微信息大数据粗糙集的近似约简*
2016-07-08任艳
任 艳
(新疆财经大学 计算机科学与工程学院, 乌鲁木齐 830012)
微信息大数据粗糙集的近似约简*
任艳
(新疆财经大学 计算机科学与工程学院, 乌鲁木齐 830012)
为了应对微信息舆情数据的格式复杂、价值稀疏和收集困难等大数据处理技术难题,基于隐含语义分析和粗糙集近似约简理论,设计微信息的数据区间值集和近似匹配分类算法.在不影响数据主要关联关系的原则下,提炼核心属性、消减次要属性,实现一种微信息异常主题倾向的发现方法.结果表明,该近似约简算法能在完成微信息兴趣倾向主题分类的前提下,将数据集属性大幅度缩减,提高微信息的信息挖掘效率,为微信息大数据舆情处理工作提供了新的思路和案例.
大数据; 微信息; 近似约简; 粗糙集; 隐含语义分析; 主题发现; 区间值; 近似集
随着智能手机等移动通信设备的迅猛发展,SNS(社会性网络服务)规模空前巨大,大数据处理面临许多难题.交互方式与信息格式复杂纷繁,处理分析越来越困难,如何降低数据复杂度,估算微信息兴趣倾向成为微信息处理的难点.
1 微信息语义倾向与高维问题
1.1兴趣倾向识别
微信息文字形式自由,语法不规范、不严格,谐音词、派生词及诙谐语多发,内容也经常不完整,相同“圈子”内的用户也不一定有相近的兴趣倾向.用户兴趣倾向难以归类和识别,所面临的大数据环境也成为微信息主题分析的重要障碍[1].通过扩展计算机网络服务的处理器和存储阵列,在一定程度上已经缓解了数据量大所带来的困难,但数据格式多样、辨识难度大和信息稀疏等困难没有较好的解决办法[2].大数据的整体信息价值蕴含量巨大,而单元信息价值密度极低,价值不规律分布和有效价值隐藏极深,所以信息集必须在更高的聚类、检索层面进行有效价值挖掘[3-4].微信息用户兴趣倾向的发现必须结合关联性,忽略部分精准性,建立一种可靠的属性降维机制以应对现实需要.
1.2聚类匹配的高维问题
传统的文本匹配法无一不受困于数据稀疏性严重、NP完全陷阱等缺陷,显示出明显的高维属性局限性[5-7].应用机器学习算法实现分类,其属性特征集的选择对分类结果有极大影响,直接关系到分类准确率和效率[8].按文句的重要性进行全域性文摘,建立语义相似性关系和上下文句语境的关系,归纳分析效果突出[9],但是文本属性空间(维性)越来越庞大,NP完全局限性成为致命难题.文本匹配计算的主要内容:将微文本中的热词分开,再将分开的热词与词库进行比对,进行同类汇聚[10-11],按照数据属性特征进行归类分隔,使同一类集内的数据关系“密切凝聚”,而不同类集间的数据“关系松散”.
1.3分布式索引中的高维问题
梳理索引技术可以发现数据降维的必要性.大数据按照“row-key”的关系表顺序形成全局性分布式索引,能够应用MapReduce架构来实现大数据处理的并行化[12-13],但当数据维性非常大的时候,由于事务性要求比较高,实效性将无法满足实际的需求.分布式服务器端的维护代价较高,多维性的关联操作需要消耗大量的资源去缓存内部节点,降维是必然的结果[14-15].
大数据降维也称为离群挖掘,即将整个目标数据集投影到包含个别属性的子空间上[16].研究微信息降维问题,就是选择和投影有意义的子空间的过程,以适应微信息快速分类和分析的需要.
2 微信息兴趣倾向发现
微信息基于各种强弱关系的交流圈,具有高频度和裂变传播特征,易于采用近似匹配法来进行兴趣倾向识别工作.近似模糊匹配可以容忍数据过滤中存在一定噪声和错误,在微信息交互分析和舆情网络分析应用中,作用越来越重要[17-19].
2.1PLSA分析
Hofmann提出了一种基于概率模型的隐含语义分析法(PLSA),使用概率模型可以将微信文本和敏感词映射到同一个语义空间中[20].通过计算信息文本、关键词与语义(兴趣倾向)空间上的夹角来实现近似匹配的量化工作.本文结合微信息交流的特点,将PLSA隐含语义分析法进行了改造,假设隐含语义(主题倾向)序列为D={d1,d2,…,dk},相应的微信息文本属性空间表示为C={c1,c2,…,cm},先验性的敏感词空间表示为W={w1,w2,…,wn}.首先观察(C,W)变量的联合概率与隐含语义D的关系,文本和敏感词的联合概率表示为
(1)
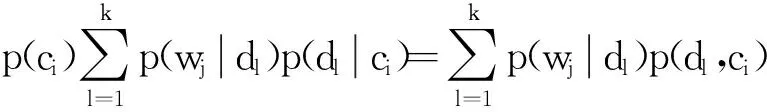
(2)
于是有
(3)
假设敏感词与语义倾向之间的映射关系保持不变,即p(wj,dl)不变,则有
(4)
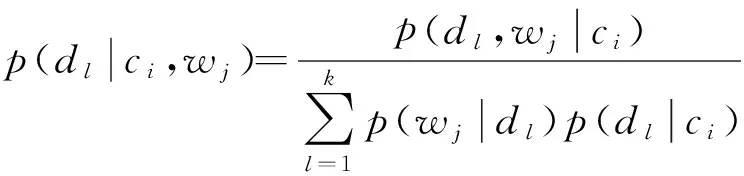
(5)
因为敏感词wj与文本属性ci之间相互独立,则有

(6)
故隐含语义dl相对于给定观察对象(C,W)的条件概率分布为

(7)
2.2微信息数据集
本文了建立两个数据集:微信息兴趣倾向数据集和敏感分词数据集,从而为倾向性判断的可靠性提供依据.
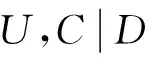
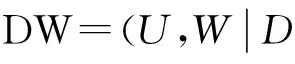
2.3粗糙集约简
RS粗糙集(Rough set,RS)理论通过集合模糊运算,构造出上下近似集来标定有效数据的边界,解决了含糊环境下的逻辑推理问题[23-24].保持住数据集主要维性、忽略次要属性是数据集化简的基本手段.
(8)
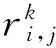
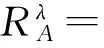
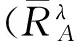
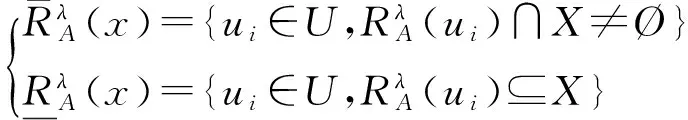
(9)
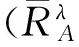
4) 多属性依赖.基于区间值条件下属性集合依赖度计算方法为
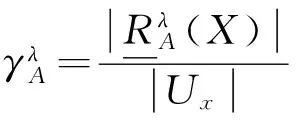
(10)
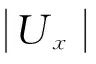

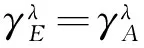
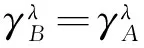
3 数据实验
本实验收集了2014年10月—2014年12月新浪微博贴吧、手机短信、微信和QQ空间数据作为样本来测试算法,具体步骤如下:
1) 原数据预处理.设置预制的主题倾向类集D={d1,d2,…,dl},依次对应着“恐怖”、“低俗”、“污蔑”、“造谣”、“反动”、“斗殴”、“欺骗”等预定倾向类.每一种倾向类下仍有许多具体的主题倾向,例如:低俗d2类下可能具体到发布黄色图片、观看黄色图片和黄色表演等.文本长度超过500字的部分自动舍弃;图片、视频部分取文件名,非文本部分自动舍弃.
2) 针对每种倾向主题建立敏感分词子集.首先应用汉语词法分析软件ICTCLAS进行中文分词、词性标注和词识别等操作,删除平庸中性词后,选取出现频率最高的分词,然后将每个倾向主题对应到多个敏感分词,预制数量在10~50之间,最后针对每一种敏感分词,按出现的次数分别定义不同的属性维度以区分敏感强度.具体规则为:以第i个敏感词为例,设置属性wi1(初级)敏感分词出现1~2次;wi2(中级)敏感分词出现4~6次;wi3(高级)敏感分词出现7~14次;wi4(极高)敏感分词出现15次及以上,每个敏感分词将产生4列区间属性值.
3) 构建用户微信息交互行为数据集.面对同类倾向涉嫌的帖子,收集微信息交互行为(ci),依然将用户的行为强度定义为四个等级:{初级,中级,高级,极高},使每一种交互行为也有四列区间属性值,即ci={ci1,ci2,ci3,ci4}.基于用户行为数据,搜集典型用户行为,由程序自动按行为强度形成用户行为数据集.
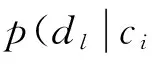
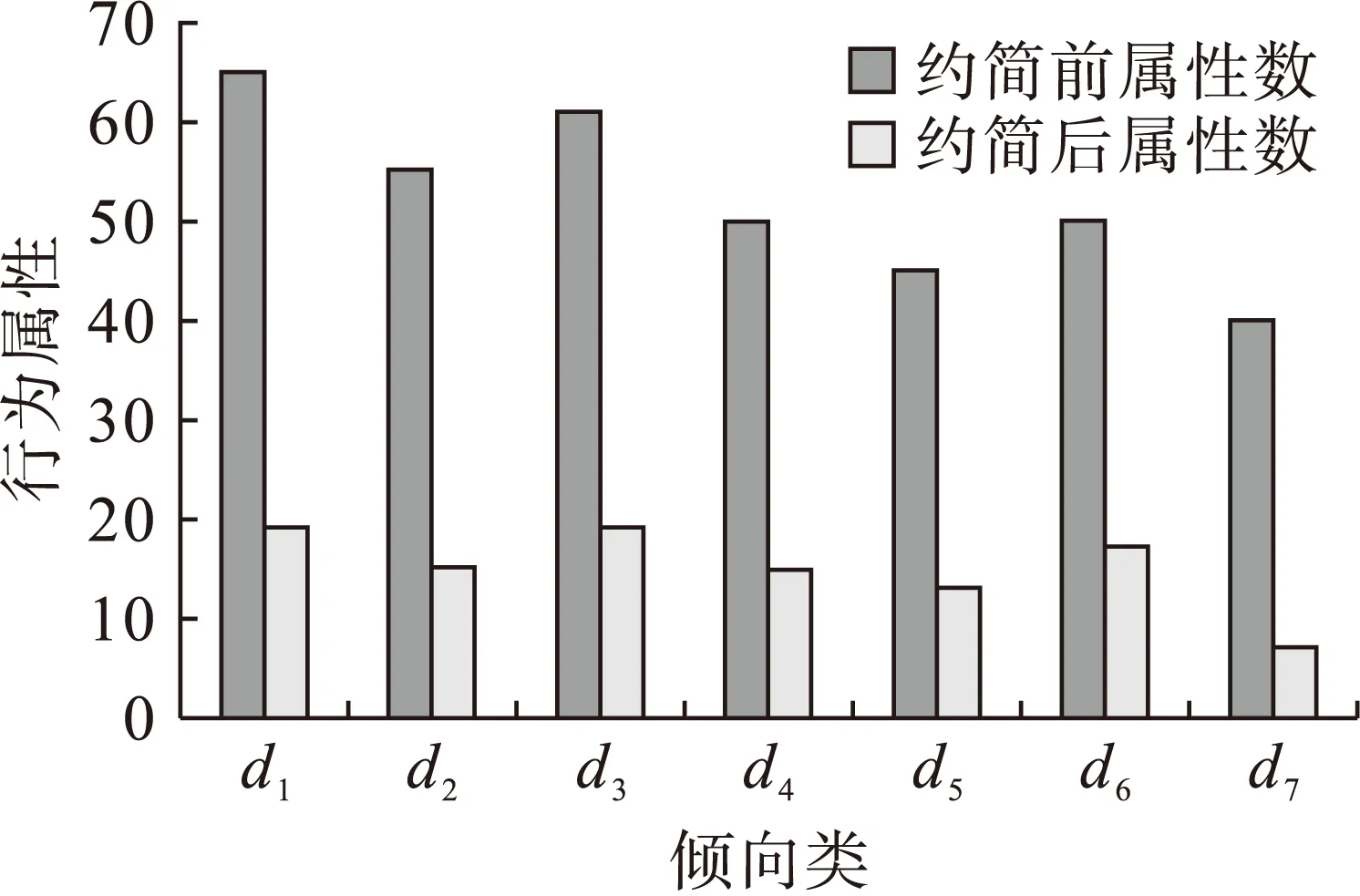
图1 属性约简效果
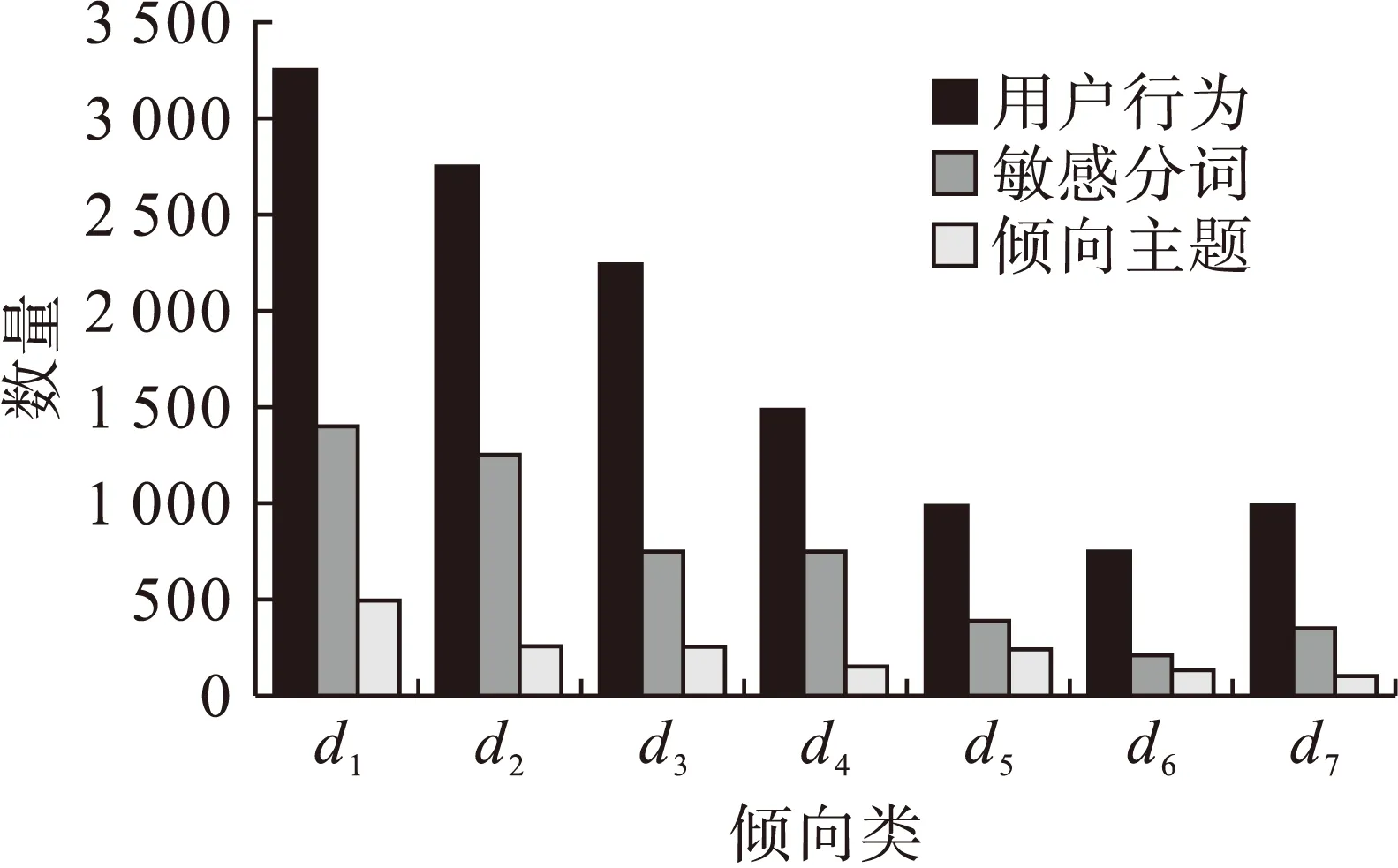
图2 用户行为、敏感类型与倾向主题对比
4 结 论
微文数据具有价值稀疏、体量大、内容不完整和碎片化等特点,本文基于粗糙集的近似模糊约简法将微信息属性集、敏感词库数据集、隐含语义信息数据集构建成“区间表”,通过构建上下近似约简集进行相关属性重要性计算,保留重要性属性,消除冗余属性.在微博、微信、短信和QQ空间等微信息数据分析中,实现主题归纳和用户兴趣捕捉工作.从实验结果可知,约简算法是有效的,为微信息的大数据属性约简和语义分析方法提供了新思路.
[1]吴纯青,任沛阁,王小峰.基于语义的网络大数据组织与搜索 [J].计算机学报,2015,38(1):1-7.
(WU Chun-qing,REN Pei-ge,WANG Xiao-feng.Survey on semantic-based organization and search technologies for network bid data [J].Chinese Journal of Computers,2015,38(1):1-7.)
[2]程学旗,靳小龙.大数据系统和分析技术综述 [J].软件学报,2014,25(9):1240-1252.
(CHENG Xue-qi,JIN Xiao-long.Survey on big data system and analytic technology [J].Journal of Software,2014,25(9):1240-1252.)
[3]何非,何克清.大数据及其科学问题与方法的探讨 [J].武汉大学学报(理学版),2014,60(1):1-12.
(HE Fei,HE Ke-qing.The scientific problems and methodology of bid data [J].Journal of Wuhan Uni-versity (Natural Science Edition),2014,60(1):1-12.)
[4]孟小峰,慈祥.大数据管理:概念、技术与挑战 [J].计算机研究与发展,2013,50(1):146-169.
(MENG Xiao-feng,CI Xiang.Bid data management:concepts,techniques and challenges [J].Journal of Computer Research and Development,2013,50(1):146-169.)
[5]李扬,苗夺谦,张志飞.情感不确定词句的分类方法比较研究 [J].计算机科学,2015,42(1):210-214.
(LI Yang,MIAO Duo-qian,ZHANG Zhi-fei.Sentiment analysis of words and sentences with uncertainty [J].Computer Science,2015,42(1):210-214.)
[6]姜芳,李国和,岳翔.基于语义的文档关键词提取方法 [J].计算机应用研究,2015,32(1):142-146.
(JIANG Fang,LI Guo-he,YUE Xiang.Semantic-based keyword extraction method for document [J].Application Research of Computers,2015,32(1):142-146.)
[7]索勃,李战怀,陈群,等.基于信息流动分析的动态社区发现方法 [J].软件学报,2014,25(3):547-559.
(SUO Bo,LI Zhan-huai,CHEN Qun,et al.Dynamic community detection based on information flow analysis [J].Journal of Software,2014,25(3):547-559.)
[8]张福勇,赵铁柱.采用路径IRP的Windows恶意进程检测方法 [J].沈阳工业大学学报,2015,37(4):434-439.
(ZHANG Fu-yong,ZHAO Tie-zhu.Windows malicious process detection method with path IRP [J].Journal of Shenyang University of Technology,2015,37(4):434-439.)
[9]刘德喜,万常选.社会化短文本自动摘要研究综述 [J].小型微型计算机系统,2013,34(12):2764-2771.
(LIU De-xi,WAN Chang-xuan.Survey on automatic summarization of socialized short text [J].Journal of Chinese Computer Systems,2013,34(12):2764-2771.)
[10]Liu X L,Liao J X,Zhu X M.Lexical analysis based on combining senses in ontology matching [J].ACTA Electronica Sinica,2012,40(8):1024-1029.
[11]Rabl T,Sadoghi M,Jacobsen H A.Solving big data challenges for enterprise application performance mana-gement [J].Process of the VLDB Endowment,2012,12(5):1724-1735.
[12]王东.大数据技术在精准化营销中的应用 [J].中国流通经济,2014(7):90-93.
(WANG Dong.The application of big data technology to precision marketing [J].China Business and Market,2014(7):90-93.)
[13]马友忠,孟小峰.云数据管理索引技术研究综述 [J].软件学报,2014,25(8):1557-1578.
(MA You-zhong,MENG Xiao-feng.Research on indexing for cloud data management [J].Journal of Software,2014,25(8):1557-1578.)
[14]Mou Y C,Su H C,Cheng X.An adaptive secondary index for data management in cloud computing environment [J].Journal of Computer Research and Development,2013,24(8):1836-1851.
[15]刘义,景宁,陈荦,等.MapReduce框架下基于R-树的k-近邻连接算法 [J].软件学报,2013,24(8):1836-1851.
(LIU Yi,JING Ning,CHEN Luo,et al.Algorithm for processingk-nearest join based on R-tree in MapReduce [J].Journal of Software,2013,24(8):1836-1851.)
[16]张继福,李永红.基于MapReduce与相关子空间的局部离群数据挖掘算法 [J].软件学报,2015,26(5):1079-1095.
(ZHANG Ji-fu,LI Yong-hong.Related-subspace-based local outlier detection algorithm using MapReduce [J].Journal of Software,2015,26(5):1079-1095.)
[17]于静.刘燕兵,张宇,等.大规模图数据匹配技术综述 [J].计算机研究与发展,2015,52(2):391-409.
(YU Jing,LIU Yan-bing,ZHANG Yu,et al.Survey on lame-scale graph pattern matching [J].Journal of Computer Research and Development,2015,52(2):391-409.)
[18]李伟平,王武生,莫同,等.情境计算研究综述 [J].计算机研究与发展,2015,52(2):542-552.
(LI Wei-ping,WANG Wu-sheng,MO Tong,et al.Survey of contextual computing [J].Journal of Computer Research and Development,2015,52(2):542-552.)
[19]夏琳琳,潘旭影,王丹,等.基于类高斯隶属函数的模糊万能逼近器性能分析 [J].沈阳工业大学学报,2014,36(3):316-321.
(XIA Lin-lin,PAN Xu-ying,WANG Dan,et al.Performance analysis of fuzzy universal approximator based on Gauss-type membership function [J].Journal of Shenyang University of Technology,2014,36(3):316-321.)
[20]王云英.基于PLSA模型的Web页面语义标注算法研究 [J].情报杂志,2013,32(1):141-144.
(WANG Yun-ying.Research on Web page semantic annotation algorithm based on PLSA model [J].Journal of Intelligence,2013,32(1):141-144.)
[21]徐恪,张赛,陈昊,等.在线社会网络的测量与分析 [J].计算机学报,2014,37(1):165-173.
(XU Ke,ZHANG Sai,CHEN Hao,et al.Measurement and analysis of online social networks [J].Chinese Journal of Computers,2014,37(1):165-173.)
[22]于洪,杨显.微博中节点影响力度量与传播路径模式研究 [J].通信学报,2012,33(增刊1):96-102.
(YU Hong,YANG Xian.Studying on the node’s influence and propagation path modes in microblogging [J].Journal on Communications,2012,33(Sup1):96-102.)
[23]李小林,张力娜.基于直觉模糊理论的混合多属性Web服务选择 [J].沈阳工业大学学报,2014,36(6):676-680.
(LI Xiao-lin,ZHANG Li-na.Hybrid multi-attribute Web service selection based on intuitionistic fuzzy theo-ry [J].Journal of Shenyang University of Technology,2014,36(6):676-680.)
[24]徐菲菲,雷景生.大数据环境下多决策表的区间值全局近似约简 [J].软件学报,2014,25(9):2119-2125.
(XU Fei-fei,LEI Jing-sheng.Approaches to approximate reduction with interval-valued multidecision tables in big data [J].Journal of Software,2014,25(9):2119-2125.)
[25]江峰,王莎莎,杜军威,等.基于近似决策熵的属性约简 [J].控制与决策,2015,30(1):66-70.
(JIANG Feng,WANG Sha-sha,DU Jun-wei,et al.Attribute reduction based on approximation decision entropy [J].Control and Decision,2015,30(1):66-70.)
(责任编辑:景勇英文审校:尹淑英)
Approximate reduction of micro-message big data rough set
REN Yan
(School of Computer Science and Engineering, Xinjiang University of Finance &Economy, Urumqi 830012, China)
In order to deal with such technological problems in big data processing as complex format, sparse value and difficult collection of micro-message public opinion data, based on the latent semantic analysis (LSA) and rough set approximate reduction theory, the data interval value set and approximate matching classification algorithm of micro-message were designed. Under the principle of not affecting the main association relationship of data, the core attributes were extracted, the secondary attributes were reduced, and a method of discovering the micro-message abnormal theme tendency was realized. The results show that under the premise of completing the classification of micro-message interest tendency themes, the proposed approximate reduction algorithm can greatly reduce the data set properties, improve the information mining efficiency of micro-message, and provide a new thought and case for the processing work of public opinion of micro-message big data.
big data; micro-message; approximate reduction; rough set; latent semantic analysis; theme discovery; interval value; approximation set
2015-12-04.
教育部规划课题资助项目(14YJA860017).
任艳(1979-),女,新疆乌鲁木齐人,讲师,主要从事计算机信息技术与应用等方面的研究.
10.7688/j.issn.1000-1646.2016.03.13
TP 393.1
A
1000-1646(2016)03-0309-05
*本文已于2016-03-02 16∶48在中国知网优先数字出版. 网络出版地址: http:∥www.cnki.net/kcms/detail/21.1189.T.20160302.1648.048.html
