细粒度与可视化的“比”字句分析模型及计算应用
2016-06-01朴敏浚袁毓林
朴敏浚,袁毓林
(北京大学 中文系 中国语言学研究中心 计算语言学教育部重点实验室,北京 100871)
细粒度与可视化的“比”字句分析模型及计算应用
朴敏浚,袁毓林
(北京大学 中文系 中国语言学研究中心 计算语言学教育部重点实验室,北京 100871)
针对现有五元组比较句语义要素框架的缺陷,该文引进了提升语义分辨率的七元组语义要素分类模板。在此基础上建立了一个可视化的“比”字句结构分析模型,用以总结出比较对象之间的三种对应模式,并确立了判定“不对称比较”的形式标准。该文的可视化分析模型可以明确阐述“比”字句内部的多重述谓结构,有助于获取容易被忽略或认错的隐含成分及比较关系。而且,它立足于谓词逻辑的基础形式,所以与OWL本体语言相兼容。作为模型的应用实践,该文还建设了小规模知识本体(ontology),演示了“比”字句语义要素的自动识别过程。
“比”字句;语义要素;比较关系;细粒度;可视化;知识本体
1 引言
人们能用各种方式对事物进行评价,其中“比较”是显著的评价方法之一。在表示比较意义的句型中,“比”字句是汉语比较句中最为典型的句型。从《马氏文通》[1]开始,汉语语法学界在比较范畴定界[2-5]、句法和语义限制[6-8]以及个别句型描述方面[9-10]进行了全面、系统的研究。与这些研究把“比”字句视为独立的研究对象不同,自然语言处理(NLP)方面的相关研究多把“比”字句作为信息抽取(IE)总体性任务的一种实验对象。从Jindal和Liu[11-12]对英文比较句识别研究开始,比较句自动识别与其关键要素提取成为了观点挖掘(opinion mining)与情感分析(sentiment analysis)的主要任务之一,不少研究展现了机器学习[13-15]、模式匹配[16-17]等新方法,推动了国内此领域的发展。但是,这些研究的重点在于工程应用方面,比如在网络商品评论中说话人的观点与评价对象的识别,因此其研究动机和重点自然不同于以结构和语义分析为宗旨的传统语言学研究。
尤其是当基于统计的机器学习方法在计算语言学研究中成为普遍的研究路线之后,传统语言学与自然语言处理之间的鸿沟也随之扩大。但是,传统语言学所重视的对结构和语义的深入分析依然具有其必要性,因为语言学驱动的知识可以弥补现有“比”字句关键要素抽取模型的不足*COAE 2013 任务2.2(比较句关键要素提取)跟其他任务相比,成绩较低(最佳F值仅为0.35)[18]。。例如,“我比你大”、“我年龄比你大”、“我眼睛比你大”中,谓语的陈述对象“我”、“年龄”、“眼睛”属于不同的语义类,分别代表不同的比较侧面;“A车比B车贵”和“A车比B车高”虽然体现在同一格式里,但其信息透明度又不同(后者“高”可以指“车高、价格、性价比”等)。这种差异主要是“比”字句述谓结构内部多重句法、语义关系所引起的。因此,“比”字句基本述谓结构的深入分析,这是理论语言学与自然语言处理两方面的研究需求互相交叉的部分。可是,这方面的研究成果尚显不足,有待进一步发展。
2 细粒度的“比”字句语义要素框架
比较句可以定义为一个由比较主体(SUB)、比较客体(OBJ)、比较点(ATT)、比较结果(RES)和比较标记(BI)组成的五元组(quintuple):
C=< SUB, BI, OBJ, ATT, RES >
目前多数比较句识别模型都是在上述基础上对“比”字句进行分析[13-17]。在语言学研究中[8] [19-22]也可发现类似的比较句要素分类,如比较主体X、比较客体Y、比较结果W以及比较点G。其中“比较点(ATT)”往往被定义为一个单一的范畴: 比较双方共有的,谓语所陈述的对象。然而,我们认为这个定义对“比”字句要素的识别和抽取来说不够精密,会错失相当多的语言学方面的启发性特征。例如,
例1 这车子发动机噪音明显比花冠大。
这车子 发动机 噪音 比 花冠 大
SUB ATT BI OBJ RES
例2 东西你比我好,价钱我比你便宜。
东西 你 比 我 好
ATT SUB BI OBJ RES
价钱 我 比 你 便宜
ATT SUB BI OBJ RES
基于五元组的上述分析框架存在两项不足。第一,比较点(ATT)的内部语义范畴不均匀。在例1“发动机噪音”中,“发动机”是一种物体(object),“噪音”则为属性(property);例2“东西”与“价钱”在语义上也不一样,有物体(有独立性)与属性(有依附性)之别。但现有的五元组分析框架把它们放在同一个层次(比较点)上处理。
这种内部不一致的分类就造成五元组分析中第二个难点,即无法识别“比较对象—比较属性—比较结果”之间所隐含的复杂的配位关系。具体来说,例2的“价钱”不是比较对象“我(或你)”的比较点,而是“东西”的比较点。然而,五元组分析框架用同一个比较点(ATT)来概括“价钱”与“东西”,忽略了“我—东西—价钱”之间的多重配位关系。
因此,我们对这一组合进行细化和补充,得出以下的七元组(septuple):
C=< SUB, BI, OBJ, ITM,DIM, RES, ENV >
例1’ 这车子发动机噪音明显比花冠大。
这车子 发动机 噪音 比 花冠 大
SUB ITM DIM BI OBJ RES
例2’ 东西你比我好,价钱我比你便宜。
东西 (质量) 你 比 我 好
ITM DIM SUB BI OBJ RES
价钱 我 比 你 便宜
DIM SUB BI OBJ RES
可见,七元组分类框架有效改善了五元组分析方法的不足。通过提高比较点(ATT)的语义分辨率,七元组能够更好地识别比较属性(dimension, DIM)与比较结果(result, RES)之间的关系,比如找出例2’所隐含的DIM“质量”。这种细分有助于网络商品评价系统,因为例2将比较点与比较项混为一谈的错误是对比较句述谓结构的多重句法、语义关系分析不精细所致。
上述“比”字句的语义要素总结为如下:
比较对象(SUB和OBJ): 参与比较的两个实体(entity),通俗地说“谁跟谁比”。其中,比较主体(SUB)通常是先出现的成分,故又称为“比较前项”。它是谓语(比较结果,RES)的描述对象;比较客体(OBJ)则是“比较后项”,语义上充任比较的基准。
比较点(ITM和DIM): 比较可以理解为在两个实体中同中见异,或异中见同的过程[2]。因此,句中往往出现比较对象SUB和OBJ共有的部分,就是所谓的“比较点”。通俗地说,它们相当于“比什么”。语义上比较点只能依附于比较对象而实现,所以它们之间形成两种关系: (i) 整体—部分关系(meronymic relation)以及 (ii) 整体—维度关系(dimensional relation)。比较项目(ITM)代表前者,比较属性(DIM)则表示后者关系。
比较结果(RES): 句法上充当谓语*在句法功能上,RES一般充当谓语核心(形容词谓语时)或谓语修饰成分(动词谓语时)。,表达比较对象在比较点上的不同*另外,作为比较结果(RES)的附属成分,比较量幅(EXT)表示比较对象在量度上的差值。为了模型的简洁性,本文省略了这一可选成分。详见朴敏浚等[19]。。
比较词(BI): 比较句的显性标记。本文中皆指“比”字句标记介词“比”。
比较环境(ENV): 比较对象的上位范畴,通俗地说“同中见异”的“同”。该范畴的设定适宜于分析特殊句型(§3.1 C类句型)。
例3 宝来的刹车系统反应比307好。
宝来 刹车系统 反应 比 307 好
SUB ITM DIM BI OBJ RES
例4 地球的北半球要比南半球细长一些。
地球 北半球 比 南半球 长一些
ENV SUB BI OBJ RES EXT
为了降低分析的复杂度,接下来本文提出一个基于谓词逻辑式的可视化模型。
3 基于谓词逻辑式的“比”字句分析模型
“比”字句所表达的意义能刻画为由几种简单的语义合成的表达式。
(A1) 我比他高(图1)。

图1 A类
“比”字句的意义可表达为各个比较关键要素之间的映射关系。“比”字句中的映射关系涉及两个部分: 一是“比较对象(谁跟谁比)”,表达为从OBJ到SUB的函数C(y);二是“比较结果”,表达为从SUB到DIM的函数P(x)。
据此,图1中的概念映射图可解释为: i) 以OBJ为基准,比较项“我”和“他”在比较对象函数C(y)的引导下形成比较双方SUB和OBJ的对比。ii) 同时,SUB“我”是谓词P“高”的论元。这个比较结果函数P(x)的值域是比较属性(DIM),并且P高的隐含属性是“个子*一些读者或许会感到质疑: 为何“个子”不属于比较项X、Y,而分开设置为独立范畴DIM,这是因为我们可以设想“我的个子比你的个子高”。但是,理论上DIM“个子”是共相(universal),而不是比较项“我、你”下位的殊项(particulars),因此“个子”有别于例(B1)中ITM“书”指殊相。另外,这里也存在实践上的理由,(A1)并不蕴含“他高”,所以谓语P高只能连接于“我”。如果“个子”同时包含于比较项X、Y,就不宜于描述该细节。”。
3.1 比较对象的配对方式
上述A类是比较双方处于语义上同位层次,形成狭义同构(相关例句详见附录,例A1-A10)。但在真实文本中出现大量比A类更加复杂的情况,比如以下的B类(ITM出现)和C类(ENV出现)。
B类是在同位的比较双方之下,比较双方所共有的部分(ITM)再次出现。例如,
(B1) 我的书比他多(图2)。
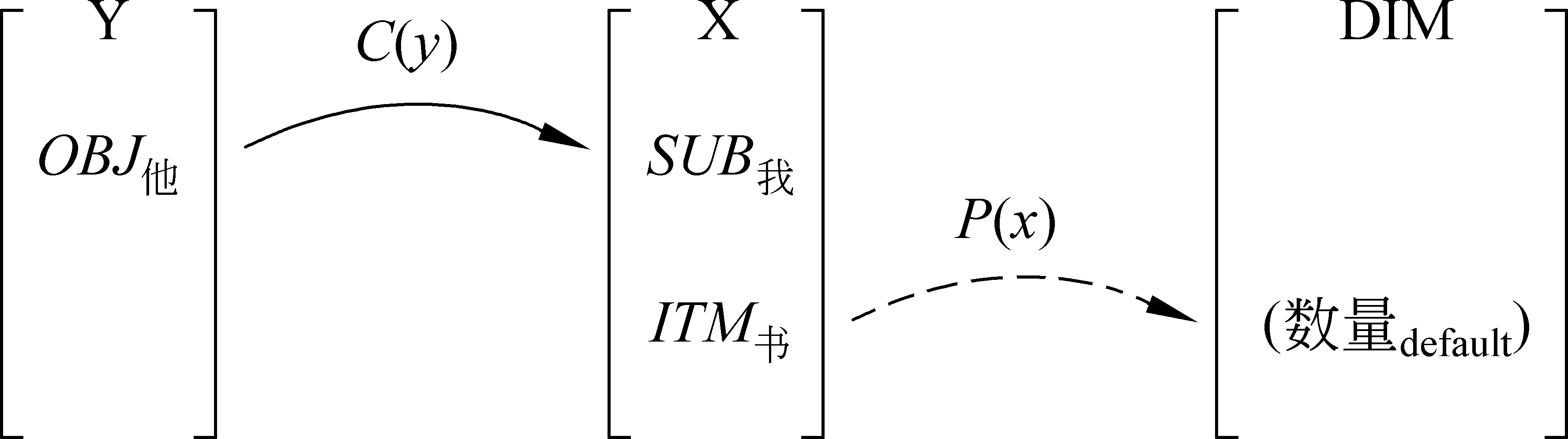
图2 B类(ITM出现)
图2中,OBJ“他”通过比较对象函数C(y) 映射到SUB“我”,因而形成比较项对立。与A类的情况不同,比较结果函数P多的定义域不是SUB“我”,而是其所领有的成分ITM“书”*值得注意的是,(B1)“我(的)书比他多”所比较的是“人”;(A5)“我的书比他的多”所比较的是“书”(朱德熙[20]: 190)。(A5)的映射关系应如下: (A5)我的书比他的多。。从图2与图1的对比可以发现,B类的比较项与A类不同,它采取了两层结构,以此突出ITM(比“什么”)。(相关例句详见附录,例B1-B10)

下面,C类“比”字句的比较项也是多层结构,但是C类的比较双方之间不存在任何ITM(比“什么”)。如果说A、B类是对两种不同的事物进行比较,那么C类则是对同一事物的不同方面进行比较。本文沿用刘焱“比较本体”概念*刘焱[21]发现C类存在新的语义范畴,即比较项的领有者“比较本体(Owner)”。作为比较的初始对象,比较本体是作为话题出现的,是有定的,是先于比较而存在的,这样能够使交际双方顺利和有效展开话题(p.80)。,设定了涵盖比较双方SUB与OBJ的概念范畴“比较环境(ENV)”。ENV是C类特有的语义成分。例如,
(C1) 地球的北半球要比南半球细长一些(图3)。

图3 C类(ENV出现)
比较环境(ENV)经常由时间、处所成分充当。
由于时空是世界万物存在上脱离不开的基本背景,因此它们先于比较项出现,提供SUB和OBJ的比较环境(environment, ENV)。
综上所述,“比”字句的比较对象的组织方式可总结为以下三类(图4)。

图4
在七元组分析框架中,比较双方之间的关系则以比较前项Y为定义域,X为值域的一种函数来表达。在一一对应函数的定义上,定义域Y中的任何元素必须映射到一个值,因此比较前项X总是大于或等于后项Y。这项限制符合李临定[6]的简略式规律: “比”前项要大于或等于后项,而不能小于后项。
值得注意的是,关于比较对象的对称与不对称的判断标准。如果我们从X、Y两种集合大小(|X|、|Y|)的角度来判断其对称与否,那A类是“对称”比字句;B、C类则是“不对称”比字句[4,22-23]。可是,从比较对象函数C的映射(SUB=C(OBJ))与否的角度判断其对称性的话,那么上述A、B、C类都可看成“对称”的。刘焱[21]坚持这种看法,她认为“比”字句的“对称”是“句法—语义”的对称,不是纯形式的对称。利用七元组分析框架就能够明确地可视化(visualize)这两种不对称定义的分歧,以更直观地理解比较对象之间的复杂层级关系。
(B2) 蔬菜的价格比上海贵(图5)。

图5 B’类(比较项不对称)
由于缺乏相对应的值域,例(B2)中以OBJ“上海”为定义域的比较对象函数C就不成立,结果造成比较项的不对称现象。例(B2)可视为上述B类的不对称形式,所以我们称之为B’类。类似于B类,C类也会出现不对称现象。例如,
(C2) 北京比昨天热(图6)。

图6 C’类(比较项不对称)
(C3) 昨天比上海还热(图7)。

图7 C’类(比较项不对称)
B’和C’类的不对称现象的出现,实际上与时空范畴的特殊性以及人类认知机制紧密相关。如上所述,时间与空间是世界万物存在的前提,也是人类认知活动的基本参照点。凡是在自然语言中出现的实体(entity),无论事物等具体事物(object)还是状态等抽象事物(abstract),都处于时间与空间这两个维度上。至于时空这两种基本言语背景(environment, ENV),如果句子中没有具体明示其值,那就默认为说话时间与说话现场*除此之外,还有“话题隐含”。由于篇幅限制,本文省略对此的论述。。这是“以我中心”的人类认知机制所致,听话人倾向于自动填补上述例句中所隐涵的成分(implicature)。换句话说,由于听话人能够推测所隐涵的成分,所以话语交际中的“适量准则”[24],尤其是“经济原则*Say no more than you must. (The R principle [27])”就会引起比较对象的不对称。
3.2 比较结果函数P
如果说比较对象函数C表达比较双方(X、Y)之间的关系,那么比较结果函数P则表达SUB与DIM之间的述谓关系。例如,
(A2) 这件衣服价格比那件贵(图8)。

图8 例(A2)的可视化模型
比较结果函数P的骨干是“个体—述语—属性”的三元组结构(triple*三元组(triple)是一种最基本的语义描述单位,通常指称资源描述框架(Resource Description Framework,RDF)中的基础格式。其基本形式为由主语(subject)和宾语(object,或 property value)以及连接这两个节点的述语(predicate, 或property)构成的有向图(directed graph)[28]。从逻辑学的角度而言,三元组
例5 解放军纪律严明。
例6 本公司财力雄厚。
例7 这衣服价格很贵。
例8 枫叶颜色红了。
例(5-8)是表示事物的性质、状态等属性的主谓谓语句。假如这个结构与上节探讨的比较对象函数C结合,便可以形成“比”字句。例如,例(A2),图8则是主谓谓语句(7)的一种扩展式。
袁毓林[25]指出,事物的属性是多方面的,形容词描述的是事物诸多属性中的一个方面。上述例句中的“纪律”“财力”“价格”“颜色”是主体名词“解放军”“本公司”“衣服”“枫叶”的一种属性(property),即属性名词。因此,基于主谓谓语句的“比”字句,其所比较的往往不是事物本身,而事物的属性或某一方面。因此,我们提出新的语义范畴——比较属性DIM(dimension)以概括这些比较属性。那么,比较结果函数P在形式上定义为: 以SUB或ITM为定义域,以DIM为值域的一种函数。据此,上述第二部分有争议的例2明示化为:
例2东西你比我好,价钱我比你便宜(图9)。


图9 例2的可视化模型
如第二部分所示,传统的分类将“东西”与“价钱”归入一个范畴,即比较点(ATT)。在本文的七元组体系中,DIM“价钱”与表示物体(physical object)的ITM“东西”不同(图9)。它表示ITM“东西”的多种特征(属性)之一。同时,谓语形容词“便宜”得以对DIM“价钱”进一步进行具体化(价位)和主观化(主观评价)。可见,在我们的七元组框架中,比较点是比较双方共同拥有的“某一属性(DIM)或某一部分(ITM)”,表示“比什么”。这是在比较点的传统定义“比较双方共有部分”上增加了一个本体类型(ontological type)的约束条件。
4 基于知识本体的语义要素识别
我们要将上述“比”字句分析模型编译成机器可读的形式,以便实现“比”字句语义要素的自动识别。目前在知识表示(knowledge representation)方面,RDF/OWL是一种普遍通用的语义描述规范[26]。简略地说,RDF提供组织互联网资源(resources)的基本词汇表(vocabulary),在此基础上OWL使得我们更细致的逻辑表示及推理。它们是国际组织W3C的推荐标准,网上也存在几种公开的编辑软件。我们选择使用Protégé知识本体编辑器*http://protege.stanford.edu,构建了基于SUMO*SUMO(Suggested Upper Merged Ontology)是IEEE制定上层知识本体标准(SUO)的候选上层知识本体之一 [29]。的一个领域知识本体(domain ontology),称之为“比”字句知识本体(BiOnt)。
我们系统地组织RDF/OWL的基本公理(axiom)与实体(entity),对本文的七种关键要素进行了明确的解释(表1)。其中,谓词性要素BI与RES以一种OWL构件(constructs)owl: ObjectProperty进行了定义; 其他五种体词性要素则是利用owl:Class,及在此基础上添加一些限制(owl: Restriction)来定义的。
“比”字句中的每个语义要素根据本体类型归入到SUMO实体分类中,如例9“古人”、“现代人”属于“human”,及“腿”则属于“body_part”。其次,根据第三部分的分析框架,我们在这些实体之间添加不同联系(relationship)[30-32],比如“现代人”以比较对象函数C连接“古人”,“腿”连接比较结果函数P短。
最后,启动了推理器(reasoner),“古人”“现代人”等语义要素按照OWL推理公理自动映射到比较关键要素分类(CEs)中(图10)。除例9之外,我们也按照同样的步骤进行“比”字句实例(附录)的知识本体录入工作(图11)。
例9 古人的腿比现代人短。
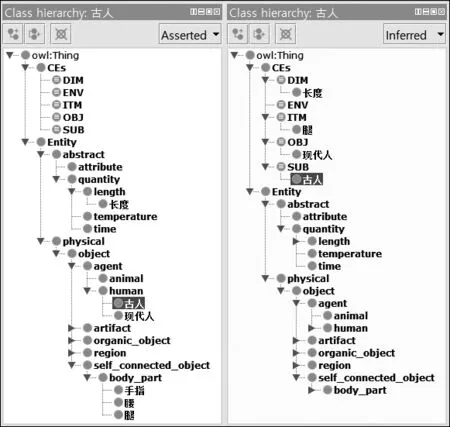
图10 推理前(左)与推理后(右)的BiOnt(例9)
本文对比较点的细分(ITM和DIM)有利于提高网络商品评论的细致分析。例10“屏幕”“待机时间”在传统的分类中概括为ATT,但我们的模型将它们分别归入到ITM与DIM。
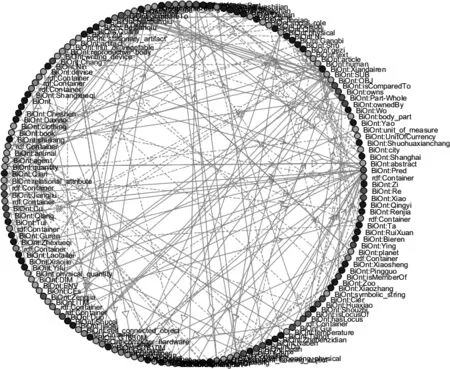
图11 BiOnt构成要素关系图
例10 这部手机屏幕比iPhone差,但待机时间比它长些。
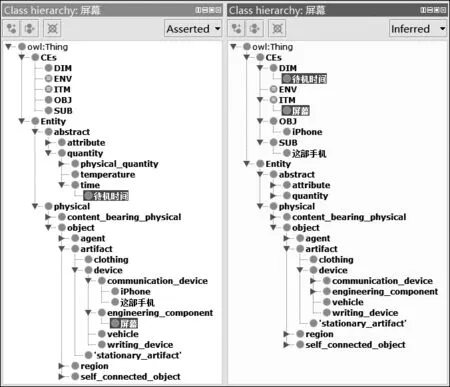
图12 推理前(左)与推理后(右)的BiOnt(例10)
另外,3.1论述的比较对象的不对称现象可以有选择地反映在BiOnt上。该知识本体上存在的“比”字句语义要素已按照SUMO做好系统的语义分类。因此,如果利用它们所属的语义类信息对比较对象范畴进行限制,则能够调控BiOnt对不对称“比”字句的允许与否。
例11 北京今天比昨天热。(对称)
例11’ 北京比昨天热。(不对称)
推理器成功地把“今天”与“昨天”识别为SUB和OBJ(图13)。然而,说话时间“今天”所隐含的不对称句(11’)却显示错误(图14)。这是因为“北京”与“昨天”不属于同一个本体类型,比较对象的等级限制(图15的第二行)则起了过滤不对称“比”字句的作用。
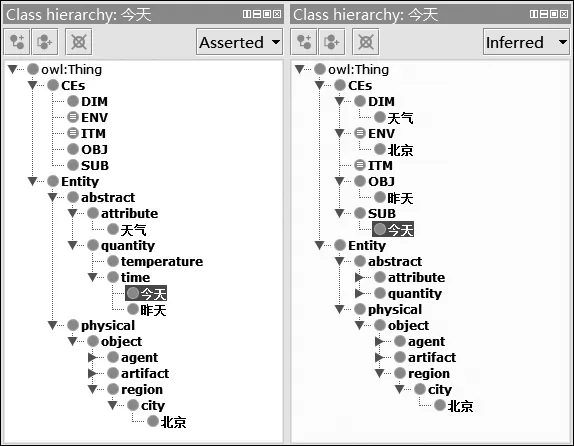
图13 推理前(左)与推理后(右): 例(11)
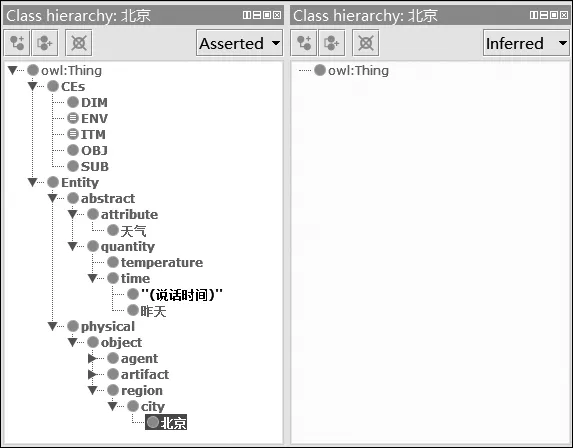
图14 推理前(左)与推理后(右): 例(11’)
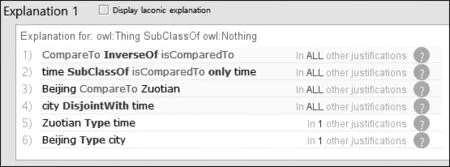
图15 Protégé 错误分析报告
5 小结
本文介绍了基于七元组的“比”字句结构分析模型。该模型把传统的比较项(X、Y)看作多层(multi-layer)结构,并包含以它们的组成要素作为论元的两种函数C、P。
如表2所示,本文把比较对象分成三层结构,以有助于凸显比较前项X与后项Y之间的多层对应关系及其不对称现象。我们以比较对象函数C来描述了比较项之间的对应关系。另外,本文以比较结果函数P阐明了“个体—述语—属性”的组合关系,用以成功地捕捉主谓关系及比较对象事物的属性信息。
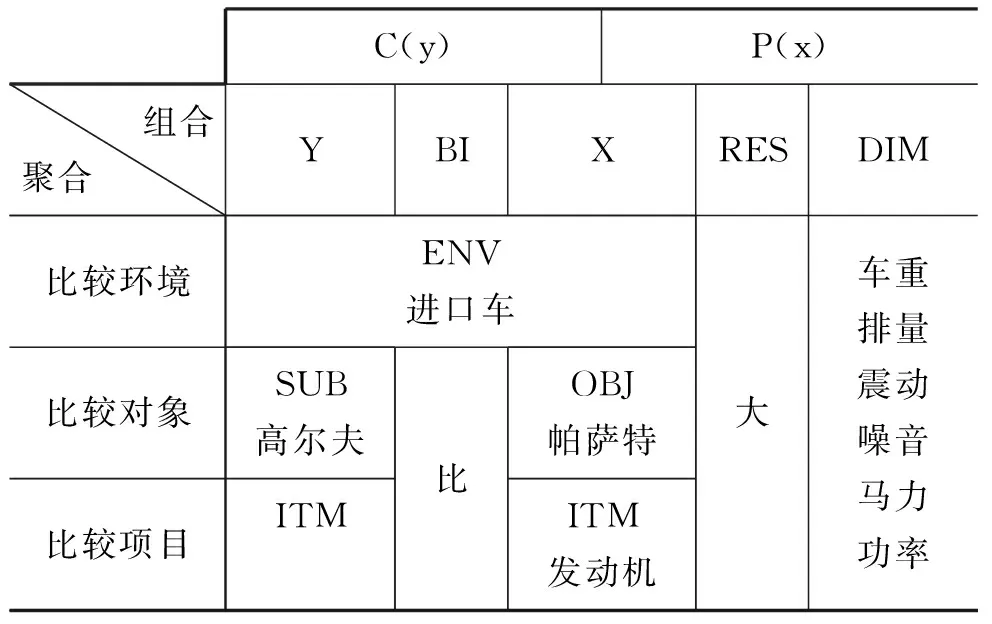
表2 “比”字句结构分析模型的层次结构及组合关系
由两种函数,即述谓逻辑式来表达“比”字句的语义结构,这种方法具有理论与应用方面的好处。首先,该方法可以获得历史演变上的支持: 最初的“比”字句是具有两个语义中心的连谓结构句式,即“比Y”和谓语“W”[33]。其次,在应用上,该模型设计基本符合三元组(triple)结构,有利于转换成计算机可操作的语义表达形式。作为一种应用实践,本文还构建了汉语“比”字句的知识本体BiOnt,并引进了一种基于逻辑推理的“比”字句关键要素识别方法。BiOnt的推理结果成功地验证了本文提出的可视化模型是合乎逻辑的分析框架。
基于细化的分类,本文引进的“比”字句分析模型为复杂多样的“比”字句实例提供了一个有效的形式化、可视化手段。该模型努力填平直观的认知模型和可计算的数据模型之间的鸿沟。虽然本文的分析模型功能上还适用于“有”、“像”字比较句: 无非是“有”字句等少数比较句型在语义组合(compositionality)上较为难以分开比较对象C和比较结果P两种函数,但是怎样用该模型来处理其他比较句句型的扩展方面尚需待进一步的后续研究。另外,网络文本中“比”字句往往是由多数分句组成的流水句,而本文讨论的例句以单句为主,所以针对篇章结构中的“比”字句分析模型的设计也有待加强。显然,这与指代消解及命名实体识别任务密切相关,我们希望今后的研究课题更加促进语言学和自然语言处理两个研究领域的互动。
[1] 马建忠. 马氏文通[M]. 上海: 商务印书馆, 1898.
[2] 吕叔湘. 中国文法要略[M]. 北京: 商务印书馆, 1982: 352-370.
[3] 丁声树. 现代汉语语法讲话[M]. 北京: 商务印书馆,1961: 107-110.
[4] 刘月华 等. 实用现代汉语语法[M]. 北京: 商务印书馆,2001: 833-854.
[5] 赵金铭. 论汉语的“比较”范畴[J]. 中国语言学报,2001(5):1-16.
[6] 李临定. 现代汉语句型[M]. 北京: 商务印书馆,1986/2011: 285-301.
[7] 马真. “比”字句内比较项Y的替换规律试探[J]. 中国语文,1986(2):18-25.
[8] 邵敬敏. “比”字句替换规律刍议[J]. 中国语文,1990(6):96-109.
[9] 陈珺,周小兵. 比较句语法项目的选取和排序[J], 语言教学与研究,2005 (2): 22-32.
[10] 耿直. 基于语料库的比较句式“跟、有、比”的描写与分析[D]. 北京大学博士学位论文,2012: 111-164.
[11] Jindal, Nitin and Bing Liu. Identifying comparative sentences in text documents[C]//Proceedings of SIGIR’06. ACM, 2006: 244-251.
[12] Jindal, Nitin and Bing Liu. Mining comparative sentences and relations[C]//Proceedings of the AAAI 2006(22): 1331-1336.
[13] 黄小江,万小军,杨建武 等. 汉语比较句识别研究[J]. 中文信息学报, 2008 (5): 30-38.
[14] 宋锐,林鸿飞,常富洋. 中文比较句识别及比较关系抽取[J]. 中文信息学报,2009 (3): 103-122.
[15] 魏现辉,任巨伟,何文译 等. DUTIR: 中文短文本倾向性分析及要素抽取方法研究[R].第五届中文倾向性分析评测会议,太原,2013: 116-129.
[16] 李岩,徐蔚然,陈光. PRIS_COAE COAE2013 评测报告[R].第五届中文倾向性分析评测会议,太原,2013: 53-69.
[17] 周红照,侯明午,侯敏,等. 基于语义分类的比较句识别与比较要素抽取研究[J]. 中文信息学报,2014 (3): 136-141.
[18] 谭松波,王素格,廖祥文 等. 第五届中文倾向性分析评测(COAE2013)总结报告[R].第五届中文倾向性分析评测会议,太原,2013: 5-33.
[19] 朴敏浚,李强,袁毓林. 汉语“比”字句关键要素的常规序列模式探索[J]. 中文信息学报,2016 (4):189-190.
[20] 朱德熙. 语法讲义[M]. 北京: 商务印书馆,1982: 189-190.
[21] 刘焱. 现代汉语比较范畴的语义认知基础[M],上海: 学林出版社,2004.
[22] 殷志平. “比”字句浅论[J]. 汉语学习,1987 (4): 3-5.
[23] 刘慧英. 小议“比”字句内结论项的不对称结构[J]. 汉语学习,1992 (5): 17-20.
[24] Grice, H. Paul.Logic and conversation[C]//Proceedings of the Syntax and semantics 3: Speech arts. 1975: 41-58.
[25] 袁毓林. 一价名词的认知研究[J]. 中国语文,1994 (4): 241-253.
[26] Allemang, Dean, and James Hendler. Semantic web for the working ontologist: effective modeling in RDFS and OWL[M]. Elsevier, 2011.
[27] Horn, Laurence.Toward a new taxonomy for pragmatic inference: Q-based and R-based implicature[C]//Proceedings of the Meaning, form, and use in context: Linguistic applications, 1984: 11-42.
[28] Kanzaki, Masahide. An introduction to RDF/OWL for semantic web[M]. Morikita Shuppan Co., 2005.
[29] Pease, Adam, et al. Suggested Upper Merged Ontology (SUMO) [DB/OL]. 2016. http://ontologyportal.org/
[30] Hitzler, Pascal, et al. OWL 2web ontology language primer (second edition)[EB/OL]. W3C recommendation, 2012. http://www.w3.org/TR/owl2-primer/
[31] Rector, Alan, et al. Simple part-whole relations in OWL Ontologies[EB/OL]. W3C editor’s draft, 2005.https://www.w3.org/2001/sw/BestPractices/OEP/SimplePartWhole/
[32] Horridge, Matthew, et al.A practical guide to building OWL ontologies using Protégé 4 and CO-ODE tools edition 1.3[M]. University of Manchester, 2011.
[33] 黄晓惠. 现代汉语差比格式的来源及演变[J]. 中国语文,1992 (3):213-224.
[34] 刘丹青. 差比句的调查框架与研究思路[M]. 戴庆厦、顾阳主编. 现代语言学理论与中国少数民族语言研究. 北京: 民族出版社,2003: 1-22.
附录
以下例句属于A类(图1模式)。
(A1) 我比他高。
(A2) 这件衣服价格比那件贵。
(A3) 今年气候比去年好。
(A4) 天然风比冷气对健康有益。
(A5) 我的书比他的多*比较语义要素的定界取决于语义要素的分析法: 整体性或分解性分析。分解性分析为: (A5)[我SUB]的[书ITM]比[他OBJ]的多。如采取分解性分析,则无法分辨(A5)与(B1)的差异(详见脚注4)。因此,本文选取整体性分析(A5-A7)。。
(A6) 你的嘴呀,比我的还花哨。
(A7) 小生的尖嗓比青衣的更硬些,更刺耳些。
(A8) 福美来的整体性能也不比对手差。
(A9) GT630M显卡比GT610M强很多。
(A10) 诺基亚机子的做工比国产机好太多了。
以下例句属于B类(图2模式)。
(B1) 我的书比他多。
(B2) 蔬菜的价格比上海贵。
(B3) 这本字典的字比那本还小。
(B4) 老太太穿的衣服比年轻的小姐们还要讲究。
(B5) 人家挣的钱比校长还多。
(B6) 瑞宣得到的消息,比别人都更多一些。
(B7) 买的i3富士通,键盘比14寸的多一个小键盘区,方便极了。
(B8) TouchHD的屏幕却足足比TouchPro大了一英寸。
(B9) 富康三厢车身比普桑小一号。
(B10) 前卫是六喇叭,比春天的四喇叭效果要好一些。
以下例句属于C类,(图3模式)。
(C1) 地球的北半球要比南半球细长一些。
(C2) 北京比昨天热。
(C3) 昨天比上海还热。
(C4) 大城市的平房比楼房少。
(C5) 动物园的猴子比狗熊多。
(C6) 苏联气候界又在宣传地球变冷的消息,说列宁格勒近年比1940年左右低1°C。
(C7) 我们现在已经比过去强,以后还要比现在强。
(C8) 我的钢笔比铅笔好使。
(C9) 他坐着比躺着舒服。
(C10) 他这学期比上学期进步多了。
A Visual Model for Fine Grained BI-structure Analysis and Its Application
PARK Minjun, YUAN Yulin
(Dept. of Chinese Language and Literature, Peking University, Beijing 100871, China)
In this study, a propositional representation model for Chinese BI(比)-structure is described. The model is based on 7 types of Comparative Elements (CEs), enhancing the resolution of existing 5 CE-based framework in analysis of comparatives. The model is also fully visualized by the relational structure of two propositional descriptions, based on which we reveal three basic patterns of comparison and define the standard of asymmetrical comparison explicitly. Consequently, it provides intuitive and easy way to analyze complex, multi-layer predications embedded in BI-structure, which are mostly elusive and tricky part of the comparative relation extraction. Moreover, the model is compatible with the OWL ontology language due to its basis of propositional logic. Accordingly, a small-scale ontology is built to demonstrate automatic relation extraction of BI-comparatives.
BI-comparatives; comparative element; comparative relations; fine grained; visualization; ontology

朴敏浚(1984—),博士研究生,主要研究领域为汉语句法学、计算语言学。E-mail:karmalet@163.com袁毓林(1962—),教授、博士生导师,主要研究领域为理论语言学和汉语语言学,特别是句法学、语义学、语用学,也涉及计算语言学和中文信息处理等应用性领域的问题。E-mail:yuanyl@pku.edu.cn
1003-0077(2016)06-0015-11
2016-09-27 定稿日期: 2016-10-15
国家自然科学基金(61375074,61371129)
TP391
A
