一种基于Chrome扩展程序的网络数据采集方法
2016-08-05沈洪洲
沈 洪 洲
(南京邮电大学管理学院 江苏 南京 210023)
一种基于Chrome扩展程序的网络数据采集方法
沈 洪 洲
(南京邮电大学管理学院江苏 南京 210023)
摘要采集大量的网络数据可以为相关的科学研究提供重要的数据基础。针对科研工作者无法方便灵活地采集针对性网络数据的现状,提出基于Chrome扩展程序的网络数据采集方法,从网页中析取数据,或通过Ajax技术从网页服务器端直接读取结构化的数据,并对采集到的数据进行集中处理和存储。最终的执行效果表明,该方法可以突破动态网页技术的限制,无需处理复杂的用户登录逻辑,并可支持多用户场景下的分布式网络数据采集。
关键词Chrome扩展程序网络数据采集Ajax分布式
0引言
随着互联网技术与理念的不断推陈出新,尤其是以Web 2.0为基础的社会化媒体的出现和普及,使得广大用户成为互联网的中心,他们通过论坛、社交网络、微博、维基等应用,不断地创造和传播各式各样的互联网内容。这些以论坛帖文、个人状态和日志、微博信息、维基条目等为典型主体的互联网内容,连同围绕这些内容产生的各种回复和评价一起形成了互联网上随处可见的海量的网络数据。在“大数据”研究受到日益重视的背景下,海量网络数据的重要性已经显而易见,其蕴藏的研究价值逐渐凸显,为基于互联网的舆情监控、用户行为分析和网络社会学等方面的科学研究提供了极其重要的数据基础[1]。然而,不同于静态网页中固定不变的数据,此类网络数据绝大多数存在于动态网页之中,均是根据不同的访问场景由数据库中的数据动态封装而成,其访问受到各个互联网应用服务商的严格控制,加之Ajax等异步网络编程技术的广泛应用,使得如何大批量地采集具有研究价值的网络数据成为许多科研工作者亟待解决的重要难题。本文从实际科研工作中的网络数据采集需求出发,提出一种基于Chrome浏览器扩展程序的网络数据采集方法,可突破普通网络爬虫和调用网站API数据采集方式的局限,帮助科研工作者以分布式的方式采集大量的具有针对性的网络数据。
1网络数据采集现状分析
目前常见的网络数据采集方法包括网络爬虫和调用网站API两种,其中,网络爬虫是较早出现的一种网络数据采集方法,它是一种能够沿着网页中的超级链接自动漫游,并依据广度优先或深度优先的策略抓取页面信息的程序。传统的网络爬虫主要用于抓取新闻门户类、论坛类及传统博客类网站的数据,更擅长处理静态网页的数据[2]。为了能够更好地抓取动态网页中的数据,有不少研究开始尝试改进传统的网络爬虫,使之能够处理受访问保护的网页和采用Ajax技术的网页。孙青云等人[3]就提出了一种基于模拟登录的微博数据采集方案,解决了传统网络爬虫在采集微博数据时需要身份验证的难题,加快了微博数据的采集速度。纪伟也设计了一种采用模拟登录技术访问受保护网页的网络数据采集系统,并详细阐述了模拟登录的过程和登陆成功后Cookie的使用问题[4]。Mesbah等人则开发了一种叫作Crawljax工具,该工具对传统网络爬虫进行了改进,可以很好地分析基于Ajax技术的网站状态以及引起状态变化的各类页面事件,从而获取Ajax请求生成的静态数据[5]。刘凡凡设计了一种面向Ajax技术的网络爬虫系统,采用Webkit引擎解析网页中的JavaScript代码,并据此生成Ajax数据的翻页脚本,实现分页数据的自动提取功能[6]。
尽管可以通过网络爬虫的一些改进技术实现各类网络数据的采集,但网络爬虫获取的往往是整个页面数据,缺乏针对性,因此还需要采取一些额外措施对采集到的网页数据进行解析和整理,以得到研究所需的目标数据。利用网站自身提供的API实现网络数据采集则可以很好地解决数据针对性的问题。越来越多的社会化媒体网站推出了开放平台,提供了丰富的API,在已获授权的情况下,第三方程序可通过这些API直接获取网络数据。通过API获取的网络数据通常以JSON或XML的格式呈现,具有清晰的数据结构,非常便于通过程序直接进行数据抽取[7]。然而,对于网站API的调用也会受到种种限制。首先,网站提供的API种类可能有限制,有时并不能提供我们所需要的某类特定数据;其次,网站API的调用次数也会受到限制,例如人人网中普通授权应用的信息获取类API调用配额为“单用户每应用150次/小时”[8],这种限制往往无法满足大批量数据的采集需求。
综合考虑现有网络数据采集方法中存在的诸多不足,并且立足于实际的科研工作,本文分析并总结出科研工作者对于网络数据采集方法的具体需求,概括如下:
(1) 能够采集到受保护的网络数据。Web 2.0背景下,许多网络数据受到保护,只有登录以后才可以访问到,在某些特定的科研工作中,这些受保护的网络数据都具有很高的研究价值,是科研工作需要重点分析的一类网络数据。
(2) 能够灵活地采集多样化的网络数据。网络上的数据种类非常丰富,为不同目的的科研工作提供了不同的研究数据,因此,可灵活地确定并采集到不同类型的网络数据显得尤为重要。
(3) 能够持续采集大量的网络数据。科学合理的研究结论往往来自对大批量研究数据的综合分析,只有能够持续地采集到大量的网络数据才能很好地对科研工作起到支撑作用。
(4) 能够采集不同用户的网络数据。单个互联网用户的网络数据往往比较有限,也不能很好地证明研究结论的普适性,因此,获取众多不同用户的网络数据才具有真实的研究价值。
2基于Chrome扩展程序的网络数据采集思路
为了更好地阐明本文所提方法的具体实现思路,可设定如下网络数据采集场景:某研究团队需要采集某社会化媒体网站的用户数据,如个人信息、好友关系、评论、留言等。为此,研究人员招募了来自各地的众多研究志愿者并试图采集他们的相关数据。基于上文对于网络数据采集方法实际需求的分析,本文基于谷歌公司Chrome浏览器的扩展程序,直接从浏览器端解析并整理需要采集的目标数据,然后将数据通过互联网发送到数据库集中存储。具体实现思路如图1所示。
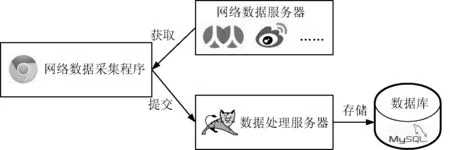
图1 具体实现思路图
图1中各个组成部分的具体功能描述如下:
(1) 网络数据服务器。要采集的目标网络数据由各类社会化媒体网站的服务器提供,如人人网服务器、新浪微博服务器等。服务器端的网络数据会以两种方式被传递给客户端的浏览器:一种是服务器端将数据整合成网页后直接发送到客户端,例如数据量较小的用户个人信息;另一种是客户端的网页通过Ajax技术请求并获取到服务器上的数据,然后再将数据填入已经载入的网页中,例如大量评论数据的分页显示。
(2) 网络数据采集程序。网络数据采集程序以Chrome扩展程序的形式直接运行于客户端的Chrome浏览器,可以直接从已载入的网页中解析出目标数据,也可以以Ajax方式根据目标数据的访问地址直接从网络数据服务器上获取到目标数据。当完成目标数据的采集后,采集程序再将数据提交给后台的数据处理服务器,供整理和存储。可见,网络数据采集程序的基础是必须分析出目标数据的传递方式,弄清楚数据在网页中的具体位置或数据的具体请求地址。对于那些受到保护的网络数据,可以在志愿者登录到网站之后再运行数据采集程序,不需要志愿者提供用户名密码,也可避免模拟登录网站的复杂逻辑。
(3) 数据处理服务器。数据处理服务器运行于后台,提供一系列基于REST模式的调用接口,网络数据采集程序可通过这些接口将采集到的目标数据发送到数据处理服务器。数据处理服务器可在后台对数据进行加工、整理和存储。数据处理服务器可置于互联网之上,位于不同地理位置的志愿者只要能访问互联网即可完成网络数据的采集。
(4) 数据库。即普通的关系型数据库,主要用于集中存储加工处理后的研究数据。
3关键技术实现
为能更为详细地阐释基于Chrome扩展程序的网络数据采集方法关键技术的实现细节,本文以采集人人网用户的状态数据为例,对网络数据采集程序和数据处理服务程序这两个核心组件的具体实现过程进行说明。
3.1网络数据采集程序的实现
Chrome浏览器的扩展程序是网络数据采集程序的实现基础,它在本质上是一段基于HTML、JavaScript和CSS等网页开发技术的小程序。Chrome浏览器的扩展程序可以被用来更改或者增强Chrome浏览器的功能,例如,通过内容脚本或者跨源请求实现与网页或者网络服务器之间的交互,也可以通过扩展程序调用书签和标签页等Chrome浏览器自带的功能。扩展程序可以有自己的用户界面,通常以两种形式来触发这个界面——浏览器动作和网页动作。当扩展程序需要作用于许多不同的网页时,可以选择浏览器动作;当扩展程序只需作用于某个特定的网页,且只有在该网页出现才需要起作用时,可以选择网页动作[9]。本文讨论的网络数据采集方法将采集来自不同网页的数据,故选择网页动作。当用户点击扩展程序图标后,程序在后台执行网络数据的采集动作,并在弹出的界面内显示数据采集的进程。
(1) 目标数据传递方式分析
在正式开发网络数据采集程序之前,必须对将要采集的目标数据的传递方式进行详细分析,为此,我们需要用到HTTP分析工具(如Chrome浏览器自带的“开发者工具”)。利用HTTP分析工具对人人网的访问过程进行分析,可以很容易发现在本例中需要首先获得人人网用户的编号,这是对人人网用户的唯一标识,也是获取该用户状态数据的基础。HTTP分析结果显示,可以通过直接访问网址“http://guide.renren.com/guide”来获得网页文件,其中“XN.user, {′id′:′373465171′”处即含有用户编号(即373465171)。因此,可以直接从网页中析取用户编号,即通过字符串处理的方法处理网页内容,并取得用户编号。进一步的HTTP分析可以发现,可以利用已获得的用户编号,通过Ajax方式访问网址“http://status.renren.com/GetSomeomeDoingList.do?userId=X&curpage=Y”即能获得用户的状态数据,其中X处用用户编号替换,Y为状态数据的页码(考虑状态数据较多需要翻页的情况)。以上网址返回的用户状态数据以JSON文件的形式存在,可通过JSON操作直接析取出需要的状态数据,如编号、发布时间、评论总数和状态内容等。
(2) 目标数据采集过程
在掌握目标数据的传递方式之后,可针对具体的传递方式编写网络数据采集程序实现目标数据的采集过程。
首先,作为一个Chrome浏览器的扩展程序,本例中网络数据采集程序最核心的文件是manifest.json,它定义了本程序的所有关键属性,包括最重要的文件和功能。在manifest.json中,声明了程序采用浏览器动作,并指明弹出的网页文件名为popup.html,更重要的是,还通过permissions参数给出了本程序可访问的网址,除了所有人人网网页的网址(http://*.renren.com/*, https://*.renren.com/*)外,还需包括数据处理服务器的网址,因为采集程序需向数据处理服务器提交结果数据。
在popup.html中加载popup.js,这是一个自行编写的JavaScript脚本程序,是实现网络数据采集过程的主体文件。由于popup.js中用到JQuery框架的Ajax调用方法,因此,popup.html中还需要加载jquery.min.js。本例中,popup.js的程序逻辑可以分为三个主要步骤:①获得用户编号;②通过用户编号获得用户状态数据;③将采集完成的状态数据提交至数据处理服务器。此处,将重点讨论以采集数据为主要目的的前两个步骤。
获取用户编号的工作由getUserID方法实现。在该方法中,首先通过Ajax请求访问网址“http://guide.renren.com/guide”,以获取包含用户编号的网页。然后,将网页视为普通文本并通过文本处理技术析取出用户编号。最后,通过用户编号调用获取用户状态数据的方法。具体的程序流程如图2所示。

图2 getUserID方法的程序流程图
用户状态的获取通过getUserStatus方法实现,该方法旨在通过用户编号获取该用户的状态数据。当状态数据较多时会出现分页的情况,必须确定当前获取的状态数据处于哪一页。因此,getUserStatus方法有用户编号(userID)和页码(n)这两个参数,在getUserID方法中调用getUserStatus方法时,参数n设定为0,即从第0页开始获取数据。getUserStatus方法的实现依然基于Ajax请求,具体的访问地址由用户编号和页码共同决定(请参考“目标数据传递方式分析”部分的分析结果)。如果请求没有异常,则会获得JSON格式的状态数据,通过JSON操作可以很方便地获取到目标数据,其核心代码如下:
function getUserStatus(userID,n){
//获取第n页的状态数据
……
//此处省略Ajax请求的发起代码
success:function(msg){
//请求成功,获取并解析返回的数据
//取得状态列表,“doingArray”为人人网规定的标识
var statusList = msg.doingArray;
if(statusList.length>0){
//状态列表不为空
for(var i=0;i //依次处理状态数据 console.log(″Status id: ″+ statusList[i].id.toString()); status = { //需要的状态信息 ″sid″: statusList[i].id.toString(), //状态编号 ″stime″: statusList[i].dtime, //状态发布时间 //状态评论数 ″scomment_count″: statusList[i].comment_count, ″scontent″: statusList[i].content //状态内容 }; userStatus.push(status); //用数组存储状态数据 } getUserStatus(userID,n+1); //继续采集下一页状态数据 }else{ //状态列表为空,已无数据可采,准备提交数据 submitResult(); //通过该方法提交结果数据 }}, ...... } (3) 结果数据的提交过程 当完成用户所有状态数据的采集之后,需要将数据提交至数据处理服务器进行集中的处理和存储,以便于科学研究的进一步使用。数据处理服务器提供的REST接口可以让网络数据采集程序很方便地通过远程调用实现数据提交。在本例中,submitResult方法可将已采集到的状态数据提交给数据处理服务器。首先,将用户编号和用户的所有状态数据封装成一个JSON数据对象,然后以Ajax方式调用数据处理服务器提供的状态数据接收接口(例如http://example.com/study/status),通过POST方法将封装有状态数据的JSON对象整体提交至数据处理服务器,最后根据数据提交结果通知用户数据采集是否顺利完成。submitResult方法完整的实现代码如下: function submitResult(){ results={ //封装状态数据的JSON对象 ″userID″: userID, ″userStatus″: userStatus }; $.ajax({ //发起Ajax请求 url:″http://example.com/study/status″, //REST接口 data:JSON.stringify(results), //将数据加入到请求中 type:″post″, //设定提交方法 dataType:″html″, contentType:″application/json;charset=UTF-8″, success:function(msg){ if(msg==″OK″){ //提交数据成功 console.log(″Succeed to submit data.″); $(″#waiting″).text(″采集数据完成。″); //通知用户 }else{ //提交数据失败 console.log(″Submit data failed:″+msg); $(″#waiting″).text(″采集数据失败。″); } }, error:function(xhr){ alert(″提交数据发生错误!″); } }); } 3.2数据处理服务程序的实现 数据处理服务程序实际是一个可以部署在互联网上的Web应用,它提供REST接口供网络数据采集程序调用,从而获得已被采集到的状态数据,然后对数据进行处理并存储至后台数据库。本文研究基于Spring框架开发了一个简单的Web应用,通过“/status”接口接收状态数据,其核心处理过程的顺序如图3所示。 图3 数据处理服务程序的顺序图 图3中RESTConroller、DataService和DAO是数据处理服务程序的主要程序模块,它们的详细功能阐述如下: (1) RESTController,是直接处理网络数据采集程序REST调用的模块,它通过HTTP协议获取采集程序提交的用户状态数据,并进一步将数据解析成JSON对象交给DataService处理。 (2) DataService,是处理并抽取已采集的具体网络数据的核心模块,它利用JSON处理工具获取诸如用户编号、状态编号、状态内容等具体的数据项,然后构建相应的Java数据对象,交给DAO处理。 (3) DAO,是负责将已采集网络数据进行持久化的模块,它直接操作后台的关系型数据库,将采集到的网络数据存入数据库。 4方法执行效果 本文基于Chrome扩展程序的网络数据采集方法已在实际研究工作中成功应用。研究招募了若干名志愿者,在向志愿者阐明研究意图并得到志愿者同意的情况下,请志愿者在Chrome浏览器上安装网络数据采集程序,然后登录人人网并点击程序图标,数据采集程序启动并完成研究数据的采集。网络数据采集程序的运行环境没有特殊要求,志愿者只需安装最新的Chrome浏览器即可。数据处理服务器的操作系统为Linux,应用服务器软件为Apache Tomcat 5.5.36,采用1.6版的Java运行环境,后台数据库为MySQL 5.0.18。 当志愿者登录人人网之后,点击右上角的“S”图标即可运行网络数据采集程序,数据采集的进程在弹出的界面上展示给志愿者。具体如图4所示。 图4 网络数据采集程序图标和界面 通过Chrome浏览器的开发者工具可以看到网络数据采集程序输出的日志信息(如图5所示),从而可以更准确地掌握数据采集的进程。 图5 网络数据采集程序的后台日志 当网络数据采集程序执行完毕后,通过数据库管理系统的界面可以查询到已经被采集到的用户状态数据。 5结语 依托实际的科研工作,本文提出一种基于Chrome浏览器扩展程序的网络数据采集方法,在系统分析网络数据采集实际需求的基础上,详细介绍了本方法的整体技术思路和核心组件的具体实现过程。基于Chrome浏览器扩展程序的网络数据采集方法弥补了网络爬虫和网站API调用等常见网络数据采集方法的不足,可以简单灵活的方式采集Web 2.0环境下受保护的各类网络数据,还可很方便地支持多用户场景下的分布式网络数据采集,为解决互联网背景下大数据研究的源数据获取问题提供了一种新的解决方案。需要说明的是,本文所提的网络数据采集方法还仅是一种新的尝试,离完善的网络数据采集工具还有一定的距离,在功能的完整性和可扩展性上还有许多工作要做。 参考文献 [1] Snijders C, Matzat U, Reips U. “Big Data”: Big Gaps of Knowledge in the Field of Internet Science[J]. International Journal of Internet Science, 2012,7(1):1-5. [2] 夏冰,高军,王腾蛟,等.一种高效的动态脚本网站有效页面获取方法[J]. 软件学报,2009,20(S1):176-183. [3] 孙青云, 王俊峰,赵宗渠,等.一种基于模拟登录的微博数据采集方案[J].计算机技术与发展,2014,24(3):6-10. [4] 纪伟. 微博数据采集系统的设计与实现[D]. 石家庄: 河北科技大学,2013. [5] Mesbah A, Deursen A V, Lenselink S. Crawling Ajax-Based Web Applications through Dynamic Analysis of User Interface State Changes[J]. ACM Transactions on the Web, 2012,6(1):1-30. [6] 刘凡凡. 支持Ajax的定址网络爬虫系统的研究与实现[D]. 北京: 北京邮电大学, 2012. [7] 朱云鹏,冯枫,陈江宁.多策略融合的中文微博数据采集方法[J]. 计算机工程与设计, 2013,34(11):3835-3839. [8] 人人网开放平台. 接口调用的配额权限[EB/OL]. 2014-10-21. http://wiki.dev.renren.com/wiki/API_Quota. [9] Google. Overview of Chrome Extension[EB/OL]. 2014-10-05. https://developer.chrome.com/extensions/overview. 收稿日期:2015-04-01。国家自然科学基金项目(71403134);教育部人文社会科学研究青年基金项目(14YJCZH122);江苏高校哲学社会科学研究基金项目(2014SJB009)。沈洪洲,讲师,主研领域:社会化媒体。 中图分类号TP302 文献标识码A DOI:10.3969/j.issn.1000-386x.2016.07.003 AN INTERNET DATA COLLECTION METHOD BASED ON CHROME EXTENSION Shen Hongzhou (SchoolofManagement,NanjingUniversityofPostsandTelecommunications,Nanjing210023,Jiangsu,China) AbstractCollecting large amounts of Internet data can provide important data base for relevant scientific research. For the current situation that researchers can’t easily and flexibly collect targeted Internet data, this paper proposes a Chrome extension-based Internet data collection method, which will extract data from a Webpage, or read the structured data directly from Webpage server with Ajax technology, and makes centralised processing and storage for the collected data. The final implementation results indicate that this new method can break through the restrictions of dynamic Webpage technology, avoids the complex logic of user login and supports distributed Internet data collection in multi-user scenarios as well. KeywordsChrome extensionInternet data collectionAjaxDistributed