Web数据挖掘及其在微博话题检测中的应用研究
2016-07-16蒋玉婷
蒋玉婷
(江苏海事职业技术学院 信息工程学院,江苏 南京 211170)
Web数据挖掘及其在微博话题检测中的应用研究
蒋玉婷
(江苏海事职业技术学院 信息工程学院,江苏 南京211170)
摘要:针对微博内容实时性的特点,对话题聚类的Single⁃Pass算法进行了改进,提出将时间参数添加到微博话题相似度检测方法中,并针对微博转发特性的处理方法给出了算法的处理步骤。仿真实验表明,该算法的优点是逻辑简单、算法执行效率高,通过算法的应用有效提高了基于Web数据挖掘的微博话题检测准确度。
关键词:Web;数据挖掘;微博;相似度
0 引言
近年来,微博服务有了爆炸性的增长[1⁃2]。作为一个为用户与朋友提供交流和信息共享的平台,微博开辟了新的交流推荐机会[3]。推特和微博等服务开辟了新的提高热点话题推荐准确性的方法。作为用户与朋友交流和分享信息的流行平台,微博服务每天都产生大量的内容。丰富的内容有助于形成对用户的偏好以及物品特点更好的理解。此外,信息中用户的社会关系和相互交互是通过微博服务体系显示的。所有以上信息可以利用数据挖掘算法来提高挖掘热点话题的准确性[4]。
在热点话题的挖掘中经常使用的方法有两种:其一是基于内容过滤法;其二是协同过滤法[5]。第一种方法在挖掘类似项目时,类似于过去的用户喜欢模式。基于内容的过滤需要项目的知识特点,这并不总是可用的;相反,协同过滤方法不依赖问题的特征项。基于用户的协同过滤方法假定相似用户的偏好往往有相似的项目。通过收集和分析大量的用户行为信息,当用户行为被发觉后,可以使用协同过滤方法去预测相似项目中用户和基于相似用户的期望。这种方法经常遭受来自三个方面的问题,冷启动,数据稀疏和可伸缩性。事实上,结合协同过滤的混合方法和基于内容的过滤已经证明能够在一定程度上缓解上述问题。利用微博挖掘热点话题时,需要注意的是:用户的社会网络和各自的偏好需要形成一个动态平衡。具有相似的兴趣和喜好的人更有可能与对方相互连接和交互;另一方面,个体在许多方面往往是受他/她的社会关系影响,包括利益和偏好。考虑到上述两个属性,有学者提出了一个基于概率矩阵分解的混合推荐模型,一个受欢迎的协同过滤方法。两个正则化被添加到矩阵分解过程中:社会正则化和项目相似性正则化,并借助于新浪微博数据集验证所提出算法在电视节目推荐中的有效性。实验结果表明,该算法明显优于最先进的协同过滤方法,展示了在结合社会信任和推荐相似项目中的重要性。此外,有学者针对向新用户推荐过程中的鲁棒性进行了研究[6⁃7]。
本文采用数据挖掘知识探索了挖掘微博热点话题的可能性。特别地,利用微博的以下两个重要特性:
(1)用户发布的丰富内容,显示用户在热点话题中的偏好;
(2)用户之间的相互影响导致各种社会互动的发生。通过利用用户社交互动以及用户在微博网站发布的内容,探索提高挖掘热点话题的准确性。
1 Web数据挖掘
微博话题检测涉及从微博相关网页中抽取制定的数据并进行数据挖掘,该种挖掘方式是以Web为基础进行的挖掘。使用一些数据挖掘技术对网络文档、网页中的有用信息进行抽取,这一过程就是以Web为基础进行的数据挖掘,因为Web数据挖掘的对象不同,所以可将Web数据挖掘分为如下三类[8⁃10]。
(1)以Web页面为基础进行的内容挖掘
在各类网页内容中将一些具有价值的知识信息提取出来,这是以Web页面为基础进行内容挖掘的重要任务。在应用中,可将网页中的主题内容当作依据,将信息分成不同的类别。分类工作和数据挖掘工作有一些相同点,由于网络的发展,出现了该种需求,因此在网络中也出现了与之对应的应用。所以在各类媒介中都可以添加应用,例如将应用添加到BBS和微博中,进而完成各目标。
(2)以Web结构为基础进行的挖掘
将一些具有价值的信息从Web结构的链接中挖掘出来,这就是以Web结构为基础进行的挖掘。在实际应用中,运用此项技术能够找到某些网页,搜索引擎经常使用这项技术。从该角度考虑,在数据挖掘任务中,以Web结构为基础的数据挖掘和其他数据挖掘具有明显的差异。
(3)以Web使用记录为基础进行的挖掘
将一些有价值的信息从使用者记录或Web服务器日志中挖掘出来就是基于Web使用记录的挖掘。将具有价值的信息从Web使用记录中挖掘出来,决策者根据这些信息能够了解系统的运行状况,从而制定各类决策,通过Web使用记录得到的信息能够让决策更加科学、合理。
2 Web数据挖掘方法
2.1微博数据信息提取及处理
当利用微博等开放平台进行相关数据获取之前,需要首先在平台上注册一个账号。如果有新浪微博账号,可以直接登录平台,还可以注册新的账号,可在http:// open.weibo.com/上注册新的账号,并记住API接口验证序号和密钥,同时将返回地址填写到微博的高级设置中,从而使获取的数据记入开发者的配置文件中[11]。
本文主要利用API接口statuses/public_timeline进行微博数据的获取。返回到最近发布的200条微博是该接口的主要功能,返回到的结果并不一定是实时动态,所以要对API接口进行多次调用,确保获得的数据满足要求。由于调用接口的频率受到网站的限制,为了控制调用频率,可采用线程和队列的方式进行控制。URL是原来存在的接口,其返回格式为JSON,超文本转移协议的请求方式是GET。
汉字话是微博中的一个主要特点,因此要对微博数据进行一系列操作,例如去除停用词等。假如要处理一些英文微博数据,必须先删除一些符号再进行处理,从而还原词干。之所以进行这项工作是因为英文中的词语存在时态变化,处理后可以更加真实的理解微博所表达的意思。
2.2文本模型构建
对微博中的文本可以利用空间向量模型进行文本建模,以便用空间向量去代替原来微博中的文本内容,即将文本Di转换为,转化公式为:

式中:tij是特征项,wij是特征权重,1jM,Di中的特征项的数量是M。
微博中的文本内容并不多,所以在微博中提取的文本内容也较少。因此,向量模型中的特征项都可以由文本预处理后的词汇来表示,当特征项被确定后,就要为特征项设置权重,权重设置越大,说明特征项越重要。因此权重设计的好坏决定了话题检测算法的好坏,是话题检测算法实现的重要步骤。词频⁃反文档频率方法是常用的话题检测算法,以此为基础,考虑微博具有的特点,以语义基础下的特征权重计算方法为依据,能够得到词频⁃反文档频率(TF⁃IDF)函数,它和语义具有相似性。此时还要利用计算方法计算词语的相似度。改造后的结合语义相似度的词频⁃反文档频率函数(TF⁃IDF)为:

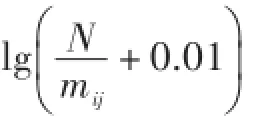
2.3微博系统数据挖掘算法
本节对本文提出的话题聚类算法Single⁃Pass进行介绍,并借助该算法的具体思想将改进后的算法在微博话题检测中进行应用。为适应微博内容实时性的特点,可以将一些时间参数添加到检测微博话题相似度的方法中,并将针对微博转发特性处理的方法添加到算法步骤中,本方法有效地利用了微博的结构化信息,使得检测的准确度得到提升[12]。
单遍聚类算法是基于向量空间模型的话题检测经常采用的算法,它也被称作是Single⁃Pass算法。该算法在对数据进行处理时,是以微博输入的次序为依据。假定初始话题为零,第一个话题的创建就要以首个文本输入来确定,之后对检测到的类似话题和输入的文本数据进行比较,通过比较得出结果。当相似度大于既定阈值时,则合并这个话题和文本,如果相似度小于既定阈值,则进行新话题的创建。逻辑简单、算法执行效率高是该算法的优点[13⁃14]。
本文针对Single⁃Pass算法单一使用余弦相似度、雅各比相似度和语义相似度的不足,采用了组合相似度策略进行微博话题检测。该算法称之为改进的Single⁃Pass微博话题检测算法。
改进的Single⁃Pass微博话题检测算法如图1所示。算法的具体步骤如下:
Step1:微博数据的获取,对数据进行预处理,为文本建模。
Step2:对数据文本进行读取,判断各数据文本,如果这些数据文本属于首个文本向量,则转到Step4,否则转Step3。
Step3:根据数据存储服务器中数据的格式进行微博话题转发关系的确认,若该微博与之前的话题有转发关系,则直接转到Step7,否则转Step5。
Step5:对该文本向量与已有话题关系的判断,并根据关系的相似程度,依次计算当前输入文本与己有话题的相似程度sim(,),根据计算结果,进行相似度的排序,并获得其中相似度值最大的
己检测出的话题的数量通过公式中的T进行表示。
Step6:比较Sa与预先设定的相似度阈值 γ,γ的预设值在0.6~0.9之间,本文中设置的相似度阈值为0.80,在比较之后,如果相似度大于阈值则进入Step7,若比设定的阈值小则转到Step4。
Step7:并入到相似话题。将当前获得的文本放置在相似度高的话题中。
Step8:对文本判断,如果这个文本是最后的文本,说明数据已经全部处理完毕,若该文本不是最后文本,则再次重复Step2到Step7,当输入的数据全部被检测完后,就要存储和话题对应的文本以及检测完的话题。

图1 改进的微博话题检测算法流程图
常用的相似度计算方法有余弦相似度、雅各比相似度、语意相似度等[15]。
借鉴信息融合中的顺序加权思想,语义相似度的定义如下:
设帖子i含有m个关键词,对应的权重为vi1,vi2,…,vim,见式(6):


如引言所述,这3种相似度的思想和角度不同,而且仅单一使用一种相似度都存在一些不足。本文基于以上方法,提出了组合相似度策略,见式(8):

式中:α,β,γ表示加权系数,反映了3种不同相似度对总体相似度的贡献大小。
3 数据仿真实验及结果分析
3.1数据采集
以新浪微博平台为本文的实验平台,从中采集了三亚海天盛筵、私人定制、中日战争、防空识别区、H7N10禽流感、支付宝、理财、银行钱荒、春晚主持人、穿丝袜的狗狗、郭德纲、如何鉴定各种表、传微信将收费、电影·风暴等14个热门话题,微博数据超过了110 000条,每条微博都有对应的发送时间。为了准确地测试算法能否发挥有效性,可以从各类话题中挑选出一些微博,这些微博的文字内容好,格式也较好,之后对这些挑选出来的微博进行算法测试。
3.2确定话题相似度及时间参数
通过话题相似度计算公式可知,在算法测试前,要对时间参数α的值和 β的值以及相似度进行确定。α用来表示内容相似的微博带来的影响,β用来表示时间参数对相似度产生的影响,图2反映了各类影响情况。

图2 话题聚类结果受到α的不同影响
由图2可知,微博内容相似度的地位比较重要,发挥辅助作用的是时间参数。α+β=1是通过相似度计算公式得到的结果,所以想要得到 β的值,一定要先确定α的值。
在本文中,当α参数的取值确定时,α=0.8,对文本向量相似度阈值γ的取值和特征项相似度阈值ε进行讨论,从而得到最小化的耗费函数值,即得到最小的CDet的值。本文中分别取 (ε,γ)的值为(0.85,0.75),(0.95,0.95)和(0.80,0.70),采用参数取值对算法进行试验,通过试验可以证明:当(ε,γ)的取值为(0.80,0.70)时,耗费函数值取得最小值为0.052 4,故选取的参数(ε,γ)为(0.80,0.70)。
3.3实验结果
针对不同的算法,本文通过设计不同的比较实验对Single⁃Pass算法进行改造测试。K⁃means算法是话题检测常常使用的对比算法。针对14个不同的话题分别使用不同的算法进行实验对比。当完成运算后,可以得到运行结果的平均值。图3就是不同算法得到的实验结果对比。
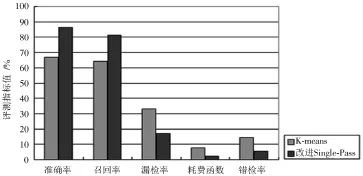
图3 两种算法的实验结果对比
由图3的实验结果数据可知:在本文采用的评测标准指标上,本文改进的Single⁃Pass算法相对于K⁃means算法来说有了较大的提升。就性能而言,在计算后发现性能提升了30%。之所以会出现这种结果,是因为Single⁃Pass算法在改进后对微博的结构化信息进行了调整,该结构化信息主要指考虑了微博转发功能的实际应用,在Sin⁃gle⁃Pass算法中时间参数和基于语义的相似度表示也能有效提升性能。

图4 两种算法的实验结果对比
由图4的实验结果数据可知:在本文采用的评测标准指标上,本文改进的Single⁃Pass算法相对于未改进的Single⁃Pass算法提升较大。从评测指标来看,在所有的5个指标中,本文改进的Single⁃Pass算法均要好于未改进的Single⁃Pass,证明了本文方法的有效性。
4 结论
以文本为对象进行的话题检测算法发展时间较长,本文提出的算法是以话题检测算法思想为基础,将其应用于新浪微博的话题检测中。微博是近几年才出现在互联网中的应用,微博不仅具有平民化特点,它的操作也十分简单,同时它能够反映人们的真实社会生活,因此得到了大众的喜爱和认可。本文提出的数据挖掘平台为微博平台,这种数据挖掘方式能够快速找出焦点话题,减少用户浏览微博的时间,快速定位当前社会讨论的热点话题,同时也有利于广告商等第三方应用进行市场走势的定位。
参考文献
[1]ZHANG L.The development research of China′s weibo[D]. Nanchang,Jiangxi University of Finance and Economics,2012.
[2]FU L,YU L.Review of 2012⁃2013 mobile Internet develop⁃ment trend[J].Journal of Interconnected World,2013,55 (2):1⁃6.
[3]ZHANG T.Weibo dissemination and public domain[D].Shang⁃hai:Shanghai Foreign Language University,2013.
[4]YANG S,LONG B.Like alike⁃joint friendship and interest propagation in social networks[C]//Proceedings of the 20th In⁃ternational Conference on World Wide Web.[S.l.]:IEEE,2011:537⁃546.
[5]陈文涛,张小明,李舟军.构建微博用户兴趣模型的主题模型的分析[J].计算机科学,2013,40(3):127⁃130.
[6]PENNACCHIOTTI M.A machine learning approach to twitter user classification[C]//Proceedings of the Fifth IEEE Interna⁃tional Conference on Weblogs and Social Media.Barcelona:IEEE,2011:121⁃125.
[7]詹勇,杨燕,王红军.混合模型的微博交叉话题发现[J].计算机科学与探索,2013(8):747⁃753.
[8]HU N,BOSE I,GAO Y,et al.Manipulation in digital word⁃of⁃mouth:a reality check for book reviews[J].Decision Support Systems,2011,50(3):22⁃30.
[9]刘茂福,康乐,顾进广.微博关注网构建与统计分析研究[J].计算机应用与软件,2013,30(11):45⁃49.
[10]LEE R,WAKAMIYA S,SUMIYA K.Discovery of unusual regional social activities using geo⁃tagged microblogs[J]. World Wide Web,2011,14(4):321⁃349.
[11]DAVID J,MOSS R,MARK B,et al.A tale of two sites:Twitter vs.Facebook and the personality predictors of social media usage[J].Computers in Human Behavior,2012,28 (2):561⁃569.
[12]YIN S.Weibo user network characteristics of research based on complex network[J].Journal of Southwest Normal Universi⁃ty,2011,33(6):57⁃61.
[13]QIAO Y.Building and empirical weibo users fans evolution model[D].Baoding,Hebei University,2012.
[14]CHENG W,LONG Z.For Internet news topic detection algo⁃rithm[J].Computer Engineering,2009,35(18):28⁃30.
[15]周刚,邹鸿程,熊小兵,等.MB⁃SinglePass:基于组合相似度的微博话题检测[J].计算机科学,2012,39(10):198⁃202.
[16]韩忠明,张玉沙,张慧,等.有效的中文微博短文本倾向性分类算法[J].计算机应用与软件,2012,29(10):89⁃93.
中图分类号:TN911⁃34;TP393
文献标识码:A
文章编号:1004⁃373X(2016)03⁃0115⁃05
doi:10.16652/j.issn.1004⁃373x.2016.03.030
收稿日期:2015⁃09⁃24
作者简介:蒋玉婷(1981—),女,江苏南京人,硕士,讲师。研究方向为计算机应用、计算机软件、数据挖掘、教学管理。
Research on Web data mining and its application in microblog topic detection
JIANG Yuting
(School of Information Engineering,Jiangsu Maritime Institute,Nanjing 211170,China)
Abstract:For the real⁃time characteristic of microblog content,the Single⁃Pass algorithm of topic clustering was improved. The time parameter is added to the method of microblog topic similarity detection,and the processing steps of the algorithm are given according to the processing method of the microblog forwarding characteristic.The simulation results show that the algo⁃rithm has the advantages of simple logic and high execution efficiency,and can effectively improve the accuracy of microblog topic detection based on Web data mining.
Keywords:Web;data mining;microblog;similarity
