A Study on Cross Processing between the Same Family and Similar Languages
2016-07-28MUHEYATNiyazbekKUENSSAULETalpDAWAIdomucao
MUHEYAT Niyazbek, KUENSSAULE Talp, DAWA Idomucao
(1. School of Information Science and Engineering, Xinjiang University, Urumqi 830046, China;2. Xinjiang Laboratory of Multi-language Information Technology, Urumqi 830046, China;3. College of Chinese Medicine of Xinjiang Medical University, Urumqi 830011, China)
A Study on Cross Processing between the Same Family and Similar Languages
MUHEYAT Niyazbek1,2, KUENSSAULE Talp3, DAWA Idomucao1,2
(1.SchoolofInformationScienceandEngineering,XinjiangUniversity,Urumqi830046,China;2.XinjiangLaboratoryofMulti-languageInformationTechnology,Urumqi830046,China;3.CollegeofChineseMedicineofXinjiangMedicalUniversity,Urumqi830011,China)
Abstract:The extension of natural language processing systems, such as MT(machine translation), to a new language especially the minority languages being used in China requires large amounts of parallel data. Generally, it is prohibitive to collect huge parallel data. This paper first investigates the similarity level between the same family and closer languages(such as Altai family languages) and then examines a transformation between their words and texts. Cosine similarity measure and dynamic programming(DP) algorithm are used to calculate the similarity between the source and target languages using a multilingual parallel data set. Test data set includes 7854 parallel sentences of Chinese, Uyghur, Kazakh and Mongolian various writing systems. Experimental results demonstrate that the similarity level of the languages from the same language branch is higher than that between different language branches while lower than that between the Altai family languages. Furthermore, it is found that a text transformation of word to word units is feasible for the same language branches when replacing the function affixes of word using a function affixes rule bank to create common models. Additionally, it functions well without MT and order changes of parallel sentences.
Keywords:text transformation; similar language; similarity; DP algorithm; minority language
Language can be considered as a unique representation of the national culture and plays an important role in the research of the development and expanding traditional culture.
Researches work on the national language processing for minority languages are gradually move from character display to intelligentized text processing. However, the resources, such as bilingual corpus, are very important to the multilingual text and speech processing. It is prohibitive to accumulate and create huge number of resources for developing country-wide languages like minority languages spoken in China.
Some languages, like Altai family languages, are very similar in their writing system and spoken style. Fig.1 shows the sentence alignment examples writing by different graphic characters of Mongolian. They are used today in Inner Mongolia, Xinjiang, and Mongolia respectively. We call them Mongolian language branch[1](MLB). Another set of sentences shown in Fig.2 are Uyghur, Kazakh and Kyrgyz languages, all written by Arabic graphic characters belonging to Turkish. These languages are called TLB. We can see that each sentence consists of a sequence of entries, where two entries are separated by a space. The SOV grammar, the order of subject, predicate, object and verb, edit rule of a word and word order, are similar to each other. MGL and TLB are different in the writing style, but they are very close in SOV grammar and syntax.
We can also find the relationship between each entry indicated by bias parts in Fig.1 or Fig.2. In a case of MLB,a transformation of word by word or stem by stem units is derived from ToDo to NM. However, it is rather difficult for the case of TM to ToDo and NM to MGL as shown in Fig.3. Notably from Fig.2, a text transformation between TLB of word or stem units may be possible.
When performing MT from Chinese to Uyghur or to Kyrgyz, the method illustrated in Fig.4 may be an efficient way. The overall procedure is that an MT from Chinese to Uyghur is first performed, and followed by TT(text transformation) from Uyghur to Kyrgyz or Kazakh, and not Chinese to Uyghur and again do Chinese to Kyrgyz. Many common stems and the same order are also observed in the case of Uyghur to Kyrgyz or Kazakh, as indicated in red parts in Fig.4. This method can also be applied for the transformation between MLB. In this work, we will first investigate the similarity level between the texts of MLB or TLB. Then we propose an approach to transform texts between similar languages in different groups of MLB or TLB based on the similarity of bilingual text entries and DP algorithm.
1Previous researches
T. Schultz et al. developed a way for acoustic modeling cross languages using global phoneme mapping to 15 languages acoustic data[2]. They examine what performance can be expected in this scenario. Their experiments are only for speech recognition on the resource sparse languages. The paper[3]introduces various approaches adopted in Chinese-English Cross language information retrieval via MT technique. Furthermore, there are many researches focused on only computing sentence similarity on the same language text for improving MT quality[4].
At present, researches on cross language transformation in the same family language, particularly minority languages, are not usual. In our framework, we proposed an approach based on a data-driven and linguistic rule to transform the Mongolian texts writing by multiform characters[5].
2Investigation approach
2.1Bilingual text similarity
In order to derive similarity of two sequences from bilingual alignment text, a cosine similarity method is used in this research.Cosine similarity is a measure of similarity between two vectors of an inner product space that measures the cosine of the angle between them. The cosine of 0° is 1, and it is less than 1 for any other angle. It is thus a judgment of orientation and not magnitude: Two vectors with the same orientation have a cosine similarity of 1, two vectors at 90° have a similarity of 0, and two vectors diametrically opposed have a similarity of -1, independent of their magnitude[6]. Cosine similarity is particularly used in positive space, where the outcome is neatly bounded in [0,1]. The cosine of two vectors can be derived by using the following formula: Given two vectors of attributes for example,AandB(see function (1)), the cosine similarity, cos(θ), is represented using a dot product and magnitude as function (2). In herenandmis indicate the size of entries of two texts respectively.
(1)
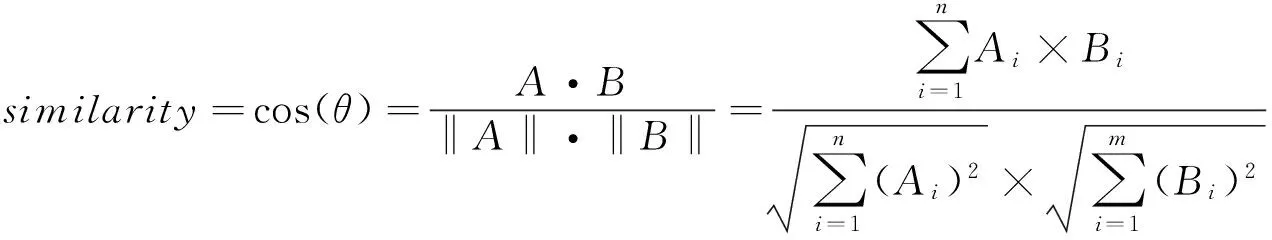
(2)
For text matching, the attribute vectorsAandBare usually the term frequency vectors of the documents. The cosine similarity can be seen as a method of normalizing document length during comparison.
2.2DP matching
In this section, a way to create the target language word model from the result of similarity word’s list is proposed based on the DP(Dynamic Programming) algorithm. This means that to develop a rule to find a target language entry when having source language entry and similar strings resulted from alignment sentences.
DP, also known as dynamic time warping(DTW), was introduced for non-linear time alignment of two continuing patterns[7]. DP can effectively minimize errors that occur during the time alignment of the two patterns. Compared with conventional methods of matching two strings such as edit distance and longest common subsequence[8], DP is more effective because an entry can correspond to more than one entry during the matching. The DP algorithm is addressed as follows:
Consider two entriesW1andW2with arbitrary length, say,landkrespectively in equation (3):
(3)
Taking distancedt(i,j) between the entries, we initialize them as follows:
(4)
(5)
Forj=1to|W2|,gt(0,j)=gt(0,j-1)+dt(0,j),
Fori=1to|W1|,gt(i,0)=gt(i-1,0)+dt(i,0).
(6)
Then, the matching between entriesW1andW2is regarded as a temporal alignment in a two-dimensional plane(see Fig.5). Suppose that the sequence of matched pairscl(il,jl) ofW1andW2forms a time warping functionFexpressed as,
F=c1,c2,…,cl,…,cL.
(7)
Letgl(cl) denote the minimized overall distance representing the explicitly accumulated distance fromc1(1,1) tocl(i,j). Then,gl(cl)=gl(i,j) can be expressed by equation (8) when the initializations are given by equations (5) and (6)(here,lis the size of the entries):
(8)


(9)
Note that, the implementation of equation (8) runs inO(k,l) time.
3Experiments and results
3.1Data
Focusing on the multilingual medical service system, a multilingual parallel database was built in our framework, supported by NSFCP[SFXP]. This database was collected from Chinese sentences in the medical science and medicine information domain, and translated to Uyghur, Kazakh and Mongolian manually. There are 7 854 sentence pairs used to evaluate the similarity between two language pairs. The details of test data are listed in Tab.1.
Tab.1Test data
3.2Similarity investigation
Experiments to investigate the similarities between language pairs were further tested in three levels, including Unicode sentence and word levels by applying the function (2) addressed in section 2 above.
First, converting the sentences to vector sequence using a space between entries was performed, and then the similarity by language pairs was computed. Fig.6(See page 358) shows the results of the similarity in sentence level for MLB and TLB respectively.
Fig.6 shows some interesting phenomena. Firstly, in the case of pairs of TLB, the similarity is very high(close to 0.87), for those in the same family and called different languages. Secondly, in the case of MLB, the similarity between TM and ToDo pair is less than TLB and to 0.72 even MLB is in the same family and same nationality languages. Finally, the similarity between the different groups and used in the same areas, e.g TLB-ToDo in Fig.6, is less than MLB comparing to TLB, and higher than TLB-TM(here TLB and TM are used in Xinjiang and Inner Mongolia respectively).
Next, vocabularies are extracted from text sentences of each language, and then the similarities are computed by word set pairs. Fig.7 show the comparison of the results. We can easily see that the similarity level is higher when a word-level comparison in the same language branch while it is so far in the case of the different language branch.
3.3Extracting the target language words
In this section, we investigate a way to extract the target language words when a set of similar words from the source language for an entry of the target language applying the similarity measure. DP algorithm addressed section 2.2 above is applied to choose the target language word.
Fig.8 shows some examples for test entry “bolj” from MLB. There were four candidates such as tests (t1), (t2),(t3) and (t4) in Fig.8. The best choose was (t2) and (t3) because it gives the minimal overall distance, min(n,m)= 0.111.The results indicate that, an entry “bolj”, which is a verb in the source language NM word set, will be created to a word “bolji” of the target language ToDo when add a postfix “i” to source word suffix in a case of MBL. There are many similar examples of TLB,e.gshown Fig.4, when a function sub-word of target language Kyrgyz“go” will be replaced by a function sub-word “ge” of the source language Uyghur. Thus, it is easy to have a text transformation by word to word unit between the similar languages, such as Altai family languages without MT technique.
4Conclusion
In this paper, we discussed a conversion method among texts for similar languages. Firstly, we investigated the similarity levels of languages in the same group and between deferent groups using cosine similarity measure. Then we investigated a way to find the target language words from the source language based on the DP algorithm.
We confirmed that the transformation is more feasible by word to word units when learning the connection rule of a stem and an affix (function words) between the source and target languages by word level. Thus, this avoids the uphill work of MT for the resource-deficient languages such as minority languages being used in the developing countries. Additionally, the costs can be reduced.
In the future, we will further investigate the connection rule of a stem and an affix (function words) between the source and target languages. Meanwhile, we will work on building the statistic models for them.
References:
[1]CHANG S K, LEE J H, WONG K F. Computer processing of orintal languages [J].WorldScientific, 2006,19(2-3): 133-152.
[2]SCHULTZ T, WEINEL A. Fast bootstrapping of LVCSR systems with multilingual phoneme sets [J].ProcEurospeech, 2014(28): 371-374.
[3]ZHANG L J. Cross-Language information retrieval [J].JournalofComputerScience, 2004,31(7): 16-19.
[4]TIAN S G. A method fro Uyghur sentence similarity computation [J].JournalofComputerEngineeringandApplication, 2009,49(26): 144-146.
[5]DAWA I, NAKAMURA S. A study on cross transformation of Mongolian language [J].JournalNaturalLanguageProcessing, 2008,15(5): 3-21.
[6]YE J. Cosine similarity measures for intuitionistic fuzzy sets and their applications[J].MathmaticalandComputerModeling, 2011,53(1-2): 91-97.
[7]LANDAU G M. Two algorithms for LCS consecutive suffix alignment[C]. Combinatorial Pattern Matching, Istanbul,Turkey, 2004: 173-193.
[8]NICOLAS F, RIVALS E. Longest common subsequence problem for unoriented and cyclic strings[J].TheoreticalComputerScience, 2007,370(1-3): 1-18.
Received date:2014-12-12
Foundation item:Xinjiang Laboratory of Multi-Lingual Information Technology Open Projects Funded(XJDX0905-2013-3); Xinjiang Medical University Education Reform Support Project(YG201301515)
CLC Number:TP 391.1 A
Document code:A
中图分类号:TP 391.1
相似语言文本横向处理的研究
木合亚提·尼亚孜别克1,2,古力沙吾利·塔里甫3,伊·达瓦1,2
(1. 新疆大学 信息科学与工程学院,乌鲁木齐 830046; 2. 新疆多语种信息技术实验室,乌鲁木齐 830046; 3. 新疆医科大学 中医学院,乌鲁木齐 830011)
摘要:针对电子资源短缺少数民族语言自然语言处理问题,提出了借助于大语言大数据,着重语言的相似性交叉处理的方法.该文在本次试验中利用维哈柯语及蒙古语多文种文本7854条平行语料,分词单位和短句子单位考查分析了同语族语言以及不同族语言之间、同语系不同语族语言之间的相似程度.引用动态规划(DP)算法定量地获取了语言之间的相似性.实验结果显示: 在句子阶段,维哈柯语言其相似度为84.3%,蒙族类语言为81.3%;在词阶段,维哈柯语言相似度可达到91.6%,而蒙族类语言相似度可达到87.8%.另外,同语系而不同语族多语言的相似性较低,在词级单位考查其相似程度不超过10%.
关键词:多文种文本横向处理; 相似语言; 相似度; DP算法; 少数民族语言
Article ID: 0427-7104(2016)03-0354-06
Biography: Muheyat Niyazbek(1967—), male, associate Professor; Corresponding author: Kuenssaule Talp(1969—), female, associate Professor, E-mail: KuenssauleTalp@163.com.
