不同学科领域的用户标签标注行为差异研究
——以新浪微博用户的标签为例*
2016-06-01池雪花张颖怡章成志
池雪花,张颖怡,高 星,卢 超,章成志
不同学科领域的用户标签标注行为差异研究
——以新浪微博用户的标签为例*
池雪花,张颖怡,高 星,卢 超,章成志
文章以新浪微博中用户标签作为研究对象,从微博中收集用户基本信息与用户标签信息,依据用户标签分类体系对用户标签进行人工分类;然后分析标签类型、标签类型分布熵、用户平均标签个数、用户平均标签长度等标签标注行为指标在不同学科领域中的差异,以及从高频和不同标签个数分组两个角度分析上述行为指标在不同学科领域的差异。研究表明,标签类型、平均标签个数在不同学科领域中有显著性差异;不同学科领域高频标签中,标签类型存在较大差异;在不同标签个数分组下,用户标签类型在不同学科领域下无明显差异,用户的平均标签长度随着个数的增多呈递减趋势。
用户标签 标签分类 标注行为 用户信息行为
0 引言
随着互联网发展,越来越多的Web2.0网站采用标签标注功能,用户针对网络资源进行标注,从而产生大量的标签。一些社交网站允许用户在维护个人文档时,用关键词标注自己的兴趣或爱好,这种类型的关键词通常称为用户标签(UserTag),图1为新浪微博博主孙茂松的用户标签(http://weibo.com/p/1005051970879995/ info?mod=pedit_more)。

图1 孙茂松的用户标签
规范的用户标签可以对社交网站上的用户进行有效分类,并为用户兴趣建模、好友推荐、专家检索等应用提供依据。然而目前微博用户标签存在标注随意、标签无序化、标签间缺乏语义关系等问题,这限制了用户标签的实际应用效果。现有的社会化标签研究主要对象为用户生成内容对应的标签,而学术界对用户标签的研究还较少,更缺乏对用户标签的分类研究。
研究不同领域的社会化标签的标注行为差异,对标签标注质量的提高有重要作用。为此,本文通过对用户标签进行分类研究,考察不同学科领域的标注差异,从而为今后的用户标签标注界面或标注系统的研究与设计提供参考。本文选择新浪微博作为研究对象,从微博中收集用户标签相关信息,设计微博用户标签分类体系,依据该体系对用户标签进行人工分类;然后分析不同学科领域中用户标签的差异。调研结果发现,标签类型、平均标签个数在不同学科领域中有显著性差异;不同学科领域高频标签中,标签类型存在较大差异;在不同标签个数分组下,用户标签类型在不同学科领域下无明显差异,用户的平均标签长度随着个数的增多呈递减趋势。
1 相关研究概述
(1)标签标注行为研究概述。标注系统中用户标注行为的研究已引起学者持续关注。2007年FarooqU等从标签增长、标签重用、标签显隐性、标签歧视、标签频率和标注方式来分析用户标签标注行为[1];Mirzaee V等从每个资源的标签数量、标签的选择与使用、标注频率等角度分析用户标签标注动机对标注行为的影响[2];Xufei Wang等以StumleUpon与Delicious为平台,从用户标签数量、用户标签共享、高频率标签的使用等角度对用户标注行为进行分析[3];Aedín Guyot从标签长度、标签个数、高频率使用标签、不同语言标签、标签长尾性等角度对LibraryThing中的书籍标签进行分析[4];章成志等人对腾讯微博用户标签与微博内容关键词进行相关度评分,考察不同领域用户标签主题表达能力[5]。
(2)标签类型划分研究概述。社会化标签具有不同的类型和功能,区分标签类型有利于有针对性的应用研究。学者们提出不同的标签类型划分方式。Sen S和Lam K等将标签划分为客观标签、主观标签和个人标签[6];Xu Zhichen和Fu Yun等将标签划分为描述内容、提供资源一些额外信息(如时间、地点)、外部属性(如拥有者类型)、表达对资源评价、用于自我组织的一些个人词汇等[7];Melenhorst M S和Van S M等将标签划分为内容标签、态度标签、自我提醒标签等[8];Bischoff K和Firan C S等将标签细分为主题、类型、作者或拥有者、评价、目的、自身任务需要、地点、时间等类型[9];Heymann P等等将标签划分为客观和基于内容的、物理属性、意见、个人、缩写词、垃圾标签等类型[10];Bhnstedt D等将标签划分为人物或者组织资源作者或涉及到的人、地点、资源的类型、资源所涉及事件、主题、目标或任务等类型[11];Cantadora I等将标签划分为基于内容和基于环境两大类,基于内容的标签可再细分为物理实体和非物理实体及组织团体,基于环境下可细分为时间、地点等类型[12]。
综上,社会化标签标注行为、标签类型划分等相关研究较深入,然而缺乏用户标签的类型划分、不同学科领域的用户标签标注行为差异等相关研究。用户标签分类研究对于用户标签标注界面或系统设计具有参考价值,因此,本文结合用户模型,引入标签分类体系,对用户标签进行分类,并进行标签类型、标签类型分布熵、标签个数、标签长度这四个方面的计算,通过四个指标分析用户在不同分类角度下的标注行为差异。
2 调研流程与关键步骤描述
2.1 调研流程
如图2所示,本文调研流程为:首先利用新浪微博平台,采集不同学科领域下的用户标签数据;其次制定用户标签分类体系,邀请3名志愿者参与用户标签分类任务,得到用户标签分类数据集;然后根据标签分类数据集进行结果分析,即利用分类结果获得标签类型比率、标签类型分布熵以及标签的平均长度、平均个数;最后进行不同学科领域、高频标签、不同标签个数用户等三个角度下的比较分析。
2.2 标签分类体系的构建
本文结合用户建模思想构建用户标签分类体系。本文通过前期的用户标签数据调研结果,参考GolematiM等关于个人本体构建的研究成果[13],结合对部分用户标签类型的考察,在GolematiM等人成果的基础上,增加状态、行业领域、身份或职位、工作经历和其他这5个用户相关属性,最终得到用户标签分类体系,如表1所示(说明:部分标签由于用户个人经历不同可划分成多种类型,如标签“音乐”可划分成专业或兴趣爱好。对于上述情况,本文参考用户主页,结合用户实际情况进行标签类型划分)。
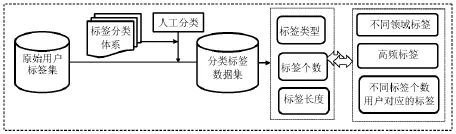
图2 用户标签类别的调查分析流程图
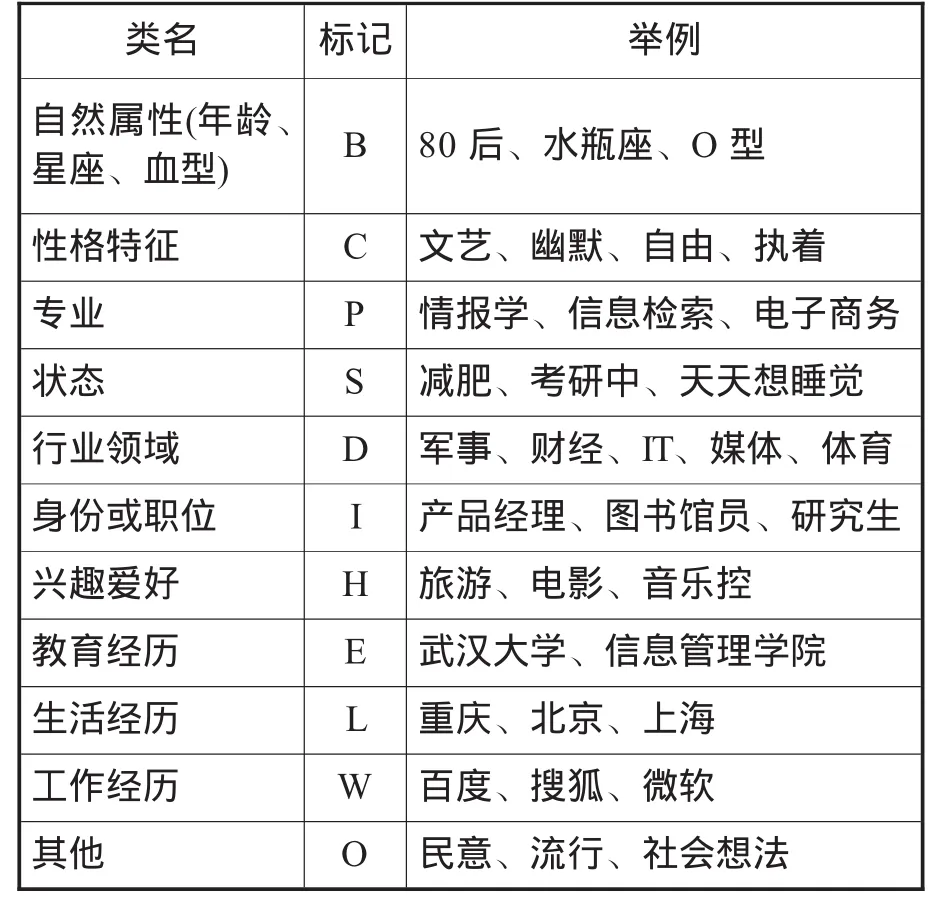
表1 微博用户标签分类体系说明与举例
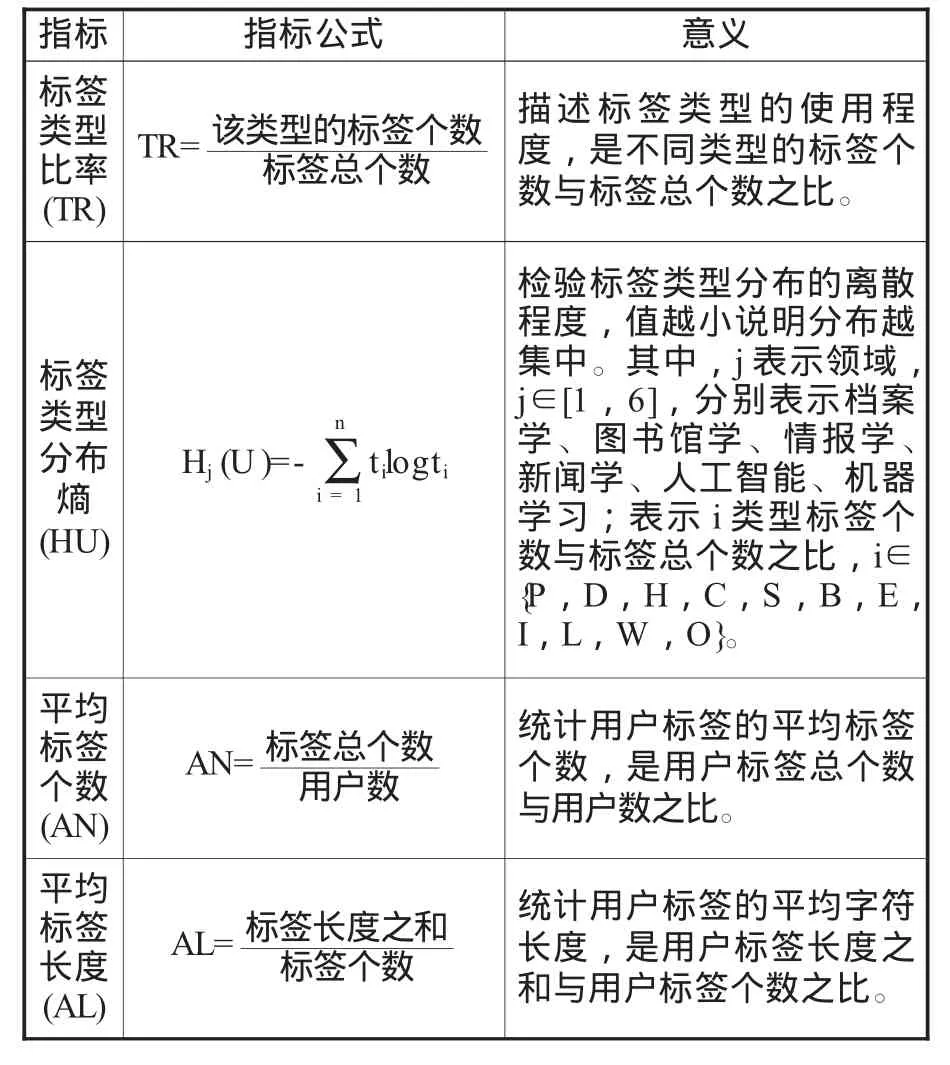
表2 用户标注行为量化指标说明
2.3 用户标注行为量化指标构建
为全面考察用户标签在不同学科领域的差异,本文从标签类型比率、类型分布熵、平均标签个数与长度等角度进行考察,见表2。
(1)标签类型比率。选择类型比率指标的原因:在微博中,用户可以标注不同类型的标签;某一类型的标签数越多,说明用户标注此类型标签的积极性越高。因此,通过类型比率,可以对用户使用不同标签类型的积极性的差异进行分析。为计算类型比率,本文对每位用户的标签按照事先构建好的标签分类体系进行分类,并对用户标签数量进行统计,从而计算出每个学科领域用户标签的类型比率。
(2)标签类型分布熵。选择标签类型分布熵的原因:信息熵是信息论中用于度量信息量的概念;一个系统的信息熵越低表明该系统越有序,信息熵越高表明该系统越混乱。计算标签类型分布熵可描述出标签类型的离散程度。因此,通过计算标签类型分布熵的大小,可对不同学科领域用户的整体标签类型分布的差异进行分析。
(3)平均标签个数。选择平均标签个数指标的原因:用户可以为自己标注不同数量的标签,因此不同用户的标签数量有差异;之前学者通过对不同网站中用户的平均标签个数,以及不同资源的平均标签个数进行调研来分析用户的标签标注行为[2][3-4][13]。因此,通过平均标签个数可以对不同学科领域用户的平均标签个数的差异进行分析。
新浪微博的标签分为中英文两种语言。对中文标签,本文将空格符号作为标签分割符,如“旅游校园生活”计算为2个标签。对英文的标签,以一个单词为标准,如“IT”计算为1个标签。由此得到每位用户的标签总数,计算用户标签总数与用户数量的比率,得到平均标签个数。
(4)平均标签长度。选择平均标签长度指标的原因:用户标注行为研究中,学者开始对标签长度予以重视[4];标签长度的研究数量占所有用户标注行为的研究仍较少。因此,通过平均标签长度指标,可对不同学科领域用户标签的平均标签长度的差异进行分析,从而为标签长度的研究提供参考。本文采用计算字节数的方式,将1个中文计算为2个字节,如“旅游”为4个字节长度;将一个英文字母计算为1个字节,如“IT”为2个字节长度。通过上述方式,统计得到标签总长度,并计算标签总长度与总个数的比率,得到平均标签长度。
3 调研结果与分析
3.1 实验数据准备
(1)实验数据采集概述。在采集实验数据时,本文对以下几点进行控制:数据来源:本文以新浪微博为研究平台,采集用户信息及用户标签数据;采集时间:数据采集的时间段为2014年12月20日至2015年4月20日;采集对象:选择档案学、图书馆学、情报学、新闻学、机器学习、人工智能6个学科领域作为采集对象;采集方法:在新浪微博网络平台上,根据事先选择的学科领域,以学科名作为关键词,在微博搜人栏目中手动检索出用户,去除认证的微博用户,记录用户名,用户URL及用户标签;通过上述途径共采集2673个微博用户,不同学科领域的调研用户分布见表3。
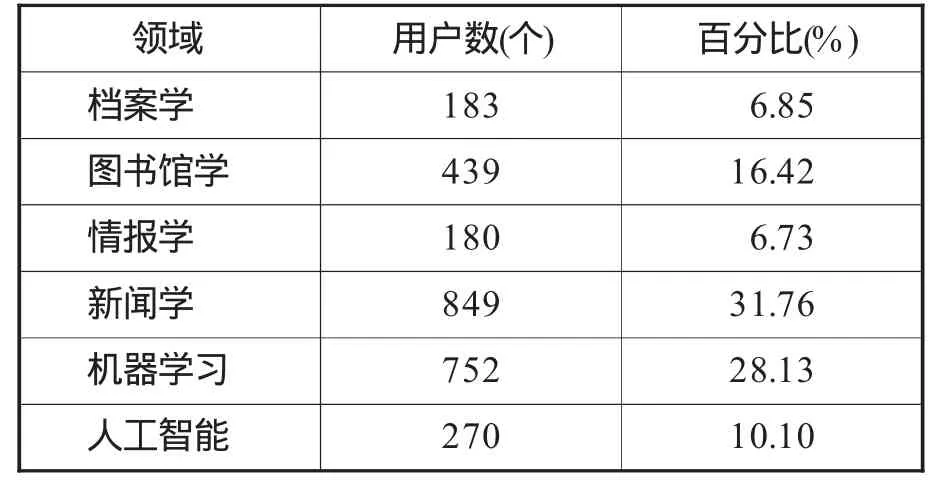
表3 不同学科领域的调查用户数
标签分类数据集的构建。根据2.2小节提供的标签分类体系,邀请2名志愿者对6个学科领域微博用户的标签进行分类,然后邀请第3名志愿者对不一致结果给予确认,作为该标签的最终分类结果。为刻画两名志愿者的标注是否一致,采用比较简单的标注差异度量化指标来度量,差异度计算公式如下:

两名志愿者的标注差异如表4所示。结果显示:6个领域中两名志愿者的标注差异度为0.13~0.28,均值为0.1570,说明两名志愿者在对用户标签进行分类时,有较好的标注一致性。
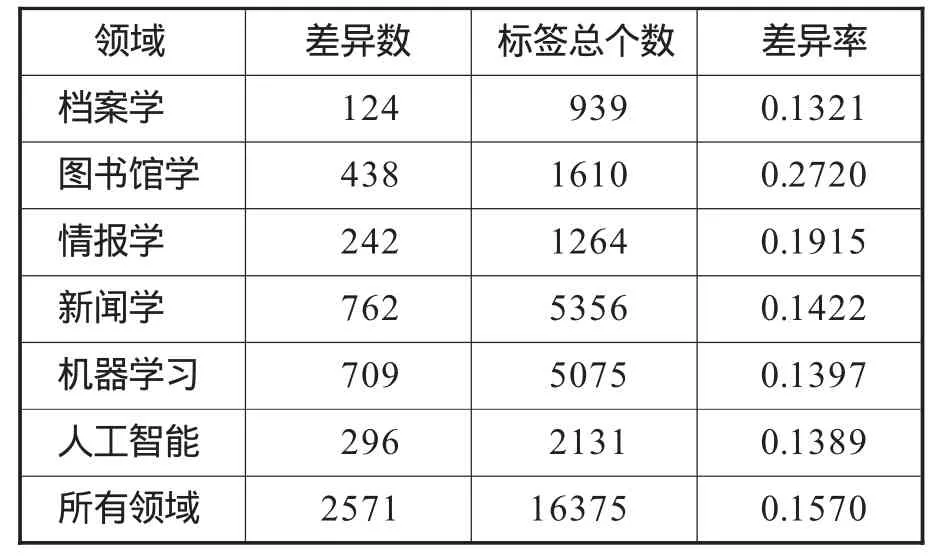
表4 志愿者标注的差异度
3.2 不同学科领域用户标签类别差异分析
选取6个不同学科领域的新浪微博用户,通过标签类型比率、标签类型分布熵、平均标签个数、平均标签长度来分析不同领域用户标签类别差异。对不同学科领域用户标签类型进行差异性分析,结果如图3所示:(1)在各个学科领域下,标签主要集中在P、H、D类型,说明大部分用户习惯选用自己的专业、所属领域、兴趣爱好来描述自己;(2)情报学、机器学习、人工智能P类的标签比率总体较高,都在0.4以上,其他三个学科领域的P类标签比率较低,说明情报学、机器学习、人工智能用户使用微博主要用于学术交流,专业属性较强,其他三个学科领域用户比较倾向综合发展;(3)H类型标签比率普遍较高,说明用户的兴趣爱好比较广泛,其中新闻学的比率最高,达到0.40左右,情报学、人工智能相对较低,机器学习最低,为0.20左右;(4)图书馆学的L类比率尤为高,体现出图书馆学用户喜欢使用表示生活经历的标签。对不同领域微博用户标签类型分布熵进行差异性分析,结果如表5所示。
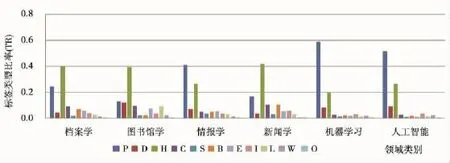
图3 不同学科领域用户标签类型分布

表5 不同学科领域标签类型分布熵
从标签类型分布熵看,值从大到小依次的领域是:图书馆学、新闻学、档案学、情报学、人工智能、机器学习。图书馆学的熵值最大为2.7258,说明在图书馆学的用户标签类型最多,差异较大。机器学习的熵值最小为1.9848,人工智能、情报学的熵值也相对较小分别为2.0422、2.5305。说明自然科学领域用户标签类型差异幅度较小,社会科学领域用户标签类型差异幅度大,标签呈现多样化。对不同学科领域微博用户平均标签个数、长度进行差异分析,结果如表6所示。

表6 不同学科领域用户平均标签个数、长度
微博用户的平均标签个数为6个左右,图书馆学用户的平均标签个数最少为3.67个,人工智能的用户平均标签个数最多为7.89个,新闻学和机器学习的平均标签个数也较多,大约为6-7个,档案学用户的平均标签个数为5.13。说明机器学习、人工智能、情报学、新闻学用户标签标注积极性较高,档案学和图书馆学用户标注积极性较低,其中图书馆学用户积极性最低。
用户的平均标签长度为7.14字节,不同学科领域下用户平均标签长度无明显差异,即用户趋向于使用3-4个字的词语用来标注。其中档案学平均标签长度最短为6.54字节。机器学习的平均标签长度最长为7.82字节,原因可能是由于其专业名词较长。从整体看,自然科学领域的用户的平均标签长度较长,社会科学领域的用户的平均标签长度较短。
3.3 高频用户标签类别差异分析
微博用户标签在一定程度上揭示了用户自身信息,如爱好、专业、观点、感想。由于具有相同文化、知识或社会背景的用户对某些事物存在一致的认识,因此他们会不约而同地使用相同的标签。本文对这些相同的标签进行统计,试图对高频次的用户标签类别在不同领域进行差异分析。
首先,通过标签比率从众多标签中挑取出高频用户标签,计算公式为:
标签比率=标签出现的次数/所有标签个数
然后通过对比率从大到小排序,得到每个领域的高频用户标签。表7为不同领域的频次最高的前10个用户标签。
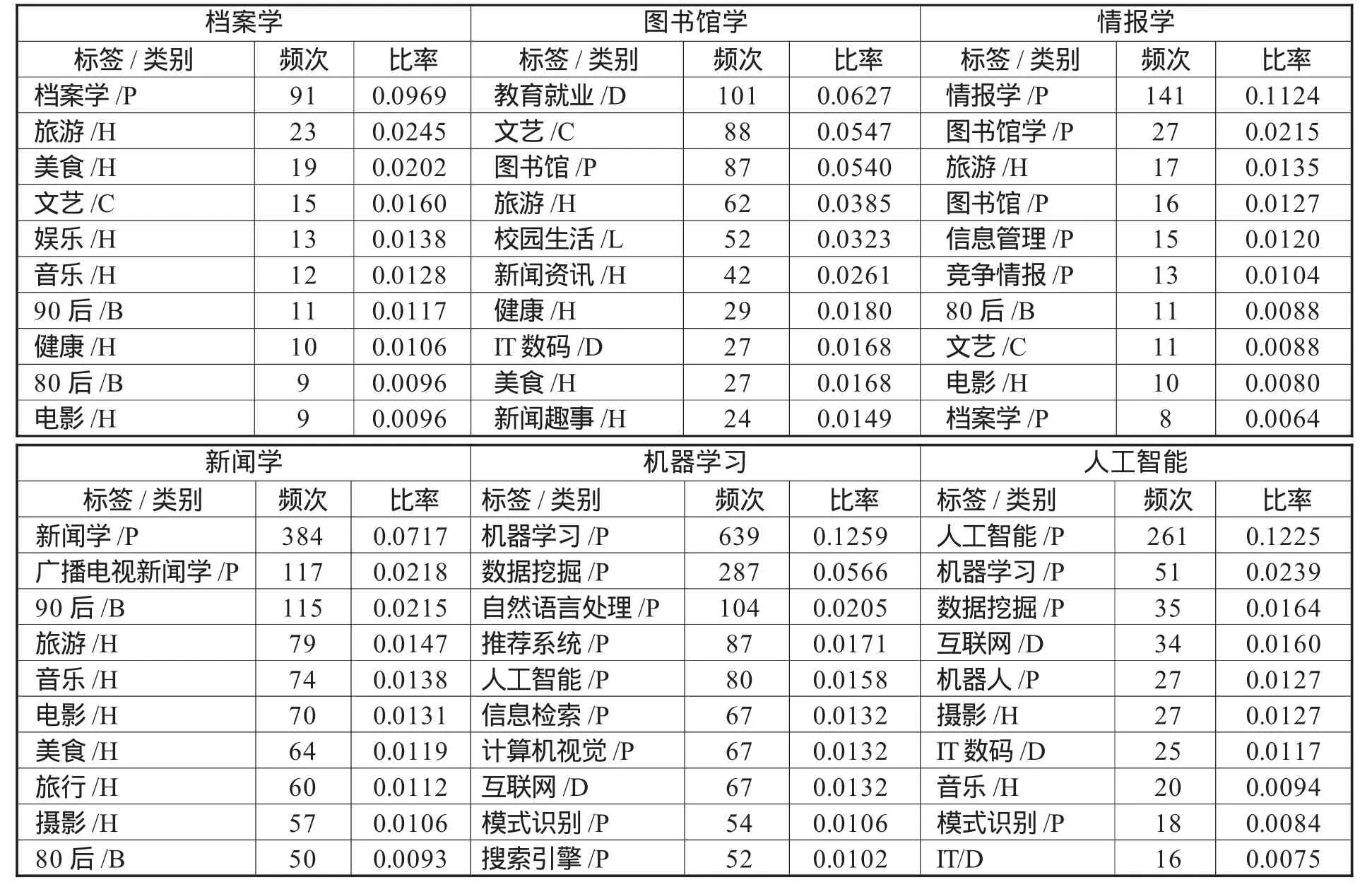
表7 不同学科领域TOP-10高频标签一览表
由表7可知:(1)每个领域中(除图书馆学)标签比率最大的标签皆为本领域的名称,图书馆学标签比率最大的是“教育就业”,说明图书馆学用户比较关注教育就业方面。(2)出现次数较多的共同标签有“旅游”“美食”“文艺”“音乐”“电影”,说明这些为用户的普遍爱好和共同特点,也有可能是因为微博为用户给自己打标签时提供的标签自动推荐功能导致该类标签比率上升。(3)多个领域出现了“80后”“90后”标签,揭示了微博用户主要为80后、90后群体。(4)情报学、机器学习、人工智能相对于其他三个领域出现较多的标签为专业名词。(5)档案学领域出现了“情报学”,情报学领域下出现“图书馆学”“档案学”等,体现了领域之间的交叉,在交叉领域下又出现了很多共同的高频标签,如“互联网”“IT”“大数据”等,体现了交叉领域间的共同背景。(6)情报学中出现“武汉大学”,新闻学中出现了“中国传媒大学”,其都为本学科领域实力顶尖的高校。
本文对微博用户高频标签进行标签类型差异性分析,将标签按照标引的频次选择Top5、Top10、Top20,并按分类体系进行类型分布统计,结果如图4(a)-(f)所示。
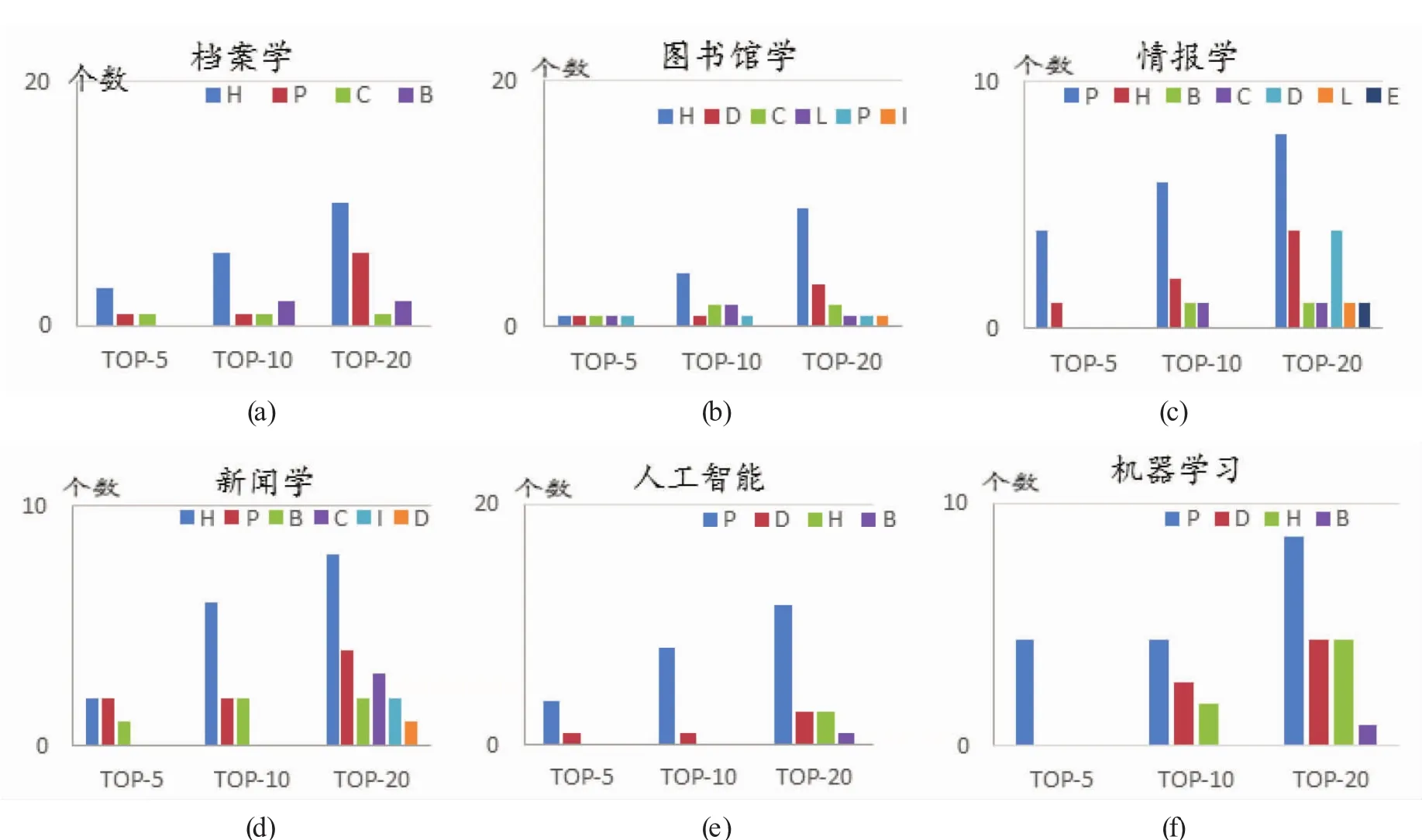
图4 微博用户高频标签类型分布比较
由图4(a)可看出,档案学领域微博用户高频标签以H、P为主,说明微博用户在表达自己的兴趣爱好之外倾向于表达专业技能。从图4(b)、4(c)、4(d)看出,图书馆学、情报学、新闻学领域的标签类型较多,但以H为主。说明微博用户并非只关注单方面的知识,而更多偏向于综合、全面和广泛的学习交流。从图4(e)、4(f)可见人工智能和机器学习的标签类型集中在P和D类,在前20个标签中只有4种类型,且只有一个标签是B类,表明这两个学科的标签类型相对单一。
从整体高频标签类型分布情况来看,用户偏向选择兴趣爱好和专业的标签。社会学科用户标签类型相对自然科学用户较多,体现社会学科用户的表达方式的多样化。
对高频用户标签进行平均标签长度的差异分析,结果见表8。取前5个高频标签进行考察时,计算出所有领域的平均标签长度为6.6字节,前10个高频标签的平均长度为6.2字节,前20个高频标签的平均长度为6.15字节。在这三个分组中标签长度无明显差异。而表6显示不同学科领域用户平均标签长度为7.14字节。对比可见,高频标签一般长度较短的,为3个字左右。在TOP5,TOP10,TOP20不同分组下,机器学习的平均标签长度始终为最长,档案学的平均标签长度始终为最短。从整体看,自然科学用户平均标签长度普遍比社会科学用户平均标签长度长。

表8 平均标签长度(单位:字节)
3.4 不同标签个数用户对应的用户标签类别差异
微博用户可以为自己选择1个或多个标签来描述自己,从标签个数在一定程度上可以看出用户使用标签的积极程度。因此根据用户的标签个数对用户进行分组研究显得有意义。本文已剔除无标签用户,根据统计发现用户标签个数最少为1个,最多有13个。所以把用户按照标签个数分组为:标签个数1-3个、标签个数4-6个、标签个数7-9个、标签个数10个以上。
对不同标签个数用户的标签类型进行差异性分析。通过按不同标签个数对用户进行分组,然后在统计了每个分组下标签的类型比率,得到的结果如图5所示。
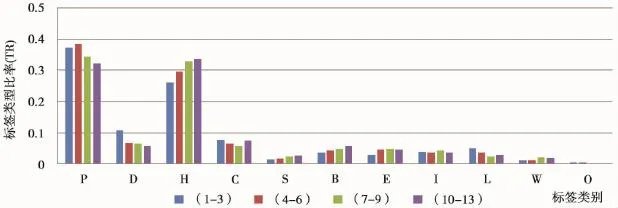
图5 不同标签个数用户分组下的标签类型比率
从图5可知:(1)标签类型为专业和行业领域的标签在用户标签个数增多的情况下成下降趋势,这是由于描述用户专业的标签个数有限,当基数增大时,比率减小。(2)标签类型为兴趣爱好的标签随个数的增多比率上升,说明用户在标签个数增多时偏向选用类型为兴趣爱好的标签,同时也说明用户广泛的兴趣爱好。(3)标签类型为性格特征的标签,在个数为1-3个和10-13个时比率较大。(4)标签类型为状态和自然属性的标签,随着标签个数增多类型比率增大。(5)类型为教育经历的标签,在标签个数为1-3个的用户组内较少使用,在标签个数为4-13个的用户中无明显差异。(6)类型为身份、工作经历的标签在不同分组内也无明显差异。
对微博用户高频标签进行平均标签长度差异分析,结果如表9所示。由表9可知,标签长度一般为6-8字节,即平均每个标签为3-4个字。当用户标签个数为1-3个时,平均标签长度为7.5字节;当用户标签个数为4-6个时,平均标签长度为7.06字节;当用户标签个数为7-9个时,平均标签长度为7.14字节;当用户标签个数为10个以上时,平均标签长度为6.94字节。可以看出用户的平均标签长度随着个数的增多而减短,即标签个数越多,平均标签长度越短,标签个数越少,平均标签长度越长。
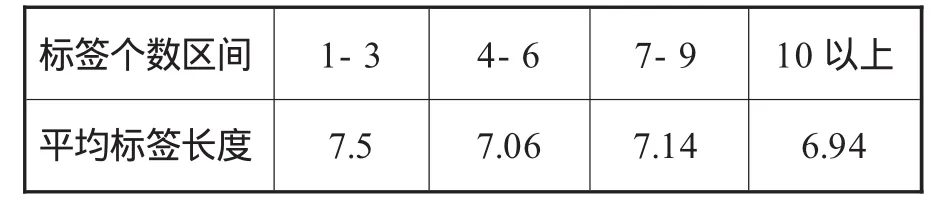
表9 平均标签长度(单位:字节)
4 结论与展望
本文从用户建模的角度区分标签类型,研究不同学科领域高频用户标签,不同标签个数用户下的标签类型的差异,结果表明:不同学科领域用户的标签类型主要集中在专业、兴趣爱好和行业领域。社会科学领域的用户标签类型多且差异较大,其中标签类型为兴趣爱好的最多,自然科学领域的用户标签类型相对较少,集中的标签类型为专业。自然科学领域的平均标签个数比社会科学领域多。从平均标签长度看,皆在3-4个字左右,这是由于用户一般使用3-4字的词语使用习惯造成的。但高频用户标签的长度较短。在标签个数逐渐增多下,用户的平均标签长度减短,且在使用标签类型为专业的标签后会偏向选择表示兴趣爱好的标签,体现了用户广泛的兴趣。
本文研究不足之处主要包括:人工分类的形式,由于每个人的认知程度,知识面限制等原因,所以不可避免地给分类带来了判断误差;数据采集在学科领域覆盖面上有待提高;此外,在采集用户信息时仅用单一的查询词且仅通过网站采集数据,并不能结合用户的实际真实信息以得到更加可靠的结果。下一步可以根据用户发微博,关注好友等行为来对用户进行动态建模,以便于更准确实时地分析用户的行为。
[1]FarooqU,KannampallilTG,SongY,et al.Evaluating tagging behavior in socialbookmarking systems:metrics and design heuristics[C]//Proceedingsofthe 2007 InternationalACM Conference on Supporting Group Work,2007:351-360.
[2]Mirzaee V,Iverson L.Tagging:Behaviour and motivations[J].ProceedingsoftheAmerican SocietyforInformationScience&Technology,2009,46(1):1-5.
[3]Wang X,Kumar S,Liu H.A Study of Tagging BehavioracrossSocialMedia[C]//Proceedingofthe2011 SIGIR Workshop on Social Web Search and Mining. Beijing:2011.
[4]Guyot A.Understanding Booksonomies-How and why are book taggerstagging[D].Aberystwyth:University of Wales,2013.
[5]章成志,何陆林,丁培红.不同领域的用户标签主题表达能力差异研究——以中文微博为例[J].情报理论与实践,2013(4):68-71.
[6]SenS,LamSK,RashidAM,etal.tagging,communities,vocabulary,evolution[C]//Proceedings of the conference on Computer supported cooperative work. USA:ACM,2006:181-190.
[7]Xu Z,Fu Y,Mao J,et al.Towardsthe semantic web: Collaborativetag suggestions[C]//Proceedings of Collaborativewebtaggingworkshop at WWW 2006.Edinburgh,Scotland:2006.
[8]Melenhorst M S,Van SM.Usefulnessoftagsin providingaccessto large information systems[C]//Proceedings of IEEE International Professional Communication Conference.Scattle:IPCC,2007:1-9.
[9]Bischoff K,Firan C S,Kadar C,et al.Automatically identifying tag types[M]//Advanced Date Mining and Applications.Berlin:Springer,2009:31-42.
[10]Heymann P,Paepcke A.Garcia-Molina H.Tagging human knowledge[C]//Proceedings of the Third ACM International Conference on Web Search and Data Mining.New York:ACM,2010:51-60.
[11]BhnstedtD,LehmannL,RensingC,etal.Automantic identification of tag types in a resource-based learning scenario[M]//Towards Ubiquitous Learning.Berlin:Springer,2011:57-70.
[12]CantadoraI,Konstasb I,Joemon M J.Categorisingsocialtagsto improvefolksonomy-based recommendations [J].WebSemantics:Science,ServicesandAgentson the WorldWideWeb,2011,9(19):1-15.
[13]GolematiM,KatiforiA,VassilakisC,etal.Creatingan Ontologyfor the User Profile:Method and Applications [C]//ProceedingsoftheFirstInternationalConferenceon Research Challenges Information Science.Ouarzazate:2007:23-26.
(责任编辑:邝玥)
Different Tagging Behavior of Microblog Users in Different Domains——A Case Study of User Tagging of Sina Weibo
CHIXue-hua,ZHANGYing-yi,GAOXing,LUChao,ZHANGCheng-zhi
This paper studies user tags of Sina Weibo.By collecting users’profiles and their tagging information,tags are classified manually according to tags classification system;then analysis is made of the differences in tag types,the distribution entropy of tag types,the average number of user tags,and the average length of tags in different domains.Tagging behavioral indicators are also compared according to high frequency and tag number. The study finds that there are significant differences in tag types and average tag number in different domains;and there are large differences in types of high-frequency words.Grouped by the numbers of different tag types,no obvious differences are showed in user tag types of different domain sand the average length of user-generated tags decreases with an increase in the number of tags.
user tags;tag classification;tagging behavior;user information behavior
格式 池雪花,张颖怡,高星,等.不同学科领域的用户标签标注行为差异研究——以新浪微博用户的标签为例[J].图书馆论坛,2016(9):112-120.
池雪花,女,南京理工大学经济管理学院硕士生;张颖怡,女,南京理工大学经济管理学院博士生;高星,女,南京理工大学经济管理学院硕士生;卢超,男,南京理工大学经济管理学院博士生;章成志,男,博士生导师,南京理工大学经济管理学院教授,通讯作者,E-mail:zcz51@126.com。
2015-08-03
*本文系国家社会科学基金重大项目“面向突发事件应急决策的快速响应情报体系研究”(项目编号:13&ZD174)、国家社会科学基金项目“在线社交网络中基于用户的知识组织模式研究”(项目编号:14BTQ033)和中央高校基本科研业务费专项资金项目(项目编号:30915011323)研究成果之一
