基于序的空间金字塔池化网络的人群计数方法
2016-08-22时增林叶阳东吴云鹏娄铮铮
时增林 叶阳东 吴云鹏 娄铮铮
基于序的空间金字塔池化网络的人群计数方法
时增林1叶阳东1吴云鹏1娄铮铮1
视频中的人群计数在智能监控领域具有重要价值.由于摄像机透视效果、图像背景、人群密度分布不均匀和行人遮挡等干扰因素的制约,基于底层特征的传统计数方法准确率较低.本文提出一种基于序的空间金字塔池化(Rank-based spatial pyramid pooling,RSPP)网络的人群计数方法.该方法将原图像分成多个具有相同透视范围的子区域并在各个子区域分别取不同尺度的子图像块,采用基于序的空间金字塔池化网络估计子图像块人数,然后相加所有子图像块人数得出原图像人数.提出的图像分块方法有效地消除了摄像机透视效果和人群密度分布不均匀对计数的影响.提出的基于序的空间金字塔池化不仅能够处理多种尺度的子图像块,而且解决了传统池化方法易损失大量重要信息和易过拟合的问题.实验结果表明,本文方法相比于传统方法具有准确率高和鲁棒性好的优点.
人群计数,空间金字塔池化,深度学习,卷积神经网络,岭回归
引用格式时增林,叶阳东,吴云鹏,娄铮铮.基于序的空间金字塔池化网络的人群计数方法.自动化学报,2016,42(6):866-874
监控视频中的人群自动计数有着重要的社会意义和市场应用前景.充分利用兴趣区域的人数统计信息可以为一些人群密集的商场、车站、广场等公共场合的安全预警提供有效的指导,还可以带来经济效益,例如,提高服务质量、分析顾客行为、广告投放和优化资源配置等.因此,该问题已成为计算机视觉和智能视频监控领域的重要研究内容.
近年来,随着计算机视觉技术的持续发展,大量的人群计数方法被提出.这些方法总体可以分为两类,一类是基于行人检测技术的直接法[1-2],另一类是基于特征回归技术的间接法[3-9].直接法通过检测和跟踪视频中的个体来完成人数统计.这种方法能够同时完成人群计数和个体定位,缺点是在人群密度较高或视频开阔的场景下识别率不高.间接法将人群视为一个整体,利用图像特征和人群人数之间的回归关系实现行人计数.这类方法能够有效地解决人群遮挡问题,具有大规模人群计数的能力.
间接法又可以分为全局法和局部法[10].全局法[3-4,8]以视频中的每一帧为计数单位,使用全局的图像特征进行计数.局部法[5-7,9]将原图像分成多个子图像块,以子图像块为计数单位,使用局部的图像特征进行计数.尽管全局法具有操作简单、计数方便的优点,然而也面临着以下几个方面的问题:1)容易受到摄像机透视效果的影响,即对于同一个目标,随着它与摄像机的距离变化,特征向量也会改变;2)人群密度大的场景比较复杂,这时将整个场景作为计数单位,会产生很多噪声,噪声累积对计数结果有负面影响;3)建立整个场景的特征和人数的回归关系,需要大量的训练数据;4)由于透视效果、视点变化和人群密度变化,图像人群密度分布应大致均匀的前提假设在真实的场境下一般不成立.局部法通过将原图像分成多个子图像块,能够有效解决全局法面临的问题[10].
图像分块和图像特征提取是影响局部法计数效果的关键技术.均匀分块方法[5-6]是现有局部法常采用的图像分块方法.该方法将原图像分成多个具有相同尺度的子图像块,有着操作简单的优点,然而并不能有效地消除摄像机透视效果和人群密度分布不均匀对计数的影响.现有局部法常用的底层特征有:形状特征[3[8]、关键点特征(兴趣点[5]、角点[11])、纹理特征(Gray level dependent matrix,GLDM)[12]和梯度统计特征(Histogram of oriented gradient,HOG)[5]等.这些底层特征对人群的表征能力有限,加上人群遮挡、透视效果的影响,难以达到理想的效果.
本文在深入研究现有人群计数方法的基础上,提出一种基于序的空间金字塔池化网络的人群计数方法.该方法将原图像分成多种尺度的子图像块,采用基于序的空间金字塔池化网络获取子图像块人数,然后相加所有子图像块人数得出图像人数.传统方法和本文方法的计数流程如图1所示.本文的贡献主要有以下几点:1)提出一种新的人群计数方法.该方法提取特征不依赖于前景分割,通过多层卷积—池化结构获取的高层特征相比于底层特征对人群的表征能力更强.2)提出一种新的图像分块方法.该方法将原图像分成多个具有相同透视范围的子区域并在各个子区域取图像块,有效地消除了摄像机透视效果和人群密度分布不均匀对计数的影响;3)提出的基于序的空间金字塔池化不仅能够处理多种尺度的子图像块,而且解决了传统池化方法易损失大量重要信息和易过拟合的问题.在UCSD行人数据集上的实验结果表明,本文方法相比于传统方法具有准确率高和鲁棒性好的优点.
1 相关研究
自Hinton等提出深度学习(Deep learning,DL)[13]以来,DL已经在学术界和产业界产生了深远的影响.它通过多层结构将底层特征逐步转换为更加抽象的高层特征,具有优异的特征学习能力,学到的特征对数据有更本质的刻画.卷积神经网络(Convolutional neural network,CNN)是第一个真正意义上的深度学习模型,也是最成功的深度模型之一,在计算机视觉领域有着广泛的应用.CNN凭借特有的卷积—池化(Convolution-pooling)结构获得的特征对平移、缩放和旋转具有不变性,相比于底层特征,判别能力和鲁棒性更强[14].修正线性单元(Rectified linear units,ReLU)[15]、Dropout[16]和响应归一化(Response normalization,RN)[16]等新方法又增强了CNN模型的能力.当前典型的卷积—池化结构如图2所示.
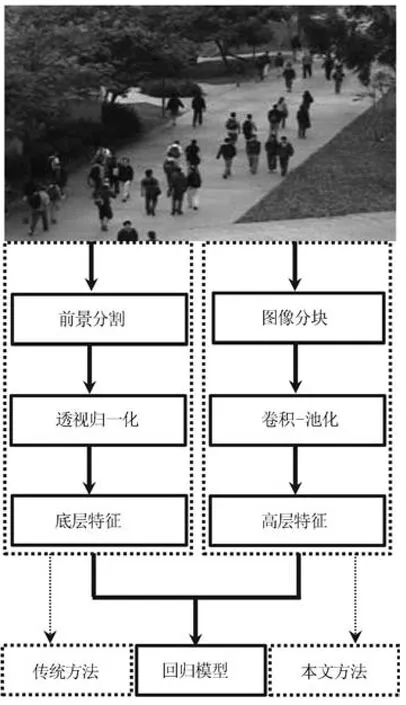
图1 传统人群计数方法和本文人群计数方法的流程Fig.1 The flow chart of traditional and the proposed crowd counting methods
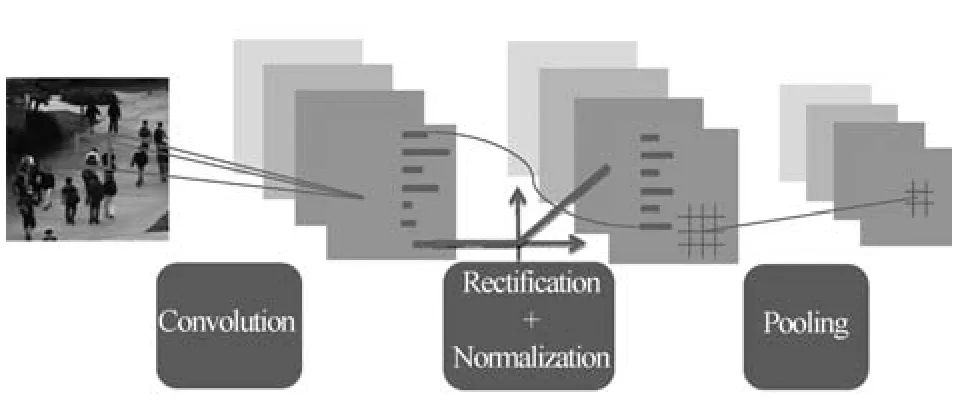
图2 当前典型的卷积—池化结构Fig.2 The typical convolution-pooling structure
CNN中的全连接层需要固定的输入维度,限制了CNN只能接受固定尺度的输入.一般只能通过图像尺度归一化的方法来处理不同尺度的输入图像,然而这种方法会导致图像信息的损失.为解决这个问题,He等提出了空间金字塔池化(Spatial pyramid pooling,SPP)[17]方法.SPP允许CNN接受任何尺度的输入,增加了模型的尺度不变性,抑制了过拟合的发生.文献[17]将使用了空间金字塔池化的卷积神经网络称为空间金字塔池化网络.典型的空间金字塔池化网络如图3所示.
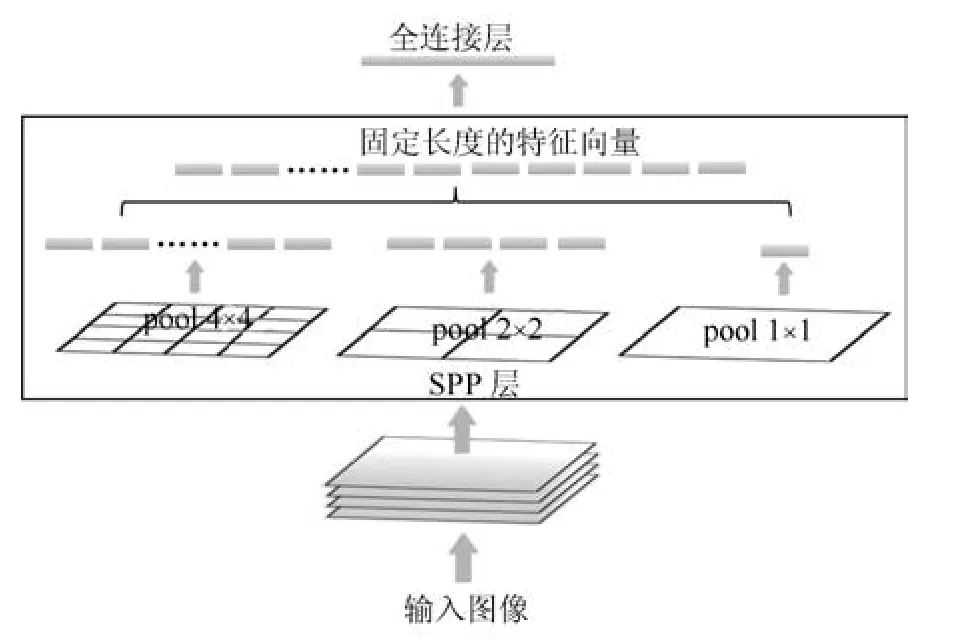
图3 典型的空间金字塔层结构Fig.3 The typical spatial pyramid pooling structure
空间金字塔池化通过使用多个不同大小的池化操作保证固定的特征向量输出,从而实现任何尺度的输入.在进行具体的池化操作时一般采用最大池化(Max pooling)和平均池化(Average pooling),然而这两种方法都有自身的缺陷.最大池化总是取池化域内的最大激活值作为池化输出,忽略了大量有用信息,容易导致模型过拟合.平均池化以池化域内所有激活值的平均值作为池化输出,会发生低的负激活值与高的正激活值相消的情况,容易产生零均值,从而导致不好的结果.为解决最大池化和平均池化的问题,文献[18]提出一种称作随机池化(Stochastic pooling)的方法.该方法采用对池化域内的n个激活值归一化的方法获取选择概率pi:

然后根据选择概率随机地选取一个激活值作为池化输出.该方法通过随机操作使得所有激活值都有机会参与到池化操作中,相比于最大池化和平均池化具有更好的表现[18-19].然而这种随机池化方法使用式(1)计算选择概率有两方面的不足:1)该式不接受负值,只能与ReLU激活函数配合使用(ReLU可以把负值强制为0),因此,不能与其他有效的激活函数结合使用;2)该式不能控制选择概率,在某些情况下会导致最大激活值的选择概率接近或达到1,使得随机池化退化为最大池化.
2 基于序的空间金字塔池化网络的人群计数方法
本文在深入研究现有人群计数方法的基础上,提出一种基于序的空间金字塔池化网络的人群计数方法.该方法将原图像分成多种尺度的子图像块,采用基于序的空间金字塔池化网络获取子图像块人数,然后相加所有子图像块人数得出图像人数.
2.1图像分块
由于摄像机的透视效果,不同景深的行人在图像平面呈现不同的形状和大小,远离摄像机区域的人群更密集,相互遮挡更严重,这些问题都增加了人群计数的难度.因此,消除图像的透视效果是提高间接法人群计数算法性能的关键步骤.图像分块可以有效地消除摄像机的透视效果,然而现行的均匀分块方法的效果并不理想.本文提出一种新的图像分块方法.该方法将原图像分成多个具有相同透视范围的子区域并在各个子区域取图像块,具体有三个主要步骤.
1)计算图像的透视关系图.本文采用文献[3]提出的方法计算图像的透视关系图.首先,标出实验所需要的感兴趣区域(Region of interest,ROI),找出ROI区域沿着摄像机远近方向的平行的两端,一个远端,一个近端,分别测量出其长度,如图4(a)中的分别测量出线段上的一个目标的长度,目标中心在上.如图4(a)中的h1和h2.然后,用透视程度表示不同景深的行人发生透视效果的程度.设线上的透视程度为1,则按照线性插值的规则,线上的透视程度应为.最后,其他景深的透视程度按照两条线之间的线性插值得到.
2)将图像分为几个子区域,使得不同子区域具有相同的透视范围(Scope of perspective,SP).
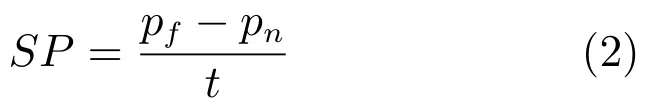
其中,pf表示ROI区域内最远方的透视程度,pn表示ROI区域内最近方的透视程度,t表示图像分成的子区域数量,可以控制子区域透视效果的强度.t值越大子区域的透视效果越弱,然而t值过大会导致计数复杂度变高和计数准确率下降.本文将图像分为A、B和C三个子区域,如图4(b)所示.
3)分别从各个子区域取子图像块.子图像块的高度与子区域的高度一致.由于不同子区域的高度不同,因此从各个子区域获取的子图像块具有不同的尺度.
文献[3]通过使用透视关系图对每个像素加透视校正权重的方式处理摄像机的透视效果,然而这种方法在真实的场景中具有局限性[9],并且不能够处理人群密度分布不均匀的问题.本文利用透视关系图将图像分成多个具有相同透视范围的子区域,从而弱化了原图像的透视效果.从各个子区域所取的子图像块相比于原图像尺寸较小,因此子图像块的人群密度分布相对均匀.
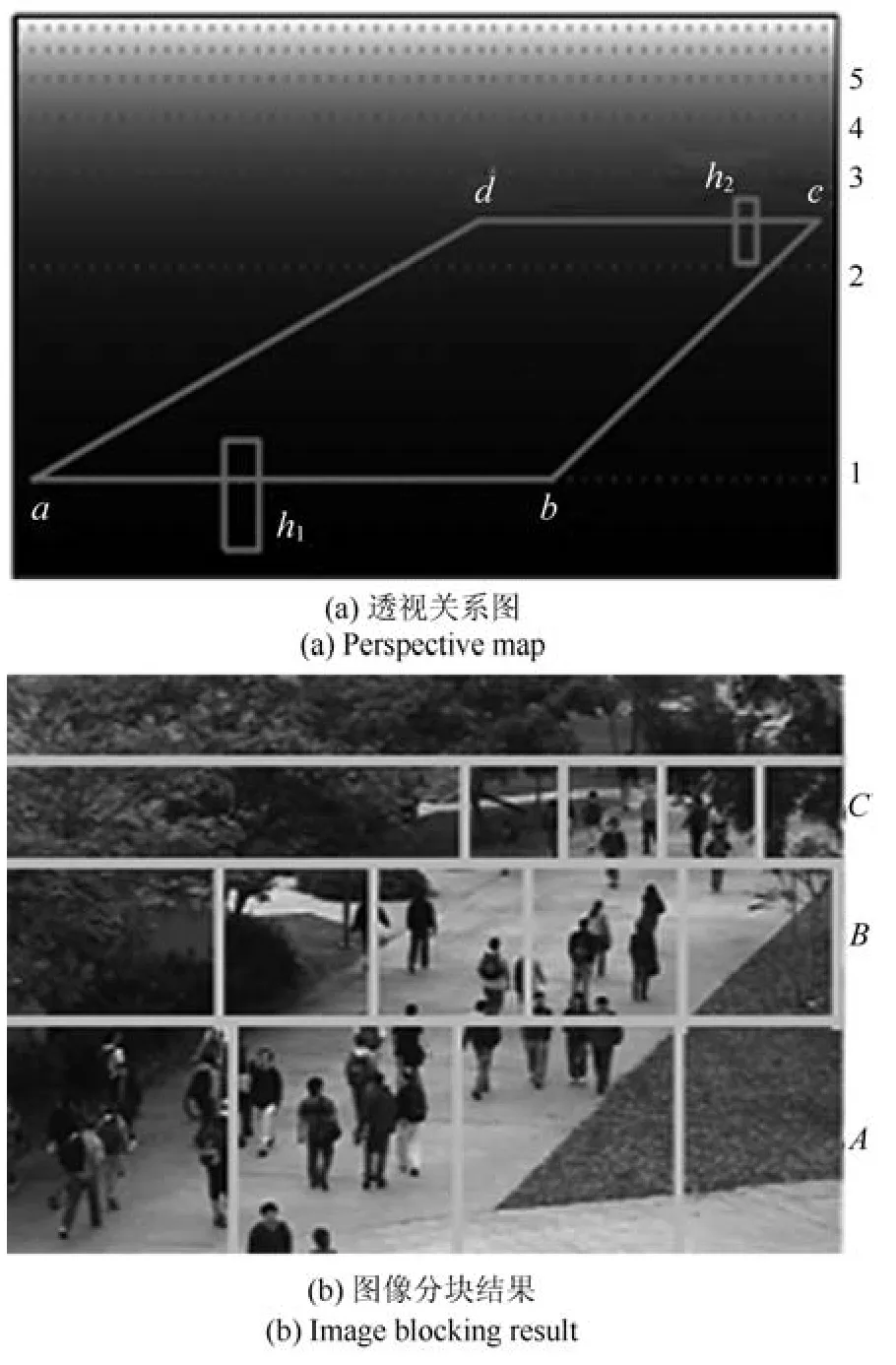
图4 图像分块方法Fig.4 The methods of dividing image into sub-image blocks
2.2基于序的随机池化
尽管空间金字塔池化网路能够处理多种尺度的子图像块,然而在进行具体的池化操作时,当前常用的池化方法有很多的不足.为此,本文提出了一种称作基于序的随机池化(Rank-based stochastic pooling,RSP)方法.
RSP首先根据池化域内激活值的大小对激活值从高到低排序,将激活值在排序后的索引作为激活值的序.例如,激活值最高的元素的序是“1”.然后,根据下式[20]计算激活值的选择概率.
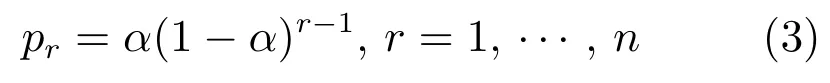
其中,α是一个超参数,表示最大激活值的选择概率,r表示激活值的序,n表示池化域的大小.最后,从选择概率的多项式分布(Multinomial distribution)中采样,得到第j个池化域要保留的激活值sj:
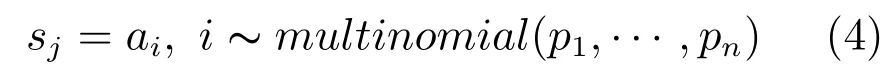
ai表示池化域j内索引为i的激活值.
在测试时,使用式(3)计算的概率对池化域内的激活值加权,取加权后的所有激活值的和作为池化的结果.
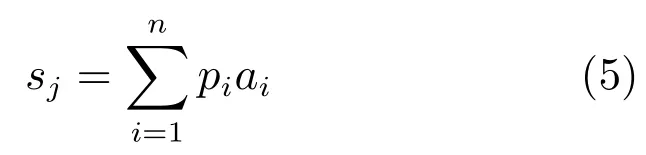
这种加权方法应用在测试时可以看作是一种模型平均策略,提高了模型的表现.式(3)可以看作是一个首项为α、公比为1-α的等比数列,因此,容易得到,
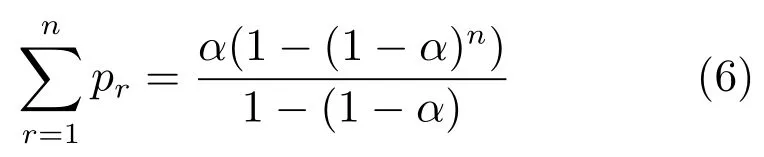
化简后得到,
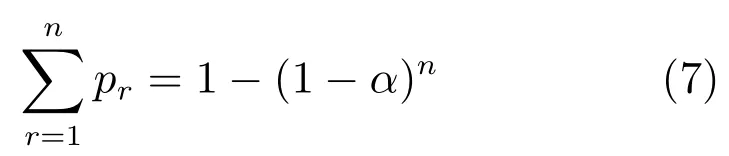
RSP使用激活值的序而不是实际的激活值计算选择概率,因此不必限制激活值的正负性,可以与更多的激活函数结合使用.式(3)能够通过参数α控制最大激活值的选择概率,使得最大激活值的选择概率不会太大,也不会太小,保证了RSP在选择激活值时具有更多的随机性,从而进一步控制过拟合.同时,更多的随机性使得RSP既保留了重要信息又保证了信息的多样性,有利于获得表征能力更强的特征.
RSP可以应用在CNN的任何池化层.本文将使用了RSP的空间金字塔池化称作基于序的空间金字塔池化(Rank-based spatial pyramid pooling,RSPP),将使用了RSPP的CNN称作基于序的空间金字塔池化网络(Rank-based spatial pyramid pooling network,RSPP-net).
2.3人群计数模型
本文提出的基于序的空间金字塔池化网络的人群计数模型是一个端到端的系统(End-to-end system).该模型直接以子图像块作为输入,通过多层的卷积—池化结构自动提取特征,然后交由岭回归层[21]处理,最终输出子图像块人数.特征提取和回归由不同的网络层自动实现.为了降低训练的难度,使用多个共享训练参数的CNN模型来逼近一个允许多尺度输入的基于序的空间金字塔池化网络[17].本文构建了三个仅输入维度不同的CNN模型来处理三种尺度的子图像块,分别记作CNN_64、CNN_44和CNN_28,它们的详细参数设置如表1所示.训练时三个模型根据输入维度大小依次进行,通过将前一个训练好的模型作为下一个训练模型的预训练模型的方式共享训练参数.这种训练方法弥补了较小尺度图像块训练数据不足的问题,并且加快了模型拟合的速度.测试时分别将子图像块输入训练好的模型得到子图像块人数,然后所有子图像块人数相加得出图像人数.提出的计数框架如图5所示.

表1 人群CNN模型的详细结构Table 1 Architecture specifics for crowd CNN model
利用开源的深度学习框架Caffe[22]训练提出的模型.Euclidean_loss被用为损失函数.使用minibatch为100的随机梯度下降(Stochastic gradient descent,SGD)方法调整模型参数.为了加快模型拟合的速度,使用了常数项为0.9的冲量(Momentum).常数项为0.01的权值衰减(Weight decay)被用于控制过拟合.RSP中的常数项α取值为0.5.
3 实验结果及分析
采用UCSD行人数据集[3]评价提出的方法.该数据集由2000帧尺寸为158×238的图像组成.每一帧图像中的行人都已经被标注,标注坐标是行人的中心位置.图像中行人数量最小为11,最大为46. 图6给出了UCSD数据集的一些示例帧.

图5 计数模型的整体结构Fig.5 The overall structure of the crowd counting model

图6 UCSD数据集示例帧Fig.6 Examples frames of the UCSD dataset
为了保证对比实验的公平性,与文献[3]保持一致,使用601~1400帧作为训练集,余下的1200帧作为测试集.分别在训练集和测试集上根据第2节描述的方法取子图像块.首先将图像分为高度为64、44和28三个子区域.然后分别在三个子区域上取尺寸相同的子图像块.由于深度学习模型复杂,需要大量的训练数据.本文在训练集上使用滑动步长为1的窗口取子图像块,进行数据集的扩展.每个子图像块的实际人数通过行人的标注坐标计算得到.训练集中存在一些只有背景没有行人的数据,这些数据作为负样本,使得训练得到的模型鲁棒性更好.在每一张图像的三个子区域分别取3、4和3个子图像块,组成测试集.测试子图像块之间没有重叠,能够覆盖整个ROI区域.一些示例如图7所示.最终获得的训练集和测试集的详细情况如表2所示.

图7 子图像块示例Fig.7 Examples of sub-image blocks
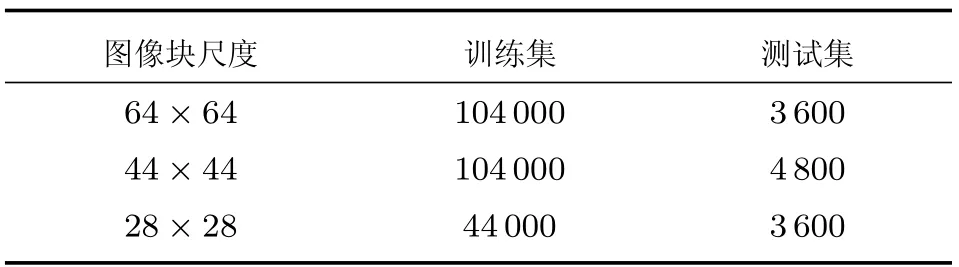
表2 实验数据Table 2 Experimental data
人群计数方法的优劣可以通过实验帧的实际人数与其对应的预测值来做判断,本文采用平均绝对误差(Mean absolute error,MAE)和均方误差(Mean squared error,MSE)作为评价的标准.
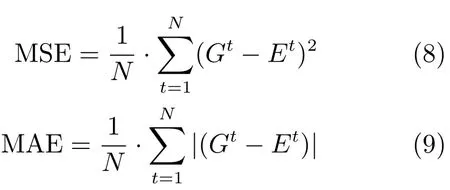
其中,N为实验视频序列的帧数,Gt为第t帧的实际人数,Et为第t帧的预测人数.
实验1.验证基于序的随机池化方法的有效性.由于尺度为64的图像块训练数据最多,首先训练CNN_64模型.为了验证本文提出的基于序的随机池化方法的有效性,在保证其他设置都不变的情况下,分别采用不同的池化方法估计人数.多种池化方法在尺度为64的子图像块上的计数结果如表3所示.通过比较表3的结果可以看出,基于序的随机池化方法避免了过拟合,在测试集上的两种评价指标均优于其他几种池化方法.
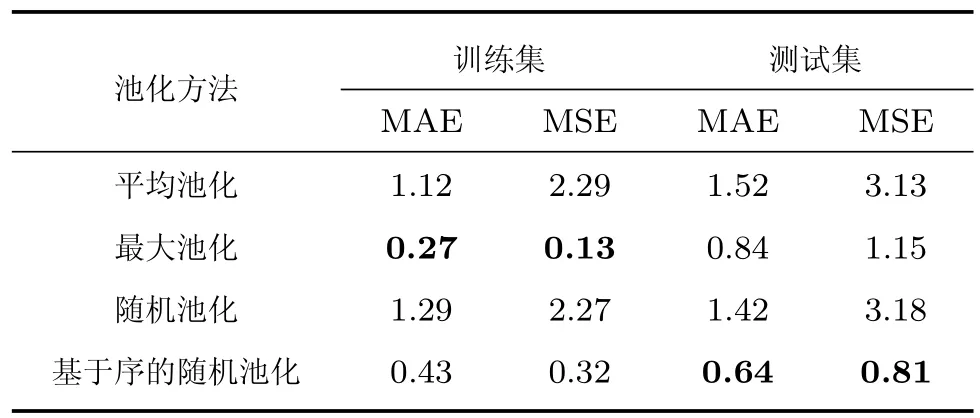
表3 多种池化方法在尺度为64的子图像块上的测试结果Table 3 Testing results for sub-image blocks with the scale of 64 of various pooling methods
实验2.验证联合训练方法的有效性.CNN_44模型将训练好的CNN_64模型作为预训练模型,并使用尺度为44的训练数据调整模型参数.最后训练的是CNN_28模型.为了验证本文提出的联合训练方法的有效性,进行了单独训练的对比实验.单独训练指的是三个模型分别使用各自的数据进行无关联的训练,彼此之间不共享训练参数.在三个尺度子图像块上的测试结果如表4所示.从表4的测试结果可以看出,联合训练大幅提高了计数准确率.
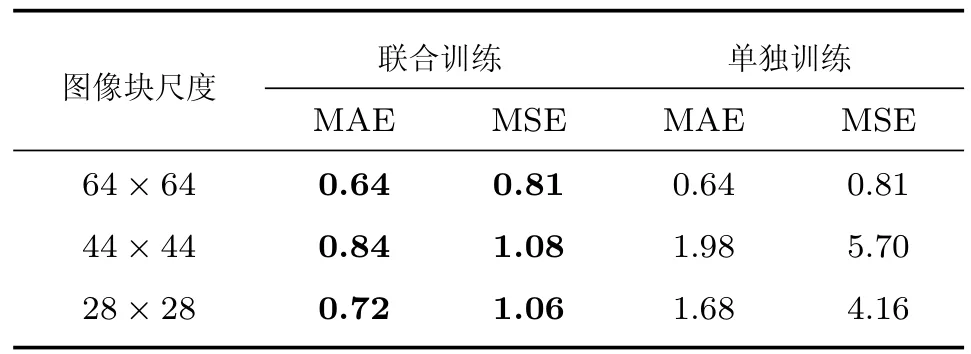
表4 子图像块上的测试结果Table 4 The testing results in sub-image blocks
实验3.验证提出的图像分块方法的有效性.本实验采用均匀分块的方法,将原图像分成尺度相同的子图像块,然后用一个CNN模型进行计数.从每个原始训练图像上随机取600个72×72的子图像块组成训练集.从每个原始测试图像上取6个72×72的子图像块组成测试集.测试子图像块之间没有重叠,能够覆盖整个ROI区域.将子图像块输入到CNN模型中,得出子图像块人数.每个原始测试图像的估计人数为6个子图像块之和.为保证计数的公平性,本实验使用的CNN模型与实验1和实验2所用的CNN模型仅输入维度不一样,其他参数设置完全相同.实验结果如表5所示,本文方法优于单CNN模型.
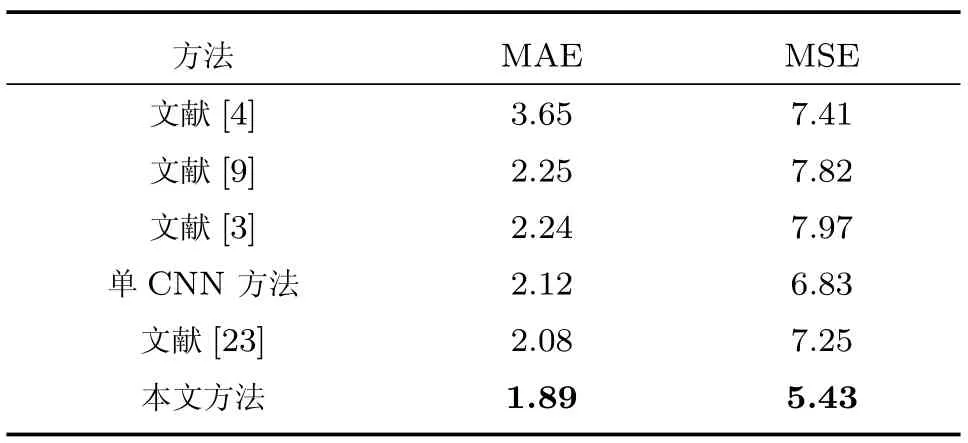
表5 整幅图像上的测试结果Table 5 The testing results in image
实验4.比较本文方法与传统人群计数方法.提出方法的最终目的是估计整幅图像的人数.分别将子图像块输入训练好的模型得到子图像块的人数,然后所有子图像块人数相加得出图像人数.提出的方法与传统最好方法(State-of-the-art methods)在测试数据上的计数结果如表5所示.从结果对比可以看出,本文提出的方法在两个评价指标上均优于已有的方法,分析原因主要有两点:1)对比方法都是先进行前景分割,再提取边缘、面积等特征描述行人.显然,前景分割后有利于更直接地描述和提取行人的特征.但是光照变化、行人拥挤程度、背景颜色等多种干扰因素都使得前景分割成为一项较难的工作.本文提出的方法一方面通过分块降低了特征提取的难度,另一方面自动学习特征的方式具有辨识前景和背景的能力,因此不需要前景分割,可以直接在原图像上学习特征;2)对比方法使用的都是底层特征,对人群表达能力有限.本文采用多层卷积—池化结构学习获得的高层特征对人群有更本质的刻画和更强的判别能力,对行人遮挡的鲁棒性好.
提出方法对整个测试集计数结果如图8所示,对一些稀疏人群和高密度人群的计数结果如图9所示.图中所标示的“E”为人数估计值,“G”为人数标定值.
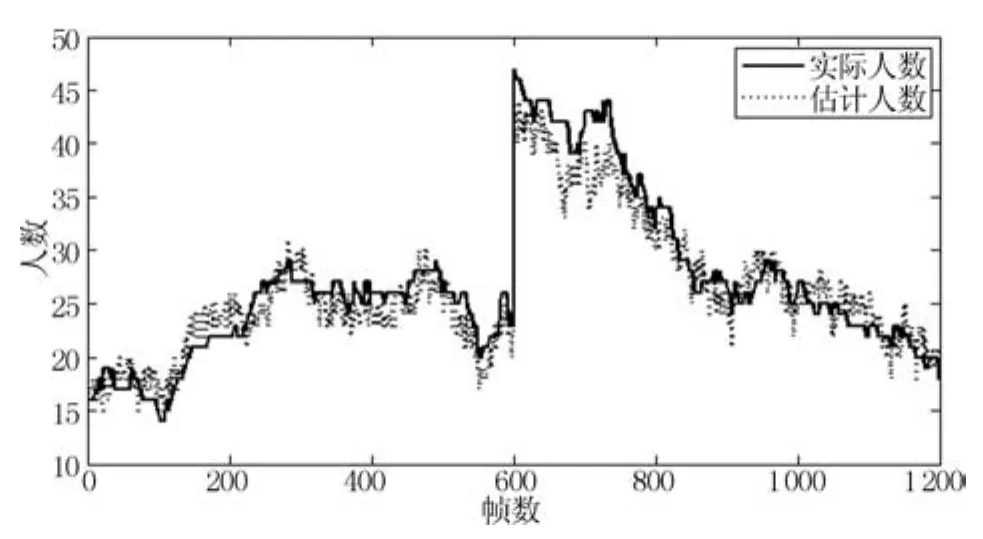
图8 整个测试集的计数结果Fig.8 The recognition results on the entire testing frames
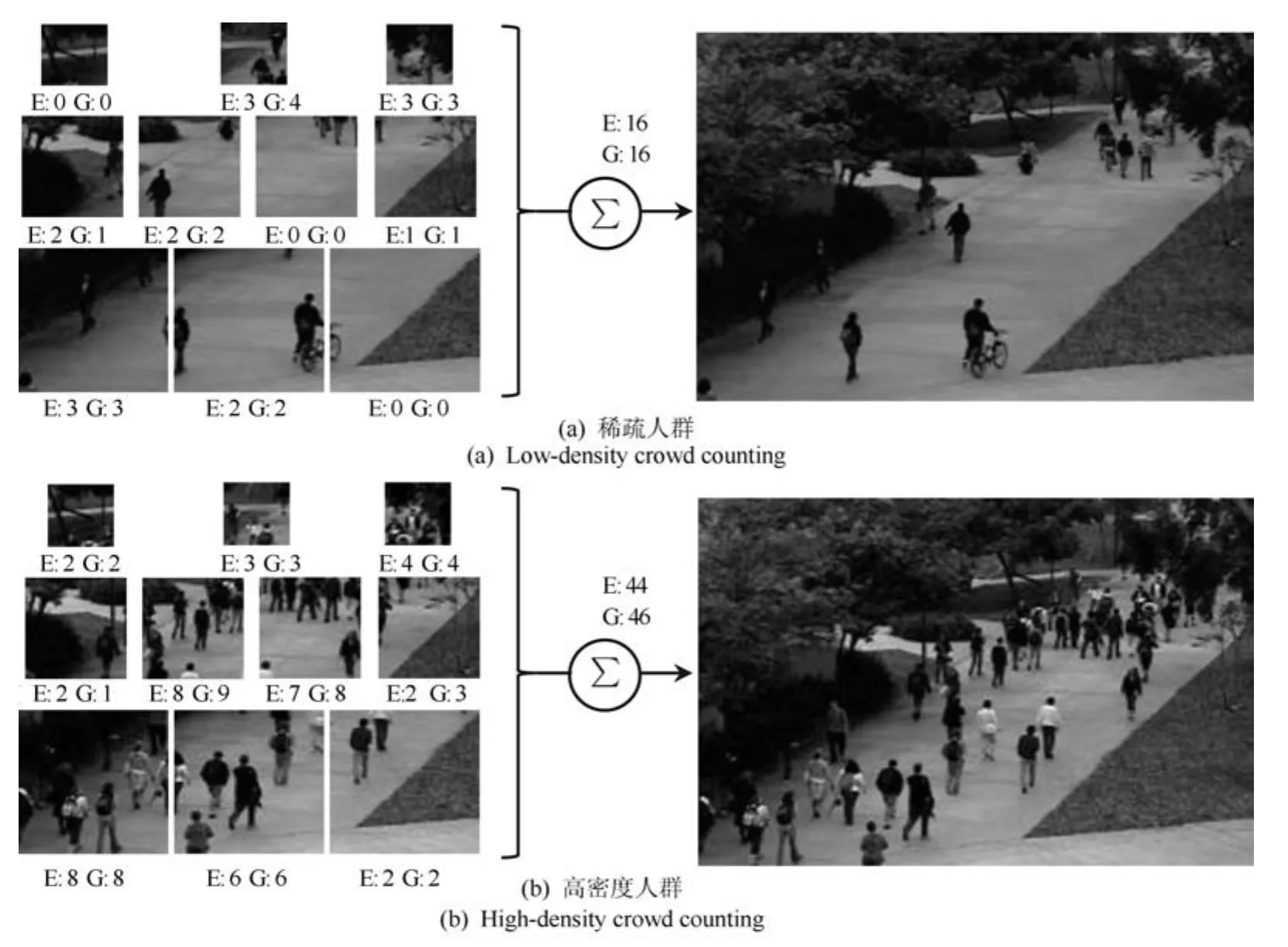
图9 在多种人群密度上的计数结果Fig.9 Various density crowd counting
4 结论
本文提出了一种基于序的空间金字塔池化网络的人群计数方法.通过将图像分成具有相同透视范围的子区域,然后分别在子区域上取子图像块的方法,有效解决了摄像机透视效果和人群密度分布不均匀对计数带来的影响.采用基于序的空间金字塔池化网络估计多种尺度的子图像块人数,不需要前景分割等复杂的步骤,通过多层卷积—池化结构提取的特征相比于底层特征对人群图像有更本质的刻画.通过实验验证了提出的图像分块方法和基于序的随机池化方法的有效性.为解决基于序的空间金字塔池化网络训练困难的问题,提出了联合训练的方法.该方法充分利用了训练数据,有效控制了过拟合现象的发生,相比于单独训练方法提高了1倍的准确率.实验结果表明,本文方法在有关人群计数准确率的两项指标上均优于其他计数方法.
References
1 Wu B,Nevatia R.Detection of multiple,partially occluded humans in a single image by Bayesian combination of edgelet part detectors.In:Proceedings of the 10th IEEE International Conference on Computer Vision.Beijing,China:IEEE,2005.90-97
2 Zhao T,Nevatia R,Wu B.Segmentation and tracking of multiple humans in crowded environments.IEEE Transactions on Pattern Analysis and Machine Intelligence,2008,30(7):1198-1211
3 Chan A B,Liang Z S J,Vasconcelos N.Privacy preserving crowd monitoring:counting people without people models or tracking.In:Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition.Anchorage,AK:IEEE,2008.1-7
4 Chan A B,Vasconcelos N.Counting people with low-level features and Bayesian regression.IEEE Transactions on Image Processing,2012,21(4):2160-2177
5 Idrees H,Saleemi I,Seibert C,Shah M.Multi-source multiscale counting in extremely dense crowd images.In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition.Portland,USA:IEEE,2013. 2547-2554
6 Lempitsky V,Zisserman A.Learning to count objects in images.In:Proceedings of Advances in Neural Information Processing Systems.Vancouver,Canada:NIPS,2010. 1324-1332
7 Ma W,Huang L,Liu C.Crowd density analysis using cooccurrence texture features.In:Proceedings of the 5th IEEE International Conference on Computer Sciences and Convergence Information Technology.Seoul,Korea:IEEE,2010. 170-175
8 Kong D,Gray D,Tao H.A viewpoint invariant approach for crowd counting.In:Proceedings of the 18th IEEE International Conference on Pattern Recognition.Hong Kong,China:IEEE,2006.1187-1190
9 Chen K,Loy C C,Gong S G,Xiang T.Feature mining for localised crowd counting.In:Proceedings of the 23rd British Machine Vision Conference.Surrey,British:BMVA Press,2012.1-3
10 Ryan D,Denman S,Sridharan S,Fookes C.An evaluation of crowd counting methods,features and regression models.Computer Vision and Image Understanding,2015,130:1-17
11 Rosten E,Porter R,Drummond T.Faster and better:a machine learning approach to corner detection.IEEE Transactions on Pattern Analysis and Machine Intelligence,2010,32(1):105-119
12 Wu X Y,Liang G Y,Lee K K,Xu Y.Crowd density estimation using texture analysis and learning.In:Proceedings of the 2006 IEEE International Conference on Robotics and Biomimetics.Kunming,China:IEEE,2006.214-219
13 Hinton G E,Salakhutdinov R R.Reducing the dimensionality of data with neural networks.Science,2006,313(5786):504-507
14 Zeiler M D,Fergus R.Visualizing and understanding convolutional networks.In:Proceedings of the 13th European Conference on Computer Vision.Zurich,Switzerland:Springer,2014.818-833
15 Nair V,Hinton G E.Rectified linear units improve restricted Boltzmann machines.In:Proceedings of the 27th International Conference on Machine Learning.Haifa,Israel:JMLR,2010.807-814
16 Krizhevsky A,Sutskever I,Hinton G E.ImageNet classification with deep convolutional neural networks.In:Proceedings of Advances in Neural Information Processing Systems. Nevada,USA:NIPS,2012.1097-1105
17 He K M,Zhang X Y,Ren S Q,Sun J.Spatial pyramid pooling in deep convolutional networks for visual recognition.In:Proceedings of the 13th European Conference on Computer Vision.Zurich,Switzerland:Springer,2014.346-361
18 Zeiler M D,Fergus R.Stochastic pooling for regularization of deep convolutional neural networks.In:Proceedings of the 2013 International Conference on Learning Representation.Arizona,USA:ICLR,2013.1-9
19 Sainath T N,Kingsbury B,Saon G,Soltau H,Mohamed A R,Dahl G,Ramabhadran B.Deep convolutional neural networks for large-scale speech tasks.Neural Networks,2015,64:39-48
20 Michalewicz Z.Genetic Algorithms+Data Structures= Evolution Programs.Berlin Heidelberg:Springer Science& Business Media,2013.59-61
21 Saunders C,Gammerman A,Vovk V.Ridge regression learning algorithm in dual variables.In:Proceedings of the 15th International Conference on Machine Learning.San Francisco,CA,USA:Morgan Kaufmann Publishers Inc.,1998.515-521
22 Jia Y Q,Shelhamer E,Donahue J,Karayev S,Long J,Girshick R,Guadarrama S,Darrell T.Caffe:convolutional architecture for fast feature embedding.In:Proceedings of the 22nd ACM International Conference on Multimedia. Florida,USA:ACM,2014.675-678
23 Zhang Z X,Wang M,Geng X.Crowd counting in public video surveillance by label distribution learning.Neurocomputing,2015,166:151-163

时增林郑州大学信息工程学院硕士研究生.主要研究方向为计算机视觉,机器学习,深度学习.
E-mail:iezlshi@gs.zzu.edu.cn
(SHI Zeng-LinMaster student at the School of Information Engineering,Zhengzhou University.His research interest covers computer vision,machine learning,and deep learning.)

叶阳东郑州大学信息工程学院教授.主要研究方向为智能系统,机器学习,数据库.本文通信作者.
E-mail:ieydye@zzu.edu.cn
(YE Yang-DongProfessor at the SchoolofInformationEngineering,Zhengzhou University.His research interest covers intellectual system,machine learning,and database system.Corresponding author of this paper.)

吴云鹏郑州大学信息工程学院博士研究生.主要研究方向为机器学习,计算机视觉.
E-mail:ieypwu@zzu.edu.cn
(WU Yun-PengPh.D.candidate at the School of Information Engineering,Zhengzhou University.His research interest covers machine learning and computer vision.)

娄铮铮郑州大学信息工程学院讲师,博士.主要研究方向为机器学习,模式识别,计算机视觉.
E-mail:iezzlou@zzu.edu.cn
(LOUZheng-ZhengLecturer,Ph.D.at the School of Information Engineering,Zhengzhou University.His research interest covers machine learning,pattern recognition,and computer vision.)
Crowd Counting Using Rank-based Spatial Pyramid Pooling Network
SHI Zeng-Lin1YE Yang-Dong1WU Yun-Peng1LOU Zheng-Zheng1
Crowd counting in videos has an important value in the field of intelligent surveillance.Due to the constraints resulting from camera perspective,uneven distribution of crowd density,background clutter,and occlusions,traditional low-level features-based methods suffer from low counting accuracy.In this paper,a new crowd counting method is proposed based on rank-based spatial pyramid pooling(RSPP)network.In the proposed method,the original image is divided into several sub-regions with the same scope of perspective,and then multi-scale sub-image blocks are respectively taken from different sub-regions.Rank-based spatial pyramid pooling network is used to get the numbers of pedestrians in sub-image blocks.Then summing the numbers of persons of all sub-image blocks gives the total number of people on the image.The proposed image blocking method eliminates the effect of camera perspective and uneven distribution of crowd density on crowd counting.The proposed rank-based spatial pyramid pooling can not only handle multi-scale sub-image blocks,but also solve the problem of huge important information loss and over-fitting encountered by traditional pooling methods.Experimental results show that the proposed method has the advantages of high accuracy and good robustness compared with traditional methods.
Crowd counting,spatial pyramid pooling(SPP),deep learning(DL),convolutional neural network(CNN),ridge regression
10.16383/j.aas.2016.c150663
Shi Zeng-Lin,Ye Yang-Dong,Wu Yun-Peng,Lou Zheng-Zheng.Crowd counting using rank-based spatial pyramid pooling network.Acta Automatica Sinica,2016,42(6):866-874
2015-10-31录用日期2016-04-01
Manuscript received October 31,2015;accepted April 1,2016
国家自然科学基金(61170223,61502432,61502434)资助
Supported by National Natural Science Foundation of China (61170223,61502432,61502434)
本文责任编委柯登峰
Recommended by Associate Editor KE Deng-Feng
1.郑州大学信息工程学院郑州450002
1.School of Information Engineering,Zhengzhou University,Zhengzhou 450002
