分类变量缺失数据处理方法有效性的比较研究*
2016-06-24哈尔滨医科大学卫生统计教研室150086肖亚明陈永杰王玉鹏刘美娜
哈尔滨医科大学卫生统计教研室(150086) 肖亚明 陈永杰 王玉鹏 刘美娜
分类变量缺失数据处理方法有效性的比较研究*
哈尔滨医科大学卫生统计教研室(150086) 肖亚明 陈永杰 王玉鹏 刘美娜△
【提 要】 目的 比较删除法(deletion methods,DM)、基于对数线性模型的多重填补法(multiple imputation of category variables using log-linear model,MILL)及基于潜在类别模型的多重填补法(multiple imputation based on latent class model,MILC)处理分类变量缺失数据的效果,并将MILC应用于实例数据的分析。方法 利用R语言产生不同缺失机制、缺失率和样本含量的多变量缺失模拟数据,运用DM、MILL和MILC处理形成完整数据集并进行logistic回归分析,通过回归系数的偏倚、均方根误差、稳定度和标准误偏倚评价各方法的处理效果。结果 模拟实验表明当缺失率为5%时,三种方法处理效果均较好;随着缺失率的增大,MILL和MILC的各项评价指标均优于DM,且MILC的准确度高于MILL。三种方法处理效果均表现为完全随机缺失优于随机缺失、样本含量1000优于样本含量500。应用MILC对实例数据填补后标准误减小,回归系数估计更准确。结论 本文应用MILL和MILC两种多重填补方法处理分类变量缺失数据均可减少缺失导致的参数估计偏倚。当缺失率>5%、样本含量1000时,建议应用MILC处理分类变量缺失数据。
【关键词】分类变量 缺失数据 多重填补 潜在类别模型 对数线性模型
缺失数据问题普遍存在于横断面研究、队列研究和实验性研究[1],尤其在问卷调查中,即使对调查设计和问卷进行了严谨的科研设计,被调查者仍易忽略题目或不作答而导致数据缺失,这对统计分析中的参数估计、检验效能有不同程度的影响[2]。删除法(deletion method,DM)直接删除含缺失值的个体以期得到完整数据集,是应用最广且简单易行的缺失数据处理方法,也是几乎所有统计软件默认的方法。随着人们对缺失数据的认识加深,缺失数据处理方法的策略不断推新,Rubin[3]首次提出多重填补(multiple imputation),经过Schafer,Meng等人完善并综合形成系统理论,成为目前处理缺失数据的基本思想。基于对数线性模型的多重填补法(multiple imputation of category variables using log-linear model,MILL)[4]以饱和对数线性模型作为填补模型,易于理解和实现;基于潜在类别模型的多重填补法[5](multiple imputation based on latent class model,MILC)结合潜在类别模型和多重填补的思想对数据进行填补,参数估计较饱和对数线性模型简单且灵活。目前国内没有MILL和MILC的比较研究,本文拟针对删除法、MILL及MILC进行数据模拟和处理效果评价,为分类变量缺失数据的处理提供相应依据,并将MILC应用于慢性心力衰竭的院内死亡影响因素的研究。
原理与方法
多重填补法的基本思想:通过填补模型为每个缺失值产生M个可能的填补值,形成M个完整数据集,通过分析模型对每个完整数据集进行分析得到参数集,综合M个参数集[3]进行最终的统计推断。
1.基于对数线性模型的多重填补法
对数线性模型主要通过对列联表单元格的频数取对数分析变量间的关系,这些关系可包含变量的高阶交互项,当模型中涵盖变量间所有高阶交互项时称该模型为饱和模型。MILL处理缺失数据时首先对不含缺失的完整数据集进行对数线性模型分析得到原始各响应变量的类别概率(response category probability),应用贝叶斯原理从这一参数的后验分布中获取M个参数;分别根据每个参数对含缺失的个体进行填补值的抽取。
2.基于潜在类别模型的多重填补法
潜在类别模型(latent class model,LCM)是利用潜在类别解释外显变量之间复杂关联性分析方法,属于潜变量分析的一种。Vermunt首次将LCM作为填补模型对分类变量缺失数据进行多重填补,填补模型中加入指示变量rij表示数据缺失情况,rij=1表示yij有观测值,rij=0表示观测值缺失,MILC模型见公式(1)。
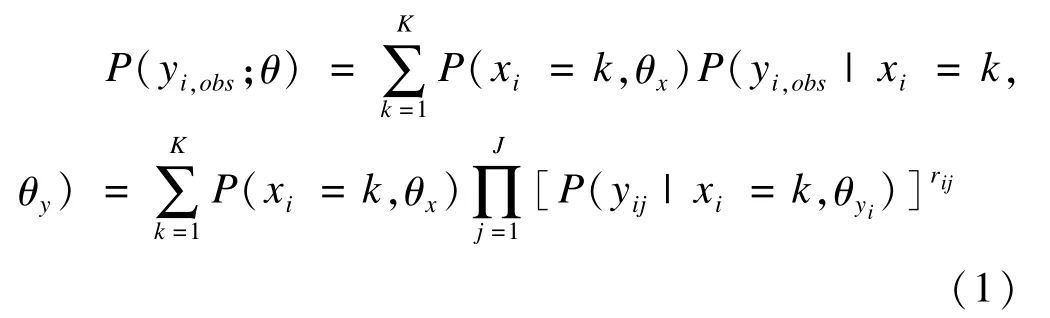
MILC填补步骤[5-6]:首先对含缺失的数据集进行非参bootstrap抽样获得M个数据集;每一数据集经过LCM分析计算潜在类别概率和外显变量的条件概率;观测根据后验类别属性概率(posterior class membership probabilities)分类到适当的潜在类别中,计算公式见公式(2);含缺失的观测根据所在潜在类别中变量的多项分布概率为缺失值选取填补值。
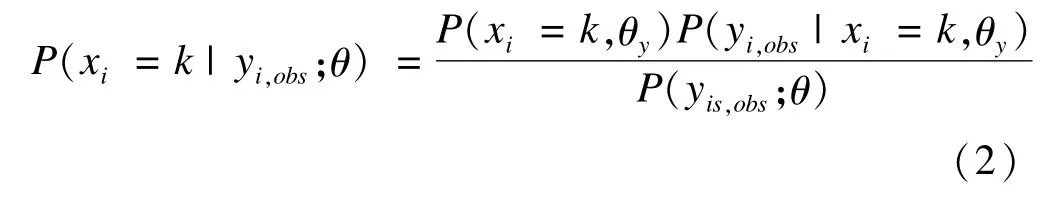
模拟实验
1.参数设置
(1)原始数据
因变量y和五个自变量x1~x5均为二分类变量,取值为0、1;自变量x1~x5间相关关系满足对数线性模型,见公式(3);因变量由logistic回归模型产生,见公式(4)。
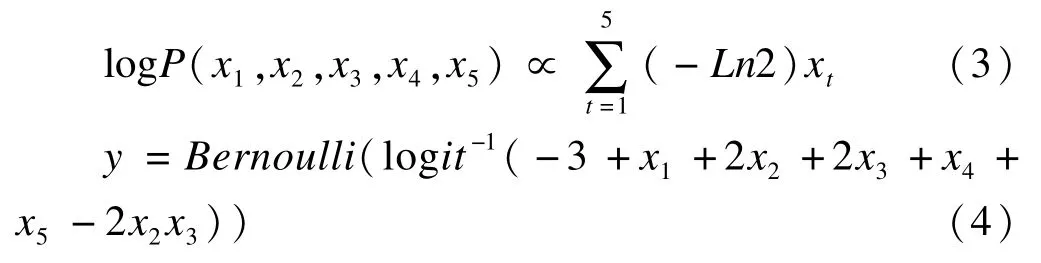
(2)缺失数据
自变量x1和x2设置为缺失变量。缺失机制为MAR时,x1的缺失与x3及x4相关,x2的缺失与x5及y相关,参数设置见公式(5)和(6)。
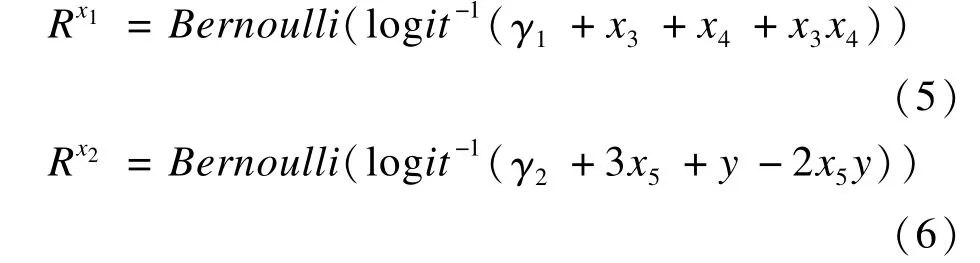
(3)样本含量设置为500、1000;缺失机制设置为MAR、MCAR;单变量缺失率设置为5%、20%、40%;填补次数M =5次;MILC中潜在类别个数K =5;各参数组合均重复模拟500次。
2.评价指标
评价指标包括参数偏倚,稳定度,均方根误差和标准误偏倚。
3.软件实现
模拟实验MILL选择饱和模型,使用R语言“cat”软件包[7]实现。MILC实现的软件很多,如Latent GOLD 4.0/4.5[3],LEM,Mplus及R语言“poLCA”软件包[8],本文模拟实验采用Latent GOLD 4.5。
4.模拟实验结果
表1可见三种方法处理数据的偏倚随着缺失率的增大而增大,样本含量大时偏倚减小,缺失机制为MAR的偏倚比MCAR大,总体上βa的偏倚小于βb及βbc。当缺失率为5%时,DM与两种多重填补法相比参数估计的偏倚较小,处理效果较佳;随着缺失率的增大,DM法偏倚明显增大,MILL和MILC的偏倚也随之增大,但均优于DM。
随着缺失率的增大,三种方法处理后参数的准确度下降,缺失机制MCAR比MAR的参数准确度高;样本含量1000的RMSE比样本含量500小;MILC和MILL处理后的βb和βbc估计准确度明显优于DM,见表2。
表3可见随着缺失率的增大,三种方法处理后的参数稳定性变差;样本含量1000比样本含量500的参数更稳定;缺失机制MAR和MCAR的稳定度相近;样本含量500、缺失率为40%时,DM的参数稳定性极差,MILC和MILL保持了β系数的稳定估计。
样本含量为500时,MILL和MILC标准误偏倚明显小于DM,MILL处理效果稍优于MILC;样本含量为1000时,三种方法的标准误偏倚均减小,MILC小于MILL;三种方法处理后的标准误偏倚均随缺失率的增大而增大,MCAR条件下标准误偏倚整体上小于MAR,见表4。
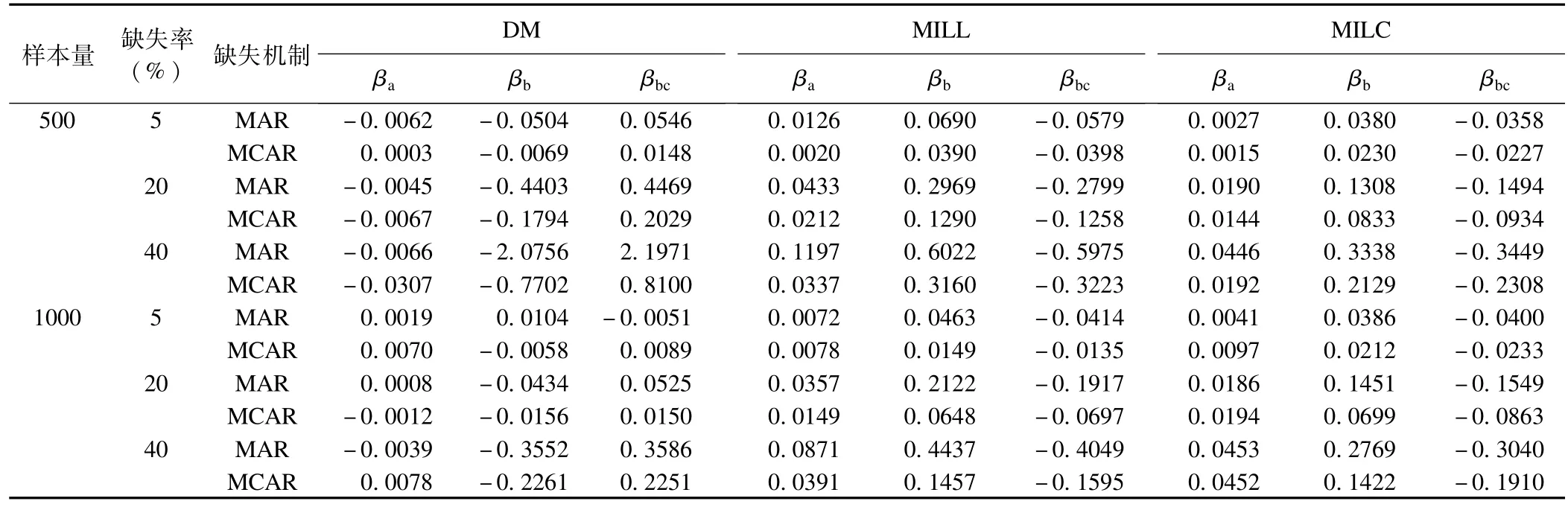
表1 不同缺失数据处理方法各参数条件下logistic回归系数的Bias结果
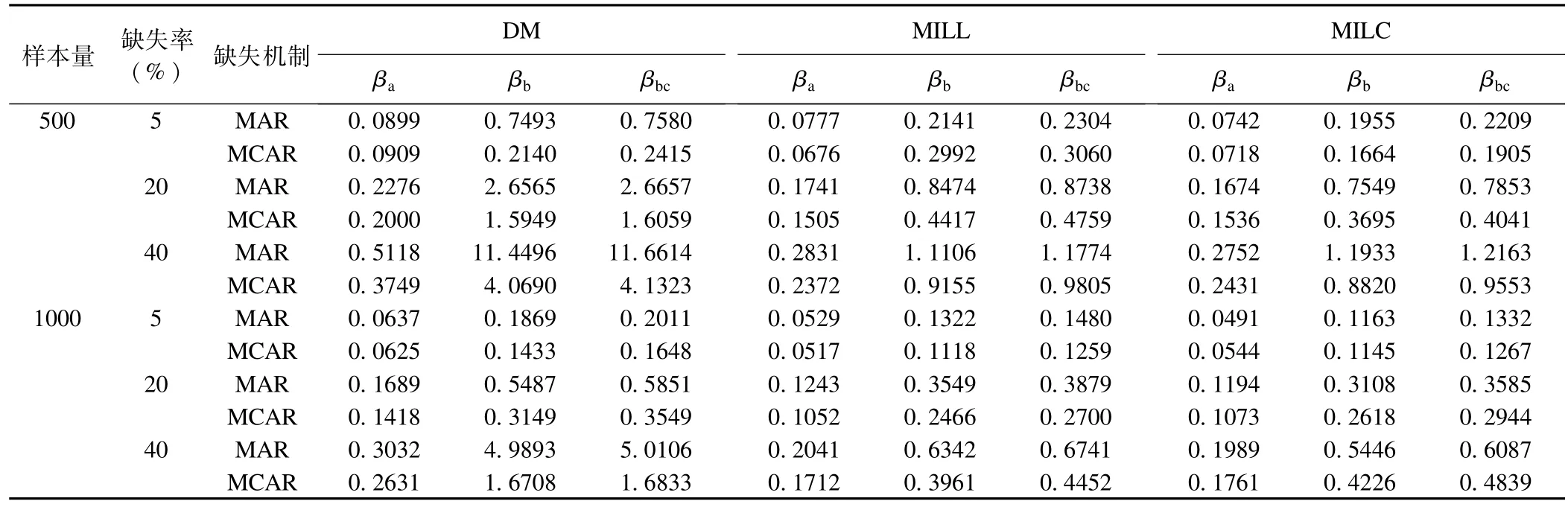
表2 不同缺失数据处理方法各参数条件下logistic回归系数的RMSE结果
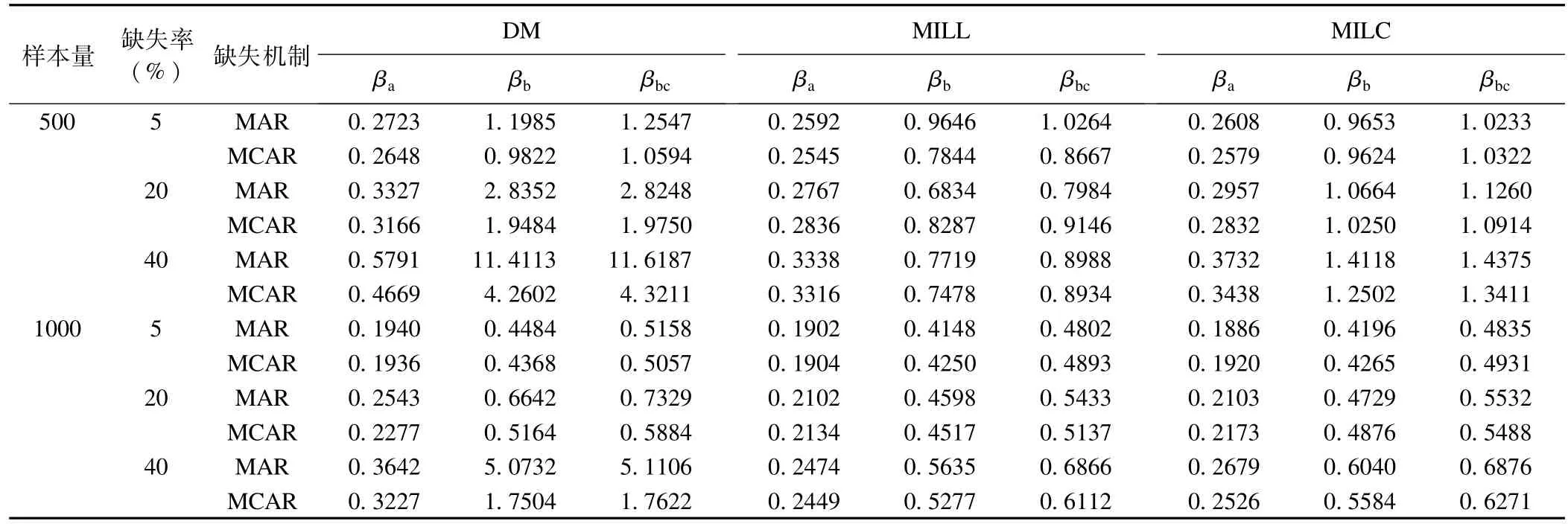
表3 不同缺失数据处理方法各参数条件下logistic回归系数的sd结果
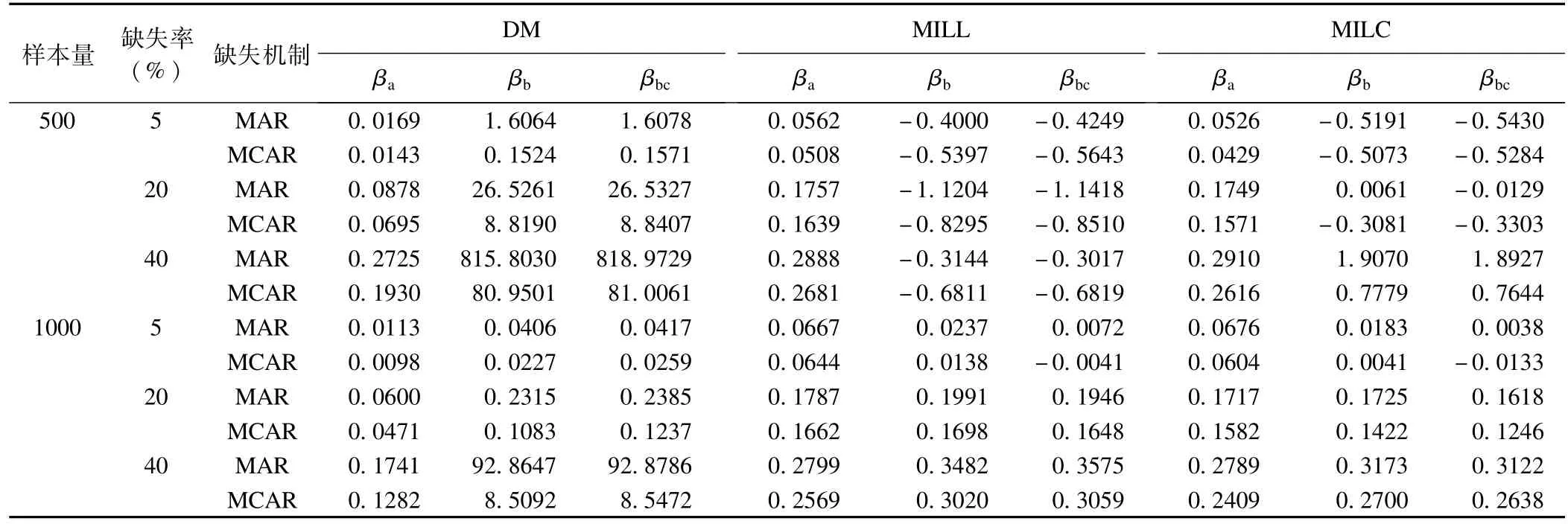
表4 不同缺失数据处理方法各参数条件下logistic回归系数的bse结果
实例应用
本文实例数据来自20家三甲医院中诊断为慢性心力衰竭(chronic heart failure,CHF)的病历资料,共收集1896例,其中心功分级缺失833例,缺失率为43.9%,入院时病情缺失34例,缺失率为1.8%。本文应用MILC处理含缺失值的实例数据,填补前后的两水平逻辑回归分析慢性心力衰竭发生院内死亡的影响因素结果见表5:填补后各回归系数标准误较填补前低,非高血压CHF患者院内死亡率高,具有统计学意义。
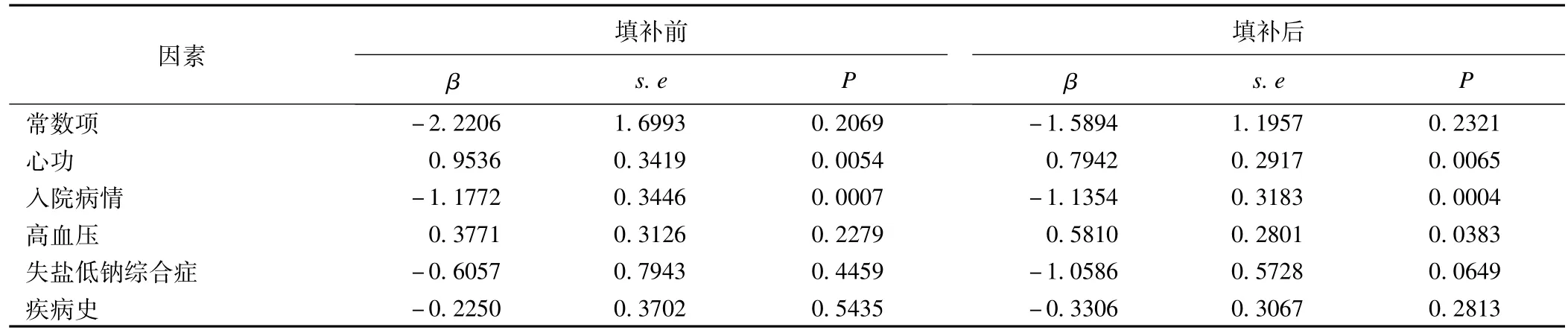
表5 DM和MILC实例数据分析结果
讨 论
删除法是一种最简单最常见的分类变量缺失数据处理方法。当样本量大、缺失率低且缺失机制为完全随机缺失时,缺失的数据相当于原始数据集的一个随机子集,数据缺失对结果造成的影响小,但在不同程度上会增大参数的标准误;当缺失机制为随机缺失时删除数据后参数估计值可发生明显的变化,因此在处理分类变量缺失数据时应避免直接删除含缺失的个体数据。
多重填补是处理缺失数据的重要思想,能保留观测到的所以数据,同时考虑到填补值的不确定性,是目前处理缺失数据的首选方法。本文比较基于两种填补模型的分类变量多重填补法:基于对数线性模型的多重填补法指定填补模型为饱和对数线性模型时涵盖所有变量间的关联,减小了由于缺失数据所导致的结果偏倚,但对数线性模型为全面估计高阶交互效应所需样本含量随变量数及变量类别数的增大迅速增大,模型复杂且计算量大,在实际应用中缺少灵活性;基于潜在类别模型的多重填补法中填补模型结合对数线性模型、因子分析和结构方程模型的思想而形成,用潜在类别数解释外显变量之间的关联,减少了高阶交互多所需的估计参数量,对样本含量的要求比MILL低,在实际应用中具有独特的优势[9]。尤其值得注意的是当样本量小而缺失率较大时,多重填补后参数保持一定的精度及稳定度,证实了多重填补的准确性和稳健性。
本文模拟实验以logistic模型为分析模型,评价基于不同模型多重填补法的处理效果。总体上MILL和MILC在处理缺失数据中效果均可接受,而DM在缺失率大的条件下效果极差,因而在实际使用时不建议直接删除观测。MILL与MILC相比较,当缺失率大于5%,MILC在样本量500时稳定度和标准误偏倚稍差,准确度均优于MILL和DM,样本量1000时则处理效果均优于MILL和DM。MILC中潜在类别数目的设定可能影响其填补效果[10],这将在后续研究中进一步探索。实例数据应用MILC进行填补后参数估计更准确,结果更可靠,为研究者在选择分类变量缺失数据处理方法时提供可靠参考。
参考文献
[1]徐勇勇.医学统计学.高等教育出版社,2004.
[2]张耀,陈培翠,张翠仙,等.二分类数据缺失多重填补分析及应用.中国卫生统计,2014(3):370-373.
[3]Schafer JL.Multiple imputation:a primer.Statistical Methods in Medical Research,1999,8(1):3-15.
[4]Shafer JL.Analysis of incomplete multivariate data.Monographs on Statistics and Applied Probability 7,1997,41(2):505-514.
[5]Vermunt JK,Van ginkel JR,Van der ark LA,et al.Multiple imputation of incomplete categorical data using latent class analysis.Sociological Methodology,2008,38(1):369-397.
[6]Sulis I.A further proposal to perform multiple imputation on a bunch of polytomous items based on latent class analysis.Statistical Models for Data Analysis:Springer,2013:361-369.
[7]Ted H,Fernando T.Analysis of categorical-variable datasets with missing values.2012:1-23.
[8]Linzer DA,Lewis JB.Polca:an R package for polytomous variable latent class analysis.Journal of Statistical Software,2011,42(10):1-29.
[9]张岩波.潜变量分析.北京:张岩波,2009:220-247.
[10]Van DD,Van der ark LA,Vermunt JK.A comparison of incompletedata methods for categorical data.Statistical Methods in Medical Research,2012:1-21.
(责任编辑:刘 壮)
Comparison of Methods Dealing with Category Variables with Missing Data
Xiao Yaming,Chen Yongjie,Wang Yupeng,et al.(Department of Biostatistics,Harbin Medical University(150081),Harbin)
【Abstract】Objective To compare the performance of deletion method(DM),multiple imputation using log-linear model(MILL)and multiple imputation based on latent class model(MILC)dealing with category variables with missing data,and applying MILC to practical data analysis.Methods Simulated data containing multiple variables missing data with different missing mechanism,missing rate and sample size was produced using R.DM,MILL and MILC were employed to obtain the complete dataset,which would be analyzed using logistic regression model.The performance of each method was evaluated by bias of regression coefficient root mean square error,stability and the bias in standard error.Results Simulation experiments showed that when missing rate was 5%,DM、MILL and MILC all performed well.With the missing rate increasing,MILL and MILC were better than DM for all evaluated indicator,and MILC was superior to MILL.The performance of each method was better for completely missing at random mechanism rather than missing at random mechanism,and for sample size of 1000 rather than 500.Practical data analysis showed that the standard error of the coefficient was reduced,and the regression coefficient were more accurate.Conclusion In this paper,two multiple imputation methods,MILL and MILC,are used to deal with category variables missing data and may reduce parameters estimation bias.When missing rate is 5%and sample size is 1000,MILC is recommended for category variables with missing data.
【Key words】Category variable;Missing data;Multiple imputation;Latent class model;Log-linear model
*基金资助:本研究获国家自然科学基金资助(81273183)
通信作者:△刘美娜,E-mail:liumeina369@163.com
