基于游戏玩家流失预警的改进决策树算法
2016-06-08林雪云
林雪云
(福建师范大学福清分校, 福建 福清 350300)
基于游戏玩家流失预警的改进决策树算法
林雪云
(福建师范大学福清分校, 福建 福清350300)
摘要:首先对样本数据的影响因素进行logistic回归剔除绝大部分噪声因素,再通过降维和共线性诊断进一步筛选出影响因素中对实际结果有重要影响的指标以及共线性的指标,剔除无用和重复的类别,对清洗后的数据进行分析。最后进行了实例验证。
关键词:决策树; 流失预警; 降维; ID3算法; CART算法; logistic回归
0引言
对网游企业而言,游戏玩家的流失情况至关重要,直接关系到企业的收益。传统的数据挖掘算法已不再适应时代的需求,针对大数据量如果无法快速地获得行业中的最新信息,对网游这一及时性和更新频率极高的行业而言就是致命的。
研究决策树在游戏玩家流失预警中的具体应用可以很好地解决这一问题,文中改进的决策树模型可以用于大数据分析,在减少计算量,提高运行效率的同时,增加预测的精确性,方便运营做出更加贴合实际的决策。
1决策树模型
1.1决策树算法简介
决策树算法[1]是数据挖掘算法中的一种分类算法,且在各种分类算法中,决策树能够最为直观看到分类的节点与方法,也更易于获得决策,因此被广泛用于数据挖掘中。
游戏玩家的流失预警将会用到ID3算法以及CART算法,两种算法分别是基于信息增益和节点不纯度的算法,文中通过对两种算法的结合获取最优决策树。
1.2ID3算法与CART算法简介
1.2.1ID3(Iterative Dichotomizer 3)算法
ID3算法[2]是一种较为经典的决策树算法,算法的主要思想是从根节点出发,赋予最优属性,之后将该属性的每个取值作为一个分支,以其分支为起点生成新的节点,对最优属性的选择标准是借鉴于以信息熵为定义的信息增益来选择每个节点的测试属性,熵(Entropy)亦成为了任意样本集纯度的衡量标准。
该算法局限性在于只能针对离散值,且算法在运算时仅考虑一个信息增益方面,即使得越在上层的节点对目标属性提供的信息越多,但并未考虑到由于属性的确定所带来的不纯度方面的影响。且ID3算法所生成的节点的分类可能有很多无用分类,即很多分类是可以进行合并的。
1.2.2CART算法
决策树算法实际上就是将样本划分成越来越小的子集,最为理想的状态即生成的决策树的所有叶子节点的标记都是一样的。如果实现,则决策树的分支过程应该已经停止,因为其中已经不包含隐藏的类别了,但是这只是一个理想化的状态。现实数据的处理中,由于较大噪声样本等情况的存在,划分往往是很难一步就达到目标的,而分类过程需要不止一步才能达到目标,那么这个分类对的过程即一种递归树的生长过程。CART则是当前仅有的一种通用的树生长算法。
CART算法[3]主要包括3个部分:
1)节点属性选择原则。CART算法对节点选择的原则可以从CART算法的目标出发来看,就是使得节点的不纯度尽可能的降低,不纯度(Impurity)是相对于纯度的概念,对一个节点不纯度的衡量往往比对其纯度的衡量更为方便,也更加利于分类。
2)分支停止原则。对现实数据的处理,往往会由于一些误差值或者极端值导致一类数据无法继续细分,这就需要对数据分支在什么时候停止进行判定,如果都是分支到不纯度达到最小,那么最后的结果可能是每个节点只对应一个样本,设计最初的目的分类就无法得到体现,因为这样的结果最多得到的就是一张巨大的“查找表”,而未实现对数据的分类。
一种分支停止原则为验证和交叉验证技术[4-6],即在验证时选择部分样本进行验证,而另一部分样本作为测试验证的样本集,分支操作直至对于验证集而言分类误差最小;另一种分支停止原则即在分支过程中设置阀值,在分支误差小于阀值时,停止分支操作。
3)剪枝。实际上是分支的逆过程,在决策树充分“生长”的情况下对决策树进行剪枝,即对所有相邻的节点,如果剪去这一分支,使得不纯度的增长很小,那么这一分支即可抹去。不足之处在于:当数据量过大时,为了剔除噪声因素即剪枝在计算量上的代价过大,甚至于无法实现。
1.2.3改进算法
针对上述ID3算法和CART算法的不足之处,文中提出了一种新的决策树算法,算法结合了ID3算法和CART算法,即通过ID3算法来初步生成决策树,再通过CART算法对决策树进行剪枝,从信息增益和不纯度两个方面同时考虑,而单纯用CART对模型进行剪枝往往会由于数据量的过大或者影响因素过多造成计算量的代价过大,所以在进行决策树模型之前,先通过logistic回归挑选出对目标变量有显著影响的因素,再通过降维和共线性诊断进一步剔除无用和重复统计的变量,大大缩减了CART模型的计算量。
2改进的决策数算法具体实现
在一款游戏的运营中,游戏玩家的流失预警是指对游戏玩家的流失能够进行预判,使得网游企业能够及时调整游戏的运营,减少由于运营上的过失等造成利益上的损失,实现游戏运营的利润最大化。游戏玩家流失的影响因素中大致由以下4部分因素组成:
1)上线情况。反映上线情况的指标有上线时长、上线频率。
2)充值情况。反映指标有充值频率、充值间隔、首充间隔。
3)角色情况。反映指标主要有角色等级信息、社群以及参与活动信息。
4)游戏广告宣传的环境因素。主要指标为地推效果、广告来源等。
下面对这4部分因素抽取一段时间数据(以14 d为流失标准和考察期间)进行分析。
2.1决策数算法数据源
选取一段时间段游戏玩家的上线、充值、角色情况以及之后的流失情况数据,总数据量18 012条,初始指标41个,通过对玩家上线、充值和角色情况数据的分析得到决策树,从而得到对玩家流失行为发生的预判模型,对玩家流失风险进行评估。
2.2改进决策数算法
2.2.1指标筛选
首先对游戏玩家流失数据源进行指标粗筛选,由于影响因素较多,所以必须先对模型进行降维,降维方法选择主成分分析法中的因子分析,因子分析中使用最大方差法得到其旋转解,即新的替代变量,代替原因素进行分析。得到的结果见表1。

表1 各成分解释的方差
由表1中“方差的%”项可知各个成分所能够解释的方差,选取前5项即解释方差>5%的成分进行分析。研究所解释方差>5%的前5项成分的组成因素,选取其中影响较大的因素进行分析,从而获得玩家流失的主要影响因素有18个。
通过在数据源中剔除这18个因素之外的数据进行共线性检验,得到相关的关联矩阵表,接着通过多项logistic回归获取对游戏玩家流失造成影响的数据,使用似然比检验,置信区间设置为95%。剔除其中共线性的指标,避免重复分类造成分类标准的错误导致决策失准[7]。
在剔除方法上文中选择的是先对游戏玩家流失数据源进行降维分析,降维方法通过系数相关矩阵来检验变量中的共线性,剔除其中的共线性指标。剔除标准为相关系数达到75%以上的系数即可认为存在共线性,即两者之间有较强的相关性,在下面的分析中只要选其中解释方差%更高的一项即可。
从选出的共线性指标的意义来看,共线性的剔除还是有效的,Level和Total_Battle_lev分别为等级和战斗值,从游戏的角度,等级越高,则其战斗值越高,Last_login和Last_Server_Date上次登录时间和上次登录服务器的时间(这两个的区别在于一个是登录账号,一个是登录游戏服务器,玩家一般是登录账号之后就登录游戏服务器开始游戏,但由于之间可能存在的一段时间差,导致数据不完全匹配)。
对数据进行标准化,以避免由度量问题带来的误差,就可以开始对数据进行决策树算法的分类。
2.2.2决策树的初步生成
因为如果对所有的指标都进行描述则过于繁杂,所以下面算法的具体实现过程是抽取样例数据且抽取关键性指标(即在之后的决策树结果中出现的指标Online_Days_byserver、Total_Credit_byserver、Total_Battle_lev进行分析)。
下面对决策树第一个分类指标的生成(取小样本数据总共537条记录)进行描述之后的分类指标的生成类似,见表2。
根据ID3算法得到第一步的决策树,之后的分类指标及其层次也是按照这个过程获得。
2.2.3决策树的分支停止
对于决策树的分支停止原则,采用熵不纯度分至阀值为止。对于节点N而言,其上的熵不纯度为
ImpN=-jPwjlog2P(wj)
式中:P(wj)----节点N处属于类别wj的样本数占总样本数的比重。
2.2.4决策树的剪枝
决策树的剪枝过程与分枝停止过程的判断恰恰相反,分枝停止过程是判断熵不纯度分值低于阀值时停止操作,而决策树的剪枝则是在决策树充分生长之后对决策树中相邻的节点进行是否剪枝的判断,即对抹去一根枝条对熵不纯度会不会造成巨大的影响,如果影响较小,那么完全可以剪去这段枝干。至此决策树的构建就已完成。
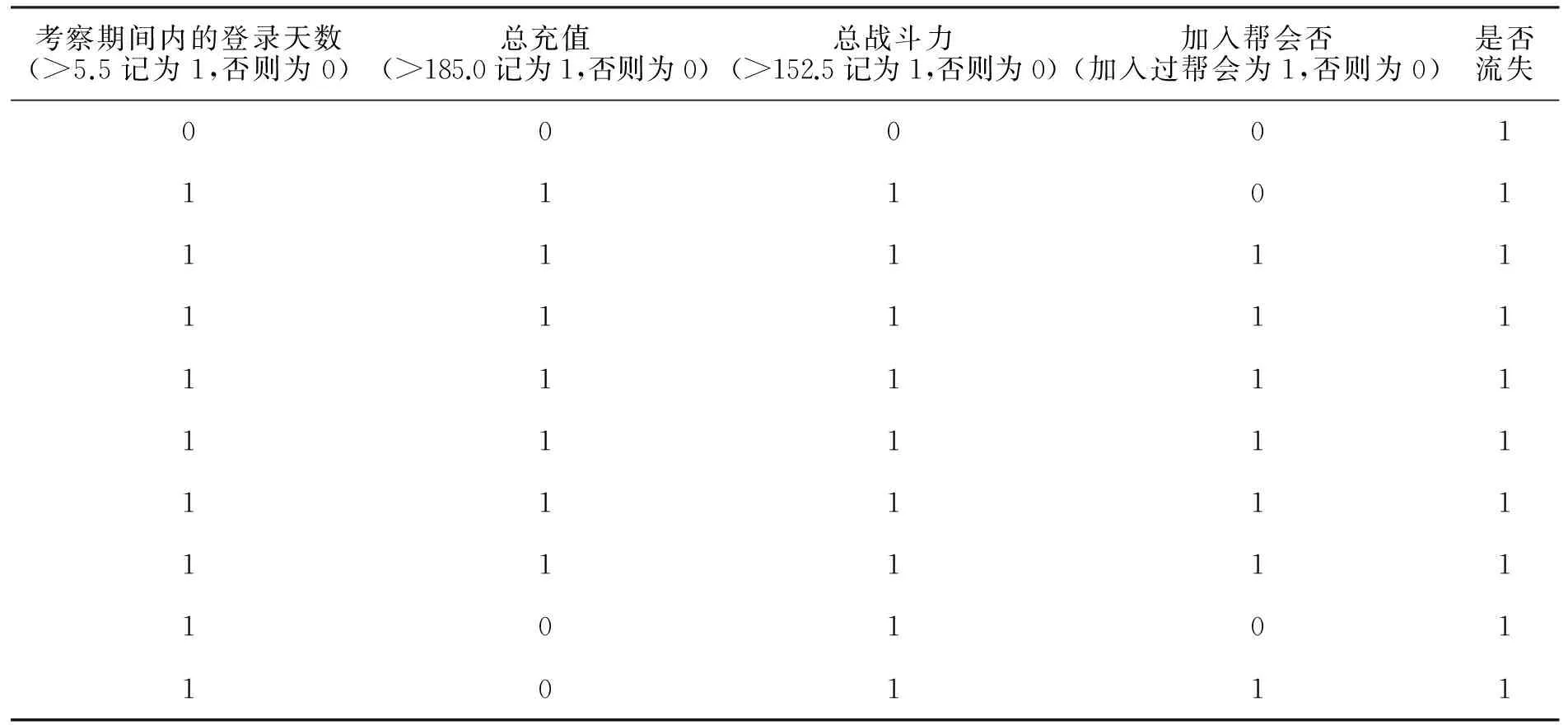
表2 小数据样本前10条记录表样例(部分指标用于阐述算法)
从生成的决策树中可以看出,玩家是否流失(is_running_off)主要影响因素为Online_Days_byserver(考察期间内的登录天数),Total_Credit_byserver(总充值)以及Total_Battle_lev(总战斗力),且影响能力递减,Onlie_Days_byserver是玩家是否流失的先决的判定标准,这亦符合现实案例,因为玩家流失的最直观表现即是不再上线或者由于对游戏的兴趣缺乏,只是受既往习惯的影响,隔天等登录一次游戏,之后就是充值金额以及战力。充值金额对玩家是否流失的影响在于玩家若是喜爱某款游戏,必会经常性或者大量充值游戏,以求在游戏中获得成就感。最后战力对玩家流失的影响则不是直观可以看出,战力越高的玩家越容易留在游戏中,若是新手并且影响过大则表明游戏机制可能有一定问题,因为这样会导致新手玩家很难在游戏中存活,游戏很难获取新玩家进入,那么游戏的盈利能力就会极差。
2.3改进的决策树与传统的决策树算法效果对比
对3种算法在事例数增加时分类错误率的效果进行对比,见表3。
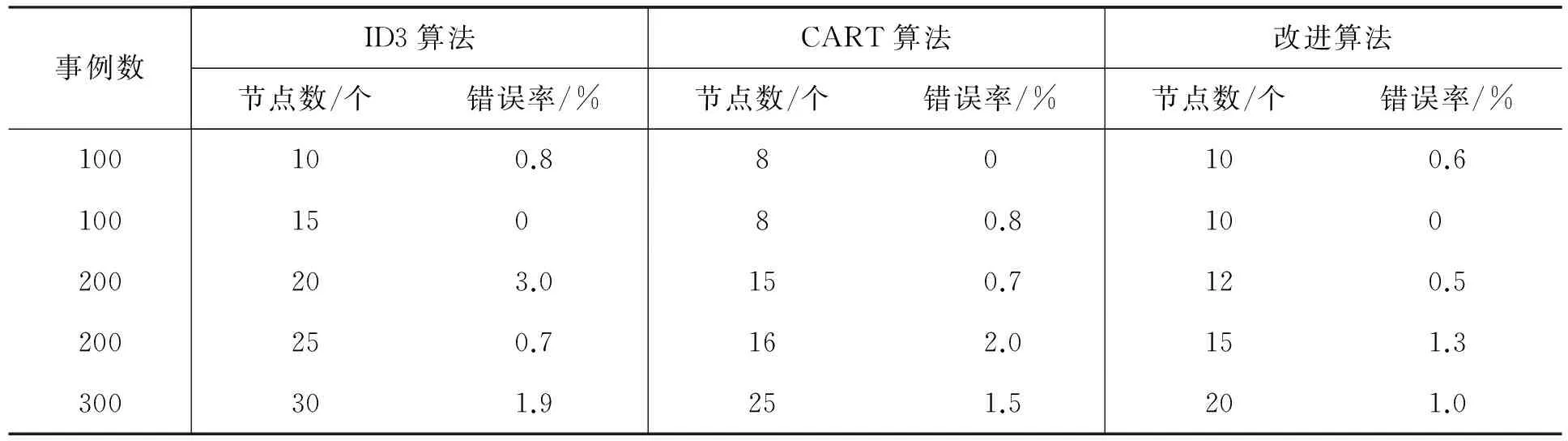
表3 3种算法在事例数增加时分类错误率的效果对比表
下面通过在节点数相同情况下3种算法的错误率的效果对比来验证改进算法的有效性,如图1所示。
从图中可以看出,改进的决策树算法相对于传统的ID3算法以及CART算法而言具有更小的错误率,即可以获得更加准确的决策方案。
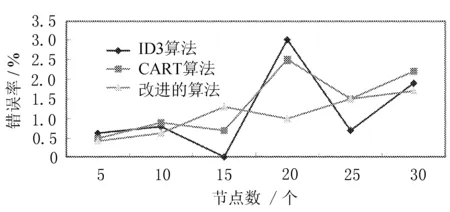
图1 随着分类节点数增加3种算法效果对比图
3结语
传统的决策树算法在运用到CART算法时,往往由于算法中大量的噪声指标和数据的影响造成数据不准,而为了剔除这类指标变量,所付出的代价往往是巨大的计算量,所以,文中在运用决策树算法的起始步骤中增加了对数据源的进一步清洗,主要通过降维和共线性诊断来剔除无用和重复指标[8]。
1)通过主成分分析中的因子分析进行降维,降维时用到的并不是降维后的变量,而是降维后能够解释方差百分比较高的因子中所用到的变量(指标),从而得到对分析结果有显著影响的指标。
2)通过logistic回归以及共线性诊断剔除数据源中无用的噪声指标以及存在共线性关系的指标,因为这类指标的存在往往会使得同一类的数据被强制分类了两次,造成的不只是计算量上的增加,还有数据的多次无用分类,可能对运营决策造成重复分析的影响。而文中用到的方法能够很好地规避这类影响。
决策树算法在决策树的生成过程中无法无视数据量纲,即决策树的生成中原始数据的量纲仍能对文中提到的改进的决策树算法造成影响,未来的研究方向即在决策树算法中引入马氏距离来避免数据量纲对决策树结果造成的影响,同时也要考虑到由于在模型中对马氏距离的引入所造成的对数据计算量上的代价。
参考文献:
[1]李华,刘帅,李茂,等.数据挖掘理论及应用研究[J].断块油气田,2010,23(1):88-89.
[2]Deng Chengyu, Zhang Jiantao, Liu Yongshan. Researchon dynamic load balancing strategy and corresponding model [J]. Computer Engineering and Applications,2011,47(8):131-134.
[3]陈辉林,夏道勋.基于CART决策树数据挖掘算法的应用研究[J].煤炭技术,2011,10:165-166.
[4]方敏,牛文科,张晓松.分类回归树多吸引子细胞自动机分类方法及过拟合研究[J].计算机研究与发展,2012,49(8):1747-1752.
[5]Maji P. fuzzy-rough supervised attribute clustering algorithm and classification of microarray data [J]. IEEE Trans on System, Man and Cybernetics, Part B,2010,41(2):1-12.
[6]冯少荣.决策树算法的研究与改进[J].厦门大学学报:自然科学版,2007,46(4):496-500.
[7]陈戈珩,胡明辉,吴天华.基于支持向量机和HMM的音频信号分类算法[J].长春工业大学学报,2015,36(4):369-373.
[8]赵强利,蒋艳凰,卢宇彤.具有回忆和遗忘机制的数据流挖掘模型与算法[J].软件学报,2015,26(10):2567-2578.
Improved decision tree algorithm based on game players erosion warning
LIN Xueyun
(Fuqing Branch, Fujian Normal University, Fuqing 350300, China)
Abstract:First the logistic regression is used to eliminate the noises from the important factors in sample data, and then the influential and collinear indexes in the factors are picked out with dimension reduction and collinear diagnosis to eliminate the useless and redundant data. The processed data are analyzed and verified with examples.
Key words:decision tree; loss of early warning; dimension reduction; ID3 algorithm; CART algorithm; logistic regression.
收稿日期:2016-01-10
基金项目:福建省教育厅B类项目(JB13197)
作者简介:林雪云(1976-),女,汉族,福建闽侯人,福建师范大学福清分校副教授,硕士,主要从事数据挖掘方向研究,E-mail:58452805@qq.com.
DOI:10.15923/j.cnki.cn22-1382/t.2016.2.16
中图分类号:TP 311.1
文献标志码:A
文章编号:1674-1374(2016)02-0182-05
