一种添加历史数据的近红外光谱特征提取方法研究
2016-07-12李浩光李卫军张丽萍董肖莉于云华
李浩光,李卫军,覃 鸿,张丽萍,董肖莉,于云华
1. 中国科学院半导体研究所高速电路与神经网络实验室,北京 100083
2. 中国石油大学(华东)信息与控制工程学院,山东 东营 257061
一种添加历史数据的近红外光谱特征提取方法研究
李浩光1,2,李卫军1*,覃 鸿1,张丽萍1,董肖莉1,于云华2
1. 中国科学院半导体研究所高速电路与神经网络实验室,北京 100083
2. 中国石油大学(华东)信息与控制工程学院,山东 东营 257061
针对近红外光谱定性分析中,增加新的品种进行建模时,原有模型识别效果不够稳定的问题,提出一种在建模样本的基础上添加同类物质的历史光谱数据的特征提取方法,首先采集建模样本的近红外光谱数据,然后添加同种物质样本的历史近红外光谱数据,再对所有近红外光谱数据进行预处理,其次对所有样本数据进行偏最小二乘(PLS)特征提取得到偏最小二乘空间,并只将建模样本数据向构建的偏最小二乘空间进行投影,最后将投影后的建模数据进行正交线性判别分析(OLDA)特征提取。以玉米种子近红外光谱为研究对象,分别对建模数据添加历史近红外光谱以及不添加历史近红外光谱两种情况进行特征提取,并通过仿生模式识别(BPR)方法构建模型进行验证,实验结果表明,添加历史近红外光谱构建偏最小二乘空间的特征提取方法相对于不添加历史近红外光谱的方法,首先在增加建模集品种数量时,原有的品种识别率基本不变;其次在相同PLS维数时,所建模型对不同时间采集的测试集识别效果基本一致,证明了该方法可以提高模型稳健性。在实际应用中就可以在品种鉴别软件中将特征提取维数设置为固定值,免除了品种鉴别软件的用户在增加建模集品种时为了保证最优识别效果重新选定最优PLS参数的麻烦。
近红外光谱;投影;定性分析;偏最小二乘
引 言
近红外光谱(near infrared spectrum,NIR)是介于可见光(Vis)与中红外(Mir)之间的电磁辐射波,美国材料检测协会(ASTM)将780~2 526 nm的区域定义为近红外光谱谱区,是人们在吸收光谱中发现的第一个非可见光区。因为近红外光谱区与有机分子中含氢基团(O—H,N—H,C—H)振动的合频和各级倍频的吸收区一致,通过扫描样品的近红外光谱,可以获取被测样品中有机分子含氢基团的特征信息,利用近红外光谱技术分析样品具有方便、快速、高效、准确和成本较低,不破坏样品,不消耗化学试剂,不污染环境等优点,因此该技术受到越来越多人的青睐[1-3]。
用仪器测得的近红外光谱实际上是样品的表观光谱,表观光谱包含确定信息及不确定信息,确定信息是样品的真实光谱特征,而不确定信息是样品光谱上叠加的各种背景信息。表观光谱不仅承载了样品的化学和物理信息,还包含了测量光谱的仪器参数、样品松紧度、温度、湿度等多方面的背景信息,这些不确定因素会造成模型的不稳定[4-5]。
在以往的近红外光谱定性分析中,通常只用某一台仪器在一段时间内所采集的近红外光谱数据建模,这种方法存在以下两个问题:(1)测试不同日期的样本时,最优识别效果所对应的特征提取环节的PLS维数或PCA维数会发生变化,即同一个模型识别不同时间采集的测试样本时,最优识别率所对应的特征提取维数不固定;(2)需要给新品种建模时,原有品种的最优识别率及最优识别率所对应的维数都会发生变化。而在实际应用中,使用近红外光谱仪进行品种鉴别或真伪鉴别时,随着时间的推移,往往需要对许多新品种进行建模,由于这种情况导致原有品种的识别效果发生变化,不利于模型的实际应用和推广。
为了解决上述问题,基于近红外光谱定性分析中的“包容”的思想[1-2],充分利用历史实验中采集的光谱,提高模型的稳健性,提出了一种在建模品种基础上添加同类物质的历史光谱数据的特征提取方法,以若干玉米种子为研究对象,对建模数据添加近红外光谱以及不添加近红外光谱两种情况进行特征提取,并通过仿生模式识别(BPR)方法[6]进行定性分析,通过实验结果说明提出的方法可以提高近红外定性分析模型的稳健性。
1 添加历史近红外光谱特征提取的原理
添加历史近红外光谱构建PLS空间方法的原理如图1所示,首先采集建模样本的近红外光谱数据,然后添加同种物质样本的历史近红外光谱数据,对前两步中的建模样本数据及历史样本数据进行预处理,其次对所有样本数据进行偏最小二乘特征提取,并得到偏最小二乘空间,将建模样本数据向构建的偏最小二乘空间[7-8]进行投影,最后将投影后的建模数据进行正交线性判别分析[9-10](OLDA)特征提取。
1.1 光谱数据预处理
由于近红外光谱中的不确定背景信息的干扰且谱带重叠,需要对近红外光谱进行预处理,采用的预处理方法包括数据归一化处理、导数法处理、平滑处理或中心化及标准化处理。不确定的背景信息是指受近红外光谱仪仪器状态、测定条件与环境影响的信息。所采用的预处理方法为:平滑、一阶导和归一化[3]。

图1 添加历史近红外光谱的特征提取方法原理
1.2 偏最小二乘(PLS)特征提取
对所有样本数据进行偏最小二乘特征提取,得到偏最小二乘特征矩阵,以利用该矩阵将数据变换到偏最小二乘空间。建模样本数据,是指经过预处理之后的建模样本数据,而所有样本数据包括建模样本数据和历史光谱数据,具体步骤如下:
对样本数据进行标准化处理,即令样本的各个变量的均值为0,方差为1;令总样本矩阵为X0,类别信息矩阵为Y0,X01为建模样本矩阵, 为同种物质的历史样本矩阵;其中,X0定义为n条光谱p个数据点的原始光谱矩阵,Y0为对应的类别属性矩阵
其中
Y0中,yij=1表示第i条光谱属于第j类,yij表示第i条光谱不属于第j类。

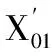
1.3 对建模样本数据进行正交线性判别分析(OLDA)特征提取
正交线性判别分析(OLDA)特征提取方法,与传统的线性判别[11]分析相比,能够解决后者在实际应用中遇到的小样本问题。
对经过偏最小二乘特征提取之后的建模集数据进行正交线性鉴别分析特征提取,得到正交线性鉴别分析特征矩阵;与线性鉴别分析相比,正交线性鉴别分析在求解变换矩阵的过程中,特征向量之间是两两正交的,即满足WTW=I。正交线性鉴别分析特征提取后得到正交线性鉴别分析特征矩阵,具体包括:
假设有C类样本,总样本数为N,Ni为第i类样本数,则定义类内散布矩阵SW、类间散布矩阵SB如下
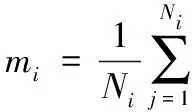
将正交线性鉴别分析的优化问题转换为求解下式的优化问题
其中,wi=(i=1,2,…)对应为下式特征值降序排列前n个值对应的特征向量,且要满足WTW=I
SBw=λSWw
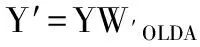
2 实验部分
2.1 仪器与样品
实验仪器采用杭州聚光科技公司(FPI)的SupNIR-2700系列的近红外光谱仪,仪器参数如下:适用的样品状态为颗粒或粉末状等固体,光源为卤钨灯,波长范围为1 000~1 800 nm,有效光程为0.2~5 mm,波长准确性为0.2 nm,测定形式是非接触漫反射。
所用的建模集玉米品种有农华032、农大108、京玉16、洛单248、屯玉2106、玉朱2107、玉朱2110、屯玉2109共八个品种足够多的籽粒,分为有包衣和无包衣的两种籽粒,玉米包衣是指在玉米种子外面通过人工方式包裹的一层含水药剂和促进生长物质的种衣剂。本实验无包衣玉米作为建模对象,而将有包衣玉米作为测试对象,可以检验模型在有干扰情况下的识别效果,同时也是种子企业的实际需求。
交替采集8个品种的近红外光谱数据,按照农华032一杯—农大108一杯—京玉16一杯—洛单248一杯—屯玉2106—玉朱2107—玉朱2110—屯玉2109…的方式采集光谱,中间无校验。
按这种方式为每一品种的有包衣和无包衣的种子各自采集30条光谱,八个品种一共采集到8×2×30=480条光谱。
采集时间为2014年9月15日、9月16日、10月21日共3天,每天采集480条光谱,最终得到1 440条光谱。
用2014年9月15日上午采集的农华032、农大108、京玉16、洛单248,每个品种的30条无包衣光谱数据作为初始建模集,在此初始建模集中按顺序增加屯玉2106、玉朱2107、玉朱2110、屯玉2109等四个品种,每次增加一种,对应的建模集中玉米品种数量分别是4,5,6,7,8共五种情况,构成建模集BM1,BM2,BM3,BM4和BM5,各建模集包含玉米品种如表1所示。
分别用9月15日、9月16日、10月21日上午每个品种的30条有包衣的光谱数据作为测试集,即每个测试集计120条光谱。三个测试集分别记作T1,T2,T3。
而同种物质历史近红外光谱是指一些在过去的实验中采集的近红外光谱,这些历史光谱与建模的光谱,使用的近红外光谱仪需为同一型号,可以是同一型号的不同机器,但是周围环境可以不同。
历史实验采集的玉米近红外光谱数据相隔时间为一年左右,具体有:屯玉绿源2012、屯玉绿源2014、屯玉绿源2015、屯玉24、农大106、农华海南101、农华海南2010、浚单20、甘肃临泽2009、浚单武威3010,共计10个品种,每个品种光谱30条,30条分为三天,每天各10条,分别采于2013年6月27日、2013年7月9日、2013年7月17日,这10个品种共计300条光谱记作历史数据集H。

表1 建模集详细信息表
2.2 方法
为验证添加同种物质样本的历史近红外光谱数据特征提取方法的有效性,以及对不同时间采集的有包衣玉米籽粒的鉴别效果,设计了两个实验,分别如下:(1)实验一:各建模集不添加同种物质样本的历史数据集H,依次将建模集BM1,BM2,BM3,BM4和BM5预处理后,进行偏最小二乘特征提取,然后向其自身构建偏最小二乘特征空间投影,对投影后的建模样本数据进行正交线性判别分析特征提取,并通过仿生模式识别方法进行定性分析。
(2)实验二:各建模集添加同种物质样本的历史数据集H,依次用建模集BM1,BM2,BM3,BM4和BM5共计240条光谱;添加屯玉2106、玉朱2107等10个品种的同种物质历史近红外光谱数据H,预处理后一起进行偏最小二乘特征提取,构建偏最小二乘空间,然后将各建模集向建模集与历史数据集H联合构建的偏最小二乘特征空间投影,最后对投影后的建模样本数据进行正交线性判别分析特征提取,并通过仿生模式识别方法进行定性分析。
仿生模式识别(biomimetic pattern recognition,BPR)是由中国科学院半导体研究所王守觉院士通过分析人类认识事物的特点所提出的一种全新思想的模式识别方法 。与传统模式识别不同,仿生模式识别把模式识别问题看成是一类一类样本的“认识”,而不是多类样本的划分。仿生模式识别以“同源连续性”为基点,认为两个同类样本之间至少存在一个渐变过程,在渐变过程中间的各样本都是同属于该类的,或者说特征空间中同类样本的全体是连续的,这个连续性规律是客观世界中人类直观认识范围的客观存在的规律,也是仿生模式识别中用来作为样本点分布的“先验知识”,从而来提高对事物的认识能力。因此,仿生模式识别的目标就是如何对一类样本在特征空间的分布进行最佳覆盖,覆盖的结果可以看作是特征空间中表征该类别的一个复杂几何形体;仿生模式识别的任务就是判别特征空间中待识别样本点是否属于该几何形体[12]。
使用仿生模式识别方法依次对BM1,BM2,BM3,BM4,BM5进行建模,然后用测试集T1,T2和T3进行测试。实验一和实验二分别对有、无历史数据集H两种情况下,增加建模集品种数目,最优识别率对应的PLS维数进行了统计。
(1)在实验一中,当OLDA的特征维数为4时,未将历史数据集H与各建模集一起构建PLS空间,最优识别率对应的PLS维数如表2所示。
(2)在实验二中,当OLDA的特征维数为4时,将历史数据集H分别与各建模集BM1,BM2,BM3,BM4和BM5联合构建PLS空间,最优识别率对应的PLS维数如表3所示。
从表2可以看出,使用未添加同种物质历史近红外光谱构建PLS空间方法时,建模集数量由四种增加到八种时,即建模集分别为BM1,BM2,BM3,BM4和BM5,最优识别率所对应的PLS维数在6~15之间变化,当测试集不同时,最优识别率所对应的PLS维数也发生变化。而表3中,使用添加历史样本光谱联合构建PLS空间方法以后,建模集由四种增加到八种时,最优识别率所对应的PLS维数变化范围主要在6~8之间,且主要稳定在6维。
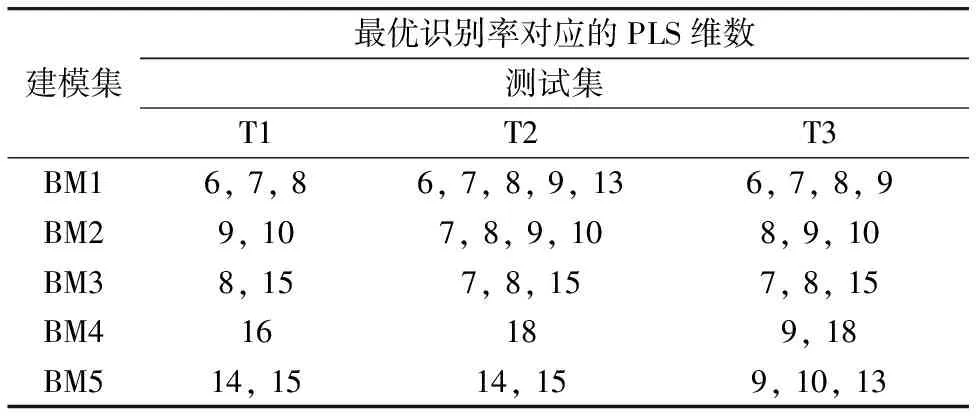
表2 实验一最优识别率对应的PLS维数
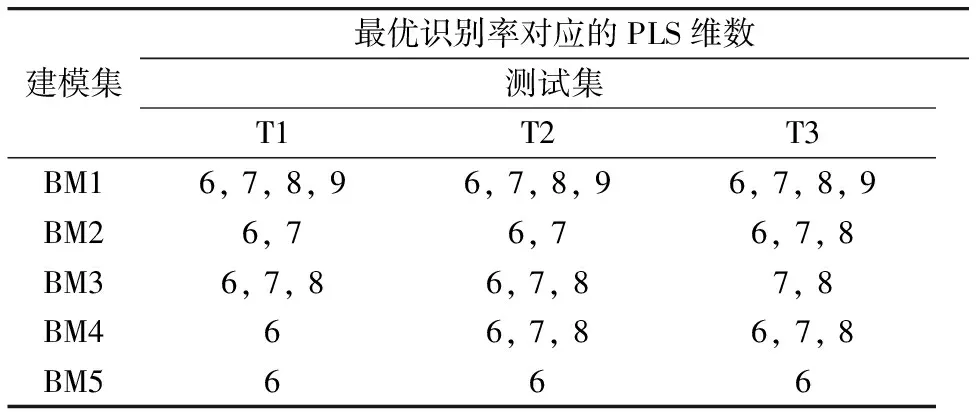
表3 实验二最优识别率对应的PLS维数
图2是未使用添加同种物质历史近红外光谱构建PLS空间方法,PLS维数等于6时,随建模集品种从四种增加至八种,9月15日、9月16日、10月21日三个测试集T1,T2和T3测试所得的识别率变化曲线。
从图2可以看出,对于同一个测试集,虽然在PLS=6时,当建模集品种从四种增加到八种过程中,识别率都会在某一个点高于90%,但是不稳定,同时对于三个日期的测试集T1,T2和T3,识别效果也不一致,所建模型缺乏实际应用价值。

图2 实验一PLS=6识别率变化曲线
图3是使用添加同种物质历史近红外光谱构建PLS空间方法后,PLS维数等于6时,建模集分别为BM1,BM2,BM3,BM4和BM5,随建模集品种从四种增加到八种,9月15日、9月16日、10月21日三个测试集T1,T2和T3测试所得的识别率变化曲线。

图3 实验二PLS=6识别率变化曲线
从图3可以看出,对于同一个测试集,当PLS=6时,建模集分别为BM1,BM2,BM3,BM4和BM5,当建模集品种从四种增加到八种,识别率都高于90%,且对于不同日期的测试集T1,T2和T3,识别效果波动不大,因此在实际应用时就可以在品种鉴别软件中固定设置PLS=6,免除了农作物种子企业在增加建模集品种时为了保证最优识别效果重新选定最优PLS参数的麻烦。
在实验一中未添加历史光谱,虽然对某一测试集能够在某一个PLS维数下获得较高的识别率,但是对于不同的测试集识别效果不一致。此外,在原有模型中增加新的品种时,最优识别率所对应的PLS维数也发生变化,同样也表明模型稳定性不足。说明只用建模品种来构建PLS空间,虽然可以剔除一定的相关信息,提取一些能够解释不同品种间差异的变量,但是由于样本容量相比于变量个数仍显不足,导致模型稳定性不足。若在偏最小二乘环节加入历史近红外光谱,相当于在同样的变量个数情况下,扩大了样本容量,使得偏最小二乘空间包容了更多的差异性,可以进一步消除变量之间的相关性,剔除多重相关信息的干扰,突出不同品种玉米之间的类间差异,从而提高了模型的稳健性。
3 结 论
针对近红外光谱定性分析中,不同时间下的测试样本的识别效果会发生变化,具体来说:同一个模型识别不同天的测试样本时,最优识别率所对应的PLS维数不固定,此外,给新的品种建模时,原有品种的最优识别率所对应的维数也会发生变化,而实际生产中,往往有许多新的品种需要加入原有模型中,由于这种情况导致原有品种的识别效果发生变化,不利于模型的实际应用。本文提出一种将同种物质历史光谱加入建模集,经过预处理后联合构建偏最小二乘空间的特征提取方法。一方面在建模集品种数增加时,使最优识别率所对应的PLS维数稳定在某一固定值;另一方面使用本文所提出的特征提取方法后的数据所建模型对不同天次的测试样本识别率均能达到90%以上,即具有较好的稳健性,使得该方法能够在实际中具有一定的实用价值。
[1] YAN Yan-lu(严衍禄). Modern Instrumental Analysis·3rd ed.(现代仪器分析·第3版). Beijing: China Agricultural University Press(北京:中国农业大学出版社),2010.
[2] LU Wan -zhen, YUAN Hong-fu, XU Guang-tong, et al( 陆婉珍, 袁洪福, 徐广通, 等) . Modern Near Infrared Spectroscopy Analytical Technology·2nd ed.(现代近红外光谱分析技术·第2版). Beijing: China Petrochemical Press(北京: 中国石化出版社), 2007.
[3] ZHU Er-yi,YANG Peng-yuan(朱尔一,杨芃原). Chemometrics Technology and Application(化学计量学技术及应用). Beijing:Science Press(北京:科学出版社),2001.
[4] YAN Yan-lu, CHEN Bin, ZHU Da-zhou(严衍禄, 陈 斌,朱大洲). Near Infrared Spectroscopy Analytical—Principles, Technology and Application(近红外光谱分析的原理、技术与应用) . Beijing: China Light Industry Press(北京: 中国轻工业出版社), 2007.
[5] CAO Wu, LI Wei-jun, WANG Ping, et al(曹 吾,李卫军,王 平,等). Spectroscopy and Spectral Analysis(光谱学与光谱分析),2014, 34(6): 1.
[6] WANG Shou-jue(王守觉). First Step to Multi-Dimensional Space Biomimetic Informatics(多维空间仿生信息学入门). Beijing: National Defense Industry Press(北京:国防工业出版社),2008.
[7] Ji Guoli, Huang Guangzao, Yang Zijiang, et al. Chemometrics and Intelligent Laboratory Systems, 2015, 144:56.
[8] Bi Yiming, Chu Guohai, Wu Jizhong, et al. Chinese Journal of Analytical Chemistry, 2015, 43(7):1086.
[9] Duda R O,Hart P E,Stork D G. Pattern Classification(模式分类). Translated by LI Hong-dong,YAO Tian-xiang,et al(李宏东,姚天翔,等译). Beijing:China Machine Press(北京:机械工业出版社),2003.
[10] Chen Quansheng, Hui Zhe, Zhao Jiewen, et al LWT-Food Science and Technology, 2014, 57(2):502.
[11] Yang J, Jin Z, Yang J Y, et al. Pattern Recognition, 2004, 37(10): 2097.
[12] Wang Shoujue. Biomimetic Pattern Recognition and Multi-Weight Neuron. Beijing: National Defense Industry Press,2012.
(Received Aug. 18, 2015; accepted Dec. 6, 2015)
*Corresponding author
A New Feature Extraction Method of Near-Infrared Spectra Based on the Addition of Historical Data
LI Hao-guang1,2,LI Wei-jun1*, QIN Hong1, ZHANG Li-ping1, DONG Xiao-li1, YU Yun-hua2
1. Institute of Semiconductors, Chinese Academy of Sciences, Beijing 100083, China
2. College of Information and Control Engineering, China University of Petroleum, Dongying 257061, China
In traditional qualitative analysis of near-infrared (NIR) spectra, the stability of recognition models is decreased when new varieties of samples are added into the model. In order to improve the robustness of the model, a new feature extraction method based on the addition of historical data was put forward. The NIR training samples will be collected first, after that the historical data of the same species is added to constitute a larger and richer dataset. Then, the pretreated data of these training samples is projected to the feature space, which is constructed by feature extraction using partial least squares (PLS) based on the above dataset. Subsequently, orthogonal linear discriminant analysis (OLDA) is employed to extract features of the projected data. 18 varieties of corn seeds were taken as study subject, the comparative experiments with and without historical data are implemented respectively, and then the biomimetic pattern recognition (BPR) method is applied to verify the efficiency of the method proposed. The results suggest that the method adopted can improve the robustness of recognition model more effectively compared with the method without historical data. It maintains the high correct recognition ratios when new varieties are added into the model. Besides that, the recognition effect on test sets of the different days remains the same basically in the condition of same PLS dimensions. Therefore, the dimension of feature extraction can be set to some fixed values in recognition software. In this way, it can keep out of the trouble of manually modifying the optimal PLS parameter in recognition software if new varieties need to be added into the model. The experiment results of the thesis manifested the effectiveness of the proposed method.
The near-infrared Spectra; Project; Qualitative analysis; Partial least square
2015-08-18,
2015-12-06
国家重大科学仪器设备开发专项(2014YQ470377),中央高校基本科研业务费专项资金项目(15CX02103A),国家公派访问学者项目(留金发[2014]3012号)和中国石油大学胜利学院科技计划项目(KY2015011)资助
李浩光,1981年生,中国科学院半导体研究所博士研究生 e-mail:lihaoguang@semi.ac.cn *通讯联系人 e-mail:wjli@semi.ac.cn
O657.3
A
10.3964/j.issn.1000-0593(2016)10-3148-06
猜你喜欢
杂志排行

光谱学与光谱分析的其它文章
- Gd靶激光等离子体光源离带辐射及其等离子体演化的研究
- Probing the Binding of Torasemide to Pepsin and Trypsin by Spectroscopic and Molecular Docking Methods
- Mn(Ⅱ)-5-Br-PADAP共沉淀-火焰原子吸收光谱法测定虾、贝样中的镉
- Near Infrared Spectroscopy Study on Nitrogen in Shortcut Nitrification and Denitrification Using Principal Component Analysis Combined with BP Neural Networks
- 内蒙古草原植被最大光能利用率取值优化研究
- 健康和糖尿病大鼠红细胞荧光光谱非线性程度差异