基于Redis内存数据库的快速查找算法
2016-06-08郎泓钰任永功
郎泓钰 任永功
(辽宁师范大学计算机与信息技术学院 辽宁 大连 116081)
基于Redis内存数据库的快速查找算法
郎泓钰任永功
(辽宁师范大学计算机与信息技术学院辽宁 大连 116081)
摘要大数据时代的到来,使许多云环境下的新型应用蓬勃发展。针对大数据管理的新需求,key-value型数据存储系统成为当今研究的热点。基于key-value引擎的内存数据库Redis以及Cuckoo Hash技术,提出一种混合哈希快速查找算法CSR_Hash。通过对实验结果的分析,表明该算法有效地缩短了查询响应时间,并将其应用在通过Hadoop云平台以及Map/Reduce编程模型实现的图书销售系统中,对图书数据进行实时高效的解析与推荐,增强了NoSQL数据库与Map/Reduce结合的实时性和高并发性。
关键词key-value型存储系统Redis数据库Map/ReduceCuckoo hash
0引言
随着移动互联技术的高速发展,网络上的数据量成指数性增长。针对大数据管理的新需求,面向特定应用的NoSQL数据库应运而生[1,2]。key-value存储系统成为当下比较流行的话题,尤其是在构建搜索引擎以及提供云计算服务的时候,如何保证系统在海量数据环境下的高性能、高可靠性、高扩展性及低成本成为研究重点[3-5]。其中Redis数据库通过把数据保存在内存中或者使用虚拟内存技术来提高系统的使用效率,同时Redis采用key-value存储模式来加速键值对内容的排序与定位。
在日常生活中,人们经常需要使用搜索引擎来解决实际问题,其中一项关键的技术就是数据查找。在key-value型数据库当中,哈希查找方法由于其查找速度快,维护方便等原因而得到广泛的应用[6-8]。
1基于Redis的快速查找算法
1.1Redis简介
作为key-value型内存数据库,Redis提供了键(key)和值(value)的映射关系,而且它支持多种不同的数据类型。目前,新浪微博作为最大的Redis用户,已有400多个端口在同时运行着Redis,进而实时并快速满足用户对微博消息的查看与转发功能[9]。Redis数据库基于内存的特性使其具有优秀的读操作速度。因此,基于Redis数据库的系统在进行查找操作时,可以在纳秒级的时间内得到匹配结果。
1.2基于Redis的前缀匹配
Redis数据库同样提供了很好的索引机制,以实现高性能的实时搜索。基于Redis研究者已经实现了不同的搜索功能。这里我们主要讨论用于前缀匹配的索引。
形如谷歌、百度、雅虎等许多搜索引擎,当用户在界面的搜索框里输入短语或标题时,搜索框下方会自动根据用户的输入从后端数据库里匹配一些相关的内容。这个搜索过程是很快的,在按键的一瞬间就会出现一些提示,这些提示按该短语被搜索的次数进行排名,进而可以帮助用户快速找到想要搜索的事物;同样,一些用户在进行搜索的时候不太确定他想找的东西是什么,但是大概了解,这一提示还可以帮助这类用户完成查询功能。Redis会把每一个字母进行拆分,然后放到Centre里去,它会自动按照字母的方式进行排序,如同建了一个索引一样。在查询的时候就可以按照这个顺序进行查找;在对关键词进行索引时,是通过分词的方式把一个标题分成很多个词语,然后在Redis里建一个ID库,成立一个数据的列表。在前缀匹配的搜索过程中,当用户在搜索“Computer”的时候,首先肯定会按“C”键,Redis会根据这个字母找到其在前缀索引中的第一个坐标,并找到里面标记顺序的序号。然后根据这个序号找一段词,之后会列出相关的实际词的内容,这个时候再根据这些实际词找出其对应的ID,最后通过ID找出这些数据,显示结果。
1.3改进的排序查找算法CSR_Hash
在key-value数据存储模型中,比较典型的是采用哈希函数来实现键到值的映射。在进行查找操作时,基于key的Hash值可以直接定位到数据所在的点,从而达到快速寻址的目的,并支持大数据量和高并发查询。为了进一步提高查询效率,提出了一种基于Redis内存数据库及Cuckoo Hash[10-15]方法的快速排序查找算法CSR_Hash。
1.3.1Hash冲突
使用Hash函数H可以加速键key的索引进程。然而,由于数据集中各元素键的取值可能有一个很大的范围,所以即使当数据集中的元素个数不是很多时,也很难选取出一个合适的Hash函数H,使其保证对于任意不同的keyi和keyj有H(keyi)≠H(keyj)。若keyi≠keyj而H(keyi)=H(keyj),则这种现象称为哈希冲突。在哈希技术中,冲突是不可避免的,只能尽量减少冲突的概率。因此哈希冲突处理是影响哈希表性能的主要因素。为了解决这一问题,通过选择Cuckoo Hash法与链表法相结合的方式,建立一个公共溢出区,并添加键频项来提高查找搜索的效率。
1.3.2Cuckoo Hash
Cuckoo Hash使用两个Hash表Table1和Table2,两个Hash函数,H1和H2。对于一个键key来说,表Table1和Table2分别使用Hash函数H1和H2来创建key在Table1和Table2中的地址,如图1所示。

图1 Cuckoo Hash表
在进行插入操作时,Cuckoo Hash首先根据哈希函数H确定key在这两个Table中的地址。如果其中一个地址为空,就可以直接存储到该地址;若两个地址均被占用,则将这两个地址中的一个key移到其自己的第二个Hash地址中。由于每个key都使用两个不同的地址进行存储,因此这个过程会循环往复,直到找到空闲地址为止。该算法可以提供恒定的查找时间O(1)(查找只要求检查Hash表中的两个位置),而插入时间则取决于高速缓存的大小O(n)。
与链地址法和线性探测法相比,Cuckoo Hash法提供了更加快捷和可靠的查找、删除以及更新操作,但其在插入操作过程中对内存的开销是不容忽视的。
1.3.3改进的CSR_Hash算法
本文提出了一种基于Cuckoo Hash及链地址法处理冲突的混合哈希表查找方法,并在哈希表结构中添加用来提供查找对比的键频项count。count用来存储一段时间内该元素被查找的频率,由该元素被查询次数除以哈希表中所有元素被查找的总次数计算得到。
改进的Cuckoo Hash表的建立过程如下:
(1) 获得键key;
(2) 根据哈希函数H1、H2检查Cuckoo Hash中两个表Table1、Table2所对应的地址是否为空,如果其中一个为空,则直接插入到空地址当中;
(3) 否则根据哈希函数H3插入到链地址哈希表Table3中,并为其添加键频项Lcount;
(4) 为Cuckoo Hash表中的数据元素添加键频项Ccount,并通过直接采用快速排序算法,根据Ccount的值由大到小对键key进行排序,将出现概率大的分配在所需比较次数少的位置,从而提高哈希表的整体查找效率;
(5) 对链地址表中的数据元素同样根据其Lcount的大小进行排序,将Lcount值大的元素上浮至链地址表的表头;当系统空闲,或者链地址表中元素的Lcount值大于Cuckoo Hash表中元素的Ccount值时,链地址表中的元素将被移到Cuckoo Hash表中,以方便查找。
由于在链地址表中的插入操作比在Cuckoo Hash表中所花费的时间少得多,所以用两种方法相结合的方式可以提高系统效率。
同样,在进行查找操作时,首先根据H1、H2查找键key是否存在于Cuckoo Hash的两个Table中,如果不存在于Cuckoo Hash的任何一个表中,则直接通过H3到链地址表Table3中进行查找。算法原理如图2所示。

图2 改进的CSR_Hash算法原理
2CSR_Hash算法在云图书销售系统中的设计与实现
图3为云图书销售系统的总体设计。当Android或者PC端用户通过浏览器登录到系统的查询页面进行查找操作时,系统利用Ajax的异步性以及动态性,实时将需要查找的请求数据传输给云计算平台中的NameNode节点;节点收到实时的请求数据后,利用云平台的Map/Reduce框架执行分布式操作,并结合改进后的CSR_Hash算法在云端的Redis数据库中完成查找过程,来快速匹配出用户需要的数据。之后通过云端HDFS文件系统将结果发送给前端。若没有匹配到结果,则不予提示。
由于Redis是内存数据库,当系统掉电时,数据将会丢失。因此本系统结合云计算平台的数据库Hbase,用来定时同步Redis数据库中的数据。当Redis数据库无法正常工作时,NameNode将直接访问Hbase,进行查询操作,以确保系统正常工作。
2.1基于Bootstrap与Ajax的前端搜索的请求实现
Bootstrap 是基于CSS、HTML和JavaS-cript设计Web应用程序中常用的前端开发技术,它可以搭建美观且功能强大的网站。在本系统中,主要利用Bootstrap框架来设计搜索引擎的Web页面部分。
Ajax是Web 2.0的核心技术[16]。不同于传统的Web模式(请求-等待-响应),它采用异步无刷新的交互方式,即通过Ajax引擎提交请求,服务器做出处理将结果送给客户端,Ajax引擎再次响应进行信息的获取,来实现“按需要获取数据”的局部页面更新效果,从而提高应用程序的效率。
Web前端请求query下发并从服务器端接收结果的实现过程为:
$(″#query″).autocomplete
Source:function(request,response)
//source为输入内容,有改变则发送请求
$ajax
//实际发送的是Ajax请求
url : ″ajax/sug.do″
//发送请求的目的地址
dataType : ″json″
//数据类型为json
data :
query : (″#query″).val()
//发送查询请求
Success:function(data)
//返回时将data填充对话框
2.2基于Map/Reduce的分布式查找算法
Map/Reduce是Google公司基于HDFS基础上实现的一种针对海量数据处理的并行编程模型,利用它可以简化程序员的开发工作。
Map/Reduce在任务处理时,主要采用“分而治之”的策略。首先把输入的数据集拆分成N个数据块并分配到不同的DataNode节点上,之后由多个DataNode节点通过“代码找数据”的模式完成Map任务并生成中间数据;之后Reduce任务会对输入的参数进行计算和汇总,来得到最终的计算结果。
将Map/Reduce编程模型与Redis数据库相结合,可以提高系统的实时性和高并发性。具体的实现过程为:
//Map过程解析出关键字
Function Map(QuestAll,QuestKeyword)
LineMessage←QuestAll.toString();
JspQuest[]←LineMessage.split(″″);
If JspQuest[1].Indexof(″sug.jsp?query″)
QuestKeyword←JspQuest[1]..splite(″query=|″);
//Reduce过程查找排序
Function Reduce(QuestKeyword,Result.value)
Result.value←CSR_Hash(″QuestKeyword″);
2.3系统实现过程
为了提高本系统检索模块的效率,提升用户的使用体验,使用户可以利用高效的搜索提示功能,完成检索查找工作。因此在设计中,服务器端运用云计算相关技术,在使用因特尔酷睿i3处理器,百兆以太网网卡以及4 GB内存硬件的基础上,利用开源的Cent OS作为云计算平台的操作系统,在系统之上搭建了Hadoop-0.20.2版本的云集群,相关的节点配置如表1所示。

表1 节点配置表
如图4所示,通过Hadoop云平台提供的50070端口,我们可以查看该平台文件系统实时的使用情况。

图4 图书销售系统的节点信息
图5为系统实现的效果图。当用户输入字母“a”之后,输入的内容会被实时下发到系统中,系统首先对输入的数据进行关联,然后对关联的结果以评分的先后顺序进行排序,之后把排名前五位的结果返回到Web前端。当用户再次输入字母“l”之后,由于没有使用空格等分隔符,因此这里没有进行分词操作,而是直接作为一个词,继续进行关联排序,最终获得结果,传送到前端显示。
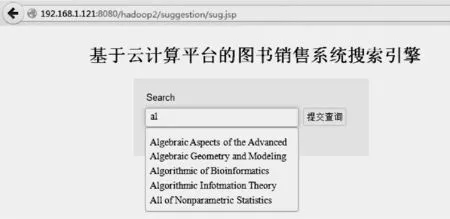
图5 系统实现效果图
3实验结果分析
为了测试改进后算法的性能,在图书销售系统中进行两个实验。
实验一在单节点实验环境中,完成相同查找任务的前提下,链地址哈希法Chained_Hash、Cuckoo Hash法及改进后的查找方法CSR_Hash用时情况如图6所示。

图6 完成相同查找任务的前提下三种算法在时间花销上的对比
实验二完成相同查找任务的前提下,分别在计算节点为1~6时对改进后的查找算法进行测试,实验结果如图7所示。

图7 云集群节点的个数与查找时间之间的关系
图6通过对Chained_Hash、Cuckoo_Hash以及CSR_Hash三种算法的对比可以看出:在查找成功的情况下,对于小批量的key查找,三种算法在效率上的差别并不大;但是随着key查找数量的增加, Chained_Hash算法由于在遍历查找的时候缓存性较差所以是三者中时间花销是最大的;Cuckoo_Hash算法虽然天生具有高概率的特性,且hash key分布均匀,但由于其哈希冲突处理时间较长,在相同条件下查找的成功率较低,因此在平均用时上比Chained_Hash略少;而CSR_Hash算法采用双Hash地址查找方式,并且在表中添加用来标记查找频率的键频项,因此在查找成功时,查询的速度最快。但是在查找不成功的时候可以看出,采用改进的CSR_Hash算法由于不成功时需要进行多次查找确认,所以在时间上开销比Cuckoo_Hash大,但仍比Chained_Hash法查找所用时间少。
从图7中可以很明显观察到,在查找量一定的前提下,随着云集群节点的增加,查找所需时间明显减少;当节点数到达6个以后,此时再增加节点的个数,查找的时间开始趋于稳定。这是由于云集群自身节点通信需要时间,而且算法本身也需要时间进行处理。
4结语
key-value型数据库是应用于云环境下的典型云存储系统。在基于前缀匹配的搜索查询操作中,系统需要根据用户提供的关键字,快速找到并推荐用户需要的信息,采用哈希表结构可以直接定位数据所在的节点,且维护方便。基于key-value引擎的Redis内存数据库,提出了一种改进的快速查找算法CSR_Hash,并将其应用在基于云平台的图书销售系统中进行查找提示服务,充分发挥了Redis数据库高效的索引与查询优势。使得海量数据下的云图书销售系统拥有更好的发展前景。基于key-value数据模型的存储系统只支持简单的数据查询操作,所以如何结合Map/Reduce模型来实现资源的负载均衡,是接下来研究的重点。除此之外,云环境下数据管理的安全性始终是研究热点,需要我们不断的学习与探索。
参考文献
[1] 申德荣,于戈,王习特,等.支持大数据管理的NoSQL系统研究综述[J].软件学报,2013,24(8):1786-1803.
[2] 覃雄派,王会举,杜小勇,等.大数据分析——RDBMS与MapReduce的竞争与共生[J].软件学报,2012,23(1):32-45.
[3] 陈全,邓倩妮.云计算及其关键技术[J].计算机应用,2009,29(9):2562-2567.
[4] Robert Escriva,Bernard Wong,Emin Gün Sirer.HyperDex:A distributed,searchable key-value store[J].Acm Sigcomm Computer Communication Review,2012,42(4):25-36.
[5] Christian Tinnefeld,Alexander Zeier,Hasso Plattner.Cache-conscious data placement in an in-memory key-value store[C]//Proceedings of the 15th Symposium on International Database Engineering & Applications,Lisboa,2011:134-142.
[6] 王珊,肖艳芹,刘大为,等.内存数据库关键技术研究[J].计算机应用,2007,27(10):2353-2357.
[7] 袁培森,皮德常.用于内存数据库的Hash索引的设计与实现[J].计算机工程,2007,33(18):69-71.
[8] 马如林,蒋华,张庆霞.一种哈希表快速查找的改进方法[J].计算机工程与科学,2008,30(9):66-68.
[9] 唐诚.Redis数据库在微博系统中的实践[J].厦门城市职业学院学报,2012,14(3):55-59.
[10] Rasmus Pagh.Flemming Friche Rodler Cuckoo Hashing[J].Journal of Algorithms,2004,51(2):122-144.
[11] Lai Y,Zhongzhi S.An efficient data mining framework on Hadoop using java persistence API[C]//IEEE 10th International Conference on Computer and Information Technology,2010:203-209.
[12] Zhao Fuyao,Liu Qingwei.A string matching algorithm based on efficient hash function[C]//International Conference on Information Engineering and Computer Science,2009:1-4.
[13] Ye Junmin,Li Songsong,Hao Guangquan,et al.Prefix and suffix query of chinese word segmentation algorithm for maximum matching[C]//International Conference on Image Analysis and Signal Processing,2011:74-77.
[14] Chouvalit Khancome,Veera Boonjing,Pisit Chanvarasuth.A two-hashing table multiple string pattern matching algorithm[C]//Tenth International Conference on Information Technology: New Generations,2013:696-701.
[15] Dean J,Ghemawat S.MapReduce:a flexible Data processing tool[J].Communications of The ACM,2010,53(1):72-77.
[16] 王锟,方明.Aajx技术研究与应用[J].现代电子技术,2008,31(6):93-98.
A FAST SEARCH ALGORITHM BASED ON REDIS MEMORY DATABASE
Lang HongyuRen Yonggong
(SchoolofComputerandInformationTechnology,LiaoningNormalUniversity,Dalian116081,Liaoning,China)
AbstractThe arrival of the era of “big data” makes the novel applications in cloud environment in full swing. Aiming at the new requirements of big data management, the key-value data storage system is becoming the focus of current researches. This paper proposes a fast hybrid hash search algorithm (CSR-Hash), it is based on Redis, an in-memory database of key-value engine, and the technology of Cuckoo Hash. Through analysing experimental results, it shows that the algorithm effectively shortens the query responding time. We applied the algorithm in a book sales system implemented through cloud platforms of Hadoop and Map/Reduce programming model to carry out efficient parsing and recommendation on book data, this enhanced the real-time and high-concurrency performances of the combination of NoSQL database and Map/Reduce.
KeywordsKey-value storage systemRedis databaseMap/ReduceCuckoo hash
收稿日期:2014-10-28。辽宁省计划项目(2012232001);辽宁省自然科学基金项目(201202119)。郎泓钰,硕士生,主研领域:数据挖掘。任永功,教授。
中图分类号TP399
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.05.011
