基于深度学习的监控视频树叶遮挡检测
2016-06-04邬美银
邬美银,陈 黎
(1.武汉科技大学计算机科学与技术学院,湖北 武汉,430065;2. 武汉科技大学智能信息处理与实时工业系统湖北省重点实验室,湖北 武汉,430065)
基于深度学习的监控视频树叶遮挡检测
邬美银,陈黎
(1.武汉科技大学计算机科学与技术学院,湖北 武汉,430065;2. 武汉科技大学智能信息处理与实时工业系统湖北省重点实验室,湖北 武汉,430065)
摘要:结合稀疏自编码器的自动提取数据特征能力和深度置信网络较好的分类性能,提出一种基于深度学习的监控视频树叶遮挡检测方法。首先从视频中随机选取一帧图像,通过栈式稀疏自编码器主动学习视频图像的特征信息,然后采用深度置信网络建立分类检测模型,最后引入学习速率自适应调整策略对整个神经网络进行微调。该方法不需要对视频连续取帧,具有较好的图像特征主动学习能力,克服了人工提取特征能力有限的缺陷。实验结果表明,在样本量充足的条件下,使用本文方法进行监控视频树叶遮挡检测可以达到88.97%的准确率。
关键词:监控视频;遮挡检测;图像识别;稀疏自编码器;深度置信网络;深度学习;特征提取
随着现代科学技术的迅猛发展,视频监控系统已经得到广泛应用。面对视频源数量的日益剧增以及对监控视频分析越来越高的要求,传统的人工监控很难保证对视频画面分析的实时性,存在报警准确度差、误报、漏报、报警响应时间长、视频数据分析困难等问题[1]。因此,引入计算机视觉研究领域中的相关技术发展智能视频监控系统已经迫在眉睫。
安防监控系统中,镜头遮挡检测是最重要也是最常见的检测之一。摄像机的镜头可能由于多种因素被遮挡,比如污渍、树叶等。其中,树叶遮挡主要是由于树木随时间和季节的变化自然生长,而监控点摄像头位置不变,使得原本没有被遮挡的摄像头在特定季节或安装一段时间后被树叶遮挡。视频遮挡会导致监控场景的缺失,给公共安全带来严重影响,特别是在一些关键的监控点,可能会造成巨大的损失和不可挽回的后果。因此,研究监控视频树叶遮挡检测具有重要的意义。
目前,大多数关于监控视频遮挡检测的研究都是针对人为遮挡,即人为用异物遮挡监控摄像头。Ribnick等[2]提出利用当前帧与前一帧之间颜色直方图的差异来检测人为遮挡。Lin等[3]使用DSP框架对比帧间灰度直方图实现遮挡检测。王宝君等[4]加入角点特征,使摄像头干扰检测算法对光线强度变化不敏感,鲁棒性更强。Saglam等[5]提出一种自适应阈值的背景差分方法来检测人为遮挡。Yin等[6]提出利用尺度不变特征进行人为遮挡检测。以上这些算法大体上都是考虑监控场景在短期内由于人为遮挡会发生剧烈变化,从而通过对比帧间某些特征来实现遮挡检测。但是,树叶遮挡是因渐变的植物生长过程而引发,不会存在场景短期剧变现象。所以,上述算法都不适用于进行监控视频树叶遮挡检测。对于树叶遮挡问题,袁渊等[7]采用累积帧差法分割视频中疑似树叶区域,提取视频中某一帧图像的整个区域和疑似树叶区域的颜色和面积信息作为视频特征,最后采用支持向量机进行树叶遮挡检测。在样本有限的条件下,该方法能取得较好的识别效果,但它仅依赖于颜色和面积信息,提取的特征过于单一,很容易出现误报现象。另外,利用连续的帧差来分割疑似树叶区域受限于内存中保留的视频信息,一旦前一帧视频图像无法获得时,该算法便失去作用。
针对上述研究的不足之处,本文提出一种基于深度学习的监控视频树叶遮挡检测算法,其利用栈式稀疏自编码器主动学习图像特征,避免了手动提取特征的复杂困境,同时无需对视频连续取帧,摆脱了视频帧间的相关性对算法的影响。
1相关研究
1.1稀疏自编码器
稀疏自编码器(sparse auto-encoder,SAE)是一种无监督的神经网络学习结构[8],包含一层隐藏层、相同的输入层和输出层,如图1所示。SAE在无监督训练调整参数的过程中对隐藏层神经元施加稀疏约束,使大部分节点值为0或接近0,只有少数节点值不为0,从而得到输入数据的稀疏表示,这些稀疏表示即为输入数据的特征。通过这种方式,稀疏自编码器能主动提取数据的高层特征[9],捕捉到输入信号最重要的因素,从而尽可能地复现输入信号。
为了得到网络最优参数,需要先求出损失函数关于权值的偏导,再利用反向传播算法和梯度下降算法更新网络权值。无稀疏约束时网络的损失函数表示为:
(1)
式中:m为样本数量;h(x(i))为第i个样本的预测输出值;y(i)为第i个样本的标签;λ为权值衰减参数;W为连接权重;b为偏置项;sl为第l层的神经元个数;nl为网络输出层的编号。
增加稀疏约束条件后,隐藏层神经元输出的平均值应尽量为0,可得到SAE的损失函数表达式为:
(2)

(3)
(4)
(5)
最终,由误差信号可求得损失函数关于权值的偏导数。
栈式稀疏自编码器可由多层SAE组成,将前一层SAE的输出作为后一层的输入,逐层无监督训练提取输入信号的特征,因此其具有强大的特征表达能力。
1.2深度置信网络
深度置信网络(deep belief network, DBN )可以看成是多个限制玻尔兹曼机(restricted Boltzmann machine, RBM )堆叠而成,一个典型的DBN网络模型如图2所示。DBN的每层都由若干个神经元(常常是几百个或几千个)组成,各自独立地计算该层接收到的数据,每层的节点之间没有连接。v为输入层,接收来自外界的输入数据。第1层(即输入层)与第2层构成一个典型的RBM 模型,通过无监督学习方法调整网络参数,使RBM达到能量平衡。逐层训练和微调整个网络权值的过程使DBN具有较好的分类能力。

图1 SAE结构图
RBM是一种有效的特征提取方法,堆叠多个RBM组成的DBN能提取更加抽象的特征[10]。假设一个RBM中有n个可见单元和m个隐藏单元,用向量v和h分别表示可见单元和隐藏单元的状态,vi表示第i个可见单元的状态,hj表示第j个隐藏单元的状态,所有的神经元都是随机二值变量,即有∀i,j,vi∈{0,1},hj∈{0,1}。那么,对于一组给定的状态(v,h),RBM的能量函数定义为:

(6)
式中:θ={Wij,ai,bj}是RBM中的模型参数,均为实数;Wij表示可见单元i与隐藏单元j之间的连接权重;ai表示可见单元i的偏置项;bj表示隐藏单元j的偏置项。
基于该能量函数可以得到可见单元和隐藏单元的联合概率分布:
(7)

对于一个实际问题,最关心的是关于观测数据v的分布P(v|θ),即似然函数:
(8)
RBM的最终目标是求出参数θ的值来拟合给定的训练数据。参数θ可以通过最大化RBM在训练集(假设有T个训练样本)上的对数似然函数学习得到,即:
(9)
由于求解过程中归一化因子的计算代价太大,一般采用对比散度(contrastivedivergence,CD)算法来近似求解。
2监控视频树叶遮挡检测算法
本文算法先从监控视频中随机选取一帧图像,利用栈式稀疏自编码器提取输入图像的特征,然后采用深度置信网络建立分类模型,最后微调整个深度神经网络模型,并实现监控视频树叶遮挡异常的检测。
2.1数据预处理
从视频库中选取的图像可能具有不同的分辨率,不适合直接输入深度神经网络中。本文先将原始视频图像降采样成64×64的大小,再进行局部对比归一化操作,然后将其分割成8×8的图像块作为网络的输入。对图像进行分块不仅增加了训练样本数据量,满足深度学习对海量数据的要求,还有利于SAE模型构建超完备集,以得到数据的稀疏表达。
局部对比归一化能避免神经元过饱和,增强网络的泛化性,有效消除亮度和对比方差对网络的影响,大大减少了相邻因子之间的依赖性。在网络训练前,本文先对提取的图像块进行局部对比归一化,将图像(i,j)处的亮度值设为I(i,j),局部对比归一化后的亮度值为I′(i,j),归一化方法可以表示为:
(10)
式中:i∈{1,2,…,M},j∈{1,2,…,N},M、N分别为降采样图像的长和宽;C取常数1,以避免分母为零;μ和σ分别为图像块像素值的均值和标准差。
2.2网络训练
本文算法中的栈式稀疏自编码器由两个SAE堆叠而成,其隐藏层神经元个数和稀疏性参数根据参数优化结果设置,权值衰减参数λ=0.003,学习速率为0.1,最大迭代次数为400。在DBN中,其输入为栈式稀疏自编码器提取的特征,学习速率仍为0.1,引入动量项p=0.5来加速学习,网络迭代200次。
对深度神经网络进行微调时,本文引入一种学习速率自适应调整方法。学习速率ε初始化为ε0=1,根据损失函数值L自适应变化,每当损失函数值进入平滞期,学习速率随之减小为原来的一半。自适应学习速率公式表示为:
(11)
式中:t为网络训练的迭代次数。
网络训练时采用批处理的方式,批处理量为100。权值更新表示如下:
(12)

网络训练完成后,根据多数表决规则,以所有图像块中所占比重最多的预测类别作为该图像的类别,从而得到对应监控视频的检测结果。
3实验与结果分析
3.1实验数据
实验所采用的监控视频库来源于某安防企业的平安城市项目,一共有1948个视频,其中包含1134个正常视频、814个树叶遮挡的异常视频。这些视频来自于不同的监控场景,视频像素规格有352×288、528×384、704×576和1280×720等。图3为从监控视频库中截取的部分视频图像,图中局部马赛克区覆盖的是版权信息。
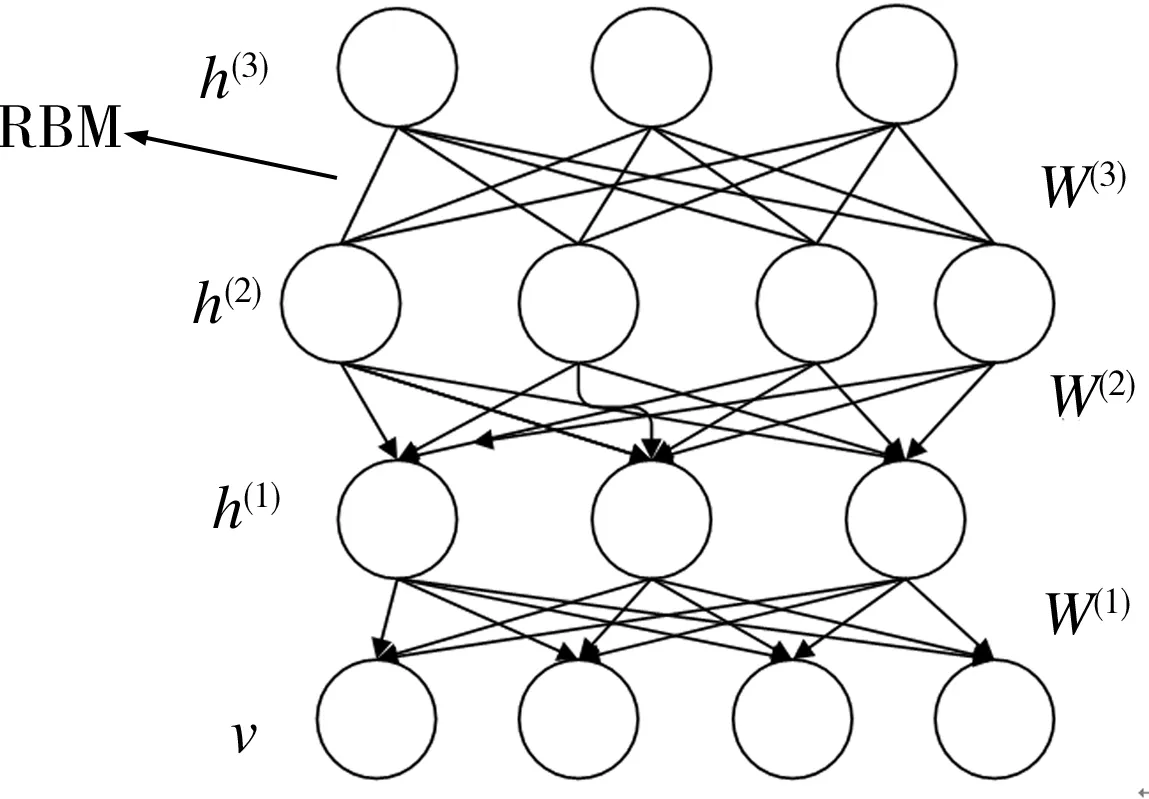
图2 DBN结构图

(a) 树叶遮挡视频

(b) 正常视频
3.2实验方法
在Matlab 2014a环境下编程实现本文算法。采用交叉验证的方法,将实验样本随机分为三个子集,其中60%作为训练集,20%作为验证集,其余20%作为测试集,训练集、验证集和测试集在图像内容上是绝对独立的。采用准确率、漏检率和误识率来评价算法的检测性能,计算公式如下:
(13)
(14)
(15)
3.3实验结果及分析
为了研究网络参数对视频图像特征提取效果的影响,通过控制变量法,分别改变栈式自编码器隐藏层神经元数目和稀疏性参数对算法性能进行实验测试。
(1)神经元数目
将稀疏性参数固定为0.1,在100~800范围内改变栈式稀疏自编码器第一个隐藏层的神经元个数,得到本文算法应用于监控视频库全体测试集上的检测性能指标如表1所示。由表1可见,随着神经元数目的增加,检测准确率逐渐提高,当隐藏层神经元个数为400时检测准确率最高,且此时的漏检率和误识率也最低;之后,随着神经元数目的进一步增加,检测准确率又逐渐降低。由于输入单元的维数为192,而400个隐藏层神经元能构成一组超完备集,可得到输入数据良好的稀疏表示,从而获得比较高的检测准确率。但继续增加隐藏层神经元个数反而会使隐藏层维数过高,不仅难以有效提取数据特征,还会增加训练时间。
表1采用不同隐藏层神经元数目的视频检测结果
Table 1 Video detecting results by using different numbers of hidden neurons

神经元数目/个准确率/%漏检率/%误识率/%10084.1014.7216.7420084.6214.1116.3030085.1313.5015.8640088.9710.4311.4550085.3813.5016.3060085.1314.1115.4280084.8714.7215.42
图4为栈式稀疏自编码器第一个隐藏层学习到的特征的可视化效果。从图4中可以看到,稀疏自编码器具有很好的特征学习能力,能主动提取出树叶的颜色、边缘和纹理等特征,比人工提取的特征更加丰富,更能表现出数据的内在特性,而这对于树叶遮挡检测是非常重要的。
(2)稀疏性参数
将栈式自编码器隐藏层神经元个数固定为400,改变稀疏性参数取值,得到针对监控视频库全体测试集的检测性能指标如表2所示。由表2可见,稀疏性参数为0.1时,检测准确率最高,漏检率和误识率最低,综合检测性能最好。这是因为,稀疏性参数过小会使特征向量过于稀疏,无法有效表示数据特征;反之,稀疏性参数过大使得特征向量大部分不为0,无法达到稀疏目的。

图4 特征的可视化
Fig.4 Visualization of features
表2采用不同稀疏性参数的视频检测结果
Table 2 Video detecting results by using different sparse parameters

稀疏性参数准确率/%漏检率/%误识率/%0.05071.5428.2228.630.07581.0318.4019.380.10088.9710.4311.450.12584.6214.7215.860.15084.1015.3416.300.20082.0515.3419.82
为了进一步验证本文算法的有效性,将本文算法与文献[7]算法进行实验对比分析。根据参数优化结果,将栈式自编码器隐藏层神经元个数设为400,稀疏性参数设为0.1,其他参数不变,实验结果如表3所示。从表3中可以看到,当样本数量较少时,由于本文算法出现过拟合问题,得到的检测结果不如文献[7]算法;但是,随着样本数量的不断增多,本文算法的性能大大提升,当样本数量为1948时,本文算法比文献[7]算法的准确率更高、漏检率和误识率更低。由此可见,在样本量充足的条件下,本文算法对监控视频中的树叶遮挡具有较好的检测效果。

表3 视频检测结果对比
4结语
本文提出了基于深度学习的监控视频树叶遮挡检测算法,结合稀疏自编码器和深度置信网络,先主动学习视频图像特征,然后对树叶遮挡进行分类检测。该方法不需要对视频连续取帧,不依赖视频的时间域动态特性,能主动学习到静态图像中丰富的特征信息。在样本量充足的条件下,本文算法对监控视频中的树叶遮挡具有较好的检测性能。在下一步的研究中,还可考虑在稀疏自编码器提取的特征中融合场景的先验知识,从而取得更好的检测效果。
参考文献
[1]刘治红,骆云志.智能视频监控技术及其在安防领域的应用[J].兵工自动化,2009,28(4):75-78.
[2]Ribnick E, Atev S, Masoud O, et al. Real-time detection of camera tampering[C]//Proceedings of the IEEE International Conference on Video and Signal Based Surveillance,November 22-24,2006, Sydney, Australia. IEEE, 2006:10-16.
[3]Lin Daw-Tung, Wu Chung-Han. Real-time active tampering detection of surveillance camera and implementation on digital signal processor[C]//Proceedings of the 2012 Eighth International Conference on Intelligent Information Hiding and Multimedia Signal Processing. IEEE, 2012:383-386.
[4]王宝君,胡福乔.基于角点的监控摄像头干扰检测[J].计算机应用与软件,2010,27(5):243-245.
[5]Saglam A, Temizel A. Real-time adaptive camera tamper detection for video surveillance[C]//Proceedings of the Sixth IEEE International Conference on Advanced Video and Signal Based Surveillance,September 2-4,2009,Genova,Italy.IEEE,2009:430-435.
[6]YinHongpeng,JiaoXuguo,LuoXianke,etal.Sift-based camera tamper detection for video surveillance[C]// 第25届中国控制与决策会议论文集.沈阳:东北大学出版社,2013:665-668.
[7]袁渊, 丁胜, 徐新,等. 基于支持向量机的监控视频遮挡树叶检测[J].计算机应用,2014, 34(7):2023-2027,2032.
[8]Bengio Y. Learning deep architectures for AI[M]//Foundations and Trends®in Machine Learning. Hanover, MA:Now Publishers Inc, 2009.
[9]Zhu Ming, Wu Yan. A novel deep model for image recognition[C]//2014 5th IEEE International Conference on Software Engineering and Service Science (ICSESS). IEEE,2014:373-376.
[10]张春霞,姬楠楠,王冠伟. 受限波尔兹曼机简介[EB/OL]. 北京:中国科技论文在线.(2013-01-11)[2015-11-14].http://www.paper.edu.cn/releasepaper/content/201301-528.
[责任编辑尚晶]
Deep learning based approach for detecting leaf occlusion in surveillance videos
WuMeiyin,ChenLi
(1.College of Computer Science and Technology,Wuhan University of Science and Technology,Wuhan 430065, China;2.Hubei Province Key Laboratory of Intelligent Information Processing and Real-time Industrial System,Wuhan University of Science and Technology, Wuhan 430065, China)
Abstract:Integrating the advantage of automatic feature extraction by sparse auto-encoder and the good classification performance of deep belief network, this paper proposes a detection approach for leaf occlusion in surveillance videos based on deep learning. Firstly, a frame is randomly selected from the video sequences, and a stacked sparse auto-encoder is used to actively learn the feature information in the video image. Next, a deep belief network is adopted to build a classification detection model. Finally, an adaptive learning rate strategy is introduced to fine-tune the whole artificial neural network. This method does not require consecutive video fetching frames and has better ability of active learning about image features, and therefore it overcomes the limitation of manual feature extraction. Experimental results demonstrate that the detection accuracy of the proposed method for leaf occlusion in surveillance videos can reach 88.97% under the condition of sufficient samples.
Key words:surveillance video; occlusion detection; image recognition; sparse auto-encoder;deep belief network;deep learning; feature extraction
收稿日期:2015-11-23
基金项目:国家自然科学基金资助项目(61375017);湖北省高等学校优秀中青年科技创新团队计划项目(T201202);武汉科技大学研究生创新创业基金资助项目(JCX2015010).
作者简介:邬美银(1993-), 女, 武汉科技大学硕士生.E-mail:1562394959@qq.com 通讯作者:陈黎(1977-), 男, 武汉科技大学教授,博士.E-mail:chenli@ieee.org
中图分类号:TP183
文献标志码:A
文章编号:1674-3644(2016)01-0069-06
