高校数据隐私保护技术
2016-06-06王玉平吴慧韫
文/王玉平 吴慧韫
高校数据隐私保护技术
文/王玉平吴慧韫
随着高校信息化的发展,以及大数据、物联网和云计算技术的发展,越来越多高校或主动或被动地进入了大数据时代。从校园一卡通、网络访问行为到教学、科研等各类业务系统,都产生积聚了大量数据,而这些数据的价值毋庸置疑,对于学校来说是很宝贵的,而且里面有大量的用户隐私信息,一但泄露,用户的隐私将被侵犯。在实际使用中,一部分数据用于校内信息化部门或各系统自主分析,或者共享给校内科研团队进行科研分析,或者共享给外部技术公司来进行分析。而这些不可避免地涉及到用户的隐私问题。尤其是常见的姓名、工号、邮箱地址、身份证号等与人员标示相关的数据。
20世纪最著名的用户隐私泄露事件发生在美国马萨诸塞州。为了推动公共医学研究,该州保险委员会发布政府雇员的医疗数据,并且对数据进行了初步的匿名化处理,删除了所有的敏感信息。然而,来自麻省理工大学的Sweeney还是根据另外一份公开的投票人名单,进行数据匹配,成功破解了这份医疗数据,确定了具体某一个人的医疗记录。2006年,美国在线公司(AOL)公布了超过65万用户三个月内的搜索记录,以推动搜索技术的研究。AOL用一个随机数代替用户的账号进行匿名化处理,但《纽约时报》成功将部分数据去匿名化,并公开了其中一位用户的真实身份。美国网飞公司(Netflix)曾举办了一个推荐系统算法竞赛,发布了一些“经过匿名化处理的”用户影评数据供参赛者测试,仅仅保留了每个用户对电影的评分和评分的时间戳。然而,来自德州大学奥斯汀分校的两位研究人员借助公开的互联网电影数据库(IMDB)的用户影评数据,获得了IMDB用户。为此,2009年Netflix遭到了4位用户的起诉,也不得不取消了该竞赛。
此外,政府主导的公共数据的开放,也面临着和医疗数据同样的隐私保护问题。以上各方面都促进了数据隐私保护技术的发展。

图1 数据匿名化处理
数据匿名化的技术
通过数据匿名化,机密数据的关键部分将被模糊化,从而保护了数据隐私。但是该部分数据仍然可以被处理分析以获得一些有用信息。也就是说,数据匿名化不能影响数据的可分析部分的结果,否则数据匿名化就失去了它的价值。
譬如上海海事大学员工的乘车数据,校内一位老师提出申请,希望获得班车数据进行分析,对学校的管理提出改进建议。若不进行匿名化,则该老师获取了非授权内的信息,而且也是其他老师不愿意被共享的信息,其次,姓名等信息与该老师的预期分析结果无关,所以可以对班车数据进行数据匿名化处理。如图1所示。
图1展示了使用数据匿名化保护数据隐私的一个简单示例,除了简单替换学工号,还可以通过添加一些虚构数据,从而避免被获取内部师生的真实数量信息。若对方形成了有效的分析方法,我们可以将该方法应用于我们内部的真实数据,从而得到真实的结果为管理层决策提供数据分析支撑。然而实际案例不是如此简单,如果仅仅替换学工号,如同AOL的案例一样,安全研究人员还可以通过分析其他数据,进行关联性分析,推断出代号对应的实际学工号。
目前数据隐私保护的方法可以分成以下几类:
1.扰动(Suppression)和泛化(Generalization)的方法。扰动是对原数据中正确的数值做一些变换,比如加上一个随机量,而且当扰动做完后,要保证分析扰动数据的结果和原数据的结果一致。泛化是指从一个合适的范围内将原值替换为一个新值,例如将日期随机替换为一年内的某一天。许多未经过处理的数据都包括用户的姓名、身份证号等身份信息,这些属性在公开前可以直接删除或者替换为某个值,也可以看作泛化的一种形式。
2.k-匿名化(k-anonymity)和l-多样性(l-diversity)的方法。
6.讲究读书方法。读书“最好使学生自学”。读书不只是学生课堂上被动听老师“灌”,须有预习与复习两个自学环节。“功课应该自己先去温习,或说是预备,将未曾教过的书,自己先去研究一下,后来先生教起来,容易明了。”[2]卷5,61对于老师教过的知识,要做到“课后再去复习一次,那就不容易忘却了”。联系到英语学习,遇一字多解不能判定时,经过“一番自修”,就会有自己的思考和判断。其他如矿物、植物、物理、化学等科,非机械地记牢不可。概言之,也就是蔡元培为发挥学生的主体作用,所提倡的自动、自学、自助、自研“四自”读书方法。
数据集上的个体识别字段有可能需要一个或多个字段构成,这些属性的集合称为准标识符(Quasi-Identifier, QI)。通过准标识符可以充分识别唯一一个个体,例如姓名和学工号。k匿名化通过扰动和泛化的方法使得每一个准标识符都至少对应k个实例,这样就不能惟一识别,从而保护了用户的隐私。k-匿名由Samarati和Sweeney(也就是前文提及的马塞诸塞州用户泄露案例的攻击者)提出,可以保证任意一条记录与另外的k-1条记录不可区分。
3.分布式(Distribution)隐私保护。大型的数据集可以在被分割后发布。划分可以“纵向”地进行,例如将数据分成不同的子集分别在不同的地方公开;也可以“横向”地进行,例如按照属性划分成不同的数据集再公开,或者两者结合起来。例如班车数据,可以根据不同的需要只提供代号和刷卡时间,不提供地点;或者只提供某年某月的班车数据。
4.降低数据挖掘结果的效果。在很多情况下,即便数据无法被获取,数据挖掘的结果(比如关联规则或者分类模型)仍然有可能泄露隐私。为此可以隐藏某些关联规则或轻微改变分类模型来保护隐私。
5.差分隐私(Differential Privacy)保护的方法。它是Microsoft研究人员在2006年提出的,基本思路是通过添加噪声的方法,确保删除或者添加一个数据集中的记录并不会影响分析的结果;差分隐私保护定义了一个极为严格的攻击模型,并对隐私泄露风险给出了严谨、定量化的表示和证明。差分隐私保护在大大降低隐私泄露风险的同时,极大地保证了数据的可用性。差分隐私保护方法的最大优点是,虽然基于数据失真技术,但所加入的噪声量与数据集大小无关,因此对于大型数据集,仅通过添加极少量的噪声就能达到高级别的隐私保护。因此,即使攻击者得到了两个仅相差一条记录的数据集,通过分析两者产生的结果都是相同的,也无法推断出隐藏的那一条记录的信息。
k-匿名化和l-多样化
k-匿名化和l-多样化虽然因其模型不够稳固而受诟病,但是其操作方便简易,在数据共享范围受限的情况下,依然可以采用该方法进行数据隐私的保护。下面就两个隐私保护方式进行简单介绍。
如果将一组数据k-匿名化,并且每项数据记录中都有一组预先设定的属性,那么至少有k-1个其他记录与这些属性匹配。例如,假定班车数据集包含一个属性——刷卡时间,如果对该数据集执行k-匿名化操作,则对于每个刷卡时间,都有k-1条其他记录与其拥有相同的刷卡时间。一般来说,k的值越大,隐私保护越有效。见表1。

表1 班车刷卡数据集
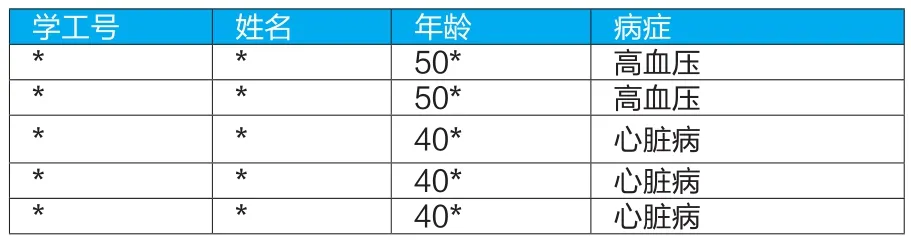
表2 职工体检数据集
相对于班车记录属性较少的情况,数据匿名技术最早应用于医疗信息的共享。譬如学校体检信息,里面可能会出现比较敏感的病症,也属于个人极不愿意公开的信息,这时候,字段会较多,出现见表2的记录。
在这份表格中,学工号和姓名字段进行隐藏处理,而年龄进行了泛化处理,代表年龄段,对于准标识符,提供了两个冗余样本(k=2),实现了匿名化,但不影响判断哪个年龄段出现病症的分布判断。尽管k-匿名化可以保证无法从k个数据集中识别个体,但是依然会受到很多攻击。
基于同质的攻击。如果攻击者知道某个教师年龄段,譬如为40多岁,那么可以根据表中记录推断出他有可能有心脏病,见表3。
背景知识攻击。如果攻击者知道某个教师在早晨有课,且在出发站上车,那么很容易推断出他有可能是在7:01或7:02刷卡上车,进而推断出其他信息。
针对以上两种攻击,有必要引入另外一种隐私保护技术l-多样化。l-多样化主要是指在k-匿名化的基础上,对每个准标识符组合添加l个不同的关键值。对表4添加l-多样化后,可以得到表3,其中l=1。通过多样化后,你无法猜测40多岁的人是否患有疾病或者患有什么疾病。
但是这样一来,虚构的关键字段信息为分析工作带来了麻烦,而且从概率上推断,依然可以得出40岁年龄段的某位教师得的疾病。如果需要解决类似问题,则需要用到差分隐私保护技术。

表3 多样化处理后的数据集

表4 数据隐私处理方式
高校中的隐私保护方法
由于高校隐私保护需求和数据的公开范围的受限,对于数据隐私保护的要求没有政府公开数据、医疗数据等面向全社会公开的数据的要求那么高。因此在实际使用中,可以结合k-匿名化和l-多样化进行匿名化处理,对某些属性进行处理,建议方式如表4所示。
在实际使用中,我们根据Intel《利用数据匿名化技术增强云的信息安全》一文,对基本的常用隐私保护操作方式进行了总结,并在实际使用中取得了较好的隐私保护效果。
实践操作中常用的模糊方法有:
隐藏
把关键字段的值替换为一个常数值。譬如对月薪统一替换为0,或者身份证号统一替换为18个X。该方法适用于隐藏无需处理或者不必要的信息。
散列
将一个或多个字段的值(尤其是准标识符)通过散列函数映射到一个新的值。譬如对姓名、学工号合并进行运算,得到一个新的散列值,可以代表两个值的唯一性。
置换
置换也是映射的一种方法,但需通过额外的映射表来进行转换,也可以进行逆运算推断出源信息。
位移
对数值进行函数运算得出新的数值。该方法不需要额外的映射表,只需要特定的一个函数计算方法即可。
枚举
枚举也是映射的一种处理方式。但是它主要用于可排序的字段,新的数值必须保留原先的排序顺序。
截断
截断是字符串常用的一种处理方式,譬如对于电话号码,可以只取前几位和后几位,或者只取前几位,用以区分运营商和地理位置。
通过以上简单的处理,再加以纵向减少数据量,可以显著地降低隐私暴露风险。在对外提供数据时,如校内搞用餐大数据分析活动、WIFI访问分析以及班车数据分析等活动时,都可以避免隐私泄露。
在大数据的场景下,单纯靠一种隐私保护技术已经很难避免安全攻击,许多隐私保护方法融合了多种技术。k-匿名和l-多样化是基于限制发布的泛化技术的比较有代表性的两种隐私保护方法。但是k-匿名易受到一致性攻击(homogeneity attack)和背景知识攻击(background knwledge attack)。而Machanavajjhala等人提出了l-多样化原则,虽然避免了一个等价类中敏感属性取值单一的情况,并确保隐私泄露风险不超过1/l,但依然容易受到相似性攻击(similarity attack)。
数据匿名化技术不是万能的,在Schneier Bruce的《为什么“匿名”数据有时没有匿名》一文中提到,在大数据前提下,统计学理论的支撑下,通过多属性关联分析,依然可以分析出被匿名化的信息。但这不是说匿名化技术不需要研究或者放弃使用匿名化,而是要有针对性地进行合适合理有效的匿名化技术。可以有针对性的对数据进行横向或者纵向分割,减少数据量或者属性的共享,减少攻击者进行反匿名化需要的信息。
(作者单位为上海海事大学)
