基于TCAM的并行路由查找方案综述
2016-08-05李晓歌秦董洪
王 辉 李晓歌 张 宾 秦董洪
1(河南牧业经济学院自动化与控制系 河南 郑州 450000)2(中国解放军理工大学总参第63所 江苏 南京 210007)3(广西民族大学信息科学与工程学院 广西 南宁 530006)
基于TCAM的并行路由查找方案综述
王辉1李晓歌1张宾2秦董洪3
1(河南牧业经济学院自动化与控制系河南 郑州 450000)2(中国解放军理工大学总参第63所江苏 南京 210007)3(广西民族大学信息科学与工程学院广西 南宁 530006)
摘要基于三态内容寻址存储器TCAM(Ternary Content-Addressable Memory)的路由查找方案是目前高性能路由器进行路由查找时普遍使用的方案,但这种方案仍存在查找速度、功耗和更新效率方面的挑战。因此,学者们提出了各种并行TCAM的解决方案以提高查找速度、降低功耗和增强更新效率。归类总结目前的并行TCAM路由查找方案,剖析它们的优缺点,指出目前这些方案仍存在的不足,并探索相应的解决方案。
关键词并行TCAM路由查找功耗地址划分
0引言
网络组织认为在一般的处理器上达到G数量级的路由查找不太可能。由于路由查找需要进行地址最长前缀匹配,所以一般认为要达到G数量级的查找速度需要硬件的支持。另外既然路由查找是一种慢和复杂的操作过程,人们自然就想到一些技术来避开这些操作,其中一个想法是在IP层下实现各种链路层的交换技术,如基于虚电路技术的ATM技术,基于标签技术的MPLS等。它们都想避开或减少路由查找,但这反而增加了网络的复杂性和冗余度,给网络带来不必要的负担,降低了网络的效率。既然链路层交换和IP层路由完成相同的功能,所以只用它们中的一种来处理将会更加简单。另一种思路使用缓存技术,这种技术缓存的命中率比较高,然而随着因特网的快速增长,增加了缓存所需要的空间,这种方法所要求的硬件缓存可能很不经济。
现在我们重新回到路由查找的思路上,目前高性能路由器中的路由查找方案大致分两类:一类是基于Trie树的软件方案,另一类是基于TCAM的硬件解决方案[1]。传统的路由表实现使用Trie树,有很多优化能减少Trie树的存储空间并且加快查找速度,然而这种数据结构仍然太大而不能满足要求,以致路由表不能装入芯片缓存中而支持不了G级路由查找速度。另外,基于Trie树的方案在进行路由查找时经常需要几次的存储器访问,虽然有很多方法来减少访问次数[2-4],但这类使用DRAM或SRAM的软件方案由于其本身的特点很难更快地提高路由查找速度。
相比之下,TCAM由于其自身的并行访问特性使其能在一次访问完成路由查找,而且基于TCAM的硬件方案在更新上要比基于Trie树的软件方案简单,所以TCAM方案在高性能路由器的发展中取得越来越多的应用。TCAM是一种三态内容寻址存储器,主要用于快速查找ACL、路由等表项,它是从CAM的基础上发展而来的。一般的CAM存储器中每个bit位的状态只有两个,“0”或“1”,而TCAM中每个bit位有三种状态,除掉“0”和“1”外,还有一个“don’t care”状态,所以称为“三态”,它是通过掩码来实现的,正是TCAM的这个第三种状态特征使其既能进行精确匹配查找,又能进行模糊匹配查找,而CAM没有第三种状态,所以只能进行精确匹配查找。
TCAM具有查找速度快、操作简单的优点。然而,这类基于TCAM的路由查找方案面临如下挑战:
• IP 前缀是变长的而到来的数据包并不携带前缀长度信息,所以在进行路由查找时会匹配到多个地址前缀而应该选择最长的那个地址前缀 (LMP)。
• 光纤技术的发展使核心路由器要处理 40 Gbps或更高的线速,而最新的18 MB TCAM只能达到266 MHz的处理速度,每秒只能完成 133 millions次的查找, 远远跟不上40 Gbps的线速[5]。
• 路由表表项以大约每年10~50 k的速度在增长[6],特别是当IPv6广泛部署后,需要TCAM要有更大的存储空间。
• TCAM在进行路由查找时需要消耗大的功耗和散发大的热量,如何降低功耗减少热量也是查找引擎需要考虑的重要问题。
• 频繁的更新要消耗查找引擎大量的计算而降低了查找的效率,所以如何进行高效的更新也是要考虑的重要问题。
归纳起来,这些挑战需要基于TCAM的查找引擎解决如下三方面的问题:
• 查找速度
• 功耗
• 更新效率
基于这三个问题,人们提出了并行的TCAM解决方案。但目前据我们所知,并没有一篇文章对这些工作进行归类、梳理和分析。为了填补这个空白,调研了各种不同的并行TCAM解决方案并分析它们各自的优缺点。并针对目前仍存在的问题提出了可能的改进方案,为进一步对基于TCAM进行并行路由查找算法的研究奠定了一定基础。
1基于端口的并行方案
基本思想是将路由表项按输出端口进行划分,具有相同输出端口的路由表项放在一个表中,每个表都用一个独立的TCAM进行存储,所以并行的TCAM数和输出端口数相同。其体系结构如图1所示[7]。
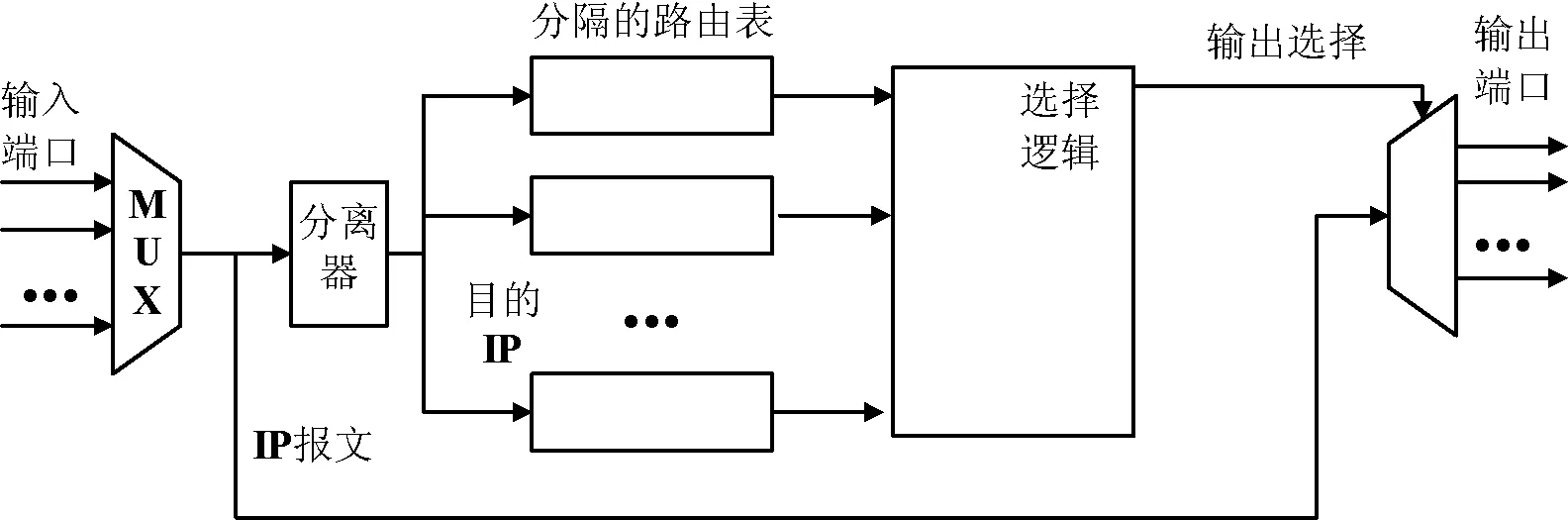
图1 基于端口的并行TCAM体系结构
当包到来时,所有并行的TCAM都要进行一次查找并输出所有匹配的表项,然后送入选择逻辑中,由选择逻辑选定最长的匹配前缀并输出其输出端口。
由于每个TCAM中的路由表项有相同的输出端口,所以每个TCAM内部的路由表项不需要进行排序。进行路由表项的插入操作时,只需要查看路由表项的输出端口号,然后插入相应表的空余的表项中即可,删除时直接删除即可,都不需要移动表项,所以更新时间复杂度可以达到O(1)。这种方案提高了TCAM的更新效率。
这种方案虽然提高了更新效率,却为此付出很大代价。首先由于所有TCAM都需要为一次路由查找进行并行查找,效率低功耗大。其次每个端口需要的路由表项数目可能相差很大而且不可预知,所以会造成很大的空间浪费。再者若端口很多则会需要很多的TCAM,不实际且扩展性差。最后它增加了选择逻辑的复杂性。
2基于无子孙关系前缀集合的并行方案
基本思想:若一个集合中的所有地址前缀无子孙关系或不为互为前缀关系(我们称这种关系为disjoint),则集合中所有前缀所包含的地址范围映射到一维地址空间上无地址重叠关系,所以在进行地址查找时这个集合至多只有一个匹配项。经过调研目前路由表的前缀Trie树一般不超过7层(包括*),如果把转发表分到不同的TCAM中,使每个TCAM中的地址前缀为disjoint关系,则这些TCAM在查找时至多只有一项匹配,所以这些TCAM就不需要优先编码逻辑。图2表示了这种方案的体系结构[8]。
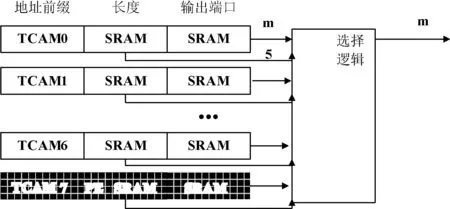
图2 基于无子孙关系前缀集合的并行TCAM体系机构
TCAM0 到 TCAM6 包含了disjoint集合的地址前缀, 不需要priority encoder logic(PE)。TCAM7仍用了一个普通的带PE的TCAM,原因是在更新时有可能到来的地址前缀和前6个TCAM中的任一个前缀集合都无disjoint关系,则插入TCAM7中。由于TCAM7中的PE逻辑,它里面的地址前缀无限定条件,TCAM7输出最长前缀匹配。
此方案TCAM更新的时间复杂度为O(1),提高了TCAM的更新效率,而且需要的并行TCAM数量固定。但这种方案也存在类似前一个方案中一些较大的缺陷。首先由于所有TCAM都需要为一次路由查找进行并行查找,效率低功耗大。其次每个TCAM中路由表项数目可能相差很大,所以会造成很大的空间浪费。最后增加了选择逻辑的复杂性。
3基于CoolCAMs技术的并行方案
为了减少TCAM的功耗,有一种机制可以只访问整个TCAM的一小部分,这些被划分的区域称为blocks,CoolCAMs的思想就是把转发表划分成多个子表称之为buckets,每个bucket部署在一个或多个TCAM的block上,在进行路由查找时只触发相应bucket对应的blocks即可。目前有三种bucket划分方案:
• 基于Trie树划分
• 基于地址位划分
• 基于地址范围划分
基于这三种划分方案并使用CoolCAMs技术有三种并行的TCAM方案,下面分别对它们进行介绍。
3.1基于Trie树划分的并行TCAM方案
首先由转发表构造二进制Trie树,然后进行划分,存在两种划分方法:1) Subtree splitting;2) Post-order splitting。具体如何划分不再详述。此方案在第一阶段的查找过程中需要用一个小的index TCAM来保存前缀Trie树,当一个包到来时,先通过它找到bucket ID的索引,这个索引指向的SRAM包含真正的ID号,由ID号触发相应的TCAM对应的blocks进行第二阶段的查找。第一阶段相当于逻辑判断。其体系结构如图3所示[9]。
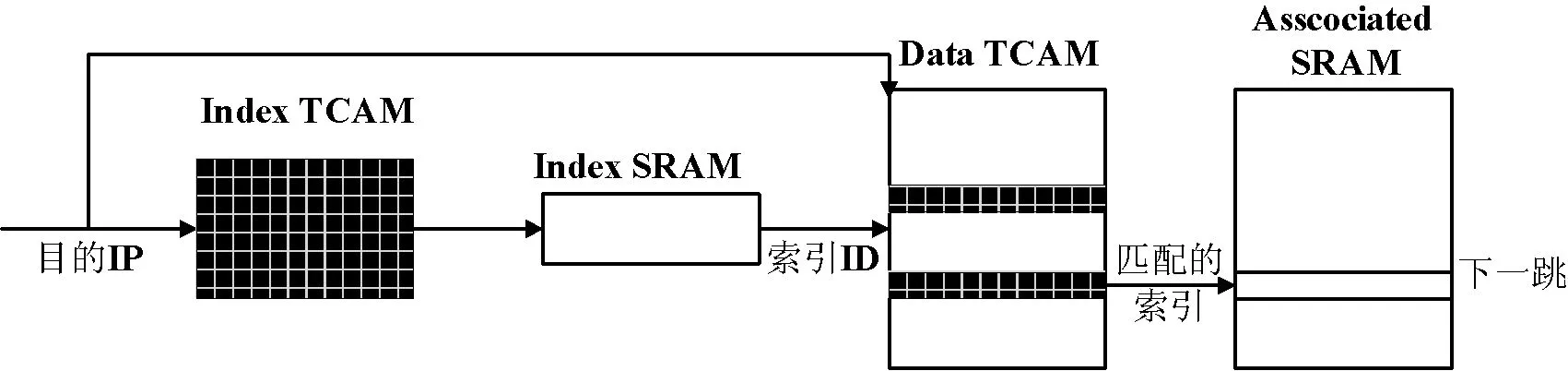
图3 基于Trie树划分的并行TCAM体系机构
这种方案相比于前两种可以使一次路由查找只在一个并行的TCAM中进行,这样就有可能为到来的包进行并行查找,而且由于使用CoolCAMs技术可以只触发TCAM中相应的blocks进行查找,查找效率高功耗小。不足之处是首先进行划分的时间复杂度是O(N + NW/b)。其中W是最大的前缀长度,O(N/b)是被砍掉的子树数目。再者划分的最大和最小bucket size相差两倍,另外还需要一个index TCAM存储Trie树并且每次查找都要访问此TCAM,会增加一些功耗。最后此方案的更新效率较低O(N + NW/b),除了进行data TCAM的更新,还要进行index TCAM的更新。
3.2基于地址位划分的并行TCAM方案
这种方案[10,11]面临的一个很大的挑战是如何选择地址前缀中的位使得划分得到的分区中的地址前缀数尽量平均,以及如何将这些分区放入TCAM使每个TCAM中的Traffic Load尽量平均,使查找效率尽量高功耗尽量小的问题。下面介绍Zheng 等提出的方案[10]。
他们分析了IPMA提供的路由表发现地址前缀的某些特定位可使它们比较平均的分布,他们用地址前缀的10~13位作为ID号,把路由表划分成16组,但如何把这16个分区放入TCAM中又是一个待解决的难题。一种思路是每个TCAM多放一个冗余的分区,当包到来时如果这个包匹配的分区在两个TCAM中都有,选择逻辑会选择输入队列较少的那个TCAM。另一种相辅相成的思路是分析Traffic分布情况,使放入TCAM中的分区让每个TCAM的流量尽量均衡。
当一个包到来时,选择逻辑会根据目的地址的10~13位判断匹配哪个分区,此分区在哪些TCAM中,然后由哪个TCAM的输入队列较短就把包送到哪个TCAM的输入队列中。而相应的TCAM在进行查找时,只触发分区所在的blocks以减小功耗。
这种方案最好情况下的查找速度能达到单个TCAM的k倍,k是并行TCAM的个数,假如每个TCAM的功率消耗为M,每个分区所占的blocks数是TCAM中所有blocks数的1/n,则最大功耗为kM/n,是一种查找效率高而功耗低的查找方案。最坏情况下是出现在突发的流量,所有的包都在某个特定分区中,而且这个分区只在一个TCAM中。这时相当于一个TCAM在处理所有任务,查找速度相当于单个TCAM的速度,如果线速很高,则会出现大量丢包,所以这种方案应付因特网上经常出现的突发流量比较差。另外在划分分区时依赖某些特定位的统计数据,对不同站点情况不同,扩展性差,而且各分区的路由表项数目不平均。更新效率为O(N/k),其中N为路由表项,k为并行TCAM数,更新时需注意对于跨多个TCAM的路由表项需要同时更新。
3.3基于地址范围划分的并行TCAM方案
基于前两种划分方案bucket中的地址前缀数都不平均,自然想到是否存在一种划分方案使每个bucket中的地址前缀数基本相等。Anigrahy[12]给出了地址范围划分的方案,如图4所示。
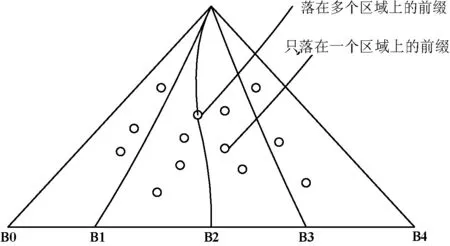
图4 基于地址范围划分的方案
图4中划分了4组,可以让每组前缀数目基本相等,把每个组都放到一个不同的TCAM中,每个TCAM最多有64个处于边界即落在线上的前缀(现实中很少会超过12个)。
Anigrahy[12]给出了这种方案的基本框架,但并没有做具体实现,Dong等[13]给出了这种划分方案的具体算法,并依此划分方案提出了一种高效的并行TCAM方案, Bin等在文献[14-16]对林冬等提出的方案进行了进一步改进。下面主要介绍基于地址范围划分的并行TCAM的主要思想。
文献[13]提出了用Preorder-Split算法划分buckets。这个算法分两步:首先根据路由表建立一个Trie树,然后根据Trie树进行划分分组。具体算法如图5所示。参数b代表将要划分的bucket数目,输出结果是b个子表和b-1个reference nodes,算法用前序遍历搜索前缀节点,每遇到一个前缀节点就存入bucket中并同时压栈,当bucket中的前缀节点数达到平均数时,一个字表就完成了,这时开始出栈并删除Trie树对应的中无孩子节点的前缀节点,直到栈空为止。最外层while循环结束时,就形成了b-1个具有相同前缀数的子表,剩余的前缀放入最后一个子表中。用reference node来计算bucket间的地址边界,如P*是一个bucket u 的reference node,则bucket[u]的上界是(P0…0 - 1),bucket [u+1]下界是(P0…0)。这样就可以得到b个TCAM buckets,并且每个都有一对地址边界。

图5 基于地址范围划分的算法
图6展示了如何用Preorder-Split算法划分了4个buckets。在查找地址a时,只有a落在地址范围中的bucket[u]所在的blocks被触发,处于边界上的地址前缀会被复制到两个毗邻的buckets中,(0.0.0.0)初始时会被放入到每个bucket中,由于Trie数层数一般小于6,所以冗余度一般小于6×buckets数。
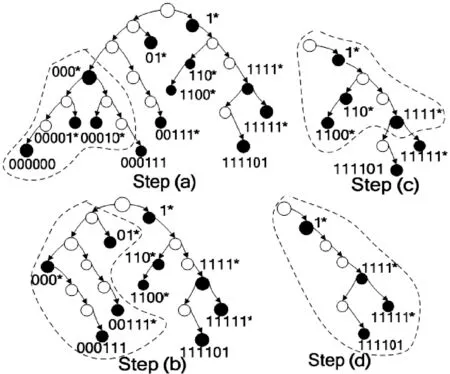
图6 用Preorder-Split算法划分举例
图7表示了选择触发TCAM block的索引逻辑。它包括并行的比较逻辑和一个索引表,每个比较逻辑对应一个TCAM bucket,并且有两个寄存器来存储每个bucket的边界值,索引表中存储bucket的分布信息,输出一个用于指示哪个bucket含有与目标地址匹配的地址前缀。此索引逻辑方案只有简单的比较操作所以速度快。

图7 索引逻辑方案
分配完成后另一个需要考虑的问题是如何动态的负载均衡,以更好的应付突发流量和提高查找效率。核心路由器中由于流聚集的影响使得流的temporal locality特性较强,所以容易考虑到使用cache的方案。由于TCAM使用block机制,可以选择TCAM的一些block作为TCAM的逻辑cache。这种机制的具体实施方案如图8所示。
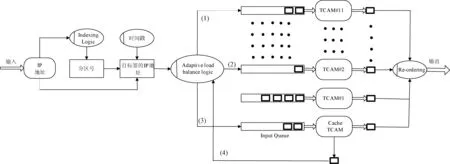
图8 基于地址位划分的并行TCAM体系机构
一个包到来后,目的IP地址被取出送到Indexing Logic作比较,Indexing Logic将返回一个partition number指示可能含有匹配前缀的 “home” TCAM,Adaptive Load Balance Logic根据FIFO队列的长度(短的优先)把IP地址送到home TCAM或其他TCAM中处理。同时处理cache-missed包,这样会使IP乱序,Re-ordering logic通过时间戳机制来处理乱序问题。所以到来的包会有三种路径:1) 若被送到home TCAM, 就会匹配的bucket所在的blocks进行查找并输出结果。 2) 若被送到一个non-home TCAM, 就会在cache进行查找,如果找到就输出结果。3) 若被送到一个non-home TCAM, 如果没找到就由Feedback逻辑把地址送回home TCAM对应的FIFO中处理。
Cache问题:有两种机制可供选择。1)缓存目的IP地址。2)缓存地址前缀[17-19]。但缓存目的IP地址所需开销太大,并且需要大量的缓存空间。所以逻辑缓存采用地址前缀缓存。但也有一个很重要的问题要考虑,比如有两个地址前缀p和q,而q是p的子孙节点,若一个请求r的LMP是p,这时p被加入cache中,若另一个请求r’到来时,它的LMP是q,若它被送入cache中处理时,就会输出错误的结果p。为解决这个问题,采用RRC-ME算法来管理cache。前缀p根据MEP(Minimal Expansion Prefix)[18]方法被扩展成一个长的前缀,假如路由表中只有两个前缀1*和111*,对请求1111的MEP为111*,对请求1000的MEP 10*(与1*有相同的地址前缀), 对请求1100的MEP为110*(与1*有相同的地址前缀),由于扩展的前缀都不相交,所以对每个请求就只有一个可能的匹配。这种方法的另一个好处是使cache blocks的更新只需要一个TCAM周期,因为cache中的前缀不需要排序。
这种方案最好情况下的查找速度能达到单个TCAM的k倍,其中k是并行TCAM的个数。假如每个TCAM的功率消耗为M,每个bucket所占的blocks数是TCAM中所有blocks数的1/n,则最大功耗为kM/n,是一种查找效率高而功耗低的查找方案。并且在TCAM数N>2,平均cache的命中率大于等于(N-2)/(N-1)时,系统的查找速度能达到N-1的加速比。每个bucket中的前缀数分配平均,扩展性能好。最坏情况下是出现在缓存的命中率为0,这时相当于一个TCAM在处理所有任务。另外还有一个可认为比较致命的问题是在缓存更新时,所有的TCAM不能进行查找,所以作者提出了慢速更新的思想,即每两次更新间隔一个固定的时间,但这又影响了缓存的命中率,更新间隔和命中率之间需要取一个折中以获得更好的效率,为此作者做了大量的实验。更新效率为O(N/k),其中N为路由表项,k为并行TCAM数,更新时需注意对于跨多个buckets的前缀项需要同时更新。
4方案比较
下面,我们从路由查找速度、功耗和更新效率三个方面简要比较前述三类方案。表1列出了三类方案的比较,可以看到,基于端口和基于无子孙关系前缀集合的方法主要是提高更新效率,这两种方案的更新效率可以达到O(1)。但是,这两种方案和采用单个TCAM进行路由查找[20]的方案相比,在查找速度和功耗上并没有改善。因为这两种方案每进行一次路由查找,所有TCAM分片都需要为一次路由查找进行并行查找,效率低功耗大。基于CoolCAMs的方案可以将一次路由查找分配到不同的TCAM分片或block上,因此,如果有k个TCAM分片,可以达到查找速度上的将近k倍加速,大大提高了路由的查找效率,并且由于采用CoolCAM技术,大大降低了设备功耗。但在更新效率相比于前两种方案相对较低,但相比于单个TCAM的查找方案其更新效率有所提高。对于N为路由表项,单个TCAM的查找方案的更新效率为O(N)[21],并行方案的更新效率为O(N/k),其中k为并行TCAM数。

表1 基于TCAM的并行路由查找方案对比
基于CoolCAM技术的三种方案路由查找速度、功耗和更新效率在具体阐述其方法时已作了详细分析,这里不再赘述。总的来说基于Trie树、基于地址位、基于地址范围这三种方案的整体效率是逐步提升的,但仍然存在一些不足和有待改进的地方。
5目前方案不足及改进
总体来看,目前基于并行TCAM的路由查找方案在逐步进展和完善,但仍存在下列不足之处:
• 位划分方案过于简单,在进行基于位对路由表进行划分时,缺少可信的调研数据[22],只是简单地用第15、16位进行划分。另外对位划分方案缺少足够的阐述。基于地址范围划分的方案虽然有很大程度上的改进,但仍然缺乏考虑流量本身的特性造成不同地址范围地址数量的巨大不均衡问题。
• 基于地址位的并行方案过于简单,只是用第15、16位划分划分的四个分区放入4个并行的TCAM中,未考虑动态的负载均衡,未提出用冗余的部分来平衡流量以加快查找速度的思想;基于地址范围划分的方案虽然考虑了一定的动态负载均衡,但并未能充分利用TCAM的剩余空间进行负载均衡[23,24];缓存机制的效率有待进一步研究[25,26]。
• 对并行处理中的报文乱序问题没有足够重视,没有一套专门处理报文乱序问题的机制。
• 新的方案虽然极大地提高了路由的查找效率,而TCAM中路由条目的更新效率并没有得到很好的提升。
• 未能充分考虑在IPV6网络环境下部署的情况。
由于前两个问题的改进需要设计一整套的改进方案和提出一个完整的体系结构,不属于本文的研究范围,下面我们针对后面两个具体的问题探索可能的改进措施。
首先我们探索一种保持包的查找次序的机制。由于在进行查找时包会去往不同的TCAM的输入队列,而每个TCAM的输入队列中的排队的包的数目不同,如果顺序到来的两个包a和b,a到来后被送入一个比较长的输入队列中,b虽然后到,但到后有可能送入到一个很短的输入队列中,这时b就可能先于a进行处理,就出现了包乱序的情况。处理包乱序的问题一种常见的机制就是在包被送入不同的输入队列前加一个含有时间戳的标记,在输出队列中根据时间戳排序后再进行输出。也可以用序号生成器加一个含序号的标签,输出时按序号进行排序,但序号生成器所生成序号的大小要能保证若最小序号的标签和最大序号的标签同时出现在输出队列中一定是含最小序号的标签在含最大序号标签的包之后。
下面,我们探索如何进一步改进TCAM的更新效率。前面我们谈到方案的更新效率为O(N/k),其中N为路由表项,k为并行TCAM数,是否有更好的方案达到更高的更新效率?由于这种方案的更新是在每个bucket中进行更新,下面我们探索一种可以在每个bucket中部署的快速更新方案。基本思想建立于若一个集合中的所有地址前缀无子孙关系或不为互为前缀关系(我们称这种关系为disjoint),则集合中所有前缀所包含的地址范围映射到一维地址空间上无地址重叠关系,如梁志勇等[27]就提出了一种基于这种非重叠前缀集合的并行路由查找算法,用软件的方式对算法进行了描述,并且提出未来可以考虑用硬件实现。因此,在这种前缀关系下,在进行地址查找时这个集合至多只有一个匹配项,也就是说集合中所有项的顺序没有任何关系,进一步就相当于只有具有子孙关系的前缀项在位置上要保持好前后顺序,即在进行插入和删除时只要保持好Trie数中的子孙关系就可以保证LMP。
经过调研目前路由表的前缀Trie树一般不超过7层(包括*),具体到bucket中某些位划分成的子表,层数会更少,所以这时的更新效率会更高,一般小于O(7),与路由表项无任何关系,不足之处是需要保存bucket中的Trie树。
关于在IPv6网络环境下如何部署目前提出的高速并向路由查找算法,当前工作大部分都是简单提到,没有充分考虑真实部署时需要关注的各种因素。Tong Yang等[28]在他们最新的工作中提出一种分裂算法,并把算法部署到CPU,FPGA,GPU等硬件上进行了测试,验证了算法的高效性。最后,提出了在IPv6上的部署问题,由于目前IPv6的FIB表的表项要远远小于IPv4中心路由器的表项,首先硬件的容量在实际部署时不成问题,一个主要考虑的问题是IPv6有128个地址位,而IPv4只有32位。但实际上IPv6的网络地址只有64位,剩下64位为主机地址,作者建议将64位网络地址按16,24,32,40,48,64划分成6层适配到Trie树节点中,而对于并行TCAM方案在IPv6实际环境中的部署,也主要是要考虑和IPv4地址位数的差别。不同的方案部署时考虑的因素不同,比如按位划分的方案就需要对IPv6的FIB表进行实际分析,看看哪几位的组合更能平均划分FIB表项;基于TRIE树和基于地址范围的方案只需要将算法进行简单扩展,用于IPv6的地址位即可。
6结语
由于TCAM自身的优良特性,使得它在核心和高端路由器上得到越来越多的应用,其应用范围也越来越广。从路由查找到流分类和防火墙的应用,其中对TCAM的要求也越来越高,如何高效节能地利用TCAM将会受到越来越多的关注和研究。我们分析了使用TCAM进行路由查找的背景和存在的挑战,总结了在用TCAM进行路由查找时应解决的三个主要问题:查找速度,功耗和更新效率。为了更好地解决面临的问题,人们提出了不同的并行解决方案。文中调研了不同的并行方案,并分析了不同方案的优缺点,总体来说是不断改进的六种方案。针对目前提出的并行方案,分析了存在的不足,并提出了可能的改进。
参考文献
[1] Ruiz-Sanchez M A,Biersack E W,Dabbous W.Survey and Taxonomy of IP Address Lookup Algorithms[J].IEEE Network 2001,15(2):8-23.
[2] Gupta P,Lin S,McKeown N.Routing lookups in hardware at memory access speed[C]//Proceedings of IEEE INFOCOM’98,San Francisco,April 1998:1240-1247.
[3] Nenfu Huang,Shiming Zhao,Jenyi Pan.A fast IP routing lookup scheme for gigabits switching routers[C]//Proceedings of IEEE INFOCOM,1999:1429-1436.
[4] Daxiao Yu,Smith B C,Wei B.Forwarding engine for fast routing lookups and updates[C]//Proceedings of IEEE GLOBECOM,1999:1556-1564.
[5] Huston G.Route Table Analysis Reports.http://bgp.potaroo.net/.
[6] CYRESS.http://www.cypress.com/.
[7] Ng E,Lee G.Eliminating Sorting in IP Lookup Devices using Partitioned Table[C]//Proceedings of 16th IEEE International Conf.on Application-Specific Systems,Architecture and Processors(ASAP),2005:119-126.IEEE Press, Greece.
[8] Jinsoo Kim,Junghwan Kim.An Efficient IP Lookup Architecture with Fast Update Using Single-Match TCAMs[C]//Proceedings of WWIC 2008:104-114.
[9] Zane F,Narlikar G,Basu A.CoolCAMs:Power-Efficient TCAMs for Forwarding Engines[C]//Proceedings of INFOCOM,2003:42-52.
[10] Kai Zheng,Chengchen Hu,Hongbin Liu,et al.An ultra-high throughput and power efficient TCAM-based IP lookup engine[C]//Proceedings of INFOCOM, March 2004:1984-1994.
[11] Xin Zhang,Bin Liu,Wei Li,et al.IPv6-oriented 4*OC768 Packet Classification with Deriving-Merging Partition and Field-Variable Encoding Algorithm[C]//Proceedings of INFOCOM,Spain,April 2006.
[12] Anigrahy R,Sharma S.Reducing TCAM Power Consumption and Increasing Throughput[C]//Proceedings of HotTI August 2002:107-112.
[13] Dong Lin,Yue Zhang,Chengchen Hu,et al.Smart Route Table Partitioning and Novel Load Balancing for Parallel Searching with TCAMs[C]//Proceedings of 21st IEEE International Parallel & Distributed Processing Symposium (IPDPS), Long Beach, California USA,2007.
[14] Bin Zhang,Jianping Wu,Qi Li,et al.Efficient Parallel Searching with TCAMs IEEE 18th InternationalWorkshop on Quality of Service[C]//IWQoS, Beijing, China ,2010:1-2.
[15] Bin Zhang,Jiahai Yang,Jianping Wu,et al.An Efficient Parallel TCAM Scheme for the Forwarding Engine of the Next-generation Router[C]//IFIP/IEEE Int’l Symp. On Integrated Network Management, May 22-27, IM, Dublin, Ireland, 2011:454-461.
[16] Bin Zhang,Jiahai Yang,Jianping Wu,et al.Efficient Searching with Parallel TCAM Chips[C]//The 35th IEEE Conference on Local Computer Networks, LCN 2010, Denver, Colorado, U.S.A 11-14 Oct. 2010.
[17] WoeiLuen Shyu,ChengShong Wu,TingChao Hou.Efficiency Analyses on Routing Cache Replacement Algorithms[C]//Proceedings of ICC’2002, Vol.4, April/May 2002:2232-2236.
[18] Tzicker Chiueh,Prashant Pradhan.High-Performance IP Routing table Lookup Using CPU Caching[C]//Proceedings of INFOCOM’99, Vol.3, March 1999:1421-1428.
[19] Bryan Talbot,Timothy Sherwood,Bill Lin.IP Caching for Terabit Speed Routers[C]//Proceedings of GLOBECOM, Vol.2, DEC 1999:1565-1569.
[20] Huang N,Zhao M,Pan J.A fast ip routing lookup scheme for gigabits switching routers[C]//IEEE INFOCOM,1999.
[21] Yu D,Wei B S B.Forwarding engine for fast routing lookups and updates[C]//IEEE GLOBECOM,1999.
[22] Huston G.Route table analysis reports[EB/OL].http://bgp.potaroo.net/.
[23] Shyu W,Wu C,Hou T.Efficiency analyses on routing cache replacement algorithms[C]//IEEE International Conference on Communications,2002.
[24] Chiueh T,Pradhan P.High-performance ip routing table lookup using cpu caching[C]//IEEE INFOCOM,1999.
[25] Talbot B,Sherwood T,Lin B.Ip caching for terabit speed routers[C]//IEEE GLOBECOM,1999.
[26] Mohammad J,Akhbarizadeh M,Nourani M.Efficient prefix cache for network processors[C]//The 12th Annual IEEE Symposium on High Performance Interconnects,2004.
[27] 梁志勇,徐恪,吴建平,等.基于非重叠前缀集合的并行路由查找系统[J].电子学报,2004,32(8):1277-1281.
[28] Tong Yang,Gaogang Xie,YanBiao Li,et al.Guarantee IP Lookup Performance with FIB Explosion[C]//Proceedings of SIGCOMM,Chicago,USA,Aug.2014.
收稿日期:2014-12-26。国家自然科学基金项目(61462009);江苏省博士后科研项目(1402138C);河南省教育厅科技计划项目(13B52 0337)。王辉,讲师,主研领域:信息系统。李晓歌,讲师。张宾,工程师。秦董洪,副教授。
中图分类号TP393
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.07.033
SURVEY ON TCAM-BASED PARALLEL IP ROUTE LOOKUP SCHEME
Wang Hui1Li Xiaoge1Zhang Bin2Qin Donghong3
1(DepartmentofAutomationandControl,HenanUniversityofAnimalHusbandryandEconomy,Zhengzhou450000,Henan,China)2(The63rdResearchInstituteofPLAGeneralStaffHeadquarters,Nanjing210007,Jiangsu,China)3(SchoolofInformationScienceandEngineering,GuangxiUniversityforNationalities,Nanning530006,Guangxi,China)
AbstractThe IP route lookup scheme based on TCAM (ternary content-addressable memory) is the widely used scheme by high-performance routes in route lookup at present. However the scheme still faces challenges in lookup performance, power consumption and update efficiency. Therefore, scholars proposed various parallel TCAM solutions to improve lookup performance, reduce power consumption and enhance update efficiency. This paper gives the classified summarisation on current parallel TCAM IP route lookup schemes, analyses the pros and cons of them, and points out the drawbacks of these schemes as well as explores some corresponding solutions.
KeywordsParallel TCAMIP route lookupPower consumptionAddress division
