聚类技术在医学数据中的应用
2016-07-18王有为
王有为, 吴 迪
(1.郑州大学 软件与应用科技学院,河南 郑州450000; 2.河南教育学院 信息技术系,河南 郑州 450046)
聚类技术在医学数据中的应用
王有为1, 吴迪2
(1.郑州大学 软件与应用科技学院,河南 郑州450000; 2.河南教育学院 信息技术系,河南 郑州 450046)
摘要:利用聚类算法和边界检测算法对脑痴呆数据进行分析,以便找出引起脑痴呆病症发生的原因和相关因素,从而采取有效的措施,更好地预防和治疗疾病.通过对脑痴呆数据的聚类和边界结果分析,得出了一些有益的结论,这些结论可以为医疗机构提供决策依据.
关键词:聚类;边界检测;数据分析
0引言
聚类就是将物理或抽象对象的集合划分成若干簇的过程,使得同一簇中的对象之间具有较高的相似性,而不同簇中的对象高度相异[1].聚类分析已经发展成为数据挖掘中的核心技术[2],广泛地应用在各行各业,例如生物学家根据聚类分析法可以从大量的遗传信息中获取类似功能的基因组[3];在网页搜索中采用聚类功能可以找到某个特定方面的网页信息;在地理气候信息中使用聚类分析能够有效地发现极地和海洋大气压力会被陆地气候影响的模式;在商业信息中聚类分析通过处理当前和潜在顾客的信息,为进一步策划商业营销活动提供便利[4].
聚类边界是近几年新兴的研究热点,对提高聚类的精度和潜在数据模式有重要意义.聚类边界由位于各个簇的边缘数据点集合构成,这部分数据点具有特殊的意义,尤其对医学数据的分析,聚类边界点代表了新的潜在的模式.例如:对于乙肝五项化验结果的数据进行聚类边界检测,会发现处在边界点的数据虽然被划分在乙肝病毒携带者的簇中,但是并未表现出乙肝病症.因此,通过聚类边界模式的分析能够对该疾病进行诊断.
1相关技术
K-means算法是经典的基于划分的聚类算法之一,利用欧式距离作为相似度的划分,即认为两个对象的距离越近,其相似度就越大.主要思想:从给定的n个数据对象的数据集中随机选择k个数据对象作为聚类的初始簇中心,其余数据对象根据相似度(欧式距离)选择距离自己最近的簇中心进行划分;然后重新计算簇中心(该簇中所有对象的均值);不断地重复该过程直到簇中心不再发生变化为止.
基于局部质变因子(BRINK)算法[5]的主要思想: 首先扫描整个数据集,计算出数据集中的每个对象在每一维上的权重,其次根据加权的欧式距离计算出每个对象在数据集中的 K 近邻和每个对象在其邻域内的可达距离,然后根据对象的可达距离计算出每个对象的局部可达密度, 最后根据局部可达密度得出每个对象的局部质变因子,并依据每个对象的质变程度标记聚类的边界.
2数据分析
数据分析先对数据对象聚类,然后求得聚类边界,分析每个类中每个属性的特征边界的属性特性,使用的分析工具是MDAP(medical data analysis platform)平台.
2.1系统平台介绍
MDAP平台是郑州大学以聚类分析和边界点检测技术为基础的医学数据分析平台,能够对含有分类属性、数值属性以及混合属性的数据进行聚类和聚类边界点检测,对数据进行分析处理,且提供友好的可视化界面.
2.2数据集说明
真实数据集“biomed”由漯河医学高等专科学校提供[6].该数据集由261个数据对象构成,每个数据对象包含22个属性〔姓名、性别、年龄、婚姻状况、居住地、文化程度、职业、经济状况、家庭关系是否和谐、有无心血管疾病、有无脑血管疾病、有无内分泌系统疾病、有无免疫系统疾病、有无消化系统疾病、有无其他疾病、有无特殊饮食习惯、牙齿情况、有无保健习惯、改良长谷川、海金斯基缺血指数量表、MMSE(minimum mental state examination)、日常生活能力等〕.
2.3分析方法
本文首先使用MDAP医学数据分析平台对脑痴呆数据集进行预处理,包括属性值转换、缺失值填补、标准化及属性约简,然后对数据集进行聚类和边界检测,从而对数据进行分析.
脑痴呆数据集中包含离散的分类属性和连续的数值属性,需要对这些属性进行转换.分类属性二元化使用的方法:如果一个属性有m个分类值,则将每个原始值唯一地赋予区间[0,m-1]中的一个整数;如果属性是有序的,则赋值必须保持有序关系.
脑痴呆数据集的属性中改良长谷川、海金斯基缺血指数量表、MMSE、日常生活能力的属性值是数值型的可以直接使用,其余属性都是分类属性,要做出预处理,将文字性的描述变换为数值型数据.例如,对有无脑血管疾病属性值处理:“有”转换为1,“无”转换为0;对居住地属性值进行如下处理:考虑到漯河市城区的生活水平要优于农村的情况,将“居住城市”的属性值转换为0,“居住农村”的属性值转换为1;对于年龄属性做如下处理:考虑到发生痴呆病症的大部分病人属于老年人,因此以65岁作为分界点,大于65岁的属性值转换为1,小于65岁的属性值转换为0;对于属性文化程度做如下处理:将属性值为“文盲”的转换为0,否则转换为1;对属性有无保健习惯做如下处理:属性值为“有保健习惯”转换为0,否则转换为1(预处理中转换为0的属性值均是不易造成脑痴呆的因素).
本文在处理缺失值时采用平均值插补方法,对数值型和分类型的属性分别处理.对于缺失值是数值型的,就根据变量在其他所有对象的平均值来填充该缺失的变量值(比如数据集中的改良长谷川、海金斯基缺血指数量表、MMSE、日常生活能力这四个属性利用该变量值在其他对象的平均值代替);对于缺失值是非数值型的(例如居住城市、是否文盲等属性),则根据统计学中的众数原理,利用该变量在其他所有对象的取值次数最多的值来补齐所缺失的变量值.
标准化采用Min-max标准化:Min-max标准化方法是对原始数据进行线性变换,即设minA和maxA分别为属性A的最小值和最大值,然后将A的一个原始值x通过Min-max标准化映射到区间[0,1]中,得到一个新的值x′,其公式为新数据=(原数据-极小值)/(极大值-极小值),利用线性变换把分类属性值映射成区间[0,1]中的值.
属性约简:即删除一些无关的属性降低数据的维度.在这22个属性中,对算法影响不大的属性有:姓名、职业、经济情况、婚姻状况、家庭关系是否和谐、有无特殊饮食习惯、牙齿情况,因此将这些属性作为无关属性去除;而性别、年龄、文化程度、居住地、改良长谷川、海金斯基缺血指数量表、MMSE、日常生活能力、有无心血管疾病、有无脑血管疾病、有无内分泌系统疾病、有无免疫系统疾病、有无消化系统疾病、有无其他疾病、有无保健习惯等15个属性与脑痴呆病症关系密切,因此作为算法处理的属性.
本文首先采用K-means聚类算法对脑痴呆数据集聚类,聚类的结果包含93个病人和 110个正常人.对聚类结果进行统计如表1所示.
病人:普遍特征为居住在农村、男性、文盲、年龄超过65岁、正常生活能力指数低于18、MMSE低于16、海金斯基缺血指数低于8.
正常人:普遍特征为居住在城市、文化程度较高、年龄大都低于65岁、无其他疾病、牙齿良好、正常生活能力指数较高、MMSE 高于16、海金斯基缺血指数大都高于8.
聚类结果表明农村比城市患病率高,男性比女性患病率高,文化程度也是影响患病的关键因素之一;正常生活能力指数、MMSE、海金斯基缺血指数等也是影响患病的重要因素. 有无其他疾病和牙齿好坏对患病没有很大的影响,特殊饮食和保健习惯对患病也没影响.
使用BRINK边界检测算法对上述聚类结果进行边界检测:首先选择对患病影响较大的属性:对居住地为农村、性别为男性、文化程度为文盲者进行实验.

表1 聚类结果统计
当选定居住地和性别这两个分类属性时,其组合属性共有4个,分别为农村-男,农村-女,城市-男,城市-女,每个组合属性的分布情况统计如表2.

表2 居住地-性别属性统计
当用户指定分类属性选择居住地(农村)、性别(男)、文化程度(文盲),则根据算法的边界点检测情况,具有这个组合属性的数据记录中是边界点的个数为29,也就是说可疑痴呆的有29个.
由边界算法得到的最终的结果如表3所示.该算法检测到38个边界点,而真实边界点为34个,该算法将4个其他数据点误检测为边界点.因此,该边界检测算法能够有效地识别出边界点即可疑痴呆人群,从而对预防脑痴呆病提供了很大的帮助.

表3 真实数据集Alzheimer边界检测结果
2.4分析结果
从表4可以看出可疑痴呆病人在属性年龄、文化程度、是否患有心血管疾病、是否患有其他疾病、是否有保健行为、正常生活指数低于18、MMSE和海金斯基缺血指数量表的属性上占有较高的比重,例如:在这38个可疑痴呆病症中,就有37个对象在年龄属性上超过65岁,占边界总人数的97.8%。而这些属性正是诊断脑痴呆病人的重要指标,因此这些人极有可能发展为老年痴呆病人.通过对该算法得到的结果进行分析,能够帮助可能痴呆人群采取有效的预防,从而降低脑痴呆病症的暴发率。
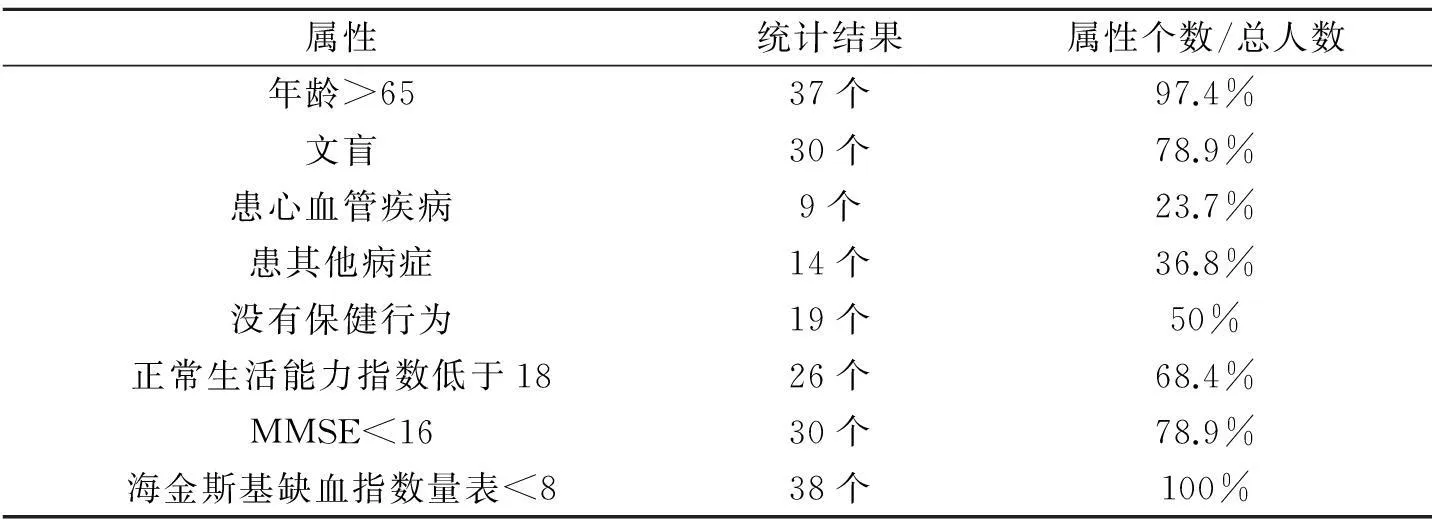
表4 标准数据集Alzheimer的边界检测结果与属性统计
3结论
脑痴呆数据集的边界点为那些有脑痴呆病症但并未患脑痴呆疾病的数据记录,即那些将患有脑痴呆的人群,MDAP对病人的数据记录进行边界点检测分析,判断出那些位于患有脑痴呆和未患脑痴呆之间的疑似痴呆人群,能有效地帮助边界人群即可疑痴呆人群预防老年痴呆症状,分析患病的重要因素,为医药研制和卫生部门提供决策依据.同时我们还可以向有关政府部门反映,改善农村的生活水平,提高生活质量,普及教育,有助于对患有病症的人群进行及早预防和治疗.
参考文献
[1]XIA CHENYI, HSU W, LEE M L. BORDER: Efficient computation of boundary points[C]. IEEE Trans on Knowledge and Data Engineering, 2006, 18(3):289-303.
[2]孔波,王红蔚.基于最小二乘法的无监督支持向量机[J].河南教育学院学报(自然科学版),2014,23(4):17-19.
[3]茹家康,袁琳.基因序列的搜索与相似性比对[J].河南教育学院学报(自然科学版),2016,25(1):25-31.
[4]王有为.基于二路生成树和融合边界的聚类边界检测算法研究[D].郑州:郑州大学,2013.
[5]邱保志,杨洋,杜效伟.BRINK:基于局部质变因子的聚类边界检测算法[J].郑州大学学报(工学版),2012,33(3):117-120.
[6]邱保志,王有为.基于二路生成树的聚类边界检测算法[J].计算机应用与软件,2013,30(10):130-132.
Application of Clustering Technology in Medical Data
WANG Youwei1, WU Di2
(1.Department of Software and Applied Technology, Zhengzhou University, Zhengzhou 450000, China;2.DepartmentofInformationTechnology,HenanInstituteofEducation,Zhengzhou450046,China)
Abstract:Using clustering algorithm and boundary detection algorithm to analyze brain dementia data, to find the factors which are more likely to cause disease, so as to take effective measures for better prevention and treatment of disease. Some useful conclusions can be drawn through analyzing the result of clustering and boundary on the brain dementia data, which can provide decision-making basis for medical institutions.
Key words:clustering; boundary detection; data analysis
收稿日期:2016-01-05
基金项目:河南省基础与前沿研究项目(142300410136)
作者简介:王有为(1987—),女,河南焦作人,郑州大学软件与应用科技学院教师.
doi:10.3969/j.issn.1007-0834.2016.02.008
中图分类号:TP301.6
文献标志码:A
文章编号:1007-0834(2016)02-0032-04
