基于视觉特征提取的压缩域在线视频摘要快速提取
2016-07-04周柏清任勇军
周柏清,黄 淼,任勇军
(1.湖州职业技术学院 信息工程分院,浙江 湖州 313000;2.平顶山学院 软件学院,河南 平顶山 467000;3.南京信息工程大学 计算机与软件学院,江苏 南京 210044)
基于视觉特征提取的压缩域在线视频摘要快速提取
周柏清1,黄淼2,任勇军3
(1.湖州职业技术学院 信息工程分院,浙江 湖州 313000;2.平顶山学院 软件学院,河南 平顶山 467000;3.南京信息工程大学 计算机与软件学院,江苏 南京 210044)
摘要:为了在有限的时间内产生质量可接受的视频摘要以达到在线使用的要求,提出一种基于视觉特征提取(visual features extraction ,VFE)的压缩域视频摘要快速提取方法。从每帧输入视频中提取视觉特征,采用零均值归一化交叉相关(zero mean normalized cross correlation,ZNCC)指标检测有相似内容的视频帧组,为每组选择代表性帧,运用2个量化直方图过滤所选择的帧,从而避免视频摘要中可能的冗余或无意义帧。在视频检索国际权威评测(TREC video retrieval evaluation,TRECVID)2007数据集上的实验结果表明,与基于聚类的高斯混合模型、基于熵的模糊C均值聚类和关键帧提取方法相比,该方法提取的视频摘要质量更高,且在时间和空间复杂度上具有明显优势,适合在线实时处理。
关键词:视频摘要;压缩域;视觉特征提取(VFE);量化直方图;TRECVID 2007
0引言
随着大数据时代的到来,视频数据充斥着工作和生活,如何从冗余数据中获取需要的视频数据是一个亟待解决的问题[1]。所需要的视频即视频摘要是一个精简版的视频序列,近些年随着高清视频的普及和网络带宽过剩, 获取高质量视频摘要的呼声越来越高,为了在线产生高质量视频摘要,解决方案必须高效且渐进执行,用户大多需要在下载视频数据过程中能产生高质量的视频摘要。
一般视频摘要提取有2种不同类型:静态视频情节提取,是从原始视频中提取视频帧的集合,如文献[1-3]就是静态视频摘要;另一种是动态视频剪辑,它是一组视频短片,加入序列,并作为视频播放,如文献[4-5]。动态视频剪辑算法框架可以按照非压缩域[5-7]和压缩域[8-9]分组。
文献[5]提出了一种通过采用一个高层次特征融合的方法来提取视频摘要。首先,预采样步骤是为了丢弃大量的冗余信息,接着,在剩余的帧中提取5个高层次的特征;之后,通过梯度下降方法组合这些功能的最优权重;最后,用加权k均值算法识别构成最终摘要中最重要的段。这种利用高层次的特征提取视频摘要可以产生不错的效果,但是需要离线操作,时间和存储开销都非常大,无法适应在线提取视频摘要。
文献[6]提出了一种聚类算法,以同类色配合视频帧组。首先,视频序列分解成片段,基于颜色矩相似帧分组;接着,采用基于粗糙集理论的谱聚类(rough-set based spectral clustering, RSC)方法聚类这些片段,属于同一个集群的连续片段结合;然后,相邻的段被合并,以便减少冗余;最后,从最长段帧的子集选择得到视频摘要。与文献[6]类似,文献[7]将输入视频转换成基于颜色直方图的镜头。此后,将它们应用贪婪RSC方法进行相邻镜头的合并,进而减少了冗余。在结束时,具有最高运动部分的视频帧才能包括在摘要中。文献[6-7]虽然一定程度上减少了冗余信息,但只适合离线提取视频摘要。
文献[8]提出了一种技术以解决视频摘要问题,通过故事结构与视频拍摄的动力学表征信息来组合,通过对视频流的部分译码,计算估计每个镜头的视频摘要贡献的运动描述符。接着,利用隐马尔可夫模型(hidden markov model, HMM)模拟拍摄顺序,最后,视频摘要作为观测序列生成,其中较高概率分配给动态拍摄。文献[8]利用HMM,是个不错的策略,在压缩域取得一些效果,不过内容的分析必须在完整可用的数据上执行,而网络数据总是满足这一条件。
文献[9]提出了一个基于熵的模糊C均值聚类的摘要算法。最初,从每个图片组序列(groups of pictures, GOP)的I-帧的数码相机(digital camera,DC)图像提取颜色布局描述符;接着,通过比较连续GOP特征向量之间的相异度,输入序列分割为视频镜头;之后,聚类方法用于镜头分组;最后,使用交互式定级过程获得视频摘要。文献[9]聚类算法的应用提高了压缩域上的操作,其局限和文献[8]一样,必须在完整可用数据上执行。
在众多解决方案中,很多研究侧重非压缩域[5-7],尽管它们有些能产生不错的质量,但非常耗时,而且存储空间也巨大,即它们只适用于离线使用,很难达到在线操作的要求。而压缩域可作为加速计算性能的替代者[8-9],尽管那些策略有效,但内容分析必须在所有完整可用的数据上执行,限制了在线操作模式。因此,本文提出一种基于视觉特征提取(visual features extraction, VFE)的视频摘要快速提取方法,直接在压缩域运行,它依赖于视频的视觉特征和简单快速的视频相似内容检测,本文框架以递进方式产生输出摘要。计算上的改进使该技术框架适用于在线操作。
1MPEG-1/2/3/4
MPGE视频主要由三类图片组成:帧内编码(I-帧)、帧间预测(P-帧)和双向预测(B-帧),这些图片组织成MPEG视频流中的GOP。
GOP必须以I-帧开始,然后是任意数目的I和P帧,它们为锚帧。每对连续锚帧之间可出现多个B-帧。图1给出了一种典型的GOP结构。
I-帧不参考任意其他视频帧,因此,可独立编码,为快速访问压缩视频提供一个入口点。另一方面,P-帧编码基于2个锚帧,前1个以及后1个锚帧。
每个I-帧划分为一个无重叠宏序列,对于以4∶2∶0格式编码的视频,每个宏包括6个8×8像素块,4个亮度(Y)块和2个色度(CbCr)块,每个宏完全内编码,因此,使用离散余弦变换(discrete cosine transform, DCT)转换每个8×8像素块到频域,然后量化(有损)和熵(运行长度和霍夫曼,无损)编码64个DCT系数,实现压缩。
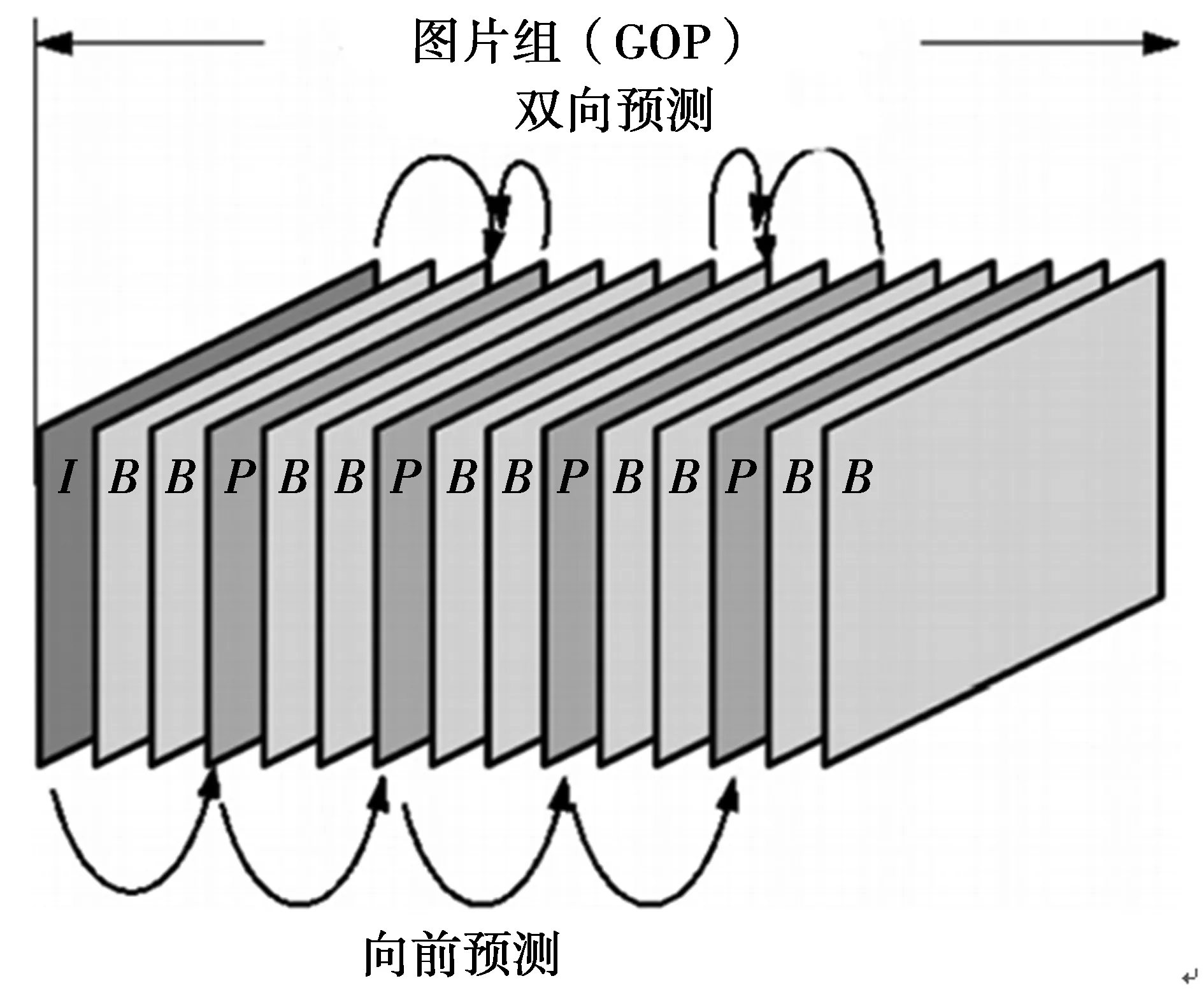
图1 MPEG视频中的GOPFig.1 GOP of MPEG video
2压缩域视频摘要快速提取方法
本文方法包括3个主要步骤:①特征提取;②内容选择;③噪声过滤。流程图如图2所示,从每帧输入视频流中提取视觉特征,接着使用一种简单快速算法检测相似内容的视频帧组,并为每个组选择代表性视频帧,最后,过滤选择的帧,以避免视频摘要中可能的冗余或无意义帧。下面详细介绍每个步骤。
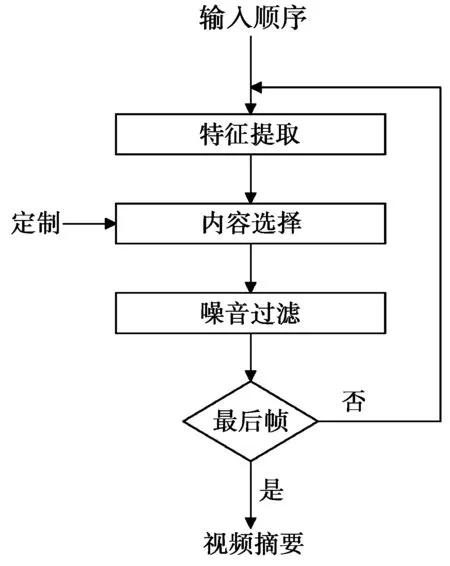
图2 本文方法流程图Fig.2 Flow chart of proposed method
2.1特征提取
将视频流划分为一组有意义可管理的单元,大部分视频编码基于GOP,作为基本单元。I-帧包括表征整个GOP内容足够多的信息。
原始图像划分为8×8像素块,每个块转换为64个DCT系数来执行MPEG视频的I-帧压缩,DC项c(0,0)通过(1)式[10]与像素值f(i,j)相关
(1)
即DC项的值是像素块平均强度的8倍,若提取所有块的DC项,可使用这些值形成原始图像的缩减版本,这个相似图像便是DC图像[10]。尽管DC图像的大小仅为原始图像的1/64,但它仍然保留了重要信息量,因此,在原始图像上执行全局特征提取可应用于DC图像。图3给出了大小为352×288的图像,其对应的DC图像大小为44×36。虽然DC图像缩减了尺寸,但它们未压缩,需要大量存储空间。为了保存待存储的数据,可通过计算彩色直方图[11]将每个DC图像变换为一个256维特征向量。该技术计算量小,且对摄像机位置的微小变化具有鲁棒性。本文从色度,饱和度,纯度(hue,saturation,value,HSV)颜色空间获得了彩色直方图,更能抵御噪声,HSV空间的彩色直方图提取如下:HSV颜色空间划分为256个子空间,使用H的32个范围、S的4个范围和V 的2个范围,特征向量的每个维度值是整个DC图像中每个颜色的空间密度。

图3 原始图像352×288和其DC图像44×36Fig.3 Original image 352 x 288 and its DC images 44×36
2.2内容选择
利用从压缩视频中提取的彩色直方图来检测具有相似内容的视频帧组,并选择每组中具有代表性的视频帧,以产生视频摘要。分组相似帧的有效性依赖于2个帧所用的相似度指标。本文采用零均值归一化交叉相关(zero-meannormalizedcrosscorrelation,ZNCC)指标[12]作为2个帧之间的距离函数,该函数对光照仿射变换具有不变性,因此,这类度量广泛用于模板匹配、运动分析等。

(2)
(2)式中,Ht1和Ht2分别是在t1和t2时刻从视频帧提取的彩色直方图。该函数返回一个从-1(-1表示直方图完全不相似)到+1(+1表示相等)的实数。
为了检测视频帧组,本文计算了连续帧的成对不相似度。图4给出了这些值按时间分布的例子,从图4中可以观察到有一些瞬时时刻视频帧之间的不相似度差别很大(对应峰值),而更长周期内则变化较小(对应非常密集的区域)。通常,峰值对应于视频中突然的动作或场景变换,而视频帧在密集区域更相似。因此,2个峰值之间的帧可视作具有相似内容的帧组。本文仅考虑特定时刻的峰值。
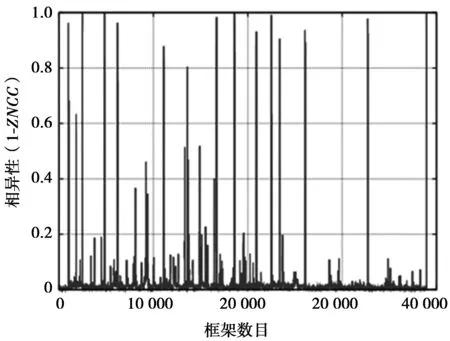
图4 TRECVID2007数据集的视频MRS150072帧之间的两两相异性Fig.4 Diversity between MRS150072 frame in TRECVID2007 data set
(3)
(3)式中,ε是相似帧之间不相似度的阈值。通过实验测试,发现该值取0.05—0.15是不错的选择[13]。
若相似帧序列的持续时间小于最小值,则丢弃所有这些帧,否则,选择这个序列中一段代表一个帧组。即当且仅当帧组大于阈值λ时,帧组可用作摘要。根据经验,相似帧视频持续时间占总的视频序列0.5%—2%是一个良好的选择。
最后,通过以用户定义的速率提取视频帧段,本文仅选择I-帧(情节摘要)或整个GOP(视频剪辑)。本文仅15%的帧组包括在视频摘要中,通过本方法选择的视频帧如图5所示,对TRECVID 2007数据集的视频MRS150072取每段中间的I-帧。
2.3噪声过滤
噪声过滤是避免视频摘要中可能的冗余或无意义帧,因为垃圾帧和冗余段可能会影响视频摘要的质量。垃圾帧通常出现在每个镜头的开始或末尾,例如测试图案、拍手板、单色帧等。冗余帧源自重复序列。

图5 对TRECVID2007数据集的视频MRS150072选定帧Fig.5 Selected frame for MRS150072 video in TRECVID2007 data sets
当选择一个新的视频帧组成视频摘要时,若它不是必须帧,则丢弃它。接着检查分析该帧是否有用,为此,从其量化的图像计算2个直方图:一个用于颜色分布,另一个用于梯度方向,原始直方图有36个bins,覆盖360°方向。图6解释了各类视频帧的直方图的行为,值得一提的是,垃圾帧的分布是均匀分布,这使得bins之间差异较大,因此,若直方图的归一化差异大于预定义阈值,本文将丢弃这个输入帧,否则,比较它与视频摘要的所有帧。比较视频帧的算法依赖于量化图像之间的像素对匹配,如果2个对应像素的强度值不同或它们对应4邻域之一拥有不同的量化颜色,则它们不相似,否则认为它们相似。因此,这些帧之间的相似度通过相似像素数与总像素数的比率测量,如果它们之间的相似度大于0.05,则2个视频帧匹配。如果匹配帧与从帧组选择的总帧数的比率低于最小值,则这个段中所有帧都包括在视频摘要中。否则,假设它们都属于冗余段,丢弃它们。按照经验,比率小于50%是个不错的选择[13]。图7为利用本文方法经过噪声过滤后的TRECVID 2007数据集的视频MRS150072。
3实验与分析
3.1实验数据集
本文所用数据集为TRECVID2007数据集[14],大约5小时的视频(409 630帧),所有视频是MPEG-1格式(352×288分辨率、帧率为25 fame/s),颜色和声音等均未剪辑,镜头主要为英国广播公司戏剧节目的5大系列。这些视频取自制作电影或纪录片的拍摄过程中,是来自摄像机的原始记录,一般在6—34 min变化,由于拍摄现场动作表现或意外失误的变化,会有一些同样的场景记录在视频序列。此外,它们还含有辅助数据,如测试图案,以校准摄像机的颜色,或拍板序列。
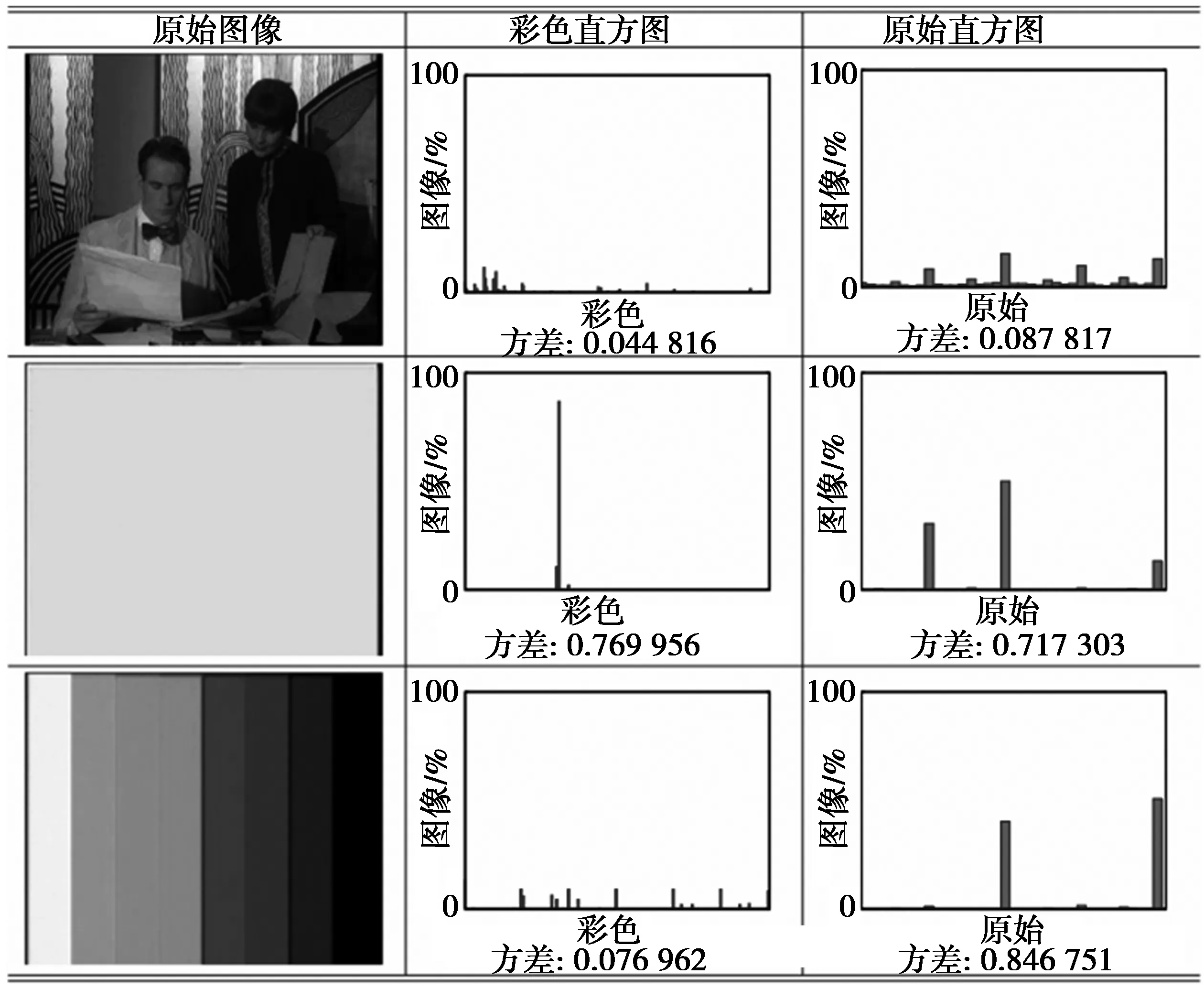
图6颜色直方图(第2列)、方向直方图(第3列)和正常行为(第1行),单色帧(第2行)和彩条帧(第3行)
Fig.6Color histograms (second column), orientation histograms (third column), normal behavior (first row), monochrome (second row) and color-bar (third row) frames

图7 经过噪声过滤后的TRECVID 2007数据集
3.2实验评估框架与参数设置
与其他的研究领域不同,评价一个视频摘要并非简单,常常需要一致的评估框架。文献[1,15]都有自己的评估方法,但没有任何性能分析。本文的评价方法与文献[14]一样,在这种方法中,地面实况是发生在原始视频中重要的视频段,每个视频段确定了鲜明的物体或事件,使用拍摄角度、距离或者其他信息决定是否合格。每一个视频摘要由多少地面实况(inclusions, IN)和多少重复材料(eedundancy, RE)来判断,另外本文还采用2个额外评估项:相对于原始视频的持续时间(duration, DU)和垃圾帧(junk, JU)所占份额。
本文方法制作视频摘要的参数:ε设定为0.075,λ为给定视频长度的0.5%,κ为所选择帧的25%。手动注释TRECVID 2007数据集视频的所有帧为正常、单色或彩条,接着计算每个帧的颜色和方向直方图的归一化差异,选择用于选择滤出垃圾帧的阈值。
3.3视频摘要质量与运行成本比较
所有实验均在英特尔酷睿2四核Q6600处理器上执行(四核运行频率为2.4 GHz),2 GByte的DDR3内存。将本文方法生成的视频摘要质量与文献[6]提出的基于聚类的高斯混合模型、文献[9]提出的基于熵的模糊C均值聚类和关键帧提取方法进行比较,比较结果如图8所示。整体结果表示为杜克式盒状图,如图9所示。
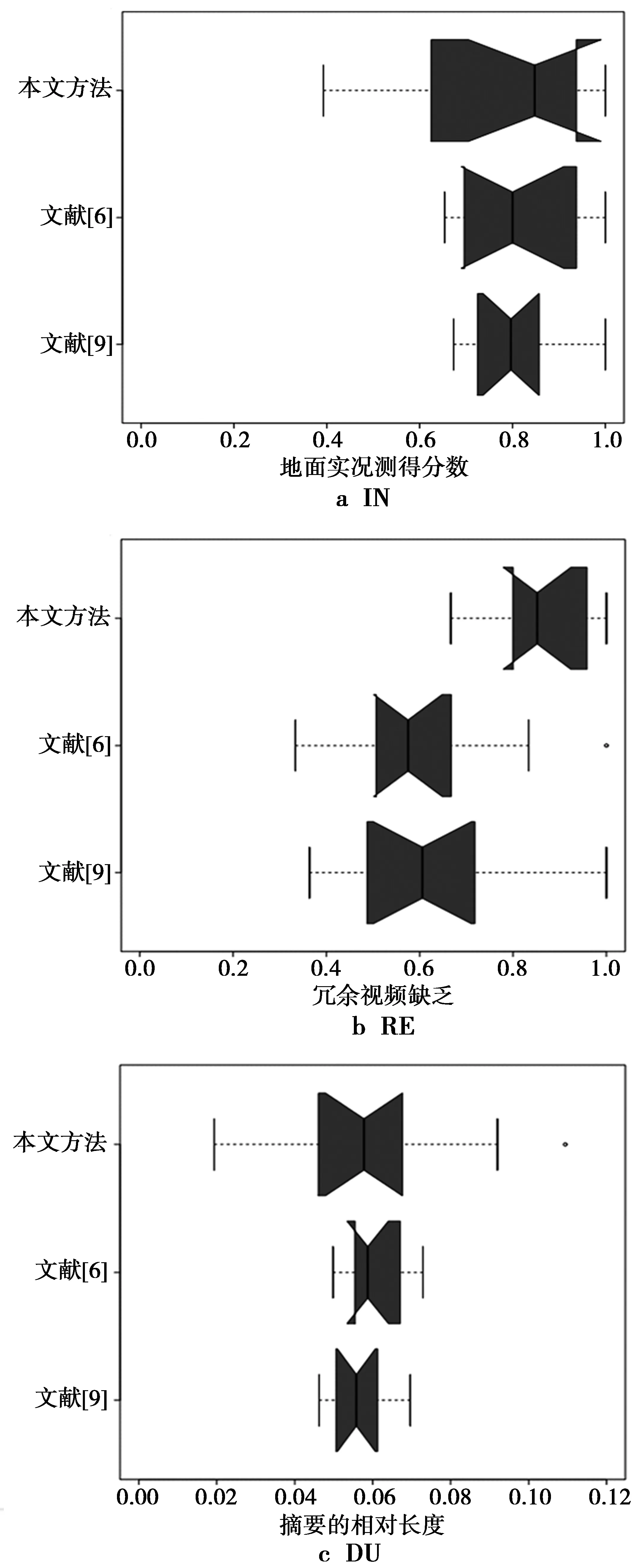

图8 各个方法产生视频摘要质量Fig.8 Video summarization quality of each method

图9 杜克式盒形图示例Fig.9 Sample of Duke box figure
实验结果表明,在视频摘要中的IN以及原始视频的DU方面,本文方法与其他方法质量差不多,但在RE和JU所占份额方面优于其他算法。为了验证这些结果的统计显著性,需要计算它们之间差异的置信区间,进而比较每对方法。若置信区间包括零,则差异在该置信水平上不显著,否则差异显著。
表1是95%置信度下不同方法的差异对比,实验分析表明,这些方法产生的视频摘要的IN和持续时间DU相似。因此,其他度量的置信区间不包括零,结果证实,本方法相对于其他方法能产生更优质量的摘要(拥有最高RE和JU)。

表1 95%置信度下不同方法的差异
由于产生视频摘要所需的时间依赖于硬件,且所有待比较方法的源代码不可用,这里只能做相对性能差异。表2为所有比较方法的计算成本和空间需求(相对于帧数n和特征向量的维度d)。

表2 各种方法的计算成本和空间需求
从表2可以看出,本文方法的计算成本和空间需求低于其他2种比较方法,本文方法采用ZNCC指标作为2个帧之间的距离函数,该函数对光照仿射变换具有不变性,可实现快速的相似度检测,通过噪声过滤避免视频摘要中可能的冗余或无意义帧,进一步降低了计算开销。

4结束语
本文提出了一种基于视觉特征的视频摘要提取方法,采用零均值归一化交叉相关指标检测有相似内容的视频帧组,为每组选择代表性帧,运用2个量化直方图过滤所选择的帧,避免了视频摘要中可能的冗余或无意义帧。本文方法可直接在压缩域运行,实现视频摘要的递进生成,适用于视频摘要的在线生成。在TRECVID2007数据集(BBC未剪辑摘要任务)的实验表明,本文方法能产生高质量视频摘要,且计算开销低于目前几种较为先进的方法。
本文方法也可采用其他视觉特征和相似度指标的评估,另外用于局部特征和运动分析将是不错的选择,这将是未来工作的重点。
参考文献:
[1]WANG L, WANG W, JIAN M A, et al. Perceptual video encryption scheme for mobile application based on H. 264[J]. The Journal of China Universities of Posts and Telecommunications, 2008, 15(4): 73-78.
[2]陈佳, 滕东兴, 杨海燕,等. 一种草图形式的视频摘要生成方法[J]. 中国图象图形学报, 2010, 43(8): 1139-1144.
CHEN Jia, TENG Dongxin, YANG Haiyan, et al. A generating method for video abstraction of the form of sketches [J]. Journal of Image and Graphics, 2010, 43(8): 1139-1144.
[3]罗斌, 戴玉名, 翟素兰. 自适应CCV及等价关系聚类的视频摘要的生成[J]. 重庆大学学报:自然科学版, 2010, 18 (2) : 69-72.
LUO Bin, DAI Yuming, ZHAI Sulan. Video summarization generation based on adaptive CCV and equivalent relation clustering [J]. Journal of chongqing university: Natural Science Edition, 2010, 18 (2) : 69-72.
[4]吴华, 冯达, 柳长安,等. 基于导航信息的架空电力线巡检视频摘要[J]. 华中科技大学学报:自然科学版,2013, 41(1): 1120-1126.
WU Hua, FENG Da, LIU Changan, et al. Overhead power line inspection video abstract based on the navigation information [J]. Journal of Huazhong University of Science and Technology:Natural Science Edition, 2013, 41 (1): 1120-1126.
[5]KLEBAN J, SARKAR A, MOXLEY E, et al. Feature fusion and redundancy pruning for rush video summarization [C]//Proceedings of the international workshop on TRECVID video summarization (TVS).Augsburg, Bavaria, Germany:ACM, 2007: 84-88.
[6]OU S H, LEE C H, SOMAYAZULU V S, et al. Low complexity on-line video summarization with Gaussian mixture model based clustering[C]// IEEE.Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on.Dresden, Germany:IEEE Press, 2014, 1260-1264.
[7]CHASANIS V, LIKAS A, GALATSANOS N. Video Rushes Summarization Using Spectral Clustering and Sequence Alignment[C]//Proc.Workshop on TRECVID Video Summarization,Vancouver. Ljubljana, Slovenia:IEEE Press,2008: 75-79.
[8]PIACENZA A, GUERRINI F, ADAMI N, et al. Markov chains fusion for video scenes generation[C]//IEEE.Signal Processing Conference (EUSIPCO), 2012 Proceedings of the 20th European.Ljubljana,Slovenia:IEEE Press, 2012: 405-409.
[9]ANGADI S, NAIK V. Entropy Based Fuzzy C Means Clustering and Key Frame Extraction for Sports Video Summarization[C]//IEEE.Signal and Image Processing (ICSIP), 2014 Fifth International Conference on, Piscataway, NJ:IEEE Press, 2014: 271-279.
[10] 刘哲. 基于视频压缩感知的编码端速率控制研究[D].西安:西安电子科技大学, 2013.
LIU Zhe. The research of coding rate control based on video compression perception [D].Xi 'an:Xi 'an university of electronic science and technology, 2013.
[11] 李延龙, 李太君, 罗其朝. 基于颜色空间特性的图像检索[J]. 海南大学学报: 自然科学版, 2013, 31(4): 344-348.
LI Yanglong, LI Taijun, LUO Qizhao. Image retrieval based on color space characteristics [J].Journal of Hainan University: Natural Science Edition, 2013, 31 (4) : 344-348.
[12] LU J, ZHAO D, JI W. Research on matching recognition method of oscillating fruit for apple harvesting robot[J]. Transactions of the Chinese Society of Agricultural Engineering, 2013, 29(20): 32-39.
[13] ALMEIDA J, LEITE N J, TORRES R Da S.VISON: VIdeo summarization for Online applications[J].Pattern Recognition Letters,2012, 33(4): 397-409.
[14] METZE F, DING D, YOUNESSIAN E, et al. Beyond audio and video retrieval: topic-oriented multimedia summarization[J].International Journal of Multimedia Information Retrieval, 2013, 2(2): 131-144.
[15] 宋杰, 徐丹, 时永杰. 视觉感知的图像和视频抽象[J]. 中国图象图形学报, 2013, 18(4): 450-908.
SONG Jie, XU Dan, SHI Yongjie. The image and video abstract of visual perception [J]. Chinese journal of image and graphics, 2013, 18(4): 450-908.
Online video abstract extraction based on visual features in compressed domain
ZHOU Baiqing1, HUANG Miao2, REN Yongjun3
(1.Faculty of Information Technology, Huzhou Vocational & Technical College, Huzhou 313000, P.R.China;2.School of Software, Pingdingshan University, Pingdingshan 467000, P.R.China;3.School of Computer & Software, Nanjing University of Information Science & Technology, Nanjing 210044, P.R.China)
Abstract:In order to produce acceptable quality of video abstract in a limited period of time, and achieve the online requirement, a fast video summarization method in compressed domain based on visual features extraction (VFE) is proposed. Firstly, visual features from each frame of the input video are extracted. Then, the zero mean normalized cross correlation (ZNCC) is used to detect similar content video frames, and the representative frames for each group are selected. Finally, two quantized-histogram filters are used to select frames to avoid possible video redundant or meaningless frames. The experimental results on the TREC video retrieval evaluation(TRECVID) 2007 data show that proposed method has higher video summary quality than the Gaussian mixture model based on clustering, entropy based fuzzy C means clustering and key frame extraction method, it has obvious dominance in the time and space complexity, and it is suitable for online real-time processing.
Keywords:video summary; compressed domain; visual features extraction (VFE); quantized-histogram; TREC video retrieval evaluation(TRECVID) 2007
DOI:10.3979/j.issn.1673-825X.2016.02.021
收稿日期:2014-12-19
修订日期:2015-10-09通讯作者:周柏清zhoubqzjhz@163.com
基金项目:国家自然科学基金(61304205,61300236)
Foundation Items:The Natural Science Foundation of China (61304205, 61300236)
中图分类号:TP391
文献标志码:A
文章编号:1673-825X(2016)02-0273-070
作者简介:

周柏清(1974-),女,浙江金华人,讲师,硕士,研究领域为视频处理、图像处理等。E-mail:zhoubqzjhz@163.com。
黄淼(1982-),女,河南社旗人,讲师,硕士,研究领域为图形图像处理、视频处理等。
任勇军(1974-),男,江苏南京人,副教授,博士后,研究领域为视频处理、信息安全等。
(编辑:王敏琦)
