国外社交媒体影响力研究述评——进展与启示
2016-08-23刘济群
刘济群
(北京大学信息管理系,北京 100871)
·综述 · 述评·
国外社交媒体影响力研究述评
——进展与启示
刘济群
(北京大学信息管理系,北京 100871)
大数据环境下信息与通讯技术的发展,使越来越多的用户进入了社交媒介建构的虚拟网络空间之中,社交媒体的影响力也在不断增强。本文从信息内容和网络结构两个层面综述了国外计算机科学等相关领域的社交媒体研究,指出了基于内容的主题提取,信息传播的流行度分析,社交媒体中的网络结构分析以及社区发掘等重要的研究领域;具体阐释了一部分具有基础性或典型性的模型、算法、以及相应的研究成果比较,同时也提出了未来的研究领域和研究方法的可能发展方向。最后,本文讨论了国外社交媒体影响力研究对基于国内语境之研究的启示。
社交媒体;社会网络;影响力分析;LDA模型;社区发掘
社交媒体是帮助用户在虚拟的网络空间中发布与获取信息、建立人际联系、形成虚拟社区的重要工具。 随着信息与通讯技术(Information and Communication Technology,ICT)的不断发展,尤其是移动互联设备的不断普及,社交媒体的影响力日益扩大,并逐渐成长为用户创造内容、分享信息与搜寻信息的主要平台。在基本的社交网络形成与维护方面,大多数社交媒体平台在维护了已有社交关系的同时,也会为陌生人建立虚拟空间中的弱联系或形成活动小组创造机会。有些社交媒体可以吸引很宽泛的范围内不同类型的用户(例如Facebook,Twitter等),但另外一些会基于语言、种族、性别、宗教信仰以及国籍等方面的相似性帮助人们建立联系。除此之外,这些社交媒体的不同之处还体现在他们可以在多大程度上吸纳新的信息与通讯工具(如WeChat逐步支持文字、语音、视频分享以及即时通话等信息与通讯功能),主要有:与手机的联通性,图片与视频的分享等。
在互联网技术较为先进,市场经济十分活跃的美国,基于公司注册或商业交流的社交媒体工具在上世纪末即开始出现。进入21世纪后,世界范围内的社交媒体在工具种类、用户范围、信息功能、交互方式等方面都经历了较大幅度的飞跃,如表1所示。在此背景下,面向社交媒体以及基于社交媒体的社会网络分析也吸引了学术界的注意,社会学、情报学、计算机科学、数学等不同研究领域都有学者投入到了社交媒体的研究之中。就图书情报与计算机科学领域的学者而言,基于社交网络结构的指标分析(如小世界网络和核心边缘结构分析[1-2],社交媒体中的虚拟社区识别[3-4](The detection of virtual community,等)和基于信息内容的主题挖掘、观点挖掘以及情感分析[5](Sentiment analysis)往往是关注的重点,也是目前在领域内拓展社交媒体研究的主要方向。

表1 国内外主要社交媒体的产生时间
社交媒体的影响力源自于其基本功能在用户群或社会网络(现实的或虚拟的)之中的发散、传递与延伸。因此,面向社交媒体的影响力研究应该从对社交媒体的构成以及基本功能的定义展开。在本文中,笔者借鉴了Boyd和Ellison的定义[6],并结合当前社交媒体发展的平台性,基于移动互联的泛在性,以及多项信息与通讯技术的整合性等特点对该定义进行了修正与补充。社交媒体站点是一种基于网络空间的服务平台,它可以支持用户执行以下功能:
在社交媒体的情境中,这一虚拟形象往往是用户在现实生活中之角色的映射。
如上所述,社交媒体在为用户提供信息服务时,既为用户构造了包含信息生产与信息分享过程的个人信息世界,也在社交网络与弱关系的形成中扮演了重要角色。对应社交媒体在用户特征、社交网络以及信息传播方面的影响,面向社交媒体的影响力分析往往从以下3个方面展开:
由此可见,在计算机与图书情报研究领域,面向社交媒体影响力的研究与社交媒体本身的特征相关,研究的主题也围绕着社交媒体情境下的社会网络(偏向于结构分析)与信息生产传播(偏向于内容分析)两个核心问题展开。
1 社交媒体中的信息生产与传播
服务于信息的生产与传播是媒体的根本功能所在。基于互联网技术的社交媒体与传统的广播、报纸、电视等离散的、节点式的媒体不同,它利用网络环境实现了媒体的情境化与平台化,从而增进了媒体在信息传播方面的作用,提高了流动在网络中的信息的影响力。另外,社交媒体的开放性和网络本身的民主性,也使得用户在接收信息的同时,成为了信息生产与传播的主导者,社交媒体中意见领袖的生成与波动则显得更加频繁。因此,基于内容要素的信息生产与传播分析,是研究社交媒体作用,发掘社交媒体潜在影响力的关键切入点之一。
1.1 基于内容的主题提取:LDA模型及其拓展
近年来,主题建模(Topic Modeling)方法在不同领域的文本挖掘研究中都受到了学者的关注。其中,LDA主题提取模型(Latent Dirichlet Allocation)比较契合文档形成的实际过程,较好地描述了文档、主题与词之间的关系,故而逐渐成为主题建模的标准化方法。在社会网络与社交媒体的影响力分析中,大量的内容分析与主题提取模型都是基于LDA模型延伸而来。例如,McCallum[7]基于LDA的模型框架提出了一个新的内容分析模型,用于在社交媒介中发掘小组并同时提取内容主题。Zhang[8]也基于LDA的主题分析功能,将LDA模型引入了虚拟社区识别与检测的研究领域。Qian[9]等人结合了不同来源的多模态数据,利用监督式(Supervised)的LDA模型研究了社交媒体中的事件分类问题。其他相似的扩展(Extension)模型也在社交媒体的研究领域不断出现。例如,基于LDA模型的标签推荐[10],事件分类与提取[11-12],挖掘生成中(Emerging)的内容主题[13]等。
LDA模型是一种面向文本语料库集合的文档生成概率模型,它同时也是一个三层结构的贝叶斯模型。在这个模型,语料库中的每个文档都被建模为基于一个特定主题集合的有限混合(Finite mixture)[14]。LDA模型作为一种无监督的机器学习技术,常被用于大量文档集合中的主题信息提取过程。LDA模型运用了词语集合的方法,将每个文档都建构为一个基于词语计数的向量。每个文档都是基于一系列主题的概率分布,而每个主题也是基于一系列词的概率分布。LDA模型定义的文档生成过程包含如下3个主要步骤:
基于LDA的思路可以发现,一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到的。因此,在一篇文档的生成过程中,文档集合里的每个词语出现的概率为:
基于词语和主题的概率分布思路使得LDA模型的分析更加全面和平滑,因而也更优于其他类似的模型(例如Unigram模型和Mixture of unigram模型等)[14]。LDA模型中的联合概率如下所示:
α和β表示语料级别的参数,也就是每个文档都一样,因此生成过程只采样一次。θ是文档级别的变量,每个文档对应一个θ,也就是每个文档产生各个主题z的概率是不同的,所有生成每个文档采样一次θ。z和w都是单词级别变量,z由θ生成,w由z和β共同生成,一个单词w对应一个主题z。通过上面对LDA生成模型的讨论,可以知道LDA模型主要是从给定的输入语料中学习训练两个控制参数α和β,学习出了这两个控制参数就确定了模型,便可以用来生成文档[13-14]。其中α和β分别对应以下各个信息:
在LDA模型的迭代中,把w作为观察变量,θ和z作为隐藏变量,就可以通过EM算法学习出α和β,求解过程中遇到后验概率p(θ,z|w)则无法直接求解,需要找一个似然函数下界来近似求解,LDA模型使用了基于分解(Factorization)假设的变分法(Variational Inference)进行计算,用到了EM算法[14]。每次E-step输入α和β,计算似然函数,M-step最大化这个似然函数,算出α和β,不断迭代直到收敛。综上所述,LDA文档生成模型的迭代运算过程如图1所示。
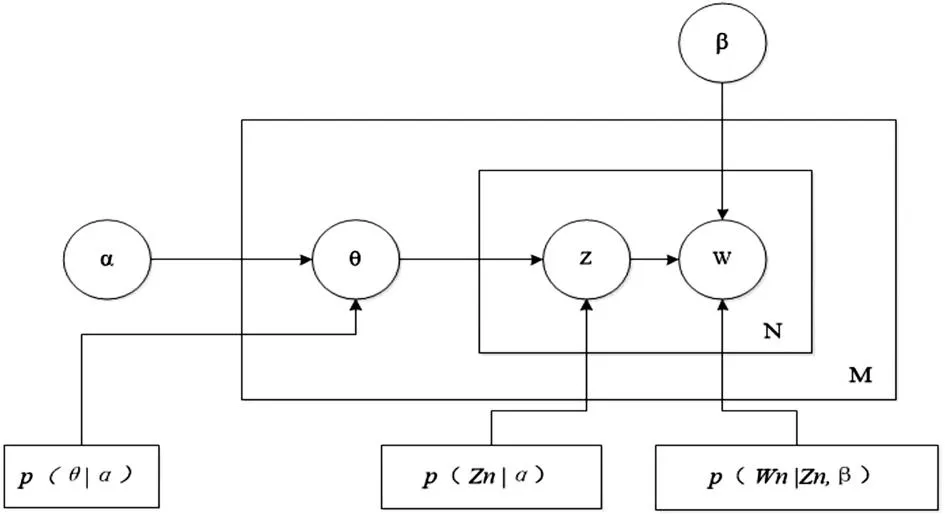
图1 LDA模型示意图
与一般性的文档主题建模相比,社交媒体中的内容影响力应基于短文本建模,尤其是在微博(Microblogging)环境下进行分析。LDA主题提取模型在社交媒体的研究情境中得到了广泛的应用,一些学者根据社交媒体中文本内容,发布者等多方面特征,对原有的LDA模型进行了进一步的拓展。作者主题模型(Author-Topic Model,AT)就是其中一个应用较为广泛的LDA扩展模型。Rosen-Zvi等在作者与文档信息提取中首次提出了初步的AT模型[15],并在基于文本语料库的机器学习研究中拓展了该模型[16]。在AT模型中,文档中的每个词w都与两个潜在的变量相联系:信息发布者x和主题z。与LDA模型相似,社交媒体中的每个信息发布者都对应着一个包含多项特征的分布,这个分布被标记为θ,它是基于主题集合T产生的。相应地,每个主题也是基于词语的多项分布而形成的。在Hong与Davison[17]面向Twitter的主题建模研究中,与LDA模型中的文档生成过程类似,AT模型中的生成阶段如下所示:
如上所述,AT模型中的主题生成规则与LDA模型相似。不同的是,AT模型增加了作者集合的维度,同时也没有应用基于概率的混合主题思路(Mixture of topic)。在社交媒体影响力这一研究领域内,Hong与Davison应用主题建模的技术所研究的问题是:①基于主题提取的内容,预测Twitter中的流行信息与内容;②将Twitter用户和相应信息放入主题分类的范畴中去。在备用的数据集合中,研究者抽取了两周的Twitter信息与用户数据,并基于Twitter中已有的Twitter Suggestion建构了用户分类。
在评估指标的选择与构建方面,基于数据和模型的评估则因问题而异:对于第一个问题,研究者运用了准确率(Precision),召回率(Recall),以及F值(F-Measure)作为评估指标。这些指标其他基于社交媒体内容的主题提取(如事件提取与事件分类问题)也有较为广泛的应用[12]。在主题建模方面,为了判别不同轮运行中训练和学习出的主题是否契合,一般引入Jensen-Shannon差异度(divergence)公式进行计算分析。公式如下所示:

在公式中,M代表不同类型词的数量,φna表示词n在类别a中的概率。由此可见,当JS相似度为0时,则说明两个分布是完全不一致的。Jensen-Shannon差异度值是基于每个分布的KL差异度平均值而确定的。这种引入差异度分析机器学习中不同分布相似度的做法在其他社交媒体内容影响力的研究中也有应用[18]。从JS差异度分析中可以发现,同一个主题下AT模型在运行的过程中学习到的词的出现概率是各不相同,不断变化的。但一部分词在Twitter测试集中出现的概率排名一直很高。在研究中,Kendall一般被用于概率排名之间的差异度。对于相同的m个词,Kendall的定义入下所示:
在上述公式中,P代表两个排名列表中排名一致的词数量,Q代表的则是排名不一致的词数量。由此可见,τ的值域是(-1,1)。1代表的是两个排名列表中相同词的排名是完全一致的。-1则代表两个排名是完全不一致的。一般地,当τ为0时,则表示有50%的词语排名是一致的。在Hong与Davison[17]的研究中,MSG,USER以及AT模型在同一个数据集中运行,其Kendall的平均值随着主题数量增加而变化的具体情况如图2所示。
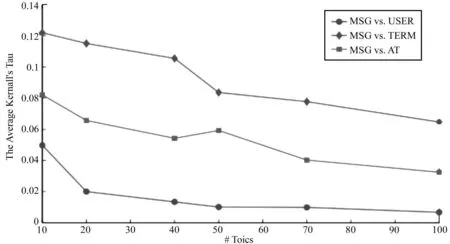
图2 Kendall的平均值
由此可见,纵轴是不同模型之间的比较下所形成的Kendallτ平均值,横轴是主题的数量。随着主题数量的不断增加,所有模型对比的Kendallτ值都在持续下降,进而说明了主题数量增加与词语数量的增多增加了概率排名列表之间的不一致情况。Kumar等人[19]研究了Twitter等社交媒体中能快速获取信息的关键人及其识别问题。在他们的研究中,词语(Term)的出现概率与主题(Topic)之间在Kendall方面的相关关系也得到了验证。
在社交媒体的文本挖掘研究中,AT模型并不是惟一,也不是目前最优的LDA模型拓展。Hong和Davison将AT模型与USER模型以及传统的TF-IDF等模型作了比较,显示出了AT模型在短文本主题提取方面的较高准确度。但进一步地,Zhao等[20]学者在对Twitter与其他传统社交媒体的比较分析中引入了Twitter-LDA模型,并将其结果与传统的标准LDA模型,AT模型分别作了比较。研究者抽取了330个主题类型以及其中的Twitter信息(Tweets)作为算法的测试集,发现Twitter-LDA模型的表现明显优于其他两个模型。其准确度结果如表2所示。

表2 Twitter-LDA,AT模型以及标准LDA模型之间的比较
在基于Twitter中短文本内容的主题分析中,除上述LDA类的关键词提取与主题发掘方法之外,Topical PageRank通常是使用较为广泛的方法之一。该方法基于每个不同的主题分别运行基于主题的PageRank算法(Topic-biased PageRank),并将与目标主题高度相关的关键词提取出来。通常地,特定主题PageRank(Topic-specific PageRank)的得分可以根据以下公式计算:
在上述公式中,Rt(W)是指在主题t中词w获得的PageRank得分数,e(Wj,Wi)是有向边(Wj→Wi)的权重,Pt(W)是词W的随机跳转概率(Random jumping probability)。在给定的主题t中,就所有的关键词w而言,必须满足Pt(W)的总和为1。上述初始模型利用社会网络分析中PageRank的算法构建了主题内词间的共现关系,为主题相关的关键词提取提供了简洁有效的方法。然而,在不同的主题关系下,同样的词共现代表的含义是不同的。例如,juice和apple可能经常共同出现,但若在电子产品的主题下,二者之间的共现关系就不能作为关键词提取的依据。由此可见,Topic-specifc PageRank算法还应该加入主题这一情境性因素[21]。特定边的权重不应该是对所有主题都通用的定值,而是一个关于t的函数。基于这种改进思路,可得主题情境下的PageRank关键词提取模型(Topic context sensitive PageRank method)如下:
值得注意的是,未经拓展的标准LDA模型在直接应用于社交媒体信息内容分析时的效果往往较差,原因在于社交媒体中的文本信息过短,且通常以单主题信息为主,故而不适合标准LDA模型的类别提取与训练过程。因此,在基于社交媒体中短文本内容主题的提取与分析中,LDA模型依然是该研究领域进行模型拓展的基础,其他的一系列研究模型,如AT模型,Twitter-LDA,USER等模型,都是在LDA核心思想的基础上,根据社交媒体的各项内容特征(文本长度,发布者特征,发布数量,主题数量等)通过增加变量,调整部分算法细节等方式进行拓展的。
1.2 社交媒体情境下的信息不平等:内容流行度分析
以新闻信息为代表的各类信息的流行度,是近年来面向社交媒体影响力分析的一个重要研究领域。社交媒体中信息的流行度受到内容,发布者影响力,发布时间等多项因素的影响,网络之外的情境因素,例如地理,语言等也很难被完全考虑到分析之内[22]。与此同时,社交媒体中传播的成功率与信息的流行度也不是均匀分布的,而多半是遵循幂律分布的:一小部分用户占据了社交媒体中信息活动的主体,他们发布和关注的信息往往被赋予权威性,受到广泛的关注,阅读与分享。另一方面,大部分普通用户发布的信息则相对单一,受到的关注也比较少,其所生产与传播之信息的传播范围以及影响力也因而十分有限[23]。以Flickr为例,在40亿图片中只有很小一部分图片被阅览超过千次,绝大部分图片都很少受到用户的点击与阅览。
基于内容流行度分析问题的复杂度,其研究者提出的算法和变量模型就相对分散,很少基于一个类似于LDA的基础模型发展出很多相似的但跨越多个研究问题拓展模型。在社交媒体研究领域诸多学者参考了已有的模型与指标,以试图预测特定信息内容在Twitter,Facebook等覆盖面较广的社交网络中会获得何种水平的流行度。Kim等[24]学者构建了包含爆炸性,热度,温和等不同程度的博客文章热度量表(Temperature scale),并抓取了文章点击率数据,以饱和状态的点击率(Hit count of saturated point)预测博客文章未来的流行度。Tatar[25]也认同了用户参与的记录在预测信息流行度中的重要性。与Kim的研究不同的是,Tatar关注了在线新闻流行度与相应较短时间段内用户评论之间的联系。基于为期4年的在线新闻与相关评论数据集,Tatar发展出了一个简单线性模型,并从准确度,复杂度等方面与其他类似模型作了比较。
由此可见,在基于文本内容的流行度分析方面,面向社交媒体中新闻信息的流行度预测是学者们较多关注的领域。除常见的twitter,Facebook,Flickr等社交媒体意外,Lerman和Togg[23]以网上新闻类社交媒体Digg为目标对象,研究了新闻受关注度随发布时间的变化走势以及影响因素。在Digg中,用户可以对自己感兴趣的新闻话题进行投票,以推出自己认可的热点新闻。在基于2 159项不同新闻事件及其投票状况之分析的基础上,Lerman首先提出了事件投票的增速(导数)模型和投票者之为投票追随者(fans)的减速模型,后者指的是投票者的fans还未浏览被投票的新闻,这种情况的不断消减也可以说明特定新闻流行度的上升。其中,投票增速模型如下所示。
Vf=Vfpage(p(t)θ(Nvote(t)-h)
Vu=CVfpage(q(t)θ(h-Nvote(t))θ(24hr-t)
Vfriends=ws(t)
在模型中,r衡量了新闻事件的兴趣度,或用户投票给该新闻的可能性。Vf(t),Vu(t)以及Vfriends(t)3个变量分别代表用户通过前一个网页,后一个网页或社交网络中的好友而得之该新闻。h表示的是推广新闻所需要的基本投票数。W指的是投票者的fans进入并关注被投票新闻的速率。公式θ(Nvote(t)-h)表示:当一个新闻的投票数少于基本要求h时,新闻只是在下一页可见;当超过h时,该新闻在前一个网页即可见。由此可见,用户了解新闻的信息渠道是决定该新闻是否被投票,以及其最终流行度为多少的决定性因素。流行度中的幂律分布与马太效应也就因此而形成。
另一方面,在社交媒体中,单个用户对信息的关注也会影响其好友的关注。投票者未关注该新闻的fans数量下降模型就是针对该种现象提出的。如果一个用户的好友较多,或其处在社交网络相对中心的位置,其投票和分享新闻对该新闻的流行度就有较强的提升作用。该模型的数学化表达如下所示:
进一步地,Lerman得出了新闻事件流行度(这里以被投票数代表)随时间的累积变化趋势如图3所示,以及事件的数量流行度分布情况如图4所示。在图3中,Lerman摘取了被投票较多,流行度较高的story2和累积流行度相对较低的story2作为样本案例进行了对比分析。在图4中,新闻事件的投票数与相应的事件频率形成了近似于幂律分布的状态。Gomez等人[26]在对Slashdot上社交网络与用户评论的分析中也发现了这种文本内容流行度在时间,空间以及内容上不均衡分布的现象。

图3 两项新闻信息的投票累积增长度

图4 新闻流行度的数量分布
在社交媒体中,除了文本信息与图片信息的生产与传播之外,视频信息(如YouTube)也是用户分享信息以及社交媒体产生影响力的主要形式之一。在视频的流行度分析方面,Cha等学者[27]在基于YouTube视频集合的研究中发现了类似于文本内容流行度的长尾分布现象(Long-tail Distribution):极少部分的视频可以吸引百万以上的浏览量,而绝大部分视频的浏览次数不超过50次。除了上述的整体特征以外,基于视频主题和地理地区分布下的视频流行度分析也在社交媒体的研究领域中受到了广泛关注。在面向地理地区变量的视频流行度分析中,浏览焦点(View focus)和浏览熵值(View entropy)是较为常用的两个衡量指标[28]。其他的相关指标有峰值强度(Peak intensity)以及单调性(uniformity)[29]等等。对于视频i的浏览焦点值Fi的计算公式如下所示:

浏览焦点代表的是视频i所获得的浏览时间与在单个地区的整个生命周期相比的最大值。另一方面,面向特定视频i的浏览熵值Hi的计算公式如下所示:
浏览熵值衡量是特定视频信息在不同地区的流行度分布状况。因此,较高的浏览熵值说明该视频关于地区的流行度分布较为平均,视频浏览的分布范围很广;熵值较低则说明视频浏览更集中于少量的地区。基于上述一系列视频流行度分析指标的研究发现,虽然社交媒体中的网络视频服务在本质上是面向全球的,但在线视频的流行度却受到了实际地理地区的显著限制,这与不同地区的用户在兴趣,文化背景以及浏览习惯等各方面的不同有关。因此,在未来的研究中,视频的流行度以及由此衍生出的社交媒体影响力分析还有很多地理性特征值得进一步挖掘。
2 社交媒介影响力的结构性分析:社交网络与社区发掘
除了信息内容本身的生成,分享以及传播以外,社交媒介中形成的社会网络与社区(Social networks and communities)也构成了社交媒介影响力传输的重要因素,即区别于主题或内容本身的结构性因素。对于社会网络的分析在学术层面和实际应用层面均有重要价值:社交媒介中人与人在虚拟世界相互联系并构成网络,对这种网络的分析可以使虚拟世界中模糊不清的信息传播和社会过程更为清晰,网络中不同内容和信息发布者的重要性都可以被量化评价。在社会网络的研究情境下,社交媒体系统正处于一个拐点。一方面,服务于信息生产的用户信息发布工具趋于成熟,但基于此的网络分析工具还相对滞后[30]。面向社交媒介的社会网络分析一般可以回答如下几个类型的问题[30-31]:
在面向社交媒体的网络分析中,由于具体的问题有差异,不同的学者在具体指标与方法上都会有分歧。但在社会网络分析方面,Perer和Shneiderman[32]提出了指标清单往往是作为分析起点的基础性研究指标:
上述指标均为社会网络分析的初始指标,也是更复杂网络分析的基础和起点。作为基础性的网络分析工具,以上的初始指标是为了得到关于社交媒介中网络结构的宏观把握。对网络进一步的分析,则往往需要涉及边的性质分析,以及社会网络中的虚拟社区发掘等问题。
在社交网络中边的性质分析方面,积极(Positive)关系和消极(Negative)关系的产生与互动往往是研究关注的重点。当涉及社交媒介中交互关系的讨论时,在积极关系(如关注,好友等)之外添加对消极关系的关注,可以是研究本身更贴近于社交媒介中虚拟网络的实际情况:基于社交媒介发展起来的社会网络通常包含着大量的积极和消极关系,并使它们同时存在于一个单一的系统中。若要更好地理解这些关系的作用和互动,就必须在边的方向和权重之外,增加对边的性质的考虑。Kunegis等学者[33]基于Slatshot中用户关系的语料库分析,挖掘了用户之间追随(tag)关系下的隐含的积极关系与消极关系。进一步地,Leskovec等学者[34]研究了Epinion,Slashdot以及Wikipedia中基于边性质的标记网络(Signed network),并探讨了上述不同社交媒体中稳定三边关系的数量和分布情况,以研究特定社交媒体情境下基于3个用户为一组的交互关系是否显著地偏向于稳定或不稳定。研究结果如表3所示。

表3 平衡与非平衡无向三边关系数
三边关系的稳定结构是分析复杂网络稳定性的基本出发点。如表所示,P表示的是特定三边关系的出现概率,P0则是相应的随机概率。S(surprise)衡量的是P偏离P0的程度。当P(Ti)>P0(Ti)时,则表明相应三边关系出现的概率大于随机概率,进而凸显了该种社交媒介对特定类型三边关系的塑造作用,也就是社交媒介影响力的一种具体体现。通过表3可以发现,T3类型(即三边关系均为积极关系)的出现概率在3类社交媒介中都大于相应的随机概率(其中在Epinion中最高),进而了说明上述3种社交媒介情境都有利于用户间相对稳定关系的形成,这些实证观测结果与Heider早期关于结构性平衡的定义是相符的。
除了社交媒介中关系性质的分析以外,虚拟社区的形成与发掘也是面向社交媒体影响力之结构性分析的一个重要领域。在目前的社交媒介虚拟社区挖掘中,目标社区一般被分为两种范式:分众分类或大众分类(Folksonomy)[35]和meta图分类(Metagraph)[36]。大众分类法使得传统分类法摆脱了固化的现象,并且跟大众的认知程度密切地结合起来,同时这种分类方法也为群体用户和信息之间建立了一个联系桥梁。这种分类是平面化的,没有等级层次的划分,虽然它相对不够严谨,缺乏准确度,但是在社会性软件中,这种平面延伸的分类方法却在无形之中成为形成了沟通的渠道和网络,而且方便,灵活,不受条件限制。所以这种以自定义标签形式的大众分类在现下流行的社会性网络服务中得到了广泛的应用,例如Delicious、Flickr和43things等等。与分众分类相比较为复杂的meta图分类则关注的是不同用户的不同分面(Facets)之间的联系,并依据不同面的组配来为用户的关系和活动建图。在研究方法与算法复杂度方面,Papadppoulos等学者[37]总结并比较了包含连续性子结构发掘,节点聚类等多种研究方法在内的社区发掘方法,如表4所示。

表4 社区发掘的复杂度比较
在上述的社区发掘算法复杂度比较中,复杂度A指的是不考虑网络密度的复杂度比较,而复杂度B指的是基于网络结构稀疏这一假设的复杂度比较。进一步地,在网络规模的比较中,S指的是小规模网络,即节点数不足104。M指的是大于小规模网络但节点数不足106的中型网络;L则是指节点数在(106,109)这一区间内的大规模网络。笔者认为,就方法论层面而言,未来社区发掘研究的重点在于如何改进算法,以解决社交媒体中数据量和网络规模急速扩张的现实状况。在社交媒介的虚拟空间中,社区中用户的整体行为与个人行为之间的差别也有待挖掘,需要构建社会网络的动态模型加以分析[38]。另外,K丛分析,多维度分析以及超网络分析都有可能在未来的社交媒介研究领域吸引更多学者的注意。
3 结论与讨论
在本文中,笔者基于国外相关的实证研究从信息内容和网络结构两个层面总结了目前的社交媒介影响力研究状况。社交媒体指允许人们撰写,分享,评价,讨论,相互沟通的网站和技术平台。简言之,社交媒体是社会化媒体与社交网络的结合体,它是一个“能互动”的媒体。和传统的社交形式和媒体传播方式相比,社交媒体网站具有便捷,及时,时尚,互动性强,突出个性化,资料更新的及时容易,使用目的手段多样性等优点,体现出平民性,参与性,对话性,社区化等明显特征。具体来说,社交媒体的形态包括博客及微博客(如国外Twitter,Facebook等,国内的饭否网等),维基(如国外的Wiki等,国内的互动百科,百度百科等),图片分享(如国外的Flickr,Pinterest等)播客及视频分享(如国外YouTube等,国内的土豆网,优酷网等)等。
纵观社交媒体的发展过程,可以说,社交媒体发展到现在已经成为我们生活中的重要组成部分。社交媒体相关的学术研究也从内容挖掘(如基于LDA模型的一系列主题提取和内容挖掘的拓展模型研究)和网络结构(如网络节点与边的性质,网络中的社区发掘等)两个层面不断展开。当社交媒体成为我们文化生活的一部分时,任何社会化的活动都不能忽略其影响。基于个人层面的影响分析,社交媒体已经覆盖人们日常生活的各个方面,并正改变人们寻找和分享信息的方式和相互交往的手段。基于社会的影响来讲,首先,社交媒体是基于关系的信息传播,具有更好的营销效果,对商业的发展带来了新的契机。另外,可以说社交媒体正在掀起一场“网络革命”:社交媒体不再是人们单独进行交流的工具,也是人们关注热点事件,组织政治活动,发动公民运动,实施危机救助的平台。相应地,面向社交媒体影响力的模型构建以及语义分析等,应将更大的数据量,更多的社交媒介现象纳入分析的范畴之中。
在国内的语境下,社交媒体,特别是微博在群体性事件和公民事件中的影响力已受到日益广泛的关注。相应地,国内面向社交媒体的影响力研究也可能借鉴国外的研究领域和研究方法,从而在国内的社交媒体情境下更准确地挖掘信息生成规律,信息传播规律,用户行为模式以及社交网络结构等方面的动态特征。
[1]Cheng X,Dale C,Liu J.Statistics and social network of youtube videos[C]∥Quality of Service,2008.IWQoS 2008.16th International Workshop on.IEEE,2008:229-238.
[2]Kwak H,Lee C,Park H,et al.What is Twitter,a social network or a news media?[C]∥Proceedings of the 19th international conference on World Wide Web.ACM,2010:591-600.
[3]Erickson T.Social interaction on the net:Virtual community as participatory genre[C]∥System Sciences,1997,Proceedings of the Thirtieth Hawaii International Conference on.IEEE,1997,(6):13-21.
[4]Mangold W G,Faulds D J.Social media:The new hybrid element of the promotion mix[J].Business Horizons,2009,52(4):357-365.
[5]Pang B,Lee L.Opinion mining and sentiment analysis[J].Foundations and Trends in Information Retrieval,2008,2(1-2):1-135.
[6]Ellison N B.Social network sites:Definition,history,and scholarship[J].Journal of Computer-Mediated Communication,2007,13(1):210-230.
[7]McCallum A,Wang X,Mohanty N.Joint group and topic discovery from relations and text[M].Springer Berlin Heidelberg,2007:28-44.
[8]Zhang H,Giles C L,Foley H C,et al.Probabilistic community discovery using hierarchical latent gaussian mixture model[C]∥AAAI.2007,(7):663-668.
[9]Qian S,Zhang T,Xu C.Multi-modal supervised latent dirichlet allocation for event classification in social media[C]∥Proceedings of International Conference on Internet Multimedia Computing and Service.ACM,2014:152.
[10]Krestel R,Fankhauser P,Nejdl W.Latent dirichlet allocation for tag recommendation[C]∥Proceedings of the third ACM conference on Recommender systems.ACM,2009:61-68.
[11]Qian S,Zhang T,Xu C.Boosted multi-modal supervised latent dirichlet allocation for social event classification[C]∥Pattern Recognition(ICPR),2014 22nd International Conference on.IEEE,2014:1999-2004.
[12]Tsolmon B,Lee K S.An event extraction model based on timeline and user analysis in Latent Dirichlet allocation[C]∥Proceedings of the 37th international ACM SIGIR conference on Research & development in information retrieval.ACM,2014:1187-1190.
[13]Saha A,Sindhwani V.Learning evolving and emerging topics in social media:a dynamic nmf approach with temporal regularization[C]∥Proceedings of the fifth ACM international conference on Web search and data mining.ACM,2012:693-702.
[14]Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].The Journal of Machine Learning Research,2003,(3):993-1022.
[15]Rosen-Zvi M,Griffiths T,Steyvers M,et al.The author-topic model for authors and documents[C]∥Proceedings of the 20th conference on Uncertainty in artificial intelligence.AUAI Press,2004:487-494.
[16]Rosen-Zvi M,Chemudugunta C,Griffiths T,et al.Learning author-topic models from text corpora[J].ACM Transactions on Information Systems(TOIS),2010,28(1):4.
[17]Hong L,Davison B D.Empirical study of topic modeling in twitter[C]∥Proceedings of the First Workshop on Social Media Analytics.ACM,2010:80-88.
[18]Xu Z,Lu R,Xiang L,et al.Discovering user interest on twitter with a modified author-topic model[C]∥Web Intelligence and Intelligent Agent Technology(WI-IAT),2011 IEEE/WIC/ACM International Conference on.IEEE,2011,(1):422-429.
[19]Kumar S,Morstatter F,Zafarani R,et al.Whom should I follow?identifying relevant users during crises[C]∥Proceedings of the 24th ACM conference on Hypertext and social media.ACM,2013:139-147.
[20]Zhao W X,Jiang J,Weng J,et al.Comparing twitter and traditional media using topic models[M]∥Advances in Information Retrieval.Springer Berlin Heidelberg,2011:338-349.
[21]Zhao W X,Jiang J,He J,et al.Topical keyphrase extraction from twitter[C]∥Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics:Human Language Technologies-Volume 1.Association for Computational Linguistics,2011:379-388.
[22]Bandari R,Asur S,Huberman B A.The Pulse of News in Social Media:Forecasting Popularity[C]∥ICWSM.2012.
[23]Lerman K,Hogg T.Using a model of social dynamics to predict popularity of news[C]∥Proceedings of the 19th international conference on World wide web.ACM,2010:621-630.
[24]Kim S D,Kim S H,Cho H G.Predicting the virtual temperature of web-blog articles as a measurement tool for online popularity[C]∥Computer and Information Technology(CIT),2011 IEEE 11th International Conference on.IEEE,2011:449-454.
[25]Tatar A,Leguay J,Antoniadis P,et al.Predicting the popularity of online articles based on user comments[C]∥Proceedings of the International Conference on Web Intelligence,Mining and Semantics.ACM,2011:67.
[26]Gómez V,Kaltenbrunner A,López V.Statistical analysis of the social network and discussion threads in slashdot[C]∥Proceedings of the 17th international conference on World Wide Web.ACM,2008:645-654.
[27]Cha M,Kwak H,Rodriguez P,et al.I tube,you tube,everybody tubes:analyzing the world’s largest user generated content video system[C]∥Proceedings of the 7th ACM SIGCOMM conference on Internet measurement.ACM,2007:1-14.
[28]Brodersen A,Scellato S,Wattenhofer M.Youtube around the world:geographic popularity of videos[C]∥Proceedings of the 21st international conference on World Wide Web.ACM,2012:241-250.
[29]Figueiredo F,Benevenuto F,Almeida J M.The tube over time:characterizing popularity growth of youtube videos[C]∥Proceedings of the fourth ACM international conference on Web search and data mining.ACM,2011:745-754.
[30]Smith M A,Shneiderman B,Milic-Frayling N,et al.Analyzing(social media)networks with NodeXL[C]∥Proceedings of the fourth international conference on Communities and technologies.ACM,2014:255-264.
[31]Kane G C,Alavi M,Labianca G,et al.What’s different about social media networks?A framework and research agenda[J].MIS Quarterly,2014,38(1):275-304.
[32]Perer A,Shneiderman B.Balancing systematic and flexible exploration of social networks[J].Visualization and Computer Graphics,IEEE Transactions on,2006,12(5):693-700.
[33]Kunegis J,Lommatzsch A,Bauckhage C.The slashdot zoo:mining a social network with negative edges[C]∥Proceedings of the 18th international conference on World Wide Web.ACM,2009:741-750.
[34]Leskovec J,Huttenlocher D,Kleinberg J.Signed networks in social media[C]∥Proceedings of the SIGCHI Conference on Human Factors in Computing Systems.ACM,2010:1361-1370.
[35]Almoqhim F,Millard D E,Shadbolt N.Improving on Popularity as a Proxy for Generality When Building Tag Hierarchies from Folksonomies[M]∥Social Informatics.Springer International Publishing,2014:95-111.
[36]Lin Y R,Sun J,Sundaram H,et al.Community discovery via metagraph factorization[J].ACM Transactions on Knowledge Discovery from Data(TKDD),2011,5(3):17.
[37]Papadopoulos S,Kompatsiaris Y,Vakali A,et al.Community detection in social media[J].Data Mining and Knowledge Discovery,2012,24(3):515-554.
[38]Yu R,He X,Liu Y.Glad:group anomaly detection in social media analysis[C]∥Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining.ACM,2014:372-381.
(本文责任编辑:郭沫含)
Research Agenda of International Social Media Influence Analysis——Advances and Implications
Liu Jiqun
(Department of Information Management,Peking University,Beijing 100871,China)
With the rapid development of information and communication technologies,more and more individual users and organizations choose to participate in the social media spaces,and the influence of social media keeps on ascending accordingly.This paper analyzed and summarized the studies of social media influences overseas in relative fields,such as computer science,and point out some basic and promising research area in social media studies including topic extraction based on contents,the popularity of information in social media,social networks and community detection.Furthermore,the paper introduced various fundamental and typical algorithms and models,and compared relevant findings.The possible direction of future research in the field of social media studies was also proposed.Finally,the implications of these studies to social media influence analysis in China were also discussed.
social media;social network;influence analysis;LDA model;community detection
2016-01-18
刘济群(1992-),男,硕士研究生,研究方向:信息行为,信息通讯技术与社会发展,图书情报学研究方法,发表论文10余篇。
10.3969/j.issn.1008-0821.2016.03.026
TP391;G252.8
A
1008-0821(2016)03-0158-09
