P2t(即w2*X2t+w3*X3t)属于互联网实时更新数据部分,且从图1和图2上可以看出,P1t有较为明显的下降趋势,P2t则显示了较为剧烈的波动,故将其分开进行研究。
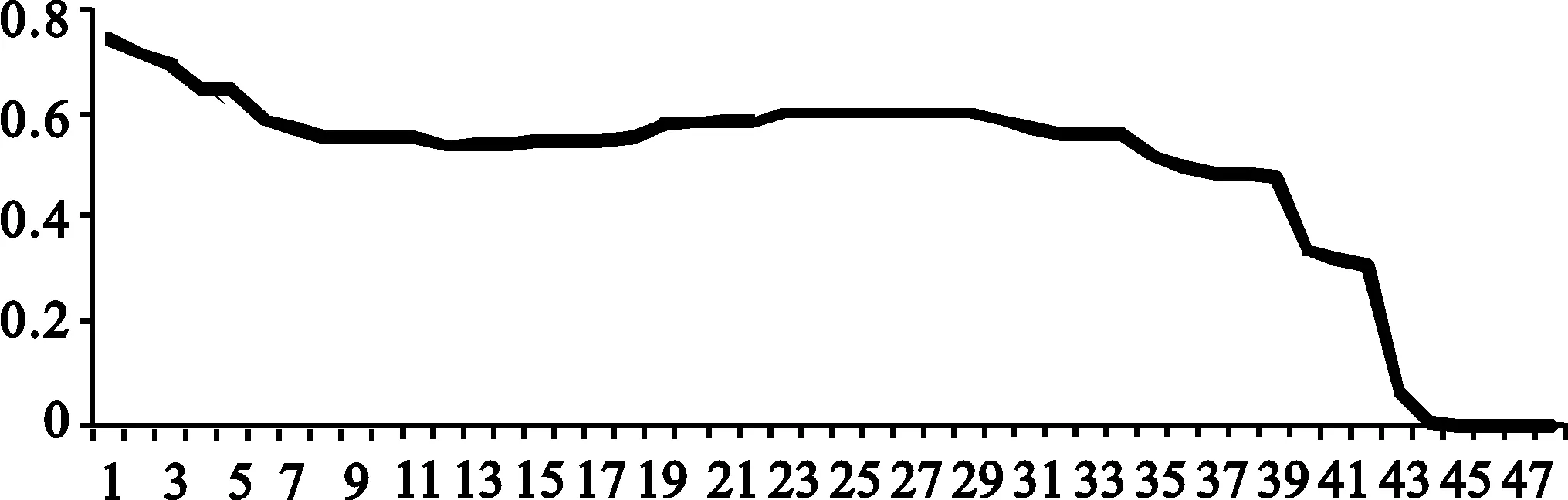
图1 P1t时序图

图2 P2t时序图
1.对序列P1t的分解。从图1可以看出,序列P1t具有显著的下行趋势,故考虑采用组合模型,对其进行分解,组合模型对原序列分析的基本思想是将原序列分解为两部分:其一为趋势部分,用某一函数进行拟合;其二是残差项,即波动部分,这样分解可以更好地反映出原序列的变动情况,其具体步骤如下:
第一步:确定序列P1t与时间t的关系。通过序列与时间的散点图可以得出,序列具有明显的下降趋势,拟采用组合模型对其进行拟合,其中函数采用指数函数和二次函数共同表示,即:
(3)
第二步:进行回归解释。对原序列用指数函数和二次函数拟合,结果得出:
P1t=0.91exp{-0.19t}+0.05t-0.001t2
t(14.33) (-9.22) (33.28)(-27.44)
(4)
从结果可以看出,在显著性水平为5%的条件下,模型的可决系数达到92.6%,调整后的可决系数达到92.1%,模型F值为72.05,表明模型拟合较好且均通过t检验。
第三步:残差项确定。通过前两步,用原序列将拟合的序列减去,即可得到波动项N1t。
2.P2t序列的分解。通过图2可以看出,序列P2t波动幅度较大,故考虑用经验模态分解(Empirical Mode Decomposition, EMD)对序列进行分解。经验模态分解对于研究非平稳序列具有优势,其可将原序列分解为不同频率的本征模函数(IMF,频率依次递减)和趋势项。
本文拟将所有的本征模函数加总,共同表示序列P2t的波动部分,剩余部分则为趋势项。图3为序列P2t的EMD分解结果。从图3中可以看出,前5行即为IMF1-5,且其频率依次递减,最后一行为趋势项T2t。通过将IMF1-5加总,得到波动部分R2t,最终可得P2t=T2t+R2t。
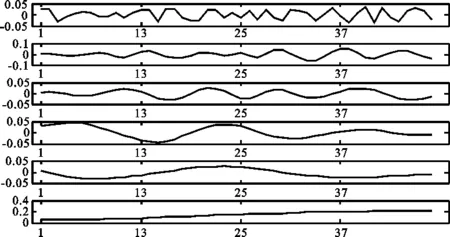
图3 EMD分解结果图
3.小结。通过对P1t和P2t的分解结果得出二者各自的趋势项和波动项,故将二者的趋势部分和波动部分分别相加,得到序列Yt的趋势项(At)和波动项(Bt),即:
(5)
最终将序列Yt表示为趋势项At和波动项Bt,其时序图见图4。
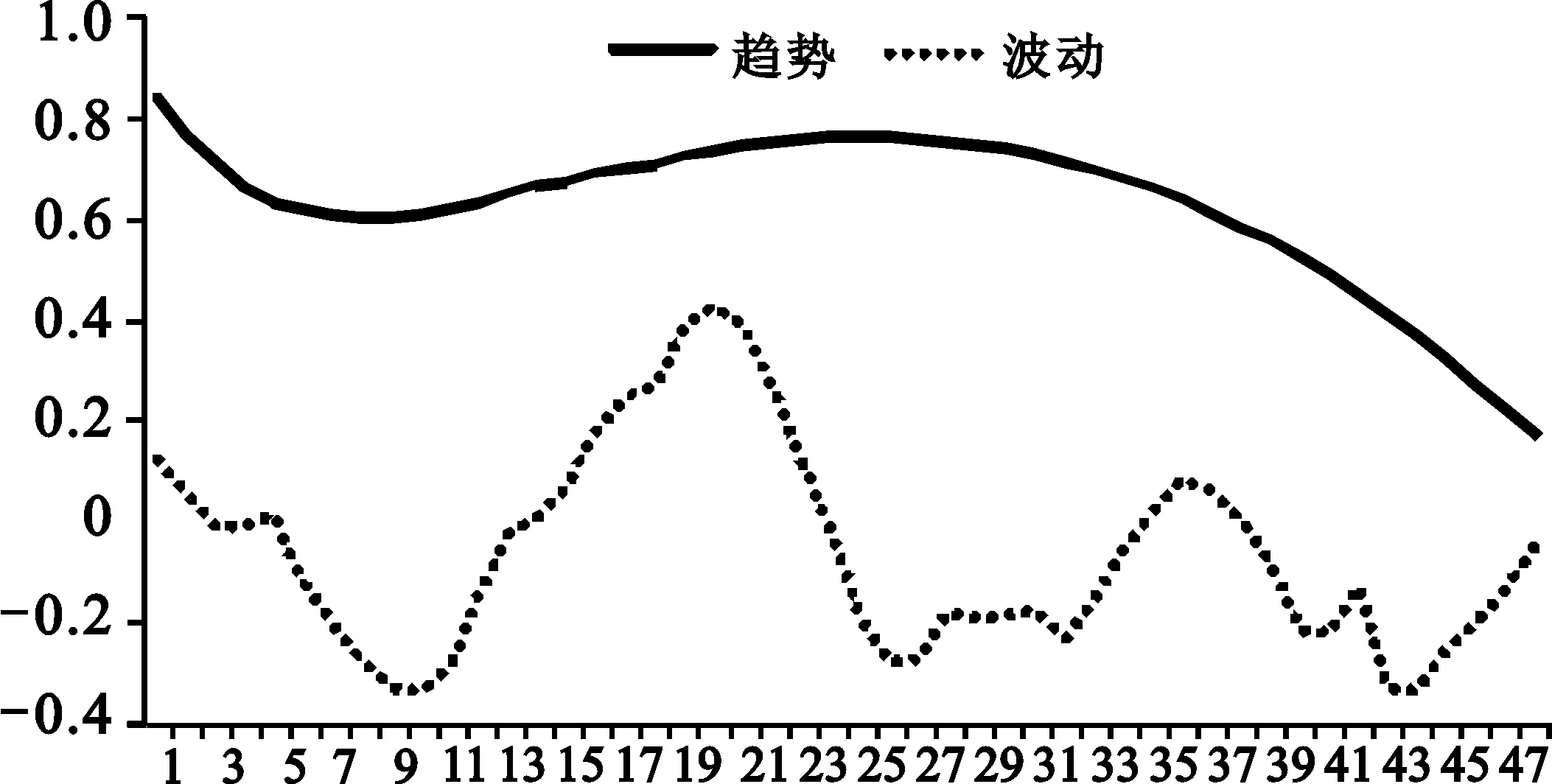
图4 At和Bt时序图
通过对序列Yt的分解结果可以得出其趋势部分At具有明显的拐点:第一个拐点出现的时间为2014年8月中旬,在这一时间之后,煤炭交易价格大数据指数出现上升趋势,但是这一趋势的增幅较为平缓,呈现这一趋势的主要原因是后半年煤炭市场进入旺季,对煤炭的需求量变大,对煤炭价格的关注度提升;第二个拐点的时间处于2015年1月初,这一时间之后煤炭交易价格大数据指数出现较为迅速的下行态势,主要原因有四个:一是市场即将进入淡季,煤炭需求减少,导致指数呈现下行趋势;二是中国经济进入新常态,工业生产增速放缓,火力发电的需煤量减少,作为工业能源的煤炭交易价格下行;三是中国政府环保压力的增大,煤炭产业在缺少国家层面政策支持的情况下,煤炭价格开始持续下降;四是在2014年12月份山西省出台了一系列的煤焦公路运销改革措施,从而对煤炭交易价格的下降有着较强烈的影响,而且这一因素对基于太原煤炭交易价格综合指数构建的煤炭大数据指数的下行拐点起着主要影响。对其波动部分,可将其解释为隐性因素的影响,即无法进行深度量化分析的因素,主要包括来自其他市场的影响、消费者心理的影响因素和决策因素以及煤炭企业自身的发展因素等。
(二)新序列Yt与原序列X1t的对比研究
通过以上的研究,将新序列Yt分解为趋势项和波动项,通过图5可以看出序列Yt与序列X1t间存在较大差异,相比之下序列Yt波动幅度较大,而序列X1t则较为平缓,主要原因是:Yt的波动幅度是由于引入了阿里指数与百度指数这一互联网实时指数的影响,因为互联网大数据是由海量用户的网络实时行为产生,所以引入这些互联网指数构建的煤炭价格大数据指数对煤炭价格的反应更为灵敏,其波动性也越强。如图5所示,在时间2014年8月中旬到2015年1月初的这一时间段内,原序列X1t的变动平缓而新构建的序列Yt有着显著的二次函数特征,这一特征出现的主要原因是互联网对煤炭价格关注度的变动引起的,从2014年8月中旬到2014年11月初,由于冬季供暖用煤量储备的需求,煤炭交易进入旺季,对煤炭价格的网络关注度增加而使序列Yt持续上升,从2014年11月初到2015年1月煤炭价格的关注度回落,序列Yt开始呈现下行趋势。
笔者认为这种波动幅度的变大,可以更好地反应煤炭价格的变动情况以及反映煤炭市场的行情趋向。
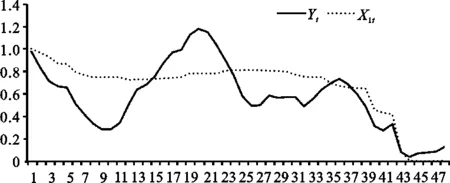
图5 序列Yt与X1t时序图
1.序列X1t的拟合。类比(一)中的对P1t的拟合方法,对序列X1t仍采用组合模型进行拟合,其具体结果为:
第一步,确定序列X1t与时间t的关系。通过序列与时间的散点图可以得出序列具有明显的趋势,拟采用组合模型对其进行拟合,其中函数采用指数函数和二次函数共同表示,即:
(6)
第二步,进行回归解释。通过对原序列用指数函数和二次函数拟合,结果得出:
Xit=1.21exp{-0.19t}+0.07t-0.001 5t2
t(14.34)(-9.25)(33.65)(-27.73)
(7)
从结果可以看出,在显著性水平为5%的条件下,模型的可决系数达到92.5%,调整后的可决系数达到92.1%,模型F值为58.31,表明模型拟合较好且各变量均通过t检验。
通过组合模型的拟合,也可将序列X1t分解为趋势部分和波动部分,而后将序列Yt和X1t的趋势部分进行对比,研究二者的同步性。
2.序列Yt和X1t的趋势项同步性研究。本文采用同步系数法对两个模型中的序列进行同步性研究。该方法相比于相关系数法而言,不存在信息遗漏的问题且对于序列特征亦无要求。同步系数是为了测量两个时间序列数据在对应相邻数据变化的一致性的指标,在满足基本的计算原则下,同步系数法可归结为:
1)假设有两个时间序列变量:Xt和Yt(t相同),将Xt作为基序列。
2)分别对Xt和Yt进行差分,比较二者在相同时间的差分方向是否一致,当方向相同时记m=1,否则m=0。
3)对m进行求和,得到M(0≤M≤n-1),利用同步系数的计算公式求得rr(0≤rr≤1),计算公式为:
(8)
且其规定:当0≤rr≤0.5时,说明计算的两个序列之间的同步性较差,表现为异步性较多;当0.5 通过以上同步系数法的检验,得到rr的值为0.936,依据其原则可以得出序列Yt和X1t的趋势项具有较强的同步性,并在一定程度上说明对于整体序列,二者在其可见影响因素的影响下具有一定的同步性,这也从一个侧面反映了新序列Yt的可解释性和合理性。 3.序列Yt和X1t的波动项研究。从图6中可以看出,序列Yt的波动项较序列X1t的波动项波动幅度更大,这主要是由于新序列Yt中的影响因素涉及面更广,包括了大数据时代下的网络实时数据。 通过以上对序列Yt和序列X1t的对比分析,在一定程度上可以认为本文编制的大数据指数较之前的煤炭交易价格指数涉及面更为广泛,且在其趋势部分二者具有同步性,证明了新的煤炭大数据指数有其存在的合理性;且煤炭大数据指数的波动部分能更好地包含其他不可控因素和消费者的心理行为等因素,并能从侧面反映出消费者对煤炭关注度的时间段,可为煤炭的需求提供部分信息。基于此,笔者认为当前构建的大数据指数较传统的太原煤炭交易价格指数,能更好地适应大数据时代和更好地反映煤炭价格的变化。 图6 序列Yt和X1t波动部分时序图 (一)研究结论 煤炭交易价格大数据指数的编制原理,是在传统价格指数中引入互联网上反映关注煤炭价格的相关搜索、引用、评论和转载的数据,革新了统计指数的编制方法,对煤炭价格可以有更为清晰、直观和全面的反映。基于前文的研究,得出以下结论:一是本文所构造的大数据指数具有较好的可解释性。大数据指数与传统统计调查指数的趋势项在一定范围内存在同向发展趋势,二者同步性特征较为显著;二是大数据指数的涉及面更广泛。大数据指数包含了传统统计调查无法涉及的“网络大数据指数”,可以更为全面地反映煤炭交易的诸多构造面及影响因素;三是通过对太原煤炭价格指数的研究表明,近期煤炭价格仍处于不断下行状态,煤炭市场不断萎缩,未来仍需探求煤炭市场供需关系的发展以及国家能源政策的扶持。 (二)方法论方面的改进与设想 本文作为大数据指数编制的初探,其方法、指标选择、权重设计和数据采集都还很不成熟:第一,对大数据指数的定义仍有待完善。本文尝试性地归纳给出大数据指数的定义,具有一定的主观性,后续研究应对其进行不断地修改和完善;第二,指标引入的代表性问题尚没有解决。本文的变量引入仅将与太原煤炭交易价格指数有关的原煤阿里指数和煤炭价格百度指数引入,由于技术和数据的限制,其代表性并不强,并且涉及的范围较窄,很难全面反映相关指数的所有情况,同时阿里指数和百度指数尚处在高速发展阶段,数据的有效性也需进一步讨论;第三,在形成新指数的过程中,数据处理存在一定的局限性。在构建煤炭交易价格大数据指数的过程中,各指数的权重确定还需一定的理论支撑以及优化方法的引入,本文只是利用简单的系数加权法来赋予变量权重;第四,大数据抽样的样本量过少。由于阿里指数和百度指数等大数据条件下的实时数据起步较晚,时间区间较短,因此本文的样本量较少,很难对总体做出准确有效的描述、分析与推断。 基于以上模型的不足之处,在之后的研究中可进行适当地改善:第一,增加指数编制的样本量。样本量对于总体推断具有决定性的作用,适当地增加样本量可起到提高估计精度和拟合优度的效果;第二,引入更具代表性的变量以及范围更为广泛的变量。对于大指数的构建,可更多地引入“网络数据指数”等变量,但并不是无限制的引入,在变量的引入过程中需进行变量的特征选择。在大数据时代,传统统计调查指数的转型仍需借助当前新兴的数据存储和提取技术与大数据有关的实时数据,所以引入诸如阿里指数、百度指数等代表性较强的变量,对于构建大数据指数具有指向性作用;从另一侧面,可以将如阿里指数和百度指数进行因素交互影响研究,如心理因素和行为因素等;第三,建立一套完备的引入变量的机制和原则等。在当前错综复杂的数据浪潮中,如何有效地利用实时数据是一个亟需解决的问题,建立一套合理引入网络数据的标准,对于构建大数据指数具有决定性作用;第四,对于大数据指数的定义。大数据指数的定义具有主观性,在以后的研究中应立足寻找其成立的理论支撑,同时应该结合大数据固有的特征,探索新的算法模型来进行大数据指数的编制;第五,对于煤炭交易价格指数,可将其作为扫描数据的一种,并将其分为三类:一类是基于传统价格网点的调查数据,二类是在信息化高速发展的条件下加入电子计价单位的实时交易数据,三类即为引入与研究变量息息相关的反映心理和行为等因素的网络大数据;第六,在大数据指数构建之后,可将其与宏观经济指标进行综合分析,更进一步地反映其合理性。 在大数据时代,大数据指数的出现给予政府统计以新思路,而如何合理合法地将当前各种复杂的网络数据有效导入传统调查指数中,以更好反映其经济意义以及简化工作流程、减少成本,达到效用最大化,则是大数据时代传统统计调查面临的新课题。从宏观经济、社会发展和政府管理的角度出发,如何将大数据指数纳入到现行的统计调查指数系列中,有效融合各自的优势和特长,面向全社会开展积极有效的指数服务,才是最重要的发展目标。 [1]BoydD,CrawfordK.CriticalQuestionforBigData:ProvocationsforaCulturalTechnologicalandScholarlyPhenomenon[J].InformationCommunication&Society, 2012, 15(5). [2]DemchenkoY,GrossoP,deLaatC,etal.AddressingBigDataIssuesinScientificDataInfrastructure[R].InternationalConferenceonCollaborationTechnologies&SystemsSanDiegoCaliforniaUsaMayProceedings, 2013. [3]徐宗本,冯芷艳,郭迅华,曾大军,陈国青.大数据驱动的管理与决策前沿课题[J].管理世界, 2014(11). [4]耿直.大数据时代统计学面临的机遇与挑战[R].天津:第十五次全国中青年统计科学研讨会,2014. [5]王元卓,靳小龙,程学旗. 网络大数据:现状与展望[J]. 计算机学报, 2013(6). [6]张崇, 吕本富, 彭赓,等. 网络搜索数据与CPI的相关性研究[J]. 管理科学学报, 2012(7). [7]李晓欣. 大数据时代中国CPI调查与编制问题研究[J]. 价格理论与实践, 2014(10). [8]乔晗.大数据背景下利用扫描数据编制中国CPI问题研究[J].统计与信息论坛, 2014(2). [9]陈梦根,刘浩. 大数据对CPI统计的影响及方法改进研究[J]. 统计与信息论坛, 2015(6). [10]李晋红. 建立山西煤炭价格指数的背景和必要性分析[J]. 中北大学学报:社会科学版, 2010(1). [11]张朋程.CR中国煤炭价格指数研究[J]. 煤炭经济研究, 2012(11). [12]刘满芝,高晓峰. 中国煤炭需求波动规律研究[J]. 资源科学, 2013(4). [13]郭洪伟. 基于网络大数据的消费者信心指数编制[J].统计与信息论坛, 2015(6). TheBigDataIndexCompilingofCoalandtheResearchofEMDModels MIZi-chuan,JIANGTian-ying (SchoolofStatistics,ShanxiUniversityofFinance&Economics,Taiyuan030006,China) Basedonopendatasource,continuousobservationandmultivariatedataestablishment,thebigdataindexshowsacoupleofdifferenceswithtraditionalstatisticalsurveyindexintermsofunlimitedexpansionofdataitself,indexinganddecompositionmethodsaswellasdifferentresearchapproaches.Inthelightofbigdata,thispapertakestheleadintryingtoputforwardthedefinitionofbigdataindexanddatahypothesis,thenintroducing"internetbigdataindex"intoCTPI(CoalTransactionPriceIndex)inordertosyntheticallycompileabigdataindexofcoaltradinginTaiyuan,whichisexpectedtodepictthechangingtendencyofcoalprice.ThispaperadoptEMD(EmpiricalModeDecomposition)modelfordecompositionresearchofthealready-madebigdataindexcoaltransaction,intendingtocompareitwiththeonemadethroughtraditionalstatisticalsurvey.ThestudyshowsthatthebigdataindexofcoalpriceismoresensitiveandrapidthanCTPIinreflectingthechangingtendencyofcoalprice.Withtheincreasingpopularityof"InternetPlus"andStrategyofBigData,comprehensiveindexbasedontheinternetbigdatawillaffectmoreandmorefields,becomingabarometerandindicatorofeconomicmanagementandallotherfieldsofsocialdevelopment,graduallyreplacingorturningintoavitalsupplementoftraditionalstatisticalsurveyindex. coaltrade;bigdataindex;EMDmodel 2016-03-29;修复日期:2016-06-08 全国统计科学重点研究课题《基于移动通信大数据的流动人口精细化挖掘研究》(2015433);山西省高等学校哲学社会科学研究项目《晋商商业遗产研究》(2013325);山西省统计学会课题《城市流动人口的大数据测度方法研究》(KY[2015]008) 米子川,男,山西祁县人,统计学博士,副教授,硕士生导师,研究方向:应用统计学,抽样调查与数据分析; F224.0 A 1007-3116(2016)08-0071-07 (责任编辑:郭诗梦) 姜天英,女,山东烟台人,硕士生,研究方向:应用统计学与大数据指数分析。 【统计应用研究】
五、研究结论
