基于马尔科夫随机场的非参数化RGB-D场景理解
2016-08-04费婷婷龚小谨
费婷婷,龚小谨
(浙江大学 信息与电子工程学系,浙江 杭州 310027)
基于马尔科夫随机场的非参数化RGB-D场景理解
费婷婷,龚小谨
(浙江大学 信息与电子工程学系,浙江 杭州 310027)
摘要:针对RGB-D场景下的场景理解问题,提出高效的基于标签传递机制的非参数化场景理解算法.该算法主要分为标签源构建、超像素双向匹配和标签传递三个步骤.与传统的参数化RGB-D场景理解方法相比,该算法不需要繁琐的训练,具有简单高效的特点.与传统的非参数化场景理解方法不同,该算法在系统的各个设计环节都有效利用了深度图提供的三维信息,在超像素匹配环节提出双向匹配机制,以减少特征误匹配;构建基于协同表示分类(CRC)的马尔科夫随机场(MRF),用Graph Cuts方法求出最优解,获得场景图像每个像素的语义标签.该算法分别在室内的NYU-V1数据集和室外的KITTI数据集上进行实验.实验结果表明,与现有算法相比,该算法取得了显著的性能提升, 对室内、外场景均适用.
关键词:场景理解;非参数化;RGB-D;马尔科夫随机场(MRF)
场景理解是用模式识别和人工智能的方法对场景图像进行分析、描述、分类和解释,最终得到场景图像中每个像素语义标签的技术,是计算机视觉的一个重要课题,在无人车驾驶、机器人导航、虚拟现实、安防监控等领域有着广泛的应用.
近年来,随着激光雷达[1]以及微软Kinect[2]等距离传感器的面世,场景深度信息的获取变得更加容易,结合三维点云数据或致密深度等三维信息的场景理解方法引起了众多学者的广泛关注[3-6].谭伦正等[4-5]采用神经网络训练的方法来进行场景理解;Ren等[6]提出基于分割树的参数化场景理解方法,对分割树的每一层分别训练一个支持向量机(supportvectormachine,SVM)分类器,结合马尔科夫随机场(Markovrandomfield,MRF)进行求解.这些参数化方法都依赖繁琐的模型训练,对场景类别的伸缩性非常差,一旦场景的语义类别发生增减,就需要对所有语义类别重新训练模型,非常耗费运算时间和计算资源.本文设计一种无需依赖任何训练、通过场景图像间的相似性传递语义标签的非参数化方法.
现有的非参数化场景理解方法主要在二维图像上展开研究[7-13],Liu等[11]首先提出通过标签传递进行场景理解的思路,将目标像素与标签源像素SIFT特征的最小欧氏距离定义为似然函数,构建MRF求解目标图像每个像素的标签.由于基于像素的方法计算量太大,Tighe等[12]提出用超像素作为场景理解的基本处理单元,设计利用目标超像素标签源中k近邻(k-nearestneighbor,kNN)属于各个语义类别的频率,定义目标超像素属于该语义类别的似然.Yang等[13]在文献[12]的基础上设计稀有类别的补充机制,提高了稀有类别的标注准确率.这些非参数化场景理解方法都利用像素或者超像素间的匹配度进行标签传递,没有考虑匹配到的各个近邻对目标对象的贡献差异.针对该问题,Eigen等[14]提出自适应近邻的标签传递方法,在文献[12]的基础上为目标待标注对象匹配到的各个近邻分配权重,以度量各近邻对目标对象的贡献差异,但权重的获得是通过训练得到的.为了避免耗时繁琐的训练,本文创新性地设计了基于协同表示分类 (collaborativerepresentationbasedclassification,CRC)[15]的标签传递机制,不仅充分考虑了标签源中的不同超像素对目标超像素的贡献差异,而且节省了运算时间和计算资源,使得整个算法更加简单高效.
二维图像包含的信息有限,单纯利用二维图像的信息进行场景理解难以取得令人满意的效果,为了提升算法性能,在算法的各个步骤都充分利用了深度图的三维几何信息.
1) 在标签源的构建过程中,设计了基于深度的法向量直方图,用以检索与目标图像空间布局相似的图像.
2) 在局部特征双向匹配的过程中,从深度图中提取了深度梯度核描述符.
3) 在MRF的平滑项中,设计了基于深度的表面法向量平滑项,用以惩罚为表面法向量夹角过大的相邻超像素分配相同语义标签的情况.
1算法概述
提出的非参数化的场景理解方法主要分为3个步骤:标签源构建、超像素双向特征匹配和基于马尔科夫随机场(MRF)的标签传递.标签源由相似图像检索集和稀有类别词典两部分组成,相似图像检索大大缩小了标签源的范围,不仅减少了场景不同的噪声标签的干扰,而且大幅提升了算法的运算速度.超像素双向特征匹配的目的是衡量匹配的超像素对之间的相似度,为标签的传递提供依据.考虑到图像相邻超像素间语义类别的平滑性,构建马尔科夫随机场(MRF),进一步提升算法的性能.如图1所示为该算法的流程框图.

图1 场景理解算法流程图Fig.1 Flow chart of scene parsing algorithm
首先输入目标待标注场景的RGB图像和深度图,结合RGB图像中提取的外观特征和深度图中提取的三维几何特征,将待标注的目标图像与训练集中已标注的图像进行全局特征匹配,根据欧氏距离构建目标图像的相似图像检索集.为了减少目标图像中稀有类别标签的丢失,根据各语义类别的超像素在训练集中所占的比例,构建稀有类别词典,与相似图像检索集一起作为待标注图像的标签源.结合RGB-D图像的颜色信息和深度信息对目标图像及目标图像标签源的超像素进行特征提取,并对提取的特征进行双向特征匹配.构建基于协同表示分类(CRC)[15]的马尔科夫随机场(MRF),通过Graphcuts[16]的方法求解能量方程得到目标图像每个超像素的语义标签.
2标签源构建
通常相似的场景所包含的语义信息往往是相似的,在数据量足够大的前提下,总是能够找到与目标待标注图像场景相似的图像,这为利用图像间的相似性进行语义标签的传递提供了可能.
为了降低算法的运算量,减少场景不同的噪声图像标签对目标图像标注的干扰,首先根据全局特征匹配构建待标注目标图像的相似图像检索集.为了充分表达图像的全局特征,采用3种全局特征:GIST特征[17]、颜色直方图hcol和法向量直方图hnor.GIST特征[17]和颜色直方图都从RGB图像中提取,本文提取的GIST特征为960维,从目标图像的R、G、B3个通道,在方向分别为8、8、4的3个尺度上提取,颜色直方图分别将R、G、B三个通道的值量化到8个单位柱上生成一个24维的特征.
法向量直方图是本文提出的一种新的三维全局特征,从图像的深度图中提取,先对深度图中的每个像素计算对应的三维法向量n(x,y,z),然后将图像所有像素的法向量的x、y、z三个维度的值分别量化到8个单位上,生成一个24维的特征.法向量直方图能够检索出具有相似空间布局的图像,但与GIST不同的是,在场景不十分杂乱,空间结构较规律的情况下,法向量直方图能够更好地描述图像的整体空间布局,检索到的相似图像的空间布局与目标图像更相近,对应的例子见图2的测试图像1.
在3种全局特征提取完成后,根据每种特征,分别将训练集图像按与目标图像对应特征的欧氏距离升序排列.为了最大限度地剔除与目标图像场景不同的图像,以减少噪声标签的干扰,将排列好的3组图像的前K1(K1=350)个图像的交集作为目标图像的相似图像检索集.
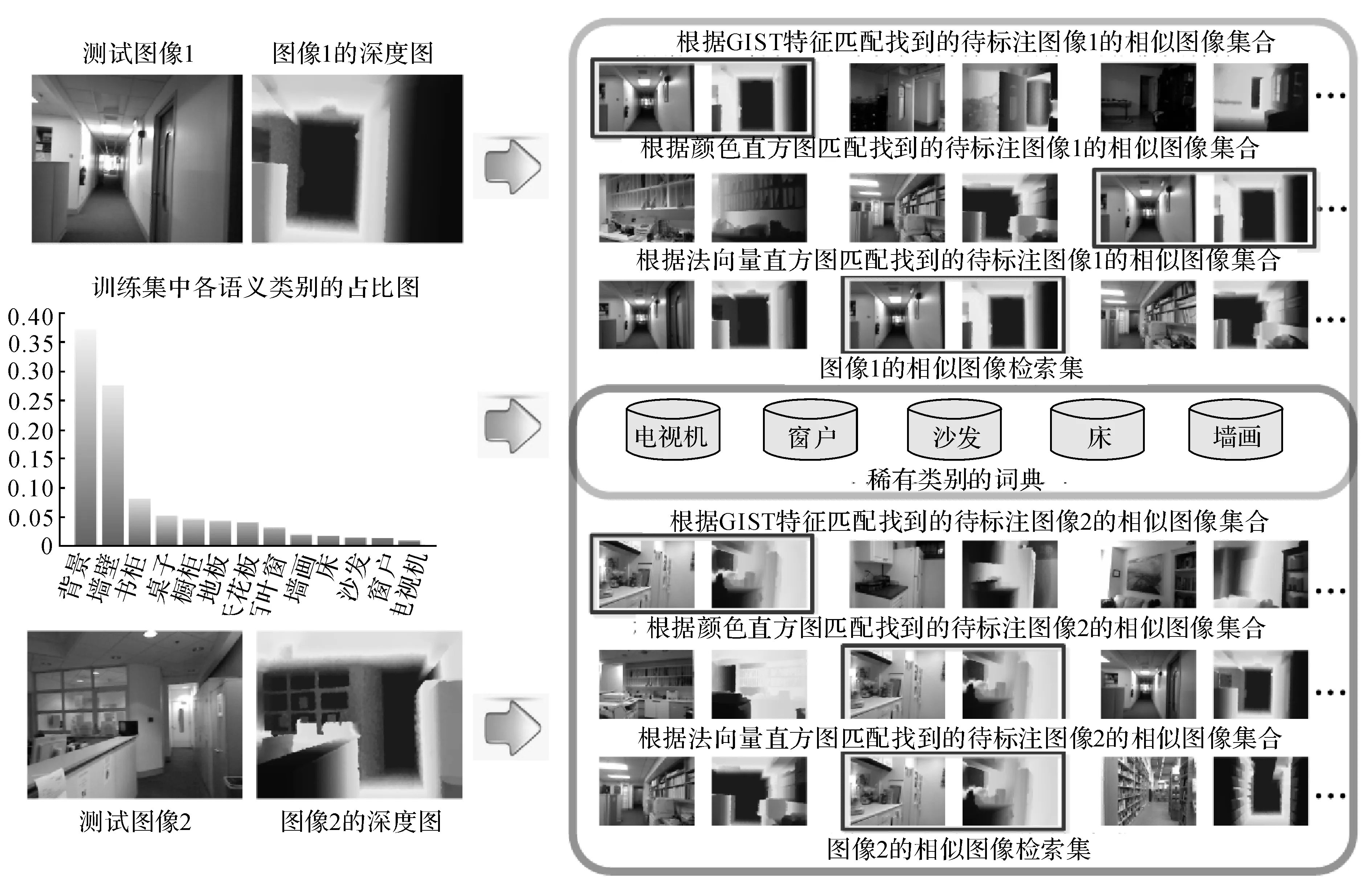
图2 标签源构建流程图Fig.2 Flow chart of label pool construction
全局特征只能描述图像的全局信息,因此目标图像中的某些语义标签,尤其是稀有类别的语义标签很可能在其相似图像检索集中缺失,从而导致这些语义标签无法通过标签传递被准确标注.如图2的测试图像2,目标测试图像中有一个小电视机,但3种全局特征检索到的相似图像检索集中没有“电视机”这个语义标签.针对该问题,将各个语义类别的超像素在训练集中占比低于3%的类别定义为稀有类别,分别对各稀有类别的超像素进行K-means聚类,聚类中心个数设置为100,这100个聚类中心构成的集合为该类别的词典.将稀有类别超像素的词典与相似图像检索集的超像素作为目标图像的标签源.标签源的构建流程如图2所示.
3超像素双向特征匹配
3.1特征提取
标签传递在像素或者超像素上都可以进行.本文采用超像素作为标签传递的基本单元,一方面大大降低了算法的运算成本;另一方面,在特征提取的过程中,对像素的特征提取考虑的往往是以该像素为中心的固定尺寸的方格范围,与之相比,超像素通常能够将属于同一个物体的区域聚集起来,为特征提取提供更好的空间支持.本文采用TurboPixel算法[18]对图像进行过分割,利用核描述符(Kerneldescriptor)[19]对生成的超像素进行特征提取.核描述符是Bo等[19]提出的一种特征提取方法,本文从二维图像中提取了梯度核描述符fgd和颜色核描述符fcol,从深度图中提取了深度梯度核描述符fgd-d;然后将3种核描述符串联,生成待匹配的局部特征f.
(1)
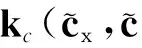
(2)
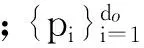
与SIFT、HOG等传统特征相比,核描述符可以通过设计不同的核函数,将颜色、纹理、形状等多种二维及三维特征整合成相同的形式,不仅能够有效地利用二维图像的外观信息和三维图像的几何信息,对图像进行更全面的表达,而且相同的特征形式能够更好地进行特征融合,为后续的处理提供便利.
3.2双向特征匹配
标签传递的本质是根据超像素间的相似度,将标签源中已标注的超像素的标签通过某种传递机制传递给目标待标注的超像素.首先对目标图像中待标注的超像素与标签源中已标注的超像素进行相似度度量,传统的方法主要通过超像素间的单向特征匹配来实现.为了有效减少单向特征匹配不可避免的误匹配,本文设计了一种双向匹配策略.
为了剔除集合SR(si)中误匹配的超像素,设计将SR(si)中的超像素反向匹配到目标图像.对于SR(si)中的每个超像素sq,根据核描述符的欧氏距离,在目标图像的超像素ST中找出与其最相似的超像素N(sq).若si与N(sq)的二维欧氏距离太大或者三维高度相差太大,则把SR(si)中的超像素sq从中剔除,最后生成si的匹配集mi,描述如下.
(3)
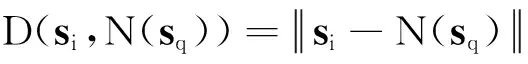
4基于马尔科夫随机场的标签传递
考虑到超像素邻域间的上、下文约束,构建基于马尔科夫随机场(MRF)的标签传递模型.将为目标图像每个超像素分配语义标签的问题转换成最小化如下能量函数的优化问题:
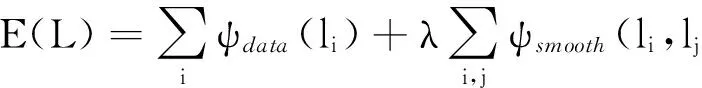
(4)
式中:L为目标待标注图像所有超像素的标签集;l为超像素的语义标签;ψdata为马尔科夫随机场(MRF)的数据项;ψsmooth为马尔科夫随机场(MRF)的平滑项,主要对邻域超像素对(si,sj)的语义标签进行平滑,过分割后与目标超像素si有公共边的所有超像素集合组成该目标超像素的邻域;λ为自定义的平衡系数,λ=10.式(4)的优化函数可以利用Graph Cuts[16]求解,Graph cuts是一种十分有用和流行的能量优化算法,该方法把图像分割问题与图的最小割(min cut)问题相关联.首先用一个无向图G=
GraphCuts中的Cuts是指这样一个边的集合,该集合中所有边的断开会导致残留“S”和“T”图的分开,所以就称为“割”.若一个割的边的所有权值之和最小,则称为最小割,即图割的结果.福特-富克森定理表明,网路的最大流(maxflow)与最小割(mincut)相等.由Boykov发明的max-flow/min-cut算法[16]可以用来获得s-t图的最小割.
虽然马尔科夫随机场模型已经在现有的非参数化场景理解方法中得到了广泛使用[10-12],但与传统的非参数化方法相比,本文数据项的设计更有效,在平滑项中增加的邻域超像素间的三维几何约束进一步提升了算法性能.具体的构建方法详述如下.
4.1MRF数据项构建
在传统的非参数化场景理解方法中,MRF数据项的构建一般都直接利用各近邻与目标超像素的欧氏距离来构建数据项,这样的处理方式忽视了不同近邻对目标超像素的贡献差异.针对该问题,采用基于协同表示分类(CRC)[15]的匹配残差来构建数据项.
当目标超像素si及局部特征fi确定后,在si的匹配集mi与稀有类别词典共同构建的标签源的标签类别C(si)中为目标超像素分配一个语义标签.CRC模型假设目标超像素位于标签源超像素的子空间,先通过求解L2正则化的最小二乘问题来估计系数矩阵:
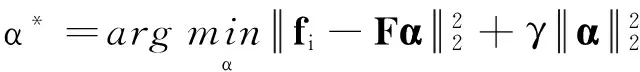
(5)
式中:F为标签源中所有超像素的特征排列堆叠构建得到的测量矩阵;γ为一个自定义的正则系数,γ=10-3.Zhang等[15]指出,式(5)中由L2范数正则化的协同表示问题可以通过矩阵法得到如下形式的解:
α*=(FTF+γI)-1FTfi.
(6)
令P=(FTF+γI)-1FT,因为P与样本无关,可以预计算成一个投影矩阵,每当要计算待标注目标超像素si的系数α*时,只需将超像素的特征fi投影到矩阵P,无需再次计算P,所以运算速度非常快.
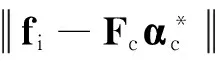
设计如下形式的数据项:
(7)
设计的基于CRC的数据项本质上是通过α*为目标超像素标签源中的各个超像素分配了自适应的权重,充分考虑了标签源中不同超像素对目标超像素的贡献差异.与其他通过离线训练来分配权重的方法[14]相比,本文的方法更加简单、高效.
4.2MRF平滑项构建
本文算法的平滑项主要根据相邻超像素间的相似度进行构建,结合二维图像信息和三维几何信息,构建如下形式的平滑项:
(8)
式中:φnor为相邻超像素si与sj表面法向量的内积,是利用从深度图中提取的表面法向量ni和nj,设计的一种新的平滑项.通常,表面法向量夹角大的相邻超像素属于相同语义类别的可能性较小,因此,设计该平滑项来对表面法向量夹角过大的相邻超像素分配到相同的语义标签进行惩罚.φfea利用相邻超像素特征的相似度对语义标签进行平滑,趋向于使特征相似的相邻超像素具有相同的语义标签,特征fi和fj的提取如前文所述,融合了二维图像的颜色信息和三维图像的几何信息.φnor的内积形式本质上是一个夹角余弦函数,是普适的向量相似度的度量标准;φfea采用径向基函数的形式,是普适的特征相似度的度量标准.因为两者都是归一化后的结果,具有可比性,共同平滑邻域超像素语义标签的平滑性.
5实验结果与分析
5.1室内场景
首先在室内场景的NYU-V1数据集[5]上进行实验.NYU-V1数据集[5]包含2 284幅由Kinect采集得到的480×640像素的图像,每幅图像对应有人工标注的语义标签,经过WordNet的处理,将所有的语义标签种类缩减至12个语义类别,除此之外的所有类别都归到“背景”一类.在实验过程中,随机选取数据集中60%的图像作为训练集,剩下的40%作为测试集.根据12个语义类别的超像素在数据集中的占比,选取占比不超过3%的语义类别作为稀有类别,得到的稀有类别为“电视机”、“窗户”、“沙发”、“床”和“墙画”.
表1将本文算法与现有的几个前沿场景理解算法进行像素准确率pp的性能对比.分析表1可以发现,不管与现有的参数化的RGB-D场景理解算法[6]还是非参数化的RGB场景理解算法[12]相比,该算法的像素准确率都得到了显著的提高,在性能上取得了长足的进步.
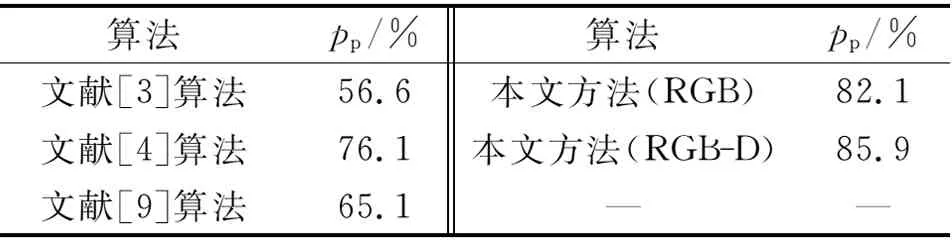
表1 像素准确率结果的对比
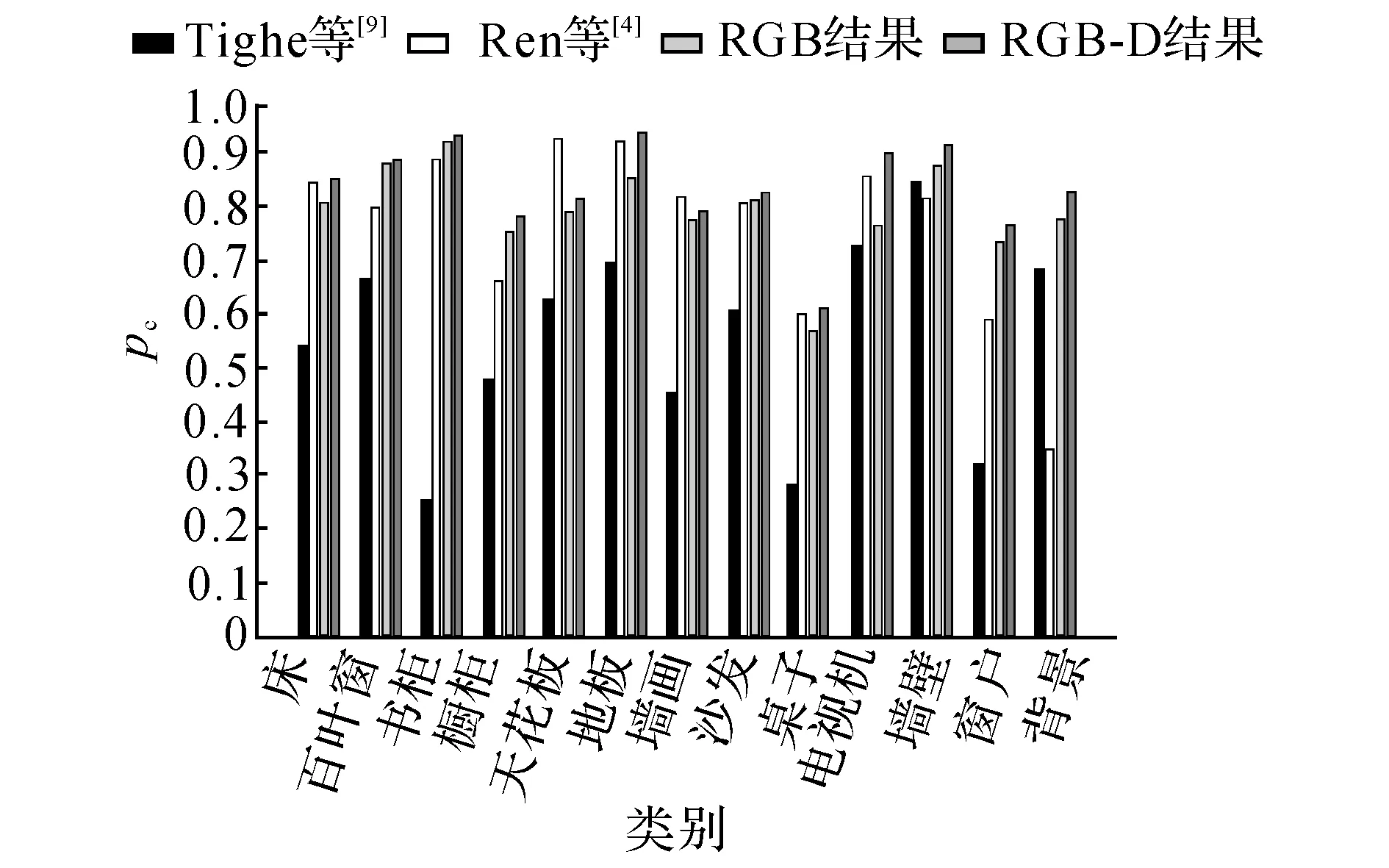
图3 语义类别准确率的对比结果图Fig.3 Comparative results of per-class accuracy
为了进一步分析该算法的优缺点,针对每个语义类别的准确率,与Ren等[6]提出的参数化RGB-D场景理解算法及Tighe等[12]提出的非参数化RGB场景理解算法进行比较.实验结果如图3所示.图中,pc为语义类别准确率.对比图3中该算法的RGB结果和RGB-D结果可以发现,在每个语义类别上,该算法在RGB-D上的准确率都比RGB上的准确率高,证明该算法对深度信息进行了有效利用.
对比本文算法的RGB-D结果与Ren等[6]的参数化RGB-D场景理解算法结果可知,本文算法取得了更高的准确率,原因在于该算法的非参数化机制,因为参数化方法需要对每个语义类别训练模型,但即使属于同一个语义类别的物体的特征也不尽相同,比如沙发有皮质的和布艺的,桌子有木质的和塑料的,颜色更是多种多样,所以难以训练出一个能够表达所有样本的模型.最典型的体现是在 “背景”这类,由于该类别表示的是许多语义类别的杂糅,而非单纯的某一种语义类别,基于模型训练的参数化方法无法为“背景”类别训练生成一个具有语义意义的模型.即使有效结合了深度信息,Ren等[6]的参数化方法在这一类上仍然无法取得好的效果.本文的非参数化方法基于相似超像素之间的标签传递,只要数据量足够大,总是能够找到与目标超像素足够相似的样本,进行准确的标签传递.
与Ren等[6]提出的算法相比,在“天花板”和“墙画”这两个类别上没有取得更好的效果.经过分析可以发现,在原始的数据集中,这两个类别的人工标注存在较多的误标注,即使对超像素进行了正确的匹配,也无法在标签传递的过程中避免因为误标注带来的影响.与参数化方法[6]相比,本文算法对误标注更敏感.
图4列出了几组典型的实验结果图.观察图4的第1组实验结果图可以发现,单纯基于RGB的场景理解很难区分颜色相似、但分属不同语义类别的物体,观察第2和第3组实验结果图可以发现,单纯的RGB场景理解难以处理光照昏暗的情况,而深度信息不受颜色和光照的影响,结合深度信息的RGB-D场景理解能够有效地处理这些情况.
本文的场景理解方法在NYU-V1数据集中平均每张图片的本地测试时间为149.8s,其中,核描述符的计算较慢, 单张图片的平均用时占到了总用

图4 NYU-V1数据集中的几组典型实验结果图Fig.4 Typical examples from NYU-V1 dataset
时的一半,为79.5s.在相同的计算机配置下,文献[6]的方法用作者官网上的原始代码,在NYU-V1数据集上的总用时为4.92×105s,平均每张图片需要用时538.5s.因为本文算法不需要训练的过程,而且数据集的全局特征只需要计算一次存下来即可,基于CRC的马尔科夫数据项的计算可以先对投影矩阵进行预计算,每计算一个超像素的协同系数,只需要进行一次投影,所以运算速度非常快.
5.2室外场景
本文算法能够同时适用于室内、外场景,在室外场景的KIITI数据集[20]上进行简单的实验.随机选取96张图像作为测试集.KITTI数据集[20]中的图像没有给出对应的语义标签,若通过全局特征匹配的方法选取标签源,因为我们的算法是监督的,则需要事先对标签源中的图像进行人工标注,而像素级语义标签的人工标注非常耗时,因为KITTI数据集是时序的,将测试集中每张图像前面第3帧的图像作为该图像的标签源,能够达到减少不同场景干扰的目的.本文没有另行计算测试集图像的相似图像检索集和稀有类别词典.
在RGB和RGB-D上分别进行实验,在RGB上取得了89.8%的像素级准确率,在RGB-D上取得了93.9%的像素级准确率.图5列出了几组典型的室外场景的实验结果图.可以看出,本文算法在室外场景中取得了理想的效果.分析图5可以发现,只利用RGB信息的场景理解,很难对室外场景的阴影部分进行准确的标记,而阴影在室外场景中是非常普遍的,加入深度信息后,阴影的问题得到了很好的解决.

图5 KITTI数据集中的几组典型实验结果图Fig.5 Typical examples from KITTI dataset
6结语
本文提出基于标签传递机制的非参数化RGB-D场景理解方法.与传统的参数化RGB-D场景理解方法相比,本文算法不需要繁琐的训练,不仅降低了运算成本,提升了运算速度,而且在准确率上得到了显著的提高.与传统的非参数化RGB场景理解方法相比,本文算法一方面有效结合了深度信息;另一方面,本文算法比传统非参数化方法优越的地方在于:1)设计了双向特征匹配机制,有效减少了传统非参数化方法单向特征匹配产生的误匹配;2)设计了基于CRC的匹配残差的标签传递机制,比基于kNN欧氏距离的标签传递机制更好地描述了标签源中不同超像素对目标超像素的贡献差异,有效提升了算法的性能.
室内、外场景的实验结果证明,提出的方法简单高效,效果可靠.
参考文献(References):
[1]Velodyne.Velodynehdl-64e[EB/OL]. [2014-06-10].http:∥velodynelidar.com/lidar/.
[2]Kinect.Microsoftkinect[EB/OL]. [2014-06-10].http:∥www.microsoft.com/enus/kinectforwindows/develop/learn.aspx.
[3] 闫飞, 庄严, 王伟. 移动机器人基于多传感器信息融合的室外场景理解[J]. 控制理论与应用, 2011, 28(8):1093-1098.
YANFei,ZHUANGYan,WANGWei.Outdoorscenecomprehensionofmobilerobotbasedonmulti-sensorinformationfusion[J].ControlTheoryandApplications, 2011, 28(8):1093-1098.
[4] 谭伦正, 夏利民, 夏胜平. 基于多级Sigmoid神经网络的城市交通场景理解[J]. 国防科技大学学报, 2012, 34(4): 1001-2486.
TANLun-zheng,XIALi-min,XIASheng-ping.Urbantrafficsceneunderstandingbasedonmulti-levelsigmoidalneuralnetwork[J].JournalofNationalUniversityofDefenseTechnology, 2012, 34(4): 1001-2486.
[5]SILBERMANN,FERGUSR.Indoorscenesegmentationusingastructuredlightsensor[C]∥ProceedingsofICCV.Barcelona:IEEE, 2011: 601-608.
[6]RENXiao-feng,BOLie-feng,FOXD.RGB-(D)scenelabeling:featuresandalgorithms[C]∥ProceedingsofCVPR.Providence:IEEE, 2012: 2759-2766.
[7]TORRALBAA,FERGUSR,FREEMANWT. 80milliontinyimages:alargedatasetfornon-parametricobjectandscenerecognition[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2008, 30(11): 1958-1970.
[8]SHOTTONJ,WINNJ,ROTHERC,etal.Textonboostforimageunderstanding:multi-classobjectrecognitionandsegmentationbyjointlymodelingtexture,layout,andcontext[J].InternationalJournalofComputerVision, 2009, 81(1): 2-23.
[9]FARABETC,COUPRIEC,NAJMANL,etal.Learninghierarchicalfeaturesforscenelabeling[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2013, 35(8): 1915-1929.
[10]STURGESSP,ALAHARIK,LADICKYL,etal.Combiningappearanceandstructurefrommotionfeaturesforroadsceneunderstanding[C] ∥ProceedingsofBMVC.London:BMVA, 2009.
[11]LIUCe,YUENJ,TORRALBAA.Nonparametricsceneparsing:labeltransferviadensescenealignment[C]∥ProceedingsofCVPR.Miami:IEEE, 2009: 1972-1979.
[12]TIGHEJ,LAZEBNIKS.Superparsing:scalablenonparametricimageparsingwithsuperpixels[C] ∥ProceedingsofECCV.Heraklion:Springer, 2010: 352-365.
[13]YANGJ,PRICEB,COHENS,etal.Contextdrivensceneparsingwithattentiontorareclasses[C] ∥ProceedingsofCVPR.Columbus:IEEE, 2014.
[14]EIGEND,FERGUSR.Nonparametricimageparsingusingadaptiveneighborsets[C] ∥ProceedingsofCVPR.Providence:IEEE, 2012: 2799-2806.
[15]ZHANGLie,YANGMeng,FENGXiang-chu.Sparserepresentationorcollaborativerepresentation:whichhelpsfacerecognition? [C] ∥ProceedingsofICCV.Barcelona:IEEE, 2011: 471-478.
[16]BOYKOVY,VEKSLERO,ZABIHR.Fastapproximateenergyminimizationviagraphcuts[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2001, 23(11): 1222-1239.
[17]OLIVAA,TORRALBAA.Buildingthegistofascene:theroleofglobalimagefeaturesinrecognition[J].ProgressInBrainResearch, 2006, 155: 23-36.
[18]LEVINSHTEINA,STEREA,KUTULAKOSNK,etal.Turbopixels:fastsuperpixelsusinggeometricflows[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2009, 31(12): 2290-2297.
[19]BOLie-feng,RENXiao-feng,FOXD.Kerneldescriptorsforvisualrecognition[C] ∥NIPS.Vancouver:NeuralInformationProcessingSystemsFoundation, 2010: 244-252.
[20]GEIGERA,LENZP,URTASUMR.Arewereadyforautonomousdriving?theKITTIvisionbenchmarksuite[C] ∥ProceedingsofCVPR.Providence:IEEE, 2012: 3354-3361.
收稿日期:2015-05-13.浙江大学学报(工学版)网址: www.journals.zju.edu.cn/eng
作者简介:费婷婷(1990-),女,硕士生,从事机器视觉研究.ORCID: 0000-0003-1924-426X.E-mail:21231083@zju.edu.cn 通信联系人:龚小谨,女,副教授.ORCID:0000-0001-9955-3569.E-mail:gongxj@zju.edu.cn
DOI:10.3785/j.issn.1008-973X.2016.07.014
中图分类号:TP 391
文献标志码:A
文章编号:1008-973X(2016)07-1322-08
NonparametricRGB-DsceneparsingbasedonMarkovrandomfieldmodel
FEITing-ting,GONGXiao-jin
(Department of Information Science and Electronic Engineering, Zhejiang University, Hangzhou 310027, China)
Abstract:An effective nonparametric method was proposed for RGB-D scene parsing. The method is based upon the label transferring scheme, which includes label pool construction, bi-directional superpixel matching and label transferring stages. Compared to traditional parametric RGB-D scene parsing methods, the approach requires no tedious training stage, which makes it simple and efficient. In contrast to previous nonparametric techniques, our method not only incorporate geometric contexts at all the stages, but also propose a bi-directional scheme for superpixel matching in order to reduce mismatching. Then a collaborative representation based classification (CRC) mechanism was built for Markov random field (MRF), and parsing result was achieved through minimizing the energy function via Graph Cuts. The effectiveness of the approach was validated both on the indoor NYU Depth V1 dataset and the outdoor KITTI dataset. The approach outperformed both state-of-the-art RGB-D parsing techniques and a classical nonparametric superparsing method. The algorithm can be applied to different scenarios, having a strong practical value.
Key words:scene parsing; nonparametric; RGB-D; Markov random field (MRF)
