一种复杂版面扭曲文档图像快速校正方法
2016-07-19曾凡锋段漾波
曾凡锋 段漾波
(北方工业大学计算机学院 北京 100144)
一种复杂版面扭曲文档图像快速校正方法
曾凡锋段漾波
(北方工业大学计算机学院北京 100144)
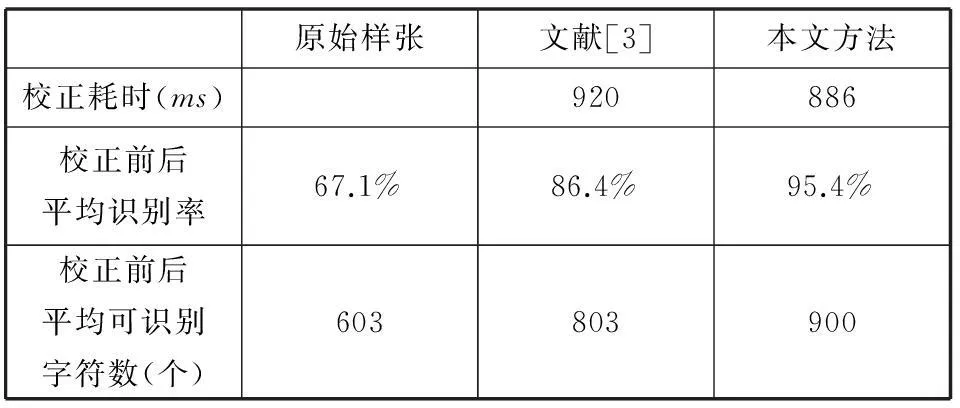
摘要在对复杂版面扭曲文档图像进行OCR识别时,识别率较低。针对这类文档图像提出一种基于形态学文本行定位的扭曲校正方法。首先根据形态学特征在复杂版面中定位文本行,区分处理文字区域和非文字区域,利用文本行信息提取文本线;再以文本线为基准利用窗口扫描法进行文字行校正,最终重构图像。实验结果表明,该方法校正效果明显,对于复杂版面的扭曲文档图像有较好的校正效果,校正后识别率大幅度提高。
关键词复杂版面扭曲文档形态学组件窗口扫描校正
0引言
在图像的采集过程中,由于受到纸质文档自身几何形状和拍摄角度的影响,采集到的图像可能发生扭曲,而文档图像的扭曲将严重影响到OCR识别的效果。当文档图像是图文混排等复杂版面的情况时,将进一步影响到OCR识别。这就需要对复杂版面文档图像进行有效的校正。近年来,国内外对扭曲图像校正技术的研究在日趋增加,但目前大部分的研究主要针对于纯文本的图像,对图文混排类的复杂版面文档图像的扭曲校正研究较少。对纯文本扭曲图像的校正方法主要分为基于3D模型的校正技术和基于2D的图像处理技术,其中基于2D的校正技术有很好的实用性和易推广性。基于2D的校正技术主要包括:1) 基于连通域的处理[1-3],这种方法有很好的校正效果,然而由于处理精度较高,对复杂版面敏感度较高,校正效率有待进一步提高。2) 基于文本线的处理[4,5],这类方法要很高的校正效率,但由于是从整体文本行入手,因此校正精度有细节上的损失,且对复杂版面的文档图像同样不适用。3) 基于模型的校正方法,该方法可以对含有表格等非文字的文档图像进行检测校正,但其校正粒度较为粗糙,效果欠佳。
通过以上分析总结,各种校正方法各有特点,但应用到复杂版面文档图像时都不易获得理想的校正效果,其原因在于复杂版面中的非文字元素影响了各种校正方法中的处理步骤。因此如何在复杂版面上进行有效的校正成为关键所在。本文针对复杂版面的扭曲文档图像提出一种基于组件分析的文本线校正方法,实现了对图像中的文字区域和非文字区域的有效区分,进而精准定位扭曲文本行,最后基于窗口扫描的方法以文本线为基准校正图像。该方法解决了对复杂版面扭曲图像的有效校正,并兼顾效率与校正精度。
1复杂版面扭曲文档图像特征及校正分析
在获取图像的过程中,相机位置及书籍的摆放,都可能使获得的图像发生扭曲,如图1所示。

图1 复杂版面扭曲文档示意图
在纯文本文档图像扭曲的情况下,识别率将会大大降低;而在复杂版面的扭曲的情况下,识别率将进一步降低,甚至无法识别。在这种情况下,文字和非文字混合排入图像中,对扭曲图像的处理难度将进一步增加。文献[6]在提出一种基于连通域的提取文档图像中的复选框组件的方法,但无法对文档图像中的图像元素进行处理。在对文本行进行扭曲校正之前,必须排除非文字区域的影响。为了提高识别精度,最终也需要剔除非文字区域,保留纯文本。这是本文所选用的处理思想。
2基于组件分析的扭曲校正算法
对于复杂版面扭曲文档图像,扭曲校正的重点是文本行的定位。本文就此提出一种基于形态学组件分析的校正方法。算法实现均采用C++编程语言。解决方案流程如图2所示。
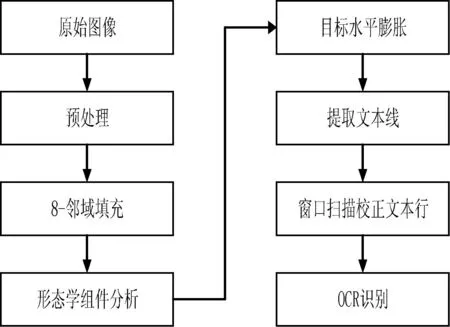
图2 本文解决方案流程图
2.1图像预处理
图像预处理包括两个步骤:灰度化和二值化。灰度化是将具有R,G,B分量的真彩色图像转换为灰度图像。具体转换规则采用以下公式:
I=0.11R+0.59G+0.3B
(1)
灰度化处理后需要将图像转为二值图像,即只包括背景色和前景色的图像。传统的二值化方法较多,如双峰法、大津法(OTSU)、Niblack法等。由于在光照均匀的情况下大津法可以很好地处理本文的研究图像,得到效果较好的二值图像,因此本文在研究中选用大津法进行处理。预处理后的图像如图3所示。

图3 二值化
2.28-邻域填充目标像素
对目标像素进行8-邻域填充是为了更好地进行形态学组件分析[7]。由于文字笔画有的地方较细,有可能出现断笔等情况,在进行形态学分析时可能导致精确度不高。而8-邻域填充可以使文字变得更饱满,充实笔画,提高形态学组件分析的精确度。
目标像素的8-邻域示意如图4所示。

图4 8-邻域像素图
具体填充规则如下:
(1) 对任意一个目标像素点T,扫描其8-邻域的像素值,分别记为E1,E2,E3,E4,E5,E6,E7,E8。
(2) 由式(2)判断其邻域内是否有空白列或行。
α=(E1&&E2&&E3)‖(E3&&E5&&E8)‖(E6&&E7&&E8)
(2)
若α为1,则目标像素为外部点,不予处理;若α为0,则为内部点,对其8-邻域像素进行置黑操作。
(3) 判断若无置黑操作则退出,否则重复(1)、(2)。
8-邻域填充的局部效果如图5所示。

图5 8-邻域填充效果
2.3形态学组件分析
对于图像的版面分析,文献[8]提出了一种基于K-means的聚类分析算法,通过对图像像素进行聚类分析将图像内容分类。但是,这种方法的效率有限,在处理文字图像时体现不出其优越性,因此本文在版面分析算法上主要参考基于形态学组件的分析方法。
形态学组件分析的目的在于区分出图像中的文字行区域和非文字区域。采用以下步骤进行组件分析:
(1) 扫描图像,统计图像中的基本元素。
(2) 根据各元素的形态学特征区分为不同的组件。
(3) 提取文本行组件,并对其进行去噪修正。
由于在复杂版面的文档图像的识别中,关键在于定位文本区域信息。区分文字区域和非文字区域只要考虑各个组件的形态学特征即可[9,10]。因此,在扫描完图像得到图像各个组件后,分别计算其形态学特征,本文主要采用计算各组件的形态学高度和宽度来区分区域。计算规则如下:
用C表示组件元素集合:
C={c1,c2,c3,…,cn}
在编程实现中,首先定义结构体Component,用来保存各个组件的信息。结构体中包含组件的宽度、高度以及编号信息。统计每个组件的形态学宽度和高度,分别用集合H和W表示:
H={h1,h2,h3,…,hn}
W={w1,w2,w3,…,wn}
并由式(3)、式(4)计算组件的平均高度和平均宽度:
(3)
(4)
由经验值可知计算出来的平均高度可以视为文档图像中文本行组件的近似平均高度。所以,在所有组件元素中,其形态学特征明显不同于平均特征的组件被视为非文字行组件。对这些组件进行标注。对于文本行组件则进行编号记录,并存储这些文本行组件的坐标信息。本文采用一种基于组件边界属性的合并方法[9]。具体步骤如下:
第一步由组件分析的结果将文字组件按照以下规则合并文本行组件;
用left,right,top,bottom,width,height分别表示组件的左右上下边界如果max(right1,right2)-min(left1,left2) left=min(left1 ,left2) right=max(right1 ,right2) top=min(top1 ,top2) bottom=max(bottom1 ,bottom2) 组件合并之后的初始状态下, 各文字组件都处于属性未定状态。修正文本行组件的过程就是采用一种渐近的过程, 首先,根据组件的宽度和高度形态学特征,区分为文字和非文字;然后,把属性已经统计为文字的各组件按照它们的间距从小到大的顺序加以逐步合并。在这一合并过程中, 只有属性未定组件将被处理。该过程最终将各个文字组件合并成为文本行。 第二步对文本行组件进行修正,对于不连续的文本行进行不同编号标记。 对上一步中合并出来的文本行进行水平膨胀,这样处理的目的是为了快速统计各个文本行,并对各个文本行进行编号。 第三步记录所有文本行位置信息。 利用上一步中水平膨胀后的文本行可以准确地标记各个文本行在图像中的坐标位置。对所有文本行进行标记,以进行下一步处理。 2.4提取文本线 组件分析完成后,由于对非文本元素进行了标注,因此,可以对文本行组件进行文本线的提取。具体的提取方法为:提取每个文字行组件的中心点,将这些中心点组成文本线,保存这些文本线的坐标信息。 提取文本线的效果如图6所示。 图6 提取文本线 2.5窗口扫描校正 图7 窗口扫描校正流程图 已有的文献的研究方法中,一种校正方法是先对文本线进行拟合,再进行几何变换来重构文本行;另一种方法是先将文字切分,再通过移动单个文字到正确位置来重构文本行。本文提出一种兼顾两种方法优点的重构文本行方法,即以适当大小的窗口为单位扫描文本线,对目标像素进行位置变换,来达到重构文本行。本方法相比于完全的文本线拟合重构方法提高了效率,相比于以文字为单位重构方法又可以更好地保留文本行细节。 利用已经获得的文本行平均高度,以及文本线位置信息,以文本线为基准,以一定大小的窗口对文本行进行扭曲校正。窗口扫描的程序流程如图7所示。 第一步设定扫描窗口大小,对于文档图像来说,其中的文本信息除去标题等少数特殊文本之外,其余文本的特征基本统一。所以,在设定扫描窗口大小时可以以文本行的平均高度为参照。本文选定的窗口大小遵照以下规则: 用window_H表示窗口高度,用window_W表示窗口宽度,其大小分别按式(5)、式(6): (5) (6) 第二步选取每条文本线的中点作为扫描起点,首先记录扫描起点的高度坐标,分别向左向右移动窗口,每移动一次,记录此次窗口内文本线中点的高度,并计算其与扫描起点的高度差,记此高度差为windowGap,然后对于每一条文本线设置一个保存高度差的数组Height_Gapn(n为文本线编号),将每个窗口相应的高度差windowGap记录在这个数组中。扫描过程如图8所示。 图8 窗口扫描 第三步根据高度差数组中的数据文本行进行重构。在经过组件分析后的图像中,文本行已经定位,因此在这一步中,对于每一条文本行,利用扫描文本线所得出的高度差结果,同样从文本行的中点处开始向两边分别移动窗口,在窗口内的目标像素统一移动其相应的窗口高度差windowGap,直至扫描移动完成当前文本行。对每一条文本行执行上述过程,直至全部文本行完成。这时,图像的所有文本行已经完成校正。其校正效果如图9所示。 图9 文本行重构效果 3方法测试及实验结果分析 3.1测试环境 本实验在VS2005开发环境下采用C++语言实现。测试环境为:Inter(R)Core(TM) 2DuoCPUE7400 @2.80GHz;内存2GB;操作系统为Windows7。实验样张取自16开普通中文书本,共对100张样张进行测试。拍摄摄像头像素为500W像素。使用汉王OCR文字识别软件进行文字识别。 图像的获取均在光照均匀的环境下进行,本文校正方法忽略噪声的干扰。图像数据为:24位真彩图像,大小为1944×2592像素。本文算法主要是针对横排的文档图像进行研究的,图像的版面特征主要是文档图像中混入了图像,简单图形(如线条)以及表格线等非文字元素,对这些文档图像均能进行有效的扭曲校正。对于任意复杂的版面,本文方法还不能有效处理,有待改进。 3.2校正效果对比 实验结果如图10所示, 图10为文献[3]方法校正结果,图11为本文方法校正结果。可以看出,对于复杂版面的文档图像,文献[3]的校正效果明显较差,不但没有排除非文字元素的干扰,而且有的文字行已经损失,识别率也会因此大大降低。而本文的算法进行校正的效果明显,且已经剔除非文本元素的干扰,这样可以较高地提升识别率。相比于文献[11,12]中所提出的相应校正算法,较之本文提出的算法都有明显不足。在所有进行测试的样张中,只有3张的校正效果不是很理想,其余的样张在校正后不论是可识别字符数还是识别率都有大幅度提升,其中识别率可达95%以上。对实验结果进行统计分析,其结果如表1所示。 图10 文献[3]校正效果 图11 本文校正效果 原始样张文献[3]本文方法校正耗时(ms)920886校正前后平均识别率67.1%86.4%95.4%校正前后平均可识别字符数(个)603803900 由于本文所提的方法首先需要对文档的版面进行分析以确定文本行,所以相对于已有的基于文本线拟合的方法在时间效率上的提升并不是很明显,但是在校正精确度和校正后识别率以及可识别字符数上都有明显优势。对于这种复杂版面的文档图像大多数已有的校正方法的校正效果很差,甚至无法校正。本文方法相比于基于连通域文字分割的校正方法就有着较为明显的效率优势。其中所测试的样张中平均识别率可以达到95%以上,而可识别字符也比其他方法明显多出。同时本文方法有较强的鲁棒性,对于不同的复杂版面都能有较好的校正效果。 4结语 本文针对复杂版面扭曲文档图像进行研究,提出基于组件 的窗口扫描校正方法。首先通过形态学特征对文档内容进行组件分析,确定文本行;然后提取文本线,最后以文本线为基准,以适当大小窗口扫描校正文本行。该方法能在900毫秒内校正1944×2592像素的图像,而且校正效果良好,其校正后的OCR识别率可以达到95%以上。经过进一步测试,对于复杂版面的英文文档图像也可以准确进行校正。本文方法在本实验室开发的智能阅读机进行了应用,无需人工干涉的情况下已能实现复杂版面扭曲文档图像的快速校正,校正后的实时识别率能达到95%。因此,本文提出的方法可以推广到实时文字图像识别系统中进行应用。 参考文献 [1]LiuHong,YeLu.AmethodrestoreChinesewarpeddocumentimagesbasedonbindingcharactersandbuildingcurvedlines[C]//InternationalConferenceonSystems,ManandCybernetics:ICSMC2009:2009:989-993. [2]LiZhang,YipAndyM,BrownMichaelS,etal.Aunifiedframeworkfordocumentrestorationusinginpaintingandshape-from-shading[J].PatternRecognition,2009,42(11):2961-2978. [3] 宋丽丽,吴亚东,孙波.改进的文档图像扭曲校正方法[J].计算机工程,2011,37(1):204-206. [4] 张伟业,赵群飞.读书机器人的版面分析及文字图像预处理算法[J].微型电脑应用,2011,27(1):58-61. [5]LiuHong,DingRunwei.InternationalConferenceonSystemsManandCybernetics[C]//ICSMC2009:RestoringChinesewarpeddocumentimagesbasedontextboundarylines,2009. [6]ZhangShengnan,YuanShanlei,NiuLianqiang.AutomaticRecognitionMethodforCheckboxinDataFormImage[C]//SixthInternationalConferenceonMeasuringTechnologyandMechatronicsAutomation,2014:159-162. [7] 于明,郭佥,王栋壮.改进的基于连通域的版面分割方法[J].计算机工程与应用,2013,49(17):195-198. [8]HamedBehin,AfshinEbrahimi,SepidehEbrahimi.IncorporatedPreprocessingandPhysicalLayoutAnalysisofaBinaryDocumentImageUsingaTwoStageClassification[C]//InternationalConferenceonComputerandCommunicationEngineering:ICCCE2010:2010. [9] 付芦静,钱军浩,钟云飞.基于汉字联通分量的印刷图像版面分割方法[J/OL].计算机工程与应用,2013,49(3):4[2013-07-31].http://www.cnki.net/kems/detail/11.2127.TP.20130731.1817.001.html. [10] 石蒙蒙.基于结构化局部边缘模式的文档图像分类[J].厦门大学学报,2013,52(3):349-355. [11]AmirRezaGhods,SaeedMozaffari,FarhadAhmadpanahi.DocumentImageDewarpingusingKinectDepthSensor[C]//21stIranianConference,ElectricalEngineering:ICEE2013:2014:1-6. [12]TongLijing,ZhangGuoliang,PengQuanyao,etal.Warpeddocumentimagemosaicingmethodbasedoninflectionpointdetectionandregistration,InternationalConferenceonMultimediaInformationNetworkingandSecurityMINES2012:November2-4,2012[C]//Nanjing,2012:306-310. A FAST CORRECTION METHOD FOR WARPED DOCUMENT IMAGESINCOMPLEXLAYOUT Zeng FanfengDuan Yangbo (College of Computer,North China University of Technology,Beijing 100144,China) AbstractThe recognition rate of OCR (optical character recognition) on warped document images in complex layout is relatively low. To solve this problem, we proposed a morphology-based warp correction method with rows of text positioning. First, according the morphological characteristics it locates the rows of text in complex layout to distinguish the text areas from other areas. After that it uses the rows of text information to extract the text lines, and then uses the text lines as the benchmark, employs the window scanning method to correct the rows of text, and finally reconstructs the image. Experimental results demonstrated that this method achieved manifest correction effect. For warped document images in complex layout it gained acceptable correction results, the recognition rate improved significantly after the correction. KeywordsComplex layoutWarped documentMorphologic componentWindows scanning correction 收稿日期:2015-01-08。国家自然科学基金项目(61371142);北京市自然科学基金项目(4132026)。曾凡锋,副研究员,主研领域:图像处理,智能识别,系统辨识。段漾波,硕士生。 中图分类号TP391 文献标识码A DOI:10.3969/j.issn.1000-386x.2016.06.042