基于改进最近邻算法的农产品B2B平台企业动态联盟合作伙伴选择研究
2016-07-25张登兰州财经大学甘肃兰州730020
张登(兰州财经大学,甘肃 兰州 730020)
基于改进最近邻算法的农产品B2B平台企业动态联盟合作伙伴选择研究
张登
(兰州财经大学,甘肃 兰州 730020)
摘 要:本文针对农产品B2B平台企业动态联盟伙伴选择问题,提出了一种改进的最近邻算法,对原有的最近邻算法加入推荐系统的思想,并对算法的结果和评价矩阵做出改进.实验表明,所提出的改进的最近邻算法是可行的,而且有较高的准确率和运算速度.对企业动态联盟的伙伴选择在理论上有一定的指导意义.
关键词:动态联盟;最近邻算法;推荐思想
1 农产品B2B平台企业动态联盟相关理论
1.1 农产品B2B平台
农业的不断发展,使各类农产品的市场也在不断扩大.规模的扩大,产量的增加以及相对稳定的在一定区域内农产品的需求量使得农产品的销售和管理遇到了前所未有的挑战.传统的以批发为主的销售方式和企业之间各自为政的管理方式已经不在农产品的销售方面占据优势了.随着“互联网+”的快速发展,电子商务已经是未来企业发展的趋势和方向.农业也不例外.所以,建立B2B平台是解决农产品销售和管理问题的主要对策.
我国的农业经济正在朝着一个健康蓬勃的方向发展,还需对农产品电子商务的探索,不断改善适合我国农业的B2B电子商务模式.
1.2 企业动态联盟
企业动态联盟系统是一个协同商务系统.是一个虚拟的平台.建立了资源虚拟化管理模型.虚拟企业是当代提出的一种新型企业联盟方式,采用灵活多变的动态组织结构,一旦发现机遇,将以最快的速度加入到企业联盟的阵营中.
企业联盟系统中盟主对盟员的选择就是因为盟主所拥有的资源和能力是有限的.为了抓住市场机遇,盟主就要利用企业外部资源即其他企业资源来提高扩充自身资源.
利用外部资源就是要联合其他企业,盟主提供核心资源(或核心业务)的服务,把非核心的资源(或非核心的业务)进行外包,外包给盟员企业.选择的盟员企业,被外包的资源(或业务)一定要是其核心资源.从而盟主企业和盟员企业优势互补,强强联合.达到盟主和盟员企业将企业内部资源和外部资源整合.
2 企业动态联盟研究现状
企业动态联盟从根本上解决了市场变化对企业快速响应的难题,但这样一种新的供应链模式亦会衍生出更加复杂的问题.企业动态联盟的合作伙伴选择是管理学研究的重点问题之一,引起国内学者的普遍关注,新的思想,方法不断的涌现.目前,有不少学者对企业动态联盟的合作伙伴选择方法进行了研究.文献[1][2][3][4]分别用层次法对选择伙伴选择所用的指标进行两两比较,确定各个指标相对其他指标所具有的重要程度.从而确定其权重.其中文献[1][2][4]在选择指标的时候分别用到了模糊综合的方法对评价指标进行筛选和分析.从而选出重要的评价指标.文献[5]对不同方法选择出来的指标进行整合,加入排序模型,使其在选择盟员伙伴时只考虑重要的重要的指标快速的选择出来合作伙伴.文献[6]通过引入蚁群算法并加入杂交因子来改进了蚁群算法来解决满足产品交货期和最小化成本为目标的虚拟企业合作伙伴的选择.文献[7]加入可拓学的思想评选出具有竞争力和相容的合作伙伴,先根据可拓学方法构建虚拟企业合作伙伴的物元模型,并用优度评选发对物元模型进行求解,从而得出优度,根据优度评选.
基于以上几点不足,基于最近邻的企业动态联盟伙伴选择盟员推荐的合作伙伴问题上相对有以下几个优点:(1)算法易于实现.(2)不用指标的建立,盟员的选择标准是通过客观数据,而不是量化完的指标.
本文研究基于最近邻思想的虚拟企业动态联盟伙伴选择的方法,伙伴的选择是该研究的核心问题.其中伙伴的选择分为两个步骤.第一步为盟主企业的选择,第二步是盟员企业的选择.从而建立企业动态联盟.
3 基于最近邻的企业动态联盟伙伴选择盟员
3.1 最近邻算法基本原理
邻近算法(K最近邻算法),是分类算法中最常用的一种.其中K-最近邻,所指就是和样本最近的K个邻居.邻近算法的核心思想是:如果该样本在特征空间中的K个最近邻中的大多数属于同一个类别,则该样本也属于这个类别.该算法的基本流程:
数据的准备过程,对数据的预处理.
选用合适的数据结构存储训练数据和测试集.设定一个初始的参数(K).
定义一个大小为K按距离由大到小的队列,队列中元素在训练数据中选取K个用来存储最近邻训练集.
遍历训练集,计算训练集中元素和该元素之间的距离.
将得到距离与队列中最大距离比较,若大于最大距离就舍弃该训练元组,若小于最大距离则保留该元组.
遍历完成,就要计算该训练集中的元素所属类别.进而判断该样本的类别.
继续设定不用的K值进行不同的计算,最后取得误差率最小的K值所谓最终确定的K值.
邻近算法中距离的计算方法有多种.本文选用欧氏距离的计算方法.欧氏距离的方法是用空间中两个向量之间的距离,两个向量之间差异的大小.
3.2 改进的最近邻算法
改进的最近邻算法主要是加入推荐的思想.协同过滤是目前最为流行的一类推荐算法.这类算法的核心思想是认为如果某些企业的行为或则特征类似,那么他们的兴趣也具有一定的相似性,它们利用企业与企业或者项目与项目的协同关系来过滤出企业的兴趣[8].
基于企业的协同过滤推荐算法:企业A和企业B 都喜欢商品1,2,3.认为企业A和企业B相似,则企业A和企业B就有相同的喜好.把企业B喜欢且企业A还未表现出喜爱关系的商品推荐给企业A,企业A喜欢且企业B还未表现出喜爱关系的商品推荐给企业B.结果就是给企业A推荐商品5,给企业B推荐商品4.
以上问题的实质都会被归结为找最近邻问题.基于企业的协同过滤是找企业的最近邻.基于企业的协同过滤找出最近邻的方法目前最常用的就是企业-商品评分矩阵.
目前最最常用的过滤技术就是使用企业对商品的评分数据,这个评分数据作为推荐系统的输入数据.首先,根据历史数据整理出企业-商品评分矩阵.其次,根据企业-商品评分矩阵的关系矩阵中找出当前企业的最近邻.最后,根据找出最近邻的评分向量,根据具体要求推荐评分较高的商品.大量的实验表明,基于企业的推荐很好的利用了人们的从众心理和社会属性,能够产生比较符合企业兴趣的推荐,通过这样的推荐,还可以发现企业的潜在兴趣,扩大了推荐的实在意义.
针对企业动态联盟的伙伴选择.对最近邻算法做出改进.基于企业的协同过滤算法的推荐结果是给企业推荐商品,而农产品B2B平台用推荐算法主要用于推荐盟主和盟员.所以推荐的结果需要改进.再者,基于企业的协同过滤算法计算企业之间的相似度主要依赖企业-商品评分矩阵,企业-商品评分矩阵中的数据是企业对商品的评价,企业之间的相似度不能用企业对商品的评价而是要对企业能力的综合评价.两个拥有同样商品的企业综合能力相当就称企业相似.所以,对最近邻算法的改进主要是:
最近邻算法得出的K个邻居根据企业的需求推荐给企业.
用于计算企业之间相似度的企业-商品评分矩阵中的数据改进为企业的综合评价.
在企业动态联盟盟员的推荐过程中对企业的综合评价用的是历史数据,所有企业存放在数据库中的数据.针对联盟系统,对企业的综合评价所用历史数据为:企业拥有商品信息,库存信息,订单信息,支付信息四类信息.具体数据存放于数据库中.与企业相关信息都要作为企业综合评价的数据.可以全面评价一个企业.建立新的企业评分矩阵.
要用建立的新的企业评分矩阵计算企业之间的相似度,采用欧氏距离法.它是在m维空间中两个点之间的真实距离.在二维和三维空间中的欧氏距离就是两点之间的距离,在m维中则表示两个向量之间的距离.计算公式为:
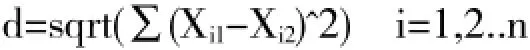
其中,Xi1表示第一个点的第i维坐标,Xi2表示第二个点的第i维坐标.n维欧氏空间是一个点集,它的每个点可以表示为(x(1),x(2),...x(n),其中x(i)(i=1,2...n)是实数,称为x的第i个坐标,两个点x和y=(y(1),y(2)...y(n)之间的距离d(x,y)定义为上面的公式.为了便于计算,我们所用向量中的数值全部用数字来代替(如商品可用商品ID来代替,商品种类可用类别ID来表示).
将欧氏距离公式用在新的企业评分矩阵,通过计算得出企业与其他企业之间的相似度.把计算出的相似度向量按照降序存储,根据订单需求量来决定推荐企业的个数.
联盟平台接到单个企业的资源无法满足商品需求量时,改进的最近邻算法具体步骤:
把订单添加到企业评分矩阵表中,企业和商品数据保留,其他缺失数据全填补为允许的最大值.
用欧氏距离找出与“订单”企业最为相似的企业作为盟主企业.
确定盟主之后,就要根据现在订单的需求量(“订单”企业的需求量-盟主企业的供给量),把新的“订单”企业加入到企业评分矩阵表,企业和商品数据保留,其他缺失数据全填补为允许的最大值.再用欧氏距离找出与新的“订单”企业最为相似的企业作为盟员企业.
重复过程(3),直至最后一个“订单”企业的商品需求量为0.结束推荐,由推荐出的盟主和盟员组成企业联盟共同提供订单需求.
4 实验结果及分析
本文选用2015年阿里巴巴大数据竞赛—天池大赛的部分数据做仿真模型.
取该数据的前三列,即企业,商品,行为.行为表示企业对商品的行为(1表示浏览,2表示关注,3表示加购物车,4表示购买).企业对商品的行为来计算企业之间的相似度,即欧氏距离是二维的.不同企业对相同商品做同样行为,则欧氏距离计算量越小,说明两个向量距离越小,两条记录越相似,企业也就越相似.以这样的方式来计算企业之间的相似度.
为了更好的表现出企业之间的相似度,我们对数据做处理,让企业对同样的商品只做一次行为.用天池大赛的数据形式在MATLAB中做仿真实验.
最近邻中的记录是通过欧氏距离计算的最近邻点,只输出距离当前点最近的点.
实验结果表明,把欧氏距离用在企业评分矩阵来计算企业之间的相似度的方法是可行而且准确率较高的.这样把欧氏距离用在企业动态联盟的企业评分矩阵来计算企业之间的相似度只需要把欧氏距离的维数调高,同样的可以计算出两个企业之间的相似度.本次实验推荐的企业是最为相似的企业,推荐个数只是一个.在实际情况中推荐的企业个数要根据订单的需求量来决定.
5 总结
本文探讨了企业动态联盟系统条件下,改进的最近邻算法用于企业动态联盟伙伴的选择过程.针对企业动态联盟,提出了最近邻算法改进方案.通过实验结果可以看出,本文所提出的改进算法具有算法易于实现,准确率和运算速度高等优点.
参考文献:
〔1〕周军宜.虚拟企业合作伙伴选择的模糊层次分析法[J].安徽工业大学学报(社会科学版),2005 (9).
〔2〕卢纪华,李艳.基于DEA/AHP的虚拟企业合作伙伴选择研究[J].东北大学学报(自然科学版),2008(11).
〔3〕侯艳军,袁文卓.基于模糊层次综合评价法的虚拟企业合作伙伴选择 [J].机械工程与自动化,2009(8).
〔4〕汪忠,吴琳,等.基于模糊综合评价法的社会企业合作伙伴选择[J].财经理论与实践(双月刊),2013(7).
中图分类号:F406
文献标识码:A
文章编号:1673-260X(2016)06-0127-03
收稿日期:2016-01-22
基金项目:甘肃省科技支撑项目(1204GKA010)基于SOA的高原夏菜协同电子商务平台的研究与开发
