基于新生儿疾病筛查信息系统设计与实现
2016-07-07张磊
张磊
基于新生儿疾病筛查信息系统设计与实现
张磊
摘 要:随着我国新生儿疾病筛查信息管理工作的发展,已取得了一些进展,但是仍存在大量手工输入带来的数据不准确性。筛查中心的分散性带来数据服务的异构性和信息共享的不及时性,网络环境下还存在的数据安全性等现状。对此设计了一个B/S架构的新生儿疾病筛查系统,通过web协议进行数据的传输与用户的透明操作,并进行了原型系统的开发实现,满足了新生儿疾病筛查信息化的准确性、及时性与安全性的需求。
关键词:新生儿疾病筛查;B/S架构设计;医疗信息化
0 引言
新生儿疾病筛查是指在新生儿期对某些危害严重的先天性疾病、遗传疾病进行群体普查,早期诊断、早期治疗,以避免发生不可逆的体格和智能发育障碍[1]。随着我国新生儿疾病筛查信息化管理工作的开展,已取得了一些成就:丰晓霞等[2]提出了健康管理模式是完善新生儿疾病筛查工作流程,明确部门的职责和评价标准,提高新生儿疾病筛查率的保证;秦成君[3]提出通过建立新生儿筛查信息平台,有效地提高新生儿疾病的工作效率与质量,是管理新生儿疾病筛查的重要手段;朱文斌[4]提出使用B/S结构的新生儿疾病筛查信息管理系统的设计方法,有利于各医疗机构信息共享,行政管理部门的指导与监督。但是依然存在以下不足:一是新生儿疾病筛查信息主要依靠人工录入,无法避免录入错误带来的数据不准确性,重复录入工作给相关部门带来额外的负担,影响到后继可疑阳性新生儿的召回工作;二是新生儿筛查数据是分别存储在各分中心的服务器上,一般需要人工对相关数据进行上传,难以实现数据更新的及时性[5],此外各分中心使用不同的软件系统,由于相关工作开展的程度不同,不同系统关注的数据兴趣点也有很大的不同,对数据结构的理解不同造成了数据的异构性,形成了信息孤岛现象,难以实现数据的有效集成与共享[6];三是新生儿可疑阳性召回的信息管理工作,仍处于人工管理阶段,筛查通知工作仍需要消费大量的人力与物力;四是新生儿疾病筛查工作需要与不同医疗机构进行信息的交流,数据需要在互联网环境中传输,提高数据的安全性,为病人隐私提供保证,是新生儿疾病筛查工作需要考虑的因素。对此,本文设计了一个B/S架构的新生儿疾病筛查信息系统,并进行了原型系统开发实现。该架构属于一种松散的web架构模式,通过统一的web协议进行相关医疗数据的封装与传输,数据的操作对于用户来说是透明的,对于新生儿疾病筛查工作信息化的及时性、准确性与安全性,都具有十分重要的意义。
1 系统的设计
1.1 系统总体架构
系统采取3层B/S架构进行设计,包括数据层、服务层和应用层。
其中,数据层包括:一是HIS基础数据库,存储病人编号、年龄、医疗机构、出生日期、家庭住址等;二是筛查信息库、存储病人编号、检验时间、收到时间和检验结果等;三是其它库存储可疑阳性、确诊阳性等其它一些补充信息。
服务层包括:一是数据源,数据源提供了数据库连接池的配置,包括不同数据库的连接方式与连接数等,通过数据库连接池的方式,可以提高数据连接的效率;二是数据事务,数据事务是用户并行操作时对数据隔离级别的一种限定,在运行异常时能及时进行事务的回滚,有益于增强数据的安全性;三是数据映射模式,系统采取对象关系映射模式,可以屏蔽数据查询逻辑,简化数据对象的保存与删除流程,此外针对医院报表具备大量复杂查询的特点,系统设计了查询映射的模式,通过数据库查询语句能更灵活地应用数据库的特殊性能,进行灵活的数据查询与统计;四是数据持久化对象,通过映射关系将数据进行封装,屏蔽了数据表结构,数据字段等底层数据结构信息;五是Web服务器,通过使用Web协议进行数据的转发与分发,用户通过浏览器就可以很方便地进行数据业务的操作,服务层屏蔽了底层的数据物理存储逻辑,透明了用户的数据操作方式。
应用层包括:筛查信息系统、查询信息系统和统计分析系统等,提供了新生儿疾病筛查结果的入库操作,相关报表的生成与打印,后期的统计与查询等相关业务操作。系统总体设计如图1所示:
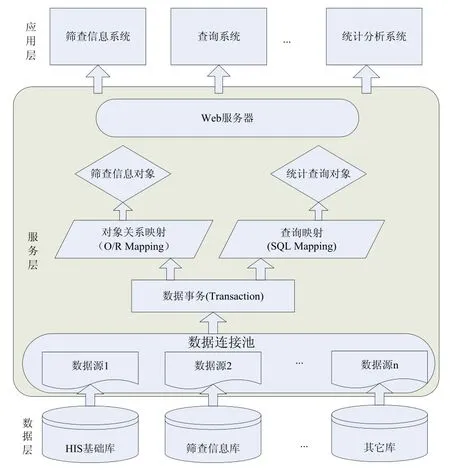
图1 系统总体架构图
1.2 系统功能模块
新生儿疾病筛查系统包括:数据录入模块、查询统计模块和报表生成模块等,如图2所示:
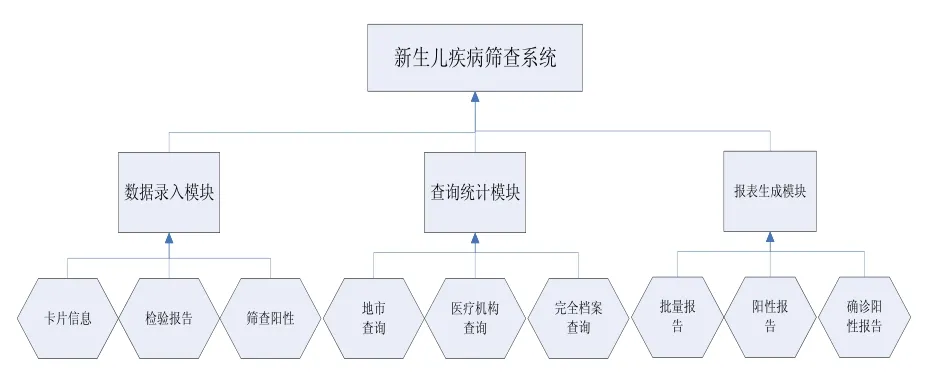
图2 系统功能模块
其中,数据录入模块是对新生儿筛查信息进行采集与入库工作。卡片信息是对病人基本信息的采集,包括标本号、医疗机构编号、母亲姓名、孕周、婴儿性别、出生日期、采血时间、标本收到时间、apgar、电话等;检验报告包括:促甲状腺TSH、苯丙氨酸PHE等检验结果值;筛查阳性信息包括:筛查可疑阳性、筛查阳性和确诊数等。在信息采集工作中,还需要对标本信息进行审核,对不合格标本进行记录;入库工作主要采取人工录入和电子表格模板导入方式,方便了不同系统平台间进行数据的对接。
查询统计模块包括:一是地市查询和医疗机构查询,是对各分中心标本数、合格标本数及筛查可疑性阳性和确诊数等工作量的查询与统计,有按出生日期查询和按标本收到日期查询两种查询方式;二是完全档案查询,是对卡片信息和筛查结果进行完全查询,查询方式有按医疗机构编号查询,按母亲姓名模糊查询和按出生日期查询。
报表生成模块包括:一是批量报告,主要是按流水号提供新生儿筛查结果检验报告单批量显示与打印功能;还提供了初检回报表,包括新生儿筛查性别统计,筛查总数统计,采血时间或出报告时间小于72小时,72小时到7天,大于7天的统计等;二是阳性报告,提供了新生儿可疑性阳性召回通知单、确诊阳性报告的显示与打印功能,并通过Itext生成PDF格式报表,提供了根据病人生日查询号与标本号在互联网上查询病人的检验结果的功能。
1.3 数据库的设计
系统数据包括:用户表(user),用来记录用户登录的帐号和密码;医疗机构字典表(dept),用来记录各医疗机构的编号和名称;基础信息表(info),用来记录新生儿的性别、出生日期、母亲姓名、电话、地址等卡片信息;检验结果表(tshphe),用来记录促甲状腺值,苯丙氨酸值phe,出报告日期等检验结果;筛查阳性表(positive),用来记录可疑阳性,阳性和确诊数等统计记录。字段设计如图3所示:
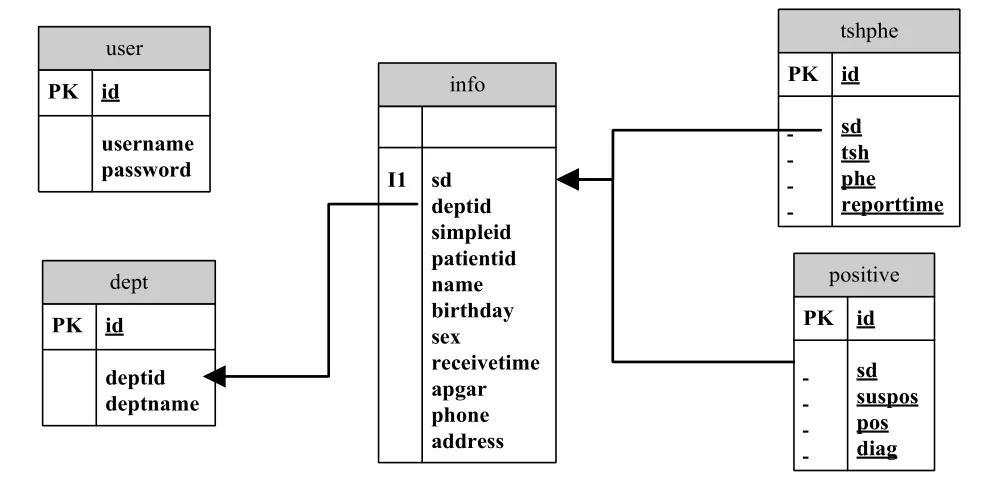
图3 数据表字段设计
其中,检验结果表和筛查阳性表中的流水号字段(sd)外键关联于基础信息表中的流水号字段(sd);基础信息表中的部门编号字段(deptid)外键关联于部门表中的部门编号字段;
出于安全性的考虑,用户表中的密码字段(password)进行加密后存储在数据库中。
2 系统的实现
2.1 开发技术与数据条件
软件系统采取Java语言进行编程,采取Struts2+Hibernate+Spring+SpringJDBC架构模式进行开发,系统运行在Windows 2003和Apache Tomcat6.0服务器下,采用mysql5.0数据库进行数据存储,其数据调用方式,如图4所示:
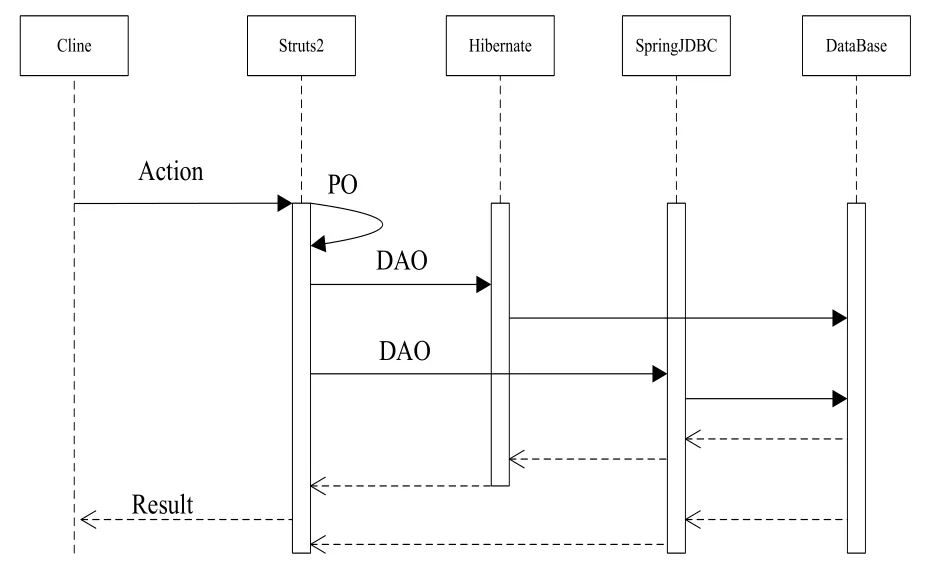
图4 数据流时序图
客户端请求一个Action视图,然后在Struts2中创建一个持久化对象PO,该对象通过调用Hibernate或SpringJDBC的数据访问对象DAO模板类HibernateTemplate或JDBCT emplate,进行数据库的操作,该模板类是由Spring架构提供,可以防止数据查询溢出,很好地保证了数据的安全性。
其中,Struts2通过自身的过滤器就能很方便进行各种请求的拦截并进行相关业务逻辑的处理工作,进行网页视图的分发与转发。Hibernate属于一种对象关系映射,即将纯关系数据库字段及其操作,映射成PO对象,简化了数据库的操作。SpringJDBC属于一种SQL对象映射[7],将关系数据库字段映射成PO对象,依然通过SQL操作数据库,可以灵活利用数据库的特性,这种设计满足了医疗机构对数据报表的要求较高,对数据查询有众多特殊的要求。Spring 是管理各业务对象的容器,基于约定优于配置的思想,提高了开发的效率,优化系统整体的架构模式。
2.2 系统功能实现
系统提供了筛查数据的录入、数据统计与分析、报表的生成等功能,如图5所示:
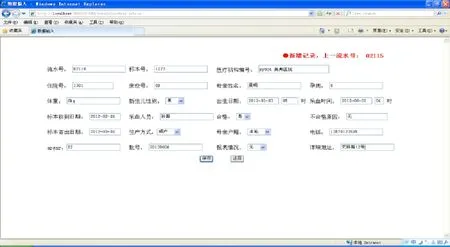
图5 数据录入功能
该模块提供了基础数据的提取、录入功能。提供上一流水号的显示功能,对于重复的流水号,提醒是否覆盖功能;对于医疗机构编号,采取A jax实时取得相关的医疗机构列表进行选择,如图6所示:
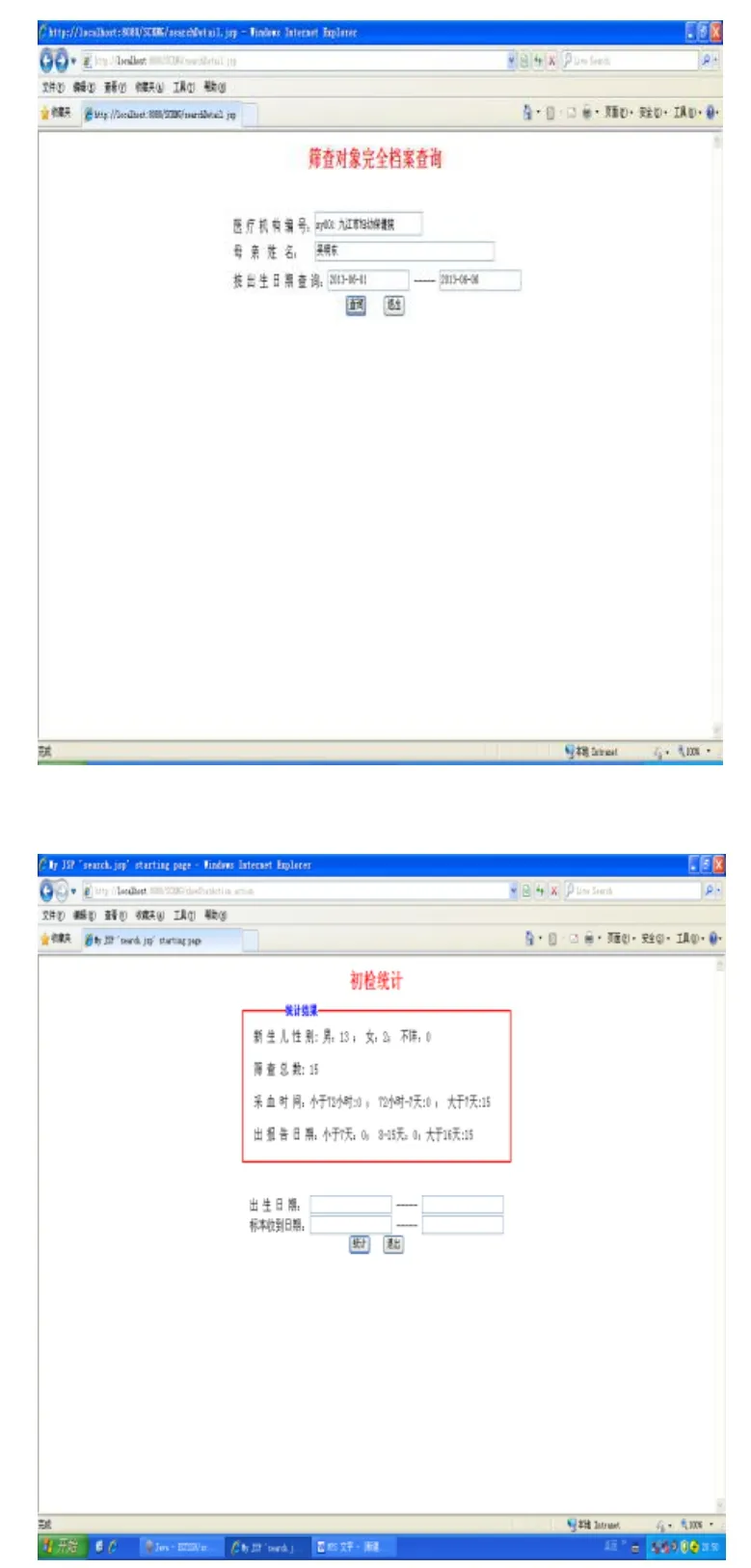
图6 数据查询统计功能
数据查询与统计模块,对于部份病人,提供了医疗机构名称、母亲姓名和出生日期就可以查询到相关病人的筛查详细记录,母亲姓名支持模糊查询的功能;提供了初检统计,包括新生儿性别统计、筛查总数统计和按采血时间与出报告时间进行统计,如图7所示:

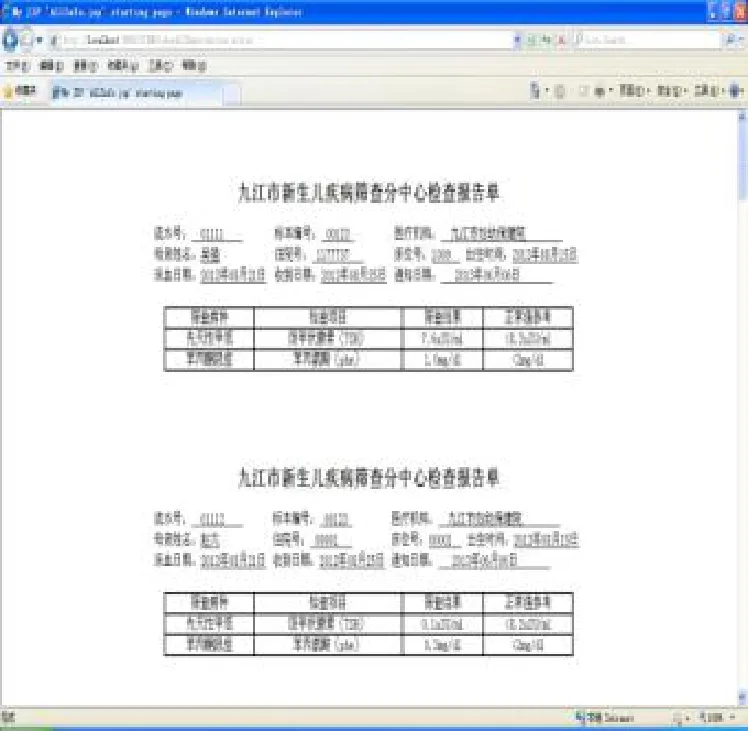
图7 数据报表功能
系统提供了新生儿筛查工作统计报表及新生儿疾病筛查报告单的生成与打印功能,根据出生日期或标本收到日期进行相关工作量的统计;提供了各医疗机构标本数、合格数、不合格数、筛查可疑性阳性、筛查阳性与确诊数等功能;提供了新生儿疾病筛查报告单的生成,包括先天性甲低与苯丙酮尿症筛查值与正常值对照单。
4 总结
从2012年投入运行至今,系统满足了新生儿疾病筛查工作实时性与准确性的要求,网络的查询报告功能已于今年年底实现。目前,一些基础信息依然采取手工录入方式,可以通过相关软件接口的对接提供数据信息的导入,简化筛查工作的流程,提高工作效率。此外,还将进一步提高网站访问性能,提高数据的安全性与查询统计的效率[8],下一步工作可以尝试使用Spring Security架构进行安全模块设计。
参考文献
[1] 苏晞,马丽明,刘海平等. 新生儿筛查信息管理的缺陷与解决方案[J]. 中国妇幼保建,2008(23).
[2] 丰晓霞,田宇等. 实行健康教育网络管理模式对提高新生儿疾病筛查率的作用研究[J]. 医院管理,2009(33).
[3] 秦成君. 应用信息平台管理新生儿疾病筛查[J]. 中国妇幼卫生杂志,2013(1).
[4] 朱文斌. B/S结构新生儿疾病筛查信息管理系统的设计与实现[J]. 中国妇幼卫生杂志,2007(22).
[5] 辛旭武,李韶斌. 基于PHP的体检网站设计[J]. 中国卫生信息管理,2012(2).
[6] 应桂英,陈文等. 四川省卫生统计数据采集与决策支持系统设计与实现[J]. 中国卫生信息管理,2012(1).
[7] 胡启敏,薛锦云,钟林辉. 基于Spring框架的轻量级J2EE架构与应用[J].计算机工程与应用,2008(5).
[8] 曹挚,攀晓玲,孙明. 我区医院医疗费用数据采集的设计与实现[J]. 中国卫生信息管理杂志,2011(8).
Design and Imp lementation of Newborn Disease Screening Information System
Zhang Lei
(Jiujiang Maternity and Child Care Hospital, Jiujiang 332000, China)
Abstract:With the development of newborn disease screening information management in our country, some progress has been made, but there are still a lot of manual input data inaccuracy. The dispersion of screening center results in the heterogeneous data service and the delayed sharing of information, and the data security situation under the network environment still exist, withal this paper designs a B/S architecture newborn disease screening system. It uses the network protocol to realize the data transmission and user transparent operation, and makes the development of prototype system to meet the accuracy, timeliness and safety requirements of the neonatal disease screening Informatization.
Key words:Neonatal Screening; B/S Architecture Design; Medical Informatization
中图分类号:TP311
文献标志码:A
文章编号:1007-757X(2016)05-0061-04
作者简介:张磊(1983-),男,九江市妇幼保健院,硕士,软件设计师,研究方向:Web数据服务,九江,332000
收稿日期:(2016.01.19)
