基于Mahout框架的协同过滤视频推荐算法
2016-07-05钟前建崔怀林贾西平
钟前建,崔怀林,贾西平
(广东技术师范学院 计算机科学学院,广东 广州 510665)
基于Mahout框架的协同过滤视频推荐算法
钟前建,崔怀林,贾西平
(广东技术师范学院 计算机科学学院,广东 广州 510665)
视频推荐技术能帮助用户快速找到其感兴趣的视频,是社交网络服务中研究的重点.针对传统协同过滤推荐算法User-Based和Item-Based存在的数据稀疏和扩展性不佳的问题,提出一种基于Mahout框架的视频推荐算法CF_PIU,通过结合User-Based和Item-Based的基本思想,采用一种计算用户之间相似度的新方法,并通过收缩相关系数优化用户之间的相似度. 实验结果表明,CF_PIU算法在视频推荐质量方面优于UserCF等视频推荐算法.
Mahout框架;视频推荐;协同过滤
0 引言
推荐系统作为一种缓解大数据环境下信息超载问题的重要方法,受到了学术界及工业界的普遍关注[1].视频推荐是推荐系统的一项重要应用,能从海量视频信息中智能搜索用户感兴趣内容,同时能够挖掘出用户本身潜在的兴趣,减少用户搜索和选择的时间[2,3].毫无疑问,面对海量视频数据,高效的个性化视频推荐技术显得尤为重要,然而,目前大数据环境下视频推荐系统的研究尚处于起步阶段[4],相关的理论和技术还不够完善.
为了提高推荐性能,文献[5]提出一种基于概率的最近邻算法,通过对近邻(相似用户)添加不同权重来提高推荐的多样性,但该算法不能同时提高推荐的准确率与多样性.文献[6]提出了一种基于主成分分析(PCA)和奇异值分解(SVD)的协同过滤算法,通过 SVD对打分矩阵实行分解,在低维的矩阵中度量用户间的相似性,找出近邻并对其填充缺失的打分值.文献[7]采用了一种不确定近邻因子的协同过滤算法,通过自适应选取符合预测目标的近邻当作推荐群,从推荐群中选出信任子群,然后基于推荐群与信任子群,由不确定近邻的方法衡量目标推荐结果.文献[8]提出了一种将项目归类和云模型相融合的协同过滤算法,计算出同类型项目的相似度,查找出目标用户的近邻,进而根据近邻最感兴趣的项目类集合进行推荐,使数据稀疏性得到一定缓解.
尽管协同过滤推荐被认为是当前应用于视频推荐最为有效的技术之一[9],相关领域的研究取得了一定的进展,但仍面临多方面挑战,主要有:(1)数据稀疏;(2)可扩展性不佳;(3)计算复杂度高,空间代价大.
鉴于以上问题与挑战,本文提出一种基于Mahout框架的协同过滤视频推荐算法 CF_PIU,并采用聚类方法提前对用户集数据进行聚类处理.CF_PIU结合了 User-Based和 Item-Based协同过滤算法思想,采用一种计算用户与用户之间相似度的新方法,并通过收缩相关系数对用户间的相似度实行优化.改进后的算法能够有效缓解数据稀疏,减少空间开销,同时能够增强算法的可扩展性.
1 相关技术综述
1.1 聚类分析
聚类方法可以把项目分配到一个组中,使得在同一组中的项目相比于不同组中的项目更加相似,目的是发现存在数据中有意义的组.聚类方法能够最小化组内距离,同时最大化组间距离.
聚类方法主要分为两大类别:划分和分层.划分即把数据划分成非重合的聚类,并确保每个数据项都能在一个聚类中;分层即在已知聚类的基础上再进行聚合项目,形成聚类的嵌套集合,构成一个层级树.
1.2 Mahout框架
Mahout是Apache基金组织赞助的一个开源项目[10],实现了许多关于机器学习领域的经典算法,包括协同过滤算法、分类和聚类等,是当前较为完整的算法库,具有高扩展性并支持Hadoop分布式数据处理[11].它整合了推荐引擎“Taste”以生成个性化的推荐.Taste的抽取模块易于应用的定制,并提供了相应的扩展接口,方便开发者编写实现自己的算法.抽取模块主要定 义 了 DataModel、UserSimilarity、ItemSimilarity、UserNeighborhood以及Recommender等接口,其设计注重灵活性、性能和可扩展性,如图 1所示.

图1 Mahout推荐模块组件图
1.3 基于用户的协同过滤算法
基于用户的协同过滤算法(User-Based Collaborative Filter,UBCF)主要通过用户间的相似度计算,查找目标用户的K个最近邻(相似用户),并由这K个最近邻相关的打分信息给目标用户尚未打分的项目实行打分预测,然后产生推荐[12],简而言之就是用户 a对尚未打分的项目 i的打分Ra,i可由 K个最近邻对已打分的项目i实行打分加权逼近得到,因此UBCF算法的关键是搜索最近邻,而度量用户间的相似度是重要步骤之一.
K-最近邻搜索是为目标用户 a在整个 “用户-项目”打分矩阵上搜索与其兴趣爱好最相似的 K个最近邻集合 U'={a1,a2,ak}(a∉U'),并将 a和 U'中的用户 ak(1≤k≤K)间的相似度 sim(a,ak)从大到小排列.sim(a,ak)的取值范围为[-1,1],其越接近 1那么用户 a和ak分别感兴趣项目的相似度就越高;其越接近-1那么用户 a和 ak分别感兴趣的项目是相反的;其为 0则用户 a和ak没有相似感兴趣的项目.
主要的相似性度量方法有皮尔逊相似度、余弦相似度以及欧氏距离[13]:
(1)皮尔逊相似度(Pearson Correlation Coefficient)

其中,m表示用户 a、b共同感兴趣项目的数量;Ra,i、Rb,i表示用户 a、b分别对项目 i的打分;Ra、Rb表示用户a、b各自的打分均值.
由于以上用户间的相似性度量方法只考虑了用户间的相似度,并没考虑项目间的关联,计算相似度时针对的项目仅是用户间都评价过的,当用户打分矩阵极其稀疏时难以计算出用户与用户之间的相似度,导致目标用户最近邻难以被找到.
2 基于 Mahout框架的协同过滤视频推荐
针对传统协同过滤视频推荐算法存在的数据稀疏、扩展性不佳以及用户相似度未考虑项目间关联而造成的相似用户搜索失败等问题,本文提出一种基于Mahout框架的协同过滤视频推荐算法CF_PIU.推荐过程如图2所示.
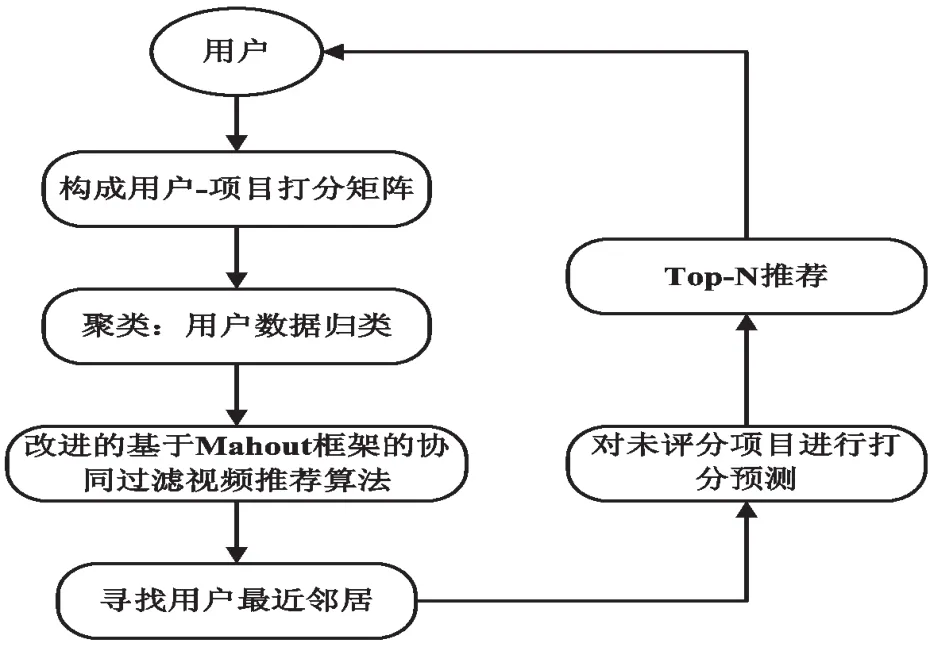
图2 基于 Mahout框架的协同过滤视频推荐过程
2.1 用户聚类
使用 K-means算法,对用户集数据进行聚类处理,通过设定阈值并计算用户与用户之间的相似度,将相似度大于一定阈值的用户归为一类,然后采用用户数最多的前k个类别当作原始条件,再由它们求出k个原始的用户聚类中心点,计算完成后再开始新一轮聚类,直到聚类中心处于稳定状态,不再改变.算法描述如下:
(1)输入
用户聚类数 k、打分数据 D=(U,I,S)
(2)输出
聚类中心 Cluster(k,n)、用户-项目打分矩阵 R(m,n)
(3)算法过程
1)对用户数据实行预处理得到 k个用户类别;
2)每个类别挑选出一个对象当作原始聚类的中心点;
3)repeat

重新计算各个用户类簇中心点;
4)until中心点不再改变.
使用聚类的方法对用户集数据进行聚类划分后,得到 k个用户聚类中心点,然后目标用户通过计算与各个中心点的相似度来判断其所属的用户类簇,再从该类簇来查找目标用户的最近邻集,最后根据最近邻集用户的信息对目标用户尚未打分的项目进行分值推测,进而产生推荐.
2.2 一种计算用户相似度的新方法
通过把目标项目与其他项目的相似度融合到基于用户的相似度计算中,既考虑用户与用户之间的相似度,又考虑用户与用户共同感兴趣项目之间的相似度,能有效缓解用户打分矩阵在大数据环境下极其稀疏时传统相似度计算方法难以处理的不足,具体定义如下:
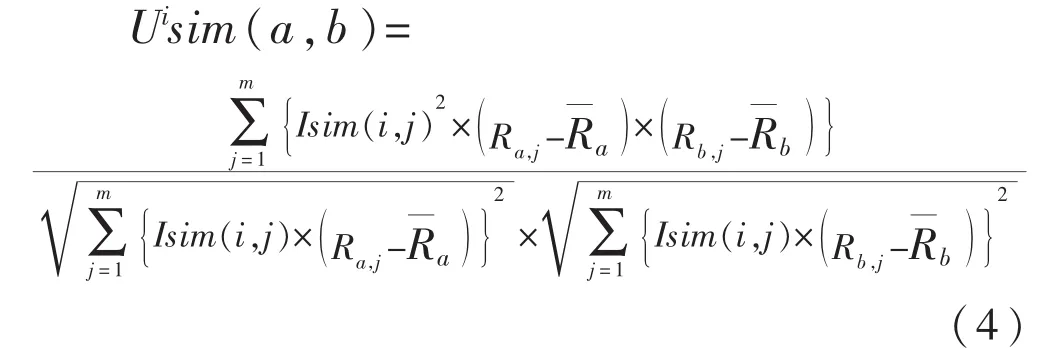
其中,m表示用户 a,b共同感兴趣项目的数量;Uisim(a,b)表示用户 a,b间加入关于项目 i的关联关系后的相似度;Isim(i,j)表示项目 i与 j的相似度,其定义如式(5)所示;Ra,j、Rb,j表示用户 a,b分别对项目 j的打分;Ra、Rb表示用户 a,b各自的打分均值.
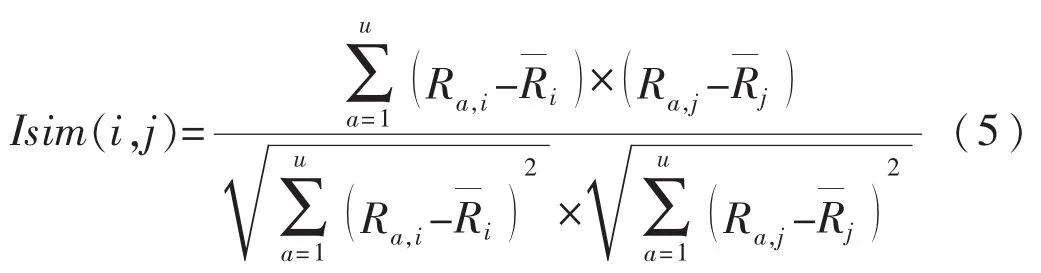
其中,u为对项目 i与 j都感兴趣的用户数量;Ra,i、Ra,j表示用户a分别对项目i与j的打分;表示项目 i、j各自的打分均值.
2.3 采用收缩相关系数对相似度进行优化
如果两个项目的交集大小要远小于其它项目的交集大小,那么这两个项目相似的可能性就比较低.假如由用户与项目间已存在的选择关系在全部可能存在的选择关系中所占有的比例来对系统的数据稀疏性进行权衡,那么推荐系统中关于某些交集呈现出相对偏小的情况是时常发生的,会造成相似度不可靠性的增加,为了预测结果的可靠性,我们根据交集的大小对相似度实行压缩:
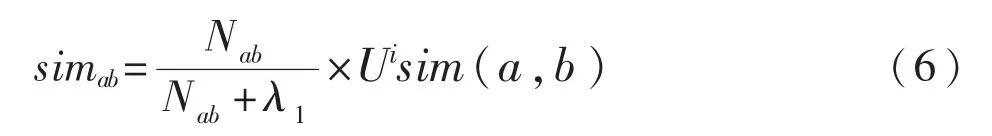
其中,Uisim(a,b)表示用户 a、b间加入关于项目 i的关联关系后的相似度;Nab表示用户a与 b共同感兴趣项目的数量,λ1为输入参数,取值通过交叉验证的方式确定.
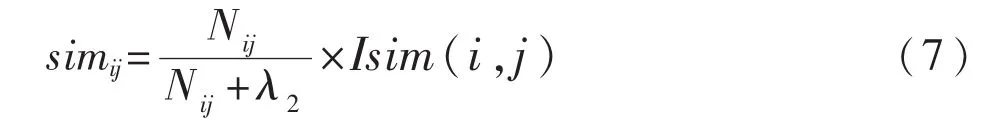
其中,Isim(i,j)表示项目 i与 j的相似度;Nij表示对项目 i与 j都感兴趣的用户数量,λ2为输入参数,取值通过交叉验证的方式确定.
2.4 选择K近邻并产生推荐列表
推荐系统的关键是为目标用户搜索其最近邻集合,并依据这些最近邻的信息实行推荐.在本文算法中,K最近邻的确定是通过将活动用户a的近邻按相似度大小进行排序得到用户集合Na,然后获取训练集中评价过目标项目i的所有用户 Ni,对 Na和 Ni取交集并取相似度最大的前K项得到,若不足 K项则直接取交集.目标用户给尚未打分项目实行打分预测的定义如下:

本文提出的CF_PIU算法描述如下:
(1)输入
1)用户-项目打分矩阵 R(m,n);
2)用户最近邻个数K.
(2)输出
目标用户尚未打分项目的打分、Top-N项目推荐.
(3)算法过程
1)选取 K个相似用户作为目标用户的近邻,在打分矩阵 R中挑选出一个用户 a,并搜索其还没打分项目的集合 I,然后选取其中一个项目 i∈I当作目标项目;
2)根据式(5)计算出目标项目i与其他项目 j的相似度 Isim(i,j),通过式(7)优化后,代入式(4)计算用户 a与 b的相似度 Uisim(a,b),再通过式(6)对用户相似度进行优化;
3)由近邻用户 b给项目 i的打分,通过式(8)计算用户 a给项目 i的预测打分;
4)重复执行 2)-3),计算出目标用户 a所有尚未打分项目的预测打分并按大到小排列,最后给目标用户a实行Top-N项目推荐.
3 实验与结果分析
3.1 实验设计
(1)实验环境:本实验是在Intel(R)Core(TM)2 Duo T6600 2.20GHz处理器,内存为 6G,Windows 8系统下进行的.
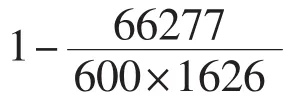
(3)评价标准:使用准确率、召回率、覆盖率和平均流行度等评价方法进行度量,具体定义如下:
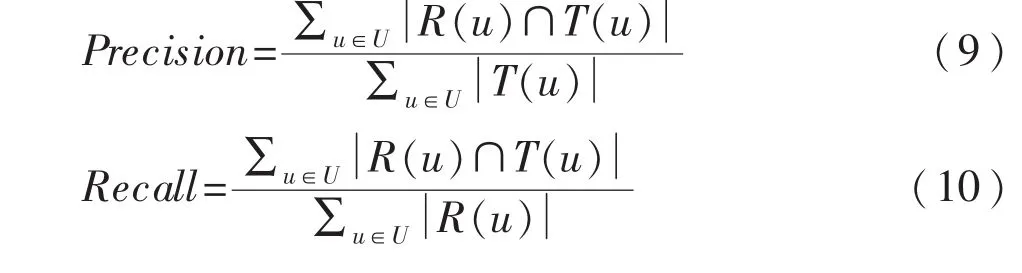
其中,U为用户集合,I为项目集合,R(u)为给用户 u推荐的项目(Top-N项目推荐),T(u)为用户 u在测试集上感兴趣的项目集合,i_p(i)为给项目 i打过分的用户数.准确率、召回率与覆盖率的值越大,平均流行度的值越小,则推荐效果越优.
平均绝对误差(Mean Absolute Error,MAE),主要用来权衡用户打分预测的误差,即用户对项目的真实打分与用户对项目的预计打分间的差值取绝对值再求平均,MAE越小越好,计算公式如下:
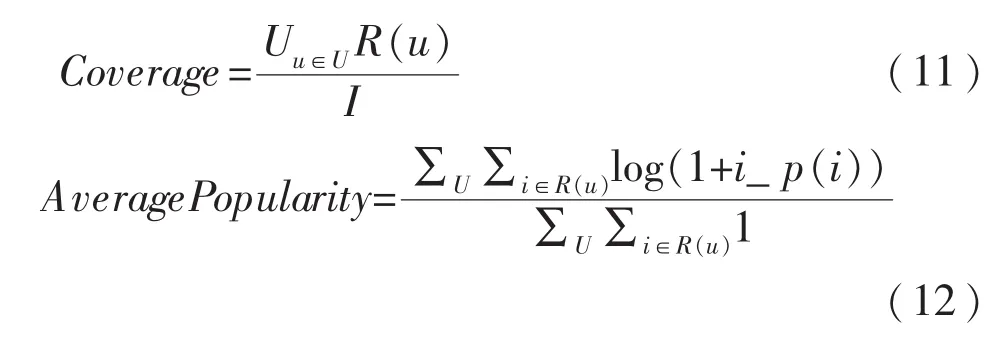

其中,qui表示用户 u给项目 i的真实打分,pui表示用户 u给项目 i的预计打分.
3.2 结果与分析
评价推荐性能时,将本文提出的CF_PIU算法分别与基于余弦相似度的传统协同过滤算法(CB_CF)、基于皮尔逊相似度的传统协同过滤算法(PB_CF)还有文献[14]提出的一种基于粗集的个性化推荐算法(RB_CF)作了比较.实验中,对目标用户的最近邻个数采取以 5递增的方式,从 5增加到 30,使用 MAE作为评测标准,得到如图 3所示的折线图.

图3 CF_PIU算法同其他算法的MAE对比图
使用准确率、召回率、覆盖率和平均流行度等评价标准对本文提出的 CF_PIU算法与传统的基于用户的协同过滤算法(UserCF)作进一步比较,结果如表 1和图 4所示.
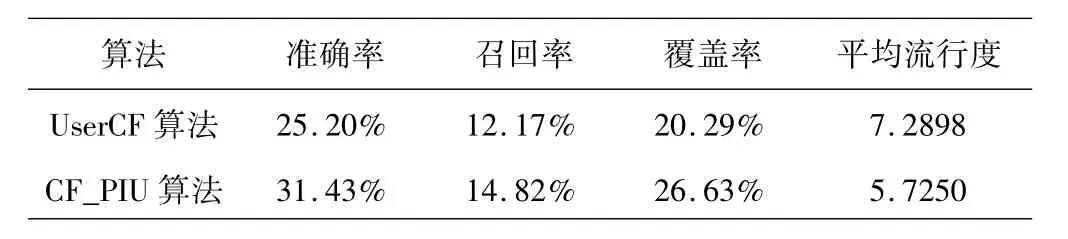
表1 传统UserCF算法与CF_PIU算法的比较
图4 CF_PIU算法与传统UserCF算法精度对比图
由 实 验 结 果 可 见 ,CF_PIU 算 法 分 别 与CB_CF算法、PB_CF算法还有文献[14]提出的RB_CF算法相比,在 MAE方面分别减少了0.31、0.21、0.10;与 UserCF算法相比,在准确率、召回率、覆盖率方面分别提高了 6.23%、2.65%、6.34%, 在平均流行度方面减少了1.5648.
CB_CF算法对目标用户没打分的项目直接采用了填充平均值的方法,但目标用户对其没打分项目的预测打分很少是完全一样的,因此这会造成精度损失;PB_CF算法在用户打分数据极其稀疏时难以度量用户间的相似性,因此目标用户的最近邻难以确定;文献[14]提出的RB_CF算法采用维数简化技术对打分矩阵实行了优化,但随着项目数量的增多,该计算方法复杂度会非常高,降维的效果难以保证,付出的空间代价太大.而本文提出的CF_PIU算法,使用用户聚类的方法对用户数据进行聚类,缩小用户最近邻的搜索范围,把目标项目与其他项目的相似度融合到基于用户的相似度计算中,并采用收缩相关系数对相似度实行优化,找出目标用户的最近邻集,再由最近邻的项目打分信息对目标用户还没打分的项目实行打分预测,填充稀疏的用户打分矩阵,能有效处理打分数据稀疏问题并提升推荐的精度.
4 结语
本文提出一种基于Mahout框架的协同过滤视频推荐算法CF_PIU并采用聚类的方法,提前对用户集数据进行聚类处理,缩小用户最近邻的搜索范围.该算法结合 User-Based和 Item-Based协同过滤算法的思想,通过把目标项目与其他项目的相似度融合到基于用户的相似度计算中,并采用收缩相关系数对相似度实行优化,进而给目标用户尚未打分的项目实行打分预测,填充稀疏的用户打分矩阵,在一定程度上缓解了大数据环境下用户打分数据极其稀疏造成传统相似度算法难以处理,以及计算复杂度高、空间代价大等问题,增强了算法的扩展性.实验结果表明,CF_PIU算法比 UserCF等推荐算法有更优的推荐性能.
[1]Zhao Z D,Shang M S.User-based collaborative-filtering recommendation algorithms on hadoop[C]//Knowledge Discovery and Data Mining,2010.WKDD'10.Third International Conference on.IEEE,2010:478-481.
[2]Deng Z,Sang J,Xu C.Personalized video recommendation based on cross-platform user modeling[C]//Multimedia and Expo (ICME),2013 IEEE International Conference on. IEEE,2013:1-6.
[3]李宁,王子磊,吴刚,等.个性化影片推荐系统中用户模型研究 [J].计算机应用与软件,2010,27(12):51-54.
[4]Ye T,Bickson D,Yan Q.Second workshop on large-scale recommender systems:research and best practice(LSRS 2014)[C]//Proceedings of the 8th ACM Conference on Recommender systems.ACM,2014:385-386.
[5]Garcin F,Faltings B,Donatsch O,et al.Offline and online evaluation of news recommender systems at swissinfo.ch[C]//Proceedings of the 8th ACM Conference on Recommender systems.ACM,2014:169-176.
[6]冷亚军,梁昌勇,陆青,等.基于近邻评分填补的协同过滤推荐算法[J].计算机工程,2012,38(21):56-58.
[7]黄创光,印鉴,汪静,等.不确定近邻的协同过滤推荐算法[J].计算机学报,2010,33(8):1369-1377.
[8]熊忠阳,刘芹,张玉芳.结合项目分类和云模型的协同过滤推荐算法[J].计算机应用研究,2012,29 (10):3660-3664.
[9]Adomavicius G,Kwon Y O.New recommendation techniques for multicriteria rating systems[J].Intelligent Systems,IEEE,2007,22(3):48-55.
[10]Anil R,Dunning T,Friedman E.Mahout in action[M]. Shelter Island:Manning,2011:28-35.
[11]樊哲.Mahout算法解析与案例实战[M].机械工业出版社,2014:2-8.
[12]Ekstrand M D,Riedl J T,Konstan J A.Collaborative filtering recommender systems[J].Foundations and Trends in Human-Computer Interaction,2011,4(2):81-173.
[13]ChenZ,JiangY,ZhaoY.ACollaborativeFiltering Recommendation Algorithm Based on User Interest Change and Trust Evaluation[J].JDCTA,2010,4(9):106-113.
[14]李慧,胡云,李存华.一种新颖的协同推荐算法研究[J].微电子学与计算机,2012,29(003):69-72.
[责任编辑:刘 昱]
Collaborative Filtering Video Recommendation Algorithm Based on Mahout
ZHONG Qianjian,CUI Huailin,JIA Xiping
(Department of Computer Science,Guangdong Polytechnic Normal University,Guangzhou 510665,China)
Video recommendation technology can help users find the interesting videos quickly and has become the key of research on social network services.A new Mahout-based collaborative filtering video recommendation algorithm CF_PIU is proposed to resolve the data sparsity and poor scalability of some traditional algorithms such as User-Based and Item-Based.In CF_PIU,a new method is proposed to denote the similarity between users by combining the basic ideas of User-Based and Item-Based;and the similarity is optimized by using the correlation coefficient.Experiment results show that CF_PIU performs better than traditional video recommendation algorithms as UserCF on quality of recommendation.
Mahout framework;video recommendation;collaborative filtering
TP 391
A
1672-402X(2016)08-0014-06
2016-03-04
国家自然科学青年基金项目(No.61202453);广东省高等学校科技创新项目(No.2013KJCX0117).
钟前建(1990-),男,广东阳江人,系统分析师,广东技术师范学院硕士研究生.专业方向:推荐算法、数据挖掘.
崔怀林(1963-),男,陕西岐山人,工学博士,广东技术师范学院教授.研究方向:智能信号与信息处理、高速数字信号处理系统、信息系统及其应用.
贾西平(1976-),男,陕西蓝田人,工学博士,广东技术师范学院副教授.研究方向:数据挖掘、机器学习、信息检索.
