一种批处理块级数据去重方法
2016-06-08杨天明吴海涛
杨天明 吴海涛
(黄淮学院国际学院 河南 驻马店 463000)
一种批处理块级数据去重方法
杨天明吴海涛
(黄淮学院国际学院河南 驻马店 463000)
摘要数据去重能消除备份中的冗余数据,节省存储资源和网络带宽,因而成为当前数据存储领域的研究热点。针对常用的块级数据去重技术指纹查询开销高、系统吞吐率低等问题,提出一种批处理块级数据去重方法,通过内存缓冲区对指纹进行排序,实现磁盘索引的顺序查询。同时文件以一种双指针有向无环图的结构存储在系统中,以消除文件读时引起的随机磁盘I/O开销。实验结果表明,该方法有效克服了指纹查询的磁盘I/O瓶颈,提高了数据去重时的系统读写性能。
关键词备份数据去重指纹查询批处理
0引言
生产和科技的高速发展不但带来了数据的爆炸性增长,而且使得数据的重要性日益提升。如何快速有效地对数据进行备份成为数据保护领域亟待解决的关键问题之一。
研究发现重复数据大量存在于信息处理和存储的各个环节。传统的备份技术不能有效消除重复数据,浪费了存储空间和网络带宽[1]。近年来,数据去重技术迅速成为数据保护领域一个新的研究方向[2]。常用的数据去重方法把数据流或文件分成较小的数据块,比较数据块指纹以消除重复数据块[3]。为了保证数据块指纹的唯一性,一般使用安全哈希函数如MD5[4]对数据块内容进行哈希来得到指纹。系统通过磁盘哈希表建立指纹到数据块的映射,由于磁盘哈希表较大而不能存储在内存中,加之指纹的极度随机性,在备份过程中查询指纹会导致随机磁盘I/O[3]。以目前的磁盘技术,随机磁盘I/O速度不会超过数百IOPS,这显然不能满足高性能数据备份的需要。因而,高性能数据去重的关键是如何有效降低指纹查询的随机磁盘I/O开销。
近年来,国内外在数据去重性能方面进行了较多研究。DDFS[3]和Foundation[5]使用cache技术和布隆过滤器[15]来提高系统读写性能。Cache技术利用数据流的冗余局部性通过容器预取数据块指纹来提高旧指纹在内存中的命中率,布隆过滤器则留驻在内存中预先检测出大部分新指纹从而有效降低数据块索引查询的随机磁盘I/O开销。Sparse Indexing[6]则把数据流分成数据段,对数据段中包含的数据块指纹进行抽样以取得钩子指纹,并使用稀疏索引建立钩子指纹到包含它们的数据段之间的映射。备份新数据段时,通过稀疏索引找到和其共享钩子指纹的旧数据段来消除新旧数据段之间的重复数据块。稀疏索引留驻在内存中能加快查询速度。由于仅在局部范围内删除重复数据块,Sparse Indexing的数据压缩效果较DDFS差。另外,对于冗余局部性较差的负载,DDFS 和Foundation的性能会降低而Sparse Indexing 的数据压缩率会下降,SiLo[7]则研究了这种情况下利用备份源目录信息整合数据流从而提高重复数据块删除比率和性能的技术。
本文提出了一种基于批处理的块级数据去重方法,通过把数据备份过程分成两个阶段,实现对磁盘哈希表的顺序查找和更新。该方法把数据去重从数据备份过程中分离开来从而减小数据去重对应用的影响,而批处理指纹查询不依赖于备份流内部的冗余局部性,因而具有稳定的写吞吐率。同时文件以一种双指针有向无环图BP-GAD(Bi-Pointer-based Directed Acyclic Graph)的结构存储在系统中,消除了文件读时引起的随机磁盘I/O开销,保证了较高的数据恢复性能。
1系统架构
系统架构如图1所示,整个系统分成三部分,客户机运行在需要备份数据的主机上,备份时从指定文件集中读出文件送往备份服务器,恢复时从备份服务器接收文件写到指定的恢复目录中。备份服务器由两大模块构成,即TPBS(Two Phase Backup Stradity)模块和文件读模块(FR)。备份时,由TPBS模块负责接收客户机送来的文件、对文件进行分块并计算数据块的MD5指纹(128 bits)、然后把数据块和指纹缓存在本地磁盘缓冲区中。待备份作业结束后再通过批处理指纹查询等机构把文件以BP-GAD的形式存储到存储池中。恢复时,由FR模块从存储池中读取相应的BP-GAD对文件进行重构,并把文件恢复到客户机的指定目录中。

图1 系统架构图
数据块以其指纹为索引存储在存储池中,指纹到数据块存储地址的映射通过磁盘哈希表建立。磁盘哈希表共包含2n个桶,每个桶占用一个磁盘扇区,包含若干个索引项,每个索引项存储一个“指纹->地址”映射。取指纹的前n位为桶号把此指纹映射到相应的桶中。
2文件索引结构
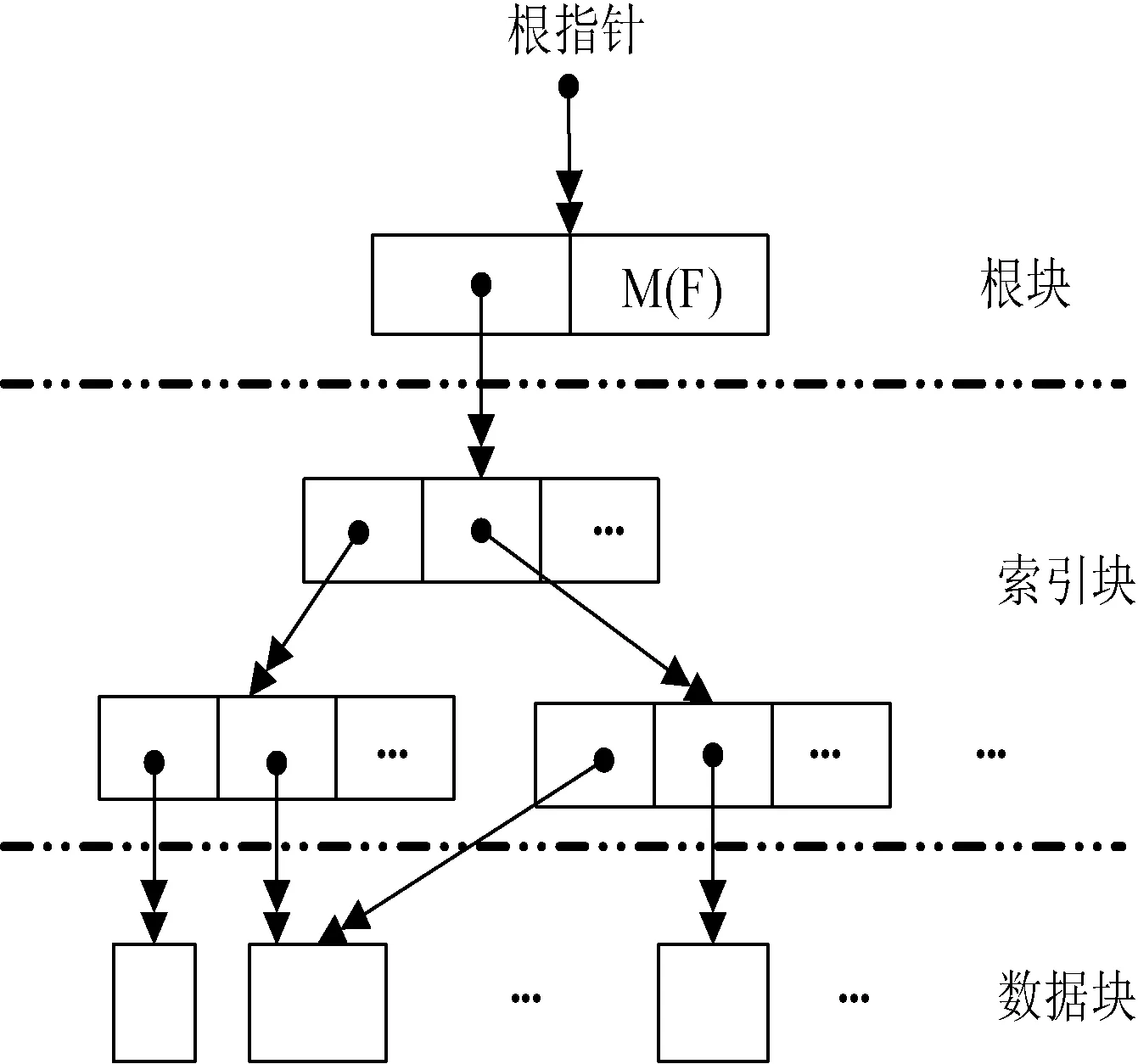
图2 文件索引结构
一般文件系统采用地址指针建立文件索引,这样文件访问速度很快,但地址指针和数据块内容无关,无法实行数据去重。以数据块指纹为指针的索引结构如Venti哈希树[8]和HDAGs[9]能消除冗余数据并实现数据块共享,但数据访问时必须通过查询磁盘哈希表获得地址指针,文件读写性能较差。为了综合两种指针的优点,本文使用一种双指针索引结构BP-GAD,如图2所示。
图2为一个文件F的BP-GAD,图中用双箭头表示BP-GAD指针。一个BP-GAD 指针是一个四元组< type, fingerprint, address, size >,其中‘type’表示节点类型,‘fingerprint’表示节点指纹,‘address’表示节点在存储池中的存储地址,而‘size’表示节点大小。显然< type, fingerprint> 是一个哈希指针,而< address, size >是一个地址指针。BP-GAD有三种不同类型的节点,分别是数据块、索引块和根块。一个BP-GAD有一个唯一的根块,根块包括文件的元数据M(F)域和BP-GAD指针域。对于较小的文件,其数据块指针可以直接放在根块中,对于大文件,有可能需要使用多个索引块以构成一个层次性的索引结构来对文件进行索引。索引块存放BP-GAD指针,它是变长块,可以设定其最大大小,比如16 KB。
BP-GAD中的哈希指针是惟一的。由于内容相同的节点哈希指针也相同,这保证了系统中不会存储重复的节点。如若文件内部或文件之间有相同的节点(索引块或数据块),这些节点在物理上只存储一次,在逻辑上通过哈希指针共享。图3所示为两个文件共享索引块和数据块的情况。

图3 文件数据共享
BP-GAD并不是树形结构,而是有向无环图,因为一个儿子节点可能拥有多个父节点。BP-GAD能有效提高文件读性能。在备份过程中,仅将文件的根块存储在元数据库中,恢复文件时,根块被读入内存中,系统根据根块所包含的地址指针直接读取索引块或数据块,而不需要查询磁盘哈希表来获得地址,因而能有效减轻读文件的随机磁盘I/O开销。
3批处理算法

图4 TPBS流程
为了克服备份中的磁盘瓶颈,把数据备份过程分成备份过程和去重过程两个阶段,这样便于对磁盘哈希表进行批处理查找和更新,有效提高备份速度。流程如图4所示。
3.1备份过程
在备份过程中,系统对文件进行分块、计算数据块指纹,并把指纹插入一个内存哈希表中,同时把数据块和指纹暂存到磁盘缓冲区。内存哈希表共2m(m≥20)个桶,每个桶里存放一个链表指针。链表中存储映射到本桶中的指纹。哈希时,取指纹的前m比特作为桶号把指纹映射到相应桶里。
数据链表的节点结构为:
• tag: 标识符,用以指示备份过程中本指纹的状态。
• fingerprintTail: 本指纹的后108比特,因为前20比特隐含在桶号中,故这里只需要存储指纹的后108比特。
• address: 指纹对应的数据块在存储池中的存储地址。
• size: 数据块大小。
• next: 指向下一个节点的指针。
备份时,对一个到来的指纹H,系统检查内存哈希表,如果哈希表中无H,则把H插入内存哈希表中,并把H和其相应的数据块D(H),即
对于周期性备份作业,内存哈希表能预先存放前一次作业的指纹,以便于在备份阶段消除相邻作业间的重复数据。
设内存哈希表桶大小为b字节,桶数为2m,链表节点大小为q字节,平均每个桶存储的节点数为u,则哈希表内存开销为(b+uq)2m字节。又设数据块平均大小为C字节,则(b+uq)2m字节的内存哈希表能支持约uC×2m字节的备份数据量。
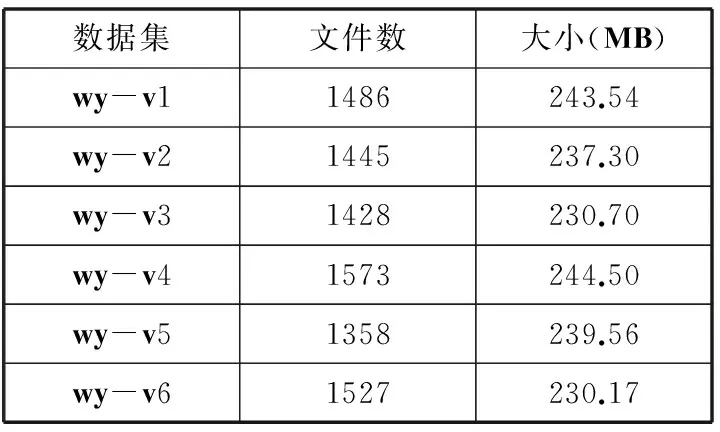
取典型值m=23,b=4,q=25,u=2,C=1024×8,则内存哈希表内存开销为(4+2×25)×223字节(432 MB),支持的物理数据量为2×1024×8×223字节(128 GB)。由于备份数据本身包含的冗余数据量一般很大,实际处理的逻辑数据量会远大于128 GB。故使用约432 MB的内存,每次能处理大于128 GB的备份数据量。
3.2批处理指纹查询
若内存哈希表和磁盘索引分别包含m和n(m 对于一个指纹H,如果在磁盘哈希表的桶中查找到了,则其内存哈希表节点的‘tag’标记为‘旧’,并把它的地址指针 3.3BP-DAG 存储 指纹顺序查询结束后,系统从磁盘缓冲区中读取指纹或数据块为文件构建BP-DAG。在这个过程中,系统查询内存哈希表以获取对指纹的处理方式。对于一个从磁盘缓冲区中读取的单元,处理如下: • 如果是 • 如果是 • 如果为‘新’,则把数据块 D(H) 写入存储池,把存储地址指针< address, size> 写到H的内存哈希表节点中, 把 对于小文件,BP-DAG指针直接存储在其根块中,对于大文件,BP-DAG指针则递归地存储在索引结构中。对于索引块的存储,必须计算其指纹,并查询磁盘哈希表以确定是否为新指纹,如果是新指纹,则索引块被写到存储池,如果是旧指纹,则索引块被丢弃,系统中原存在的索引块被共享。由于索引块的数量比数据块的数量少得多,索引块查询的磁盘I/O开销不大。 BP-DAG存储完毕后,内存哈希表中所有的新指纹都获得了地址指针,这时候,系统顺序读取磁盘索引,按照内存哈希表记录的新指纹对磁盘索引进行顺序更新。更新操作完成后,内存哈希表销毁,数据去重过程结束。 3.4文件读 文件的读过程是一个读取BP-DAG并对文件进行重构的过程。为了便于文件读操作,建立了文件恢复索引:按照被备份的目录结构生成一个相同的目录结构,目录里的文件只有文件名,无内容。 每个文件名对应一个索引项,记录此文件的根块在存储池中的地址。备份完成后,用户得到一个和原目录结构相同但无文件内容的目录结构。恢复时,只要浏览此目录,选择要恢复的目录或文件即可。用户指定了恢复目录后,系统读取目录中文件的索引项,得到其根块地址,按照根块地址从存储池中读取组成文件的数据块,重构文件,并把文件恢复到指定的目录中。 4实验结果及分析 为了测试数据去重算法性能,和传统备份软件Bacula以及没有实现指纹查询优化的数据去重算法进行比较。测试数据来自离线浏览器Offline Explorer Enterprise V6.9从网址www.163.com搜集的网页和文件,搜集深度为2。搜集数据按照时间顺序分为如表1的6个数据集,共8817个文件,约1.39 GB数据,平均文件大小约165 KB。 表1 测试数据集 图5所示为备份数据集所消耗存储空间的对比,图中Dedup为没有实现指纹查询优化的数据去重算法,TPBS为本文提出的批处理块级数据去重算法,数据去重平均分块大小8 KB。Bacula消耗存储空间1425.8 MB,Dedup和TPBS分别仅消耗存储空间415.9、424.3 MB,数据去重效果明显。TPBS较Dedup多消耗8.4 MB存储空间,用于BP-DAGs索引开销。 图5 存储空间消耗 图6所示为备份吞吐率对比。Dedup备份wy-v1达到了和Bacula、TPBS差不多的速度,是因为第一次备份,系统中无旧数据,无须查询指纹。Dedup备份其他数据集速度很慢,仅达到平均0.95 MB/s。而TPBS采用批处理指纹查询,并且在备份阶 段可以通过预先载入相邻数据集指纹的方式消除部分冗余数据,其达到了高于Bacula的吞吐率。 图6 备份吞吐率 图7所示为文件恢复对比。虽然TPBS的文件恢复速度没有Bacula快,但采用BP-DAG技术后,文件恢复速度较Dedup有了明显提高。 图7 文件恢复吞吐率 5结语 本文描述了一种基于批处理的块级数据去重方法,该方法把数据去重过程从数据备份过程中分离出来从而降低了数据去重对应用的影响,同时通过批处理消除了指纹查询和更新的随机磁盘I/O开销。文件以双指针有向无环图的形式存储在系统中,既有利于文件间的数据共享,又有效提高了文件的读性能。在未来的工作中,我们将致力于提高批处理数据去重的可扩展性,以满足大规模分布式数据存储系统的备份需求。 参考文献 [1] 贺翔.一种基于NDMP的块级备份和数据管理方法及其实现[D].中国科学院,2006. [2] 王树声.重复数据删除技术的发展及应用[J].中兴通讯技术,2010,16(5):9-14. [3] Zhu B,Li H,Patterson H.Avoiding the disk bottleneck in the data domain deduplication file system[C]//Proceedings of the 6th USENIX Conference on File And Storage Technologies,2008:269-282. [4] 魏晓玲.MD5加密算法的研究及应用[J].信息技术,2010,35(7):145-151. [5] Rhea S,Cox R,Pesterev A.Fast, inexpensive content-addressed storage in foundation[C]//Proceedings of the 2008 USENIX Annual Technical Conference,Boston,Massachusetts,June 2008:143-156. [6] Lillibridge M,Eshghi K,Bhagwat D,et al.Sparse indexing: Large scale, inline deduplication using sampling and locality[C]//Proceedings of the 7th USENIX Conference on File And Storage Technologies,2009:111-123. [7] Xia W,Jiang H,Feng D,et al.Silo:a similarity-locality based near-exact deduplication scheme with low ram overhead and high throughput[C]//Proceedings of the 2011 USENIX Annual Technical Conference,2011:26-28. [8] Quinlan S,Dorward S.Venti:a new approach to archival storage[C]//Proceedings of the USENIX Conference on File And Storage Technologies,January 2002:89-101. [9] Eshghi K,Lillibridge M,Wilcock L,et al.Jumbo store:Providing efficient incremental upload and versioning for a utility rendering service[C]//Proceedings of the 5th USENIX Conference on File And Storage Technologies,2007:22-38. A CHUNK-BASED DE-DUPLICATION METHOD BASED ON BATCH PROCESS Yang TianmingWu Haitao (CollegeofInternational,HuanghuaiUniversity,Zhumadian463000,Henan,China) AbstractData de-duplication technology, which eliminates the redundant data from backups to save network bandwidth and storage resources, has become a hot research topic in current data storage field. The commonly used chunk-based de-duplication technology suffers from high overhead in fingerprint lookup and low system throughput. In light of this, the paper proposes a chunk-based de-duplication method using batch process, which sorts the fingerprints in memory buffer to achieve the sequential lookup of disk indexes. Moreover, the files are stored to the system in a structure of bi-pointer-based directed acyclic graphs so as to eliminate random small disk I/O costs caused by file read. Experimental results show that this method breaks the disk I/O bottleneck of fingerprint lookup and hence improves read-write performance of the system during data de-duplication. KeywordsBackupData de-duplicationFingerprint queryBatch process 收稿日期:2014-12-08。河南省科技项目(142300410288,132400 411178);河南省教育厅科学技术研究重点项目(112102210446)。杨天明,高级工程师,主研领域:数据存储。吴海涛,副教授。 中图分类号TP333 文献标识码A DOI:10.3969/j.issn.1000-386x.2016.05.012