人工神经网络在聚类分析中的运用
2016-08-23李赛邹丽华
李赛++邹丽华

摘 要:本文采用无导师监督的SOM网络,对全国31个省市自治区的人民生活质量进行了综合评价,在没有先验信息的条件下,不采用人为主观赋予各指标权重的办法,转而运用自组织神经网络自组织竞争学习的网络方法来进行赋值、计算和评价,消除了主观确定各指标的权重的主观性,得到的结果较为符合各省市自治区的实际结果。
关键词:聚类分析;K-Means聚类;系统聚类;自组织神经网络;人民生活质量
一、引言(研究现状)
自改革开放以来,我国生产力极大发展,生活水平总体上得到了提高。但是,地区间的发展不平衡始终存在,而且差距越来越大,不同地区人民的生活水平也存在显著的差异。据此,我们利用自组织人工神经网络方法对全国31个省市自治区的人民生活水平质量进行分析评价。
二、指标选取与预处理
1.指标选取
遵循合理性、全面性、可操作性、可比性的原则,从以下5个层面共11个二级指标构建了人民生活质量综合评价指标体系(如下表所示)。
人民生活质量综合评价指标体系
2.指标预处理
(1)正向指标是指标数据越大,则评价也高,如人均可支配收入,人均公园等。
正向指标的处理规则如下(1):
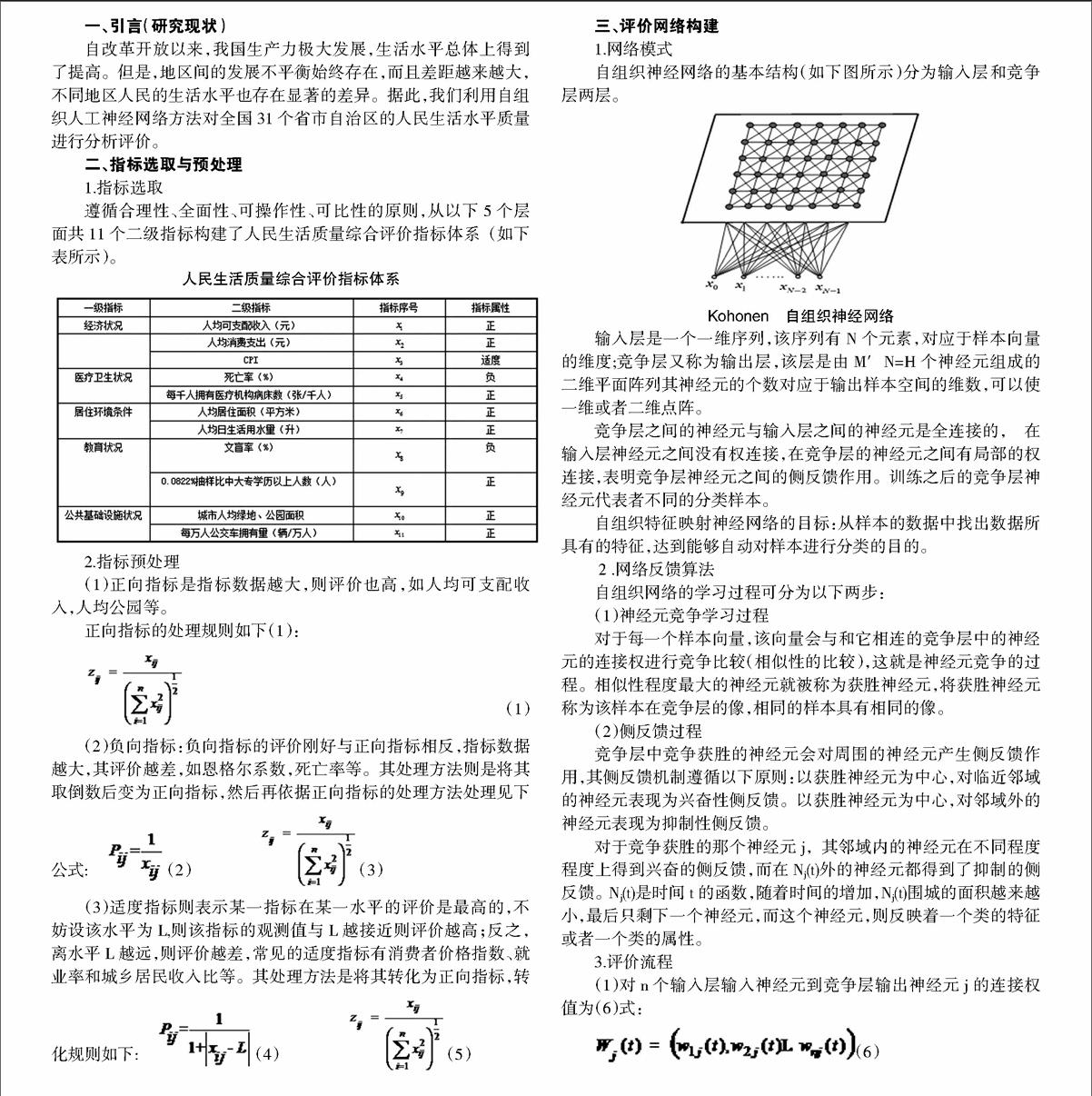
Kohonen 自组织神经网络
输入层是一个一维序列,该序列有N个元素,对应于样本向量的维度;竞争层又称为输出层,该层是由M′N=H个神经元组成的二维平面阵列其神经元的个数对应于输出样本空间的维数,可以使一维或者二维点阵。
竞争层之间的神经元与输入层之间的神经元是全连接的, 在输入层神经元之间没有权连接,在竞争层的神经元之间有局部的权连接,表明竞争层神经元之间的侧反馈作用。训练之后的竞争层神经元代表者不同的分类样本。
自组织特征映射神经网络的目标:从样本的数据中找出数据所具有的特征,达到能够自动对样本进行分类的目的。
2.网络反馈算法
自组织网络的学习过程可分为以下两步:
(1)神经元竞争学习过程
对于每一个样本向量,该向量会与和它相连的竞争层中的神经元的连接权进行竞争比较(相似性的比较),这就是神经元竞争的过程。相似性程度最大的神经元就被称为获胜神经元,将获胜神经元称为该样本在竞争层的像,相同的样本具有相同的像。
(2)侧反馈过程
竞争层中竞争获胜的神经元会对周围的神经元产生侧反馈作用,其侧反馈机制遵循以下原则:以获胜神经元为中心,对临近邻域的神经元表现为兴奋性侧反馈。以获胜神经元为中心,对邻域外的神经元表现为抑制性侧反馈。
对于竞争获胜的那个神经元j,其邻域内的神经元在不同程度程度上得到兴奋的侧反馈,而在Nj(t)外的神经元都得到了抑制的侧反馈。Nj(t)是时间t的函数,随着时间的增加,Nj(t)围城的面积越来越小,最后只剩下一个神经元,而这个神经元,则反映着一个类的特征或者一个类的属性。
3.评价流程
(1)对n个输入层输入神经元到竞争层输出神经元j的连接权值为(6)式:
(2)获胜邻域j*(t),设定为邻域函数(h)t,表示第i个神经元与获胜神经元之间的距离函数。S2会随着学习的进行而减小,从而邻域在学习初期很宽,随着学习的进行会变窄。因此,权值随着学习的进行从较大幅度调整向微小幅度调整变化。邻域函数产生了有效的映射作用。其中邻域函数的表达式如下(8)式所示
分析结果如下:
第一类:北京,天津,辽宁,上海,江苏,浙江,广东
第二类:福建,山东,湖北,重庆,陕西
第三类:河北,山西,内蒙古,吉林,黑龙江,江西,湖南
第四类:安徽,河南,广西,海南,四川,贵州,云南,西藏,甘肃,青海,宁夏,新疆基于分类结果,得知第一类中的各地区的人民生活质量最高,主要分布于东部沿海。这些地区共同点是:工业和经济文化实力雄厚,基础设施建设齐全,医疗卫生事业、教育水平高度发达。
对于第二类,他们的生活质量相对于第一类次之,但比第三、四类的评价则较优。福建是东南部沿海的经济大省,山东、湖北、陕西具有较强的工业实力和较高的教育水平;重庆市内地唯一的直辖市,境内有长江干道,这五省的共同他点在于其工业实力较强,教育水平发达,基础设施齐全。
第三类中的诸多省份均是我国农业和采矿业大省,相比前两类,他们则是缺少雄厚的工业基础,但有良好的气候条件社会环境和丰富的自然资源。
第四类,造成这些地区的人民生活质量较差的原因多且复杂。就安徽、河南而言,自古以来河南是华夏文化的中心,安徽是有名的产量大省,是什么因素限制了它们生活水平的发展还值得考究。广西,海南,贵州,云南,西藏,等的一个共性在于自然条件的劣势。广西,海南自古以来是官员贬庶之地;贵州、则云南困于云贵高原,交通向来闭塞;西藏、青海更是由于自然环境恶劣而在各方面的发展较为欠缺;宁夏、甘肃、新疆则是身居内地,生活用水奇缺,种植业较为薄弱,多以畜牧为主,自古有甘凉不毛之地之说。四川则居于天府之国,但人口基数庞大且发展不平衡,所以人民生活质量也不是很高。
总体而言,此分类结果与实际基本吻合;但受变量体系等因素的干扰,部分地区仍然存在疑问,具体原因还值得进一步探讨。
五、模型评价
网络结构简单、自组织自学习能力强和学习速度快是自组织网络所具有的优点,在样本识别上具有很强的优势。此外,它将输出表现成一维或者二维的概率密度分布,因此运用越来越来广泛。对于实际中复杂和高维度的数据,该网络具有较好的适应性和识别性。它本属于一种无监督的自主竞争学习的神经网络,网络根据样本的特征进行自组织学习竞争、聚类,将高维数据映射到低维度的二维平面,能够较好地在保持数据拓扑结构不变的情况下进行数据压缩和识别。其聚类的客观性,更适用于于处理海量未知数据问题。以此同时,由于模型的可视化,在人们开发和构建新型网络变得更加简洁,易于被人们接受。
自组织神经网络的二维拓扑映射图的可视性很强,通过映射图,可以直接观察到数据的特征。同时,清晰的了解其分类情况。但是,传统自组织特征映射神经网络采用了向量内积、欧氏距离函数等确定输入样本最为相似的连接权向量,这就要求数据必须是连续的,若数据是离散的或者数据为顺序型或者属性型,则就不能胜任聚类这项任务。
参考文献:
[1]张建萍,刘希玉.基于聚类分析的K-means算法研究及应用[J].计算机应用研究,20075(5):166-168.
[2]么枕生.用于数值分类的聚类分析[J].海洋湖沼通报,1994(2):2-12.
[3]刘慧,冯乃琴,南书坡,王伟.基于粗糙集理论和SOFM神经网络的聚类方法[J].计算机与应用软件,200926(8):228-230.
[4]郭伟业,赵晓丹,庞英智,奇志.数据挖掘中SOM神经网络的聚类方法研究[J].情报科学,2009,7(6):874-876.
[5]王家伟,周浩宇,同庆,田宏杰,贾花萍.基于MATLAB的自组织特征映射网络的实际应用[J].电子设计工程,2013,21(6):47-48.
[6]郭丽华.人工神经网络基础[M].哈尔滨:哈尔滨工程大学出版社,2008.
[7]王国梁,何晓群.多变量经济数据统计分析[M].西安:西安陕西科学技术出版社,1993.
[8]宋浩远.基于模型的聚类方法研究[J].重庆科技学院学报,2008(7):71-71.
[9]何晓群.多元统计分析[M].3版.北京:北京中国人名大学出版社,2012.
[10]韩力群.人工神经网络理论、设计及运用[M].北京:北京化学工业出版社,2007.
作者简介:李赛(1990.05- ),男,汉族,河北省石家庄市,研究
生硕士,云南大学
