一种大数据分析组件的自动化开发集成方法
2016-08-05吴怀林马志柔
陈 茜 吴怀林 马志柔 刘 杰 钟 华
1(中国科学院大学 北京 100049)2(中国科学院软件研究所 北京 100190)
一种大数据分析组件的自动化开发集成方法
陈茜1,2吴怀林2马志柔2刘杰2钟华2
1(中国科学院大学北京 100049)2(中国科学院软件研究所北京 100190)
摘要随着大数据时代的到来,数据分析需求日趋多样化,大数据分析工具自带的算法库已无法满足个性化的数据分析需求,亟需开发或集成新的算法。但现有的大数据分析工具算法开发集成学习成本高,给新算法的开发集成带来一定困难。提出一种针对大数据分析工具自动化开发集成算法的方法,算法以组件的形式集成到分析工具中。首先定义组件模型,其次给出组件模型自动化生成流程,最后重点分析组件代码的自动生成和代码检测问题,给出基于元信息的代码生成方案和基于Soot控制流的静态代码检测方法。实验表明,该方法可以完成大数据分析组件的自动化开发集成。
关键词大数据分析组件Soot控制流分析代码生成
0引言
随着互联网的快速发展,我们已经进入大数据时代,越来越多的机构组织开始重视数据分析带来的价值,人们对数据分析的需求也迅速提升。许多优秀的算法分析师致力于数据分析算法开发优化的同时,日趋增长的大数据分析业务亟需业务部门的分析师完成。集成化的大数据分析工具正是连接两者的纽带,它可以集成开发者开发好的数据分析算法,供业务分析师使用。
Haflow正是这样的一个集成化的大数据分析工具。该工具以组件为设计单位,具有拖拽式流程设计界面,以分布式集群Hadoop为组件运行的基础设施,组件间通过HDFS文件传递数据[1]。除了Haflow,目前市场上已经有一些成熟的数据分析工具,如Weka[2]、Clementine、R[3]等。这些工具本身集成了一些优秀的数据分析算法,数据分析师固然可以利用这些工具自带的算法进行数据挖掘分析。但是当遇到特定的数据分析需求,需要开发和实现新的数据分析算法时,这些数据分析工具却并未提供很好的平台算法扩展接口和算法开发工具,方便算法的快速开发和集成。以Weka为例,扩展现有的算法库,添加一个新的算法需要完成以下步骤:1) 按照Weka接口和规范编写新的算法;2) 建立合理的目录结构,定位算法所在的包;3) 修改Weka启动时加载的系统配置文件[4]。这必然增加了算法开发和集成的复杂程度,给算法开发人员带来了学习负担。
为了解决大数据分析工具算法集成开发复杂的问题,本文基于现有的大数据分析工具Haflow提出一种自动的算法开发集成方法。通过该方法,屏蔽算法开发人员与工具适配的工作,免去算法开发人员研究平台接口规范的麻烦,使其只需关注在算法的实现和优化工作上,从而提高算法开发人员的工作效率。另外本文还利用静态代码分析的方法检测现有开源代码中不符合工具规范的部分,从而实现开源代码的自动化集成。总之,利用该方法,可以快速地为Haflow大数据分析工具开发和集成开源算法,从而解决数据分析算法开发集成困难的问题。
1相关研究
相关研究主要调研了主流的商业数据分析工具算法开发现状和学术界数据分析组件自动化开发方案。
在数据挖掘领域,国内外针对不同的应用场景研究开发了不同的数据分析工具。主流的数据分析工具包括:SAS、SPSS、Weka以及R语言等。研究这些工具上的算法开发解决方案,SAS、SPSS由于不开源,基本无法为其开发自定义的算法。R和Weka是开源的,前文中以及提到为Weka编写新算法需要三步,Weka并未提供自动化的算法开发方法;R是一个开放式平台,R提供了包结构的解决方案来管理算法,开发的新的算法需要满足包结构的标准。Haflow是一个基于组件的大数据分析工具[1],该工具构建在分布式集群上,以HDFS为底层文件系统,提供可扩展的组件接口。数据分析算法可以以组件的形式集成到工具平台上,并且支持异构底层的算法。Haflow虽然提供了开放接口来支持组件开发集成,但没有提供自动化的方法,开发人员要学习Haflow本身的接口,熟悉Haflow的处理逻辑才能开发组件。对于开源算法的集成,也需要开发人员找出算法中不符合平台规范的地方,代价很高。
综上所述,现有的大数据分析工具给出的算法开发和集成方案为:提供可扩展的算法开发接口,新组件的开发需要实现该接口,满足包结构管理规范,但没有给出自动化的组件开发集成方案。
除了以上提到的商业数据分析工具,学术界提出了以下研究方法。
采用模型驱动的代码生成方法,利用系统提供的模型组件定义数据挖掘过程,该过程是一个逻辑模型,与具体实现技术无关。逻辑模型经过系统的后台解析成物理模型,然后在系统中执行。通过Jet模板解析的方式来生成物理模型代码,Jet解析器将用户参数和代码模板转换成可执行Java代码[5]。该方法实现了数据挖掘组件的自动化开发过程,但没有提供开源算法集成到数据分析工具的解决方案。
利用静态代码分析方法可以对程序中的代码进行检测分析,Soot是McGill大学的Sable研究小组于1996年开发的Java字节码优化框架[6],其目标是开发能够更快更好地理解与执行Java程序的工具[7]。通过 Soot 提供的过程内和过程间的分析与优化支持,用户可以很方便地获得每个方法的控制流图和各个折衷级别上的全局调用图[8]。在学术研究中,Soot还被用来检测分析程序中的缺陷[9]。本文将利用Soot分析开源算法中的输入输出语句代码,从而完成开源算法的集成。
2大数据分析组件的自动化开发集成
本文将研究如何自动化开发和集成大数据分析算法到Haflow工具中。Haflow将平台上的分析算法定义为组件,首先要了解组件的概念,然后给出自动化集成和开发这些组件的步骤和处理框架。
2.1大数据分析组件模型
由图1可以看出组件模型由三部分构成:组件元信息、组件实体和组件接口,可以表示为V=(M,E,I)。
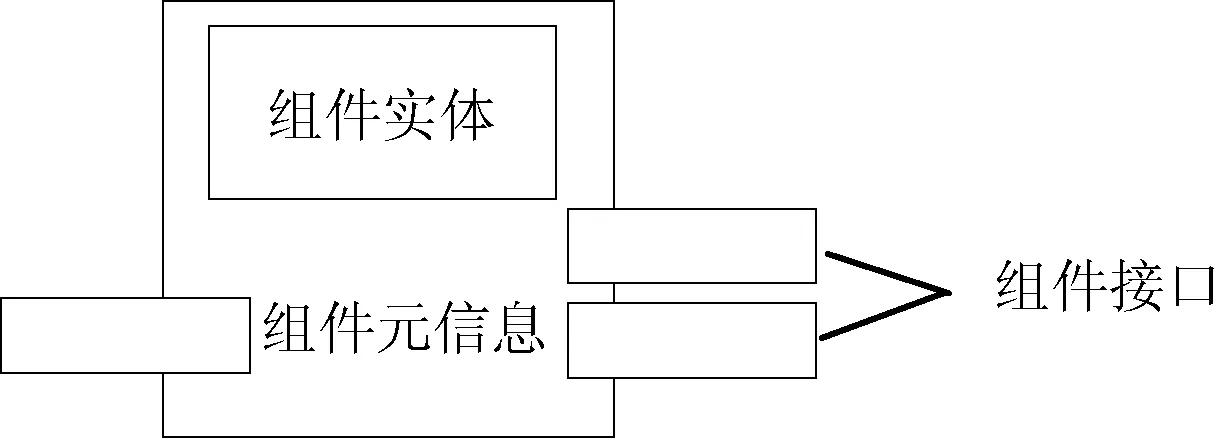
图1 组件模型
具体介绍如下:
M为组件元信息:定义组件的描述,继承Haflow提供的抽象类来满足其规范,是组件被平台识别和管理的基础。
E为组件实体:是组件功能的实现部分,是集成或者全新开发的算法部分,支持Java、MapReduce、R、Hive等多种底层异构平台。
I为组件接口:是组件的输入输出部分,用来满足与其他组件的匹配,将相邻两个组件的匹配转换为中间数据结点的匹配。
从具体代码实现上看,一个组件可以理解为一个Jar包,是由Java代码按照规定的包结构打包生成。Java源码按照功能的不同区分成两部分:组件元信息Java类和组件实现Java类。组件接口Java代码段分布在两者之中,组件Jar包结构如图2所示。
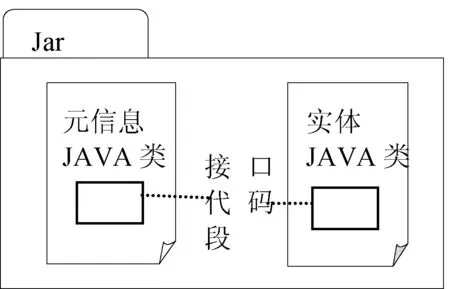
图2 组件Jar包结构图
元信息Java类由ID、组件参数以及根据底层平台不同继承实现的不同组件抽象类三部分组成。实体部分可以是以Main函数作为调用入口的一个Java类,也可以是由Main函数做入口调用的多个Java类。组件接口部分比较特殊不是单独的Java类,而是由两部分代码段组成:元信息Java类中描述组件输入输出的参数部分和实体Java文件中对这些输入输出进行处理的部分。Haflow底层是HDFS文件系统,组件协同工作需要以HDFS文件作为接口标准,即前一个组件输出的HDFS文件作为与其相连的后一个组件的输入。如图3所示,组件的输入输出会以键值对(Key,Value)的形式作为Main函数的命令行参数传递到组件实体类内,实体类读取Main函数的Args参数即可读到输入输出文件所在的地址。

图3 组件接口文件处理机制
2.2组件自动化开发集成处理流程
Haflow的组件主要有两种来源:一是算法工程师自己从头开始编写的全新的算法包装成组件;另一种是将Mahout、Weka等开源的算法适配成工具支持的组件。
两种来源的算法要集成到平台上成为组件。首先,要能被Haflow平台识别,这就需要自动生成组件的元信息;其次,Mahout、Weka中有部分单机算法,对输入输出文件的处理都是单机方法,不满足Haflow接口文件处理要求,需要自动化检测这部分代码,给出需要修改的片段;最后,修改后的算法本身可以作为组件实体,连同自动生成的组件元信息按照一定的包组织结构生成Jar包提交到Haflow上。按照以上三步就完成了组件自动化开发集成,流程如图4所示。
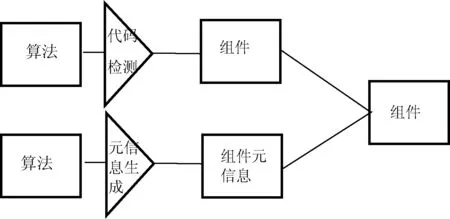
图4 组件自动化开发集成处理流程
3方法实现及关键技术研究
3.1组件元信息自动化生成
Haflow对于组件元信息有统一的规范,可以抽象成一个元信息逻辑模型LM=(ID,Property,Platform)。该逻辑模型从用户的角度来定义,ID是自动为组件生成的唯一标识,Property是组件的参数信息,Platform代表组件依赖的底层平台,不同的平台对应的物理模型不一样。组件开发人员只需要填写抽象逻辑模型要求的字段,从而屏蔽了其对底层平台学习的成本。
采用基于元数据逻辑模型的文本模板替换算法实现组件元信息Java类的自动生成,处理流程如图5所示。核心思想是定制一套文本模板,模板分为静态和动态部分。根据组件元数据信息的不同,组件生成引擎加载文本模板,将静态部分直接复制,动态部分根据元数据信息生成不同的代码,最终自动化生成元信息Java文件。元信息代码生成工作方式如图6所示,元数据逻辑模型本质是标识组件元信息的一套键值对。文本模板显式标明了这些这些键值对该被替换的位置,替换算法的任务就是将文本模板的变量替换和根据底层物理平台不同集成实现不同的抽象类。

图5 组件元信息自动生成处理流程

图6 元信息代码生成工作方式
替换算法将文本模板中带有$符号的变量被替换成参数键值对中实际值,按照底层平台模型不同分别选择继承AbstractJavaModule、AbstractHiveModule、AbstractSqoopModule或AbstractMapReductModule不同的类。这些支持底层平台的抽象类是预先写好的,只要选择需要的类型继承。替换算法的伪代码如算法1所示,首先将文本模板读入输入流中,然后遍历参数键值对,查找文本模板输入流中的相应Key值,替换成Value即可。另外Haflow具有可扩展性,组件元信息中可实现用户自定义的组件配置参数处理,用户利用键值对<$type,custom>标记参数里有需要自定义处理的类型。然后给出自定义的处理方法,替换算法会用该方法重写上面提到的抽象类中的getArguments方法。最后给出生成的组件元信息Java类。
算法1替换算法
Input: ModulePropertyMap, ModuleTemplate
Output: ModuleMetaJavaFile
Read ModuleTemplate file into MTInputStream;
for each MP in MoudlePropertyMap:
key ← MP.key; value ← MP.value
//用户自定义类型,需重写读取参数方法
if key==type && value==custom:
needtooverride is true
Endif
//将文本模板中的变量替换成参数键值对中的实际值
replace key in MTInputStream to value
if needtooverride is true
override getArguments function
Endif
Write MTInputStream into ModuleMetaJavaFile
3.2基于Soot控制流的静态组件代码检测
开源算法对于命令行输入输出的处理多样化,不同的代码有不同的处理逻辑,要找到代码中对于特定参数的读写语句是一个十分复杂繁琐的工作。主要有两个难点:找到输入文件地址从命令行参数变量开始到最终被赋值的存储输入文件地址的变量;找到对该变量进行文件读写的语句。
以Mahout中的单机代码TrainLogistic为例,代码的部分相关片段如下:
public class TrainLogistic{
private static String inputFile;
⋮
public static void main(String[] args){
mainToOutput(args,new PrintWriter());
}
static void mainToOutput(String[] args,PrintWriter o){
if(parseArgs(args)){
BufferedReader in= open(inputFile);
⋮
}
}
private static boolean parseArgs(String[] args){
Option inputFile = builder.withLongName(″input″)
⋮
CommandLine cmdLine=parse.parseAndHelp(args);
TrainLogistic.inputFile=getStringArgument(cmdLine,inputFile);
}
从中可以看出,输入文件参数从Main函数的命令行参数读入后,并未在Main函数体内直接处理,而是传递多次到parseArgs函数中。而该函数体中又没有对args参数直接处理,而是调用了其他类的函数进行处理。经过多次非本类的成员函数处理后,最终赋值给本类的成员变量InputFile,这才完成了两个难点中的第一步。找到最终的InputFile变量后,查看对其文件读写语句,发现inputFile作为函数open的调用参数,分析open函数体内语句,最终找到对inputFile变量的文件处理语句,完成了难点中的第二步。
为了解决以上两个难点,我们采用Soot代码分析工具来获得代码的控制流图UnitGraph,从而跟踪代码对输入参数的处理语句。
基于Soot控制流的静态代码检测算法核心思想如下:
1) 从处理args的函数作为入口,跟踪args中保存输入或输出路径的变量被传递到的函数和变量;
2) 根据变量类型以及对其的相关处理判断这些变量是目标输入输出变量的可能性;
3) 将可能是目标变量的作为“污染”变量;
4) 进一步跟踪,发现“污染”变量作为参数的函数,且函数返回值是InputStream、OutputStream、Reader、Writer及其子类,且函数调用是第三方类库中的函数或者初始化构造函数时,报警该行;
5) 重复步骤2)-步骤4),直到算法分析完。
为了实现以上算法,需要利用Soot中的一些基本对象和方法。Scene用来保存整个分析发生的场景,可以设置要分析的包含main函数的类和应用类,以及采用过程间还是过程内分析。SootClass是装入Soot中的单个类,而SootMethod是类中的一个方法,Body是存储SootMethod的实现代码,Unit是Body中具体的语句,UnitsChain是Body中Units组成的链,UnitGraph表示一个具体方法生成的控制流图,Unit有多种类型。例如定义语句IdentityStmt、调用语句InvokeStmt、赋值语句AssignStmt以及判断语句IfStmt、跳转语句GotoStmt等。Local表示临时变量,Field是成员变量,两者都叫作Value。
结合Soot的基本对象和方法,基于以上核心思想,得到最终的静态检测算法如算法2所示。
算法2基于Soot控制流的静态代码检测算法
Input: classname,classpath,key, IORegex
Output: JavaSourceCodeLineNum, WarnLevel
MAIN(String,String,String,String)
globalTargetList←Null
//全局变量,用来保存成员变量中属于目标变量的部分
load classes into Scene
//配置分析场景
set whole mode
//设置为过程间分析模式
methods←sootclass.getMethods
for each method in methods:
if method is Main:
call ANALYSIS(method, paras)
End MAIN
ANALYSIS(SootMethod,Int[])
paraList←Null
//记录该函数的调用参数变量
localTargetList←Null
//记录函数体内目标变量
taintList←Null
//记录被key污染的变量
body←get body from method
graph← new UnitGraph(body)
for each unit in graph
switch condition in rule 1
case 1:
get newMethod and newParas
ANALYSIS(newMethod,newParas)
case 2:
add to paraList,globalTargetList, taintList or localTargetList
if returnType in IORegex
print line based on rule 2
End ANALYSIS
输入数据是待分类组件实体的类名、类所在的路径、命令行参数args中与输入或输出相关的关键字、需要捕获的函数返回值类型对应的正则表达式(即输入输出流及其子类)。输出是单机读写输入或输出文件的Java源代码所在的行以及该行的危险度级别。算法包括一个主函数MAIN,完成将类转换成中间代码的准备工作,并且获得类中的所有方法。算法还包括静态代码分析函数ANALYSIS,该函数用来分析类中单独的方法片段,调用参数是SootMethod和调用参数中需要被跟踪的参数位置。ANALYSIS遍历要分析方法的UnitGraph,按照表1作出相应的动作,包括递归调用ANALYSIS方法或者将相关变量加入四个List中的一个。当正在遍历的unit语句返回值符合IORegex,并且参数在四个List中时,按照表2给出报警的源代码行数和报警级别。其中重点介绍四个List,四个List都是用来记录与输入的Key相关的变量。paraList是用来保存函数调用参数中与key相关的变量,localTargetList用来记录某个方法内部与key直接相关的临时变量,taintList是间接相关的临时变量。两者的区别是targetList是我们要找的value值所在的变量,而taintList是可能为value值的变量。最后将跨函数的变量,比如成员变量,存储在globalTargetList中。
表1跟踪规则
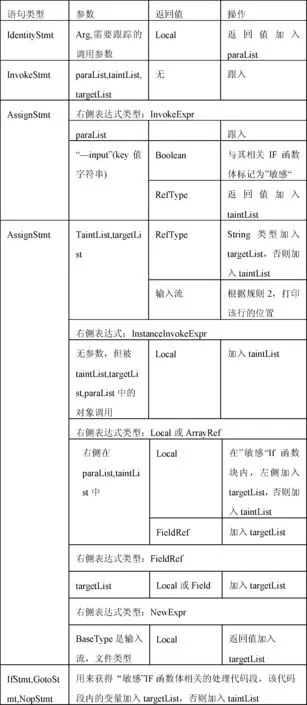
表2 报警规则

参数函数报警等级taintList中的变量第三方类库函数低(L0)输入流构造函数中(L1)targetList中的变量第三方类库函数中(L1)输入流构造函数高(L2)paraList中的变量第三方类库函数中(L1)输入流构造函数高(L2)
4实验验证
4.1实验目的和数据选取
实验是为了验证基于Soot控制流的静态代码检测算法的准确性。使用该算法能够将检测出开源算法库中对输入输出关键词单机读写的代码,从而找到代码中不满足Haflow要求的代码行,给出报警。选取机器学习领域著名的开源算法Mahout中的例子以及要集成进Haflow的开源文本分析算法进行实验。
4.2评价标准
采用准确率(P)、召回率(R)、有效性(E)三者结合的评价标准,定义算法给出的报警语句数目为NumOfWarn。其中确实判断正确的语句数目为NumOfRight,待检测的类中实际应该报警的语句数目为NumOfShouldWarn。当语句被正确报警时,给出的报警等级与实际报警等级相符的语句数目为NumOfRightLevel,给出评价标准公式如下:
(1)
(2)
(3)
4.3实验结果
首先给出两个测试案例,mahout-examples包中TrainLogistic类是单机处理输入输出文件的类[10]。使用该类对本文提到的算法进行测试,定位类中对输入单机处理的代码行并且报警。算法得到的结果和人工审核结果对比如表3所示,可以看出准确率75%,召回率100%,有效性67%。

表3 TrainLogistic中输入处理报警的行
定位类中对输出单机处理的代码行并且报警,算法得到的结果和人工审核结果对比如表4所示,准确率75%,召回率100%,有效性100%。

表4 TrainLogistic中输出处理报警的行
按照以上方法,对mahout-example中的其他以main函数为入口的主类用该方法进行测试,给出测试结果如图7所示。
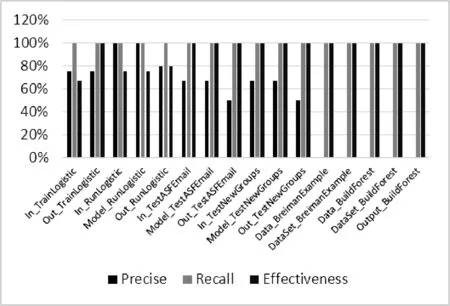
图7 mahout-example中部分代码的实验结果
从结果中可以看出,该算法的召回率一直稳定在100%,这就保证了该方法不会漏掉开源代码中有问题的代码片段。从图7中可以看出,前十一个程序都是单机程序,其准确率平均值为73%,表明找到的语句基本与输入输出处理相关;后五个代码的准确率为0,这是由于后五个代码均是MapReduce代码,并没有需要修改的代码。前十一个程序的有效性平均值为91%,表明算法对于认为有问题的语句给出的相关性判断即报警等级基本正确。利用报警等级来优化了算法的准确率,开发人员可以优先修改报警等级高的语句,大大提高了工作效率。
5结语
大数据分析工具的组件开发和集成往往非常复杂,缺少自动化的方法。结合大数据分析工具Haflow,本文提出了一种大数据分析组件自动化开发集成的方法。方法主要包括组件元信息代码自动生成和开源组件代码的静态检测两方面。利用开源Mahout代码对静态检测算法进行实验验证,结果表明,该算法效果较好,能够相对准确地找到开源代码中需要修改的语句,方便开源组件的集成。在未来的工作中,将进一步考虑利用Soot代码生成的方法,自动化修改有问题的代码行,从而进一步提高组件集成的自动化程度。
参考文献
[1] 赵薇,刘杰,叶丹.基于组件的大数据分析服务平台[J].计算机科学,2014,41(9):75-79.
[2] Hall M,Frank E,Holmes G,et al.The WEKA data mining software:an update[J].ACM SIGKDD explorations newsletter,2009,11(1):10-18.
[3] Ihaka R,Gentleman R.R:a language for data analysis and graphics[J].Journal of computational and graphical statistics,1996,5(3):299-314.
[4] Bouckaert R R,Frank E,Hall M,et al.WEKA Manual for Version 3-7-8[EB/OL].http://prdownloads.sourceforge.net/weka/WekaManual-3-7-12.pdf.
[5] 黄斌,许舒人,蒲卫.基于MapReduce的数据挖掘平台设计与实现[J].计算机工程与设计,2013,34(2):495-501.
[6] Vallée-Rai R,Co P,Gagnon E,et al.Soot-a Java bytecode optimization framework[C]//Proceedings of the 1999 conference of the Centre for Advanced Studies on Collaborative research.IBM Press,1999:13.
[7] Einarsson A,Nielsen J D.A survivor’s guide to Java program analysis with soot[EB/OL].http://www.brics.dk/SootGuide/sootsurvivorsguide.pdf.
[8] 李远玲,陈华,刘丽.Soot的Java程序控制流分析及图形化输出[J].计算机系统应用,2009,18(10):88-92.
[9] 佟超,王建新,齐建东.基于形式化规约的缺陷规则库构建与检测方法[J].Computer Engineering and Applications,2014,50(13):66-72,102.
[10] Anil R,Dunning T,Friedman E.Mahout in action[M].Manning,2011.
收稿日期:2015-02-06。国家自然科学基金项目(61170074,6120 2065);国家科技支撑计划项目(2015BAH06F01,2012BAH14B02)。陈茜,硕士生,主研领域:大数据分析,软件工程。吴怀林,工程师。马志柔,工程师。刘杰,副研究员。钟华,研究员。
中图分类号TP3
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.07.008
AN AUTOMATIC DEVELOPMENT AND INTEGRATION APPROACH FOR BIG DATA ANALYSIS MODULES
Chen Xi1,2Wu Huailin2Ma Zhirou2Liu Jie2Zhong Hua2
1(UniversityofChineseAcademyofSciences,Beijing100049,China)2(InstituteofSoftware,ChineseAcademyofSciences,Beijing100190,China)
AbstractAs the coming of big data era, the need of data analysis is becoming increasingly diverse, this results in the incapability of big data analysis tools to meet the customised data analysis requirements by using its own build-in algorithm libraries, to develop or integrate new algorithm is urgently necessary. But existing big data analysis tools algorithm has high learning cost in development and integration, and makes it difficult to develop and integrate a new one. This paper proposes an approach targeted at the automatic algorithms development and integration for big data analysis tools, the algorithms are integrated into analysis tools as modules. The approach first defines the module model, and then presents the automatic generation flow of the module model, finally it puts the emphasis on analysing the automatic code generation and code detection method of modules, and proposes the metadata-based code generation scheme and the Soot control flow-based static code detection algorithm. As the experiment shows, this approach can complete the automatic development and integration for big data analysis modules.
KeywordsBig data analysisModuleSoot control flow analysisCode generation
