一种改进的AprioriTid算法*
2016-07-08张伟科
张伟科
(沈阳理工大学 理学院, 沈阳 110159)
一种改进的AprioriTid算法*
张伟科
(沈阳理工大学 理学院, 沈阳 110159)
针对经典Apriori算法多次扫描数据库产生I/O负载影响运行效率等问题,在对Apriori算法的原理及其相关改进算法研究的基础上,提出了一种基于压缩集的改进Apriori算法,即AprioriTid_M算法.通过有效的裁剪方法减少无效项集的产生,减少候选项集的数量,从而提高算法的效率.仿真实验表明,在支持度相同但数据量不同,以及数据量相同但支持度不同这两种条件下,AprioriTid_M算法在性能上和运算时间上都比Apriori算法有很大程度的改善.
Apriori算法; AprioriTid算法; AprioriTid_M算法; 关联规则; 置信度; 项集; 支持度; 性能
数据挖掘关联规则中相当经典的算法就是Apriori算法,该算法具有反单调性的特点.Apriori算法首先生成候选项集判断是否为频繁项集[1],所生成的频繁项集的任一子集均是频繁的,含有非频繁项集的任意子集的项集一定是非频繁的.运用迭代的思想,首先发现频繁1项集,由频繁k-1项集生成k候选项集,逐层扫描数据库后从候选k项集中筛选出频繁k项集,直到最终剩下的候选项集为空时算法结束[2].
1 Apriori算法核心思想
Apriori算法生成频繁项集的算法描述如下.
输入:数据集D,设置最小支持度min_sup的阈值.
输出:D中的频繁项集L.
L1=find_frequent_1-itemset(D);
for(k=2;Lk-1≠φ;k++){
Ck=apriori_gen(Lk-1);
//产生候选项集
for all transactiont∈D{
Ct=subset(Ck,t);
//识别t包含的所有候项集
for all candidatesc∈Ct{
c.count++;
//支持度计算增值
}
}

//提取频繁k项集
}
returnL=∪kLk;
procedure apriori_gen(Lk-1)
for eachitemsetl1∈Lk-1
for eachitemsetl2∈Lk-1
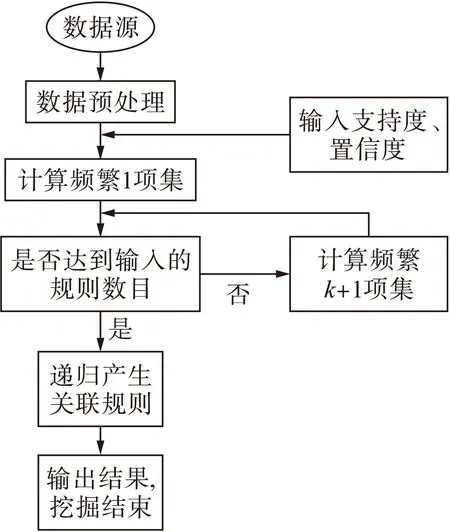
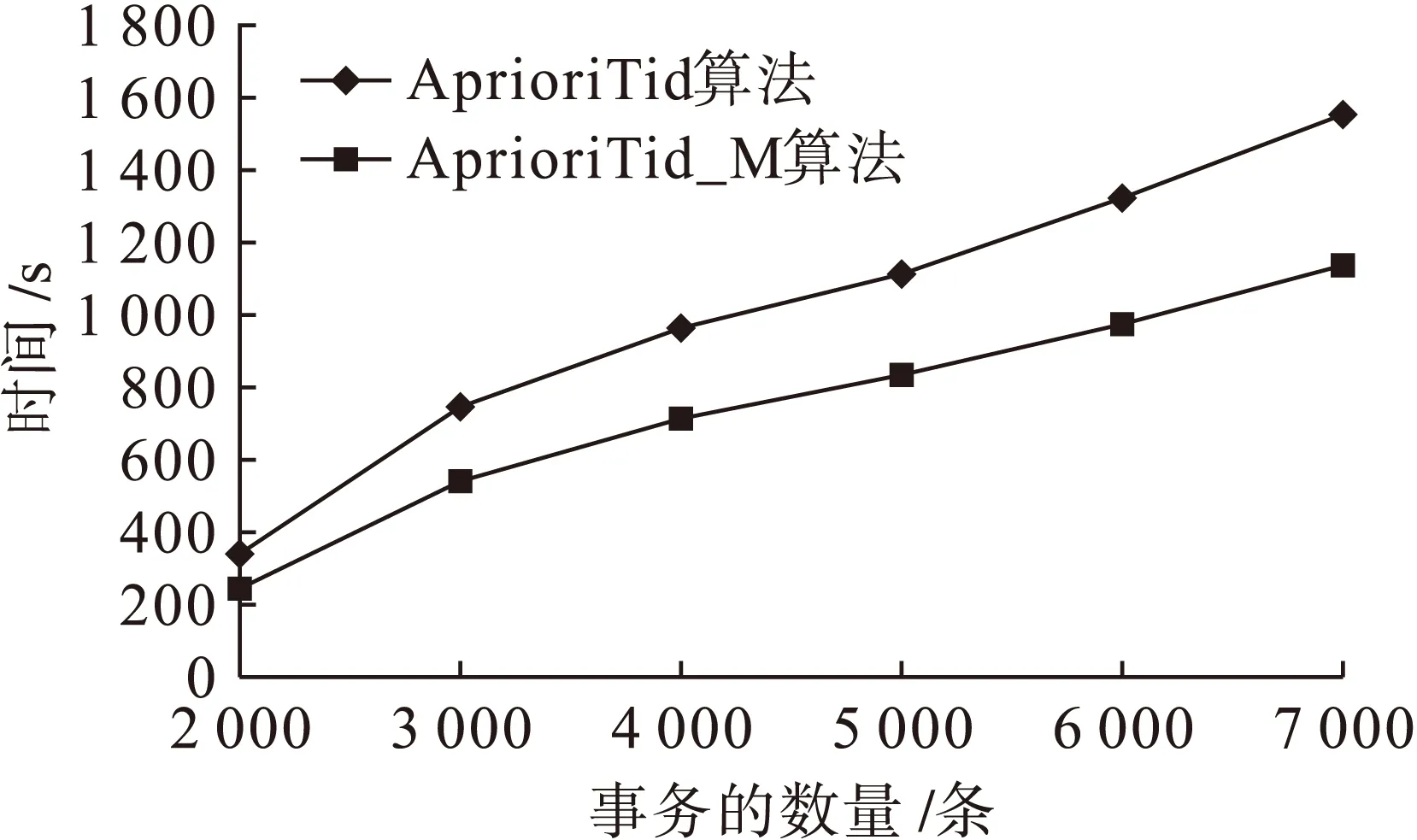
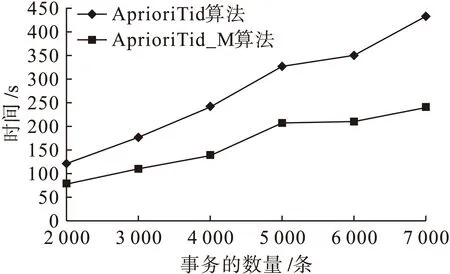
if(l1[1]=l2[1])∧…∧(l1[k-2]=l2[k-2])∧(l1[k-1] c=join(l1,l2); //连接:产生候选项集 if has_infrequent_subset(c,Lk-1)then deletec //剪枝:移除非频繁的候选项集 else addctoCk } returnCk procedure has_infrequent_subset(c,Lk-1) //使用先验知识判断候选项集是否频繁 for each(k-1)-subsetsofc ifs∉Lk-1then return TRUE; return FALSE 算法的具体步骤如下. 1) 单遍扫描数据集,得到每个项的支持度以及所有频繁1项集的集合L1. 2) 通过调用apriori_gen[3]函数对前一次扫描得到的频繁k-1项集再次扫描,依据每项的支持度使判断阈值得到新的候选k项集.apriori_gen函数由频繁k-1项集生成候选k项集,经过连接和剪枝,其两个步骤如下所示. ② 剪枝.由has_infrequent_subset函数完成[5],判定候选项集中的k项集是否含有k-1非频繁项集,若含有k-1项集是非频繁的,则要将该候选项集删除以此完成剪枝.图1为Apriori算法挖掘事物数据的关联规则流程图. 图1 关联规则流程图 虽然Apriori算法能够实现对数据项的关联规则挖掘,但是随着数据库存储量的增加和对算法的迭代应用及研究,表明Apriori算法主要有两方面运行性能瓶颈[6]. 1) 反复多次扫描事物的数据库,增加了I/O的负载.Apriori算法每次进行k循环都要完整地扫描数据库,判定候选项集Ck中的每一个元素是否能够成为项集Lk.例如,一个最大频繁项集中有15个项,就需要至少扫描事物数据库15遍才能完成任务.对于海量数据挖掘来说,I/O负载量非常大. 2) 海量数据会产生异常庞大的候选项集.项集Lk-1候选项集Ck是呈指数增长的,数量庞大.例如,104个频繁1项集会产生大约107个元素的候选2项集[7].庞大的候选项集浪费了存储空间,同时降低了运行效率,因此,算法的运行性能方面需加以优化. 2.1AprioriTid算法 AprioriTid算法主要是通过减少扫描事物数据量来实现性能优化.一个事物中如果不包含k阶大项集,则一定不含有k+1阶的大项集.因此,忽略大项集事务后,可减少后续循环扫描事物的次数,并且不会影响到候选项集的支持度. AprioriTid算法的过程描述如下: L1={large 1-itemsets}; //计算1阶大项集 for(k=2;Lk-1≠φ;k=k+1); Ck=apriori_gen(Lk-1); //构造候选项集 //t包含的候选项集 for allC∈CtdoC.sup=C.sup+1;end for end if //构造k阶候选项集的Tid表 end for //计算k阶大项集 end for L=∪kLk 2.2AprioriTid_M算法 AprioriTid算法只在计算1项集的支持度时对数据库D进行了扫描,减少了运行时间,但是过于庞大的候选项集还是会影响运行时间,因此,本文提出一种基于压缩集的AprioriTid_M改进算法.根据原理,频繁项集的所有非空子集一定是频繁项集[9],可得频繁k项集的所有k-1项集一定也是频繁的,以此为基础进一步地优化Tid表. 性质1如果频繁k项集可以产生频繁k+1项集,那么频繁k项集中的项集个数一定大于k. 证明由一切频繁项集的非空子集一定是频繁的,推出Lk+1任何项集的k+1个不同k项子集一定在频繁k项集中,证明完毕. 性质2若Mk是数据库D中的频繁k项集[10],那么Mk中包含的任何一项在全部k-1项集Mk-1里出现的次数一定大于等于k-1次. 证明假设Nk={x1,x2,x3,…,xk},xi∈Lk,频繁项集Nk∈Lk,xi∈I,i=1,2,…,k,其中,I={I1,I2,…,Im}是数据项的集合,则Nk中任何一个含有k-1个项的子集也一定是频繁项集,且它们都属于Lk-1.设Nk-1,i=Nk-{xi},则推出xi∈Nk-{xj},j≠i,j=1,2,…,k,即xi一定在其他的k-1项集集合中,因此,频繁k项集Lk中任意的xi项在Lk-1里面至少出现k-1次,证明完毕. L1={频繁1项集}; for(k=2;Lk-1≠φ;k++)do begin; //产生全部的频繁项集 Lk-1=A_prune(Ck-1); for每一个项目T1∈t.set-itemsets; for每一个项目T2∈t.set-itemsets; for所有候选c∈Ctdo; if((T1[1]=T2[1])∧(T1[2]=T2[2])∧…∧(T1[k-2]=T2[k-2])∧(T1[k-1] {c=T1; addctoCt; c.count++}; end; Answer=UkLk 图2 改进的AprioriTid_M算法示例 为了验证改进后的AprioriTid_M算法的性能,分别采用AprioriTid算法和改进的AprioriTid_M算法对相同的数据进行挖掘,测试出在不同的支持度下两种算法执行所需要的时间,和不同的数据规模下两种算法运行所需要的时间.操作系统采用Windows XP Professional,利用SQL 2005对实验数据进行预处理. 图3为设置不同支持度时,数据集量为1 000条时,使用AprioriTid算法和AprioriTid_M算法生成频繁项集所消耗的时间对比图.当数据量相同时,AprioriTid产生频繁项集的时间随着支持度的增加变化幅度比较大,性能不够稳定.改进的AprioriTid_M算法对于相同的数据进行运算时,时间变化幅度相对较小,且运算时间明显少于没有改进时所使用的时间,说明AprioriTid_M算法在计算时间和性能上比AprioriTid算法有很大程度的提高. 图3 支持度不同时产生频繁项集所需的时间 图4为分别选取事务数据量为2 000、3 000、4 000、5 000、6 000和7 000,支持度为0.5时两种算法运行所消耗的时间对比图.由图4可以看出,两种算法在数据量增加时,消耗的时间越来越多.但是在处理等量数据时,AprioriTid_M算法运行的时间明显小于改进前的算法消耗时间,且当数据量增加时,运行时间的增值幅度是趋于平稳的,而AprioriTid算法随事务总量增加时,消耗时间增长幅度比较大,性能不够稳定. 图4 支持度为0.5时两种算法的运行时间 图5为支持度为0.7时两种算法的运行时间.由图5可知,当支持度为0.7时,改进后的AprioriTid_M算法用时较少,且随着事务量的增长,运行时间平稳增长,而AprioriTid算法运行时间随事务量增加而急剧增长,性能不如改进后的算法稳定. 图5 支持度为0.7时两种算法的运行时间 综上可知,改进后的AprioriTid_M算法在性能上和运行效率上有所提高,稳定性比较好. 本文研究了经典Apriori算法的核心思想,分析了该算法性能上的缺点和不足,在此基础上研究了AprioriTid算法,并提出一种基于事务集压缩的AprioriTid_M算法.通过对这两种算法在等量事务数据、不同支持度下的运行时间比较和某一设定支持度下不同事务数据量的运行时间比较分析,证明了AprioriTid_M算法在性能和效率上均高于AprioriTid算法. [1]张春燕,孟志青,袁沛.文本挖掘的时态文本关联规则算法研究 [J].计算机科学,2013,40(6):219-224. (ZHANG Chun-yan,MENG Zhi-qing,YUAN Pei.Mining algorithm for temporal text association rules in text mining [J].Computer Science,2013,40(6):219-224.) [2]Silverstri C,Orlando S.Approximate mining of frequent patterns on streams [J].Intelligent Data Analysis,2007,11(1):49-73. [3]于孝美,陈贞翔,彭立志.基于决策树的网络流量分类方法 [J].济南大学学报(自然科学版),2012,26(3):291-295. (YU Xiao-mei,CHEN Zhen-xiang,PENG Li-zhi.Traffic classification based on decision tree [J].Journal of University of Jinan(Science and Technology),2012,26(3):291-295.) [4]Tsang S,Kao B,Kevin Y Y,et al.Decision trees for uncertain data [J].IEEE Transations on Knowledge and Date Engineering,2011,23(1):64-78. [5]Kohavi R,Provost F.Applications of data mining to electronic commerce [J].Data Mining and Knowldege Discovery,2011,5(1):5-10. [6]焉晓贞,谢红,王桐.一种基于相关分析的多元回归数据估计方法 [J].沈阳工业大学学报,2013,35(2):212-217. (YAN Xiao-zhen,XIE Hong,WANG Tong.Data evaluation method using multiple regression based on correlation analysis [J].Journal of Shenyang University of Technology,2013,35(2):212-217.) [7]翟云,杨炳儒,曲武,等.基于新型集成分类器的非平衡数据分类关键问题研究 [J].系统工程与电子技术,2011,33(1):196-201. (ZHAI Yun,YANG Bing-ru,QU Wu,et al.Study on source of classification in imbalanced datasets based on new ensemble classifier [J].Systems Engineering and Electronics,2011,33(1):196-201.) [8]向程冠,熊世桓,王东.基于关联规则的社交网络好友推荐算法 [J].中国科技论文,2014,9(1):87-91. (XIANG Cheng-guan,XIONG Shi-huan,WANG Dong.Social network friends recommendation algorithm based on association rules [J].China Sciencepaper,2014,9(1):87-91.) [9]章志刚,吉根林.一种基于FP-Growth的频繁项目集并行挖掘算法 [J].计算机工程与应用,2014,50(2):103-106. (ZHANG Zhi-gang,JI Gen-lin.Parallel algorithm for mining frequent item sets based on FP-Growth [J].Computer Engineering and Applications,2014,50(2):103-106.) [10]胡维华,冯伟.基于分解事务矩阵的关联规则挖掘算法 [J].计算机应用,2014,34(增刊2):113-116. (HU Wei-hua,FENG Wei.Improved Apriori algorithm based on decomposed transaction matrix [J].Journal of Computer Applications,2014,34(Sup2):113-116.) (责任编辑:钟媛英文审校:尹淑英) An improved AprioriTid algorithm ZHANG Wei-ke (School of Science, Shenyang Ligong University, Shenyang 110159, China) In order to solve the problem that the I/O load generated in the repeated scanning database for the classic Apriori algorithm will affect the running efficiency, an improved AprioriTid algorithm based on the compression set, namely the AprioriTid_M algorithm, was proposed on the basis of the research on the principle of Apriori algorithm and its related improved algorithms. Through the effective pruning methods, the generation of invalid item sets was reduced, and the number of candidate item sets was decreased. Therefore, the efficiency of the algorithm was improved. The results of simulation experiments show that under such conditions as the same support degree but different data amount or the same data amount but different support degree, the performance and running time of AprioriTid_M algorithm get greatly improved compared with those of Apriori algorithm. Apriori algorithm; AprioriTid algorithm; AprioriTid_M algorithm; association rule; confidence degree; item set; support degree; performance 2015-12-03. 辽宁省科学技术计划项目(2012217005); 辽宁省科学事业公益研究基金资助项目(2012004002). 张伟科(1965-),男,河北秦皇岛人,讲师,硕士,主要从事计算机视觉、智能检测与控制等方面的研究. 10.7688/j.issn.1000-1646.2016.03.14 TP 311 A 1000-1646(2016)03-0314-05 *本文已于2016-04-22 15∶41在中国知网优先数字出版. 网络出版地址: http:∥www.cnki.net/kcms/detail/21.1189.T.20160422.1541.006.html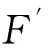
2 改进的Apriori算法



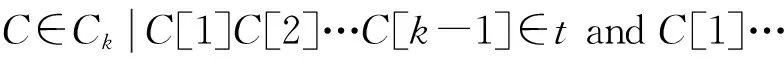
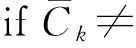
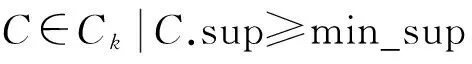
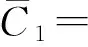


3 算法性能比较

4 结 论
