基于RTEM模型的问答社区候选答案排序方法
2016-06-13刘瑜,袁健
刘 瑜,袁 健
(上海理工大学 光电信息与计算机工程学院,上海 200093)
基于RTEM模型的问答社区候选答案排序方法
刘瑜,袁健
(上海理工大学 光电信息与计算机工程学院,上海200093)
摘要问答社区作为搜索引擎的补充,在人们生活中起到越来越重要的作用,但随着大量问答对的积累,部分答案不能及时得到其他用户的评价,使得提问者选择最佳答案的难度加大。文中在研究用户行为及其行为所产生的结果后,提出一种新的基于主题模型的候选答案排序方法。通过大规模的实验数据证明,相较于其他模型方法,取得了较好的效果。
关键词问答社区;答案排序;主题模型;用户行为
目前,随着大数据时代的来临,信息呈爆炸式增长,搜索引擎已不能较好地满足用户对信息的需求,人们越来越多地通过问答社区来获取所需信息。与基于关键词、返回大量网页的搜索引擎不同,问答社区允许用户利用自然语言进行提问,由其他用户给出问题的答案,更好地满足了用户的信息需求。在用户提出问题并得到相应回答以后,系统将结合用户的背景知识及其他用户给出的投票和评论信息选择最佳答案,然而要得到最佳答案,则可能需要花费大量的时间来等待其他用户的投票和评论。因此,在缺少其他用户的评价信息时,如何利用已有的信息对候选答案进行排序,以帮助提问者高效地选择最佳答案,是一个亟需解决的重要问题。
鉴于此,本文在研究了用户的行为以及问答社区的特点后,在TEM(Topic Expertise Model)[3]模型的基础上,对用户专业知识背景重新定义,依据用户的熟悉程度对用户兴趣主题分类,并引入其他用户的回答,最后结合用户的知识背景和问题答案的匹配程度对问答社区中的候选答案进行排序。
1相关工作
近年来,有关问答社区中关于答案质量问题的研究分以下两种:(1)答案质量研究;(2)问答对质量研究。
第一种研究可分为两类,第一类研究[1-2]通过与答案相关的外部特征,筛选出高质量的答案。Ginsca等[1]重点分析了包含头像、自我评价在内的用户特征,并结合相关行为,通过RSVM(Ranking Support Vector Machine)分类器筛选出了高质量答案。姜雯等[2]引入了情感因素,通过Weka机器学习算法进一步提升了选取最佳答案的准确率。第二类研究[3-5]为基于主题模型、HowNet等引入问题答案相关性的研究方法,挖掘问题和答案、答案和答案之间的关系来对候选答案进行排序。Yang等[3]利用TEM(Topic Expertise Model)模型,引入用户之间的链接关系,得到用户的兴趣分布和专业程度,通过问题答案主题相似性和用户的权威度对候选答案进行排序。廉鑫[4]通过构建答案与答案之间的相似度矩阵,并结合答案的得票情况,对答案质量进行评价。Surdeanu[5]通过引入语言学特征,比如语义角色标注,并结合排序模型对非事实型的答案进行排序。
第二种研究将“问答对”看成一个整体,以其为主要特征抽取对象。刘高军等[6]从“问答对”的文本特征、关联度等4个方面的特征进行评价,并建立分类器,选取出高质量的问答对。
基于主题模型的研究方法,相较于其他研究方法而言,不但可挖掘问答社区中文本信息的潜在语义,而且比其他挖掘语义的方法更灵活,不再局限于已有的词库。而TEM模型[3]在主题模型的基础上,结合用户相关信息建模,取得了较好的结果。本文以TEM模型为基础,通过分析用户的行为和问答社区中的文本信息对用户所造成的影响提出一个新的RTEM模型,并用该模型的结果对候选答案进行排序。
2基于RTEM主题模型的候选答案排序
2.1TEM模型
TEM(Topic Expertise Model)模型[3]是针对问答社区情况对主题模型的改进,从而获得用户的主题分布和基于主题的专业程度。其主要思想是利用主题模型对用户产生的问题答案的相关文本信息建模,获取用户的兴趣主题分布,并同时在模型中引入问题答案的得票数,结合高斯分布,计算出每个用户基于主题的专业程度。
2.2RTEM模型描述
TEM模型在候选答案排序方面效果较优,但仍存在以下问题:TEM模型把其他用户对所提问题支持的票数作为衡量该用户专业程度的重要因素,但用户并不熟悉所提问题,该问题仍可能因描述清楚或解决了其他用户的疑惑而得到较高票数。因此,问题收到票数高低与用户专业程度之间并无直接关系。另一方面,若用户提问后,通过学习高质量的答案知识,从而对这个问题的主题的熟悉程度和专业程度均会有所提升。因此,在计算用户专业程度时,不代入所有问题的得票数,而是选取其中包含高质量答案的问题和相关高质量答案作为了解领域建模,剩余问题作为生疏领域建模,所有答案作为精通领域建模,更符合实际情况。综上所述,改进后的RTEM(Related Topic Expertise Model)模型如图1所示。
模型图中带有阴影的变量为已知内容,其中的e和P为基于主题的用户精通领域和了解领域的专业程度大小,分别有e和P个专业程度级别;与TEM模型相同,用户产生文档的票数v和b服从高斯分布,正态-伽马分布是高斯分布的先验分布。最后可由模型计算出,基于每一个主题t,用户精通领域的主题分布θu,f和专业程度分布φu,e,了解领域的主题分布θu,q和专业程度分布φu,P,以及生疏领域主题分布θu,D和主题-特征词分布ψt。

图1 RTEM模型图
模型中所用的参数如表1所示。

表1 模型所用参数列表
模型的工作流程如下:
步骤1对社区问答系统中的用户u,从以α为参数的Dirichlet分布中抽取其精通领域主题分布θu,f~Dir(α),了解领域主题分布θu,q~Dir(α)和生疏领域主题分布θu,q~Dir(α);
步骤2对精通领域的专业程度e,从以α0,β0,μ0,κ0为参数的正态-伽马分布中抽取每个用户基于主题的票数分布м(μe,γe)~ мн(α0,β0,μ0,κ0);对了解领域的专业程度P,同样从上述的正态-伽马分布中获得基于主题的票数分布м(μb,γb)~ мн(α0,β0,μ0,κ0);
步骤3对于每个用户u。
(1)精通领域。u产生的文档中的第a项答案,从参数为θu,f的多项式分布中抽取其主题zf,即zf~Multi(θu,f);从参数为φf,u的多项式分布中抽取其专业程度,即e~Multi(φf,u);从参数为μe,γe的高斯分布中抽取其平均票数,即v~м(μe,γe);从参数为ψt的多项式分布中抽取第P个特征词,即wf~Multi(ψt);
(2)了解领域。u产生的文档中的第q项内容(包含问题和答案),从参数为θu,q的多项式分布中抽取其主题zq,即zf~Multi(θu,f);从参数为φq,u的多项式分布中抽取其专业程度,即P~Multi(φf,u);从参数为μb,γb的高斯分布中抽取其所得平均票数,即v~м(μb,γb);从参数为ψt的多项式分布中抽取第R个特征词,即wq~Multi(ψt);
(3)生疏领域。u产生的剩余问题中的第s项内容,从参数为θu,D的多项式分布中抽取其主题zD,即zD~Multi(θu,D);从参数为ψt的多项式分布中抽取第k个特征词,即wD~Multi(ψt)。
文献[8]指出,Yahoo answers!中当问题的答案数目超过7个时,就会有较高质量的答案出现。因此步骤3的(2)中用户产生的内容,选取回答数超过10个,并且有超过3个以上的得票数超过10票的问题和高质量答案。此外,用户了解领域的票数b计算如式(1)所示,这些答案所得票数votes之和除以该问题下所有的答案票数votes之和。其中ps>10,为得票数超过10的约束条件。
vote=∑α∈q,PS>10votes/∑a∈qvotes
(1)
采用常用的吉布斯采样对模型参数进行估计,以精通领域为例,如式(2)所示,其余领域与此相似,不再赘述
(2)
通过吉布斯采样,计算得到基于主题t的用户u的精通、了解和生疏领域的用户-主题分布、主题-特征词分布和主题-专业程度分布分别如式(3)所示
(3)
由该模型同样可得到问题和答案的主题分布,如式(4)和式(5)所示,其中wq和wa分别为问题和答案中的特征词,ψ(t,w)由模型推导可得,表示该特征词w在主题t下的概率统计。
(4)
(5)
2.3基于RTEM模型的候选答案排序
这里依据问答对的主题相似度、用户对问题的熟悉程度和用户的专业程度3个方面来对候选答案进行排序,得分越高,排序越靠前,反之亦然。答案评分计算如式(6)所示。
(6)
式中,q表示某个问题;a表示该问题下的答案;uf表示熟悉领域中用户的兴趣主题分布;uD是了解领域中用户的兴趣主题分布;sim(·)表示两者之间的主题相似度,通过Jensen-Shannon距离公式计算。expert(·)表示精通或了解领域中用户的基于主题的专业程度分布。式中Ω1、Ω2、Ω3通过层次分析法(Analytic Hierarchy Process)[8]来计算,具体如下:
步骤1构建候选答案排序的层次结构型,确定(1)目标层,某问题下的候选答案排序;(2)指标层,问题答案主题相似性、精通领域和了解领域的问题用户相似性及用户专业程度;(3)方案层,待排序的各答案。

表2 判断矩阵中的标度及其含义
步骤3在该模型通过一致性检验后,利用算数平均法获得Ω1、Ω2、Ω3,如式(7)所示
(7)
最后得到Ω1=0.557 1,Ω2=0.320 3,Ω3=0.122 6。
3实验与分析
3.1实验数据集及评价指标
Stack Overflow是与编程技术相关的垂直领域的问答平台。自成立之日,积累了大量的问答对。本次实验数据是从该问答社区收集的2008年7月31日~2014年1月的所有问答对及用户数据[1]。数据集剔除了候选答案少于2个(排序无意义)和提问回答个数少于80的用户(不活跃的用户提供的答案对提问者有用的概率较小)。选取2009年7月1日~2009年10月1日的数据作为训练集,从2009年10月2日到2010年6月2日的数据作为测试集。数据的整体情况如表2所示,因为测试集和训练集中的用户集合相同,所以数量也是相同的。
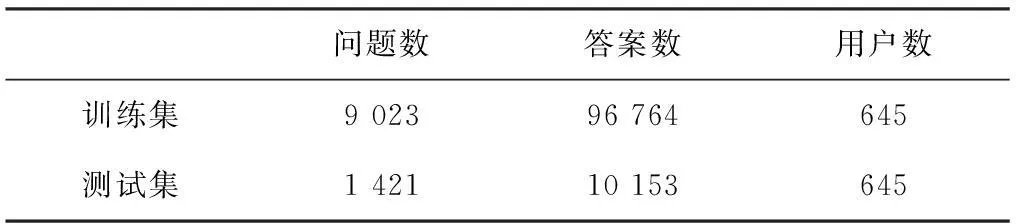
表3 实验数据整体情况
为评估本文所提出的候选答案排序方法的性能,本文采用NDCG(Normalized Discounted Cumulative Gain)、Spearman和Kendall共3种方法对排序结果进行评价。三者均表示取值越大,两者相关性越高,效果越好。其中三者的如式(8)~式(10)所示
(8)
(9)
(10)
其中,式(8)中的NF(q)是归一化因数,vq,j是问题q下排在第j个位置的答案的票数,IdealScore(N,q)是问题q的前k个答案的排序分数;式(9)中di为问题q和答案ai的主题相似度;式(10)中C表示问答集合中拥有一致性的元素对数,D表示两者拥有不一致性的元素对数。
按照答案得票数高低的排序结果作为正确的排序结果,作为上述方法的对比基线。
3.2参数设置及对比实验
依据已有的候选答案方法,选取以下两种方法进行实验对比:
(1)EM模型[3]。Tem模型通过用户的问答记录获得用户的兴趣分布和专业程度;
(2)AAM(Authority and Activity Method)。文献[9]中提到通过用户回答问题的数量和提问问题的数量计算用户专业程度的方法,以及计算用户的活跃度的方法。这里通过两者相乘得到基于活跃程度的用户专业程度,并把用户和问题之间以及问题和答案之间的相似度设置为1;
(3)RTEM模型:本文所提方法。
结合文献[3]和多次试验的结果,取循环次数为500次,主题T的个数为10,专业程度E和P的个数均为12,α0=κ0=1,β0为随机抽样的500个票数的平均距离,μ0为训练集中所有票数的平均值,并按常规设置α=50/T,β=0.01,ε=0.01。
3.3实验结果及分析
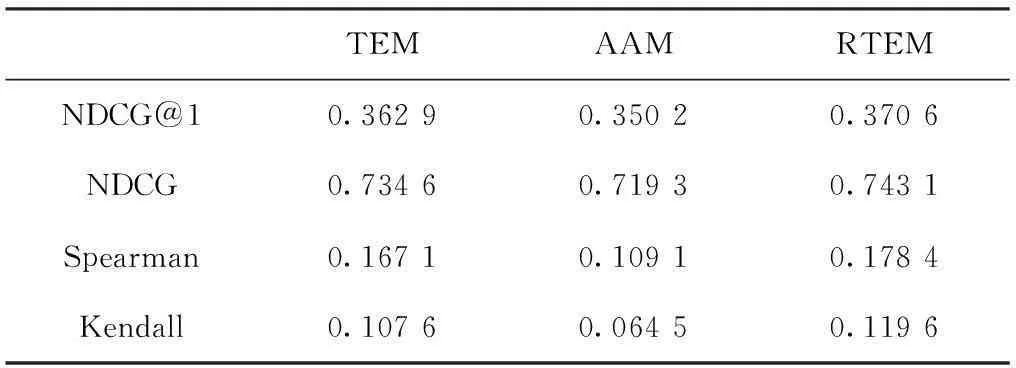
表4 候选答案排序实验结果
通过表4的实验结果可得出如下结论:
(1)从表中可明显看出,与其他模型相比,四个指标下,RTEM模型的效果最好,充分证明了RTEM模型的有效性;
(2)RTEM模型与TEM模型相比,前者取得的效果更好,说明在模型中对用户的兴趣领域分类,并引入用户提问问题所得高质量答案有助于计算在不同掌握程度之下的用户的专业程度和主题分布,从而证明了本文所提模型的有效性;
(3)TEM模型、RTEM模型和AAM相比,前面两种模型的效果明显要优于AAM。这是因前面两种方法所用的基础模型引入了潜在语义分析,而AAM仅从用户的回答数和活跃程度来描述用户的专业程度,未涉及到相关语义信息,由此可看出,语义信息在候选答案排序中的重要性。
4结束语
本文在TEM模型[3]的基础上,通过分析用户的行为,提出了一种新的问答社区候选答案排序的方法RTEM模型。实验结果表明,该算法能够获取较好的答案排序。在研究过程中发现由于提问者恶意或无意,选出的最佳答案并非最佳答案,甚至是错误答案。因此,下一步的研究工作将在现有工作的基础上,通过引入其他特征,对答案质量进行评价,自动选出最佳答案。
参考文献
[1]Ginsca A L,Popescu A.User profiling for answer quality assessment in Q&A communities[C].Ningbo:Proceedings of the 2013 Workshop on Data-driven User Behavioral Modelling and Mining From Social Media,ACM,2013.
[2]姜雯,许鑫,武高峰.附加情感特征的在线问答社区信息质量自动化评价[J].图书情报工作,2015(4):100-105.
[3]Yang L,Qiu M,Gottipati S,et al.Cqarank:jointly model topics and expertise in community question answering[C].Paris:Proceedings of the 22nd ACM International Conference on Information & Knowledge Management,ACM,2013.
[4]廉鑫.社区问答系统中若干关键问题研究[D].天津:南开大学,2014.
[5]Surdeanu M,Ciaramita M,Zaragoza H.Learning to rank answers to non-factoid questions from web collections[J].Computational Linguistics,2011,37(2):351-383.
[6]刘高军,马砚忠,段建勇.社区问答系统中“问答对”的质量评价[J].北方工业大学学报,2012,24(3):31-36.
[7]Fichman P.Information quality on yahoo! answers[J].Approaches and Processes for Managing the Economics of Information Systems,2013(6):192-199.
[8]邓雪,李家铭,曾浩健,等.层次分析法权重计算方法分析及其应用研究[J].数学的实践与认识,2012(7):93-100.
[9]Han W W,Que X,Song S.Ranking potential reply-providers in community question answering system[J].Communications,2013,10(10):125-136.
Candidate Answer Sorting Method of Q&A Community Questions Based on RTEM Model
LIU Yu,YUAN Jian
(School of Optical-Electrical and Computer Engineering,University of Shanghai for Science and Technology,Shanghai 200093,China)
AbstractAs a supplement of search engine,community question and answering is playing a more and more important role.But with increasing numbers of questions and answers,part of the answers fail to get the evaluation of other user in time,which makes it difficult for askers to choose the best answer.Based on the study of the user behavior of and its effects this paper proposes a new topic model on the basis of user behaviors.Experiments with large sets of data show that the proposed method is superior to other models.
Keywordscommunity question and answering;answer ranking;topic model;user behavior
doi:10.16180/j.cnki.issn1007-7820.2016.05.035
收稿日期:2015-09-28
作者简介:刘瑜(1991—),女,硕士研究生。研究方向:数据挖掘、社区问答系统。袁健(1971—),女,博士,副教授。研究方向:数据挖掘、网络安全等。
中图分类号TP391
文献标识码A
文章编号1007-7820(2016)05-130-05
