基于稀疏MK-LSSVM的高光谱图像不平衡分类
2016-08-16晁拴社楚恒
晁拴社,楚恒
(1.重庆邮电大学,重庆 400065; 2.重庆市勘测院,重庆 400020)
基于稀疏MK-LSSVM的高光谱图像不平衡分类
晁拴社1,2∗,楚恒1,2
(1.重庆邮电大学,重庆 400065; 2.重庆市勘测院,重庆 400020)
针对高光谱图像分类中没有考虑高光谱数据地物种类复杂、数据规模较大以及样本分布不规则而导致的少数类分类精度较低,分类器鲁棒性差的问题,提出一种基于稀疏多核最小二乘支持向量机(Multiple Kernel Least Squares Support Vector Machine,MK-LSSVM)的高光谱图像不平衡分类方法。该方法先用k均值聚类将多数类的训练样本分为k类,然后利用采样技术对每一群组中的样本进行处理与少数类样本均衡,最后建立最MK-LSSVM分类器。该方法对于MK-LSSVM不稀疏的问题,引入了压缩感知理论对其进行稀疏求解。实验表明本文提出的分类方法提高了少数地物的分类精度,同时减少了标准支持向量机训练样本时间消耗大的问题。
高光谱图像;不平衡分类;稀疏MK-LSSVM;压缩感知
1 引 言
高光谱图像(Hyperspectral Image,HSI)数据有着丰富的光谱信息,可以对地物进行精细的光谱分类,所以近年来被应用在军事勘察、矿业勘测、医学检测等多个领域[1]。由于传统的高光谱图像分类方法没有考虑不平衡分类问题,即没有考虑少数类(像素点少的地物类别)与多数类(像素点多的地物类别)在分类上的不同,从而导致少数类分类精度不高的问题[2]。目前针对不同地物类别中像素点数差距较大即数据不平衡的分类问题主要有两种方法:一种是利用合适的采样技术对训练样本进行预处理。采样技术分为欠采样和过采样技术,欠采样技术主要是随机欠采样方法,过采样技术主要运用的是少数类样本合成过采样技术(Synthetic Minority Over Sampling Teachnique,SMOTE);另一种就是设计新的分类方法来解决数据的不平衡分类问题。支持向量机(Support Vector Machine,SVM)是目前解决Hughes现象最有效的分类方法[3],而且在解决高维、小样本分类问题上有很好的分类性能。LSSVM[4]是1999年Suykens提出的一种新的支持向量机,将最小二乘线性系统引入到支持向量机中代替传统的支持向量机直接采用二次规划方法解决分类与函数估计问题[5],简化了标准支持向量机的计算复杂性,适合于处理较大规模的学习问题。但也丢失了标准SVM的稀疏性,使得LSSVM分类平面上的支持向量个数增多,计算复杂度变大。2010年,Jie Yang,Abdesselam Bouzerdoum等[6]提出将压缩感知理论来解决最小二乘支持向量机的欠稀疏性问题。
本文结合采样技术和MK-LSSVM来解决高光谱图像的不平衡分类问题。先用k均值聚类将多数类的训练样本分为k个群组,对聚类后的k个群组与少数类样本数作比较,对聚类后样本数多的群组采用随机欠采样技术,对聚类后样本数少的群组采用SMOTE过采样,然后训练分类器进行高光谱图像的分类。针对高光谱数据分类中的不平衡问题,提出基于稀疏MLLSSVM分类模型,不仅节省了训练样本时间、提高了少数类地物分类精度,而且也使得部分多数类地物的分类精度有所提高。
2 LSSVM
SVM集成了结构风险最小化、凸二次规划和核函数映射等几项技术,有效解决了在经典机器学习中出现的“维数灾难”,但同时SVM计算复杂度高的缺点。LS-SVM采用最小二乘线性系统作为损失函数,简化了标准支持向量机的计算复杂性,适合于处理较大规模的学习问题.最小二乘支持向量机高光谱分类模型可表示为:
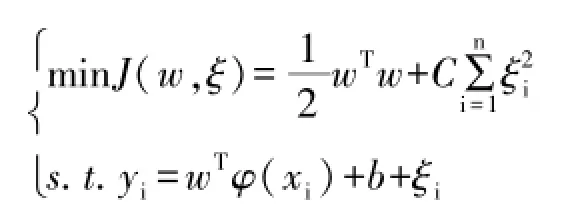
(1)
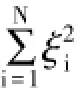
∗ 收稿日期:2015—12—04
作者简介:晁拴社(1989—),男,硕士研究生,主要研究方向:高光谱图像的分类、机器学习。
基金项目:重庆市博士后科研项目(Rc201336)
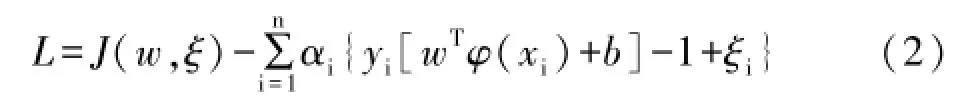
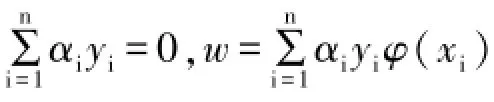
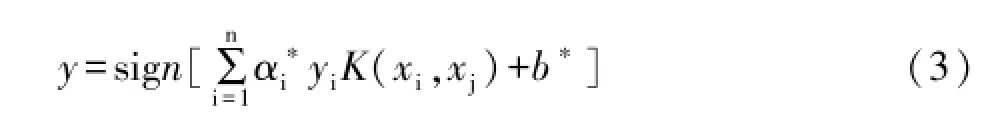
其中K(xi,xj)=φ(xi)φ(xj),α∗i,b∗为(3)式中α 和b的最优解。
3 基于稀疏ML-LSSVM的不平衡分类
本文考虑到高光谱图像数据中多数类与少数类的训练样本数差距过大,在进行训练之前先对训练样本进行预处理。利用SMOTE技术对少数类样本进行过采样,然后对预处理后的样本训练ML-LSSVM分类器,再利用奇异值分解设计一种新的观测矩阵并对原稀疏的ML-LSSVM分类模型进行改进,最后利用改进的稀疏的ML-LSSVM分类模型对测试样本进行分类。
3.1 预处理训练样本
传统的高光谱分类方法没有考虑少数类与多数类在分类上的不同,以LS-SVM为例,为了减少训练误差和增强LS-SVM的泛化能力一般就需要合理的设置式(1)中的C值(惩罚系数)使得在训练误差合理的范围内获取最大的分类间隔(即泛化能力)。但是因为高光谱数据存在不平衡分类问题,使得C值的设置失去意思,所以本文首先将训练样本中的多数类k均值聚类分为m个群,第二部分是对聚类后的k个群组与少数类样本数作比较,对聚类后样本数多的群组采用随机欠采样技术,对聚类后样本数少的群组采用SMOTE技术。SMOTE方法主要思想是在距离较近的少数类样本之间进行插值,产生新的少数类样本,增加少数类样本的数目[7],从而提高少数类样本的分类精度,这里的少数类特指多数类聚类后样本少的群组。设xi为少数类的样本,选择其近邻的k个样本,按照式(4)合成新的少数类样本点yi。
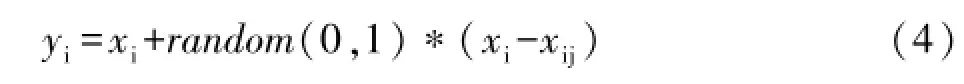
random(0,1)表示区间(0,1)之间的任意数,将新合成的样本添加到原有的少数样本中以均衡训练样本集,然后建立稀疏MK-LSSVM分类模型。
3.2 稀疏MK-LSSVM分类器
为了避免SVM模型中的凸优化问题,本文采用了LSSVM分类方法,但同时也失去了SVM稀疏性特点,使得计算复杂度增加。所以本文提出稀疏MK-LSSVM分类模型进行高光谱图像分类。由上文可知最小支持向量机模型的分类函数中只需要求出α和b便可,已知对w,b求偏微分并令它们等于0,得到约束条件:

带入式(2)也可求出ξi值,所以可以将式(2)写为线性矩阵的形式:
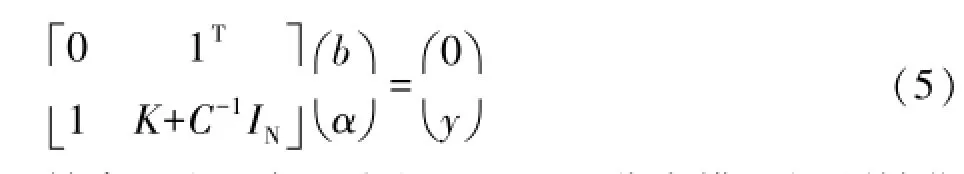
结合上文可知,稀疏LS-SVM分类模型问题转化为利用压缩感知来重构信号的问题。信号的重构是压缩感知理论的核心,E.cande等证明了信号重构问题可以通过求解最小l0范数问题加以解决[9,10]。在信号X稀疏或者可压缩的前提下,求解欠定方程组y=ΦX的问题转换为最小0范数问题[8]。如式(11)所示:
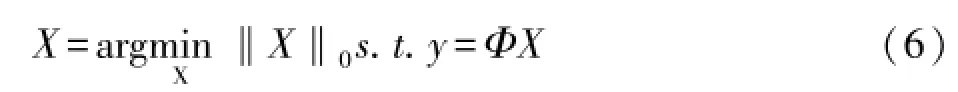
如果直接用贪婪算法对式(11)求解时,因为N太大,计算过于复杂,这时可由压缩感知的第二部分观测矩阵的设计来减少计算量,通过保证采样得到M个观测值,并保证从中能重构出长度为N的信号。可以给左右两边同时乘以采样矩阵(观测矩阵)Φ。观测矩阵Φ∈RM×N(M<<N)是用来对N维的原信号进行观测得到M维的观测向量y,然后可以利用最优化方法从观测值y中高概率重构X。对比式(4)可将其化为:
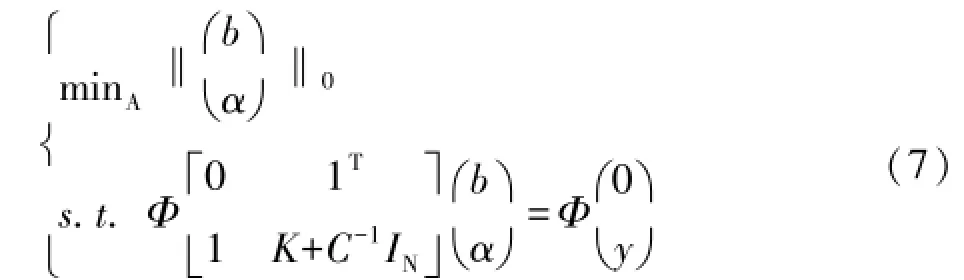
分类中效果较好的径向基核。LSSVM的分类性能受核函数的选择、参数的设置的影响,对样本分布不均衡的高光谱图像分类问题表现一般,特别是对少数类地物的分类效果很差,而且分类模型的鲁棒性较差导致有时部分多数类分类精度也会很低,所以本文利用MK-LSSVM来代替单核LSSVM以解决高光谱图像的地物种类复杂、数据规模较大以及样本分布不规则的而导致的少数类分类精度较差。利用MK-LSSVM来代替单核LSSVM以解决高光谱图像的地物种类复杂、数据规模较大以及样本分布不规则的而导致的少数类分类精度较差,分类器鲁棒性差的问题。与第1部分式(1)的化简过程相同引入拉格朗日乘子,对其求偏微分计算出新的约束条件,最终化简为对偶的形式:
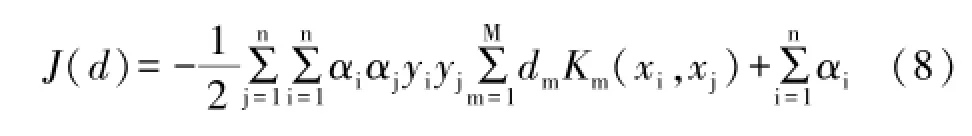
利用LSSVM分类模型中求出α值并固定,则J (d)对dm的微分为:
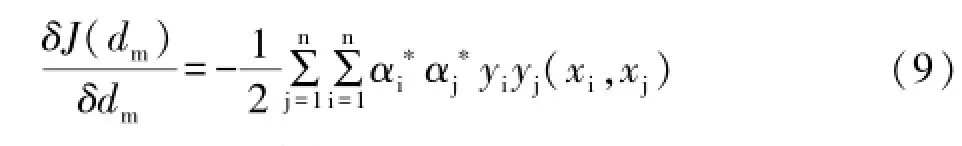
利用梯度下降算法对多核系数进行最优求解。γt为更新步长,可通过一维线性搜索计算得到,Dt为梯度下降方向。通过迭代求出最优dm。

然后将其在带入到式(7)通过贪婪算法比如正交匹配追踪算法(Orthogonal Matching Pursuit,OMP)对式(7)求解[6]。
3.3 设计新的观测矩阵
由上文可知稀疏MK-LSSVM分类模型,但是对于稀疏基和观测基没有做讨论。已知稀疏基,设计新的合适的观测矩阵对分类模型至关重要。
如果稀疏基和观测基不相关,则很大程度上保证了RIP性[9]。CandeS和Tao等证明:独立同分布的高斯随机测量矩阵可以成为普适的压缩感知测量矩阵(即观测矩阵)。同时当观测矩阵Φ与稀疏基矩阵Ψ相干性越小,则所需的训练样本数越少。一般选取随机高斯矩阵为观测矩阵[10~12],受主成分分析启发本文对稀疏基矩阵Ψ进行奇异值分解(Singular Value Decomposition,SVD)Ψ=UΛV,选取前P个奇异值(按大小排列),计算求得对应的UP,转置得到,令作为观测矩阵Φ,由稀疏基矩阵Ψ推出的观测矩阵Φ与其必不相关。令B=Φ∗Ψ,计算均方根误差(IN-BTB的F范数),有实验已表明采用作为测量矩阵的均方根误差比随机高斯矩阵的均方根误差(即F范数)更小,所以将作为观测矩阵。与之前的随机高斯矩阵相比,结合稀疏基矩阵Ψ与新的观测矩阵使用相同的训练样本的稀疏MK-LSSVM具有更好的泛化能力,使得高光谱图像的分类精度更高。
本文提出稀疏ML-LSSVM分类器来解决高光谱图像的分类问题,并且通过稀疏基来设计新的观测矩阵,用于在解决高光谱图像的地物种类复杂、数据规模较大以及样本分布不规则的而导致的少数类分类精度较差,分类器鲁棒性差的问题。
4 实验与分析
4.1 实验
本文实验采用1992年AVIRIS采集印第安纳州西北部的 Indian pines高光谱数据,数据大小、220个波段,去除由于噪声和水汽吸收的20个光谱波段,一般有16种地物覆盖类型。将每一类的10%作为标记样本用作训练共有 1 043个,剩下的90%用作测试。如表1所示,苜蓿、收割牧地、燕麦地的训练样本只有几个,而大豆略耕地的训练样本有几百个,出现不平衡分类问题。多核SVM分类的参数主要包括惩罚系数C、高斯核参数σ从此以及多核权系数dm。在分类时需要预先设置,在本文的实验中,权系数的初始值设置为1/M,M为基核函数个数,C的取值范围设置为{10-4,10-3…,104},利用简单多核学习工具箱SimpleMKLtoolbox通过梯度下降法选择最优dm相对应的核参,C值可通过训练样本的交叉验证获得,最优值为100,权系数的初始值设置为1/M,M为基核函数个数即不同核函数对应核参数个数总和。本文主要比较LSSVM 和ML-LSSVM以及本文提出的稀疏ML-LSSVM 3种方法的分类精度、总体分类精度(Over Accurary,OA)以及各方法的训练时间、Kappa系数等。

每一类别地物的训练样本个数 表1

3种分类方法分类精度、训练样本时间 表2

续表2
因为本文提出的方法比传统的高光谱图像分类方法考虑了不平衡分类问题以及高光谱图像的地物种类复杂、数据规模较大以及样本分布不规则等问题。所以本文首先对多数类预处理,k均值聚类然后对每个类进行采样使其与少数类均衡,然后训练分类器,并且利用稀疏化MK-LSSVM对高光谱图像进行分类。由实验结果可知LSSVM,MK-LSSVM和本文方法对于少数类苜蓿的分类精度分别为36.84,82.86和87.50;收割牧地的分类精度为68.33,80.00和86.05;燕麦地的分类精度为52.75,81.04和86.16,而且如图1黑框/黑椭圆所示本文方法很明显地提高了少数类分类精度。部分多数类地物的精度也有部分提高如表2黑色标注所示,训练样本时间本文方法较LSSVM和MKLSSVM分类方法分别减少171.21(s),291.68(s)。Kappa系数本文提出的分类方法达到0.885高于LSSVM分类的0.736和MK-LSSVM分类的0.807。通过迭代5次,分析聚类个数k对高光谱图像不平衡分类的影响当聚类个数8时总体分类精度趋于稳定。实验结果表明本文提出的分类方法提高了少数类地物的分类精度,同时也提高了部分多数类地物的分类精度以及减少了支持向量机训练样本时间消耗大的问题。
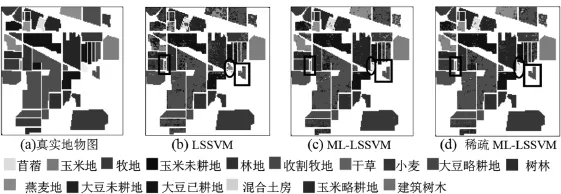
图1 Indian Pines的真实地物图和各分类方法的分类结果
4 结 语
本文提出新的稀疏MK-LSSVM分类方法解决高光谱数据的不平衡分类问题,先将多数类k均值聚类,然后待聚类结束后比较少数类与k个多数类群组的样本数,对样本数多于少数类的群组进行欠采样,反之进行过采样,最后由处理后的样本训练MK-LSSVM模型并且对其进行稀疏。实验表明本文提出的分类方法提高了少数类地物的分类精度,同时解决了支持向量机计算复杂运算速度慢的缺点。尽管不平衡高光谱分类问题可以提高少数类的分类精度,但是也会使一些多数类分类精度有所降低,在接下来的研究中可以联合光谱和空间信息进行高光谱数据的分类。
[1]杜培军,谭琨,夏俊士.高光谱遥感影像分类与支持向量机应用研究[M].北京:科学出版社,2012.
[2]Japkowicz N,Stephen S.The class imbalance problem:A systematic study[J].Intelligent data analysis,2002,6(5):429~449.
[3]Melgani F,Bruzzone L.Classification of hyperspectral remote sensing images with support vector machines[J].Geoscience and Remote Sensing,IEEE Transactions on,2004,42(8):1778~1790.
[4]Suykens J A K,Vandewalle J.Least squares support vector machine classifiers[J].Neural processing letters,1999,9 (3):293~300.
[5]Wu L,Feng Q,Zhang K.Classification of remote sensing image using improved LS-SVM[C].Proc 4th IEEE Conf Photonics and Optoelectronics(SOPO).ShangHai:IEEE Press,2012:1~4.
[6]Yang J,Bouzerdoum A,Phung S L.A training algorithm for sparse LS-SVM using compressive sampling[C].Proc 35th IEEE Conf Acoustics Speech and Signal Processing(ICASSP).Texas:IEEE Press,2010:2054~2057.
[7]Chawla N V,Bowyer K W,Hall L O,et al.SMOTE:synthetic minority over-sampling technique[J].Journal of artificial intelligence research,2002:321~357.
[8]石光明,刘丹华,高大化等.压缩感知理论及其研究进展[J].电子学报,2009,37(5):1070~1081.
[9]CANDES E,TAO T.Never optimal signal recovery from ran-dom projections:Universal encoding strategies[J].IEEE Transaction on Information Theory,2006,52(12):5406~5425.
[10]瞿广财,张淑芬,吕卫等.基于图像分块的Toeplitz结构测量矩阵设计[J].计算机工程,2012,38(16):212~ 214.
[11]史久根,吴文婷,刘胜等.基于压缩感知的图像重构算法[J].计算机工程,2014,40(2):229~232.
[12]邹伟,李元祥,杨俊杰等.基于压缩感知的人脸识别方法[J].计算机工程,2012,38(24):133~135.
The Imbalanced Hyperspectral Image Classification Based on Sparse MK-LSSVM
Chao Shuanshe1,2,Chu Heng1,2
(1.Chongqing University of Post and Telecommunication,Chongqing 400065,China;2.Chongqing Survey Institute,Chongqing 400020,China)
Aiming at the problem that the low classification accuracy of minority classes in classification of complex hyperspectral imagery data,this paper proposed an imbalanced classification method based MK-LSSVM.Firstly,to keep the same size between the minority class and the majority class,this method partitions the majority class into different groups with k-means clustering.After clustering,the proposed method apply sampling techniques to balance every group and minority classes.At last,build MK-LSSVM classifiers and Hyperspectral Image Classification.For the MK-LSSVM model is not sparse,the compressive sensing theory can be introduced to solve this problem.Experimental result on real HIS dataset show that our method can effectively improve the classification accuracy for the minority classes in the imbalance dataset and reduce the consumption time when training model.
hyperspectral Image;imbalance classification;sparse MK-LSSVM;compression sensing
1672-8262(2016)02-69-05中图分类号:TP751.1
A
