电力用户用电数据的异常数据审查和分类
2016-07-05沈海涛秦靖雅庄才杰
沈海涛,秦靖雅,陈 浩,范 蓉,庄才杰
(1. 上海东捷建设(集团)有限公司,上海 201210;2. 复旦大学 计算机科学技术学院,上海 201203;3. 网络信息安全审计与监控教育部工程研究中心,上海 200203;4. 上海新能凯博实业有限公司,上海 201210)
电力用户用电数据的异常数据审查和分类
沈海涛1,秦靖雅2,3,陈浩2,3,范蓉1,庄才杰4
(1. 上海东捷建设(集团)有限公司,上海201210;2. 复旦大学 计算机科学技术学院,上海201203;3. 网络信息安全审计与监控教育部工程研究中心,上海200203;4. 上海新能凯博实业有限公司,上海201210)
摘要:在电网的运行过程中,电力自动抄表系统收集的用户用电数据因为受到天气原因,线路故障和系统故障等影响出现偏差和错误。这些偏差和错误是用户用电数据中的异常数据,它们的存在严重影响了电网运行时信息的准确采集和用户用电信息分析。这就要求对用户用电数据进行预处理,在大量的用户用电数据中发现识别出异常数据,进而采用一定的方法对异常数据进行处理和补偿。着眼于自动抄表系统中用户用电数据的数据清理方法研究,对用户用电数据预处理的主要问题进行比较详尽的讨论,提出了用户用电数据预处理的模型和流程方法,采用k近邻法对异常数据进行分类,并利用实际用户用电数据进行实验,得到了初步的成果和经验,对未来智能电网系统中用户用电数据的预处理具有借鉴的作用。
关键词:智能电网;用户用电数据;数据预处理;k近邻法;样条曲线拟合
随着“智能电网”[1]的兴起和普及,其运行过程中遇到的问题和挑战越来越受到人们的重视。在智能电网系统中,要求电网自身能有效地应对可能出现的因为自然因素或突发故障而造成的电力系统失效,并且在提供传统电力服务的同时对于用户的需求能够提供积极和及时的反应。在这种需求条件下,如何利用智能电网收集到各种数据进行决策就成为了一个非常重要的问题。
然而在电网的实际运行过程中,保证用户用电数据收集的准确性和完整性是一件非常困难的事情。受到传感器故障,传输线路故障,自然天气原因和其他复杂因素的影响,用户用电数据会出现不同程度上的数据遗漏和错误。本文将这些用户用电数据称为异常数据(corrupted data)。异常数据的存在严重影响了电网系统中的决策,隐藏了实际可能发生的问题和故障,对指导用电和响应用户需求造成不利影响。
在现实的电网系统中,存在着相当比例的异常数据,但是目前缺乏系统,有效的处理模式和方法。本文采用k近邻法对用户用电数据中的异常数据进行了分类,建立一种具有一定普适性的模型和方法,并分析了异常可能的出现原因,并利用实验对方法模型进行了评估,对智能电网系统中的异常数据分析处理提供了一定的借鉴意义。
1相关工作
1.1数据挖掘领域的异常数据处理方法
在数据挖掘领域,有大量的方法被提出来解决离群点检测的问题。这些方法处理简便,能比较好的分析出待检测序列是否属于“正常的”序列。但是这些方法在本文的工作环境中并不直接适用。本文希望在处理一个很长的时间序列时(用户的用电量序列),识别出异常数据,并加以分析,补偿。
文献[6]研究出了一种在时间序列中发现“异常值”的方法。其方法可以简要概括成几个步骤:①将时间序列分割成等长的片段;②分别计算每两个片段之间的“距离”来找出“距离”最近的邻居片段;③与邻居的距离最大的片段就是异常值。这种方法在处理时间序列中的异常值是有效的,但是在本文的研究问题中缺少时间序列长度的限制,很难确定分割的长度和总时间序列的长度。
1.2用户用电数据预测和分析中的预测和补偿方法
另外一个和研究问题有着紧密联系的领域是用户的用电预测[7]。本文的工作和用电预测的相似性在于利用历史数据或者现有的用电信息,对一些时刻的用电情况进行预测和计算。用电预测往往利用历史数据作为重要参考,通过建立模型或者统计的方法对未来某个时间点的用户用电进行估计。在这个过程中,研究者假定历史数据具有非常高的可信性,即历史数据作为一种“正常的”用电数据来进行处理。而本文所要进行的用户用电的异常数据识别和分析,是不能轻易地将历史数据作为“可信的”或者是“正常的”用电数据。因为在历史数据中也存在着异常数据,这些异常数据在入库时并不一定被识别和补偿修正。如果利用这些数据作为现今用电数据的识别和分析处理基础,有可能使得同样或相似类型的异常数据不能被识别出来,甚至影响对正常用电数据的识别和分析。但是从补偿数据,对某个时间节点的用电数据利用现有信息进行估计的方面来说,用电预测工作对于异常数据识别和分析是有着一定的借鉴作用的。可以将异常数据中的遗漏数据看作是一种未知的用电情况,对这些数据进行处理,就是利用其他现有的用电信息,对其进行估计的过程,正好与用电预测的方法和适用范围有着很大的相似性。
在用电预测中,一种很有代表性的方法是指数的平滑技术[8]。所谓指数平滑技术,是对未来某一时间节点的用电进行估计时,为用于进行估计的时间数据添加不同的权重,通过加权平均来估计出未来时刻的用电情况。
此外,文献[9]通过定义全年趋势和局部趋势,对于负载曲线(load curve)进行了刻画,并在此基础上进行数据的补偿和研究。遗憾的是大部分的实际数据集没有作者采用数据集的完备和准确,导致用电数据的模式界定变得更加困难。文献[10]使用二维小波阈值方法进行噪声处理,方法重点在于去除多余的噪声。但异常数据的出现不完全是噪声,所以这种方法具有局限性。文献[11]提出了融合稳健统计和B样条函数的频率异常数据处理方法,它通过设定阈值辨识尖峰值,采用B样条基函数的线性组合重构原始频率序列,引入曲线粗糙度控制B样条基函数学习过程中存在的过拟合问题.这个方法给用户用电数据预处理提供了借鉴,对于异常数据中尖峰和缺失值的处理是一个很好的参考。
1.3电力一线工作者的异常数据处理经验
电力工作者在智能电网系统运行的实际过程中,积累了大量的第一手的经验。这些经验在理论上来说比较简单,缺乏系统性和严谨性,但是对用户用电数据处理具有一定的指导意义。
文献[12]针对用户信息采集系统中的数据审查问题进行了一定的探讨,提出了包含多个阶段的数据审查策略。对于数据集常见的突变情况利用简单的三天之内电能数值的大小关系和数量关系,判断是否出现了异常的电能突减和电能突增。
在前人的劳动成果基础上,本文主要进行了下面几个方面的工作:
(1)结合了统计数据预处理过程的基本方法和体系,针对自动化抄表系统用电数据的特点,提出了一个用于电力自动化抄表系统用电数据处理的数据处理模型,规范处理的过程和方法;
(2)在进行数据审查阶段的设计时,吸取了电力一线工作者在设计判断逻辑和规则的成果,结合统计学的方法和知识,设计出独立于某个电力信息数据集的规则和方法,使得新的数据审查策略在具有更好的适应性和普适性,同时处理的结果也更为准确;
(3)在异常数据的分类中引入了k近邻法,对数据审查阶段发现的异常数据进行预测分类,再根据异常的分类采取相应的补偿方法,从而提高了异常数据处理的效率和准确性。
2模型建立和异常分类
本文建立的电表数据处理模型由三部分组成:数据审查模块、异常分类模块和数据修正模块。数据审查模块根据设定好的审查原则对数据集进行审查,发现违反审查原则的异常数据。异常分类模块对发现的异常数据运用分类器进行分类,得到异常数据的类型。数据修正模块根据异常数据的类型,采取修正补偿或者标记忽略的处理方法,对异常数据进行处理。
2.1数据审查模块
数据审查模块的核心是审查的规则。本文通过设计合适的审查规则,来发现从正常数据中发现异常数据,为异常分类打好基础。模型中的审查原则有下面几个:
(1)检查数据中时间字段时间的合理性。比如2月份是否出现了三十号。
(2)针对电表读数总电量和峰谷电量,本文设计的审查策略是|总用电量—高峰用电电量-低谷用电电量|<ε,ε的值和数据集自身的性质有关。如果数据集采集过程中误差较大,则ε的值要设置的大一些。在这个实验数据集中,本文采用的ε值是0.3。
(3)针对用户总用电量本文设计了用电量不能为负值的审查策略。数据集中的电表读数是电表自动抄送返回的电量使用累加数值。总用电量通过后一天的数据值减去前一天的数据值作为前一天的用电量。在遇到月份的边界时,读入下一个月的数据记录文件来计算最后一天的用电量。
2.2异常分类模块
通过数据审查模块的处理得到了违反审查原则的异常数据。然而,只是将异常数据识别出来还是不够的,有些异常数据的产生是由于偶然因素造成的,在经过数据修正后仍然可以用于数据分析和数据挖掘工作;而有些异常数据的产生是由于电表或者通信线路的故障产生的,这些数据应该被标记出来用于故障的排查和分析,不能用以数据分析和决策。
通过对数据集的分析,本文将异常数据的类型分成了下面三类:normal,change和complex类型。在这里,为了描述异常数据的特征,本文引入毛刺这个术语。
毛刺指的是电表读数绘制成曲线后出现的向上的尖峰。比如在电表读数序列[1.0,2.0,3.0,6.0,4.0]中,片段[3.3,6.0,4.0]就是一个毛刺。定义发生毛刺周围边界值对应的时间的差值为毛刺的宽度,毛刺宽度等于5-3=2。
异常数据的第一种类型是normal类型。这种异常的特点是用户用电曲线图中的异常以毛刺为主,整体曲线趋势正常,没有出现大幅度下移的情况。对于这种类型的电表来说,可能出现多个毛刺,但是一般宽度都比较少。一个典型的normal类型的用户用电曲线如图1所示。
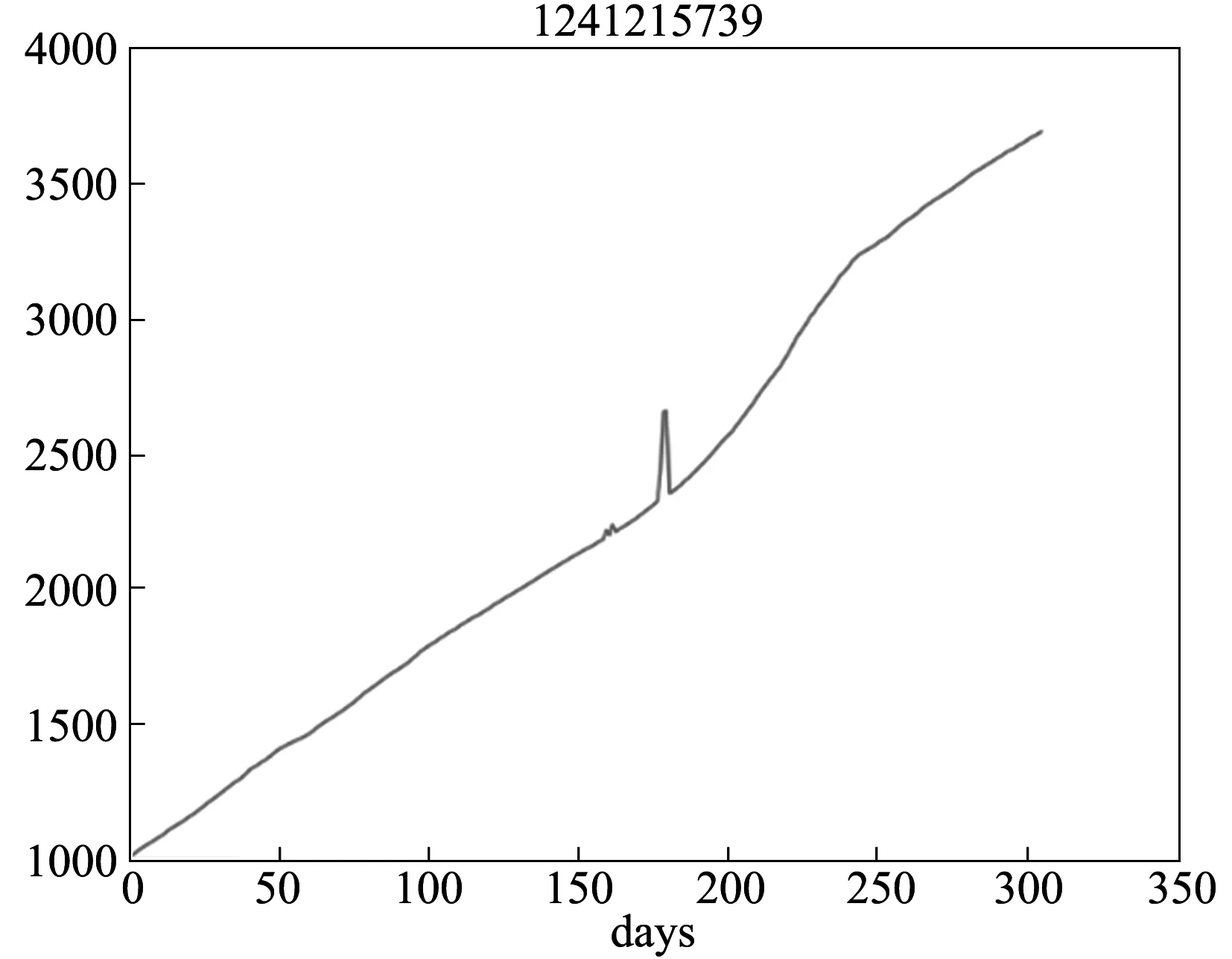
图1 normal类型用户用电曲线示例
异常数据的第二种类型是change类型。这种类型的特点是用户用电曲线中毛刺很少,整体曲线有一次大幅度的下移,将下移段平移之后可以看出曲线的上升趋势一致。这种类型的产生很有可能是智能电网实际工作中的换表或者是电表读数清零造成的,所以用change来命名这种异常类型。一个典型的change类型的用户用电曲线如图2所示。

图2 change类型用户用电曲线示例
最后一种异常类型是complex类型。这种类型的用户用电曲线比较杂乱,无规律,往往出现了比较多的毛刺,或者是毛刺宽度特别大。曲线的整体趋势也比较混乱,违反了用户用电曲线整体向上的原则。一个典型的complex类型的用户用电曲线如图3所示。
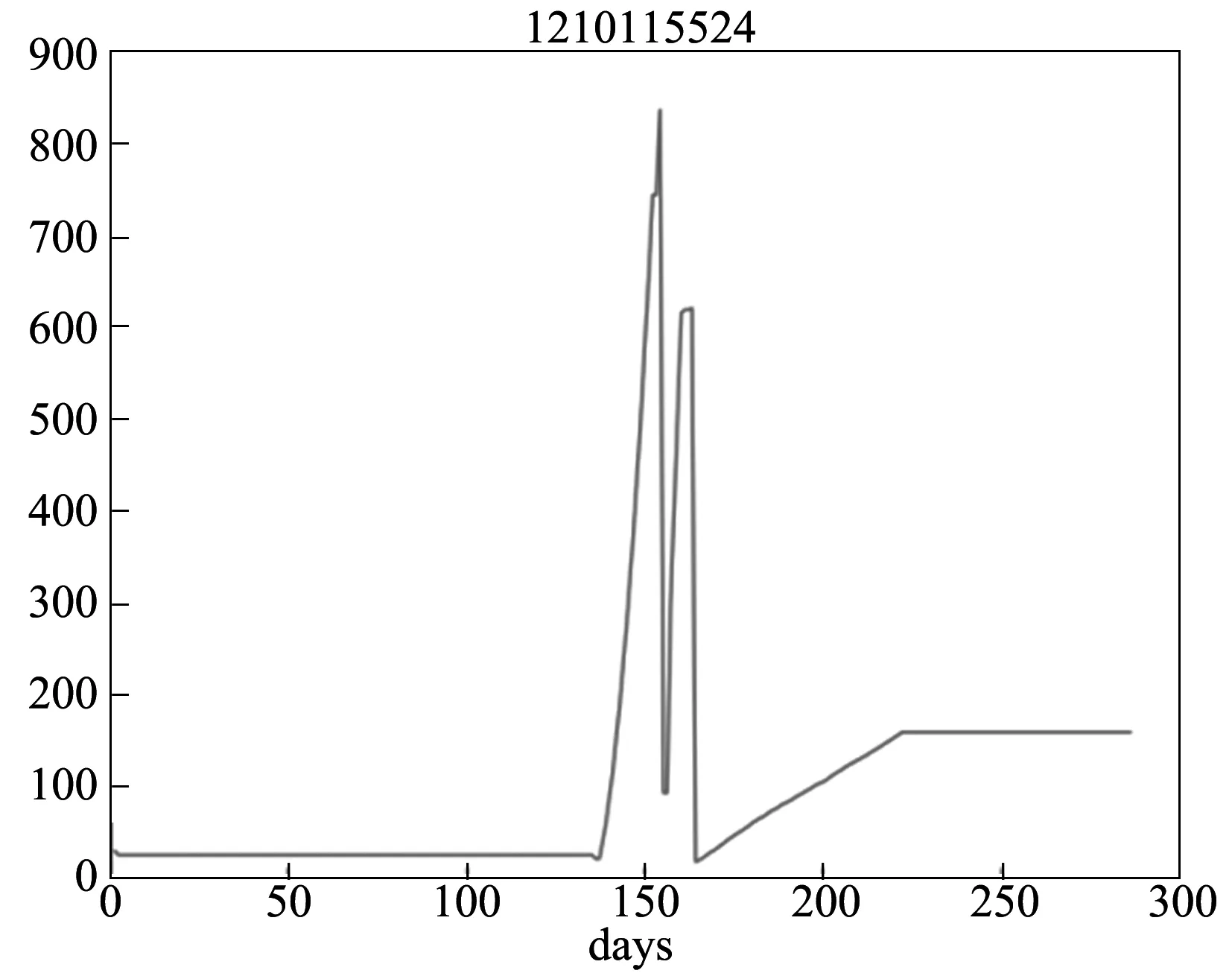
图3 complex类型用户用电曲线示例
本文采用K近邻(kNN)方法[13]对异常数据进行分类。K近邻法的输入是实例的特征向量,输出为实例的类别。K近邻法假定给定一个训练实例集,其中的实例类别已定。分类时,对新的实例,根据K个最近的训练集实例的类别,采取多数表决等方式预测类别。
在异常数据的K近邻法分类器实现中,本文采取欧氏距离作为距离度量,类别决定采取多数表决的方式。分类器的重点在于特征的选取。
K近邻方法有多种实现,常见的有线性扫描法和kd树等。线性扫描法分类时对每一个输入向量,对数据进行扫描,分别计算输入向量和训练集中每个数据的距离,然后选取K近邻。线性扫描法实现简单,在数据集较少时经常采用。本文在实现K近邻方法时采用的也是线性扫描法。
数据集较少时,常常采用交叉验证(cross-validation)的方法进行训练效果的评测。数据集较少时,有时选取的测试集不具有代表性,使得分类器效果的结果产生偏差,影响对分类器真实分类准确率的检验。交叉验证的思想在于尽可能多地利用数据,通过数据的多次利用达到隐性增大数据集大小的效果。交叉验证的基本步骤如下:将数据集分成K等分,第1次训练时采取第1份作为测试集,其余K-1份作为训练集,得到测试结果1;接着选取第2份作为测试集,其余作为训练集,得到测试结果2;同样的过程进行K次,最后对测试结果取平均,得到分类器在这个数据集上的分类效果。
在进行分类器训练时,首先要进行输入数据特征的特征提取工作,将输入数据转化成特征向量。特征提取对于分类器最后的效果有很大的影响。如果特征选取的好,特征会把输入数据的特性表示出来,在分类器训练时一般来说会获得更好的效果;如果特征选取的不好,输入数据的特性没有被选取的特征表示出来,反而使得分类器训练时产生偏离,降低了分类器的准确率和效果。
在用户用电数据集的处理中,本文选取了三个特征来构成输入向量:异常数量,毛刺宽度总和重复出现读数的最大值。
异常数量从一个方面反映了数据的异常程度。一般来说,一个电表异常数量越多,就可以认为这个电表自身的问题越大,这些异常的产生可能是系统性或者是自身性的,而不是偶尔的异常。反之,异常数量少的电表可能预示了偶尔的异常,在分类中更有可能被认为是出现偶尔异常的电表,而不是来自系统性的错误。
毛刺宽度是异常的一种数量上最直观的衡量。在智能电网的实际运行过程中,偶尔出现的异常往往在时间上的延续比较短,而系统性的异常在时间上延续往往会比较久。然而,在分类中,有一些电表可能会出现的比较多的异常数量,但是他们的毛刺宽度都比较少,本文认为这些电表更接近于正常的表。在实际数据中,毛刺很可能不止出现一次,所以通过毛刺宽度总和这个特征来刻画数据的这种特性。
重复读数的最大值是用户用电数据集比较特有的属性之一。在智能电网实际运行过程中,在通信线路出现异常时,搜集数据的传感器的数据不能及时传到收集器中,收集器常常会以发生异常前采集到的数据作为填充。重复读数出现的多,暗示着用户用电系统出现的通信或者其他故障比较多,有理由将其归类为异常频繁的表。选取这个特征从另外一个方面刻画了电表读数数据的特征,可以帮助进行异常电表的分类。
2.3数据修正模块

其中ti是节点值。
B样条曲线具有局部性,连续性,几何不变性和灵活性等特点,可以较为准确地刻画用户用电曲线的变化趋势,也能较为准确地填补出用户用电曲线某一处的缺失值。
3实验结果
3.1实验数据集情况
在这篇论文中,实验数据集采用的是某电力公司采集到的用户用电数据。
数据集中包含两种不同类型的用户:居民用户和大用户。大用户指的是工厂,企业等较为集中式的用电单位。这些用户隶属于几个不同的台区,每个台区下辖多个自动采集的电表。每个电表记录一个用户的总电量,用电高峰时期的用电量和用电低谷时期的用电量。电表采用累加计数的方式,当电表读数接近量程的时候会进行换表操作,重新对用电量进行累加计算。
数据集的采集时间从2013年1月1日开始,到2013年10月31日结束,时间跨度为十个月。一般来说居民用户的电力采集粒度(采集时间节点的间隔时间)小于大用户,但是在这个数据集中时间的粒度都是一样的,为一天采集一次。
3.2实验过程和结果
经过数据审查模块的分析处理,实验数据集中各个台区的异常数量分布情况如表1所示。

表1 实验数据集异常数据的台区分布情况
为了训练异常电表的分类器,本文从5个台区分别抽取了50个电表进行标记工作。实际用于训练和测试的异常条目为193个,其中normal类型的电表有111个,change类型的有41个,complex类型的有41个。在实验中,采取90%的数据作为训练集,剩下的10%作为测试集。
本文使用错误分类率作为指标对分类结果进行评判,错误分类率由分类错误的数目除以分类总数得到。由于训练集的数量有限,采用了交叉验证的方式进行训练,计算错误率的平均值。表2给出了采取不同k值的情况下分类率情况(见表2)。
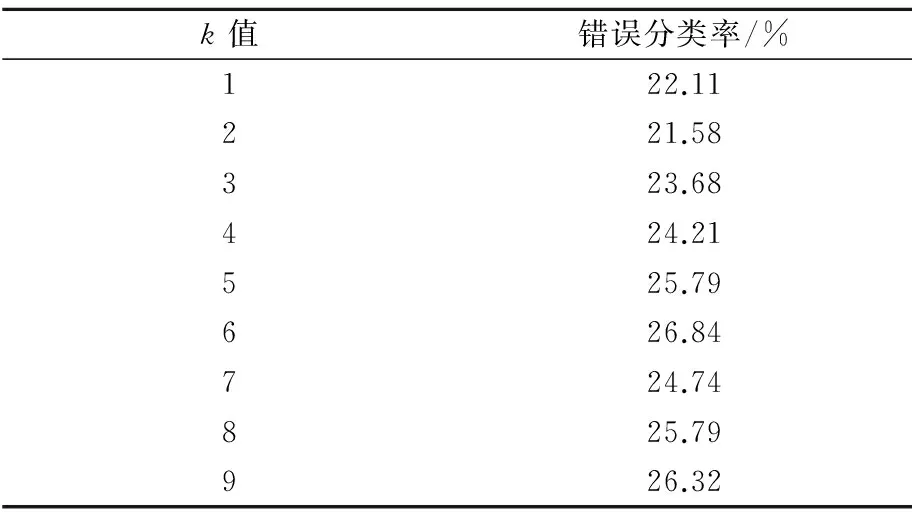
表2 不同k值情况下的错误分类率
除此之外,实验中还测试了测试集占总的标记数据集比率不同时的情况(见表3)。测试时采取的k值为2。

表3 不同测试集占比的错误分类率
3.3实验结果分析和展望
从异常数据的分布情况我们可以发现,在一些实际运行的电力系统中,异常数据总量虽然不多,但是比较广泛地分布。这说明了分析异常数据,进行异常分类的必要性和迫切性。
从分类的结果说,异常电表的分类器还是比较准确的,k值的选取不是越大越好,在k=2时候分类器的效果最好。k值过大时反而训练效果发生下降。当k=1的时候,实际上选取的是最近邻。实验结果表明采取较大的k值(k>3)时,训练效果并没有较选取最近邻有所提高,说明在现有的特征提取下,同一类的数据聚合程度还是很高,还有较大的改进空间。
测试集的比率占比越大,训练的例子就越少,分类器的准确率下降。综上所述,使用这个分类器可以对发现的异常类型进行较为快速、准确的分类。
未来的工作主要在于进一步提高分类器的准确率。一方面将会加强对特征的提取和选择,争取改进的特征更加能体现数据集本身的特性,加强分类内部之间的聚合度和分类之间的距离;另一方面改进分类器的算法,使用其他方法或者K近邻法的改进方法,从算法的层面提高分类器的分类准确性。
参考文献:
[1]Smart Grid Available via http://energy.gov/oe/technology-development/smart-grid para1.
[2]Ramaswamy Sridhar, Rastogi Rajeev, and Shim Kyuseok. Efficient Algorithms for Mining Outliers from Large Data Sets. SIGMOD, 2000.
[3]NAIRAC A, TOWNSEND N, KING S, CARR R, COWLEY P, TARASSENKO L. A System for the Analysis of Jet Engine Vibration Data. Integrated Computer-Aided Engineering, 1999.
[4]Simon Hawkins, Hongxing He, Graham Williams, and Rohan Baxter. Outlier Detection Using Replicator Neural Networks. DaWaK, 2002.
[5]VICTORIA J. hodge and Jim Austin. A Survey of Outlier Detection Methodologies. Artificial Intelligence Review, 2004.
[6]EAMONN KEOGH, JESSICA LIN, ADA FU. HOT SAX: Finding the Most Unusual Time Series Subsequence: Algorithms and Applications. ICDM 2005.
[7]JAMES W, TAYLOR. An Evaluation of Methods for Very Short-Term Load Forecasting, Using Minute-by-Minute British Data. International Journal of Forecasting, 2008, Vol. 24, pp. 645-658.
[8]NIST. Available via: http://www.itl.nist.gov/.
[9]CHEN J, LI W, LAU A, et al. Automated load curve data cleansing in power systems[J]. Smart Grid, IEEE Transactions on, 2010, 1(2): 213-221.
[10]童述林, 文福拴, 陈亮. 电力负荷数据预处理的二维小波阈值去噪方法[J]. 电力系统自动化, 2012, 36(2): 101-105.
TONG Shu-lin, WEN Fu-shuan, CHEN Liang. A two-dimension wavelet threshold de-noising method for electric load data pre-processing[J]. Automation of Electric Power Systems,2012,36(2):101-105.
[11]刘育明, 姚陈果, 孙才新, 等. 采用稳健统计与 B 样条函数处理频率扰动记录单元异常数据[J]. 高电压技术, 2012, 38(6): 1500-1505.
LIU Yu-ming, YAO Chen-guo, SUN Cai-xin. Outlier detection of frequency disturbance recorder data using robust statistics and b-spline functions[J]. High Voltage Engineering,2012,38(6):1500-1505.
[12]钱立军, 李新家. 用电信息采集系统中数据审查策略与异常原因分析[J]. 电力需求侧管理, 2013,15(1): 45-47.
QIAN Li-jun, LI Xin-jia. Strategy of the data checking and the exception reason analysis in the information collection system[J]. Power Demand Side Management,2013,15(1):45-47.
[13]李航. 统计学习方法[M]. 北京:清华大学出版社, 2012, 37-40.
[14]孙家广,等. 计算机图形学[M].北京:清华大学出版社, 1998.
(本文编辑:杨林青)
Anomaly Detection and Category of Electrical Utilization Data
SHEN Hai-tao1, QIN Jing-ya2,3,CHEN Hao2,3, FAN Rong1,ZHUANG Cai-jie4
(1. Dongjie Construction (Group) Co., Ltd., Shanghai 201210, China;2. School of Computer Science, Fudan University, Shanghai 201203, China;3. Engineering Research Center of Cyber Security Auditing and Monitoring, Ministry of Education, Shanghai 200203, China;4. Xinneng Kaibo Industrial Co., Ltd., Shanghai 201210, China)
Abstract:During the grid operation, users′ consumption data collected by the automatic metric gathering system may have deviations and errors due to the weather, line failures and system failures. These deviations and errors are anomalies in the data and their presence has seriously affected the accuracy of the information collection and analysis of user consumption. It is urgent to preprocess user consumption data, including identifying anomaly data in the large-scale user consumption data and using certain methods to handle and compensate abnormal data. This paper focuses on the data cleansing method for user consumption data in an automated metric gathering system. It presents a detailed discussion of major problems in user consumption data, builds a model for data preprocessing using k-nearest neighbor method to classify corrupted data and carries experiments based on the above methods and model. The preliminary results are presented and concluded, which provides reference value for the future work of user consumption data preprocessing.
Key words:smart grid; user consumption data; data preprocessing; k-nearest neighbor; spline smoothing
DOI:10.11973/dlyny201601004
作者简介:沈海涛(1977),男,工程师,从事电力工程管理。
中图分类号:TM727
文献标志码:B
文章编号:2095-1256(2016)01-0017-06
收稿日期:2015-10-15
