Mel频率下基于LPC的语音信号深度特征提取算法
2016-07-04吴承军黎小松
罗 元,吴承军,张 毅,黎小松,席 兵
(1.重庆邮电大学 光电信息感测与传输技术重点实验室,重庆 400065;2.重庆邮电大学 信息无障碍工程研发中心,重庆 400065)
Mel频率下基于LPC的语音信号深度特征提取算法
罗元1,吴承军1,张毅2,黎小松2,席兵1
(1.重庆邮电大学 光电信息感测与传输技术重点实验室,重庆 400065;2.重庆邮电大学 信息无障碍工程研发中心,重庆 400065)
摘要:针对传统语音信号二次特征提取方法在保证识别率的前提下,实时性较差的问题,提出一种Mel频率下基于线性预测系数(linear predictive coefficient,LPC)的改进的语音信号深度特征提取算法。该方法根据人耳的听觉特性把LPC在Mel频率下进行非线性变换,再进行微分、高阶微分和按比例重组等步骤,得到一种既考虑声道激励又兼顾人耳听觉的新特征参数,从而大大减少传统语音信号深度特征提取的计算量,在不影响识别效率的情况下,极大提高系统的实时性。最后,将该算法在智能轮椅平台进行有效性验证,大量实验表明,语音控制系统实时性差的问题在使用该算法后能够得到明显改善,该算法既保证了特征提取识别率,也有效地改善了系统的实时性。在一定程度上使语音控制智能轮椅更具实用性。
关键词:语音识别;线性预测系数;Mel频率倒谱系数;Mel-LPC算法;深度特征提取
0引言
随着语音识别技术广泛应用到各个领域,人们对语音识别系统在复杂环境下的实时性有了更高的要求。而由于目前孤立词语音识别系统实时性差,人们无法在更多领域使用语音识别对一些设备进行控制。因此,需要对语音信号的特征提取方法进行改进,使语音识别系统具有更快的反应速度。
目前,在语音信号的二次特征提取中,应用较多的是对频谱包络特征尤其是倒谱特征进行二次特征提取,主要有线性预测倒谱系数(linear prediction cepstrum coefficient, LPCC)和美尔倒谱系数(Mel-frequency cepstrum coefficients, MFCC)[1-4],以及微分后的LPCC与MFCC参数进行加权和重组的方法。基于LPCC参数的二次特征提取算法简单,系统实时性较好,但其识别率较低,只有87%左右,而基于LPCC与MFCC参数结合的二次特征提取算法虽然识别率较高,但运算量巨大,处理单一语音帧特征时间高达47 ms,故实时性较差[5]。
因此,我们提出了一种改进的深度特征提取算法。该算法首先在线性预测系数(linear predictive coefficient,LPC)的基础上,对特征参数进行Mel频率的尺度变换,然后再对特征参数进行进一步提取。与分别提取LPC和MFCC参数相比,该方法能大幅度减少运算量,解决实时性差的问题;而且,算法融入了MFCC提取过程中模拟人耳听觉机理,既具有LPC声道激励的优点,又具备MFCC的鲁棒性,因此,能有效地提升系统的识别率。
1传统语音信号二次特征提取原理
语音信号的特征提取,其本质是对语音信号进行降维,用较少的维度表现了时域上的语音信号[1,6],二次特征提取则是对已经提取出的常用特征向量序列进行再分析[7],常用的语音特征包括基音(pitch),共振峰(formant),MFCC,LPCC以及线谱对系数(linear specturm pairs,LSP)等[6]。图1是将LPCC与MFCC融合的二次特征提取算法的语音识别基本流程。
此算法分别对LPCC与MFCC运用加权、微分,并将二者按照一定比例进行重组,得到新的特征参数,根据不同算法的需要,为了达到最优的识别效果,各方法先后次序可以调换并且多次使用。此方法的优点是可以进一步剥离隐藏在语音背后的潜在语音特征[8]。但由于其大量使用了LPCC,MFCC以及其一阶、二阶微分参数,所以运算量其实是相当大的。经过大量实验证明,这种传统的二次特征提取方法不具有较好的实时性,且识别率并不是很高。

图1 传统语音二次特征提取流程图Fig.1 Flow chart of traditional speech signal further features extraction
Mel-LPC特征是将LPC参数通过具有人的耳蜗效应的Mel滤波器组[9-10]进行变换的一种特征参数,进行改进的二次特征提取,能够进一步提高本语音识别系统的实时性。
2基于Mel-LPC的深度特征提取
任何特定时间点的信号,通过LPC,可以用该时间点以前的若干个任意时间点信号的线性加权来预测,而MFCC与LPC不同,它是受人耳听觉特性的启发从而得到发展,它先将信号频谱的频率轴转变为Mel刻度,再变换到倒谱域得到倒谱系数。将Mel频率变换得到的Mel-LPC参数进一步特征提取,得到F_Mel-LPC特征参数,图2为改进的深度特征提取流程图。
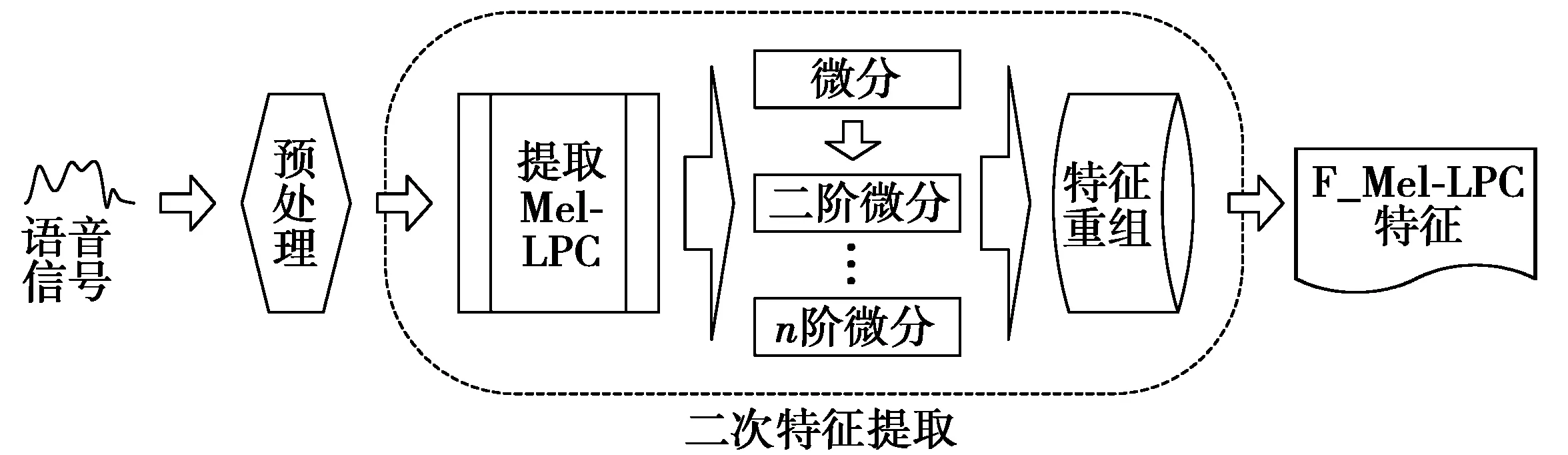
图2 改进的Mel-LPC深度特征提取流程图Fig.2 Flow chart of improved Mel-LPC further features extraction
2.1线性预测系数
根据语音产生的模型,假设一个线性移不变稳定因果系统,它在受到信号激励时产生输出,这个输出就是语音信号。而在时域中,将单位取样响应和激励信号进行卷积,即可得到该系统的语音信号。另外我们使用了全极点模型,即(1)式描述了语音信号产生的声道模型。
(1)
根据最小均方误差对该模型参数αp进行估计,就得到了LPC算法,求得的αp就是线性预测系数,P是预测阶数。
2.2Mel频率滤波器
将语音频谱的幅度或能量通过Mel滤波器组进行滤波,即可得到Mel频率,通常Mel频率用以模拟耳蜗的频率响应。图3为Mel滤波器组示意图,为使图像显示的性能更直观,图3中纵坐标采用归一化单位。所谓Mel滤波器组,就是将若干个三角滤波器组配置在Mel频率轴上,由Mel尺度得到该滤波器组的带宽以及中心频率,决定滤波器个数的因素主要是信号截止频率,我们等间隔分配了Mel频率轴上三角滤波器的中心频率。
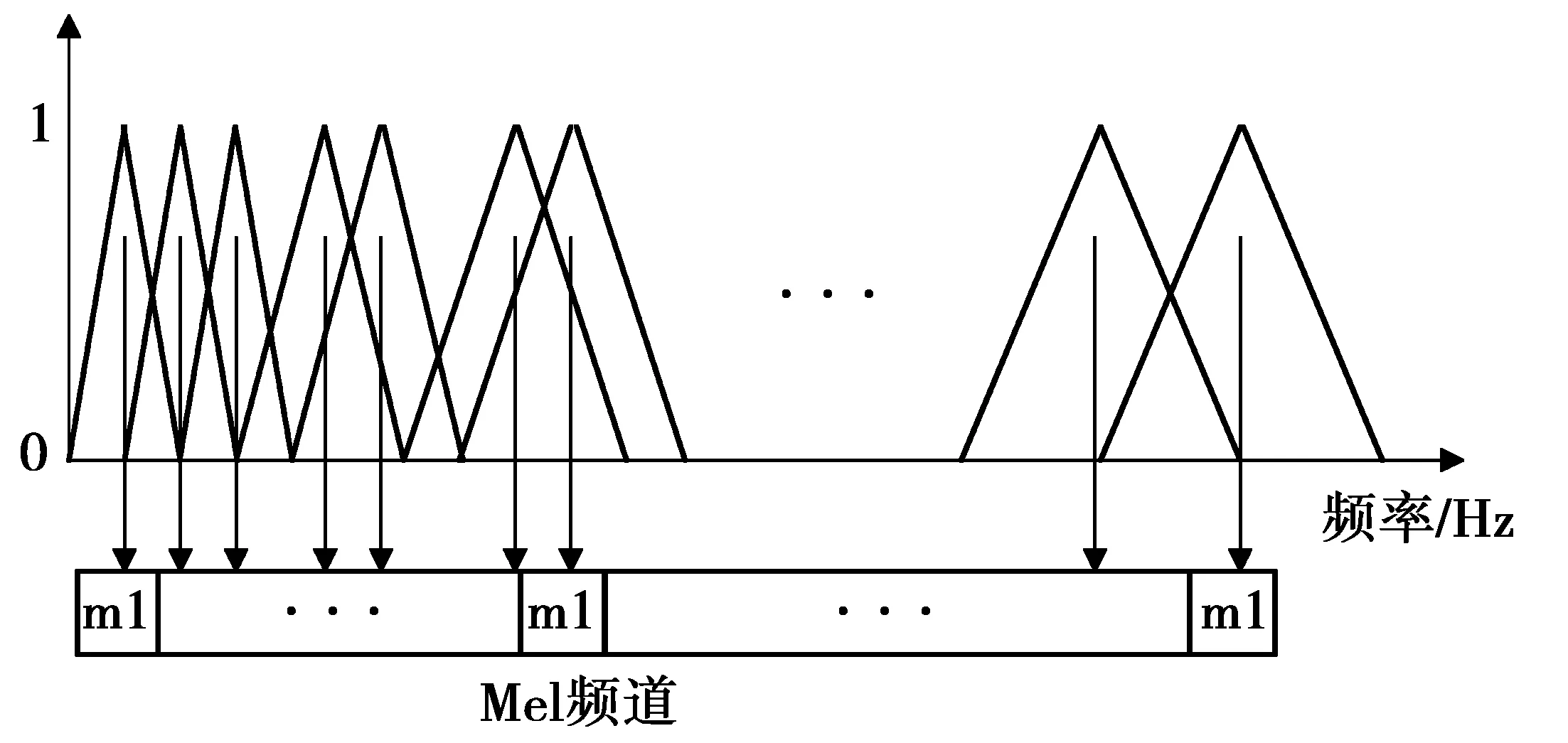
图3 Mel频率尺度滤波器组

(2)
(2)式中,L为滤波器的个数。
根据语音信号的线性频谱Xn(k)求得每个三角滤波器的输出为
(3)
(4)
(4)式中,o(l)可以用式(5)表示为
(5)
(5)式中:fl和fu分别为滤波器的频率范围的最低频率和最高频率;N为FFT变换窗宽,为采样频率;而B-l为B的逆函数,表示为
(6)
2.3Mel-LPC特征参数
一般来说,语音信号是一种非平稳的时变信号,但由于发声器官的状态变化速度与声音的振动速度相比,要缓慢得多,同时为了简化系统模型,通常人们认为非平稳的语音信号在较短的时间内(5-50ms)可以看作一种平稳信号。因此,人们用短时谱来描述语音特征,比如倒谱。通过倒谱的定义可直接求得倒谱系数,然而为了减少不必要的计算,通常情况下也可由线性预测系数递推得到。在求得了LPC参数之后,根据人的听觉特性把上述参数进一步按Mel尺度进行非线性变换,从而求出Mel-LPC特征参数。
(7)
(7)式中:Ck表示倒谱系数;MCk表示美尔倒谱系数;n为迭代次数,k为美尔倒谱阶数,取n=k。当抽样频率为8kHz时,α为频率扭曲因子,通过调节α值可以找到近似于美尔尺度的方法。Mel-LPC算法简单,因为且同时考虑了声道激励和人耳听觉,在移动语音控制领域中具有相当大的优势。
2.4改进的深度特征提取算法
Mel-LPC虽然大大缩短了语音特征参数的提取时间,但其在特定环境下识别率较MFCC有所下降,针对此问题,我们需要对于提取出的Mel-LPC特征参数进行深度特征提取,从而提高识别率。
语音信号x(n)经过预加重、分帧、加窗等预处理工作后,计算每一帧的LPC系数α,α的长度与一帧语音信号的长度相等。每帧的LPC经过快速傅立叶变换(fastFouriertransformation,FFT)得到离散频谱xα(k)。然后取频谱模的平方|xα(k)|2得到离散能量谱。通过Mel滤波器组对上述能量谱进行滤波,计算每个三角滤波器的输出对数能量,再经过余弦变换得到Mel-LPC系数。
接下来是对Mel-LPC特征参数进行微分,首先需要采集语音特征向量的连续动态变化轨迹,这里我们使用特征微分来获取。特征矢量的变化速度由一阶微分获得,特征矢量的变化加速度由二阶微分获得。
D_Feature(j)i=Feature(j)i-Feature(j-1)i
(8)
(8)式中:Feature是原始特征的向量序列,即Mel-LPC:D_Feature是原始特征向量序列的一阶微分;i=0,1,…,P,j=1,2,…,N,P为特征阶数,N为特征向量数。
对于得到的Feature,D_Feature等一系列向量进行组合,因为不同的语音微分向量表现出了说话人语音的不同特征,将它们用特定的比例加权重组,可以进一步凸显固化语音信号特征。将3种不同阶数的特征向量按照不同的加权比率进行重组,见式(9),得到一组全新的二次特征参数F_Mel-LPC。
F_Mel-LPC=
(9)
3实验及分析
3.1算法性能比较
本算法在Inter Pentium 2.5 GHz、内存2 GByte的计算机上,通过Cool Edit采集采样率为44.1 kHz,16位数的采样精度的语音信号,利用短时能量和平均过零率的两级判决方法进行语音端点检测,采用隐马尔科夫模型(hidden markov model,HMM)作为语音识别模型[11-12]。从上万次重复性语音控制指令中,选择10名男性和10名女性的语音指令作为实验样本,在MATLAB上进行仿真实验。我们主要对LPCC,MFCC,与Mel-LPC的二次特征提取时间以及识别率进行比较,分析了系统接收到语音信号后的反应时间,验证了本算法是兼顾实时性与识别率的有效算法。图4表现了频率扭曲因子对F_LPCC,F_MFCC,Mel-LPC及F_Mel-LPC的识别率的影响。
图4中横坐标表示α的值,纵坐标代表了识别率百分比,图4上不同的线分别代表了F_LPCC,F_MFCC,Mel-LPC及F_Mel-LPC算法的识别率随着扭曲因子α的变化曲线。可以看出,当α小于0.2时,F_Mel-LPC算法识别率没有明显高于Mel-LPC,且二者识别率均低于传统F_LPCC。但随着α值的增加,F_Mel-LPC算法由于对原始特征进行了深度提取,所以识别率较Mel-LPC有明显提高,在α=0.3时已经能够达到传统F_LPCC的识别效果,而当α=0.4时,F_Mel-LPC算法识别率要略高于其他几种算法,对于孤立词具有较好的识别效果。
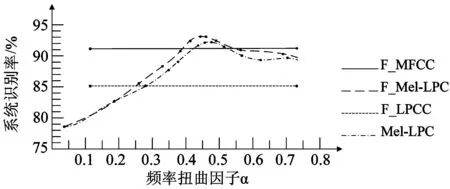
图4 频率扭曲因子对4种算法识别率的影响Fig.4 Influence of frequency twist factor on this four algorithms
在MATLAB平台上进行语音识别特征提取研究及仿真实验,分别运用F_Mel-LPC,F_LPCC,F_MFCC及Mel-LPC对一些常用的孤立词汇进行特征提取,对比其性能。并通过在实际环境下进行语音控制实验,20人说出同一指令,计算其识别率,寻找出性能最佳的孤立词语音特征提取算法。4种算法的识别结果如表1。

表1 4种算法的识别结果
表1统计了F_Mel-LPC算法和几种主流算法的平均识别率,可以看出,经过二次特征提取的F_Mel-LPC对比Mel-LPC识别率有明显提高。下面测试几种语音识别算法的反应时间,在MATLAB中,使用tic/toc重复测试5次,分别测得F_Mel-LPC,F_LPCC,Mel-LPC及F_MFCC 4种算法将一帧语音信号提取所消耗的时间如图5所示。另外,为了减少F_MFCC特征的提取时间,此次测试将MFCC提取步骤中的DFT(discrete Fourier transform)变换调整为FFT(fast Fourier transform),从而使提取MFCC特征的时间减少到原来的十分之一。

图5 5次实验中4种特征提取算法所耗时间对比Fig.5 Time four algorithms spent in five tests
从图5可以看出,由于F_Mel-LPC算法只是在线性预测分析的基础上增加了Mel频率滤波器,并对其进行二次特征提取,因此,对于F_Mel-LPC算法的特征提取时间仅比F_LPCC略高,远小于F_MFCC。而即便是改进了的F_MFCC特征提取方法,它的耗时仍远大于F_Mel-LPC算法。表2是几种特征提取方法的平均提取一帧语音特征的时间。

表2 4种算法提取一帧语音特征的平均时间
由表1、图5以及表2可知,在相同的环境下,F_Mel-LPC算法的识别率分别比F_LPCC和Mel-LPC高出了7.29%和2.48%,且与F_MFCC方法相比,识别率也高出了3.69%;在一帧语音特征提取所耗费的时间上,F_Mel-LPC算法比F_LPCC高8 ms,比Mel-LPC高3 ms,但远低于F_MFCC的47 ms,所以具有更好的实时性。综上所述,F_Mel-LPC算法改进了基于Mel频率的LPC特征提取方法,提高了孤立词的语音识别率,同时具有较短的特征提取时间,具有更好的实时性。
3.2算法有效性验证
为了进一步验证F_Mel-LPC算法的有效性,将“前进、后退、左转、右转、停止”5个语音词汇作为智能轮椅的控制指令。通过让4位受试者分别使用基于传统二次特征提取算法和深度二次特征提取算法对智能轮椅进行重复性实验,完成指定的路线(如图6所示)。设定的轮椅控制方式为搭载2种算法的PC笔记本识别受试者的语音指令,通过串口将指令发送至智能轮椅控制系统,最终实现语音对智能轮椅的基本控制。
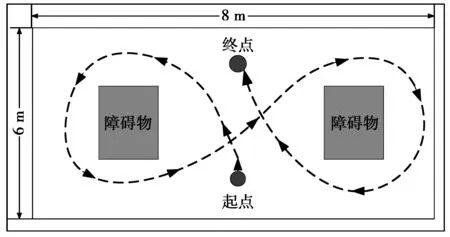
图6 实验路径Fig.6 Path of experiments
图7为试者采用2种算法操作智能轮椅完成该路线时在不同时间段的轨迹。
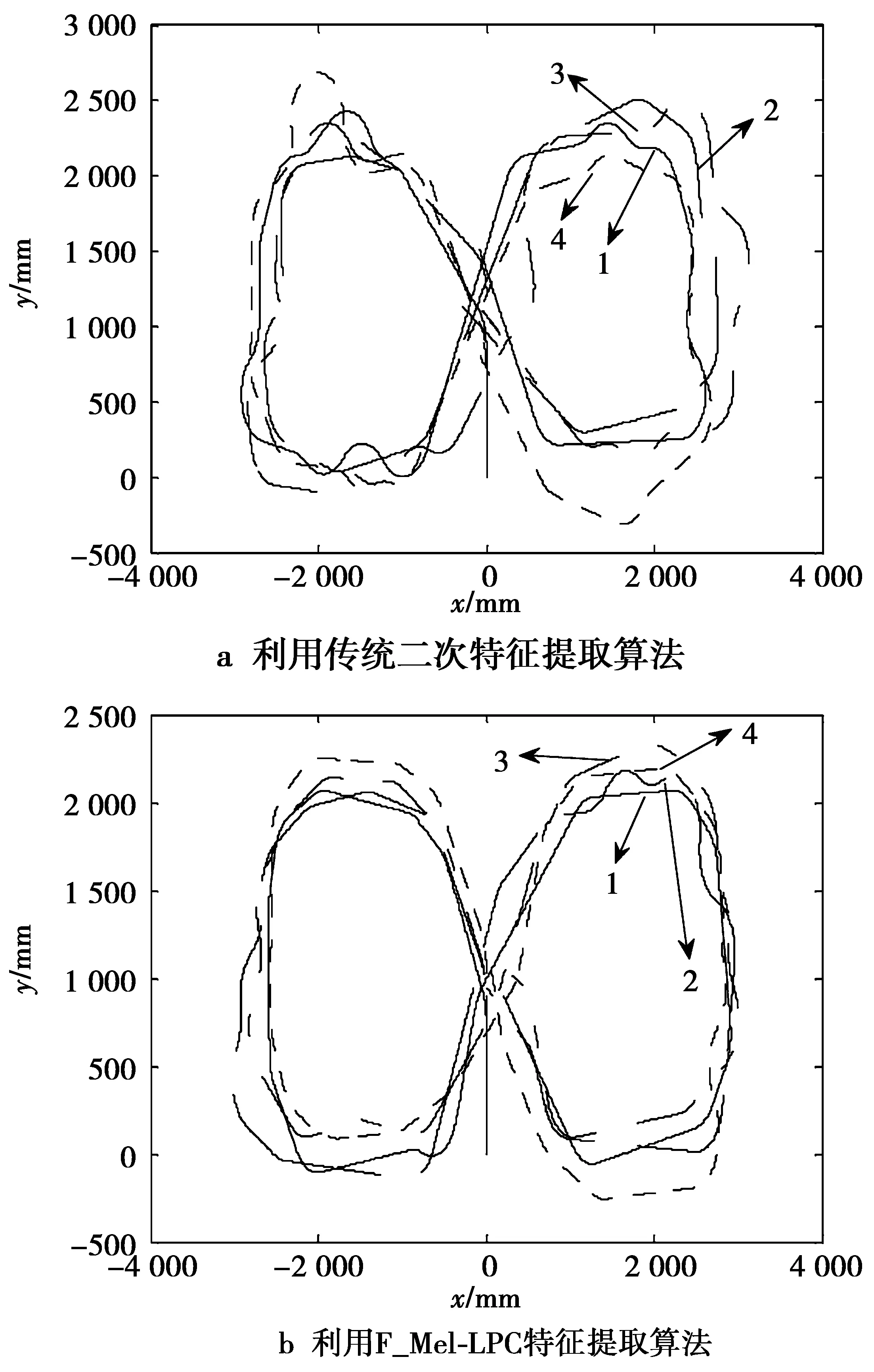
图7 采用2种算法进行人机交互的轮椅轨迹Fig.7 Wheelchair trajectory of using two algorithms
可以看出,由于传统二次特征提取算法的实时性较差,导致智能轮椅反应时间明显比改进算法要长,受试者很难完全掌控智能轮椅的路径,产生了很多误识别动作。而经过优化后的F_Mel-LPC特征提取算法的路径则有明显的改进,整体比较规整,可操控性较强。
表3为采用2种算法的受试者完成指定路线所用的时间。可以看出,受试者在采用传统二次特征提取算法时,总体耗时较长,且稳定性较差。而采用F_Mel-LPC算法进行测试时,平均耗时明显降低,且稳定性大大优于前者。

表3 4位受试者采用2种算法完成指定路线所用时间
4结论
我们提出了一种基于Mel频率下LPC的语音信号深度特征提取方法,该算法既保留了传统LPCC算法的实时性,运算量与传统MFCC算法相比大幅减小,降低了系统的功耗,同时也提高了语音识别系统的识别率。所以,本算法将更适合应用于对系统实时性要求比较高的特定功能语音控制设备,比如对智能轮椅的控制,能够使智能轮椅语音识别系统的时效性和识别准确率得到较大提高。
参考文献:
[1]LAWRENCE R R,RONALD W S. Theory and applications of digital speech processing[M]. Beijing: Publishing House of Electronics Industry,2011.
[2]GIACOBELLO D,CHRISTENSEN M G,MURTHI M N,et al. Sparse linear prediction and its applications to speech processing[J]. Audio, Speech, and Language Processing,2012,20(5):1644-1657.
[3]张毅,何春江,罗元,等. 基于改进感知非均匀谱压缩的鲁棒语音识别算法[J]. 信息与控制,2013,42(5):565-569.
ZHANG Yi,HE Chunjiang,LUO Yuan,et al. A robust speech recognition method based on improved perception Non-uniform spectral compression[J]. Information and Control,2013,42(5):565-569.
[4]ISLAM M B,RAHMAN M M. Performance evaluation of blind equalization for Mel-LPC based speech recognition under different noisy conditions[J]. International Journal of Computer Applications,2013,65(4):4-8.
[5]蔡敏. 基于多特征组合优化的汉语数字语音识别研究[J]. 电子器件,2013,36(2):282-284.CAI Min. Study of Chinese digital speech recognition based on various features combinatorial optimization[J]. Chinese Journal of Electron Devices,2013,36(2):282-284.
[6]KUO S M,LEE B H,TIAN W. Real-Time digital signal processing: fundamentals, implementations and applications[M]. New York:John Wiley & Sons,2013.
[7]李战明,林娟,陈若珠.组合特征和二级判断模型相结合的说话人识别[J].计算机工程与应用,2011,47(10):180-182.
LI Zhanming,LIN Juan,CHEN Ruozhu. Speaker recognition method using combined features extraction and Two-stage decision model[J]. Computer Engineering and Applications,2011,47(10):180-182.
[8]项要杰,杨俊安,李晋徽,等.一种适用于说话人识别的改进Mel滤波器[J].计算机工程,2013,39(11):214-217.
XIANG Yaojie,YANG Junan,LI Jinhui, et al. An improved Mel-frequency filter for speaker recognition[J]. Computer Engineering,2013,39(11):214-217.
[9]邹欣,李万龙,刘琚. 基于二维 ICA 变换的语音特征提取[J]. 山东大学学报:工学版,2007,37(4):85-88.
ZOU Xin,LI Wanlong,LIU Ju. Speech feature extraction based on 2-D independent component analysis[J]. Journal of Shandong University:Engineering Science,2007,37(4):85-88.
[10] 姚敏锋,李心广,杨佳能.基于语音特征聚类的HMM语音识别系统研究[J].微计算机信息,2012,28(10):458-460.YAO Minfeng,LI Xinguang,YANG Jianeng. The study of speech recognition based on sound characteristic clustering and HMM[J]. Microcomputer Information,2012,28(10):458-460.
[11] HSU D,KAKADE S M,ZHANG T. A spectral algorithm for learning hidden Markov models[J]. Journal of Computer and System Sciences,2012,78(5):1460-1480.
A further speech signal features extraction algorithm based on LPC Mel frequency scale
LUO Yuan1, WU Chengjun1, ZHANG Yi2, LI Xiaosong2
(1. Key Lab of Optical Sensing Information and Transmission Technology, Chongqing University of Posts and Telecommunications,Chongqing 400065, P.R. China;2. Engineering Research & Development Center of Information Accessibility,Chongqing University of Posts and Telecommunications, Chongqing 400065, P.R. China)
Abstract:According to the bad real-time performance of the traditional further speech signal features extraction algorithm in the premise of ensuring the recognition rate, a further speech signal features extraction algorithm based on linear predictive coefficient(LPC) Mel frequency scale is put forward in this paper. This method transforms LPC with Mel-frequency in a nonlinear way, calculates the derivative, high order differential and combines the feature according to a certain proportion to realize a new features parameter which takes both the channel incentives and the human auditory into account. So the calculation quantity of the traditional speech signal further features extraction is decreased sharply. The real-time performance of the system is improved in the premise of ensuring the recognition rate. Through the intelligent wheelchair platform to verify the validity of the algorithm, a lot of experiments show that the problem of real-time performance is not good of traditional algorithm can be improved effectively; this algorithm can improve the real-time performance and the practicability, on the basis of ensuring the recognition rate of the further features extraction.
Keywords:speech recognition;linear prediction coefficient;Mel-frequency cepstrum coefficients;Mel-LPC algorithm;further features extraction
DOI:10.3979/j.issn.1673-825X.2016.02.006
收稿日期:2014-12-04
修订日期:2015-10-04通讯作者:吴承军wucj.summer@foxmail.com
基金项目:重庆市自然科学基金重点项目(CSTC2015jcyjB0241);重庆市教委科技项目(KJ13051)
Foundation Items:The Key Science and Tchnology Project of CQ CSTC (CSTC2015jcyjB0241);The Scientific and Technology Research Project of Chongqing Municipal Education Commission(KJ13051)
中图分类号:TN912.3/TP311
文献标志码:A
文章编号:1673-825X(2016)02-0174-06
作者简介:

罗元(1972-),女,贵州贵阳人,教授,博士,主要研究领域为信号与信息处理,数字图像处理。E-mail:luoyuan@cqupt.edu.cn。

吴承军(1990-),男,江苏徐州人,硕士研究生,主要研究领域为语音识别与智能机器人。E-mail:wucj.summer@foxmail.com。

张毅(1966-),男,重庆人,教授,博士生导师,博士后,主要研究领域为智能机器人及应用、生物信号处理及应用、信息无障碍技术。E-mail:zhangyi99@263.net。

黎小松(1988-),男,湖南邵阳人,硕士研究生,主要研究领域为语音识别。 E-mail: lxscqyddx@163.com。
席兵(1972-),男,江苏沛县人,硕士,主要研究领域为信号处理、通信网测试仪器仪表。E-mail:xibing@cqupt.edu.cn。
(编辑:张诚)
