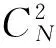基于Hadoop的图书推荐系统研究与设计
2016-07-02南磊
南 磊
(1.江苏省信息中心 南京 210013)(2.计算机软件新技术国家重点实验室(南京大学) 南京 210023)
基于Hadoop的图书推荐系统研究与设计
南磊1,2
(1.江苏省信息中心南京210013)(2.计算机软件新技术国家重点实验室(南京大学)南京210023)
摘要经过近些年的发展,图书市场在种类规模和总体数量等方面有了长足的进步。但是同时也带来了图书过多,使得读者难以选择合适图书的困难。常规的明细分类使得读者可以针对每一种类型的书进行选择,但是其每个分类下依然有成千上万中书籍。论文完成的是一种基于Apriori算法创建关联规则的图书推荐在Hadoop上的实现。利用在豆瓣读书上获取的图书评论数据,使用Hadoop生成图书的K-频繁集,并计算相关的图书推荐置信度。论文实现的算法能够高效地为读者提供推荐服务。
关键词MapReduce; 并行计算; 关联规则; 图书推荐; Hadoop
Class NumberTP311
1引言
近几年,由于多终端接入网络的便利性,越来越多的读者开始利用因特网来记录自己对各种事务的评价,这就形成了针对不同商品的庞大的评论数据集。其中图书的种类繁多,内容相对于小商品、电影、音乐等需要比较长的时间才可以被读者体会,利用其他读者对不同书籍的评价和感兴趣程度为其他读者提供阅读推荐成为推广文化和扩大书籍销售的一种重要手段。
传统上要实现这样的推荐系统可以采用Apriori算法[2]。这个算法基于关联规则,挖掘出数据集中有较大联系的数据项。并以此作为依据给读者推荐其可能感兴趣的书籍。但Apriori算法存在一个问题,就是它需要不断地去扫描整个数据库,效率很低。在面对一些访问量较大的网站时,客户的数量和其留下的有用信息都是以百万的数量级来表示的,在面对这种海量数据时Apriori算法在单机上的运行比较慢,并且可能超出了普通主机、大型机的性能限制。基于以上想法,我们采用了基于MapReduce的方法[1],用并行优化后的算法来进行处理,期望以一种可以接受的成本快速地实现Apriori算法在图书推荐上的应用。
2相关技术
2.1网络爬虫
网络爬虫是捜索引擎抓取系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地形成一个或联网内容的镜像备份[7]。
2.1.1网络爬虫的基本结构及工作流程
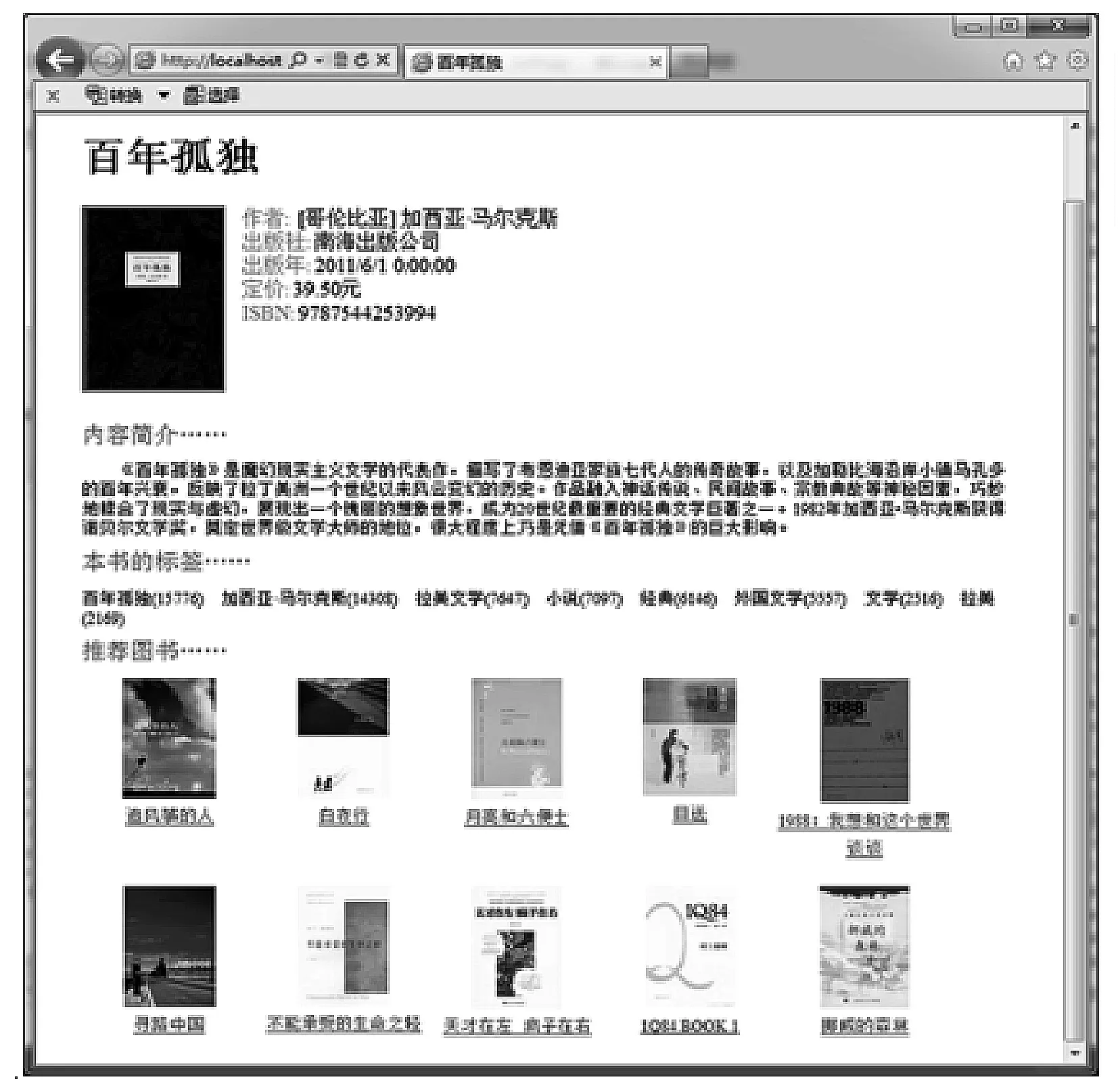
一个通用的网络爬虫的框架如图1所示。
图1 网络爬虫基本原理图
网络爬虫的基本工作流程如下:
1) 首先选取一部分精心挑选的种子URL;
2) 将这些URL放入待抓取URL队列;
3) 从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的IP,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列;
4) 分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
2.1.2抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面是几种常见的抓取策略:
1) 深度优先遍历策略;
2) 宽度优先遍历策略;
3) 反向链接数策略;
4) Partial PageRank策略;
5) OPIC策略策略;
6) 大站优先策略。
2.2数据挖掘相关算法
2.2.1关联规则
关联规则是用来描述事物之间的联系,是用来挖掘事物之间的相关性。挖掘关联规则的核心是通过统计数据项获得频繁项集,现有的算法主要有Apriori、PARTITION、FP2growth及抽样算法等。
设I={i1,i2,…,im}是项的集合,设任务相关的数据D是数据库事务的集合,其中每个事务T是项的集合,使得A包含于I。每一个事务有一个标志符,称作TID,设A是一个项集,事务T包含A,关联规则是形如A→B的蕴涵式,并且A∩B=∅。
定义1:可信度/置信度(Confidence)。可信度即是“值得信赖性”。设A,B是项集,对于事务集D,A∈D,B∈D,A∩B=∅,A→B的可信度定义为:可信度(A→B)=包含A和B的元组数/包含A的元组数。
定义2:支持度(Support)。支持度(A→B)=包含A和B的元组数/元组总数。支持度描述了A和B这两个项集在所有事务中同时出现的概率。
定义3:强关联规则。设min_sup是最小支持度阈值;min_conf是最小置信度阈值。如果事务集合T中的关联规则A→B同时满足Support(A→B)>=min_sup,Confidence(A→B)>=min_conf,则A→B称为T中的强关联规则。而关联规则的挖掘就是在事务集合中挖掘强关联规则。
2.2.2Apriori算法[1]
Apriori算法是R.Agrawal和R.Srikant在1994年提出的基本关联规则挖掘算法。该算法的核心思想是基于频集理论的一种递推方法,目的是从数据库中挖掘出那些支持度和信任度都不低于给定的最小支持度阈值和最小信任度阈值的关联规则。
算法通过迭代的方法反复扫描数据库来发现所有的频繁项目集。通过频繁项集的性质知道,只有那些确认是频繁项的候选集所组成的超集才可能是频繁项集。故只用频繁项集生成下一趟扫描的候选集,即Li-1生成Ci(其中:L为频繁项集的集合,C为候选项集的集合,i为当前扫描数据库的次数),在每次扫描数据库时只考虑具有同数目数据项的集合。Apriori算法可以生成相对较少的候选数据项集,候选数据项集不必再反复地根据数据库中的记录产生,而是在寻找k频繁数据项集的过程中由前一次循环产生的k-1频繁数据项集一次产生。算法的描述如下所示。
k= 0;//k表示扫描的次数
L=∅;
C1=I; //初始把所有的单个项目作为候选集
Repeat
k=k+ 1;
Lk=∅;
For eachIi∈Ckdo
Ci= 0;//每个项目集的初始计数设为0
For eachtj∈Ddo
For eachIi∈Ckdo
IfIi∈tjthen
Ci=Ci+ 1;
For eachIi∈Ckdo
IfCi>=(s×|D|)then//|D|为数据库中事务项的总数
Lk=Lk∪Ii;
L=L∪Lk;
Ck+ 1=Apriori-Gen(Lk);
UntilCk+ 1=∅
2.3并行计算相关技术
2.3.1MapReduce[5]
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念“Map(映射)”和“Reduce(化简)”和它们的主要思想都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(化简)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
2.3.2Hadoop[6~8]
Hadoop是一个分布式基础架构,可以在不了解分布式底层信息的情况下,开发分布式或秉性应用程序,充分利用集群的威力高速运算和存储,它是云计算的主要架构之一。Hadoop具有以下一些特点:
· 扩容能力:能可靠地存储和处理PB级别数据;
· 成本低:可以通过普通微机组成的集群来分发以及处理数据。这些服务器群总计可达数千个节点;
· 高效率:通过分发数据,Hadoop可以并行地处理数据,这使得处理非常的快速;
· 可靠性:Hadoop能自动地维护数据的多份复制,并且在任务失败后能自动地重新部署计算任务。
Hadoop是Google MapReduce算法的开源实现,MapReduce的执行流程主要包括Map和Reduce两步。一个任务启动后,会在集群上按各个节点的能力配置产生相应个数的Map进程。每个Map进程处理一个具有key-value特性的数据分块,产生一组key-value对形式的结果。当一个节点上的某个Map进程执行结束后,集群的Hadoop架构会在这个节点上启动一个新的Map进程处理下一个分块。而Reduce进程对每个Map进程产生的key-value对进行合并,完成计算。
3总体设计
通过以下几个步骤实现图书推荐系统:
1) 网络源数据获取;
2) 对源数据进行抽取和清洗,以达到实验算法的需求;
3) Apriori算法在Hadoop上的实现;
4) 最终界面的实现以及相关测试。
其中数据来源有两个部分:
1) 图书列表由图书馆网站获得;
2) 以图书馆图书为基础,获取每一本图书在豆瓣读书(book.douban.com)上的用户评论。
3.1设计思路
基于MapReduce的Apriori并行策略,其候选项集的支持数统计类似于单词计数过程,因此在海量数据且支持度较低时,算法产生了大量的候选项集,从而产生了大量〈itemset,1〉的〈键,值〉对,增加了MapReduce系统的负担。比较单词计数与候选项集的支持数统计不难看出,单词计数要统计的单词是未知,因此,单词计数思想较适合找出1-频繁项集。然而,候选项集的支持数统计要统计的候选项集是已知的,它是由频繁项集通过自身的连接而生成的。因此,为提高候选项集支持数统计的效率,大量减少键/值对的产生,将Apriori数据分割的分组思想应用在候选项集的支持数统计阶段,实现候选项集支持数的分组统计,较大幅度地提高了算法的运行效率。实验拟采用的最基本的MapReduce并行的Apriori分组统计算法思路为:采用类似单词计数的过程并行扫描数据库,找出满足最小支持度的1-频繁项集L1;L1通过自身连接产生2-候选项集C2,采用候选项集支持数的分组统计算法统计C2的支持数,形成2-频繁项集L2;相同步骤,L2产生L3,如此迭代循环,直到没有新的k-频繁项集产生。
除此之外我们希望尝试的另外一种可以加速运行的算法的具体步骤为:将原数据库划分为n组,使各组数据足够载入内存运行,并分别统计候选项集在各组数据中的支持数,称为候选项集的局部支持数;合并候选项集在各组数据中的支持数,形成最后候选项集的全局支持数。
3.2期望结果
我们计划通过MapReduce的方式在Hadoop集群上求解出图书推荐系统所需要的频繁项集,之后以关系数据库的形式来存放这些数据。当用户在网站上进行图书阅读记录时会根据由频繁项集得到的图书之间的关系给用户提供可能感兴趣的图书推荐。这种推荐基于众多用户的真实体验,利用简单的算法在大数据中更准确地体现了用户的需求。
4实现过程
4.1获得数据
实验中需要大量图书的评论作为Apriori算法挖掘关联规则的源数据,但是目前网上没有国内图书评论的数据库。因此本文采用南京大学图书馆的藏书作为图书评论的源,并以此为基础从国内读书比较流行的网站豆瓣读书上来获取用户的评论。
在第一步获取图书馆藏书列表时,利用图书馆以《中图法》为标准定义的分类检索所有图书的接口将图书按类别进行遍历,获取其中关于图书的基本信息(ISBN,图书名,作者等),共获得图书549621册。按类别统计如表1所示。

表1 图书总量
然后使用豆瓣读书所提供的API来获取所有图书的评论信息,豆瓣读书API如表2所示。

表2 豆瓣图书API列表
之后共获得图书评论339621条,其中涉及图书39186本。
4.2利用MapReduce实现Apriori算法
以上一部分所得数据为基础,采用Apriori算法来计算图书推荐的关联规则。根据上文所描写的Apriori算法,获得二项频繁集的过程主要有三个部分: 1) 计算每本图书的支持度; 2) 统计二项频繁集每个元组的支持度; 3) 计算二元组中图书A到图书B的置信度。
1) 整理数据
由豆瓣读书得到的数据为{ISBN,{{用户ID,用户名,评分},…}}的集合,为进行二项频繁集的统计我们需要将其转换为{用户ID,{{ISBN},…}}的形式。将爬取的以ISBN为区分的评分数据转换为以用户ID为区分的数据。此处的MapReduce设计为在Map阶段对每行数据进行分析,然后以用户ID为key,以ISBN为value将其传入到下一阶段的Reducer中;Reducer阶段将key相同,即用户ID相同的记录进行合并,合并为{用户ID ISBN;ISBN;ISBN}的格式以方便之后支持度和二项频繁集的计算,其主要代码如下:
publicclassPreJobMapperextends Mapper〈Object, Text, Text, Text〉 {
//Input:“ISBNUser_ID/User_Name/Rate;…”
//Output: “User_ID ISBN Rate”
//用于将形如“ISBN User_ID/User_Name/Rate;…”的输入转换成形如“User_ID ISBN Rate”的输出
publicvoidmap(Object key, Text value, Context context)
throwsIOException, InterruptedException {
String bookRate[] = value.toString().split(" ", 0);
String rates[] = bookRate[1].split(";", 0);//得到每一条ISBN的用户评分集合
for(inti=0;I String rateEntry = rates[i];//得到格式如下的字符串rateEntry:用户ID,用户名,评分 String rateUseID = rateEntry.split("/", 0)[0];//得到用户ID String rate = rateEntry.split("/", 0)[2];//得到用户评分 context.write(new Text(rateUseID), new Text(bookRate[0]+" "+rate));//拼接如下格式的字符串作为输出:用户ID ISBN 评分 } } } publicclassPreJobReducerextends Reducer〈Text, Text, Text, Text〉 { //Input:“User_ID ISBN Rate” //Output: “User_ID ISBN1;ISBN2;…” //用于合并同一个用户所评分的书 publicvoid reduce(Text key, Iterable〈Text〉 values, Context context) throwsIOException, InterruptedException { Text value = newText(); String strISBNs = ""; Iterator〈Text〉it=values.iterator(); while(it.hasNext()){ String isbn = it.next().toString().split(" ", 0)[0]; if(strISBNs==""||!strISBNs.contains(isbn)) strISBNs += isbn+";"; } //判断当前ISBN是否已存在于该用户的ISBN列表中,如不存在,直接添加在该用户列表后面 context.write(key, new Text(strISBNs));//以User_ID作为key,该用户评过分的书目ISBN列表作为value输出 } } 2) 计算支持度 支持度是每本图书在数据集中出现的次数,即每本图书的评论数量。计算支持度时需要在Map阶段将第一部所得数据转换成以ISBN为key,以数字1为value的记录,在Reducer阶段再统计相同ISBN的记录条数,即可得到图书的支持度。 3) 计算二项频繁集 publicclassFreqItemSet2Mappeextends Mapper〈Object, Text, Text, Text〉 { //Input: “User_ID ISBN1;ISBN2;…” //Output:“ISBN1;ISBN2 1” //统计所有出现过的图书二元组,例如一个用户读过A,B,C三本书,那么会产生(A,B),(A,C),(B,C)这三个二元组 publicvoidmap(Object key, Text value, Context context) throwsIOException, InterruptedException { Text newValue = newText(); String row[] = value.toString().split(" ", 0); String allisbn[] = row[1].split(";", 0);//得到该用户评分的所有ISBN列表 for (inti = 0; i for (int j = i + 1; j context.write(new Text(allisbn[i] + ";" + allisbn[j]), new Text("1;" + row[0])); context.write(new Text(allisbn[j] + ";" + allisbn[i]), new Text("1;" + row[0])); }//以(A,B)(B,A)作为两种独立的输出,防止hadoop将其当做不同的二元组造成支持度计算错误 } } publicclassFreqItemSetReducerextends Reducer〈Text, Text, Text, Text〉 { //Input: “ISBN1;ISBN2 1” //Output:“ISBN1;ISBN2 support” //合并计算相同的二元组出现的个数,并计算支持度 publicvoid reduce(Text key, Iterable〈Text〉 values, Context context) throwsIOException, InterruptedException { int total=0; Text value = newText(); String strUserIDs = ""; Iterator〈Text〉it=values.iterator(); while(it.hasNext()){ String temp = it.next().toString(); strUserIDs+= temp.split(";", 0)[1]+";"; ++total; } //统计相同的ISBN二元组出现的个数,即有多少用户同时读过相同的两本书 if(total>=2) context.write(key, new Text(total+","+strUserIDs)); //选取支持度大于2的二元组 } } 4) 计算置信度[1] 置信度是表示图书之间相关性的属性,是生成关联规则的关键,表达的是从事物A产生事物B的可信度,其计算方式为式(1): (1) 计算置信度需要知道二元组的支持度和每本图书的支持度,为此需要步骤2)和3)中的数据,需要两个表关联操作。将二项频繁集中二元组{A,B}的支持度除以二元组中图书A的支持度即可得到从图书A生成图书B的可信度。以二元组中图书A的ISBN为Key,将图书A的支持度和二元组{A,B}的支持度分别作为value,这样在Reduce的过程中做好区分二元组和图书A的支持度之后就可以计算出二元组{A,B}中图书A对图书B的置信度。 5) 其他 因为其他K-频繁项集(K>2)都是2-频繁项集的子集,只要将步骤3)中得到的2-频繁项集数据处理为步骤1的结果,并再如步骤3)一样处理就可以得到3-频繁项集等。 4.3运行结果 实验所得2-频繁项集及其置信度数据如图2所示。 为便于用户使用,将该结果存储在关系数据库SQLServer2008中,并用ASP.Net MVC开发了一个搜索图书推荐的网站。推荐网站的查询界面如图3所示,查询结果如图4所示。 图2 2-频繁项集及其置信度 图3 图书推荐系统查询界面 图4 查询结果 4.4存在的问题及改进 由于图书推荐系统中图书项是很庞大的,且用户选择读书有一定的随机性,所以想要生成满足一定支持度和置信度的频繁项集是很困难的,针对这个问题,做了如下改进: 1) 只生成到二次频繁项集。因为继续往后生成更高的频繁项集得到的结果会很少,对任意图书的推荐并没有很大的意义,且增加了计算量。而二次频繁项集相对是比较容易生成,且基本涵盖了大部分的图书项,方便对任意图书进行有效的推荐。 2) 不设定具体的最小支持度和最小置信度,只是统计二次频繁项集时出现的具体个数,在具体查询某一具体书籍时,寻找与它相关的所有二次频繁项集,并查看相关二次频繁项集的个数,这个个数即可反应出该二元组规则的一个支持度和置信度。我们根据这个个数进行从大到小的排序,选取前五个作为推荐书籍。这样一来,可以有效杜绝因为不同书籍出现的频次不同,导致有的书推荐很多,有的书无书可推的情况。 5结语 本文完成的是一种基于Apriori算法创建关联规则的图书推荐在Hadoop上的实现。利用在豆瓣读书上获取的图书评论数据,使用Hadoop生成图书的K-频繁集,并计算相关的图书推荐置信度。通过简单的操作,就可以在其上实现Apriori算法,并且具有相当高的运行速度。项目中也表现出了图书评论集中的问题,有相当一部分的书籍由于没有多少人阅读和评论,出现了无法进行推荐的情况。此外还有一部分数据虽然ISBN等不相同,但是是同一本书的不同版本,也应将其合并为同一本书进行推荐,这部分会作为下一步工作的一部分进行对该图书的推荐。 参 考 文 献 [1] 黄立勤,柳燕煌.基于MapReduce并行的Apriori算法改进研究[J].福州大学学报,2010,39(5):680-685. HUANG Liqin, LIU Yanhuang. Research on improved parallel Apriori with MapReduce[J]. Journal of Fuzhou University,2010,39(5):680-685. [2] 戎翔,李玲娟.基于MapReduce的频繁项集挖掘方法[J].西安邮电学院学报,2011(7):37-39. RONG Xiang, LI Lingjuan. Frequent item set mining method based on MapReduce[J]. Journal of Xi’an University of Posts and Telecomunications,2011(7):37-39. [3] 余楚礼,肖迎元,尹波.一种基于Hadoop的并行关联规则算法[J].天津理工大学学报,2011,27(1):26-30. YU Chuli. A parallel algorithm for mining frequent item sets on Hadoop[J]. Journal of Tianjin University of Technology,2011,27(1):26-30. [4] 郑志娴.基于云计算的Apriori算法设计[J].莆田学院学报,2014,21(5):61-64. ZHENG Zhixian. The Design of Apriori Algorithm Based on Cloud Computer[J]. Journal of Putian University,2014,21(5):61-64. [5] 郑祥云.基于主题模型的个性化图书推荐算法[J].计算机应用,2015,35(9):2569-2573. ZHENG Xiangyun. Personalized book recommendation algorithm based on topic model[J]. Journal of Computer Applications,2015,35(9):2569-2573. [6] 王东雷.基于MapReduce的大数据流程处理方法[J].计算机应用,2013,33(S2):57-59,127. WANG Donglei. MapReduce-based method for large data flow processing[J]. Journal of Computer Applications,2013,33(S2):57-59,127. [7] 王淑芬.基于Hadoop的广域网分布式主题爬虫系统框架[J].计算机工程与科学,2015,37(4):670-675. WANG Shufen. A framework of WAN distributed topic crawling system based on Hadoop[J]. Computer Engineering & Science,2015,37(4):670-675. [8] 李建江.MapReduce并行编程模型研究综述[J].电子学报,2011,39(11):2635-2640. LI Jianjiang. Survey of MapReduce Parallel Programming Model[J]. Acta Electronic Sinica,2011,39(11):2635-2640. [9] 杜江,张铮.MapReduce并行编程模型研究综述[J].计算机科学,2015,42(6):537-564. DU Jiang, ZHANG Zheng. Survey of MapReduce Parallel Programming Model[J]. Computer Science,2015,42(6):537-564. [10] 王雪蓉.云模式用户行为关联聚类的协同过滤推荐算法[J].计算机应用,2011,31(9):2421-2425. WANG Xuerong. Cloud pattern collaborative filtering recommender algorithm using user behavior correlation clustering[J]. Journal of Computer Application,2011,31(9):2421-2425. Research and Design of Hadoop-Based Book Recommendation System NAN Lei1,2 (1. Jiangsu Information Center, Nanjing210013)(2. State Key Laboratory for Novel Software Technology(Nanjing University), Nanjing210023) AbstractAfter years of development, the book market in the type of scale and the overall number of such areas have made considerable progress. But at the same time, it brings too many books, which makes it difficult for readers to choose the right books. The general classification allows the reader to choose from each type of book, but there are still thousands of books under each category. In this paper, a kind of book recommendation based on the Apriori algorithm to create the association rules is realized in Hadoop. Using the book review data obtained from the book review, Hadoop is used to generate the K-frequent sets of books, and the relevant books recommended confidence is calculated. The algorithm can efficiently provide the recommendation service for readers. Key WordsMapReduce, concurrent computation, association rules, book recommendation, Hadoop 收稿日期:2015年12月5日,修回日期:2016年1月26日 基金项目:国家自然科学基金面上项目(编号:61272418)资助。 作者简介:南磊,男,博士研究生,助理研究员,研究方向:大数据、无线网络、软件工程等。 中图分类号TP311 DOI:10.3969/j.issn.1672-9722.2016.06.016