CAT模拟结果的分析模式与评价指标
2016-06-05简小珠戴步云
简小珠 戴步云 陈 平
CAT模拟结果的分析模式与评价指标
简小珠 戴步云 陈 平
计算机化自适应测验(CAT)模拟是CAT研究的主要方法之一。CAT模拟结果的评价分析内容主要包括三个方面:被试能力估计与被试能力分类分析、题库试题使用情况分析和CAT测验作答过程分析。CAT模拟结果的分析模式主要分为整体分析和细化分析两种模式。本研究从测验模拟返真性能、测验准确性、题库安全性、题库使用率、测验分类效率与准确性、多测验目标约束控制的实现程度等角度概述CAT模拟结果的各类评价指标。CAT模拟结果的评价角度和评价指标需要根据CAT研究目标和测验情境要求加以确定。
CAT;CAT模拟;分析模式;评价指标
1 CAT模拟结果的分析模式
计算机化自适应测验(Computerized Adaptive Testing,CAT)模拟是CAT测验技术研究的主要手段。从分析内容角度来看,CAT测验技术研究主要从三个方面对CAT模拟结果进行分析:一是被试能力估计和被试能力分类情况;二是题库中试题使用情况,包括试题曝光率情况、题库使用率和试题内容平衡等;三是CAT作答过程,包括在CAT作答过程中被试能力估计值变化情况、试题曝光率情况等。从分析模式角度来看,CAT模拟结果的分析大致可以分为两种模式:一种为整体分析模式,对所有被试在测验上的模拟结果进行整体评价分析;另一种为细化分析模式,即依据CAT分析内容的三个角度,或者从被试能力量尺的各个水平上对被试能力水平进行细化分析,或者从试题难度量尺水平上对题库试题利用情况、曝光情况进行细化分析,或者对CAT的每一步作答过程进行细化分析。
1.1 从被试能力水平方面分析CAT模拟结果
对被试能力进行准确估计和正确分类是CAT测验过程中的最主要目标,因而几乎所有CAT研究都包含对被试能力估计结果的分析。被试能力估计结果的分析模式可以分为三种:整体分析模式、细化分析模式和介于二者之间的分段分析模式。
(1)整体分析模式。使用整体分析模式时,被试群体能力往往设计为服从正态分布或均匀分布。在每一种测验情境下,在每一评价指标上,所有被试的CAT模拟结果只使用一个数据来评价。大部分CAT研究都是使用这种整体分析模式。但是,这种分析模式只能反映被试整体的模拟返真情况,而不能反映处于不同能力水平的被试在模拟测验结果上的差异情况。例如,Chang和Ying在比较α分层与其他选题策略时,使用整体分析模式对每种测验情境下被试能力估计的MSE和Bias指标进行计算分析[1]。再如,Revuelta和Ponsoda在比较试题曝光率控制方法时,使用整体分析模式分析被试能力模拟返真性能[2]。
(2)细化分析模式。此种分析模式是在能力量尺上抽取各个对应不同能力被试群体的代表性能力点进行模拟结果分析。很多研究采用代表性能力真值进行CAT模拟分析。例如,Bock和Mislevy选取了从-2.8至+2.8之间各个能力水平的被试,分析期望后验能力估计方法(EAP)在CAT能力估计中的应用特性[3]。Sympson和Hetter模拟了能力被平均分配在7个水平点(-3、-2、-1、0、1、2和3)上的7 000名被试,以分析被试能力估计情况和试题曝光率情况[4]。Chang和Ansley选取了固定在-3.2至+3.2之间的17个能力点,以估算各水平段被试的能力的条件标准误[5]。陈平和丁树良在-3.2至+3.2之间选取17个代表性能力点,每个点模拟100名被试[6]。Magis以0.5为间隔距离在-3至+3之间选取了13个代表性能力点[7]。
(3)分段分析模式。此模式介于前两种模式之间,对CAT模拟结果按能力水平进行分段计算分析,要求被试群体的能力服从正态分布或均匀分布。例如Rulison和Loken计算了全体被试、前10%的高能力被试和最末10%低能力被试的Bias、RMES等[8]。Lin在分析被试群体的整体被试分类准确性时,还单独对能力初始值大于-1的被试群体进行分析[9]。
1.2 从题库的试题使用情况方面分析CAT模拟结果
题库试题使用情况主要指试题曝光率和题库使用率。题库试题使用情况的分析模式主要有两种。一种是整体分析模式,即对题库中所有试题的曝光率等指标进行评价分析,例如Chang和Ying提出α分层选题策略,在各种测验情境下对题库中所有试题的使用情况(包括分析测验重叠率、卡方统计量、曝光率低于0.2的试题数量等评价指标)进行分析评价[1]。由于整体模式使用评价指标值来评价题库整体使用情况,往往较为笼统,难以细化整个题库的试题使用情况。一些研究者便采取另外一种题库分析模式——细化分析模式。细化分析模式又分为两种情况。
第一种情况是以题库容量为横坐标分析题库使用情况。Chang和Ying以题库试题序号为横坐标(试题按区分度由小到大进行排序)、以试题曝光率为纵坐标描绘整个题库的试题曝光率情况,较为全面详尽地比较了α分层选题策略和其他几种选题策略对试题曝光率的影响[1]。Leung,Chang和Hau在分析采用α分层与最大题目信息量相结合的选题策略对试题曝光率的影响时,也采用类似的方法[10]。van der Linden和Veldkamp在对几种传统的试题曝光率控制方法与项目合格法进行比较时,以题库容量作为横坐标的最大坐标,按照每一道试题曝光率由大到小依次排序形成线图,较好地展示了试题曝光率的整体情况以及各个试题曝光率控制方法的对比情况[11]。
第二种情况是一些研究者对试题使用情况进行分段统计,并运用表格或图形来更清晰地反映试题使用的细节。例如,Revuelta和Ponsoda使用表格统计曝光率水平分别为0、1%~10%、11%~20%直至91%~99%和100%的试题的数量,从而反映题库在不同曝光率水平上试题使用的整体情况[12]。Thompson以题库中的试题使用频数作为分段标准,使用表格分段的方式来统计分析在各个分段内的试题数量[13]。Han在研究中也使用类似表格形式来分析题库整体曝光率情况[14]。同时,Han以试题序号为横坐标,以试题曝光率为纵坐标,使用图形描绘整个题库中试题曝光率的散点图[14]。
1.3 从CAT测验过程的角度来分析CAT模拟结果
大多数CAT研究往往只分析评价CAT模拟测验结束时的被试能力估计、题库试题选择使用情况以及被试作答信息,而没有关注CAT测验过程中每一步作答的测验信息及其变化情况。一部分研究者为了进一步探讨CAT测验过程中对试题曝光率和测验交叠率的控制情况,分析被试能力和试题选择的参数变化等情况,对CAT测验过程中的每一步选题、能力估计等测验信息均进行记录,从而实现对CAT测验过程中的各项测量指标的分析评估以及对试题曝光率和区分度的控制。对CAT测验过程进行分析评价的代表性研究有:(1)Cheng和Liou依据测验开始至第30题被试估计值的Bias变化情况,分析比较了几种选题策略对被试能力估计准确性的影响[15]。(2)Barrada,Veldkamp和Olea在CAT测验过程中的每一步都设置当前位置的最大曝光率水平和累计最大曝光率水平,提出多重曝光率的控制方法。他们以最大曝光率为纵坐标,以CAT测验过程(从第1题到第25题)为横坐标,绘制了CAT测验过程中题库试题曝光率的变化趋势[16]。(3)Gnambs和Batinic计算了CAT测验过程每一步骤的被试能力分类情况信息,包括被试分类准确性的数量和百分比,并由模拟结果的比较分析得出,删节的序列概率比检验终止策略(SCSPRT)要优于序列概率比检验(SPRT)终止策略[17]。(4)简小珠计算被试在CAT测验过程中每一步的能力估计值,据此计算多次模拟测验的能力估计值的平均值,并以能力估计值为纵坐标,以测验长度为横坐标,较好地描绘了CAT测验过程中被试能力估计值的变化趋势[18]。(5)Olea等分析第5题至第40题的CAT测验过程中,根据选题策略所选择试题的参数变化情况,发现所选择的试题a参数估计值和初始值的平均值都是随着CAT测验进程逐渐变小,所选择的b参数估计值和初始值之间的差异均值随着CAT测验进程也逐渐变小[19]。
此外,CAT过程分析也有一种分阶段分析的模式,即在CAT测验过程中分两个阶段进行分析。Cheng、Chang和Yi在比较4种内容模块的选题策略时,提出在第一阶段采用指定内容选择的选题方法,在第二阶段则从指定内容选择和非指定内容选择(又称内容弹性选择)两种选题方法中任选其一。结果表明,两阶段均采用内容弹性选择的选题策略能够实现较好的题库曝光率控制和题库使用率[20]。Cheng、Chang和Douglas等在探讨分析约束加权控制的α分层策略时,使用的也是分段分析模式[21]。目前这种分阶段研究相对很少,但对于那些需要实现多测验目标约束控制的测验来说,在CAT测验过程中进行分阶段的控制分析是较为理想的一种模式。
2 CAT模拟结果的评价指标
根据CAT测验情境要求,研究者已经从多个角度提出对CAT模拟结果进行评价的指标。基于不同的研究目的,往往需要使用不同的评价角度和评价指标。本文归纳主要有6个评价角度:侧重评价测验模拟返真性能,侧重分析测验的测量准确性,侧重评价分析题库安全性,反映分析题库的利用率,评价分析测验分类效率、分类准确性,综合评价测验多目标约束控制的实现程度。在这6个评价角度下又分别有多个评价指标,以下分别论述。
2.1 评价模拟返真性能方面的指标
反映测验题目参数或被试能力参数的模拟返真性能指标有:均方根误差RMSE(或均方误差MSE)、偏差Bias、平均绝对值误差ABS、能力真值与能力估计值的皮尔逊积差相关系数以及标准误等。
(1)均方根误差(RMSE),是各个测量值离均差的平方和均值的平方根。它是对一组测量数据可靠性的估计。均方根误差小,测量的可靠性大一些,反之,测量就不大可靠。计算公式为其中,N为被试(或测验试题)总数,M为模拟次数,xjk是第j个参数(此参数可以是题目参数,也可以是被试能力参数)在第k次模拟时的估计值,x0j是第j个参数的模拟初始值或模拟真值,以下公式中的符号含义与此相同。RMSE是CAT模拟研究中最常用的指标,也是其他教育与心理测量模拟研究中最常用的指标。
当然在有些研究中使用均方误差(MSE),MSE是均方根误差的平方。Chang和van der Linden进一步提出条件Bias和条件MSE或RMSE,条件Bias和条件MSE是指针对某一被试或某一单独被试群体而计算的Bias和RMSE,条件Bias和条件MSE与Bias和MSE对CAT模拟返真性能评价意义是一样的[22]。简小珠对在-3至+3区间19个代表性被试分别计算每个被试的Bias和RMSE[18]。Rulison和Loken计算成绩前10%的群体和成绩最后10%群体的Bias和RMSE[8]。
(2)绝对值平均偏差(ABS)是数据估计值与模拟真值的绝对平均偏差,反映估计值与真值的绝 对 距 离 的大 小 ,计 算 公式 为 ABSE=
(3)偏差(Bias)是参数估计值与模拟真值平均偏差程度的反映,表示测量估计值距离模拟真值的偏离的程度,可反映估计值是否存在整体偏差。计算公式为如果需要反映参数估计值的偏离方向是正向还是负向,就可以选择Bias。例如,依据Rulison和Loken的研究,在三参数模型下,高能力被试答错前两题后,使用Bias指标分析模拟初始值和被试估计值,可以反映被试能力被低估的程度[8]。
(4)皮尔逊积差相关系数,即求取题目参数或能力参数真值与估计值的皮尔逊积差相关系数ρ。由以往的研究结果发现,皮尔逊积差相关系数ρ往往对真值与估计值相关性不灵敏,数值往往都在0.90以上,有些甚至为0.99或接近1,而且在不同的测验情境下皮尔逊积差相关系数ρ的变化都很小[22-23]。
RMSE、ABSE与SE这些指标值越小,或Bias的绝对值越接近于零,或皮尔逊积差相关系数 ρ越大,说明测验模拟结果越准确。此5项指标中,RMSE和Bias最为常用。
2.2 评价测验测量精度方面的指标
反映CAT模拟测验的测量精度的指标有覆盖百分率、测验信息量(测量误差)和平均试题信息量。指标值越大,说明模拟测验的测量结果越准确。
(1)覆盖百分率(percentage coverage of 95% confidence intervals,PCC)是指根据模拟测验的参数估计值和测验标准误,计算第j个参数在第k次测验模拟时的参数估计值xjk的95%置信区间,观测第j个参数的模拟真值在第k次模拟时是否落入这个置信区间。如果落入此区间则αjk=1,否者αjk=0,则由N个被试(试题)M次模拟得到的能力估计值落入置信区间的次数,再除以N×M,即可得到覆盖百分率。计算公式为也就是说,覆盖百分率可以反映能力参数初始值能否落入试题参数、能力参数估计值的置信区间的次数百分比,也是测验参数估计稳定性的指标。如Rulison和Loken使用覆盖百分率衡量被试能力估计的测量精度[8]。
(2)测验信息量(test information)。测验信息量反映的是CAT测验对估计被试能力所提供的信息多少,也是测量误差大小的反映。Kingsbury和Zara在增加内容模块设计的CAT研究中,计算了被试在CAT过程中每一步的测验信息量[28]。
(3)测验试题的平均信息量,即计算CAT测验中所有被试在测验过程中的所有试题的测验信息量的平均值,反映了测验效率(与测验长度有关),也侧面反映了测验测量误差,其计算公式为以及程小扬等在分析CAT结果时都使用了试题平均信息量指标来反映被试能力的测量精度[29-31]。Revuelta和Ponsoda在比较几种试题曝光率的研究中,使用图形方式呈现了CAT测验过程中试题平均信息量的变化趋势[2]。
2.3 评价测验安全控制方面的指标
评价测验安全和试题曝光率控制方面的指标包括观察到的试题最大曝光率、测验重叠率、试题使用频数的卡方统计量χ2以及过度曝光试题的数量。其中,最大曝光率观测值、测验重叠率以及卡方统计量这三项指标使用较多。
最大曝光率观测值(observed maximum exposure rates)。题目曝光率是指某一试题被调用的次数与参加测验总人数之比。观察题库中试题的最大曝光率以及所有题目的曝光率是否都控制在某一预设值rmax之下,是评价测验安全性的一个标准要求,是所有CAT曝光率控制研究中都需要考虑的指标。
测验重叠率(test overlap rate)。测验重叠率是指任意两个被试间作答相同题目的比例,也是衡量测验安全性的一个重要指标,Chen、Ankenmann和Spray推导了测验重叠率与题目曝光率(item exposure rate)之间的关系[32]:
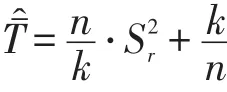
卡方统计量(χ2statistic)。Chang和Ying提出χ2统计量用于反映曝光率分布的观测值与理想值之间的差距,认为题库中题目曝光率的一致分布也是比较测验安全控制方法的一个指标[1]。若题库容量为N,测验长度为L,则题库中题目曝光率的最一致的分布为,所以 χ2统计量的公式表示为其中erj是题目j的曝光率。χ2统计量越小,说明题库的使用越均匀,题库中所有试题的曝光率就相对较小。如果某种选题方法得到的χ2值较低,则说明题库中绝大多数的题目都得到充分利用。在比较不同的选题策略的曝光率结果时,可以比较它们的χ2。对两种不同选题方法得到的χ2求F值,表示为:F方法1,方法2=χ2方法1/χ2方法2。如果F方法1,方法2<1,那么可以认为方法1在题目曝光率的平衡方面要好于方法2。
试题曝光率在CAT测验过程中的分布均匀性。Barrada、Olea、Ponsoda和Abad以及Barrada、Veldkamp和Olea都提出在CAT测验过程的各个位置上设置最大试题曝光率阈限值,并分析题库试题在CAT测验从开始到结束时各个测试位置上的试题曝光率分布[16,33]。Barrada、Veldkamp和Veldkamp以及Olea提出的多重曝光率控制方法有助于使得整个题库试题曝光率均匀化。
过度曝光的试题数量(number of overexposed items)。当某一试题实际曝光率超过曝光率限制值0.25(0.2或0.3),那么该试题就被认为是过度曝光了。题库中过度曝光的试题量越多,则题库安全性就越差[34]。
2.4 评价题库使用方面的指标
反映题库使用情况的指标包括题库使用率、题目使用均匀性、从未调用试题的数量或者曝光率低于0.02的试题量、高使用率试题的比例与低使用率试题的比例。
题库使用率(utilization rate of item bank)是使用最多的评价指标。题库使用率是指在题库中被调用试题所占全库容量的比例(试题使用的数量与题库容量之比)。Chang、Qian和Ying认为在不降低测验效率的前提下,题库中的中、低区分度试题的使用情况是题库使用率的衡量标准[35]。
题目使用均匀性,即计算题库中所有题目调用次数的标准差,该指标也间接反映了题库使用率。题目调用次数的标准差越小,则说明试题使用越均匀,也间接说明题库使用率较高。程小扬和丁树良使用该指标分析题库试题利用率的均匀性[36]。
从未调用试题的数量或者曝光率低于0.02的试题数量,反映题库中试题未被使用的情况。Lin在比较计算机化分类测验中的选题策略时,使用从未调用试题的数量这一指标[9]。Chang和Ying使用曝光率低于0.02的试题数量这一指标比较多种选题策略,发现使用α分层选题策略时曝光率低于0.02的试题数量最少[1]。
高使用率试题的比例与低使用率试题的比例。高使用率试题的比例是指被超过20%的被试用于测试的试题数量占整个题库试题量的比例。低使用率试题的比例是指被少于2%的被试用于测试的试题数量占整个题库试题量的比例。Huebner和Li在研究中使用了高使用率试题的比例与低使用率试题的比例这两个指标[37]。曝光率低于0.02的试题数量这一指标仅仅是反映题库使用的绝对数量;而低使用率试题的比例这一指标反映了题库使用的相对程度,因而要优于曝光率低于0.02的试题数量这一指标。
此外,题库中的中等和低等区分度的题目使用情况也用来作为评价选题策略的重要标准之一。Hau和Chang发现在不降低测验效率的前提下,如果中等和低等区分度的题目被充分利用,则说明这种选题策略的效果较好,较容易避免高区分度题目过分曝光导致的测验安全问题和测验题目的维护与补充带来的高成本问题[34]。
2.5 评价被试分类效率和分类准确性方面的指标
在计算机化分类测验(或掌握性自适应测验)中需要评价测验对被试的分类情况,可以从两个方面进行评价:一是被试分类效率的评价指标,包括平均测验长度和人均用题量。Lin在计算机化分类测验中使用了平均测验长度指标[9]。陈平等在选题策略分析比较时使用了人均用题量指标[38]。 二是被试分类准确性的评价指标,包括被试正确分类的百分比(percentage of correct decision)和被试强制分类的百分率(forced classi fi cation rates)。Lin在计算机化分类测验中提出并使用被试正确分类的百分比这一评价指标,用于比较各种选题策略方法的优劣[9]。Wang和Huang在基于能力的猜测模型下,在计算机化分类测验研究中提出并使用被试强制分类的百分率这一指标[39]。
2.6 评价多测验目标约束控制有效性方面的指标
在多测验目标约束控制的CAT模拟研究中,要求CAT模拟设计要同时达到多个测验目标,此时需要三种评价指标:一是He,Diao和Hauser使用的达到约束条件要求的测验百分比这一指标[40];二是Cheng和Chang在比较分析最大优先指标与其他选题策略时提出并使用的约束条件违背的平均测验数量这一指标[41];三是潘奕娆、丁树良和尚志勇、汤楠和丁树良以及汤楠、丁树良和余丹等在CAT选题策略研究中提出的被试平均违规次数这一指标[42-44]。其中,达到约束条件要求的测验百分比是相对指标,更能在整个测验情境中比较各种选题策略的优劣;而约束条件违背的平均测验数量、被试平均违规次数是绝对指标,只能局部地横向比较各个选题策略。
2.7 其他评价指标
评价CAT的模拟结果还有一些其他指标,包括正确作答的题量、选题的耗时时长等。例如Chang和Ying使用正确作答的平均题量来分析CAT初始值位置对被试能力估计的影响[45]。在一些选题策略方法的研究中,需要考虑选题过程的耗时问题,因为CAT往往需要即时为被试选择和呈现下一道试题,以进行下一步作答。例如,van der Linden报告了CAT选题时每选择一道试题的平均耗时[46]。Passos、Berger和Tan的研究也报告了选题策略的选题时间情况[47]。
研究者还提出统一量纲方法,将各个评价指标综合计算成一个指标,以作为选题策略的综合评价指标[30,48]。但统一量纲方法容易受到权重系数、评价指标的实际数值的影响,需要研究者慎重确定权重系数的大小。
2.8 各个评价角度之间关系的分析
以上概括了CAT模拟结果的6个评价角度与评价指标。在不同研究中,一些评价指标会有不同的变式,或者不同研究者对某个评价指标会使用不同的名称,但本质上是同一个指标。
6个评价角度的基本关系可以概况如下:(1)测量准确性(包括模拟返真性能指标、测验精度指标、被试分类准确性)与测验安全性、题库使用、多测验目标约束控制等其他评价角度的指标存在着此消彼长的反向关系。如果CAT测验过程中选择测量准确性较高的选题策略和试题曝光率控制方法,那么题库使用率将下降,测验安全性下降,多测验目标约束控制的实现程度将下降;反之,如果要提高测验安全性、题库使用率和多测验目标约束控制的实现程度,则需要选择测量准确性较低的选题策略和试题曝光率控制方法;(2)题库使用情况与测验安全这两个角度的指标评价性能是基本一致的:如果题库使用情况较为全面且均匀,那么测验安全性就相对较高;如果题库使用情况较为不均匀,那么部分试题曝光率就相对过高,测验安全性就相对较低。
如何选择合适的评价角度与评价指标呢?余嘉元和汪存友提出,需要根据CAT具体测验情境以及评价指标的敏感性来选择适当的CAT评价指标[49]。 笔者根据以往研究概括为以下几点:(1)如果CAT测验是选拔性、高利害关系的入学考试、职业资格考试等,就需要提高测验安全控制方面的要求,需要选择测验安全性能评价指标值较好的试题曝光率控制方法;(2)如果是低利害关系的练习性、诊断性的CAT测验,则不需要考虑测验安全性这方面的性能要求,主要侧重于被试能力估计的准确性;(3)被试分类效率与分类准确性方面的评价指标主要用于计算机化分类测验中评价被试分类情况;(4)多测验目标约束控制指标(如达到约束条件要求的测验百分比、被试平均违规次数等)主要是在需要多个测验条件约束控制的CAT测验中使用。
2.9 测验准确性与测验安全性两个评价角度的综合评价
具有较高的测验准确性以及题库试题被充分有效使用是所有CAT研究的测验目标或评价要求。然而,许多研究表明,CAT研究结果在测验准确性与测验安全性上往往出现此消彼长的现象。有些选题策略(或终止策略)测量准确性较高,但试题曝光率也高(即测验安全性低),如最大Fisher信息量方法;有些选题策略试题曝光率较低(即测验安全性较高),而测量精度也较低,如α分层法。在测量准确性与测验安全性之间,如何比较与选择较好的选题策略?Barrada、Olea、Ponsoda和Abad提出一种综合比较的新方式,以控制最大试题曝光率为自变量,分析其对测验的精度(以RMSE为指标)和安全性(以测验交叠率Overlap为指标)的影响,并以图形方式呈现测验准确性与测验安全性之间的相对变化关系[50-51]。Barrada等比较了最大Fisher信息量(PFI)、似然函数加权Fisher信息量(FI-L)、似然函数KL信息函数法(KL-L)、最大项目信息量分层法(MIS-B)、过程法(progressive method,PG)和概率法(proportional method,PP)6种选题策略。结果显示,在测验安全性方面,6种选题策略的重叠率依次升高的顺序(测验安全性下降)是MIS-B、PP、PG、PFI、FI-L和KL-L;在测验精度方面,依次增大的顺序恰好相反。RMSE与Overlap的反函数关系图可以为CAT选题策略的选择提供较好的参考依据,例如:当需要最大化的测验精度,而可以容忍相对较低的测验安全性时,可以选择使用KL-L、FI-L、PFI及其选题策略方法;如果需要尽可能高的测验安全性,同时又只能允许测验精度下降一点时,可以选择使用PP选题策略方法;如果要追求测验安全性的最大化时,可以根据测验的长度和题库的大小,使用MIS-B方法。
3 小结
CAT测量技术研究是近年来心理与教育测量的热点领域之一,在教育入学考试、职业资格认证、认知诊断等领域有较广泛的应用。本研究概述了CAT研究评价可以分为被试能力估计、题库试题使用情况、CAT测验过程三方面内容,并且都有整体分析、细化分析两种分析模式。CAT模拟结果的评价分析角度包括被试能力模拟返真性能、测验测量准确性、测验安全性、题库使用率、被试分类有效性与分类准确性、多测验目标约束控制的有效性6个角度,每个角度又包含多个评价指标。对CAT模拟结果分析模式与评价指标的概括与总结可为今后CAT模拟研究的设计与评价提供参考依据。
[1]CHANG H,YING Z.α-Stratified multistage computerized adaptive testing[J].Applied Psychological Measurement,1999,23(3):211-222.
[2]REVUELTA J,PONSODA V.A comparison of item exposure control methods in computerized adaptive testing[J].Journal of Educational Measurement,1998,35(4):311-327.
[3]BOCK R J,MISLEVY R D.Adaptive EAP estimation of ability in a microcomputer environment[J].Applied Psychological Measurement,1982,6(4):431-444.
[4]SYMPSON J B,HETTER R D.Controlling item exposure rates in computerized adaptive testing[C]//Proceedings of the 27th annual meeting of the Military Testing Association.San Diego,CA:Navy Personnel Research and Development,1985.
[5]CHANG S W,ANSLEY T N.A comparative study of item exposure control methods in computerized adaptive testing[J].Journal of Educational Measurement,2003,40(1):71-103.
[6]陈平,丁树良.允许检查并修改答案的计算机化自适应测验[J].心理学报,2008,40(6):737-747.
[7]MAGIS D.Efficient standard error formulas of ability estimators with dichotomous item response models[J].Psychometrika,2015,81(1): 184-200.
[8]RULISON K,LOKEN E.I’ve fallen and I can’t get up:can highability students recover from early mistakes in CAT?[J].Applied Psychological Measurement,2009,33(2):83-101.
[9]LIN C.Item selection criteria with practical constraints for computerized classification testing[J].Educational and Psychological Measurement,2011,71(1):20-36.
[10]LEUNG C,CHANG H,HAU K.Computerized adaptive testing:A mixture item selection approach for constrained situations[J].British Journal of Mathematical and Statistical Psychology,2005,58(2):239-257.
[11]VAN DER LINDEN W J,VELDKAMP B P.Conditional item-exposure control in adaptive testing using item-ineligibility probabilities [J].Journal of Educational and Behavioral Statistics,2007,32(4): 398-418.
[12]REVUELTA J,PONSODA V.A comparison of item exposure control methods in computerized adaptive testing[J].Journal of Educational Measurement,1998,35(4):311-327.
[13]THOMPSON N A.Item selection in computerized classification testing[J].Educational and Psychological Measurement,2011,71(1):114-128.
[14]HAN K T.A gradual maximum information ratio approach to item selection in computerized adaptive testing//Weiss D J.Proceedings of the 2009 GMAC Conference on Computerized Adaptive Testing, 2009.[2016-08-01].www.psych.umn.edu/psylabs/CATCentral/.
[15]CHENG P E,LIOU M.Estimation of Trait Level in Computerized Adaptive Testing[J].Applied Psychological Measurement,2000,24(3):257-265.
[16]BARRADA J R,VELDKAMP B P,OLEA J.Multiple maximum exposure rates in Computerized Adaptive Testing[J].Applied Psychological Measurement,2009,33(1):58-73.
[17]GNAMBS T,BATINIC B.Polytomous adaptive classification testing:effects of item pool size,test termination criterion,and number of cutscores[J].Educational and Psychological Measurement,2011, 71(6):1006-1022.
[18]简小珠.IRT模型中c、γ参数对被试能力高估和低估现象的纠正[D].广州:华南师范大学,2011.
[19]OLEA J,BARRADA J R,ABAD F J,et al.Computerized adaptive testing:the capitalization on chance problem[J].Spanish Jouranl of Psychology,2012,15(1):424-441.
[20]CHENG Y,CHANG H,YI Q.Two-Phase Item Selection Procedure for Flexible Content Balancing in CAT[J].Applied Psychological Measurement,2007,31(6):467-482.
[21]CHENG Y,CHANG H H,DOUGLAS J,et al.Constraint-weighted α-stratification for computerized adaptive testing with nonstatistical constraints:Balancing measurement efficiency and exposure control[J].Educational and Psychological Measurement,2009,69(1):35-49.
[22]CHANG H,VAN DER LINDEN W J.Optimal Stratification of Item Pools in α-Stratified Computerized Adaptive Testing[J].Applied Psychological Measurement,2003,27(4):262-274.
[23]HE W,RECKASE M D.Item pool design for an operational variable-length computerized adaptive test[J].Educational and Psychological Measurement,2014,74(3):473-494.
[24]WANG T,VISPOEL W P.Properties of ability estimation methods in computerized adaptive testing[J].Journal of Educational Measurement,1998,35(2):109-135.
[25]SCHUSTER C,YUAN K.Robust estimation of latent ability in item response models[J].Journal of Educational and Behavioral Statistics,2011,36(6):720-735.
[26]RAîCHE G,BLAIS J G,MAGIS D,et al.Adaptive estimators of trait level in adaptive testing:Some proposals[Z].Graduate Management Admission Council Conference on Computerized Adaptive Testing(GMAC),2007.
[27]CHEN S,ANKENMANN R D,CHANG H.A Comparison of Item Selection Rules at the Early Stages of Computerized Adaptive Testing[J].Applied Psychological Measurement,2000,24(3):241-255.
[28]KINGSBURY C G,ZARA A R.A Comparison of Procedures for Content-Sensitive Item Selection in Computerized Adaptive Tests [J].Applied Measurement in Education,1991,4(3):241-261.
[29]ZHANG J.The Impact of Variability of Item Parameter Estimators on Test Information Function[J].Journal of Educational and Behavioral Statistics,2012,37(6):737-757.
[30]程小扬,丁树良,严深海,等.引入曝光因子的计算机化自适应测验选题策略[J].心理学报,2011(43):203-212.
[31]程小扬,丁树良,巫华芳,等.多级评分模型下的题库结构对CAT的影响分析[J].心理学探新,2014(34):452-456.
[32]CHEN S,ANKENMANN R D,SPRAY J A.The Relationship between Item Exposure and Test Overlap in Computerized Adaptive Testing[J].Journal of Educational Measurement,2003,40(2):129-145.
[33]BARRADA J R,OLEA J,PONSODA V,et al.Test Overlap Rate and Item Exposure Rate as Indicators of Test Security in CATs[C]// Weiss D J.Proceedings of the 2009 GMAC Conference on Computerized Adaptive Testing,2009.[2016-08-01].www.psych.umn. edu/psylabs/CATCentral/.
[34]HAU K,CHANG H.Item selection in computerized adaptive testing:should more discriminating items be used first?[J].Journal of Educational Measurement,2001,38(3):249-266.
[35]CHANG H,QIAN J,YING Z.α-Stratified multistage computerized adaptive testing with b blocking[J].Applied Psychological Measurement,2001,25(4):333-341.
[36]程小扬,丁树良.子题库题量不平衡的按α分层选题策略[J].江西师范大学学报(自然科学版),2011,35(1):5-9.
[37]HUEBNER A,LI Z.A stochastic method for balancing item exposure rates in computerized classification tests[J].Applied Psychological Measurement,2012,36(3):181-188.
[38]陈平,丁树良,林海菁,等.等级反应模型下计算机化自适应测验选题策略[J].心理学报,2006,38(3):461-467.
[39]WANG W,HUANG S.Response model with ability-based guessing computerized classification testing under the one-parameter logistic[J].Educational and Psychological Measurement,2011,71(6):925-941.
[40]HE W,DIAO Q,HAUSER C.A Comparison of Four Item-Selection Methods for Severely Constrained CATs[J].Online Submission,2014,74(4):27.
[41]CHENG Y,CHANG H.The maximum priority index method for severely constrained item selection in computerized adaptive testing[J]. British Journal of Mathematical and Statistical Psychology,2009,62(2):369-383.
[42]潘奕娆,丁树良,尚志勇.改进的最大优先级指标方法[J].江西师范大学学报(自然科学版),2011,35(2):213-215.
[43]汤楠,丁树良.一阶段选题的最大优先级指标的修正[J].江西师范大学学报(自然科学版),2012,36(5):452-455.
[44]汤楠,丁树良,余丹.结合优先级指标和曝光因子的多级评分选题策略[J].江西师范大学学报(自然科学版),2011,35(6):646-650.
[45]CHANG H H,YING Z.To weight or not to weight?Balancing influence of initial items in adaptive testing[J].Psychometrika,2008,73(3):441-450.
[46]VAN DER LINDEN W J.Bayesian item selection criteria for adaptive testing[J].Psychometrika,1998,63(2):201-216.
[47]PASSOS V L,BERGER M P F,TAN F E S.The D-optimality item selection criterion in the early stage of cat:a study with the Graded Response Model[J].Journal of Educational and Behavioral Statistics,2008,33(1):88-110.
[48]戴海琦,陈德枝,丁树良,等.多级评分题计算机自适应测验选题策略比较[J].心理学报,2006,38(5):778-783.
[49]余嘉元,汪存友.项目反应理论参数估计研究中的蒙特卡罗方法[J].南京师大学报(社会科学版),2007(1):87-91.
[50]BARRADA J R,OLEA J,PONSODA V,et al.Incorporating randomness in the Fisher information for improving item-exposure control in CATs[J].British Journal of Mathematical and Statistical Psychology,2008,61(2):493-513.
[51]BARRADA J R,OLEA J,PONSODA V,et al.A Method for the Comparison of Item Selection Rules in Computerized Adaptive Testing[J].Applied Psychological Measurement,2010,34(6):438-452.
Analysis Models and Evaluation Indexes of Computerized Adaptive Testing Simulation Results
JIAN Xiaozhu,DAI Buyun&CHEN Ping
Computerized Adaptive Testing(CAT)simulation is one of the main methods of CAT research. Evaluation and analysis of CAT simulation results mainly includes three aspects:estimation and classification analysis of examinee ability,analysis of the utilization of the test items from the item bank and analysis of the CAT response process.Analysis of CAT simulation results mainly involves a holistic approach and a fine-grained approach.This study provides an overview of the various evaluation indexes involved in evaluating CAT simulation results from the perspectives of simulation recovery,measurement accuracy,item security,item utilization rates, examinee classification efficiency and accuracy,and control of multiple test objectives.The perspectives and evaluation indexes required for a CAT simulation study have yet to depend on the purpose and context of that study.
Computerized Adaptive Testing;CAT Simulation;Analysis Model;Evaluation Index
G405
A
1005-8427(2016)12-0019-10
(责任编辑:陈宁)
本文系江西省高校人文社会科学研究青年项目“计算机化自适应测验(CAT)测量技术与评价分析”(项目编号:XL1515)的研究成果之一。
简小珠,男,井冈山大学教师教育中心,副教授,江西师范大学心理学院,江西省心理与认知科学重点实验室,博士后(江西吉安 343009)
戴步云,男,江西师范大学心理学院,江西省心理与认知科学重点实验室,博士后(南昌 330022)
陈平(通讯作者),男,北京师范大学中国基础教育质量监测协同创新中心,副教授(北京 100875)
