基于概率回归模型和K-最近邻的电子商务个性化推荐方案*
2016-08-26徐平平王华君黎远松
王 伟, 徐平平, 王华君, 黎远松
(1.无锡太湖学院 工学院,江苏 无锡 214064;2.东南大学 信息科学与工程学院,江苏 南京 211189;3.四川理工学院 计算机学院,四川 自贡 643000)
基于概率回归模型和K-最近邻的电子商务个性化推荐方案*
王伟1,徐平平2*,王华君1,黎远松3
(1.无锡太湖学院 工学院,江苏 无锡 214064;2.东南大学 信息科学与工程学院,江苏 南京 211189;3.四川理工学院 计算机学院,四川 自贡 643000)
针对电子商务中个性化推荐问题,提出一种基于概率回归模型和K-最近邻的电子商务个性化推荐方案.实验结果表明,该方案能够准确为客户推荐所需的商品.
电子商务;个性化推荐;概率回归模型;K-最近邻
许多学者提出了多种电子商务推荐方案.[2]提出一种基于评价特征分析的推荐方案,从众多评价中提取特征,采用多关系矩阵分解(MRMF)来搭建用户对于商品和特定特征观点之间相关性的模型,从而预测客户所需商品的可能性.这种方案的局限性在于没有强调新用户“不完全偏好”现象.为了在电子商务领域开发更为有效的推荐系统,需要充分挖掘商品评价中其他客户有价值的评价信息,为新用户决策提供帮助[7].
本文提出一种基于概率回归模型(PRM)和K-最近邻(K-NN)的电子商务个性化推荐方案,首次将概率回归模型(PRM)用来确定整体评价和特征评价之间的关系,从文本评价中挖掘评价者的权重偏好.再利用K-NN算法,基于获得的用户权重偏好,定位与当前买家具有相似权重偏好的评价者组,并给出前N名的商品推荐列表.实验结果表明,本文方案能够准确地给出用户推荐.
1 本文方案架构
为了生成当前买家的精确推荐,其核心理念是:区分买家固有偏好与商品评价者间的相似性[3].其中,亟待解决的问题有:(1)根据买家提供的评价信息来恢复评价者的多特征偏好;(2)建立当前买家和评价者间的偏好相关性;(3)预测买家的完整偏好,并做出推荐.
本文推荐系统的工作流程主要由三个步骤构成.
步骤1:对文本进行预处理,进行特征级意见挖掘,用以确定每个评价者的特征-意见值〈feature,opinion_value〉对.意见(opinion)表示评价者对特征的积极、中性,或负面的评价.
步骤2:利用了概率回归模型(PRM)[4]生成评价者的权重偏好.
步骤3:根据步骤2输出的评价者偏好权重,利用K最近邻算法(K-NN)[5]来定位与当前买家具有相似权重偏好的评价者组,并定位相关商品.最终返回排名前N的商品,并通过评价任务测试当前买家的目标选择是否在反馈商品列表中.表1列出了文中相关符号说明.
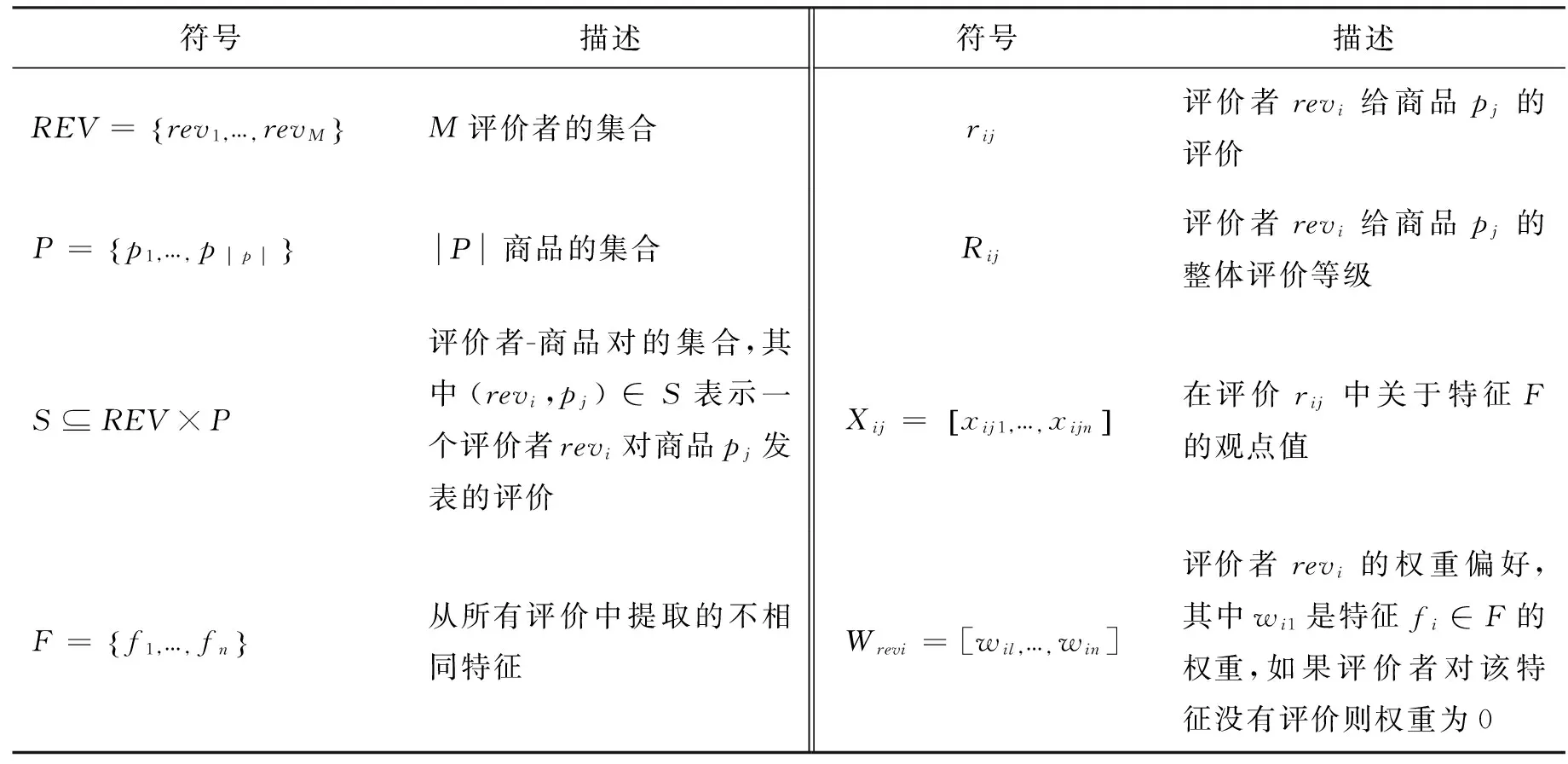
表1 本文所涉及的符号及含义Tab.1 The symbols and meaning involved in this paper
2 预处理过程
在推导评价者权重偏好前,需先对原始评价文本进行预处理,转化生成特征-意见值〈feature,opinion_value〉对.本文实施两个步骤来生成特征-意见对.
步骤1:从评价中提取特征并对同义词特征进行分组.本文中使用Core-NLP包的词性(POS)标记来提取常见的名词(和名词短语),用以识别潜在的候选特征.此外,定义了种子词集合,利用WordNet工具[6],通过计算词汇与种子词的相似度来对同义特征进行分组.
步骤2:量化意见值.这步中,本文评估每个意见词的情绪强度(也叫做极性值).为此,文中对每个意见词s提供三种极性值:积极性、消极性和客观性,分别记为Pos(s)、Neg(s)和Obj(s),其范围区间从0.0到1.0,并满足Pos(s)+Neg(s)+Obj(s)=1.然后,将三种分值综合为单一的情感评分:Os=Neg(s)*Rmin+Pos(s)*Rmax+Obj(s)*(Rmin+Rmax)/2.其中,Rmin和Rmax分别表示最小和最大规模;设置Rmin=1、Rmax=5;Os范围为从1到5.
3 基于概率回归模型(PRM)生成权重偏好
在每次评价后,进行预处理,提取〈feature,opinion_value〉.然后推导出对应评价者的权重特征偏好.为此,本文基于概率回归模型(PRM)学习单个评价者的权重,生成评价者级权重偏好.
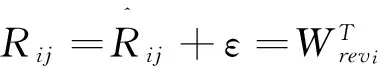
4 基于K-最近邻算法生成推荐
假设当前买家偏好为Wu,则买家评价相似度由以下公式计算得到:

式中wfl(u)为基于特征的当前买家权重偏好fl,wfl(revi)为第i个评价者.然后检索k个与当前买家具有较高相似评分的评价者,并据此定位得到商品,形成商品池(product pool).商品池中的商品pj用预测评分来表示商品对当前买家的吸引度:
PredictionScore(u,pj)=∑revi∈Ksim(Wu,Wrevi)×Rij[∑revi∈Ksim(Wu,Wrevi)]-1,
式中K表示一组(k个)相似的评价者,Rij是评价者revi对商品的评价(如果没有评价者则评价为0).具有最高预测评分的前N个商品,作为推荐商品反馈给买家.
5 实验及分析
5.1实验设置及数据集
实验中从一个电子商务网站上获取笔记本电脑网上销售数据集.对于每个文本,对评价者的评价分配等级为1到5星.首先清理数据集:(1)移除少于4个特征的评价(包括那些太短或没有意义的字符);(2)移除少于10个评价的商品.清理过程确保每个评价都包含相当量的信息,每个商品都有充分的评价用于分析.该步骤之后,笔记本电脑数据集有155台笔记本电脑,一共6 024个评价.其中,每个评价者在商品上只给出一条评价.数据集的详细信息见表2.
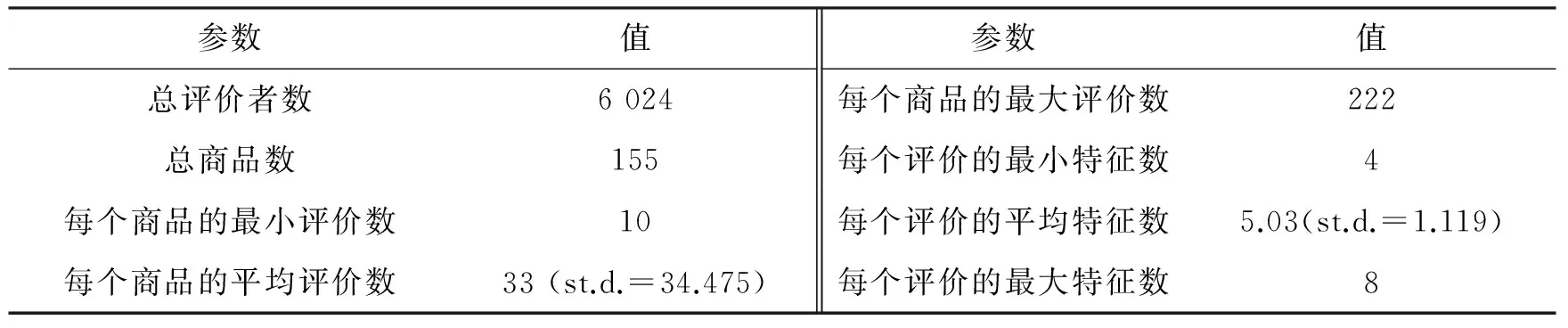
表2 笔记本电脑测试数据集参数Tab.2 The parameters of notebook computer test data set
5.2性能指标
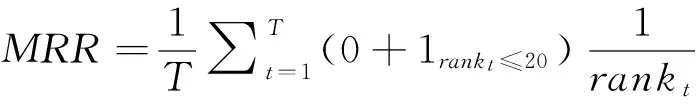
5.3结果分析
表3和表4分别列出了在不同推荐列表长度情况下(分别为5、10和20个),笔记本数据集上各种方案的命中率和MRR的比较结果.可以看出,随着特征数量的增加,各种方案的性能有所提高.从命中率指标上看,本文方案性能优于其他两种方案,当N=20时,本文方案所生成的推荐列表的命中率为83.1%,分别比[1]和[2]方案提高了37.6%和7.6%.这是因为文献[4]方案只是简单地使用了评价匹配值实现商品排名,与其他方法差距较大.[2]纯粹依靠评价者提供的评价信息进行偏好提取,这样在稀疏评价的情况下,不可避免地存在偏见和过拟合现象,所以影响了推荐精确度.然而,本文方案基于评价者的权重偏好,利用客户和评价者组之间的相似性预测买家未声明的偏好,所以能够准确地给出推荐.
同样,MRR的实验结果也表明了本文方案的有效性,不仅能够提高推荐表中用户选择目标命中的数量,还能提高选择目标在列表中排名位置,使其能够更好地呈现在用户面前.
本文提出一种基于概率回归模型和K-最近邻的电子商务个性化推荐方案.通过对评价数据进行预处理,提取出每个评价者的特征-意见对.利用概率回归模型(PRM)生成了评价者的权重偏好.利用K-最近邻(K-NN)算法,寻找出与当前客户具有相似权重偏好的评价者组,定位该评价者组相关的商品,从而生成推荐列表.在一个笔记本电脑网上销售数据集上进行实验,结果表明,本文方案所产生的推荐列表中的商品符合用户需求的准确率达到了83%.
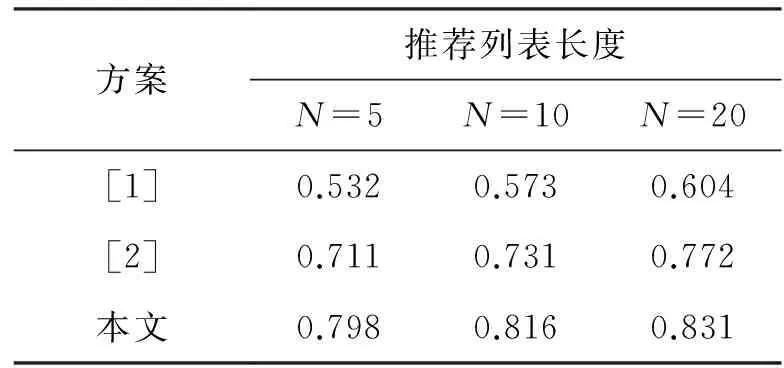
表3 不同推荐列表长度下,实验数据集中命中率比较Tab.3 The accuracy in experiment data set under different suggestion list length
表4不同推荐列表长度下,实验数据集中MRR比较
Tab.4The MRR in experiment data set under different suggestion list length
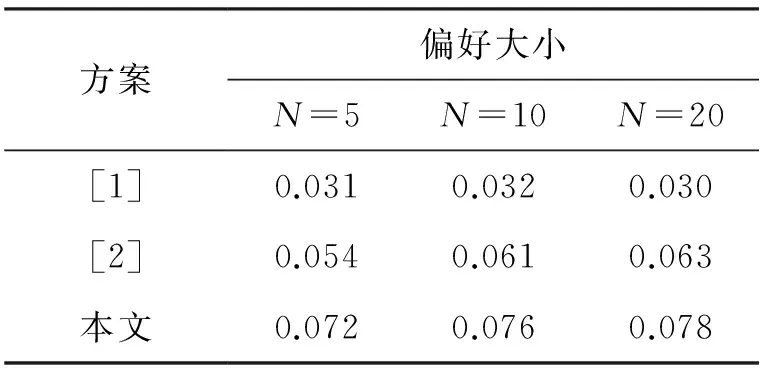
方案偏好大小N=5N=10N=20[1]0.0310.0320.030[2]0.0540.0610.063本文0.0720.0760.078
[1]HUANG S L. Designing utility-based recommender systems for e-commerce: Evaluation of preference-elicitation methods[J]. Electronic Commerce Research & Applications, 2011, 10(4):398-407.
[2]KROHN-GRIMBERGHE A, DRUMOND L, FREUDENTHALER C, et al. Multi-relational matrix factorization using bayesian personalized ranking for social network data.[J]. User Behavior, 2012, 26(8):173-182.
[3]PU Q, LBATH A, HE D. Location based recommendation for mobile users using language model and skyline query[J]. International Journal of Information Technology & Computer Scien, 2012, 4(10):19-28.
[4]GRAFAREND D I E W, AWANGE D I J L. The second problem of probabilistic regression[J]. Linear & Nonlinear Models, 2012, 25(6):183-261.
[5]硕良勋, 柴变芳, 张新东. 基于改进最近邻的协同过滤推荐算法[J]. 计算机工程与应用, 2015, 51(5):137-141.
[6]LI L, XIAO H, XU G. Finding related micro-blogs based on word net[J]. Lecture Notes in Computer Science, 2012, 32(4):115-122.
责任编辑:龙顺潮
Personalized Recommendation Scheme Based on Probabilistic Regression Mode and K-Nearest Neighbor in E-Commerce
WANGWei1,XUPing-ping2*,WANGHua-jun1,LIYuan-song3
(1.School of Engineering, Taihu University of Wuxi, Wuxi 214064;2.School of Information Science and Engineering, Southeast University, Nanjing 211189;3.School of Computer Science, Sichuan University of Science & Engineering, Zigong 643000 China)
For the issues that the personalized recommendation in e-commerce, a personalized recommendation scheme based on probabilistic regression mode and K-nearest neighbor in e-commerce is proposed.Experimental results show that the proposed scheme can be accurate for customers to recommend the required goods.
e-commerce; personalized recommendation; probabilistic regression mode; K-nearest neighbor
2015-10-05
江苏省高校自然科学研究项目(14KJB520036)
徐平平(1957-),女,江苏 南京人,博士,教授,博士生导师. E-mail:wangweithu@126.com
TP391
A
1000-5900(2016)01-0097-04
