基于组合核函数SVM的文本主题识别
2016-07-07吕洪艳刘芳
吕洪艳,刘芳
基于组合核函数SVM的文本主题识别
吕洪艳,刘芳
摘 要:文本内容主题识别的实际应用中,大量文本之间彼此掺杂,使其无法线性表述,应用SVM可以有效地解决这种非线性不可分问题,而核函数的选择是SVM的关键。鉴于单核无法兼顾识别准确率与召回率,针对文本主题识别的特定应用,将多项式核函数和径向基核函数进行线性加权组合,构建兼具全局核函数的泛化能力及局部核函数的学习能力的组合核函数,并通过网格搜索法确定最优参数。在仿真实验中评估了线性核、多项式核、径向基核以及组合核函数,实验结果表明,组合核函数SVM的识别性能明显优于其它3单核函数,识别准确率与召回率都比较理想。
关键词:SVM;组合核函数;文本识别;召回率;文本主题
章编号:1007-757X(2016)05-0073-04
基金来源:黑龙江省教育科学规划重点课题(GJB1215019);教育部人文社会科学研究项目(15YJA630074)。
0 引言
随着信息技术的迅猛发展, 网络文本信息也不断膨胀,文本内容识别作为确定文章类别的分析方法,是组织、管理文本信息的有效手段,可以有效地解决信息杂乱无章的问题,使用户从大量杂乱的信息中定位到所需的信息。文本分类广泛地应用于信息检索、信息过滤、电子邮件、搜索引擎、数字图书馆等各方面,在多种领域都起着至关重要的作用。随着人们对信息分类需求的日益增长,如何提高分类性能是目前亟待解决的问题。
目前基于文本内容过滤的模型主要有贝叶斯决策模型、向量空间模型(VSM)、神经网络模型、和支持向量机模型(SVM)等。贝叶斯决策模型能够解决多语种兼容性问题,而且算法逻辑简单、比较稳定,适用于垃圾邮件过滤领域,但模型中特征项是在独立性假设的基础上建立的,所以准确率较低[1]。VSM模型把文本信息过滤过程简化为空间向量的运算,可操作性好,但是无法区分特征项出现在不同位置对表达文档主题性质能力的差异,无法充分反映文本全貌,且特征项权重难以确定[2]。神经网络模型具有很强的自适应能力,能够实现自我更新和完善,但算法复杂、不支持部分匹配,而且执行速度慢[3]。SVM主要优势体现在解决高纬度、小样本以及线性不可分问题上。目前已有学者将SVM应用到文本分类领域,并取得了一定的进展,但识别准确率与文本判定的召回率往往无法兼顾。本文针对这个问题,将多项式核函数与径向基核函数进行组合,以期提高文本主题识别性能。
1 SVM原理
SVM是由Vapnik 等人在1996 年提出的基于结构风险最小化原理的一种机器学习方法。基本思想是寻找一个最优分离超平面,把两类样本正确分开,使错误概率最小,分类间隔最大[4]。
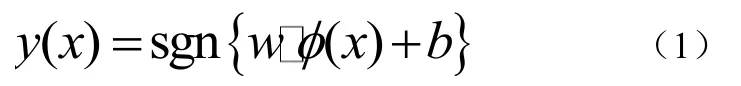
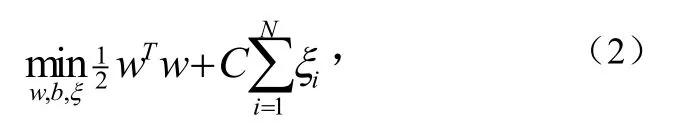
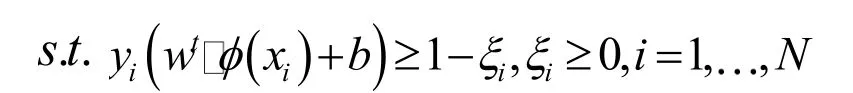
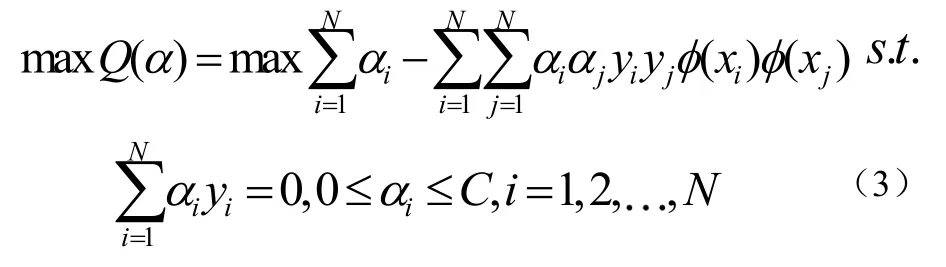

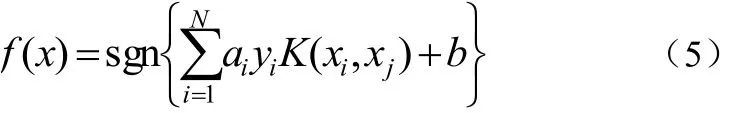
在文本识别的实际应用中,大量文本之间总有交界甚至彼此掺杂,使其无法线性表述,核函数的引入可以使高维空间的内积运算转化为原空间一个内积核函数的计算[6],在不增加算法复杂度的同时实现了非线性算法,这就是SVM。
2 SVM核函数
2.1 常用核函数
在SVM中,常见的核函数有以下4种。
①线性内积核函数如公式(6):
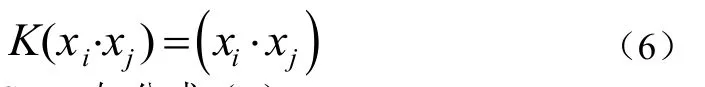
②多项式核SVM如公式(7):
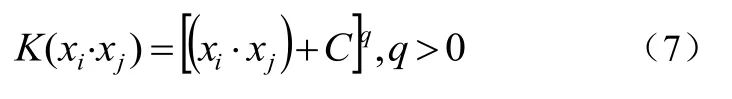
③径向基核SVM如公式(8):
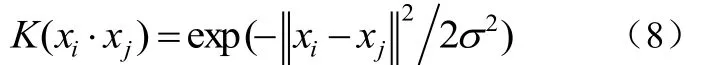
④两层神经网络SVM(Sigmoid核)如公式(9):
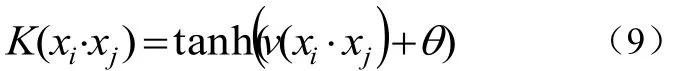
2.2 局部核函数和全局核函数
不同类型的核函数表现出不同的特性,根据核函数的特性不同,常分为局部性核函数和全局性核函数。其中多项式核函数具有良好的全局性质,而径向基核函数是局部性很强的核函数[6]。
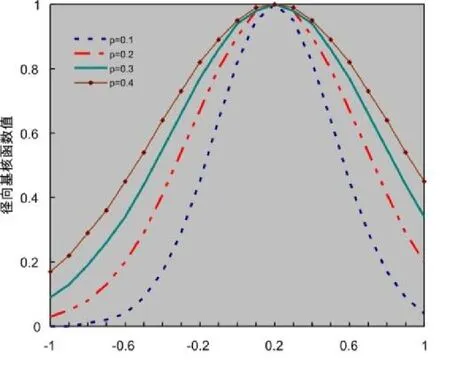
图1 径向基核函数特征曲线图
由图1可知,在测试点附近,核函数值较大,当距离较远时,核函数值显著下降,而且当2越小时,核函数值下降的速度越快,局部性越强,泛化能力越弱。
根据多项式核函数的表达式,当q分别取1,2,3,4,测试点取0.2时,可得到多项式核函数特征曲线图,如图2所示:
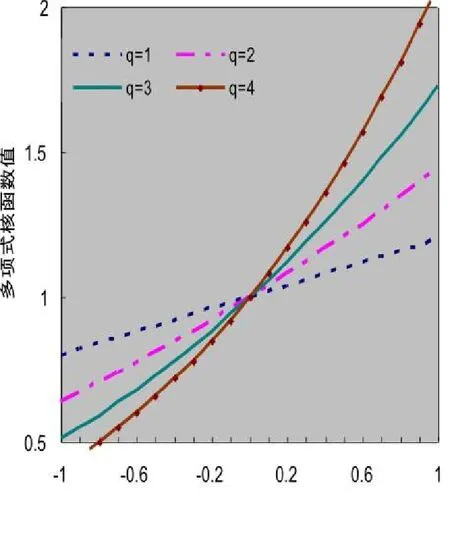
图2 多项式核函数特征曲线图
由图2可知在输入数据与测试数据距离不断加大的情况下,多项式核函数值变化不大,而且对于离测试点较远的数据仍然有较强的影响,具有很强的泛化能力。
综合以上分析可得,全局性核函数作用范围比较广,甚至对整个数据点都有影响,泛化能力较强,但局部学习能力较弱。而局部性核函数作用范围较小,仅对测试点周围的数据有作用,学习能力较强,泛化性能较弱。
2.3 组合核函数构建
核函数的选择对SVM的识别性能有重要的影响,因为不同的核函数具有不同的特性,使其在解决具体问题时表现差别很大。目前,关于单核的构造、改进及其参数优化的研究较多,但采用单核SVM的识别效果并不理想。由上可知,全局核函数泛化能力较强,而局部核函数学习能力较强。因此,可以将这两种核函数进行组合,充分发挥它们各自的优点,使组合核函数兼具良好泛化能力与良好学习能力,以提高识别性能。
2.3.1 组合核函数形式
根据核函数的构成条件,两个核函数之和仍然满足Mercer条件,因此这里对多项式核函数和径向基核函数进行线性组合,即公式(10):
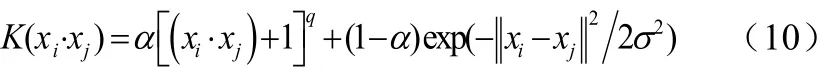
2.3.2 组合核函数SVM参数优化方法
构造的组合核函数中共有惩罚因σ子C、多项式核α函数的幂指数q、径向基核函数的宽度系数、及比例系数四个参数。关于SVM最优参数选取, 常用的方法网格搜索法,此方法可以同时搜索多个参数值,但当参数较多时,训练时间较长。主要思路是首先选取合适的搜索范围,然后确定搜索的步长,以固定的步长沿着各个参数方向生成网格,网格中的节点就是初始给定范围内的所有可能的参数组合。多重网格搜索法从上一次网格寻优确定的最优点开始,再次进行网格寻优,减小搜索步长,以此类推。综合考虑参数优选的准确度与训练时间,这里采用二次网格搜索法确定组合核函数参数。
3 组合核函数SVM在文本主题识别中的应用
3.1 基于SVM的文本信息过滤的流程
基于SVM的文本信息过滤过程共分为两个阶段,即训练阶段和分类阶段。由于多数Web网页中包含广告、注释、HTML标签及版权声明等与内容无关的信息,为了方便后续处理,需将这些无关信息去除,这个过程就是预处理。在训练阶段,对经过预处理后的训练样本集中的文本进行分词处理,将结果存入特征库,根据特征库中的分词结果进行特征提取,通过统计出每个特征项出现的次数计算出特征权重,并表示成向量形式,在此基础上训练SVM分类器。在分类阶段,对待测样本进行预处理、分词处理后,根据生成的文本特征库对分词结果进行特征提取,计算出特征权值,并表示成向量,再运用SVM进行分类,判定待测样本的类别,具体流程如图3所示:
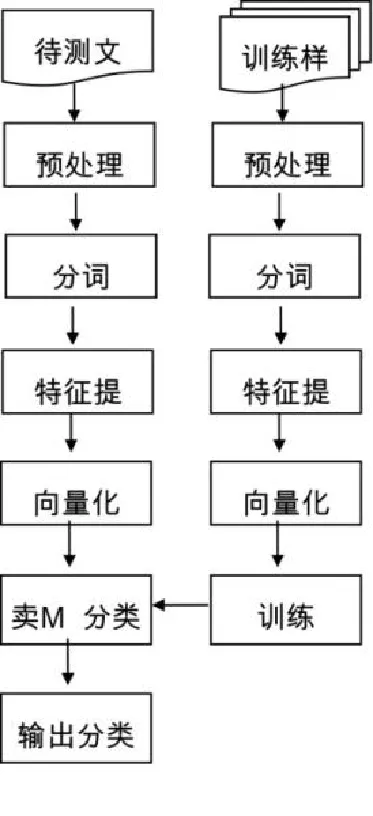
图3 基于SVMMD文本信息过滤过程
3.2 实验分析
3.2.1 数据来源与实验方法
为了验证本文算法的有效性,本文分别对传统的线性核函数、多项式核函数、径向基核函数和新提出的组合核函数进行了测试对比。
本文采用复旦大学计算机信息与技术系国际数据库中心自然语言处理小组提供的文本分类语料库。该预料库共收集了19637篇文本,测试预料有9833篇,训练语料有9804篇,均分20类。在本实验中,抽取其中最大的8类,训练数据在训练语料库的Economy、Computer、Environment、Sports 4类中每类随机抽取1000篇,在Politics、Agriculture、Art、space 4类中每类随机抽取500篇,共6000篇文本。测试数据在测试预料库中随机抽取,前面4类每类抽取300篇,后面4类中每类抽取150篇,共1800篇。实验采用多分类的一对多算法,再将8类文本的识别结果取平均值,并在此基础上采取多次实验再次平均,以保证实验结果的客观性。
实验使用词根萃取与停用词过滤的方法去除冗余特征,采用由中科院计算所开发的汉语词法分析系统进行分词,用两步特征选择方法得出特征集,用TFIDF函数计算训练文本集中文本的特征项权值,并表示成向量模式。
3.2.2 最优参数确定
对于组合核函数,根据选定的二次网格搜索法,第一次搜索C、、、q的范围分别是[1,500],[0,20],[0, 1],[1,20],步长分别是10,0.5,0.1,1,得到的最优参数为C=100,、、。在此基础上进行二次优选,C、、、q的范围分别是[80,140],[0,2],[0, 0.3],[1,10],步长分别是1,0. 05,0.01,1,得到的最优参数为C=125,、、q=3。便于比较实验结果,需确定单核核函数参数,这里采用一次网格搜索法,确定如下最优参数:线性核参数C=128,多项式核参数q=3,C=2,径向基核函数参数,C=2。
3.2.3 性能评价指标
评价标准采用Recall(查全率)、precision(准确率)以及F-value(标准测度),其中F-value是Recall、Precision两个评价指标的综合,见公式(11):

3.3 实验结果与对比分析
在仿真实验评估了线性核、多项式核、径向基核以及本文提出的组合核函数,选择不同的参数值进行实验,以对比网格优选的参数及其它参数组合对文本识别性能的差异,实验结果图表1所示:
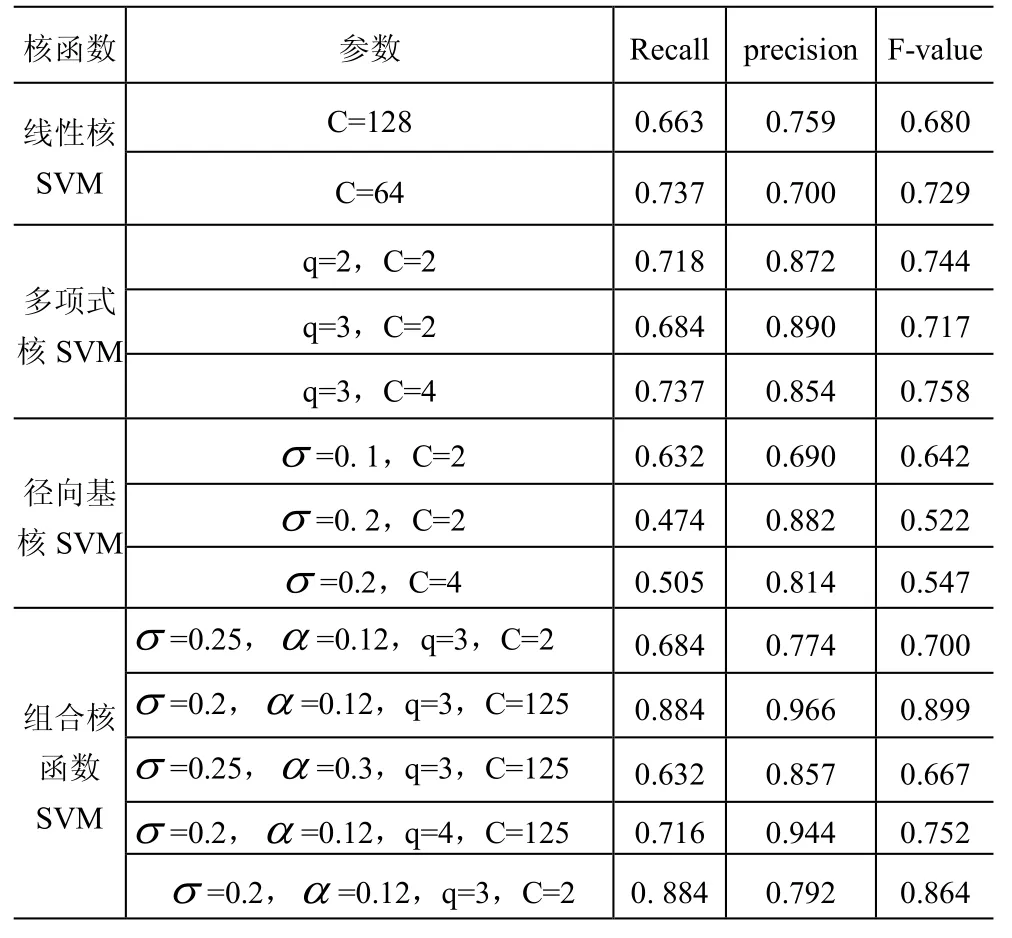
表1 不同SVM核函数识别效果
从线性核、多项式核和径向基核函数SVM的实验数据来看,准确率和召回率是成反比的,准确率越高,召回率则越低。结果显示三者识别准确率较高,但召回率相对较低。这是由SVM本身的特点所决定的,因为SVM是以结构风险最小化原则为理论基础的一种算法,目标就是保证识别准确率,从而无形中影响召回率。
在3个单核函数线性核、多项式核和径向基核构建的SVM中,在选择最优参数情况下,识别准确率分别为75.9%,89%和88.2%。线性核的识别性能最差,其它两个准确率相差不多。同时它们的准确率都明显高于其它的非最优的参数组合,而且多项式核函数由于参数变化引起的准确率变化最小,径向基核函数的变化最大,这是由于多项式核函数是全局核函数,有很好的泛化能力,而径向基核函数是局部核函数,泛化能力差。
在组合核函数中应用每个单核选出的最优参数构建的SVM,准确率仅为77.4%,甚至低于两个单核的准确率。在最优参数的基础上,分别改变,q和C的值,得到的结果也都不理想,这些都说明如果参数选择不准确,组合核函数SVM也无法得出理想的结果。若选择的参数正确,组合核函数SVM的准确率为96.6%,查全率为88.4%,标准测度为89.9%,三个性能评价指标均达到最佳。这是由于组合核函数兼顾了径向基核函数较强的学习能力与多项式核函数较强的推广能力,兼顾了文本分类的准确率和召回率。实验结果说明以二次选优的网格搜索法确定的参数构建的组合核函数SVM确实能够很好地进行拟合,能够以较理想的性能实现文本识别。
4 总结
应用SVM进行文本主题识别时,选择适合的核函数是最为关键的问题。本文基于单核函数的特点,依据Mercer规则对多项式核函数与径向基核函数进行线性加权,构建具有良好的泛化能力与良好的学习能力的组合核函数。在文本识别的仿真实验中,组合核函数表现出明显优于其它单核SVM的良好性能。但语料库的质量直接影响分类性能,如何减少分类的准确率对测试文本的依赖性是今后要探索的问题。
参考文献
[1] Sergios Theodoridis,Konstantinos Koutroumbas 著,李晶皎等译.模式识别.3rd ed.[M]北京:电子工业出版社,2006:45-48.
[2] 吕洪艳,杜娟.基于SVM的不良文本信息识别. [J]计算机系统应用,2015,24(6):183.
[3] 高会生,郭爱玲. 组合核函数SVM在网络安全风险评估中的应用. [J]微计算机工程与应用,2009,45(11): 123-124.
[4] 张冰,孔锐.一种支持向量机的组合核函数. [J]计算机应用,2007,27(1):44-45.
[5] 叶志刚. SVM在文本分类中的应用.[D].哈尔滨:哈尔滨工程大学,2006.
[6] 刘志刚,杜娟,衣治安.一种改进的分类算法在不良信息过滤中的应用. [J]2011,32(2),11-12.
Text Topic Recognition Based on Combination Kernel Function of SVM
Lv Hongyan, Liu Fang
(Institute of Computer and Information Technology, Northeast Petroleum University, Daqing 163318 , China)
Abstract:In practical application of text information identification, most of the text always doped with each other, so that they are unable to linear expression. The nonlinear non-separable problem can be solved effectively by SVM. And the key of the SVM is to choose the appropriate kernel function. As the recognition accuracy rate of a single kernel function is not high and the recall value is not ideal, for the specific application of text topic identification, combining w ith homogeneous polynom ial kernel and radial basis kernel function by linear weighted method, it structured a new combination kernel function w ith the advantage of both homogeneous polynomial kernel and radial basis kernel function. That is the combination kernel function which has the generalization ability of global kernel function and the learning ability of local kernel function. And it determ ines the optimal parameters through the grid search method. Then it evaluates the linear kernel, homogeneous polynom ial kernel, radial basis kernel function and combination kernel function in the sample experiment. The experimental results show that the recognition accuracy rate and the recall value of combination kernel function of SVM are more ideal than other kernel functions.
Key words:SVM; Combination Kernel Function; Text Identification; Recall; Text Topic
中图分类号:TP311
文献标志码:A
作者简介:吕洪艳(1982-),女,五常市,东北石油大学,计算机与信息技术学院,讲师,研究方向:人工智能与模式识别,大庆,163318 刘 芳(1983-),女,伊春市,东北石油大学,计算机与信息技术学院,讲师,研究方向:人工智能与模式识别,大庆,163318
收稿日期:(2015.11.03)
