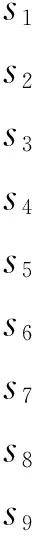基于知识图及VSM的儿童学习者行为特征相似度计算
2016-07-15刘建炜郑健成
刘建炜,郑健成,陈 璟
(福建幼儿师范高等专科学校 人文科学系,福建 福州 350013)
基于知识图及VSM的儿童学习者行为特征相似度计算
刘建炜,郑健成,陈璟
(福建幼儿师范高等专科学校 人文科学系,福建 福州 350013)
摘要:在学习社区中,学习者之间的相似度计算是进行分组的重要技术依据。本文介绍了一种基于知识图及VSM(Vector Space Model)的儿童学习者行为特征相似度计算算法,对网络儿童学习者进行分组。通过实验验证该算法能够较为高效、准确地计算出儿童学习者之间学习行为特征的相似性,并以此为依据进行有效的分组。
关键词:学习者;行为特征;算法;相似度
DOI:10.13757/j.cnki.cn34-1150/n.2016.02.014
研究发现在移动学习平台支持下的海量信息让儿童在学习过程中更易产生“信息过载”和“信息迷航”的现象,并由此引发厌学、焦虑,甚至是自闭情绪[1]。应对此类问题可以通过增加学习者的学习交流、增强学习的趣味性、开放性等方式来避免上述不良问题的产生。当前,如何让“那些具有相似学习偏好及学习水平的学生”[2]能够进行有效交流,共享相似类型的学习资源,是移动学习领域研究的一大热点。国外主要通过研究如何有效构建网络学习社区来解决诸如此类的问题,包括研究学习社区的原理、模式、智能推送、智能分组、帮助学习者构建学习共同体(Community of Learners,简称COL)等,以此增强学习社区、学习软件的粘性。在智能分组划分方面,Sun等采用基于距离的RMHC(Random Mutation Hill Climbing)算法以寻找最优的学生划分分组研究;杨帆等提出了基于交换及激励的学习社区协作学习的分组算法[3]。这些算法具有很强的针对性与指导性,但也还存在着一些问题:在分组的准确性、适应性、有效性上面还有待进一步提升,以及交互不够智慧,算法不能进行自我学习、改进等。
1构造基于兴趣的学习者模型
网络学习社区的分组中最核心的问题是区分具有不同属性的学习者,组合具有共同、相似属性的学习者。学习者模型(Learner Model,简称LM)是一种能够记录学习者的基本信息、知识背景、学习记录等相关信息的数据结构模型[4]。它能够反映学习者的知识掌握水平、认知能力、学习风格、学习过程路径等情况。作为儿童学习社区,通过建立学习者模型就能够很好地掌握学习者的兴趣、喜好、学习掌握情况等基本信息,并以此作为分组划分的主要依据。
1.1知识图的构建
在儿童教育软件中,知识库是经过咨询该领域专家后建立起来的知识点集合,是学习资源组织和管理的核心。知识图是一种属于语义网络范畴的知识库的一种表示方式,它用节点表示概念,用有向弧表示概念与概念之间的关系[5-6]。图1是以科学领域中的部分数学知识为例生成的领域知识图。但在多数情况下,学习软件中的知识库所对应的知识点是以一种树状结构呈现的,表1是领域知识图的参照表。
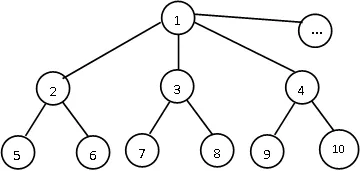
图1 领域知识图
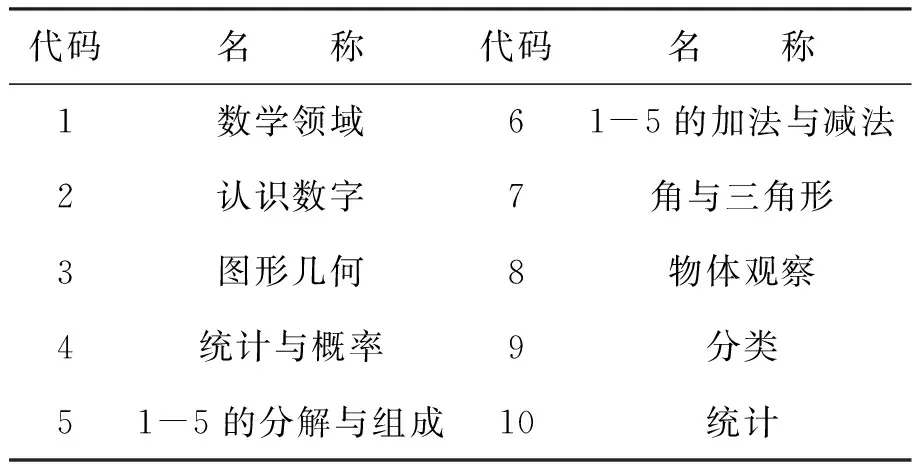
代码名 称代码名 称1数学领域61-5的加法与减法2认识数字7角与三角形3图形几何8物体观察4统计与概率9分类51-5的分解与组成10统计
定义1知识结构定义为K,对于学习者掌握的知识结构可以通过知识树进行表示K= {k1[k2(k5,k6),k3(k7,k8),k4(k9,k10),…],…},用集合的方式来表示:K′={k1,k2,k3,…,km},其中K′为知识点集合,km表示第m个知识点。
1.2学习者模型(LM)表示
对于儿童教育软件中,建立LM主要包含学习者的基本情况、能力、学习目标、学习历程及学习风格等信息。同时在学习过程中学习者发生的行为也可以作为检验学习者对知识了解与掌握程度及对学习内容感兴趣程度等信息的重要推断依据,其主要行为可以归纳为对学习资源的点击浏览、下载相关资源、上传相关资源、对资源及相关内容的评论、进行测试等。
定义2学习者在儿童教育软件中的模型可表示为s={基本信息,能力信息,学习目标,学习历史,学习风格,等},用户集合为S={s1,s2,s3,…,sn},其中n表示为用户对象总数,学习行为可以表示为SAC={浏览,下载,上传,评论,测试等}。
1.3学习者行为特征的量化
对于儿童教育软件中,学习者的基本情况信息可以通过用户注册时填写的相关信息获取;学习风格等有关信息可以通过学习风格测试量表获取;对于学习者的认知能力、习得知识情况、对某些知识的感兴趣程度和学习路径等系列问题只能通过从学习者的学习行为(SAC)获取,并对这些行为进行量化。
定义3对于知识点K,通过T={t1,t2,t3,…,tn}系列题目进行学习者认知能力测试,则对于该知识点K的认知程度可以表示为

其中qR=1表示为答对的分值,qw= -1为答错的分值,0≤Q1≤1。
另外,对于儿童教育软件还有大量的非测试性练习,对于这些题目的评价可以表示为

其中Nph为当前用户的阅读点击计数,Nth为用户总数的阅读点击计数,Tp为当前用户阅读本题的时间总计,Ta为所有用户的阅读时间总计,0≤Q2≤1。
1.4学习者行为特征的表示
根据以上论述,可以把儿童教育软件中学习者的行为特征表示为
定义4K={(k1,Q1),(k2,Q2),…,(km,Qm)},其中km为第m个知识点,Qm表示对km个知识点的认知程度,即可表示为Qm=V(km)。
2学习者相似度计算
2.1概念图相似度计算
用概念图(ConceptualGraph)来表现文本的内容,并进行相似性计算的研究已经非常成熟,而且现有的一些算法也具有较高的计算效率[7-8]。教育软件中的知识点集合,它们之间本身就是一种具有继承与派生关系的图结构,知识树本质上就是一个层级式的知识图[9-10],如图2-3所示。
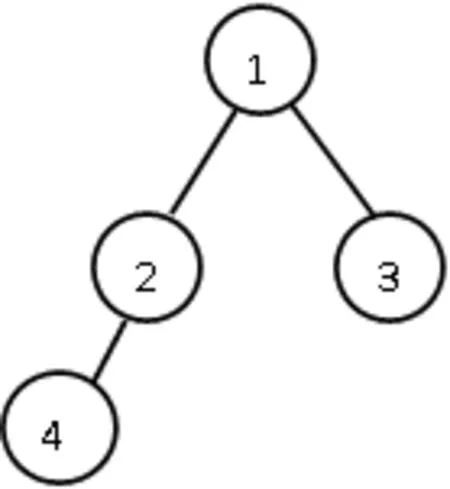
图2 知识G1

图3 知识图G2
为了对比图中G1与G2之间的相似度关系Eq,通常通过考察图的节点与边这两个维度,运用以下公式[11-12]进行比较:
Eqc=2n(Gc)/[n(G1)+n(G2)],
Eqr=2m(Gc)/[mGc(G1)+mGc(G2)],
其中,Eqc表示两个图G1和G2中同节点的相似度,Eqr表示图G1和G2中边的相似度。
Gc=G1∩G2,
n(G1),n(G2),n(Gc)分别表示图G1,G2,Gc中的节点数,m(Gc)表示图Gc中的边数,mGc(G1),mGc(G2)分别表示图G1,G2中至少有一端与图Gc相连的边数。
2.2基于本体的知识概念相似度计算
由图1知,在儿童教育软件中知识一般可以由图的形式呈现,在此基础上,给出下面的定义。
定义5[1]设定概念Kx、Ky分别为图中的某个节点,D(Kx,Ky)为Kx与Ky之间的语义距离,在满足
1)D(Kx,Ky)≥0;
2)D(Kx,Ky)=0,当且仅当Kx≡Ky;
3)D(Kx,Ky)= D(Ky,Kx);
4)D(Kx,Ky)≤D(Kx,Kz)+D(Kz,Ky)的条件下,以此表示概念Kx与Ky的相似度问题。
根据此定义,可知两个概念之间的语义距离D值越小,则表示这两个概念相似度高;反之,如果语义距离D值越大,则相似度越低。
下面给出用于知识概念的相似度计算的Sim公式[13]。
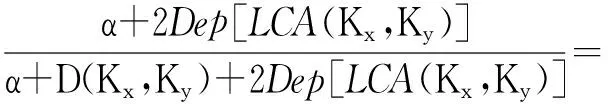
(1)
其中α是一个可调节的因子,Dep(Kx,Ky)为距离根节点最远的Kx、Ky的共同祖先节点;Dep(point)表示节点的深度,即该节点距离根节点的距离。
例如,概念K1是概念K2的父节点,则Dep(K2)=Dep(K1)+1,如K1为根节点,则Dep(K1)=1。
2.3学习者行为特征相似度计算
结合(1)式与文献[11]中相关概念可以得到学习者行为特征相似度计算公式。
定义6设学习者s1的习得知识表示为
Ks1={(k1,Q1),(K2,Q2),…,(km,Qm)},
s2的习得知识表示为
Ks2={(k1,Q1),(K2,Q2),…,(kn,Qn)},
其中Qm、Qn可以表示为Qm=V(Km),Qn=V(Kn)。
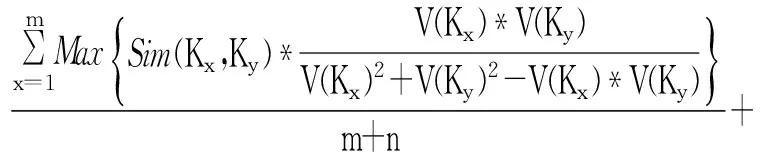
(2)
(2)式通过计算s1的所有概念元素与s2的所有概念元素之间的相似度的平均值作为s1、s2学习行为特征的相似度值。
3学习者行为特征相似度计算算法
在学习者行为特征相似度算法中,最核心的算法之一就是要计算两个概念K1、K2最近的公共祖先所在概念图中的深度值。下面算法通过对欧拉序列遍历查找的方式进行计算,部分代码如下。
①intrmq[2*MAXN];//rmq数组,就是欧拉序列对应的深度序列
②intF[MAXN*2];//欧拉序列,就是dfs遍历的顺序,长度为2*n-1,下标从1开始
③intP[MAXN];//P[i]表示点i在F中第1次出现的位置
④structST{
⑤ ……
⑥intquery(inta,intb) { //查询[a,b]之间最小值的下标
⑦if(a>b)swap(a,b);
⑧intk=mm[b-a+1];
⑨returnrmq[dp[a][k]]〈=rmq[dp[b-(1< ⑩ } ①publicDoublegetCompareValue(Personx,Persony) { ②for(inti=1;i ③for(intj=1;j ④ …… ⑤if(getSimValue()*value>maxValue) ⑥maxValue=getSimValue()*value; ⑦ } ⑧sumValue+=maxValue; ⑨maxValue=0.0; ⑩ } 4实验分析 通过下列实验对本文所描述的儿童教育软件中的学习者进行分析,以期对本算法的有效性进行检验。实验从真实的儿童教育软件中随机抽取部分数据进行相关实验。 4.1实验的样本 从数据库中抽取以下数据作为本次实验的实验数据,其中给定的领域本体图参见图1,学习者数据根据定义1、定义4表示如下 s1={(图形几何,77),(统计与概率,68),(分类,72)}; s2={(认识数字,83),(分类,88)}; s3={(图形几何,85),(分类,78),(角与三角形,80)}; s4={(角与三角形,81),(分类,88)}; s5={(1-5的分解与组成,92),(物体观察,78)}; s6={(统计与概率,65),(统计,69)}; s7={(认识数字,80),(分类,77)}; s8={(1-5的加法与减法,71),(物体观察,88)}; s9={(1-5的分解与组成,80),(分类98)}; 4.2计算概念的相似度 在实际应用中,由于教育软件中所设计的知识概念[14]经过领域专家的审核后在一定时期内可以保持相对的稳定,即所谓统一标准的知识库。如图2即为在儿童教育软件中截取的关于数学领域部分的领域知识图。因此可以在学习者进行学习之前就根据(1)式(其中取α=0.5)计算出领域本体的相似度,表2是部分参照值。 表2 知识概念相关度参照表 4.3学习者相似度计算 根据学习者的学习兴趣、习得成绩,由(2)式计算出M=9个学习者间的相似度,用矩阵表示: 对上述矩阵进行归一化处理,输入参数λ=0.6,相似度值大于阈值的将自动设置成1,而小于阈值的被设置成0,进而得到下列归一化矩阵, 根据匹配浓度法自组织学习小组:s1、s3、s4、s6进入第1分组学习,s2、s7、s9进入第2分组学习,s5、s8进入第3分组学习。 4.4实验结果分析 在获得学习者在教育软件中习得知识结构、兴趣等方面的综合评价后,计算出学习者间的相似程度。根据设定的阈值λ,对学习者的相似度进行归一化处理,求出被置为1值最多的学习者,然后以此为中心进行学习分组。从实验数据表明,阈值越小则分组数越少,而掌握不同知识程度及具有不同兴趣的学习者有可能成为一同分组的学习者。反之,阈值越大则分组数量增多,而组内学习者习得知识结构、兴趣等方面较为接近。 4.5算法计算效率 根据上述计算公式,学习者行为特征相似性的计算主要可以分为3个部分。第1部分是教育软件设计时产生的概念知识树,决定了知识概念之间相似度的计算。第2部分是教育软件运行过程中学习者在学习过程中对学习者行为、结果的评价计算。第3部分是特定时间内针对学习者在第1、2部分产生的数据,进行学习者行为特征的相似度计算。 因为第1、2部分的计算在前期即已完成,第3部分计算时只是实时查询结果,所以此处仅考察第3部分计算的时间复杂度,即主要考察(2)式的时间复杂度。由于需要对知识概念相关度参照表进行查询,如概念树中的知识有m个,即最差的情况是进行m*m次查询,即O(n);n个学习者之间进行比较的时间复杂度为O(n*n),即该算法的总时间复杂度为O(n3)。 5软件实现 学习模块主要记录学习者日常的学习情况,是学习者学习行为记录、学得知识情况的重要评价依据,见图4。分组设置界面模块主要用来根据设定的阈值进行组别划分,阈值的大小决定了小组中学习者之间相似程度,见图5。分组情况模块用来显示学者的分组结果,见图6。 图4学习者记录 图5分组设置界面 图6分组情况界面 6结束语 本文尝试建立一个基于知识图及VSM的儿童学习者行为特征相似度计算模型,以帮助学习者在学习社区中找到拥有相似兴趣、学习习惯的学习伙伴。模型考虑了术语间语义相关性的计算、学习背景等相关因素,并通过实验检验了这种学习社区自组织分组算法的有效性。 参考文献: [1] 王红磊. 基于社会性标签的相似学习伙伴推荐系统设计与开发[D].上海:华东师范大学,2010. [2] 王志梅, 杨帆. 基于相似学习者发现的资源推荐系统[J]. 浙江大学学报(工学版), 2006 (10): 1688-1691. [3] 杨帆,申瑞民,童任, 等.一种新颖的协作自组织学习社区算法[J].上海交通大学学报,2004,38(12):2078-2081. [4] 谢忠新, 王林泉, 葛元. 智能教学系统中认知型学生模型的建立[J]. 计算机工程与应用, 2005(3): 229-232. [5] 张瑞霞, 朱贵良, 杨国增. 基于知识图的汉语词汇语义相似度计算[J]. 中文信息学报, 2009(3): 116-119. [6] 陈杰, 蒋祖华. 领域本体的概念相似度计算[J]. 计算机工程与应用, 2006(33): 163-166. [7] 李鹏, 陶兰, 王弼佐. 一种改进的本体语义相似度计算及其应用[J]. 计算机工程与设计, 2007, 28(1): 227-229. [8] 王婷婷. 泛在学习中学习行为分析与应用[D]. 西安:西安电子科技大学,2014. [9] 程艳, 许维胜, 赵斐, 等.基于本体的VSM在兴趣型学习社区分组中的应用[J].同济大学学报, 2010, 38(5): 736-743. [10] 林木辉, 张杰, 包正委. 智能教学系统中基于本体的知识表示及推送研究[J]. 福建师范大学学报(自然科学版), 2009(1): 120-124. [11] Inaba A,Tarnura T,Ohkubo R,et al.Design and analysis of learners’ interaction based on collaborative learning ontology[C].Proceedings of Euro-CSCL2001,Maastricht, 2001:308-315. [12] 李峰, 李芳. 中文词语语义相似度计算—基于《知网》2002[J]. 中文信息学报, 2007, 21(1): 99-105. [13] Jokim Amy. Network Community Construction—Design Strategy Unmasked[M]. Beijing:Tsinghua University Press, 2001. [14] 詹文法, 孙秀芳, 程啸天. 计算机辅助学习软件现状的调研[J]. 安庆师范学院学报(自然科学版), 2009, 15(3): 97-101. A New Method of Behavior Characteristic Similarity Calculation between Children Learners Based on Knowledge Graphs and VSM LIU Jian-wei,ZHENG Jian-cheng,CHEN Jing (Department of Human Sciences,Fujian Preschool Education College, Fuzhou, Fujian 350013, China) Abstract:In the learning community, the similarity calculation between learners is an important technical basis for grouping. This paper introduces a computational algorithm for the similarity of children learners’ behavior characteristics which is based on knowledge map and Vector Space Model(VSM), by using it we group children learners of the network. The experiment results show that the algorithm can be more efficient and accurate in calculating the similarity of study behavior between children learners, which thus can be as a basis for us to carry out an effective grouping. Key words:learners; behavior characteristics; algorithm; similarity * 收稿日期:2015-07-21 基金项目:福建省教育厅科技A类课题 (JA14400)。 作者简介:刘建炜,男,福建龙岩人,硕士,福建幼儿师范高等专科学校人文科学系讲师,研究方向为教育技术、数据挖掘、网络技术。E-mail: 83998067@qq.com 中图分类号:G40;057 文献标识码:A 文章编号:1007-4260(2016)02-0054-06 网络出版时间:2016-06-08 12:57网络出版地址:http://www.cnki.net/kcms/detail/34.1150.N.20160608.1257.014.html