一种基于修正倒谱平滑技术改进的维纳滤波语音增强算法
2016-08-06李季碧马永保刘金刚
李季碧,马永保,夏 杰,刘金刚
(重庆邮电大学 信号与信息处理重庆市重点实验室,重庆400065)
一种基于修正倒谱平滑技术改进的维纳滤波语音增强算法
李季碧,马永保,夏杰,刘金刚
(重庆邮电大学 信号与信息处理重庆市重点实验室,重庆400065)
摘要:传统的倒谱平滑维纳滤波算法在求取选择性平滑范围时,噪声会对维纳增益函数的倒谱产生影响,使估计出的选择性平滑范围不正确,进而导致此传统算法在平滑掉音乐噪声的同时也影响了噪声抑制效果。为此提出了一种基于修正倒谱平滑技术改进的维纳语音增强算法,该算法先用最大似然准则估计出纯净语音的倒谱,然后在纯净语音倒谱中求取基频和共振峰的位置,进而得到选择性平滑的范围。该方法提高了选择性倒谱平滑的准确性,进而改善了传统倒谱平滑维纳滤波语音增强算法的噪声抑制效果。最后在不同的噪声场景中对传统算法和改进算法进行了仿真对比,表明该算法能够在去除噪声的同时更好地保留语音的特征结构,较好地提高了带噪语音的质量。
关键词:语音增强;维纳滤波;音乐噪声;增益函数;修正倒谱平滑
0前言
语音增强技术是语音处理系统重要的预处理环节,其目的是从受到噪声干扰的语音信号中提取出纯净的原始语音信号,从而消除噪声的干扰。语音增强技术广泛应用于通信系统、语音识别系统、助听器、可移动设备等领域中,用于提高语音的质量、增强系统的鲁棒性。
基于短时谱估计的语音增强算法具有复杂度低和易于实现的优点,因此被广泛应用。频域维纳滤波技术[1]是一种典型的短时谱估计语音增强算法。此算法在平稳的噪声条件下可以有很好的噪声抑制效果,但是在非平稳噪声的环境中,先验信噪比的错误估计会使维纳增益函数中出现很多异值点,导致在抑制了原有噪声之外又产生了音乐噪声[2],为了抑制这种音乐噪声,文献[3]提出了一种增益函数加权修正的算法,但是此算法严重依赖对噪声和先验信噪比正确的估计。文献[4]提出了一种方法,它的基本思想是:搜索并去除在增强后语音频谱中的一些尖峰。但是这种方法会因为搜索的不准确,影响到语音的频谱,使增强后的语音失真。文献[5]对增益函数的倒谱进行了选择性地平滑,此算法可以较好地去除异值点,从而抑制音乐噪声。此算法是从增益函数的倒谱中提取语音的基因频率,但是由于增益函数的倒谱中有噪声倒谱的干扰,导致直接从增益函数的倒谱中提取基因周期和共振峰的位置不准确,因此在平滑掉异值点的同时也影响其噪声抑制效果。本文采用从最大似然方法估计出的纯净语音中求出基音频率和共振峰的对应的倒谱位置,该方法减小噪声对求取基因周期和共振峰位置时的干扰,提高倒谱选择性平滑的准确性,能在传统算法的基础上更好地保留语音的频谱结构,从而提高噪声抑制的效果。
1基于维纳滤波的语音增强算法
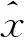
(1)
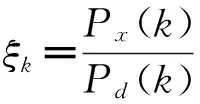
(2)
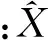
(3)
(3)式中:ξ(k,i)是第i帧第k个频点的先验信噪比;γ(k,i)为对应频点的后验信噪比[6],其中,|Y(k,i)|2,λx(k,i)和λd(k,i)分别为带噪语音信号、纯净语音信号、噪声信号的功率谱。
为了得到(3)式中维纳滤波的增益函数,需要估计出每一帧语音信号的先验信噪比ξ(k,i),本文使用经典的Ephraim和Malah提出的“判决引导法”[7]估计先验信噪比
ξ(k,i)=αξ(k,i-1)+(1-α)max[γ(k,i)-1,0]
(4)
2倒谱平滑技术
文献[5]中提出了选择性倒谱平滑算法。其主要思想为:在倒谱域中语音的信息主要体现在基音频率和共振峰所在的系数,而其他倒谱系数基本不包含语音的信息,所以在增益函数的倒谱域中,将代表语音的基音频率和共振峰的倒谱系数采取轻微地平滑,而在其他地方进行较大程度地平滑,从而最大程度平滑掉增益函数中的异值点,减少非平稳噪声条件下出现的音乐噪声,大致过程如下:

(5)
(5)式中,q表示倒谱的谱线。然后对增益函数进行选择性平滑
(6)
(6)式中,平滑因子β定义为
(7)
最后将平滑后的增益函数转换到频域,得到平滑后的维纳增益函数Gceps(k,i)为
(8)
3修正的倒谱平滑技术
由于直接从增益函数的倒谱中提取基因周期和共振峰的位置不一定准确,所以本文提出了修正的倒谱平滑技术,即从最大似然估计出的纯净语音中求出基音频率和共振峰的对应的倒谱位置,此修正方法减小了噪声对求取基因周期和共振峰位置时的干扰,提高了倒谱选择性平滑的准确性。下面介绍修正的倒谱平滑技术。
首先我们给出增益函数的倒谱与语音倒谱相对应的关系。将维纳增益函数写成(9)式所示的形式,然后对两边取对数可得(10)式,再分别取反傅里叶变换得到(11)式
(9)
(10)
IDFT{log(GW(k,i))}=IDFT{log(X(k,i))}-
IDFT{log(Y(k,i))}
(11)
(12)
(13)
(14)
(15)
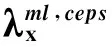
首先,由于无话段没有语音,不存在基音频域和共振峰,因此需要用话音活动检测(voiceactivitydetection,VAD)[9]判决出语音的话音段和静音段,从而去掉在静音段求出的基音频率和共振峰对应的倒谱位置。本文所用的VAD算法流程如下。
(16)
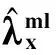
(17)
(18)
(18)式中:qlow=|fs/f0,high|到qhigh=|fs/f0,low|表示语音的基音频率在倒谱域中的位置范围,其中fs是采样率,f0,high,f0,low分别表示语音基音频率的最小值和最大值,⎣*」表示向下取整。再用 (19)式求得基音频率在倒谱中出现位置的范围pitch
(19)
4)通过(20)式、(21)式、(22)式求出语音共振峰在倒谱中出现位置的范围envelope。
(20)
(21)
(22)
(20)式中:fpeaks{*}表示在语音倒谱中找出最大值函数;windowH(q)是低通的窗函数,用来平滑语音的倒谱。(21)式中,H和len分别表示窗长和帧长。(22)式中,Δqpitch是一个小的边界值。
4算法性能的仿真
本文对基于修正倒谱平滑技术改进的维纳滤波语音增强算法进行仿真实现,然后与不经过平滑处理的维纳滤波增强算法和文献[5]中的倒谱平滑的维纳滤波增强算法对比。分别从频域分段信噪比测度[11]、ITU-TP.862的感知语音质量评估(perceptualevaluationofspeechquality,PESQ)测度[12]、CMU的pocketsphinx语音识别系统[13]的识别率测度方面对这3种语音增强算法做了对比。频域分段信噪比的定义为
fwSNRseg=
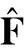
本文中,求先验信噪比时要用到估计噪声的功率谱,我们采用文献[10]中基于MMSE的噪声估计算法估计噪声的功率谱,使用文献[7]中提出的经典的“判决引导”的先验信噪比算法计算先验信噪比。被测试的纯净语料是我们录制的400个短句,然后将这400个短句分别加上来自NOISE92[14]噪声库中不同信噪比的4种代表性噪声,它们分别是白噪声、粉红噪声、工厂噪声和babble噪声,带噪语音的信噪比分别为0 dB,5 dB,10 dB和15 dB。此外,仿真中用到的其他的一些重要参数如下:
1)频域维纳增益参数的相关参数:
len=512;fs=16 kHz;ξmin=-25 dB;α=0.94;
帧与帧之前的叠加为50%。
2)倒谱平滑和修正的倒谱平滑参数:
f0,high=500 Hz;f0,low=200 Hz;Λthr=0.35;
Δqpitch=2。
3)语音识别系统参数:
识别系统: Pocketsphinx-5[15]
声学模型: cmusphinx-en-us-ptm-5.2[15]
语言模型: building by lmtool[16]
注意,这里的声学模型是在纯净语音数据训练得到。
在用最大似然算法估计出的语音的倒谱中,我们用VAD算法找出有话段和无话段,只在有话段求基音频率和共振峰对应的倒谱位置。图1是本文用的基于最大似然先验信噪比的VAD算法的仿真图,图中的带噪语音由2段加了不同信噪比的语音拼接而成,其中前半段语音加了0 dB的babble噪声,后一半语音加了15 dB的babble的噪声。从图1中可以看出,本文提出的VAD算法不仅能准确地找到高信噪比带babble噪声语音的有声段和无声段,而且对带0 dB的babble噪声的语音也能取得较好的VAD结果,因此本文的VAD算法具有一定的鲁棒性,可以准确地删除无话段没有意义的基音频率和共振峰。
然后我们分别用上述3种语音增强算法处理加了不同信噪比噪声的400段带噪语音,分别计算处理后语音的分段信噪比、PESQ,然后输入到待测试的语音识别系统中测试识别率。
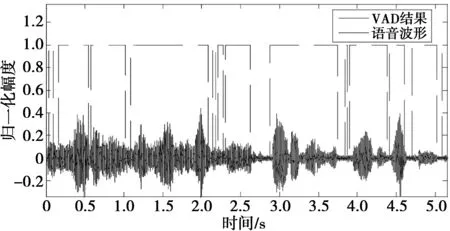
图1 VAD结果图Fig.1 Result of VAD
用3种语音增强算法处理过的语音的频域分段信噪比的结果如图2所示,图2a、图2b、图2c、图2d分别为白噪声、粉红噪声、工厂噪声、babble噪声条件下,3种语音增强算法对语音处理过的频域分段信噪比图。从图3中可以看出,倒谱平滑的维纳滤波与本文改进的算法比原始的维纳滤波算法的频谱分段信噪比高,尤其在低信噪比下比较明显。基本的倒谱平滑与本文修正的倒谱平滑的维纳滤波算法相比,在白噪声和粉红噪声条件下,表现出相近的效果,但是在工厂和babble非平稳噪声条件下,本文提出的方法有较高的分段信噪比,平均高0.61 dB。
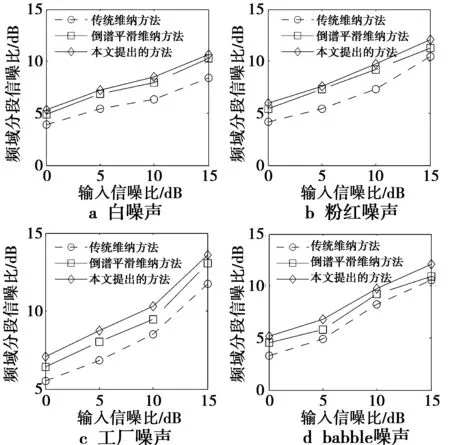
图2 频域分段信噪比对比Fig.2 Comparison of frequency domain SEG-SNR
图3是用3种算法处理过的语音的语谱图的比较。其中,图3a是带0 dB信噪比工厂噪声语音的语谱图,图3b、图3c和图3d分别为维纳滤波、倒谱平滑维纳滤波、修正的倒谱平滑维纳滤波处理过的带噪语音的语谱图。从图3中可以看出,相较于图3b,图3c和图3d在去除了背景噪声的同时,保留了更多的语音的谐波结构,而图3b则有语音的失真。而图3d与图3c相比,图3d进一步保留了较弱的语音段的语音的频谱特征结构,进一步提高了语音的质量。
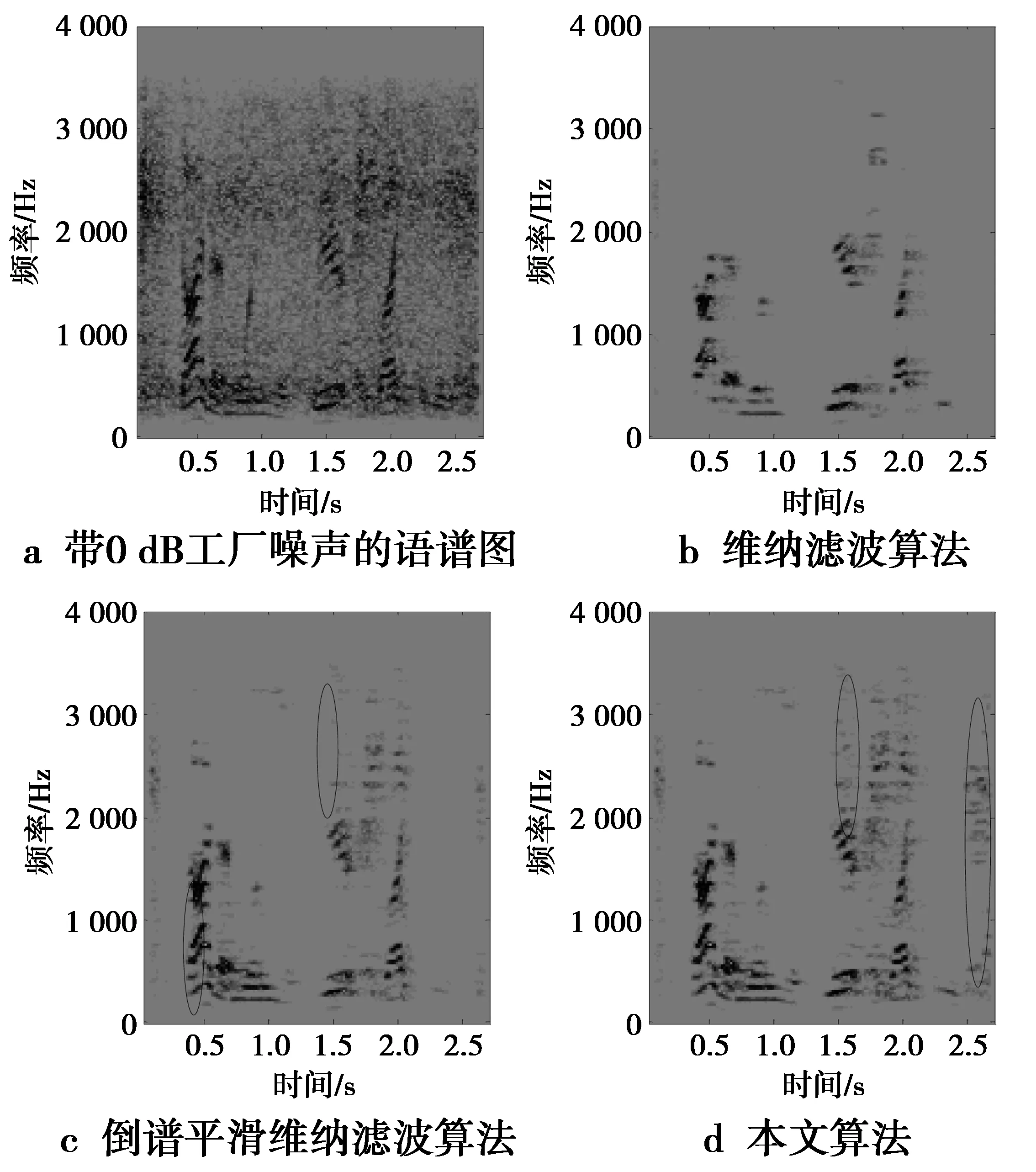
图3 三种增强算法的语谱图比较Fig.3 Spectrogram of the enhanced speeches by three different algorithm
3种不同算法处理后语音的PESQ和语音识别系统的识别率的结果如表1所示,由于基本的维纳滤波在非平稳噪声,如工厂和babble噪声下会对带噪语音过度抑制,导致出现语音失真和音乐噪声,在表1中也表现出了比其他2种算法低的PESQ和识别率的提升,从主观听觉方面,基本的维纳滤波有明显的音乐噪声,而后2种算法无明显的音乐噪声。后2种算法在相对平稳和非平稳噪声的情况下都表现出了不错的效果,其中PESQ大约分别比基本的维纳滤波高了0.1和0.23左右,识别率分别大约分别高了10%和17%。其中,后2种算法相比,本文的算法表现出了略高的PESQ和识别率的提升。
5结论
本文基于倒谱平滑算法,提出了一种基于修正的倒谱平滑技术改进的维纳滤波语音增强算法,用于解决在非平稳噪声情况下,传统基于倒谱平滑的维纳滤波算法因估计选择性平滑范围不准确,而导致的减少音乐噪声的同时噪声抑制效果也不佳的问题。通过仿真实验测试,本算法比维纳滤波和基本的倒谱平滑算法有更好频域分段信噪比、PESQ和语音识别系统识别率得分,且主观听觉上也无明显的音乐噪声。所以本文提出的基于修正倒谱平滑技术改进的维纳滤波语音增强算法在减少音乐噪声的基础上提高了噪声抑制的效果。
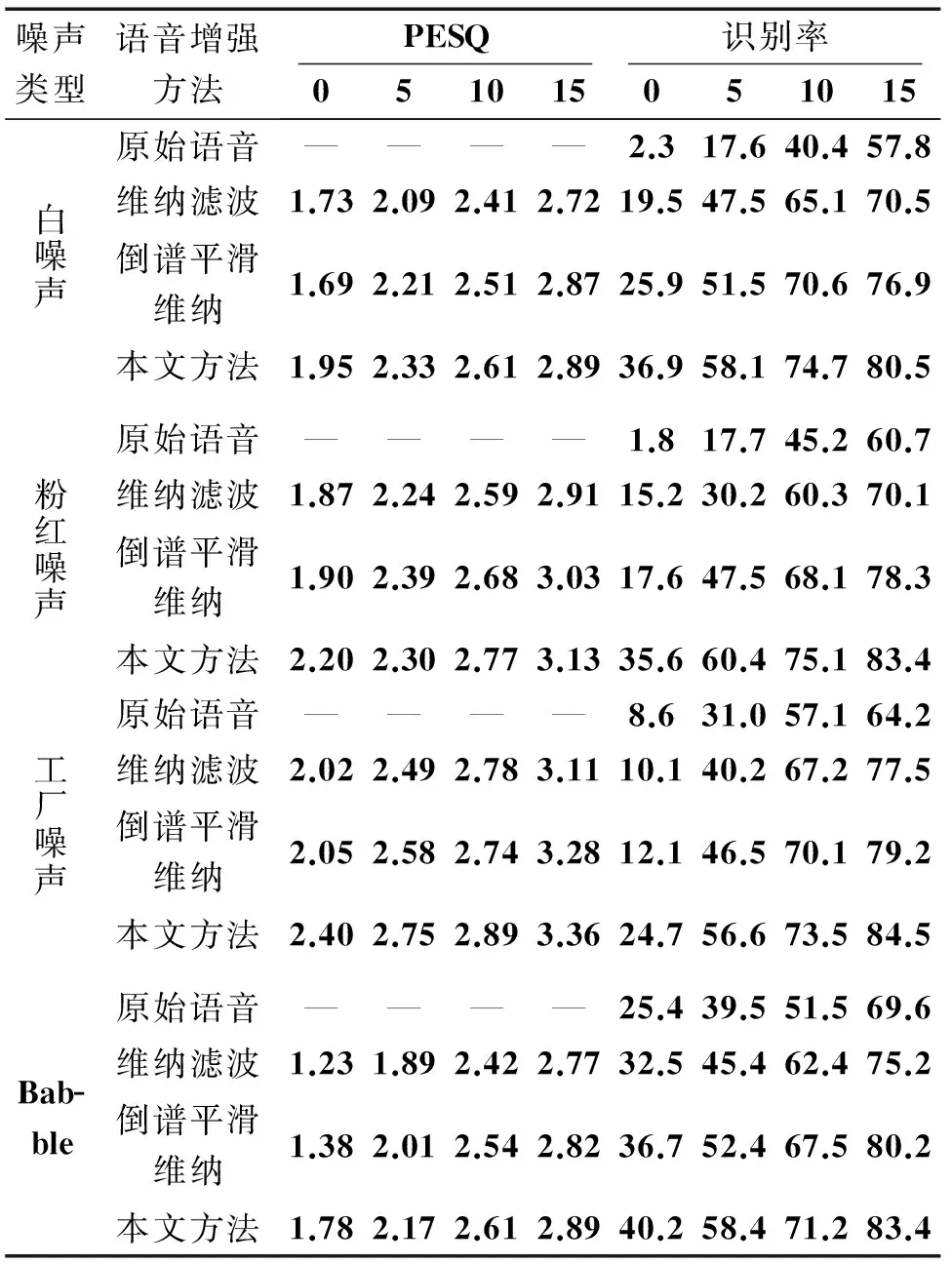
表1 3种算法增强后语音的客观测度比较
参考文献:
[1]WIENER N. Extrapolation interpolation and smoothing of stationary time series[M]. Boston:Technology Press of the Massachusetts Institute of Technology,1950:1043-54.
[2]BEROUTI M,SCHWARTZ R,MAKHOUL J.Enhancement of speech corrupted by acoustic noise[C]//International Conference on Acoustics,Speech,and Signal Processing(ICASSP).London:IEEE Press,1979:208-211.
[3]MALAH D, COX R V, ACCARDI A J. Tracking speech-presence uncertainty to improve speech enhancement in non-stationary noise environments[C]// International Conference on Acoustics, Speech, and Signal Processing (ICASSP). Phoenix, AZ: IEEE Press, 1999: 789-792.
[4]GUSTAFSSON H, NORDHOLM S E, CLASON I. Spectral subtraction using reduced delay convolution and adaptive averaging[J]. IEEE Transactions on Speech, Audio, and Processing, 2001, 9(8):799-807.
[5]BREITHAUPT C, GERKMANN T, MARTIN R. Cepstral smoothing of spectral filter gains for speech enhancement without musical noise[J].IEEE Signal Processing Letters, 2007, 14(12):1036-1039.
[6]LOIZOU P C. Speech enhancement: theory and practice, second edition[M]. Florida: CRC press, 2013.
[7]EPHRAIM Y, MALAH D. Speech enhancement using a minimum mean-square error log-spectral amplitude estimator[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1985, 33(2): 443-445.
[8]BREITHAUPT C, GERKMANN T, MARTIN R. Cepstral smoothing of spectral filter gains for speech enhancement without musical noise[J]. IEEE Signal Processing Letters, 2007, 14(12):1036-1039.
[9]LI Y, WANG T, CUI H, et al. Voice activity detection in nonstationary Noise[J]. IEEE Transactions on Speech, Audio, and Processing, 2000, 8(4):478-482.
[10] TRIBOLET J M, NOLL P, MCDERMOTT B, et al. A study of complexity and quality of speech waveform coders[C]// International Conference on Acoustics, Speech, and Signal Processing (ICASSP). Chicago: IEEE Press, 1978:586-590.
[11] RIX A W, BEERENDS J G, HOLLIER MP, et al. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs[C]// IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP).Salt Lake City, UT: IEEE Press, 2001: 749-752.
[12] CMU RESEARCH GROUP. Open source speech recognition toolkit[EB/OL].[2015-12-07]. http://cmusphinx.sourceforge.net.
[13] HENDRIKS R C, HEUSDENS R, JENSEN J. MMSE based noise PSD tracking with low complexity[C]// IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP). Dallas, TX: IEEE Press, 2010: 4266-4269.
[14] VARGA A, STEENEKEN H J M. Assessment for automatic speech recognition: II. NOISEX-92: A Database and an Experiment to Study the Effect of Additive Noise on Speech Recognition Systems[J]. Speech Communication, 1993, 12(93): 247-251.
[15] CMU RESEARCH GROUP.CMU sphinx download[EB/OL].[2015-12-7].http://sourceforge.net/projects/cmusphinx.[16] CMU RESEARCH GROUP. Language model tool download[EB/OL].[2015-12-07]. http://www.speech.cs.cmu.edu/tools/lmtool.html.
DOI:10.3979/j.issn.1673-825X.2016.04.004
收稿日期:2015-12-10
修订日期:2016-04-01通讯作者:李季碧lijb@cqupt.edu.cn
基金项目:国家自然科学基金项目(61501072);重庆市教委项目( KJ130504)
Foundation Items:The National Natural Science Foundation of China(61501072); The Science and Technology Research Project of Chongqing Municipal Education Commission of China(KJ130504)
中图分类号:TN912.35
文献标志码:A
文章编号:1673-825X(2016)04-0462-06
作者简介:

李季碧(1975-),女,四川开江人,讲师,硕士,主要研究方向为通信信号处理。E-mail:lijb@cqupt.edu.cn。

马永保(1989-),男,甘肃武威人,硕士研究生。主要研究方向为语音增强、语音识别。E-mail:yb_ma@outlook.com。
(编辑:张诚)
An improved Wiener filtering speech enhancement algorithm based on modified cepstrum smooth technology
LI Jibi,MA Yongbao,XIA Jie,LIU Jingang
(Chongqing Key Laboratory of Signal and Information Processing,Chongqing University of Posts and Telecommunications,Chongqing 400065, P. R. China)
Abstract:Because the noise will influence cepstrum of the gain functions when using traditional cepstrum smooth technology, it reduces the performance of noise reduction while suppressing music noise. To solve this problem, we propose a modified cepstrum smooth technology to improve Wiener filter speech enhancement algorithm. In the proposed scheme, we compute the range of selective smooth by using the estimation of clean speech cepstrum which is obtained by maximum likelihood criterion. The proposed method modifies the accuracy of selective smoothing,therefore it improves the noise reduction performance of the traditional cepstrum smooth Wiener filter speech enhancement algorithm. Finally, we simulate the proposed algorithm and compare it with traditional algorithm in different noise scenario. The simulation results show that the proposed algorithm can well reduce the noise and reserve the speech feature structure, so it has a better quality improvement of the noisy speech than traditional algorithm.
Keywords:speech enhancement; Wiener filter; music noise; gain functions; modified cepstrum smooth
