CRFs融合语义信息的英语功能名词短语识别
2016-06-01马建军裴家欢黄德根
马建军,裴家欢,黄德根
(1. 大连理工大学 外国语学院,辽宁 大连 116024;2. 大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
CRFs融合语义信息的英语功能名词短语识别
马建军1,裴家欢2,黄德根2
(1. 大连理工大学 外国语学院,辽宁 大连 116024;2. 大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
名词短语识别在句法分析中有着重要的作用,而英汉机器翻译的瓶颈之一就是名词短语的歧义消解问题。研究英语功能名词短语的自动识别,则将名词短语的结构消歧问题转化成名词短语的识别问题。基于名词短语在小句中的语法功能来确定名词短语的边界,选择商务领域语料,采用了细化词性标注集和条件随机域模型结合语义信息的方法,识别了名词短语的边界和句法功能。在预处理基于宾州树库细化了词性标注集,条件随机域模型中加入语义特征主要用来识别状语类的名词短语。实验结果表明,结合金标准词性实验的F值达到了89.04%,改进词性标注集有助于提高名词短语的识别,比使用宾州树库标注集提高了2.21%。将功能名词短语识别信息应用到NiuTrans统计机器翻译系统,英汉翻译质量略有提高。
功能名词短语;名词短语识别;条件随机域模型;语义信息
1 引言
名词短语识别在句法分析中有着重要的作用,名词短语的识别可以降低句法分析的复杂性,提高机器翻译的性能和效率。英汉机器翻译的瓶颈之一就是名词短语的歧义消解问题,真实文本中存在的大量名词短语结构歧义是导致整句英汉机器翻译正确率较低的主要因素之一。人工翻译中看似简单的名词短语结构往往却在机器翻译中产生结构歧义。例如,n1+prep+n2结构。结合名词短语在小句中的句法功能,这一表层结构至少存在三种深层结构如下:
a. He likes the book on the table. (prep+n2结构“on the table”做后置定语)
b. He finds the book on the table. (prep+n2结构“on the table”做状语)
c. He puts the book on the table.(prep “on”是小品词,put…on…是固定搭配)
将句子输入到Google在线翻译系统,得到如下结果:
a. 他喜欢的书放在桌子上。(参考译文: 他喜欢桌子上的书。)
b. 他发现在桌子上的书。(参考译文: 他在桌子上找到了那本书。)
c. 他把书放在桌子上。(参考译文: 他把书放在桌子上。)
从前两个例句可以看出,在统计机器翻译中,往往把prep+n2简单处理为n1的后置定语,造成明显的翻译错误。因此专门针对机器翻译领域,研究英语名词短语的结构歧义及消歧方法,对提高机器翻译的效率,将起到关键作用。
目前的英语名词短语识别研究主要集中在基本名词短语和最长名词短语的识别。Church[1]利用统计方法进行名词短语的识别,Voutlainen[2]设计了名词短语识别系统NPTool,但是这两个系统识别的名词短语非常简单,甚至不包括名词前的修饰成分。Ramshaw 和Marcus[3]提出了基本名词短语的概念,把名词之前的修饰语包含在名词短语中。Koehn 和Knight[4]提出了最长名词短语的定义,把名词后的修饰语包含在名词短语中。这两种名词短语是根据名词短语的逻辑结构来定义的,如: 是否包括名词前和名词后的修饰语,而没有考虑名词短语的句法功能。文献[5]研究发现,这种定义方法在识别阶段易于识别,但是在翻译阶段会引起许多结构歧义。因此有必要融合结构和句法功能来定义名词短语,把对翻译要素的考虑提前到句法分析阶段,提高句法结构歧义的消歧率和机器翻译的质量。马建军和黄德根[6]基于系统功能语法获取名词短语在小句中的句法功能,根据句法功能界定名词短语的边界,并将这种名词短语定义为功能名词短语,初步论证了这种界定方法在机器翻译应用中的实际意义。
国内外英语名词短语的识别方法有很多,主要可分为两大类: 基于规则的方法和基于统计的方法。基于规则的方法主要指通过人工方法或人工结合机器学习的半自动方法获取规则,例如,基于转换的错误驱动学习方法[7]。基于统计机器学习的方法包括: 边界统计方法[1]、基于实例的方法[8]、基于粗糙集的方法[9]、基于决策树[10]、基于词频统计模型[11]、以及支持向量机方法[12-13]。从统计模型的角度看,主要有最大熵模型[14-16]、隐马尔可夫模型[17-18]、条件随机域模型[19-20]等。研究的趋势是综合多种不同的方法以及应用不同的统计模型来识别名词短语,如规则和边界统计相结合[21],最大熵和规则方法相结合[22],基于条件随机域和支持向量机的混合统计模型[23-24]。
因此,本文选择商务领域语料,采用了细化词性标注集和条件随机域模型结合语义信息的方法,进行功能名词短语的自动识别研究,不仅识别名词短语的边界,同时还识别名词短语的句法功能。
2 英语功能名词短语的定义
本文识别的功能名词短语是指由中心名词及其修饰语组成的短语。其结构为 “前置修饰语+名词+后置修饰语”。其中,前置修饰语可以是限定词、数词、形容词、或名词;名词包括普通名词、代词和专有名词;后置修饰语可以是介词或“介词+名词短语”结构或形容词;前置修饰语和后置修饰语不是必须的结构。基于系统功能语法[25],本文把名词短语在小句中的功能主要归纳为六类: S,C,C1/C2/C3/C4,D,PR,和CR。其含义如表1所示。
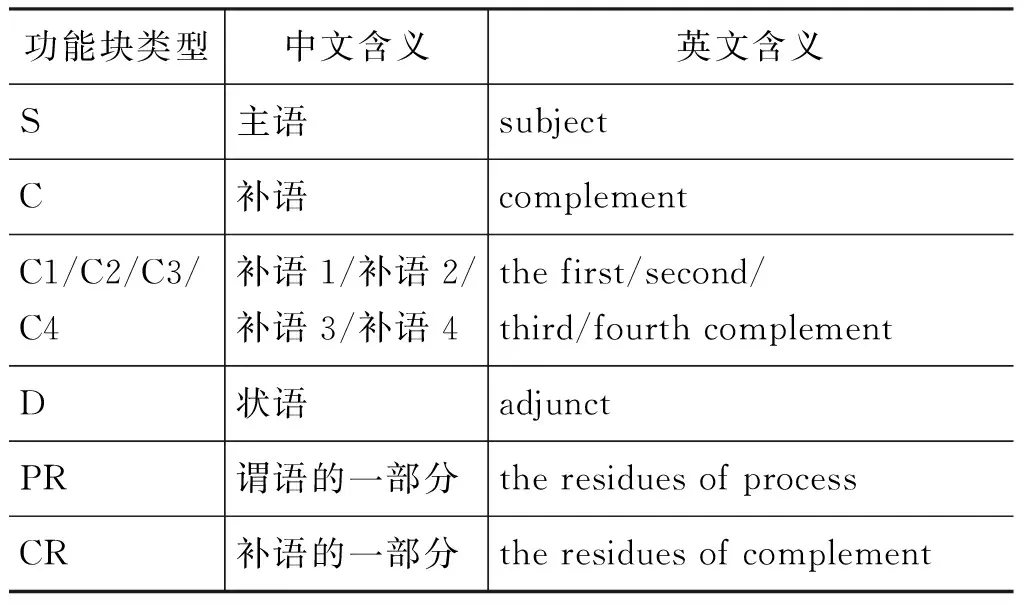
表 1 名词短语功能块标注集
具体例句如下:
a. [S A very clever traveling salesman] sold [C his complete stock of washing machines] [D the next day].
b. Please send [C1 us] [C2 all available data on your Hand Tools], enabling [C us] to introduce [C1 your products] to [C2 our customers].
c. If [S your products] are satisfactory and [S prices] are right, [S we] expect to place [PR regular orders for] [C large numbers].
3 标注训练语料
3.1 人工标注训练语料
本文所用的是自建的小型商务英语语料库[26]。由10 059个经过去重的英语句子及其中文翻译构成,包含14个类别,如: 询价及回复、运输、建立业务、还价、合同、包装、运输、付款、代理、索赔、订货、保险、报价和市场营销。根据功能块标注集对近20万词的英语语料进行了人工标注,语料库的语料信息如表2所示。
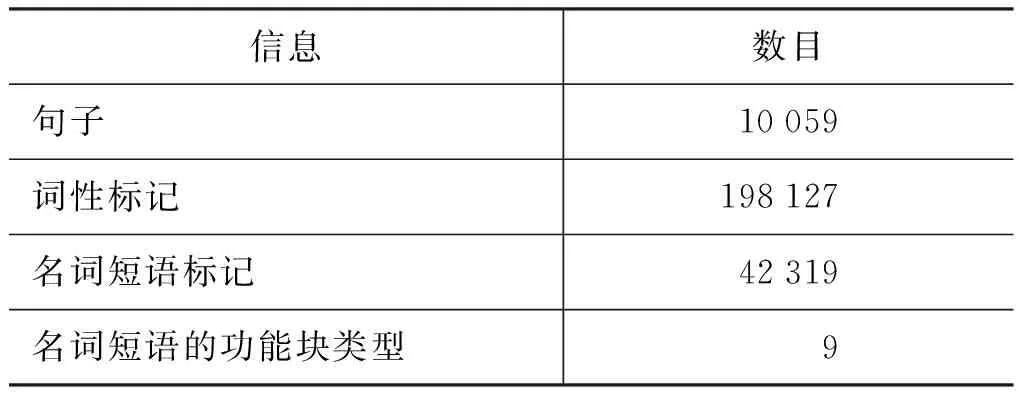
表 2 语料库信息
表3详细列举了名词短语功能块的分布情况。表3表明,语料中名词短语的句法功能归纳为九个: S,C,D,C1,C2,C3,C4,PR,CR。其中,主语(S)、补语(C)和状语(D)是名词短语在小句中的三个主要句法功能,一共占整个语料的近84%;而C3,C4和CR则出现频率很小,一共才占0.23%。值得注意的是,状语占15.83%,是名词短语识别的重点,因为不像主语和补语,状语往往包括那些诸如“for your reference”之类的以介词开头的名词短语,而不是以名词开头的名词短语。这些名词短语以介词开头,在识别中很容易被误认为是之前名词的后置定语,因而造成识别错误,对机器翻译带来结构歧义问题。
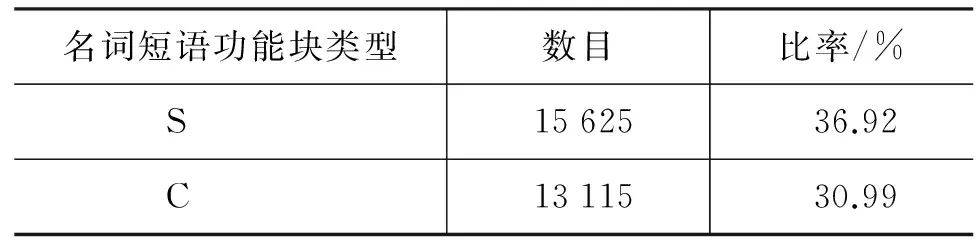
表 3 名词短语功能块的分布
续表
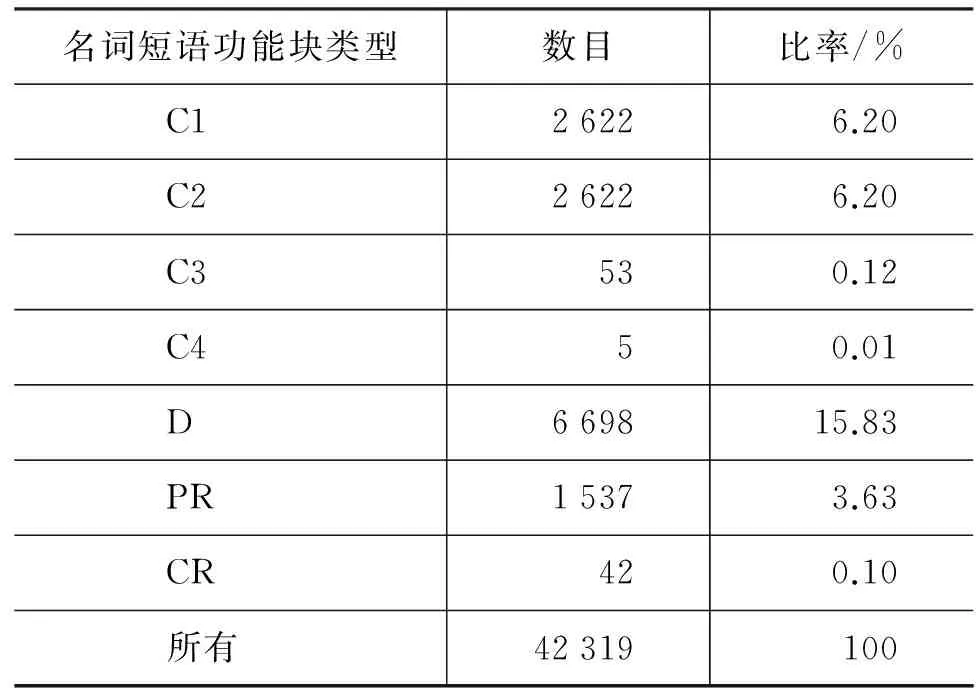
名词短语功能块类型数目比率/%C126226.20C226226.20C3530.12C450.01D669815.83PR15373.63CR420.10所有42319100
3.2 IOB2标注方法
在实验中,将名词短语的识别任务转化为序列标注任务。采用IOB2的标注方法,对名词短语块的边界进行标记,从而把块分析问题转化为序列标记问题。标记B表示当前词是名词短语的首词,标记I和标记O分别表示当前词属于名词短语内还是名词短语外。同时,标记I和标记B还同名词短语的句法功能结合起来,如: B-S表示当前词是名词短语的开始,该名词短语的句法功能是S(主语)。具体范例见表4。
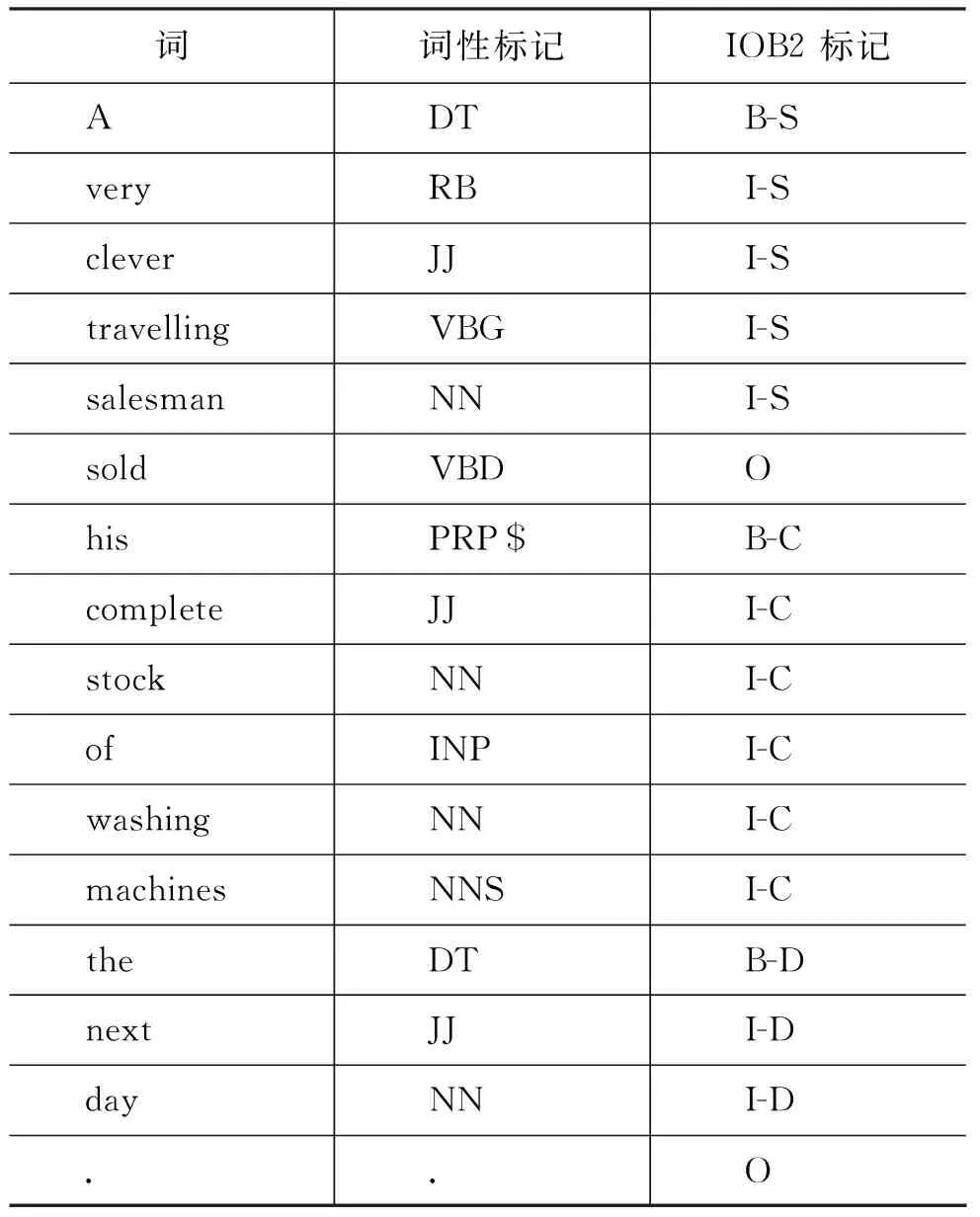
表 4 IOB2标注方法范例
4 研究方法
4.1 CRFs的识别模型
本文将功能名词短语的识别问题转化为序列标注问题,利用条件随机域建立功能名词短语的序列标注模型。本文介绍的条件随机域模型是比较简单的线性链条件随机域,给定参数Λ=(λ1,λ2,…,λn),线性链条件随机域定义在一个给定的观测序列X=(x1,x2,…,xn)上对应的状态标记序列Y=(y1,y2,…,yn)的条件概率为式(1)。
其中ZX是所有状态序列的归一化因子,使得在给定输入上所有可能状态序列的概率之和为1。fk(yt,yt-1,X,t)通常被定义为关于整个观测序列和位置t以及位置t-1标记的二值特征向量函数,参数λk是在训练中得到的与特征函数fgk相关的权重,当训练状态序列被完全明确地标记后,可为该模型找到最优的λ值,一旦这些值被找到,一个新的未标记序列的标记工作就可以用Viterbi算法来完成,k的取值范围取决于模版中特征的数量。那么求解序列标注的任务就是求出使条件概率PΛ(Y|X)最大的Y,即最大可能的标记序列为式(2)。
条件随机域模型识别名词短语的关键在于特征的选择,特征的选择恰当与否会对识别结果产生直接的影响。通常来讲,丰富的上下文特征对于识别精确率的提高有着积极的作用。本文在进行特征选择的时候,不仅充分利用了词和词性本身的信息,考虑到词和词性及其上下文之间存在着的种种依赖关系,还利用了融入更多上下文信息的组合特征。在实验中,本文选择了三种主要特征: 当前词、当前词的词性以及组合特征。表5为条件随机域模型所采用的特征模板,其中wi代表词本身特征,ti代表词的词性特征,其他特征为词和词性的组合特征。特征模板描述如下。
(1) 前后各三个词的词语和词性特征;
(2) 相邻两个词的词性组合特征;
(3) 次相邻两个词的词性组合特征;
(4) 当前词的词性分别与前、后词的词语组合特征;
(5) 相邻两个词的词性组合特征再分别与其正对应窗口为四的词语组合特征;
(6) 后两个词的词性组合特征再分别与当前词、前词的词性组合特征。
其中,最后两条特征是通过大量的特征选择实验总结得出的对结果有较大影响的特征组合。利用表5中的特征模板,将给定的训练语料拿到CRFs上进行训练,再用训练得到的名词短语识别模型对测试语料进行标注,最后得到功能名词短语的识别结果。

表5 条件随机域模型的特征模板
4.2 CRFs结合语义信息
通过大量的语言现象可以发现,一些“介词+名词”搭配的短语对于提高功能块的标注效果有积极的作用,如for your reference为标注整个句子的组块标记提供了重要的信息。为了进一步利用这种固定搭配短语的特征,本文进一步引入语义信息,即用语义类来代替固定搭配中的名词部分,这样一定程度上减少了数据稀疏的影响(具体见表6)。
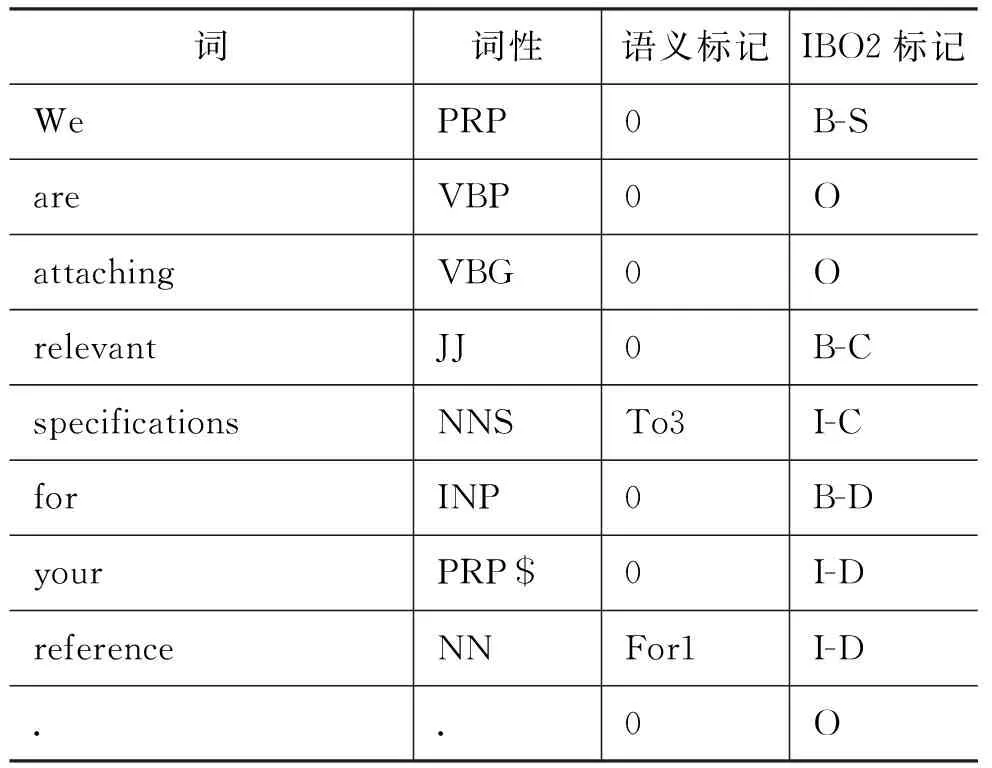
表 6 带语义信息的功能名词短语标注举例
本文的语义信息是从词典《柯林斯COBUILD英语语法句型2: 名词与形容词》[27]中人工抽取形成的。每个名词只赋予一个语义标记,若超过一个,则选择出现频率最高的情况,另外对于不在词典中的词则统一用数字0来标识。表7以“for + N”搭配为例说明了语义分析的结果。当引入语义后,一些低频的搭配短语可以聚集在一起。例如,for your reference(供您参考)和for your consideration(供您决定)可以分类为“for + N”的搭配中,同时,reference和consideration根据语义还可以进一步分类为“USE”类。这样reference和consideration就属于相同的语义类: For/USE 组,并赋予相同的语义标记: For1。

表 7 名词语义信息列表
此时,在CRFs模型中引入固定搭配特征。通过观察可以发现,一个搭配短语对于标记短语中的每一词的BIO状态,以及前词后词的BIO状态有重要的提示作用。因此,为了捕获这些搭配短语的信息,需要在位置t位于搭配短语中时,启动特征抽取过程。对于前词和后词的位置并不需要这样,因为它们的标记可以通过fk(yt,yt-1,X,t)来影响其标注。依旧以表6为例,抽取到的特征如下所示:
当t指向for时: s1=F or 1
当t指向your时: s2=F or 1
当t指向reference时: s3=F or 1
其中,s的下标指示当前词在短语中的位置,等式右边为短语的语义标记。
利用结合语义信息的CRFs模型进行了预实验,主要关注功能块状语D的识别。将英文语料按照商务情景分成七组,每组任意抽取300句,共2 100句子作为测试语料,其余7 959句子作为训练语料。评价指标包括功能名词短语的准确率(Precision,P)、召回率(Recall,R)和F值(F-1 measure,Fβ=1)。具体计算公式如式(3)~(5)所示。
功能块D识别结果如表8所示。结果表明,加入语义信息后,识别结果有所提高,准确率、召回率和F值分别提高了3.76%、4.56%和4.16%。
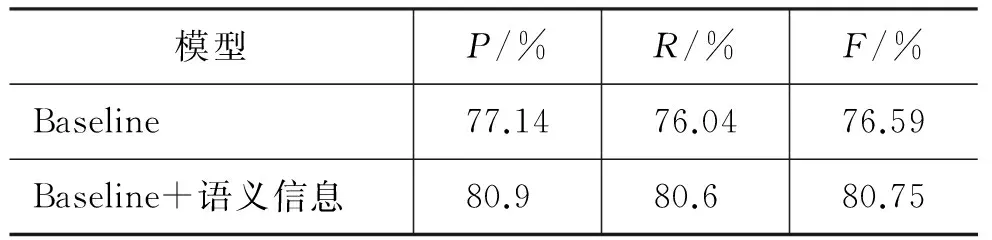
表 8 功能块D标注结果
4.3 预处理
预处理进行了词性标注。为了提高名词短语识别效果,本文面向机器翻译的目的在宾州树库词性标注集[28]的基础上构建了本文的词性标注集。具体改进方法如表9所示,主要在四个方面进行了细化,包括: 区分介词和从属连词;增加了功能词it, for, by,如: It/IT is dangerous for/FOR children to walk alone in the forest中的it和for;区分单词to的不同功能;定义小品词的广义定义,即与动词构成短语动词的介词或方位副词,包括如: He informed Barbara of/RP his objections.中的of,而这个小品词在宾州树库中标注为介词IN[26]。
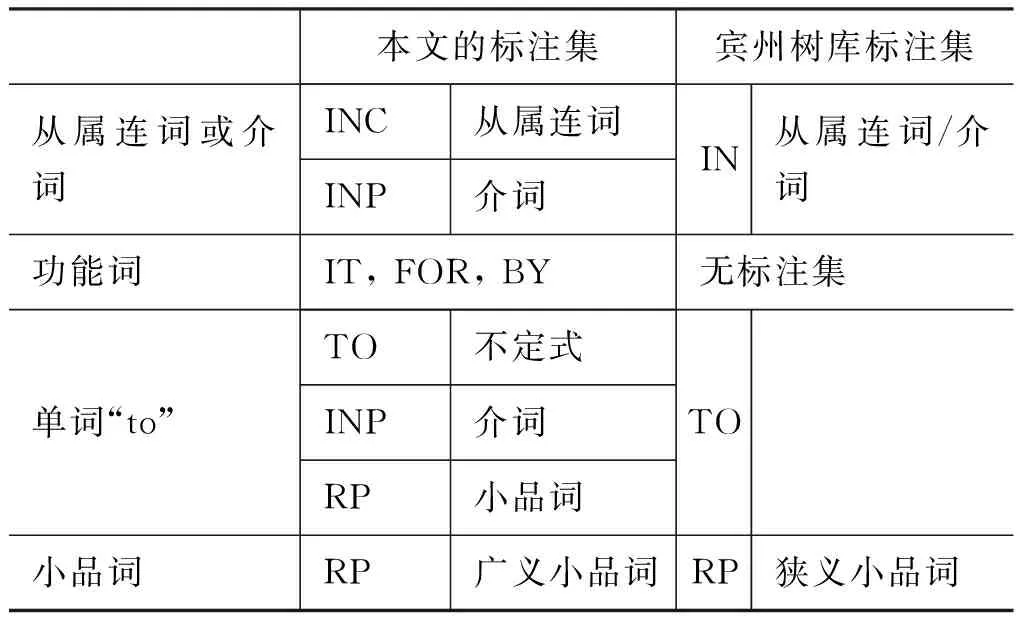
表 9 两个标注集的比较
5 实验结果及分析
5.1 封闭测试和开放测试实验结果
应用CRFs结合语义信息和规则的方法进行了封闭测试和开放测试,开放测试采用五重交叉验证方法,分别进行了结合金标准词性标记(gold standard POS tags)和结合实际输出的词性标记两种实验。为检验本文的词性标注集在功能名词短语识别中的作用,在开放测试中还选择了斯坦福标注器的词性标记来取代本文的词性标记,分别进行了上述两种相同的实验。实验结果如表10所示。
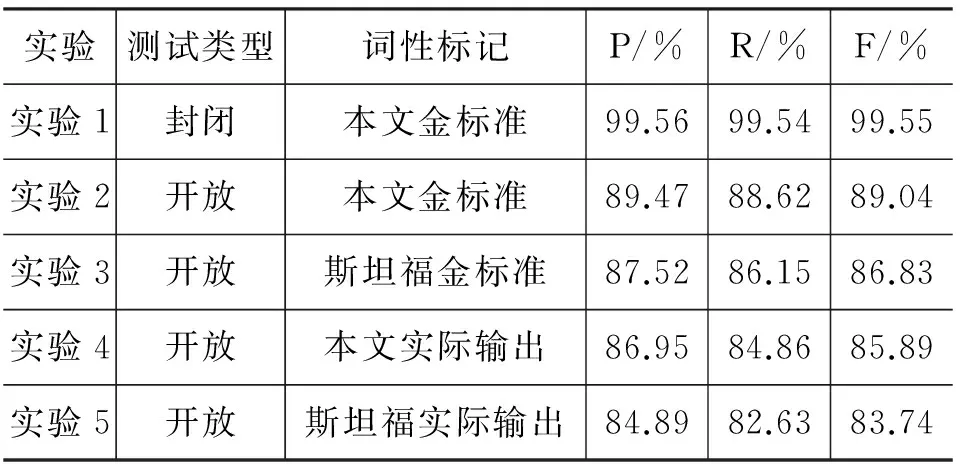
表10 名词短语识别结果
实验1的结果表明,封闭测试识别的准确率达到99.56%,召回率达到99.54%,F值达到99.55%。实验2和实验3 结合金标准词性标记进行了五重交叉实验,分别基于本文的词性标注集和宾州树库词性标注集,基于宾州树库标注集的金标准词性标记是通过斯坦福词性标注器标注后,人工修订标注结果得到的。根据表10,使用本文的词性标注集的识别结果要好于使用宾州树库词性标注集。使用本文的金标准词性标记准确率达89.47%,召回率88.62%,F值达到89.04%,这个结果比使用宾州树库词性标注集的结果分别提高了1.95%、2.47%和2.21%。实验4和实验5结合实际输出的词性进行了实验。将实验4和实验5的结果分别同实验2和实验3的结果进行比较,结果表明,无论是采用本文的词性标注集,还是采用宾州树库词性标注集,使用实际输出的词性标记的识别结果低于使用金标准词性结果,准确率低近2.5个百分点,召回率和F值的差值都超过了3个百分点。这说明,需要提高词性标注器的标注效果,从而为名词短语的识别提供更好的支持。另外,同实验2和实验3的结果一样,采用本文的实际词性标记的识别结果仍然高于采用斯坦福词性标记的识别结果,这也说明了选择词性标注集对名词短语的识别有一定的影响。
5.2 六种功能块识别结果
表11比较了结合金标准词性的两个试验中(实验2和实验3),六种名词短语功能块S,C,D,PR,C1,C2的识别结果,识别结果用平均值表示。没有比较功能块C3,C4和CR的识别结果,是因为名词短语以这三种功能块出现的频率较小,在语料中分别占0.12%、0.01%和0.10%(见表3)。从表11可以看出,几乎在所有六种功能块的识别中,使用本文的词性标注集的识别结果都好于使用宾州树库标注集。仅有一种情况除外,即结合斯坦福金标准词性的PR的召回率(74.93%)略高于结合本文的金标准词性的召回率(74.75%)。但是在其他所有情况,无论是准确率还是召回率和F值,都是基于本文的词性标注集的结果好。此外,表11还表明在结合本文的金标准词性标记的实验中,S,C,C1的识别结果要比D,PR,C2好得多。S的识别结果最好,F值达到97.46%;而D的识别仍然是研究的难点,F值为79.47%。所以,状语D的识别问题值得进一步研究[26]。
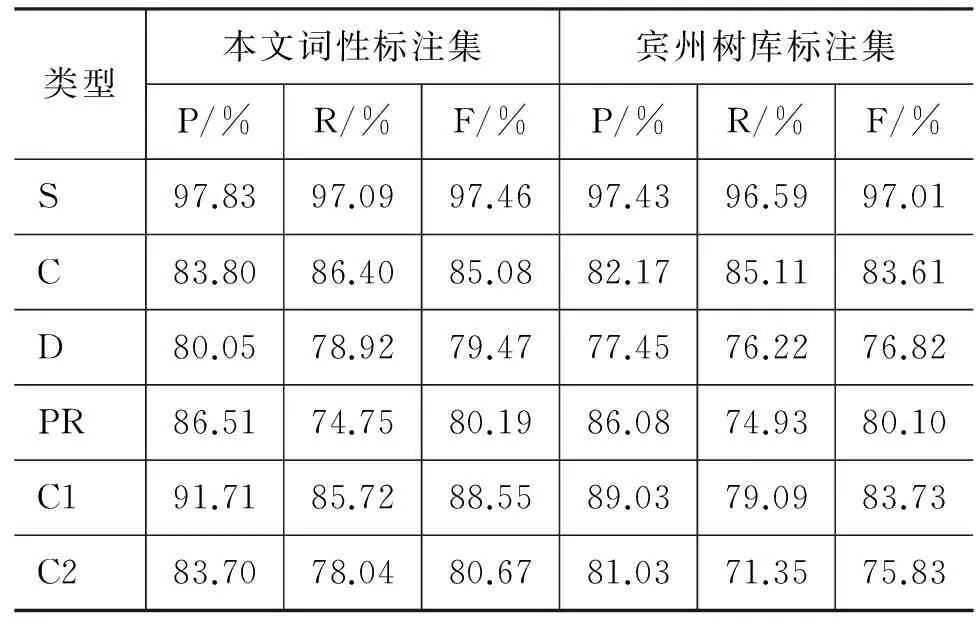
表 11 功能块识别结果
5.3 在统计机器翻译中的应用
将功能名词短语信息应用到NiuTrans统计机器翻译系统中,以检验功能名词短语识别对机器翻译质量的影响。随机选择2 000英汉句对作为测试语料,其余8 059句对作为训练语料,应用NiuTrans统计机器翻译系统构建英汉机器翻译baseline;然后将英语功能名词短语的句法信息作为特征加入到生成的短语表。比较两次翻译的BLEU值,结果见表12。结果表明: 翻译结果略有提高,BLEU值从9.87%提高到10.42%,提高了0.55%。
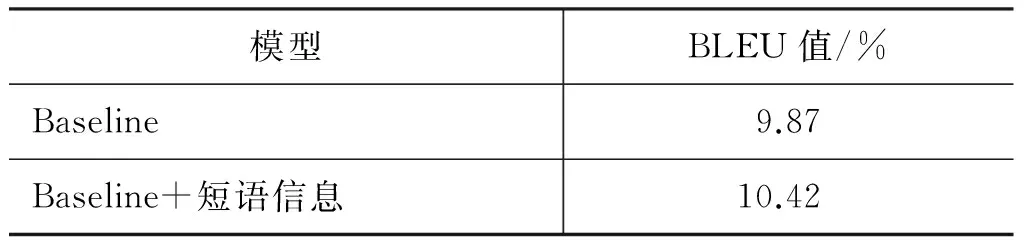
表 12 统计机器翻译结果
6 结论
本文改进了词性标注集,采用了CRFs结合语义信息的方法识别英语功能名词短语。实验结果表明:
(1) 使用CRFs结合语义信息的方法能有效识别英语功能名词短语,使用本文的金标准词性标记准确率达89.47%,召回率88.62%,F值达到89.04%。
(2) 细化词性标注集有助于提高功能名词短语的识别。结合金标准词性标记的开放测试结果表明,使用细化的词性标注集比使用宾州树库标注集F值提高了2.21%。结合实际输出的词性标记的开放测试也表明,采用细化的实际词性的识别结果仍然高于采用斯坦福词性的识别结果,F值提高了2.15%。
(3) 功能名词短语识别的主要问题集中在作状语的名词短语识别方面。
(4) 在统计机器翻译系统中加入功能名词短语识别信息,略微提高了英汉机器翻译的质量,BLEU值提高了0.55%。
功能名词短语识别可以应用到机器翻译的研究中,因为识别这类名词短语能够在识别阶段就解决了名词短语结构歧义问题,把名词短语的结构消歧问题转化成名词短语的识别问题。如果这类名词短语在识别阶段能够较好地识别出来,就能够在一定程度上提高机器翻译的质量。
[1] Church K. A Stochastic Parts Program and Noun Phrase Parser for Unrestricted Text[C]//Proceedings of Second Conference on Applied Natural Language Processing. Austin, USA: Association for Computational Linguistics, 1988: 136-143.
[2] Voutilamen A. NPTool, A Detector of English Noun Phrases[C]//Proceedings of the Workshop on Very Large Corpora: Academic and Industrial Perspectives. Columbus, USA: Association for Computational Linguistics, 1993: 48-57.
[3] Ramshaw L, Marcus R. Text Chunking using Transformation-Based Learning[C]//Proceedings of the Fourth Workshop on Very Large Corpus. Copenhagen, Denmark: Association for Computational Linguistics, 1995: 82-94.
[4] Koehn P, Knight K. Feature-Rich Statistical Translation of Noun Phrases[C]//Proceedings of the 41st Annual Meeting of the Association for Computational Linguistics. Sapporo, Japan: Association for Computational Linguistics, 2003: 311-318.
[5] 马建军. 基于规则和统计的机器翻译方法歧义问题比较分析[J].大连理工大学学报(社会科学版), 2010, 31(3): 114-119.
[6] 马建军,黄德根.英语功能名词短语的研究及其应用[J].大连理工大学学报(自然科学版), 2012, 52(1): 126-131.
[7] Brill E. Transformation-based error-driven parsing[C]//Proceedings of the Third International Workshop on Parsing Technologies. Tiburg, Netherlands: Association for Computational Linguistics, 1993: 13-16.
[8] Veenstra J, Buchholz S. Fast NP Chunking Using Memory-Based Learning Techniques[C]//Proceedings of the Eighth Belgian-Dutch Conference on Machine Learning. Wageningen, Netherlands: Wageningen ATO-DLO, 1998: 71-78.
[9] 郭永辉,杨红卫,马芳,等. 基于粗糙集的基本名词短语识别[J]. 中文信息学报, 2006, 20(3): 14-21.
[10] 李生, 孟遥. 基于决策树的英语BNP识别[J]. 黑龙江工程学院学报, 2001, 15(1): 36-39.
[11] Kong L, Ren F, Sun X. et al. Word Frequency Statistics Model for Chinese Base Noun Phrase Identification[C]//Proceedings of the 10th International Conference on Intelligent Computing (ICIC). Taiyuan, China: Springer International Publishing, 2014: 635-644.
[12] Kudo T, Magsumoto Y. Chunking with support vector machines[C]//Proceedings of NAACL-2001. Pittsburgh, USA: Association for Computational Linguistics, 2001: 192-199.
[13] Wu Y C, Lee Y S, Yang J C. Robust and Efficient Multiclass SVM Models for Phrase Pattern Recognition[J]. Pattern Recognition, 2008(41): 2874-2889.
[14] Koeling R. Chunking with Maximum Entropy Models[C]//Proceedings of CoNLL-2000 and LLL-2000. Lisbon, Portugal: Association for Computational Linguistics, 2000: 139-141.
[15] 周雅倩, 郭以昆, 黄萱菁,等. 基于最大熵方法的中英文基本名词短语识别[J]. 计算机研究与发展, 2003, 40(3): 440-446.
[16] 王晓娟, 赵春. 最大熵方法在英语名词短语识别中的应用研究[J]. 计算机仿真, 2011, 28(3): 414-417.
[17] Molina A, Pla F. Shallow Parsing using Specialized HMMs[J]. Journal of Machine Learning Research, 2002(2): 595-613.
[18] Shen H, Sarkar A. Voting between Multiple Data Representations for Text Chunking[C]//Proceedings of the Eighteenth Meeting of the Canadian Society for Computational Intelligence, Canadian AI. Victoria, Canada: Springer Berlin Heidelberg, 2005: 389-400.
[19] Sha F,Pereira F. Shallow Parsing with Conditional Random Fields[C]//Proceedings of HLT-NAACL 2003. Edmonton, Canada: Association for Computational Linguistics, 2003: 213-220.
[20] Sun X, Morency L P, Okanohara D et al. Modeling Latent-Dynamic in Shallow Parsing: A Latent Conditional Model with Improved Inference[C]//Proceedings of the 22nd International Conference on Computational Linguistics. Manchester, UK: Association for Computational Linguistics, 2008: 841-848.
[21] 梁颖红,赵铁军,翟舒. 规则和边界统计相结合的英语基本名词短语识别[C].全国第七届计算语言学联合学术会议论文集. 哈尔滨, 中国: 中文信息学会,2003: 173-178.
[22] 吕琳,刘玉树. 最大熵和Brill方法结合识别英语BaseNP[J]. 北京理工大学学报, 2006, 26(6): 500-503.
[23] 谭魏璇, 孔芳, 倪吉,等. 基于混合统计模型的中文基本名词短语识别[J]. 计算机应用与软件, 2011, 28(8): 254-156.
[24] 钱小飞, 侯敏. 基于混合策略的汉语最长名词短语识别[J]. 中文信息学报, 2013, 27(6): 16-22.
[25] Halliday M A K. 功能语法导论[M]. 北京: 外语教学语研究出版社, 2008.
[26] 马建烟. 面向机器翻译的英语功能名词短语识别研究[D].大连:大连理工大学,2012.
[27] Sinclair J. 柯林斯COBUILD英语语法句型2: 名词与形容词[M].上海: 上海外语教育出版社, 2000.
[28] Marcus M P, Santorini B, Marcinkiewicz M A. Building a large annotated corpus of English: the Penn Treebank[J]. Computational Linguistics, 1993, 19(2): 313-330.
Identification of English Functional Noun Phrases by CRFs and the Semantic Information
MA Jianjun1, PEI Jiahuan2, HUANG Degen2
(1. School of Foreign Languages, Dalian University of Technology, Dalian, Liaoning 116024, China ;2. School of Computer Science and Technology, Dalian University of Technology, Dalian, Liaoning 116024, China)
The study on the automatic identification of English functional noun phrases (NP) may transform the task of resolving structural ambiguity caused by noun phrases into the task of NP chunking. Functional noun phrases refer to those noun phrases which are defined based on their syntactic functions in clauses. On a corpus of business domain, this study aims to identify both the scope of NP chunks and their syntactic function types by refining the Part-of-speech (POS) tagset, and adopting conditional random fields (CRFs) model combined with the semantic information. Modification to the Penn Treebank tagset is completed in the pre-processing, and semantic features are added to the CRFs model to improve the recognition of the adjunct types of noun phrases. Test results show that the system has achieved an F-score of 89.04% in the open test using our gold standard tags; and refining the POS tagset is a better approach for NP chunking, which has increased the F-score by 2.21%, compared with the model using the Penn Tree bank POS tags. This knowledge of English functional noun phrases is then combined with the NiuTrans SMT system, which slightly improves the English Chinese translation performance.
functional noun phrases; noun phrase identification; CRFs; semantic information

马建军(1972—),教授,主要研究领域为句法分析、机器翻译。E-mail:majian@dlut.edu.cn裴家欢(1992—),博士研究生,主要研究领域为句法分析、查询时间意图分类和句子相似度计算。E-mail:p_sunrise@mail.dlut.edu.cn黄德根(1965—),教授,主要研究领域为自然语言处理、机器翻译。E-mail:huangdg@dlut.edu.cn
1003-0077(2016)06-0059-08
2016-09-27 定稿日期: 2016-10-20
教育部人文社会科学研究规划基金(13YJAZH062)
TP391
A
