线指数特征空间内恒星光谱离群数据挖掘与分析
2016-07-12王光沛潘景昌衣振萍
王光沛,潘景昌*,衣振萍,韦 鹏,姜 斌
1. 山东大学(威海)机电与信息工程学院,山东 威海 264209
2. 中国科学院光学天文重点实验室,国家天文台,北京 100012
线指数特征空间内恒星光谱离群数据挖掘与分析
王光沛1,潘景昌1*,衣振萍1,韦 鹏2,姜 斌1
1. 山东大学(威海)机电与信息工程学院,山东 威海 264209
2. 中国科学院光学天文重点实验室,国家天文台,北京 100012
大规模光谱巡天将产生海量的光谱数据,为搜寻一些奇异甚至于未知类型的光谱提供了机会,对这些特殊天体的研究有助于揭示宇宙的演变规律和生命起源,巡天数据的离群数据挖掘有助于这些特殊的光谱的发现。利用线指数对光谱数据进行降维能够在尽可能多的保留光谱物理特征的同时,有效解决高维光谱数据聚类分析中运算复杂度较高的问题。提出了基于线指数特征的海量恒星光谱离群数据挖掘及分析的方法,以恒星光谱的Lick线指数作为光谱数据的特征,利用聚类搜寻离群数据的方法在海量光谱巡天数据搜寻离群数据,以此为基础并给出线指数特征空间内离群光谱数据的分析方法。实验结果证明:(1)以线指数作为光谱的特征值能快速的完成对高维光谱数据的离群数据挖掘,可以解决高维光谱数据运算复杂度高的问题;(2)该方法是在聚类结果上进行的离群数据挖掘,能够有效的挖掘出数量较少的发射线恒星、晚M型恒星、极贫金属星、缺失数据光谱等数据;(3)线指数特征空间的离群数据挖掘可以得到线指数特征空间内特殊恒星的发现规则。本文所提出的基于线指数特征的离群数据挖掘及分析方法可以应用到巡天数据的相关研究中。
Lick线指数;离群数据挖掘;恒星光谱
引 言
随着LAMOST[1-3]开始正式巡天,每天将会观测到上万条光谱数据。巡天数据中包含一些新的、特殊的天体,对这些数据的研究有助于揭示宇宙的演变规律和生命起源。
特殊天体光谱数据与其他光谱数据在行为或者模型上不一致,这些数据被称为巡天数据中的离群数据,巡天数据离群数据挖掘就是对这些数据的挖掘[4]。
本文提出了基于线指数特征的海量恒星光谱离群数据挖掘及分析的方法,以恒星光谱的Lick线指数作为光谱数据的特征,利用聚类搜寻离群数据的方法在海量光谱巡天数据搜寻离群数据,以此为基础并给出线指数特征空间内离群光谱数据的分析方法。
1 背景介绍
1.1 Lick线指数
线指数是光谱数据的物理特征值,一般是一组数据。Lick/IDS线指数(简称Lick线指数)是线指数的一种,定义了25条光学波段的吸收线指数,包括19条原子吸收线指数以及6条分子吸收线指数。Lick线指数是一个相对来说较宽的光谱特征,用Lick线指数作为巡天数据的特征值能够保留光谱数据的更多物理特征。
文献[5-6]中给出了Lick线指数的完整定义及描述。
1.2 离群数据挖掘
离群挖掘[7]根据是否需要专家进行提前标记正常数据或者标记离群数据的模型可以分为三种类型:监督方法、无监督方法以及半监督方法。
离群挖掘的过程是基于数据的不同假设的前提下进行的,根据对数据的不同假设可以把离群数据挖掘的方法分为统计学方法、基于近邻性的方法、基于聚类的方法。本文使用的离群数据挖掘方法是无监督聚类的方法,该方法基于近邻性的算法想法,假设所有的数据都具有相关性,而离群点属于小或者稀疏的簇,或者不属于任何簇。
1.3 聚类算法[8]
聚类算法是用来发现数据分布规律率以及隐藏知识的重要算法,该算法将相似的数据聚集到一起的过程,未聚集在一起的数据相互有较大的差异性。
聚类算法可以分为划分聚类算法、层次聚类算法、基于密度的聚类算法、基于网格的聚类算法、基于模型的聚类算法、基于约束的聚类算法等。
划分聚类算法在进行数据的聚类之前需要给出聚类的数目或者给出每个类的簇心,通过不断的迭代,将各个点聚集到相应数目的簇。
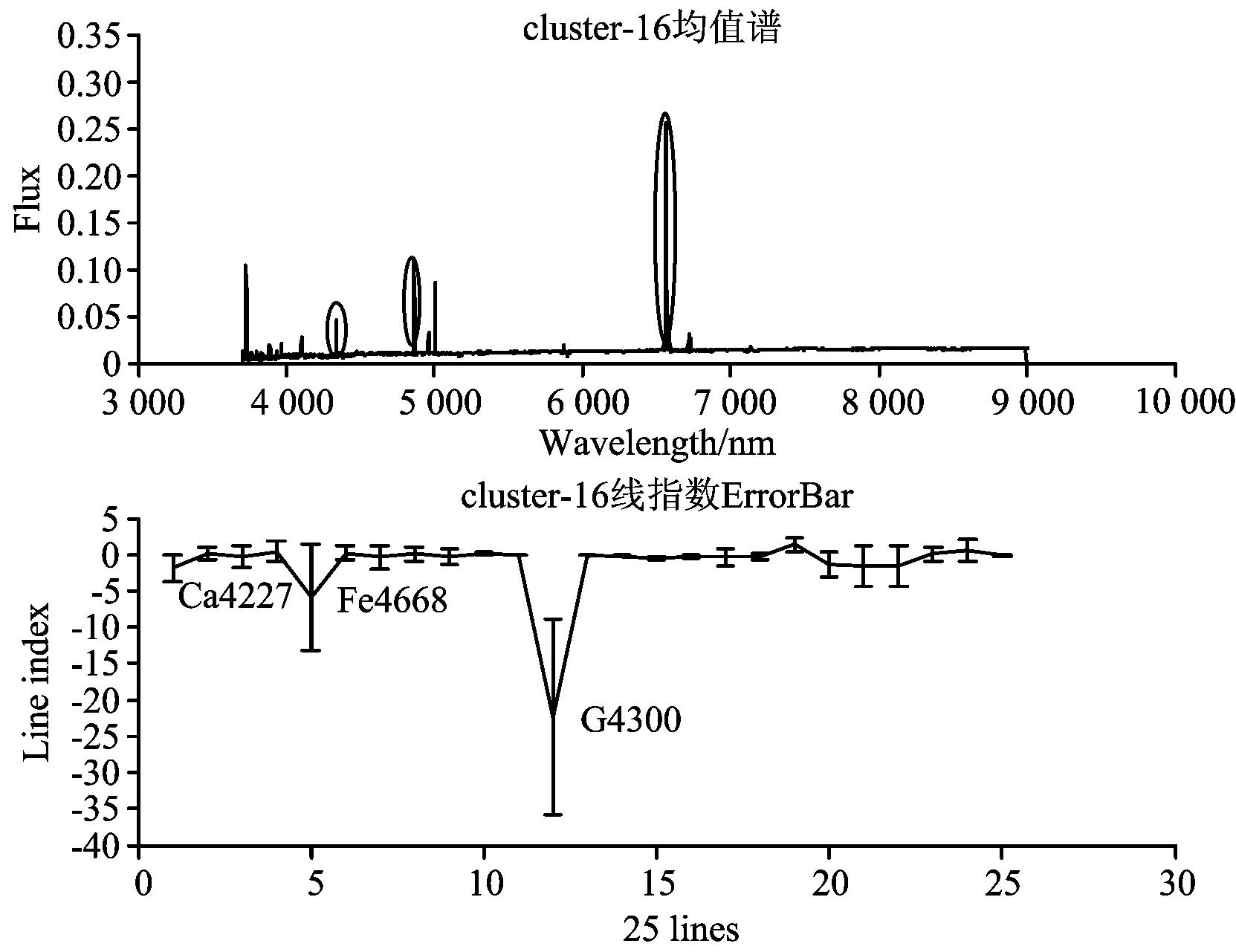
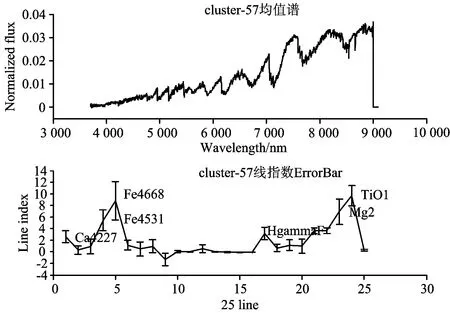
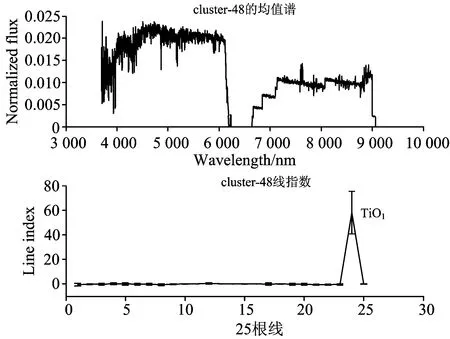
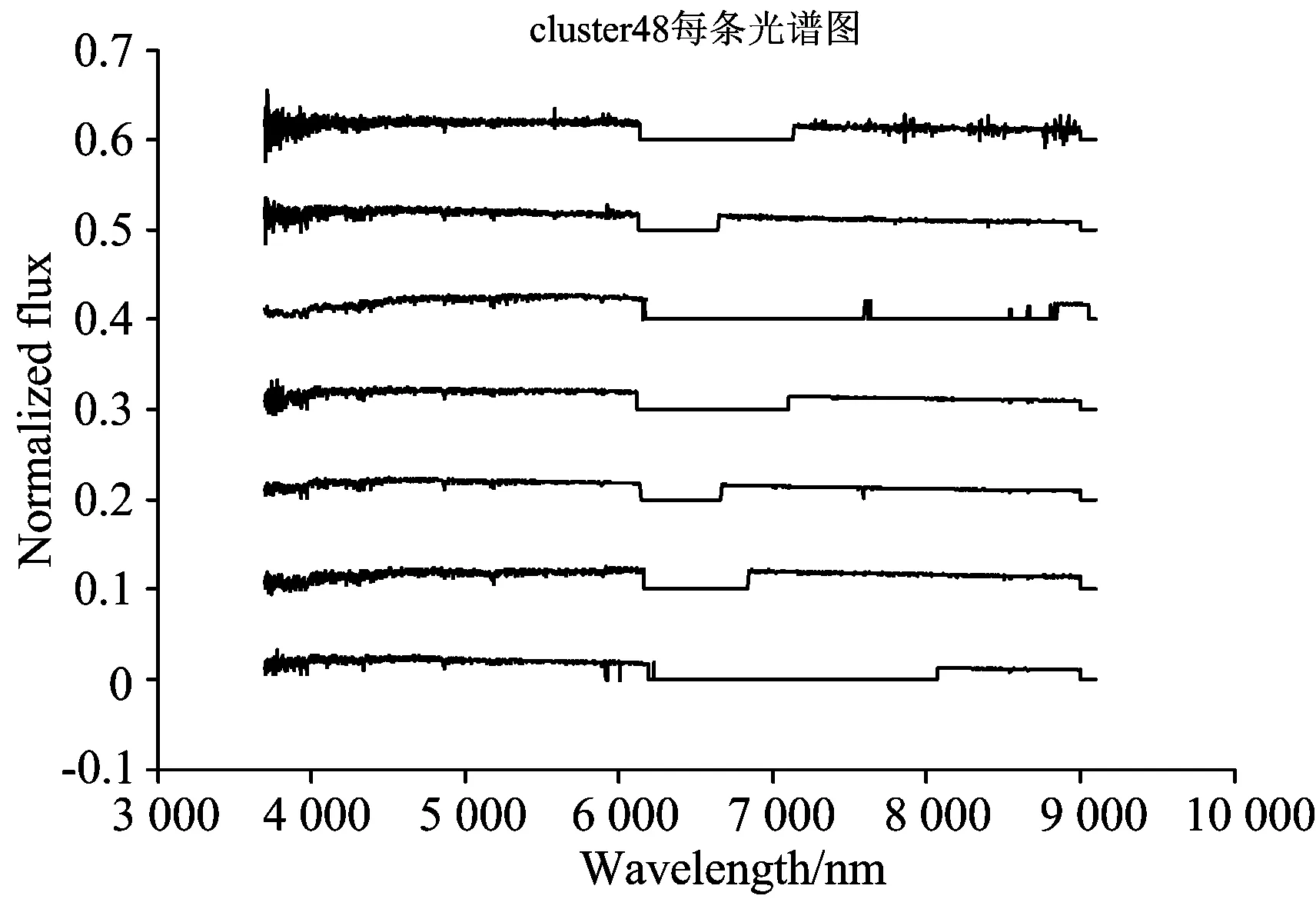
k均值算法是聚类算法中的经典算法,属于划分聚类算法。该算法的思想是把n个对象根据属性特征划分到k个(k 利用Lick线指数对巡天光谱数据进行降维,使用k均值聚类算法完成恒星巡天光谱数据的聚类并对聚类结果进行离群数据挖掘及分析。实验结果证明该方法能够快速准确地挖掘出巡天数据中特殊的恒星光谱数据和错误的数据。 2.1 数据 本文实验从LAMOST DR2数据中选取了10万条g波段和r波段的信噪比大于5的恒星光谱数据。数据集中包含F型、G型、K型以及M型恒星,实验数据中各个子类的样本数量如图1所示。 图1 实验数据分布 2.2 聚类步骤 (1)计算每条fits文件中光谱流量对应的线指数;(2)对实验数据的25个线指数进行标准正态分布归一化的处理,消除不同线指数之间的差异;(3)使用k均值算法,使用欧式距离,将10万条数据聚为k=100个簇。 2.3 离群数据挖掘及分析 筛选100个簇中的样本数量最少的20个簇中的数据,这些簇样本数量都在20以下,以此数据作为离群数据。分析这些簇中数据是否属于特殊数据,并从线指数的角度分析这些数据聚集到一起的原因,进而找到特殊类型数据与线指数的对应关系。 计算所有簇中的每个波长采样点的流量平均值,记为均值谱。均值谱的特征可以代表簇中样本的特征,分析均值谱的特征可以加快对数据的理解和挖掘。为消除不同光谱尺度上的差异,在计算均值谱之前,对所有光谱进行二范数归一化处理。 对聚类结果进行离群数据挖掘过程中查看了所有簇的均值谱,对于均值谱异常的簇,分析簇中数据的特点以及形成原因。 本文方法有效的挖掘出大量特殊及稀少恒星光谱,限于篇幅限制,下面将对几类典型特殊恒星进行分析。 3.1 发射线恒星 明显的吸收线或者分子吸收带是大部分恒星光谱的主要特征。光谱的发射线特征只有一部分恒星存在,这部分恒星一般对应一些非常特殊的目标,如激变变星、Herbig Ae/Be和行星状星云等。 聚类结果中,第16簇的平均光谱中表现出非常明显的发射线特征(如图2所示)。和正常恒星相比,第16簇的均值谱有非常强的表征吸积过程的氢发射线,这些特征都是行星状星云存在的。图3展示了第16簇中所有光谱,簇中数据都有非常明显的发射线特征,特别在氢的发射线附近有非常强的表征吸积过程,证明这个簇中的所有光谱都是比较稀有的行星状星云。 图2 第16簇中平均光谱及线指数分布 图2给出了第16簇中光谱数据线指数的分布情况,该簇中光谱的G4300以及Fe4668这两条线的线指数相比于其他线数值较低,这个特点对于发现行星状星云有很重要的作用。 3.2 晚M型恒星 晚M型的恒星在恒星数据比例很小。查看所有簇的均值谱可以发现第57簇的均值谱(如图3所示)符合晚M型恒星光谱的特点。统计该簇样本光谱型可以发现第57簇聚集了10万条数据中大部分晚M型数据。 文献[9]指出晚M型的恒星在TiO线的线指数高于其他线指数。在图4中可以看到该簇光谱数据的线指数均值在TiO线有较高的峰值,符合已知规律,利用该特征可以加快晚M型恒星的查找工作。 图4 第57簇中平均光谱及线指数分布 3.3 极贫金属星 贫金属星是其大气中金属元素丰度十分低的一类恒星,对该类恒星的研究有助于认识宇宙大爆炸的性质、了解第一代恒星的性质及研究银河系化学演化历史,发现此类恒星对天文研究工作具有重要意义。LAMOST巡天获取了海量银河系恒星光谱数据,但是在DR1的数据中,科研工作者只挑选出了100余颗(极端)贫金属星候选体,该类星体是十分稀少的星体[10]。 极贫金属星在波长5 890 Å附近有一条很明显的吸收线,可以发现极小簇第40簇和极小簇第95簇的均值谱(如图5所示)符合这个特征。 第40簇以及第95簇都是单点簇,即这两个簇中都只含有一个光谱数据,说明聚类过程中,基于Lick线指数特征的聚类方法对极贫金属星的特征十分敏感,能够将这类数据完全分离出来。 这两个簇所包含的两条光谱的Fe5682这条线的线指数数值较低,该特征可以应用到极贫金属星的发现工作中。 图5 第40簇及95簇的平均光谱 3.4 缺失数据光谱数据 由于巡天望远镜的拍摄过程中出现的不稳定情况,以及光谱拼接过程中出现的错误,巡天数据中的某些波段就会出现流量的突然消失或者流量的不稳定,这些数据就是断谱数据[11],在后续研究前需要先将这些数据挑选出来。 第48簇的均值谱(如图7所示)出现了断谱数据的特征,分析该簇的每条光谱,可以发现该簇所有数据均为断谱数据。分析第48簇的线指数特点可以发现,断谱数据造成了簇中数据某些线的线指数出现了异常的过大过小,这是断谱数据线指数的特征,该特征可以应用到断谱光谱的过滤工作中。 图6 第40簇及95簇的平均光谱及线指数分布 图7 第48簇中平均光谱及线指数分布 提出了一种基于线指数特征的离群数据挖掘及分析方法。该方法利用线指数对巡天恒星光谱数据进行降维,使用k均值算法对数据进行聚类分析,然后以聚类分析结果为基础进行离群数据挖掘。该方法能够快速有效的挖掘特殊及稀有恒星光谱以及缺失数据光谱,利用给出的离群分析方法可以在在辅助离群数据分析同时发现线指数特征空间内特殊恒星的发现的规则。实验证明,该挖掘和分析方法可以有效地应用于诸如LAMOST和SDSS等光谱巡天数据的离群数据挖掘及分析中。 [1] Cui X, Zhao Y, Chu Y, et al. Research in Astron. Astrophys., 2012, 12(9): 1197. [2] Luo A, et al. Astrophys., 2012, 12(9): 1243. [3] Zhao G, et al. Research in Astron. Astrophys., 2012, 12(7): 723. [4] Wei P, Luo A, Li Y, et al. Monthly Notices of the Royal Astronomical Society, 2013, 431(2): 1800. [5] Guy Worthey, Faber S M, et al. The Astrophysical Journal Supplement Series, 1994, 94: 687. [6] Trager S C, Guy Worthey, et al. Astrophysical Journal Supplement Series, 1998, 116(1): 1. [7] Koteeswaran S, Visu P, Janet J. American Journal of Applied Sciences, 2012, 9(2). [8] YAN Tai-sheng, ZHANG Yan-xia, ZHAO Yong-heng, et al(严太生, 张彦霞, 赵永恒, 等). Progress in Astronomy(天文学进展), 2010, 28(2): 112. [9] Woolf V M, West A A. Monthly Notices of the Royal Astronomical Society, 2012, 422(2): 1489. [10] Li H N, Zhao G, Christlieb N, et al. Astrophysical Journal, 2015, 798(2). [11] Comerford L A, Kougioumtzoglou I A, Beer M, et al. An Artificial Neural Network Based Approach for Power Spectrum Estimation and Simulation of Stochastic Processes Subject to Missing Data[C]// Computational Intelligence for Engineering Solutions (CIES), 2013 IEEE Symposium on. IEEE, 2013. 118. (Received Jul. 22, 2015; accepted Nov. 28, 2015) *Corresponding author Outlier Data Mining and Analysis of LAMOST Stellar Spectra in Line Index Feature Space WANG Guang-pei1, PAN Jing-chang1*, YI Zhen-ping1, WEI Peng2, JIANG Bin1 1. School of Mechanical, Electrical & Information Engineering, Shandong University, Weihai, Weihai 264209, China 2. Key Laboratory of Optical Astronomy, National Astronomical Observatories, Chinese Academy of Sciences, Beijing 100012, China Large scale spectrum survey will produce mass spectral data and offer chances for searching rare and unknown types of spectra, which is contribute to revealing the evolution law of the universe and the origin of life. Data mining in outlier data in sky survey can serve the purpose of finding special spectra. Line index can be used in spectra data dimension reduction, keeping the spectral physical characteristics as much as possible, and at the same time, it can effectively solve the high dimensional spectral data clustering analysis in the high computation complexity. This paper proposed a method outlier data mining and analysis for massive stellar spectrum survey data based on line index characteristics, according to this, an outlier spectral data analysis method was proposed using line index characteristics space. Experimental results demonstrated that (1) using line index as the characteristic value of the spectrum can quickly perform the outlier data mining for high dimensional spectral data, and it can solve the problem of high computation complexity of the high dimensional spectral data. (2) this outlier data mining method was conducted based on the clustering results; it can effectively finding out emission stars, late type stars, late M type stars, extremely poor metal stars, and even finding spectra data missing certain data. (3) outlier data mining in line index feature space can help to analysis of rules of special stars found in the feature space. The mothed proposed in this paper based on the characteristics of line index outlier data mining and analysis method can be applied to the study of survey data. Lick line index, Outlier datamining, Stellar spectra 2015-07-22, 2015-11-28 国家自然科学基金项目(U1431102,11473019)资助 王光沛, 1990年生,山东大学(威海)硕士研究生 e-mail: wangguangpei@live.com *通讯联系人 e-mail: pjc@sdu.edu.cn P145.4 A 10.3964/j.issn.1000-0593(2016)10-3364-052 实验部分

3 结果与讨论


4 结 论
猜你喜欢
杂志排行

光谱学与光谱分析的其它文章
- Gd靶激光等离子体光源离带辐射及其等离子体演化的研究
- Probing the Binding of Torasemide to Pepsin and Trypsin by Spectroscopic and Molecular Docking Methods
- Mn(Ⅱ)-5-Br-PADAP共沉淀-火焰原子吸收光谱法测定虾、贝样中的镉
- Near Infrared Spectroscopy Study on Nitrogen in Shortcut Nitrification and Denitrification Using Principal Component Analysis Combined with BP Neural Networks
- 内蒙古草原植被最大光能利用率取值优化研究
- 健康和糖尿病大鼠红细胞荧光光谱非线性程度差异