一种基于时间戳的新闻推荐模型
2016-07-19史艳翠戴浩男石和平汪圣洁杨硕珩钟惠军
史艳翠 戴浩男 石和平 汪圣洁 杨硕珩 钟惠军
(天津科技大学计算机科学与信息工程学院 天津 300457)
一种基于时间戳的新闻推荐模型
史艳翠戴浩男石和平汪圣洁杨硕珩钟惠军
(天津科技大学计算机科学与信息工程学院天津 300457)
摘要互联网的高速发展,使用户很难在“信息海洋”中找到感兴趣的新闻,如何为用户准确推荐满足其需求的个性化新闻已成为当前研究的热点和难点。为了改善新闻推荐系统的准确性,将时间戳信息引入到新闻推荐模型中。首先,利用分词工具对新闻标题和新闻内容进行分词,并引进时间加权函数来计算用户对单个分词的偏好;预测用户偏好时不仅根据用户自身的偏好进行预测,还使用改进协同过滤方法来预测用户偏好;最后,通过融合得到的偏好值对新闻进行推荐。实验结果表明,该模型不仅能提高新闻推荐系统的准确性,还缩短了模型构建的响应时间。
关键词时间戳稀疏性分词新闻推荐
0引言
互联网的普及使用户可以更方便地获取信息,但互联网中信息量爆炸式的增长,造成了严重的“信息过载”问题,用户很难从“信息海洋”中找到需求的信息。推荐系统作为一项重要的信息过滤技术,很早就被广大学者视为极具潜力的解决信息过载的有效手段而被广泛研究[1]。推荐系统根据用户以往行为在进行分析后对用户即将发生的行为进行预测。在商务领域,以亚马逊为代表的电子商务网站就是利用推荐系统增加商品销售的典型案例。推荐系统不仅能够为用户提供个性化的服务,而且能够与用户建立长期稳定的关系,提高用户忠诚度,防止用户流失[2]。
目前,个性化推荐系统分为基于内容的推荐系统、基于协同过滤的推荐系统、基于知识的推荐系统以及几种推荐系统的混合模型等[1,3,4]。由于以上几种算法各有所长,因此,很多推荐系统对上述算法进行组合以得到准确的推荐结果[5,6]。
另外,随时间变化,用户偏好会发生变化[7,8]。如果不及时更新用户偏好,使用已过时的用户偏好为其推荐信息或服务,将无法满足其个性化的需求,造成推荐系统性能的下降,客户的流失。针对该问题,研究人员将时间因素引入到推荐系统中以更新用户偏好,改善推荐系统的性能。郑先荣等人[9]为了及时捕捉用户偏好的变化,借鉴心理学中人的遗忘理论,引入了线性遗忘函数对用户评分进行加权计算。而邓娟等人[8]考虑到用户对项目的评分随时间迁移对当前用户偏好的影响会衰减,引进了按指数衰减的时间加权函数。相比于线性遗忘函数,按指数衰减的遗忘函数能更好地拟合用户偏好的衰减,因此印桂生等人[10]和张磊等人[11]分别提出了不同形式的按指数衰减的遗忘函数。在上述研究中,用户评分被看做用户偏好,因此可以直接进行相应计算,但在新闻推荐系统中,收集到的数据只有用户阅读过的新闻,并没有直接给出相应的评分,所以在新闻推荐系统中首先需要挖掘用户偏好。
针对上述问题,本文提出一种基于时间戳信息的新闻推荐模型。首先,使用分词工具对新闻标题以及新闻内容进行分词;然后,计算分词的相对词频,考虑到时间因素的影响,本文参考已有文献,引入了按指数衰减的时间加权函数;根据计算得到的相对词频,提出计算用户偏好的公式;根据计算得到的用户偏好,结合基于用户自身偏好和改进的协同过滤方法实现推荐;最后,使用真实数据验证本文提出模型的有效性。
1提出的模型
本文提出的模型,首先根据新闻的分词计算用户对新闻主题的偏好,然后根据用户自身偏好和改进的协同过滤方法分别预测用户可能的偏好,最后对得到的用户偏好进行融合。在模型中本文引入时间戳信息来改善推荐系统的性能。
1) 计算相对词频
在新闻推荐系统中,不能直接获取用户偏好,因此本文通过新闻分词来挖掘用户偏好。首先使用分词工具对新闻标题和新闻内容进行分词。由于随时间变化,用户偏好会发生迁移,原有偏好对当前用户偏好的影响比较小。因此,借鉴已有研究,采用按指数衰减的时间加权函数来调整分词对用户偏好的影响。时间加权函数[10]如下:
f(ti)=e-β(ti-t0)
(1)
其中,t0表示当前的时间;ti表示用户阅读第i条新闻的时间,β为时间衰减参数。
用户阅读的新闻包括新闻标题和新闻内容两部分,但新闻标题的分词和新闻内容的分词对用户偏好的影响是不同的。新闻标题中的分词影响更大一些。因此,考虑到时间衰减的影响,本文提出了一种计算相对新闻分词词频的方法,其公式如下:
(2)
其中,N1表示第i个分词在用户阅读的新闻标题中出现的次数;N2表示第i个分词在用户阅读的新闻内容中出现的次数;N表示用户阅读的所有新闻标题和新闻内容的分词数量;tk表示第i个分词第k次出现的时间,α表示权重参数。
2) 计算用户偏好
由于用户对新闻的偏好与阅读次数之间不是线性关系,而是随着阅读次数的增加,用户兴趣度增长速度逐步变慢,这符合著名的经济学理论——边际效应递减理论。即其他条件不变的情况下,如果一种投入要素连续地等量增加,那么产生的实际效应的增加速度会逐步下降。因此,本文根据边际效应递减理论使用式(3)来计算用户对新闻分词的偏好:
(3)
其中,a为对数的底数。当a的取值比较大时,得到的用户偏好的范围比较小,当a的取值比较小时,得到的用户偏好的范围比较大,本文中需要将用户偏好映射到[0,1]之间的数值,而fi∈[0,1],所以设定a=2。
在获取了用户对单个分词的偏好后,可以计算出用户对某个新闻标题的偏好,其计算公式如下:
(4)
其中,Nnewi表示新闻标题中包含的分词的数量。
3) 基于用户自身偏好进行推荐
由于用户偏好受自身因素的影响,例如用户的学历、兴趣等。因此可以根据用户的偏好来预测用户可能的偏好。预测步骤如下:
(1) 根据目标用户最后阅读新闻的时间,选择近三天发布的新闻标题。
(2) 根据计算得到的分词的偏好,根据式(4)计算用户对已选择出的新闻标题的偏好。
(3) 对计算得到的新闻标题排序,选择出偏好最高的前5个新闻标题。
但是当给出的新闻标题中不包含用户已阅读过的分词时,根据式(3)预测的新闻标题的偏好会是0。因此,基于用户自身偏好的预测方法,不能发现用户对新的新闻主题的偏好。为了弥补基于用户自己偏好预测方法的缺点,本文还结合使用了改进的协同过滤方法。
4) 基于改进的协同过滤进行推荐
(1) 根据其他用户和目标用户浏览的新闻的共同的分词数量选择近似邻居。由于本数据集中用户阅读的新闻数量比较少,在寻找近似邻居时,不是以新闻标题作为一个项目,而是将单个分词作为一个项目。例如用户A和用户B,他们分别读了关于马航的5条新闻,但相同的新闻标题没有。这并不能说明A和B偏好不相似,因此,在寻找近似邻居时,使用单个的分词作为项目是合理的。
(2) 在计算用户之间的相似度时,为了提高计算的准确性,本文考虑了用户之间共同分词数量对相似度的影响。假设用户A和B分词分别为100和200个,且共同的分词只有一个,计算得到的偏好相等,那么根据传统的相似度计算公式得到的相似度可能比较高,但显然,这是不合理的。因此本文使用改进的皮尔森相关系数来计算用户之间的相似度,其公式如下:
(5)
其中,Sc表示用户ui和uj阅读的新闻标题以及新闻内容的共同分词;pui,sk表示用户ui对分词Sk的偏好;θ用户度量共同分词数量的影响,其计算公式如下:
(6)
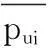
(7)
其中,Sui表示用户ui阅读的新闻标题分词的集合。
(3) 根据计算得到的相似度,选择前K个相似度最高的用户作为目标用户的近似邻居。
(4) 由于新闻的特点,用户一般会阅读最近发生的新闻。因此,为了减少计算复杂度,本文根据目标用户最后阅读新闻的时间,从近似邻居最近阅读的新闻中选择出目标用户没有阅读过,且新闻的发布时间和目标用户最后阅读新闻的时间不超过三天的新闻标题进行预测。
(5) 根据近似邻居的偏好预测目标用户的偏好。
(8)
其中,Un表示用户ui的近似邻居的集合;sk∈Ss,Ss表示选择出的符合要求的新闻标题的集合。
(6) 对于新用户,本文根据其余用户的偏好以及新闻的发布时间,选择出最新的热门新闻推荐给新用户。
(7) 对于新推出的新闻,一方面通过分词,来计算用户对该新闻的偏好,另一方面将该新闻推荐给时尚型用户。根据用户阅读新闻的时间与新闻发表的时间平均差来判断用户是否为时尚型用户,其计算公式如下:
(9)
其中,Nn表示用户ui阅读的新闻标题的数量,即Nn=|Sr|,Sr表示用户阅读的新闻标题的集合;tsk表示新闻sk发表的时间,sk∈Sr;tui,sk表示用户ui阅读新闻sk的时间戳。如果计算得到的平均时间差小于给定的阈值,则判定用户为时尚型用户。
(8) 根据预测得到的偏好,选择偏好最高的前5个进行推荐。
5) 推荐结果融合
由于基于用户自身偏好的推荐和基于协同过滤的推荐各有优缺点,因此,本文结合两种方法进行推荐。将基于用户自身偏好的推荐结果和基于协同过滤的推荐结果进行融合,选择出偏好最高的5个新闻标题推荐给目标用户。
2实验验证和结果分析
1) 数据集
使用爬虫工具从搜狐网站上爬取10 000个用户在1个星期内阅读新闻的行为信息。并对用户、新闻进行编号,另外还抓取了新闻发表的时间,以及用户阅读新闻的时间戳信息。经统计分析该数据集包含7156条新闻,每个用户阅读的新闻量如表1所示。
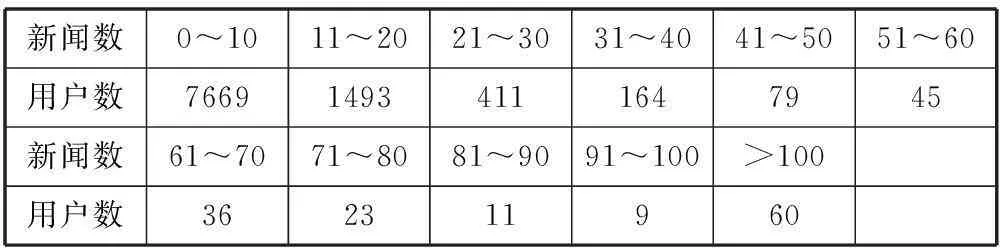
表1 用户看新闻总量的统计
2) 新闻标题及内容分词
本文使用分词工具——NLPIR汉语分词系统对新闻标题和新闻内容进行分词。但该系统不允许一次性对超过四句话的文本进行分词。为提升效率对该软件进行了改良。通过对文件编码进行替换来适配汉语字符特有的宽编码以及应用Windows核心编程API技术完成两个进程间的通信需求。制作出了一个全新的文本读写软件,将网上的分词系统内置其中,可以通过循环控制和进程间通信的手段一次性完成所有的分词工作。
3) 评价标准
本文采用F值作为评价指标,F值不仅考虑了准确率,还考虑了召回率,可以更准确地度量推荐结果。其计算公式如下:
(10)
其中,P表示准确率,R表示召回率,它们的计算公式分别如下:
(11)
其中,Na表示推荐的结果是用户阅读的新闻,Nl表示所有推荐的新闻标题的数量。
(12)
其中,NT表示测试集中所有的新闻标题的数量。
4) 结果分析
(1) 参数α的影响

图1 当参数α取不同值时的推荐结果
从图1可知,当α=1.3时,推荐结果最好。这是因为,当α=1时,即分词没有区分是新闻标题中的分词还是新闻内容中的分词,所以推荐结果的准确性低;1<α<1.3时,新闻标题中的分词所占比重逐渐增大,所以准确性提高;当α>1.3时,由于新闻标题中的分词所占比重过大,所以推荐的准确性开始降低。根据实验结果,在后续试验中,设定α=1.3。
(2) 参数β的影响

图2 当参数β取不同值时的推荐结果
从图2可知,当β=0.7时,得到的推荐结果最好。这是因为,当β取值比较小时,衰减速度比较慢,所以一些过时的偏好对现有偏好影响比较大,导致推荐结果的准确性降低;当β取值比较大时,用户偏好衰减速度过快,使一些偏好对现有偏好的影响降低,同样带来了推荐结果准确性的降低。综上分析,在后续实验中,设定β=0.7。
(3) 不同推荐方法的比较。选择传统的协同过滤算法作为基准对比方法,即method1,本文提出的建模方法为method2,分别进行建模,对比推荐效果。实验结果如图3和图4所示。

图3 当平均时间差阈值为不同值时,不同建模方法的F值对比

图4 当平均时间差阈值为不同值时,不同建模方法的建模时间对比
根据图3和图4可知,当平均时间差阈值为1天时,获得结果最好,这是由新闻的实时性特点决定的。因此一般时尚型用户会在新闻发布的第一时间进行浏览。根据图3可知,与基于传统的协同过滤算法的推荐系统相比,本文提出的模型在F值最好的情况上提高了0.0322;根据图4可知,本文提出的建模方法,在建模时间上比基于传统的协同过滤的推荐系统缩短了23.39分钟。这是因为本文提出的建模方法不仅考虑了时间因素的影响,在使用协同过滤时考虑了用户共同偏好数量的影响,并且在建模过程中做了一些预处理操作。改进方法的预处理因为是一些统计计算,因此其计算复杂度比较小,而传统的方法需要计算目标用户和其他所有用户的相似度,所以计算的复杂度比较大。因此虽然改进方法增加了预处理操作,但总的计算复杂度却减小了。
3结语
为了提高新闻推荐的准确性,本文将时间戳信息引入到新闻推荐模型中。首先,在计算用户对单个分词的偏好时,使用了时间加权函数来度量时间对用户偏好的影响;在为用户推荐新闻时,通过融合基于用户自身的偏好的推荐结果和利用改进的协同过滤算法推荐的结果来实现推荐。实验结果表明,本文提出的模型有效地提高了新闻推荐系统的准确性,并缩短了模型构建的响应时间。
参考文献
[1] 许海玲,吴潇,李晓东,等.互联网推荐系统比较研究[J].软件学报,2009,20(2):350-362.
[2] 刘鲁,任晓丽.推荐系统研究进展及展望[J].信息系统学报,2008(1):82-90.
[3] 刘建国,周涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1-15.
[4] 王国霞,刘贺平.个性化推荐系统综述[J].计算机工程与应用,2012,48(7):70-80.
[5] 乔向杰,张凌云.近十年国外旅游推荐系统的应用研究[J].旅游学刊,2014,29(8):117-127.
[6] 李忠俊,周启海,帅青红.一种基于内容和协同过滤同构化整合的推荐系统模型[J].计算机科学,2009,36(12):142-145.
[7] 柯良文,王靖.基于用户特征迁移的协同过滤推荐[J].计算机工程,2015,41(1):37-43.
[8] 邓娟,陈西曲.基于用户兴趣变化的协同过滤推荐算法[J].武汉工业学院学报,2013,32(4):48-51.
[9] 郑先荣,曹先彬.线性逐步遗忘协同过滤算法的研究[J].计算机工程,2007,33(6):72-73.
[10] 印桂生,崔晓晖,马志强.遗忘曲线的协同过滤推荐模型[J].哈尔滨工程大学学报,2012,33(1):85-90.
[11] 张磊.基于遗忘曲线的协同过滤研究[J].电脑知识与技术,2014(12):67-72.
A NEWS RECOMMENDER MODEL BASED ON TIMESTAMP
Shi YancuiDai HaonanShi HepingWang ShengjieYang ShuohengZhong Huijun
(School of Computer Science and Information Engineering,Tianjin University of Science and Technology,Tianjin 300457,China)
AbstractRapid development of Internet makes it difficult for users to find the interested news from “information ocean”. It has been the hot issue and challenge in current studies that how to accurately recommend the personalised news to users meeting their requirements. In the paper, we introduced the timestamp into news recommendation model in order to improve the accuracy of the news recommender system. First, we employed the word segmentation tool to segment the news titles and news contents into words, and introduced the time weighting function to compute the preference of users on individual word segmentation. When predicting users preference, we were not just based on the preference of users themselves, the improved collaborative filtering method was also applied in prediction. Finally, the news recommendation was achieved by integrating the derived preference values. Experimental results showed that the proposed model could not only improve the accuracy of news recommender system, it also shortened the responding time of model building as well.
KeywordsTimestampScarcityWord segmentationNews recommendation
收稿日期:2015-01-27。国家自然科学基金项目(61402331)。史艳翠,讲师,主研领域:用户偏好获取,推荐系统,上下文感知,社会网络。戴浩男,本科生。石和平,本科生。汪圣洁,本科生。杨硕珩,本科生。钟惠军,本科生。
中图分类号TP3
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.06.010
