基于文本分类的维吾尔文数字取证研究
2016-06-23如先姑力阿布都热西提贺一峰亚森艾则孜新疆警察学院信息安全工程系新疆乌鲁木齐830013
如先姑力·阿布都热西提,贺一峰,亚森·艾则孜(新疆警察学院信息安全工程系,新疆乌鲁木齐 830013)
基于文本分类的维吾尔文数字取证研究
如先姑力·阿布都热西提,贺一峰,亚森·艾则孜
(新疆警察学院信息安全工程系,新疆乌鲁木齐830013)
摘要:针对维吾尔文书写的数字文本的犯罪取证,提出一种基于文本分类的维吾尔文数字取证方案。首先,对维吾尔文文本进行预处理,滤除文本中非维吾尔文字符和停用词;然后,提出一种多特征空间正则化互信息(M⁃FNMI)算法,使用输入特征组合与类之间的互信息(MI)来代替单个特征与类之间的MI,从而提取出更准确的特征词;最后,利用支持向量机(SVM)算法来对特征进行分类。实验结果表明,该方案具有较高的分类精度,能够为犯罪取证提供判断依据。
关键词:数字取证;文本分类;维吾尔文;互信息;支持向量机
0 引 言
由于信息和存储技术的飞速发展,公安信息系统中存储了大量的案件信息。为了能够更好地预防、打击和控制犯罪,则需要应用数字取证技术,对存储数据进行深度分析,发现各类案例信息的规律和关系[1]。在数字取证过程中,面对大量的电子文档,如何快速地将电子文档进行分类,准确地辨析案件类型,以及从中提取出有用的信息是取证人员需要解决的一个主要问题,而数据挖掘中的文本分类技术是解决这种问题的一种有效方法[2]。
随着国家对新疆地区的大力投入,使其信息化建设得到快速发展,维吾尔文等少数民族语种的大量文字信息开始以数字化形式呈现。对维吾尔文书写的大量文本数据进行文本分类,从而进行电子取证,能够为新疆地区的计算机犯罪提供有力证据,具有重要的意义[3]。
目前,对于英文和中文等大语种的文本分类技术已经得到大量研究,并趋于成熟。然而,对于维吾尔文表述的数字文本的文本分类,相关方面的研究还处于起步阶段。维吾尔语是一种黏着性语言,具有比较复杂的时态变化和丰富的形态结构[4]。为此,文献[4]提出一种基于语义词特征提取的维吾尔文文本的分类方法,用一种组合统计量(DME)来度量文本中相邻单词之间的关联程度,以此来提取特征词。文献[5]利用χ2统计量来提取词干,并利用支持向量机(Support Vector Machine,SVM)算法来构造了维吾尔文文本分类器。文献[6]提出一种新的统计量(CHIMI),将χ2统计量和互信息(Mutual Information,MI)进行结合组成CHIMI,抽取Bigram作为文本特征,并采用SVM算法对维吾尔文文本进行分类。
本文在改进传统MI提取特征的基础上,提出一种基于文本分类的维吾尔文数字取证方案,用于犯罪文本取证。利用改进型正则化互信息算法对维吾尔文进行特征提取,利用SVM进行文本分类,从而取证出与犯罪相关的文本信息。
1 本文方案
本文提出一种基于文本分类的维吾尔文数字取证方案,其主要包括3个部分:维吾尔文文本预处理;特征提取;文本分类。
其中,在特征提取阶段,本文针对传统MI特征提取中只考虑单个特征和类别的MI,而没有考虑上下文特征关联性的缺陷,对其进行改进,将输入特征的组合与类别之间的MI代替单一特征与类别的MI。
1.1文本预处理
维吾尔文文本预处理主要包括两个部分:文本过滤和词干提取。其中,文本过滤用于过滤掉文本中非维吾尔文文字和停用词;词干提取是用来提取文本中具有真正含义的词汇。经过文本预处理,可将文本原始特征维度降低约一半。文本去噪过程中,首先对文本进行过滤,获得维吾尔文单词集。然后,通过和事先准备好的停用词表进行比对,过滤掉停用词。停用词为对文本主题没有贡献,不包含文章类别信息的词,例如介词、副词、代词等。去掉停留词能够实现特征降维,提高分类精度[7]。词干提取过程中,首先,根据维吾尔文单词与单词之间的空格符来进行分词。由于维吾尔文单词是由字母拼写而成的,通过将不同的词缀粘贴到单词的头部来实现语法功能,所以,提取文本中能够代表真实含义的词汇是困难的。维吾尔文中,同一词干可以演变为很多不同含义的词语,虽然这些词语的词形不同,但词义却不会有很大区别[8]。其中一个典型例子如表1所示。为了提取单词的词义,并考虑特征的数量,本文以词干(学校)作为特征项,以此从文本中提取出词干集。

表1 维吾尔词语变体
1.2特征提取
目前,主流的特征提取方法有文档频率(DF)、信息增益(IG)、χ2统计量(CHI)和互信息(MI)等[9]。这些特征选择方法基本思想都是基于一种评估函数,评估每个特征词的价值,然后根据价值将特征词从高到低进行排序,根据设定的特征数量,从高到低提取特征词作为特征集合,以此获得具有高区别能力的特征集并降低特征维数。本文采用基于MI的特征提取方法,MI根据特征和类别共同出现的概率,度量特征和类别的相关性。将预处理得到的词干集作为初始特征集,根据每个词干和每个类别之间的MI值来选择具有较高类别区分能力的词干作为最终特征,进一步降低特征维数[10]。然而,传统MI特征提取只计算单个特征和目标类之间的相关性,没有考虑文本的上下文特征。
为此,本文对传统MI特征提取方案进行改进,提出利用输入特征的组合与类别之间的MI代替单一特征与类别的MI,并应用前向选择特征空间MI理论,增强特征选择算法的选择能力。
1.2.1传统MI特征提取算法
MI通常用来测量特征与类别之间的相关性,MI值越大表明相关性越大。定义维吾尔文本两个特征变量U =(u1,u2,…,uk)和V =(v1,v2,…,vd)之间的互信息为:

式中:(u1,u2,…,uk)和(v1,v2,…,vd)分别为变量U和V的离散值;p(U,V)为一个联合密度函数;p(U)和p(V)都为边缘密度函数。
式(1)中,特征变量V =(v1,v2,…,vd)和类C =(c1,c2,…,ck)之间的MI可表示为:

特征变量v1在类c1中出现的概率越高,则互信息I(c1,v1)就越大,则相关性越大。
1.2.2改进型MI特征提取算法
针对传统MI的缺陷,本文提出一种改进算法,利用具有多个特征的特征空间来正则化用于特征选择的MI,称为多特征空间正则化互信息(Multi⁃feature Space Nor⁃malized Mutual Information,M⁃FNMI)。使用输入特征组合与类之间的MI来代替传统MI算法中单个特征与类之间的MI,并融入贪心选择策略,本文改进算法如下:
(1)初始化:设置F←n个特征的初始集,F ={f1,f2,…,fn},初始选择特征集S←{ }。
(2)根据式(2),计算每个输入特征∀fi∈F与输出类C之间的MI:I(Cfi)(式(2)中fi= V)。
(3)选择第一个特征:找出最大I(Cfi)所对应的特征fi,设置F←F{fi},S←{fi},其中F{fi}表示从F中删除fi。
(4)贪心选择:重复下述过程,直至选择出期望的特征数目:
①计算特征之间的MI:
对所有的特征( fi,fs),其中fi∈F,fs∈S,计算I( fi,fs)。
②选择下一个特征:
选择特征fi∈F,最大化:

接下来,求解特征空间F的信息概率空间。假设每个个体特征fi有ni个离散值(v1,v2,...,),每个离散值vj对应的概率为。每个个体特征fi的信息概率空间为:

对所有个体特征中选择出的离散值进行组合,形成特征空间F的值,特征空间F的信息概率空间可表示为。其中:()表示特征空间F的值;表示特征空间F的值所对应的概率值。例如,数据集A包含两个特征f1和f2,值为(v1,v2)=(0,1),数据集A为:,则特征f的信息1概率空间为,特征f的信息概率空2间为,由此可以计算出特征空间F = f1⋃f2={f1,f2}的信息概率空间为,其中,第一行的二进制数“00”表示特征f1和f2都有一个值为0;“01”表示f1有一个值为0,f2有一个值为1。另外,特征空间F ={f1,f2}中的特征不需要都是独立的,例如:
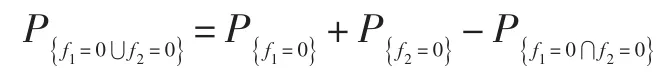
上述算法中,特征空间只考虑包含两个特征,但可以扩展到包含两个以上特征。
1.3文本分类
文本分类是一种学习过程,其利用一个已被明确分类过的训练文档集,找出文本特征与文本类别之间的关系,然后对此进行学习,获得一个关系模型,从而对新的文本进行分类[11]。目前,主流的文本分类算法有基于质心的分类、朴素贝叶斯分类(NB)、K近邻分类(KNN)、决策树分类、神经网络(NN)分类以及支持向量机(SVM)分类算法等[12]。文献[13]通过文本分类实验,将SVM与其他多种分类算法进行比较,发现SVM的文本分类性能最好,所以本文采用SVM分类器。SVM算法基本思想是寻找出一个最优分类面,最优分类面不但能将两类样本点正确地分开,而且使两类的分类间隔最大[14]。SVM中,线性判别函数为g(x)= wTx + b,分类面函数为wTx + b = 0。为了使最优分类面能准确分类所有样本,则需要满足以下条件:
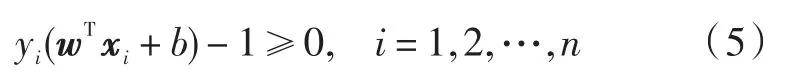
能够使式(5)中等于0成立的那些样本成为支持向量。两类样本的分类间隔为:

因此,可利用以下约束优化问题来表示最优分类面问题,即在约束条件式(5)下,求式(7)的最小值:

为此,可以定义拉格朗日(Lagrange)函数:
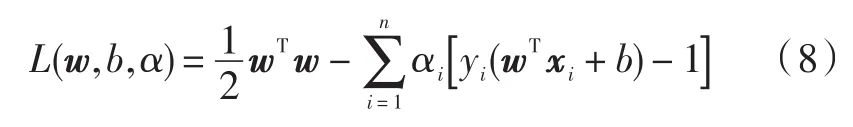
式中,αi≥0为拉格朗日系数,为了对w和b求拉格朗日函数的最小值,将式(8)分别对w,b,α求偏微分,并令它们等于0,得:

根据式(9)~式(11),则可将原问题转化为一个凸二次规划问题:

式(12)为一个求解二次函数极值问题,存在惟一的最优解,若为最优解,则:


式中,sgn(·)为符号函数。
2 实验及分析
2.1实验环境
为了评估本文方案的性能,构建一个计算平台,以Intel酷睿i5作为CPU,主频为2.4 GHz,应用Windows 7系统环境,利用Matlab 2011进行实验。
对于维吾尔文的文本分类应用,目前还没有可使用的标准文本集。由于本文方案是应用于犯罪数字取证领域,所以本文从新疆公安犯罪数据库中的案情、新疆公安网公布的治安新闻以及人民网维吾尔文版的新闻上收集了2 500篇文本,通过人工方式将其分为7类犯罪:危害国家安全;危害公共安全;侵犯公民人身权利;破坏市场经济秩序;妨害社会管理秩序;侵犯财产;贪污贿赂。其中,1 600篇文本作为训练集,900篇作为测试集。各类的训练和测试样本数如表2所示。

表2 分类文本库
2.2性能指标
本文采用分类中常用的性能指标F1值来评估方案性能,其由准确率(P)和召回率(R)计算获得:

式中:a表示正确分类的文本数;b表示分类为该类,但不属于该类的文本数;c表示属于该类,但未被分类到该类的文本数。通常将准确率和召回率进行综合,得到评估文本分类质量的F1值,表达式如下:

通常情况下,方案的F1值越高,则分类效果越好。实验中,本文将各个类别的F1值求平均,得到最终性能指标,即F1平均值。
2.3分类实验
实验中,首先对维吾尔文文本集进行预处理,为了方便后续处理,把文本转换成UTF⁃8二进制编码格式。然后,过滤掉文本中的非维吾尔文字符和停用词。预处理结束后,获得一个具有24 420个特征的初始特征集。然后进行词干提取,将同一词根演变而来的特征进行聚合,使初始特征项降维到13 826个。然后通过本文提出的M⁃FNMI特征提取算法,提取出和类别具有高互信息(高区分度)的词干作为最终特征。设定每个类别提取500~2 500个特征词。表3描述了危害国家安全类别和侵犯公民人身权利类别中前5名的特征词,这些特征词具有最强的区别能力。

表3 类别的前5名高区分度的特征词
由于本文分类算法采用传统的SVM算法,而特征提取算法采用提出的新算法。所以,为了更好地证明本文方案对维吾尔文文本分类的性能,将本文特征提取算法与传统MI、文献[5]、文献[6]中的特征提取算法进行比较。为了实现更好地比较,设定各种方法都采用同样的分类算法,即SVM。在各类别特征集大小为500,1 000,1 500,2 000和2 500情况下分别进行分类实验,并计算分类性能指标F1。图1为本文方案在不同特征集大小下,各类别分类的F1值。图2为本文方案和传统MI、文献[5]、文献[6]方案的比较,其中性能指标为各类别分类的F1平均值。

图1 不同特征集大小下,本文方案中各类别分类的F1值
从图1可以看出,在不同特征集大小下,各个类别的分类精度不等,其中“侵犯公民人身权利”类别分类精度最高。从图2可以看出,随着特征集大小的增加,各种方法的分类精度都随之增加,然后趋向稳定或有所下降。这是因为特征集过大时,选入了有些不重要的“噪声”特征,影响了分类效率。当特征集大小为2 000时,各种方案都获得了最高性能,其中本文方案获得的F1值为0.91,分别比传统MI、文献[5]、文献[6]高出约23%,11%和6%。

图2 不同特征提取方案中分类的F1平均值
3 结 语
本文针对维吾尔文表述的数字文本取证应用,提出一种基于文本分类的取证方案,利用提出的多特征空间正则化互信息(M⁃FNMI)对维吾尔文文本进行特征提取,利用SVM算法对特征进行分类。实验中,设定7类犯罪类型,将本文方案与现有方案进行比较,结果表明,本文方案具有较高的分类性能,能够为新疆公安部门进行数字取证提供有力依据。
注:本文通讯作者为亚森·艾则孜。
参考文献
[1]程春惠,何钦铭.面向不均衡类别朴素贝叶斯犯罪案件文本分类[J].计算机工程与应用,2009,45(35):126⁃128.
[2]刘露,彭涛,左万利,等.一种基于聚类的PU主动文本分类方法[J].软件学报,2013,24(11):2571⁃2583.
[3]热依莱木·帕尔哈提,孟祥涛,艾斯卡尔·艾木都拉.基于区分性关键词模型的维吾尔文本情感分类[J].计算机工程,2014,40(10):132⁃136.
[4]吐尔地·托合提,艾克白尔·帕塔尔,艾斯卡尔·艾木都拉.语义词特征提取及其在维吾尔文文本分类中的应用[J].中文信息学报,2014,28(4):140⁃144.
[5]阿力木江·艾沙,吐尔根·依布拉音,库尔班·吾布力.基于SVM的维吾尔文文本分类研究[J].计算机工程与科学,2012,34 (12):150⁃154.
[6]阿力木江·艾沙,库尔班·吾布力,吐尔根·依布拉音.维吾尔文Bi⁃gram文本特征提取[J].计算机工程与应用,2015,51(3):216⁃221.
[7]UYSAL A K,GUNAL S. The impact of preprocessing on text classification [J]. Information processing &management,2014,50(7):104⁃112.
[8]陈卿,袁保社,李晓,等.基于模板匹配的印刷维吾尔文字符识别研究[J].计算机技术与发展,2012,22(4):119⁃122.
[9]DENG H,RUNGER G,TUV E,et al. A time series forest for classification and feature extraction [J]. Information sciences,2013,239(4):142⁃153.
[10]OVEISI F,OVEISI S,ERFANIAN A,et al. Tree⁃structured feature extraction using mutual information [J]. IEEE transac⁃tions on neural networks & learning systems,2012,23(1):127⁃137.
[11]刘露,彭涛,左万利,等.一种基于聚类的PU主动文本分类方法[J].软件学报,2013,24(11):2571⁃2583.
[12]赵辉,刘怀亮,张倩.一种基于复杂网络的中文文本分类算法[J].情报学报,2012,31(11):1179⁃1186.
[13]LIU Zhijie,LYU Xueqiang,LIU Kun,et al. Study on SVM compared with the other text classification methods[C]// Interna⁃tional Workshop on Education Technology & Computer Science. Wuhan,Hubei,China:[s.n.],2010:219⁃222.
[14]CAO J F,CHEN J J. An improved web text classification al⁃gorithm based on SVM⁃KNN [J]. Applied mechanics & materials,2013,27(8):1305⁃1308.
[15]胡文军,王士同.隐私保护的SVM快速分类方法[J].电子学报,2012,40(2):280⁃286.
Research on Uyghur digital forensics based on text categorization
RUXIANGULI Abudurexiti,HE Yifeng,YASEN Aizezi
(Department of Information Security & Engineering,Xinjiang Police College,Urumqi 830013,China)
Abstract:For the crime forensics of digital texts written in Uighur,a Uyghur digital forensic scheme based on text categori⁃zation is proposed. The Uyghur texts are preprocessed to filter the non Uyghur characters and stop words. A multi⁃feature space normalized mutual information(M⁃FNMI)algorithm is proposed. The mutual information(MI)between input feature combina⁃tion and class is used to replace the MI between the single feature and class,so as to extract more accurate feature words. The support vector machine(SVM)algorithm is used to classify those features. Experimental results show that the proposed scheme has higher classification accuracy,and can provide a basis for criminal evidence collection.
Keywords:digital forensic;text categorization;Uyghur;mutual information;support vector machine
中图分类号:TN911⁃34;TP391
文献标识码:A
文章编号:1004⁃373X(2016)10⁃0009⁃05
doi:10.16652/j.issn.1004⁃373x.2016.10.003
收稿日期:2015⁃09⁃24
基金项目:国家社会科学基金科研项目(13CFX055);新疆维吾尔自治区自然科学基金科研项目(2015211A016);新疆维吾尔自治区高校科研计划科学研究重点项目(XJEDU2013I34)
作者简介:如先姑力·阿布都热西提(1976—),女,新疆喀什人,讲师,硕士。研究方向为信息安全、数字取证等。贺一峰(1978—),男,新疆乌鲁木齐人,讲师,硕士。研究方向为信息安全、数字取证等。亚森·艾则孜(1975—),男,新疆库车人,教授,硕士,国家电子数据司法鉴定员。研究方向为信息安全、自然语言处理等。
