基于时间序列的Openstack云计算平台负载预测与弹性资源调度的研究
2016-08-06李达港金连文黄甘波
李达港,李 磊,金连文,黄甘波,吴 权
(1.华南理工大学 电子与信息学院,广东 广州 510641; 2.世纪龙信息网络有限责任公司,广东 广州 510630)
基于时间序列的Openstack云计算平台负载预测与弹性资源调度的研究
李达港1,李磊1,金连文1,黄甘波2,吴权2
(1.华南理工大学 电子与信息学院,广东 广州 510641; 2.世纪龙信息网络有限责任公司,广东 广州 510630)
摘要:随着云计算技术的发展与运用,云计算在资源的效用比、按需服务等方面优势显著;相对于传统的计算资源构建,云计算凭借其安全性保障、高效的弹性计算资源分配能力、简易的硬件要求等特性,能实现面对不同需求时的计算资源快速弹性构建。基于云计算的弹性资源效用比为研究点,以经典的电信接入随机过程模型—泊松过程为基础,采用相关性时间序列模型对资源预测进行研究,并对相似的多类模型进行仿真与分析;最后以Openstack云平台为基础,结合实际需求对模型进行了工程化实现和初步测试。结果表明,该方法为云计算按需使用和资源弹性构建提供了一种可行的方式,在保证服务等级协议(service-level agreement, SLA)的同时,进一步降低云计算平台的运行损耗,提高资源的效用比。
关键词:时间相关;泊松分布;弹性资源分配;高效用比 ;openstack
0引言
目前云计算已经成为互联网技术和业务支撑的重要基础设施,它使用户能够通过网络按需地从一个共享的、可配置的资源池中获取包括计算、存储、网络等资源[1-3],极大地降低了用户对于基础设施的资源投入,可以快速部署自己的应用,并上线运行。目前关于云计算资源调度和效用比的研究成为当前云计算技术和学术的热点之一,包括用户的资源利用率、资源调度的过程、服务的响应时间和服务队列长度[4-6],其目的在于降低云计算平台运行过程中各种无效的损耗,实现“绿色云”[7-11]。然而文献[5]中论述了在高可用条件下,为了满足任何用户在任意时间不确定的负载,目前以超量资源(所提供的资源大于最大的实际资源需求)方式进行资源的规划成为云计算系统资源规划的一个常见的方式,这种方式的效用比较低,造成资源大量浪费和资源损耗。
基于上述问题,目前降低云计算平台中能源损耗和其他无效损耗的方法主要包括:①关闭云计算平台中空闲状态的主机,进一步减低能源的消耗[12];②基于优化虚拟机调度方法,使得虚拟机在调度上可以进一步保证资源的有效集中[13];③将云计算的虚拟机按照应用的负载压力分为多个状态,即休眠、空闲和忙等状态,并对状态的切换进行优化[14]。
然而上述方法是通过优化虚拟机调度过程减低云计算的平台运行消耗,并没有从按需使用方面来对云计算的资源进行伸缩,从而降低云计算平台的各项无效损耗,提高云计算的资源的效用比。本文的主要贡献包括:①从云计算的本质出发,即everything as a service[15],其本质认为任何资源都是一种服务。以云计算平台提供的服务负载为基础,对其所需的计算资源进行预测,从按需使用方面对云计算平台的资源进行弹性伸缩和调度;②以泊松过程为基础,推演资源预测的数学模型,并对该模型下相似方法进行了类比,说明不同方法之间的有效性,为相关研究提供有价值的基础性研究;③将本文所提出的数学模型在Openstack云计算平台上进行工程化实现,在此过程中依据实际的需求和环境进行了优化和修正,并初步验证了实现效果。
1云计算服务负载相关研究与基础
云计算平台提供的服务本质是互联网的接入服务,在文献[12,14,16-19]中采用了典型电信接入的随机过程模型—泊松过程作为系统资源调度优化的研究基础。
泊松过程是一类最基本的描述随机事件的独立增量过程,将事件发生的时间间隔认为是相互独立的随机变量,等效为一种更新过程[20]。典型的泊松过程表示为
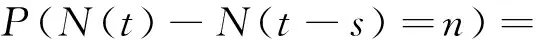
(1)
(1)式中:N(t)为0到t时刻事件发生的数量;λ为事件发生的强度。在互联网接入服务中可以分别看做是t时刻互联网服务的接入数量和接入强度,N(t)-N(t-s)为[t-s,t)时间段内的互联网的服务接入数量的增量。
2基于互联网接入服务数量的时间序列预测模型的研究
互联网服务的接入数量在时间序列上虽然服从泊松过程,并且各个时间段的服务接入数量的增量相互独立,但从人类行为学来看,用户使用互联网服务与其作息时间密切相关,互联网服务请求量在确定时间间隔内的增量并非稳定,而是与时间点密切相关。文献[21]测量了CN域名服务器在48h内的查询请求量,如图1[21]所示。
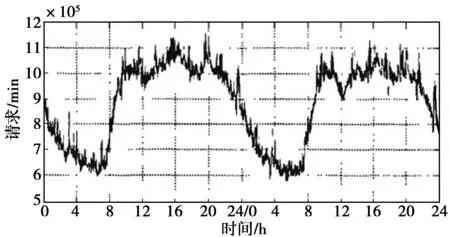
图1 CN域名服务器在2008年11月连续48小时查询请求率分布Fig.1 48 hours request rate distribution on CN domain name server on November 2008
根据泊松过程,即s时间段内的互联网的负载增量服从(1)式,其数学期望为
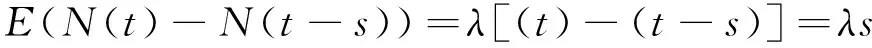
(2)
同时泊松过程的条件期望为

(3)
从(3)式可以得出泊松过程的条件期望等于其泊松过程的期望,本文将E(N(t)|N(t-s))作为互联网接入服务预测的基本数学依据,即下一个时刻互联网接入服务数量的预测等于已知前一个时刻的互联网接入数量情况下的条件期望。
如图1所示,本文假设互联网接入的事件过程是一个具备各态历经性的过程,且与之前多个时刻的互联网接入数量有关,因此有
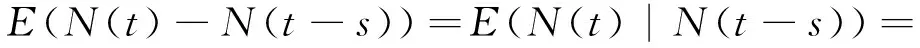
(4)
为进一步体现时间序列的相关性的强弱,一般而言,认为相距较近时间的事件关联性越强,数学描述为

(5)
(5)式中,a(n)为相关系数,表示各个时刻互联网接入数量与预测结果的相关强度。a(n)的数值直接决定了互联网接入数量预测的质量。为了进一步给出不同方法的对比,本文采用了如下方法对a(n)进行设定。
1)自回归模型(autoregressivemodel,AR)线性预测模型方法。AR模型是一种线性预测,即已知n个数据,可由模型推出第m点前面或后面的数据(设推出m+1点),所以其本质类似于插值,其目的为了增加有效数据[22]。本文采用的AR线性模型数学表述式为
(6)
(6)式,中a(n)由Yule-Walker方程依据自相关矩阵得出。
2)时间强度相关模型方法。依据(5)式,同时依据图1表达的数据趋势,本文认为如下假设成立:假设下一个时刻的互联网接入数量与其过去的某一个时间相距最近时刻的事件数量相关性最强,时间相距最长的相关性最弱。因此,本文假定
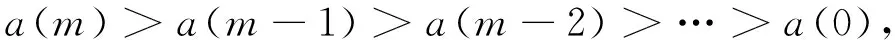

(7)
3)斜率导向模型方法。由图1所示,预测互联网的接入数量主要目的是预测其增长的趋势和强度,由公式E(N(t)-N(t-s))=E(N(t)|N(t-s))可得出,利用斜率导向的预测模型数学描述为
(8)
3资源预测模型的仿真与结果对比
3.1预测算法与原始数据的对比仿真
本文产生一个以正弦波为载波,并且以此为基础调制一组泊松分布随机数据,从而产生一组测试的数据输入,其中数据长度为100个,即在一段时间内的采样点为100次,泊松强度假设为λ=5。
1)AR线性预测模型方法的实验对比。本文采用前5个互联网接入服务数量作为AR模型的输入,与实际服务数量对比结果如图2所示。
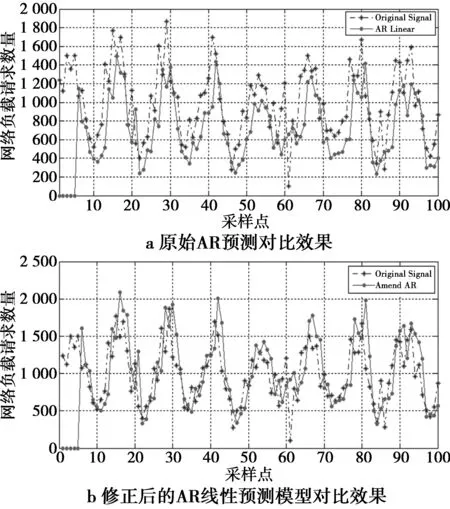
图2 AR线性预测模型的效果对比图Fig.2 Comparison of the effect of AR linear prediction model
从图2a中可以看出,在每个时刻其预测结果相对于真实的互联网接入数量结果偏低。为进行修正,本文引入了加权修正因子b。修正后的AR线性预测模型数学表达式为
(9)
在本实验仿真中,b=1.4。
从图2b可以看出,相对于原始AR线性预测方法,改进后的AR效果在峰值和提前量上有所改进,但对于某些拐点预测结果误差较大。这2种方法都出现对于某些低点预测误差过大的问题。
2)时间强度相关模型方法和斜率导向模型的实验对比,如图3所示。

图3 时间相关模型预测效果对比Fig.3 Comparison of time dependent model prediction
本文同样采用前5个互联网服务数量作为模型的预测,即系数a(0)—a(4)设置为0.6,0.2,0.1,0.07,0.03和0.8,0.1,0.05,0.03,0.02,分别代表时间序列的弱相关和强相关。从图3a可以看出,在时间强度相关模型中强相关和弱相关在预测效果上接近,说明在系数归一化的条件下,系数的设置对于各历经性的随机过程影响较小,整体而言预测结果与实际数据匹配较好。
在斜率导向模型方法中,为了进行类比,本文同样采用前5个互联网服务负载作为输入预测后一个负载数量,即设定2组系数0.6,0.2,0.1,0.07,0.03和0.8,0.1,0.05,0.03,0.02代表互联网服务负载的数量变化斜率时间序列的弱相关和强相关。从图3b可以看出,在斜率导向模型强相关性模型中最大值和最小值的预测上出现明显的过冲现象。与弱相关性预测模型对比,强相关性在数据的突变上反应较慢。
3.2各个预测算法之间的效果对比说明
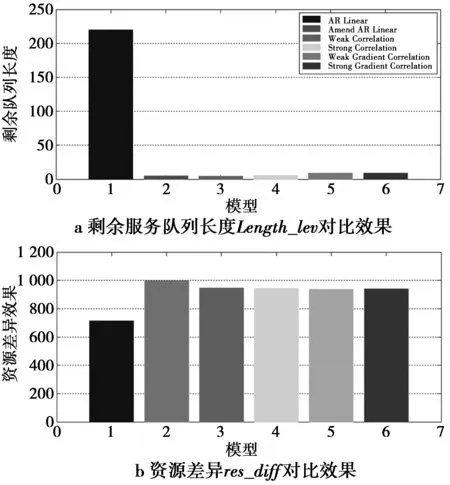
由于直观上难以对各个预测模型的结果直接进行对比说明,因此,为了进一步得到各个预测算法之间有效性,本文依据真实的云计算平台结构设计以下2个评测指标。
1)队列剩余任务数。在文献[12,14,16-19]中均认为云计算平台为队列模型处理模型,即互联网服务遵循先到先服务(firstcomefirstservice,FCFS)[21],因此,为了评估预测模型的效果,本文定义相同时间段后云计算平台中任务队列长度(剩余未处理的任务)Length_lev作为评测指标。Length_lev越大,说明以该模型为预测方法的弹性预测质量较差,其具体的过程包括以下步骤:①依据真实的云计算服务情况设定初始计算服务资源数,该变量定义为init_res。一般而言,租户都会预先启动一定资源的虚拟机作为服务的首次计算资源配置;②假设一个计算单位的计算能力为C,即处理一个计算单位可以处理C个服务,本文实验设定为100。其数学描述为
Length_lev=Length_lev(before)+
input/C-predict/C
(10)
(10)式中,当Length_lev(before)<0时,Length_lev(before)=0。Length_lev(before)是前一个时刻的服务队列长度的数量,input是当前时刻互联网接入数量,predict是上一个时刻对当前时刻的接入数量预测。当tn 2)计算资源单位数量误差。为了进一步对预测的质量进行对比,本文同时定义了资源准确度,即实际所需的计算单位的数量和所预测的计算单元数量差异的总和—res_diff。其数学描述为 res_diff=res_diff(before)-input/C+predict/C (11) (11)式中,res_diff(before)是前一个时刻的计算资源单位数量误差。各预测模型在这2个标准下的效果对比如图4所示。 图4 各个预测模型的对比效果Fig.4 Contrast effect of different forecast models 从图4中可以看出,经过一段时间后,未改进的AR线性模型预测模型的剩余服务队列最长,约为其他预测模型剩余服务队列长度的20倍;但在资源的差异方面最小,说明未改进的AR预测模型预测的结果总是低于实际的互联网接入服务数量,经过一定时间后造成剩余服务队列长度最长,同时每个时刻与实际数值差值相对最小,因此资源差异最小;而由于未改进的AR线性模型预测模型的剩余的服务队列最长,无法保证其SLA。同时其他预测模型在剩余的消息队列长度上接近,说明在某些时刻预测结果大于实际数量,但差值都小于10,说明所调度的计算资源能较好地满足接入服务的计算资源需求,可以保证SLA;另外,除了改进的AR预测模型,其他预测模型在资源差异上数值接近,说明这些模型在预测的资源与实际需求上,其效果和质量接近,同时相对于未改进的AR预测模型,资源准确度相对误差均在30%内,差值并未出现如剩余服务队列长度那样极高的差异;在计算复杂度上,AR线性预测模型>斜率导向模型>时间强度相关模型。综合考虑本文采用时间强度相关模型作为Openstack平台的弹性资源预测系统的基础模型。 4基于Openstack平台的弹性资源预测调度系统的实现 Openstack[23]是由Rackspace 和美国国家航空航天局共同开发的云计算平台。 从IceHouse版本开始除了包括了6个主要的核心子工程:Nova—提供虚拟主机的调度、创建和删除和简单网络资源管理功能;Cinder—提供网络的块存储设备;Glance—提供创建虚拟主机所需的镜像注册、存储和删除功能;Swift—提供对象方式的分布式存储功能;Keystone—服务权限的验证、用户信息注册、修改、删除和相关服务权限管理功能;Horizon—基于Django架构的Web服务,提供面向终端用户的网页操作管理功能;还提供了包括NaaS(network as a service)—Neutron工程提供用户定义网络的服务,监控工程—Ceilometer工程,提供资源的监控服务,按照模板启动虚拟机工程—Heat工程,按照用户自定义的规则和模板批量动态扩展虚拟机资源。 4.1基于Openstack云计算平台的资源预测与弹性调度设计 本文以Heat工程为参考,直接采用了各个相关工程的API进行资源预测和弹性调度模块的开发。其架构如图5所示。 图5 基于Openstack的资源预测与调度云计算平台架构Fig.5 Cloud computing platform architecture for resource prediction and scheduling based on Openstack 本文在原有虚拟机管理上增加虚拟机加入集群的预备状态和退出集群继续执行任务的待关闭状态(在此状态下的虚拟机继续执行任务),如图6所示。 图6 弹性集群虚拟机管理Fig.6 Structure of elastic cluster virtual machine management 同时在实际环境中,需要考虑监控信息获取的便利性和虚拟机负载的稳定性(一般位于50%—80%),在工程化资源预测和弹性调度系统的过程中做了如下的修正和优化。 1)对现有系统内的每个虚拟机的负载进行预测,结合公式(5),第k个虚拟机的负载预测为 (12) 2)第i个时刻,系统内虚拟机的平均负载为 (13) 本文以Load_Avg(i)作为资源扩展的依据,设置上、下2个阈值。当Load_Avg(i)大于上阈值时,扩展虚拟机计算资源;当Load_Avg(i)低于阈值时,收缩虚拟机资源,具体流程如图7所示。 图7 资源预测与弹性资源调度策略流程图Fig.7 Resource prediction and flexible resource scheduling strategy flow chart 4.2系统初步实验结果 本文通过LoadRunner并发测试工具来模拟多个用户同时访问应用服务,以每隔10 s改变并发用户的递增速度模拟对应用服务的访问压力,资源预测和弹性调度集群使用的虚拟机类型为2VCPU,2GByte内存的配置,时间窗口m取值为5,同时设定触发集群扩展策略的集群平均负载阈值为80,触发集群收缩策略的平均负载阈值为30。 如图8所示为资源预测和弹性调度集群扩展时虚拟机负载曲线图,随着用户的并发连接数量不断增大,弹性集群的平均负载不断增高,集群中的虚拟机的互联网接入服务数量增加超过一定阈值时,系统会自动增加一台虚拟机作为资源的弹性扩展;当互联网接入服务数量下降到一定数值,在虚拟机的内部负载接近0时,关闭其中一台虚拟机,另外一台虚拟机的内部负载会出现少量的提高,将关闭的虚拟机处理能力接管过来。 实验结果可以看出,弹性伸缩策略可以很好地适应互联网接入服务数量的变化,保障良好的服务质量。当用互联网接入服务数量上升时,集群也可以随之扩大规模;当互联网接入服务数量下降时,集群也可以随之收缩规模;使用户的计算资源更多地用在应用服务上,提高资源的效用比,资源收益得到提高。 图8 资源预测和弹性调度集群扩展时虚拟机负载曲线图Fig.8 Resource prediction and flexible scheduling cluster expansion virtual machine load curve 5总结 经过实践和实际运行,本文完成了既定的2个目标:①从互联网接入服务负载的过程出发,提出了基于泊松过程的资源预测模型,并对相关的理论做了研究和仿真;②以Openstack平台为基础,结合实际的条件和需求,对理论的模型进行优化和修正,初步实现了模型的工程化。本文为云计算平台资源弹性和高效用比使用提出一种可行的数学模型和实现方法,展示了理论和工程化结合的过程。下一步的工作我们将进一步对模型进行优化和修正,并结合调度的颗粒度,进一步提高云计算按需使用和资源的效用比。 参考文献: [1]WANG L, LASZEWSKI G V, YOUNGE A, et al. Cloud computing: A perspective study[J]. New Generation Computing, 2010, 28(2):137-146. [2]SOTOMAYOR B,MONTERO R S,LORENTE I M,et al.Infrastructure Management in Private and Hybrid Clouds[J].IEEE Internet Computing,2009,12(5):14-22. [3]MELL P, GRANCE T. The NIST definition of cloud computing (draft)[J]. NIST special publication, 2011,80(145): 7-15. [4]RUYYA R,YEO C S,VENUGOPA S, et al. Cloud computing and emerging IT platforms: vision, hype, and reality for delivering computing as the 5th utility[J]. Future Generation Computer Systems,2009,25(6):599-616.[5]ARMBRUST M A, FOX R, GRIFFITH R, et al. Above the clouds: A Berkeley view of cloud computing[J]. Eecs Department University of California Berkeley, 2009, 53(4):50-58. [6]XIONG K, PERROS H. Service Performance and Analysis in Cloud Computing[J]. World Conference on Services-i, 2009(13), 1:693-700. [7]LEE Y, ZOMAYA A Y. Energy efficient utilization of resources in cloud computing systems[J]. J Supercomput, 2012, 60(2): 268-280. [8]BElOGLAZOV A, BUYYA R, LEE Y, et al. A taxonomy and survey of energy-efficient data centers and cloud computing systems[J]. Advances in Computers, 2011, 8(3):47-111. [9]PAWAR C, WAGH R. Priority Based Dynamic Resource Allocation in Cloud Computing with Modified Waiting Queue[C]//In Proc. IEEE International Conference on Intelligent Systems and Signal Processing (ISSP). Gujarat, Pakistani: IEEE Press, 2013:311-316.[10] 周相兵.一种基于粒子群优化的虚拟资源分配方法[J].重庆邮电大学学报:自然科学版, 2014, 26(5):686-693. ZHOU Xiangbing. An optimization approach of virtual resources allocation base on particle swarm algorithm[J]. Journal of Chongqing University of Posts and Telecommunications: Natural Science Edition,2014,26(5):686-693.[11] 史少锋,刘宴兵.基于动态规划的云计算任务调度研究[J].重庆邮电大学学报:自然科学版,2012,24(6):687-692. SHI Shaofeng, LIU Yanbing. Cloud computing task scheduling research based on dynamic programming[J]. Journal of Chongqing University of Posts and Telecommunications:Natural Science Edition,2012,24(6):687-692.[12] BIANCHINI R, RAJAMONY R. Power and Energy Management for Server Systems[J]. Computer, 2004, 37(11): 68-74. [13] HUANG W, LI X, QIAN Z. An Energy Efficient Virtual Machine Placement Algorithm with Balanced Resource Utilization[C]//In Proc. IEEE Seventh International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing. USA: IEEE Press,2013:313-319. [14] CHIANG Y, OUYANG Y, HSU C. An Efficient Green Control Algorithm in Cloud Computing for Cost optimization[C]∥IEEE Transactions on Cloud Computing, Taichung, China: IEEE Press, 2015, 3(2):145-155. [15] SUN Y, XIAO Z, BAO D, et al. An Architecture Model of Management and Monitoring on Cloud Services Resources[C]//In Proc. IEEE 3rd International Conference on Advanced Computer Theory and Engineering (ICACTE). Chengdu, China: IEEE Press, 2010,3:207-211. [16] RANJAN R,ZHAO L,WU X,et al.Peer-to-peer cloud provisioning:Service discovery and load-balancing[J].Computer Communications & Networks,2010,12(2)195-217. [17] ZHANG M, HOU Z. M/G/1 queue with single working vacation[J]. Applied Mathematics and Computing, 2012, 39(1):221-234. [18] WANG K,HUANG H.Optimal control of an M/Ek/1 queueing system with a removable service station[J].Operational Research Society,1997,48(9):936-946.[19] CHIANG Y, OUYANG Y, HSU C. An Optimal Cost-Efficient Resource Provisioning for Multi-Servers Cloud Computing[C]//In Proc. IEEE International Conference on Cloud Computing and Big Data(CloudCom-Asia).Fuzhou,China:IEEE Press,2013:225-231. [20] Wikipedia. Poisson distribution[EB/OL]. (2016-03-30) [2015-10-09]. https://en.wikipedia.org/wiki/Poisson_distribution. [21] 尉迟学彪,李晓东,阎保平,等. DNS服务中的Internet访问行为测量研究[J].计算机工程与应用, 2009, 34(1):85-88. YUCHI Xuebiao, LI Xiaodong, YAN Baoping, et al. Internet usage measurements in DNS services[J]. Computer Engineering and Applications, 2009, 34(1):85-88. [22] Wikipedia. ARMA [EB/OL]. (2016-03-31) [2016-04-01]. https://en.wikipedia.org/wiki/Autoregressive%E2%80%93moving-average_model. [23] BELL T. OpenStack Documentation[EB/OL]. (2016-04-01) [2016-04-06]. http://docs.openstack.org/. DOI:10.3979/j.issn.1673-825X.2016.04.018 收稿日期:2015-12-30 修订日期:2016-04-20通讯作者:李磊eelilei@scut.edu.cn 基金项目:国家科技支撑计划(2013BAH65F01-2013BAH65F04);广东省工业高新技术领域科技计划项目(2013B010202004);广东省应用型科技研发专项(2015B010131004) Foundation Items:The National Key Technology Support Program(2013BAH65F01-2013BAH65F04); The Guangdong Science and Technology Project(2013B010202004);The Guangdong Science and Technology Research Plan(2015B010131004) 中图分类号:TP13 文献标志码:A 文章编号:1673-825X(2016)03-0560-07 作者简介: 李达港(1991-),男,广东佛山人,硕士研究生,主要研究方向为云计算、分布式系统、性能评估、机器学习和大数据。E-mail:eric.lee.ltk@gmail.com。 李磊(1983-),男,云南昆明人,博士研究生,工程师,研究领域包括云计算、最优控制算法、性能评估、机器学习和绿色云计算系统。E-mail:eelilei@scut.edu.cn。 (编辑:田海江) Research of load forecasting and elastic resources scheduling of Openstack platform based on time series LI Dagang1, LI Lei1, JIN Lianwen1, HUANG Ganbo2, WU Quan2 (1. School of Electronic and Information Engineering, South China University of Technology, Guangzhou 510641, P.R.China;2. 21CN, Guangzhou 510630, P.R.China) Abstract:With the rapid development of cloud computing, cloud computing outperforms in aspects of providing high utility ratio and on-demand resources. Compared with traditional computing resource construction technology, cloud computing, which provides better security levels, higher elastic resource allocation capability and lower hardware requirements, can satisfy the need of fast resource allocation. We focus on one of the researching hot spot of cloud computing, elastic resource effectiveness ratio, and use the time series correlation based on network access probability distributions, Poisson distribution, to analyze and simulate different related models. Finally, based on Openstack cloud computing platform, the model has been developed, which is suitable for the real environment. We also have tested the platform and got some useful results. The results show that the way we provided is a feasible way to improve the cloud computing resource utilization ratio and guarantee service-level agreement(SLA). Keywords:time correlation; Poisson distribution; elastic resources allocation; high effectiveness ratio; openstack