基于决策树技术的仓储企业综合竞争力评估研究
2016-05-31孟强
孟强
摘 要:文章运用SQL Server 2008商务智能平台和决策树分析技术,通过构建决策树挖掘模型,对仓储企业的综合竞争力进行了科学的、准确的、合理的评估分析,实现了认知规则的提取和知识的发现,具有一定的理论和现实意义。
关键词:决策树;仓储企业;评估;SQL Server 2008
中图分类号:F253 文献标识码:A
Ahstract: The use of SQL Server 2008 business intelligence
platform and decision tree analysis technology, by constructing a decision tree mining model, comprehensive competitiveness of enterprise logistics were analyzed and the scientific, accurate and reasonable assessment. The cognitive rules extraction and knowledge discovery have certain theoretical and practical significance.
Key words: decision tree; storage enterprise; evaluation; SQL Server 2008
仓储业是物流业的重要组成部分,也是第三产业中的独立行业,近10年来,我国经济持续稳定高速增长,电子商务迅猛发展,促使物流业的规模不断扩大,传统物流企业逐步转型,现代物流发展的生态环境日益优化,物流基础设施和信息化建设进度加快,现代物流服务体系已逐渐形成,仓储物流配送服务的能力和水平得到了显著的提高,现代物流业已成为现代服务业的重要支撑。然而,与西方发达国家相比,我国仓储业的发展还不够成熟,存在着许多不足,需要进一步加强和完善现代仓储物流体系的构建,并对仓储物流企业进行综合评估和考察,促使仓储物流企业竞争、创新和发展,不断提升仓储物流企业的服务质量和综合竞争力,以更好地适应现代仓储业的发展。
1 SQL Server 2008 BI平台概述
Business Intelligence Development Studio,即微软公司SQL Server 2008商业智能平台,被用于创建和使用数据挖掘模型,通过对该平台中数据挖掘算法和工具的使用,进而为企业提供有价值的、高效的、可靠的商务智能决策方案。
SQL Server 2008系统结构主要包括4个部分,即数据库引擎、分析服务(Analysis Services)、报表服务(Reporting Services)和集成服务(Integration Services)。在用BI平台进行数据挖掘时,主要使用的是Analysis Services,它不仅能够被用来进行多维数据分析,还能创建数据挖掘结构和模型,并且提供了9种比较常用的数据挖掘技术(Microsoft Naive Bayes、关联规则、聚类分析、决策树、逻辑回归、神经网络、时序、线性回归、顺序分析和聚类分析),除此之外用户还能自定义算法。
2 决策树简介
数据挖掘的本质就是知识发现的过程,它是从海量的数据中提取有价值的、对人们有用的信息和知识[1],而决策树是数据挖掘技术中常用的一种,在分类和预测中运用比较广泛,该技术就是通过分析已知类别训练集,挖掘并发现分类规则,再对未知数据的类别进行分析预测,从而给决策者提供参考[2-3]。
据此可知该技术的实施一般分为模型训练和应用两个步骤[4],该方法具有以下几个优点:方法简单,计算量较小;容易挖掘和发现有价值的规则;连续和离散字段均能适用;能够明显直观地显现出各字段的重要性程度。然而也存在一些不足,比如对连续字段和时间顺序这样的字段需要进一步转化处理,类别太多会增加错误决策的概率等。
3 数据挖掘的ETL过程
3.1 数据的获取和导入
根据挖掘和分析的需要,文章随机从物流产业大数据平台[5]中抽取全国仓储物流企业相关数据集,该样本数据集合共有400条记录,每条记录主要选取了10个相关属性,其属性名称分别为Comp_ID(企业ID)、Comp_Name(企业名称)、Comp_Prop(企业性质)、Region(所属区域)、Address(企业地址)、Cont_Way(联系方式)、Asset(TTY)(企业资产(万元))、Income(TTY)(企业经营收入(万元))、Comp_Numb(企业员工数)和Comp_Eval_Result(企业评估结果)。通过Excel对所需数据进行初步的汇集和整理,再运用SQL server 2008 Management Studio所提供的数据导入功能,进行数据的导入并创建Basic_Info(基本信息)表,储存在事先已创建好的名为仓储物流企业综合竞争力评估系统数据库中。
3.2 数据的清洗和转换
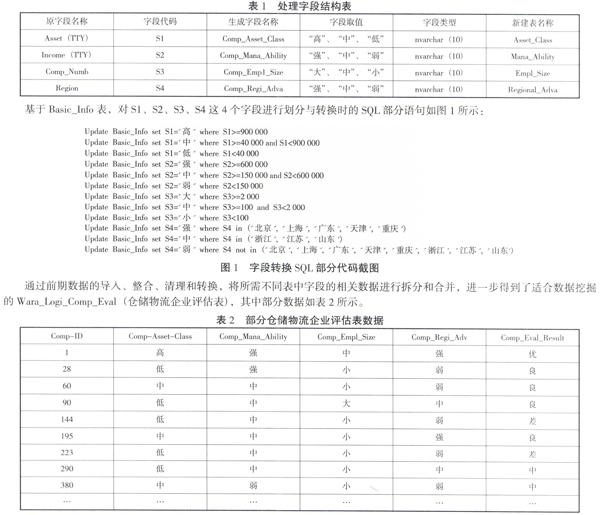
在随机抽取的400条数据中,数据可能并不是非常完整,不能被直接用来进行数据分析,需要根据分析需求对数据本身做进一步的处理,也就是所谓的查缺补漏工作。如果某条记录超过3个属性值为空,则放弃录入该条数据。为了能够更好地对仓储物流企业的综合竞争力进行评估,需要对相关数据进行转换,基于Basic_Info表,需要对Asset(TTY)、Income(TTY)、Comp_Numb和Region字段的数据进行离散化处理转换,也就是把待处理字段的每个取值用“字符串”的形式进行处理转换[6],然后把各字段转换后的值存储在数据库中,其转换处理字段的具体结构如表1所示。文章将Asset(TTY)(企业资产(万元))按照“高”、“中”、“低”3个级别进行划分、转换并生成Comp_Asset_Class(企业资产级别)字段,基于此创建Asset_Class(资产级别表);将Income(TTY)(企业经营收入(万元))按照“强”、“中”、“弱”3个级别进行划分、转换并生成Comp_Mana_Ability(企业经营能力)字段,基于此创建Mana_Ability(经营能力表);将Comp_Numb(企业员工数)按照“大”、“中”、“小”3个级别进行划分、转换并生成Comp_Empl_Size(企业员工规模)字段,基于此创建Empl_Size(员工规模表);将Region(所属区域)按照“强”、“中”、“弱”3个级别进行划分、转换并生成Comp_Regi_Adva(企业区域优势)字段,基于此创建Regional_Adva(区域优势表)。
基于Basic_Info表,对S1、S2、S3、S4这4个字段进行划分与转换时的SQL部分语句如图1所示:
通过前期数据的导入、整合、清理和转换,将所需不同表中字段的相关数据进行拆分和合并,进一步得到了适合数据挖掘的Wara_Logi_Comp_Eval(仓储物流企业评估表),其中部分数据如表2所示。
4 决策树挖掘模型的创建及准确性验证
4.1 挖掘结构和模型的构建
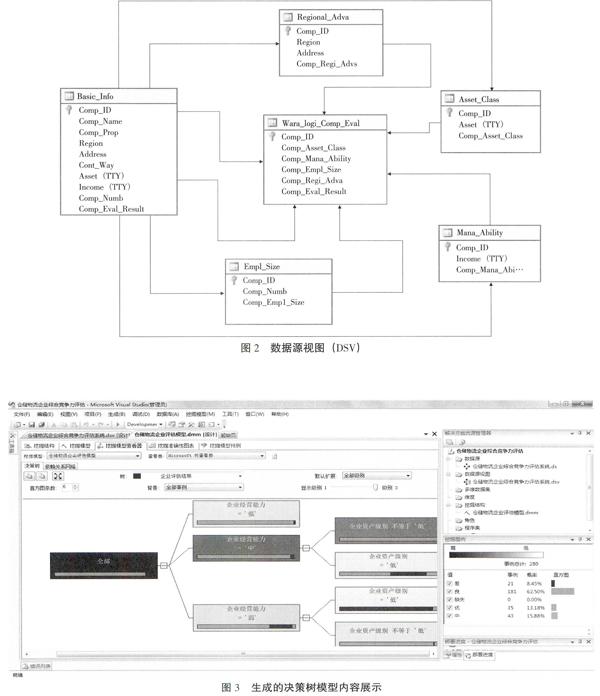
启动BI Dev Studio,在开发环境中新建名为“仓储物流企业综合竞争力评估”的Analysis Services项目,以及定义项目保存位置信息和解决方案名称,然后创建数据源和数据源视图(DSV),最终所建DSV如图2所示。
然后按照数据挖掘向导的提示,逐步构建挖掘结构和挖掘模型,在创建的过程中,需要重视测试集的创建,即指定要为模型测试保留的事例数,一般需要指定测试数据百分比和测试数据集中的最大事例数,通常指定测试数据百分比为30%。本文随机抽取120个作为测试集,用来测试和检验模型,剩余280个作为训练集,用来生成规则。最后将所创建的数据挖掘结构和模型都命名为“仓储物流企业评估模型”。该挖掘模型成功部署处理之后,就可以查看所创建的挖掘结构、挖掘模型、挖掘模型查看器、挖掘准确性图表和挖掘模型预测相关的各种信息,通过挖掘模型查看器可以查看所生成的决策树如图3所示。
4.2 模型的准确性验证
4.2.1 分类矩阵
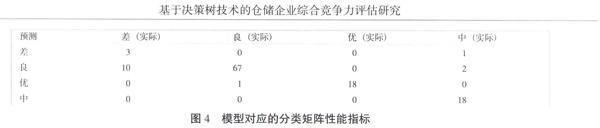
分类矩阵(Classification Matrix)也称无秩序矩阵,它能够精确地显示该算法测试的结果正确的次数,并且显示错误的预测是什么。本文所创建的决策树挖掘模型选取对应的测试集共400*30%=120个事例来对所生成的挖掘模型进行测试并将测试结果以分类矩阵的形式加以表示,如图4所示。
根据分类矩阵所显示的内容可知,本模型预测的结果为:真“差”事例数目为3,假“差”事例数目为1;真“良”事例数目为67,假“良”事例数目为12;真“优”事例数目为18,假“优”事例数目为1;真“中”事例数目为18,假“中”事例数目为0[7]。综上所述,可求出本模型在测试集上的平均分类评估的准确率为:(3+67+18+18)/(3+1+10+67+2+1+18+18)
≈88.33%,该结果表明模型具有较强的可靠性。
4.2.2 挖掘提升图
提升图是按照测试数据集中可预测列的已知值来绘制从该测试数据集进行预测查询的结果,并同时展示理想模型、随机模型和所建模型的结果。本文测试数据集中共有120个事例,可以得到企业评估结果(可预测字段)分别为“优”、“良”、“中”和“差”不同条件下的模型所对应的提升图,文章仅给出企业评估结果为“良”条件下模型所对应的提升图(如图5所示)及其相应的挖掘图例(如图6所示)。
从提升图(图5)明显可以看出,红色曲线不断向绿色曲线靠拢,也就是所构建模型的提升曲线十分靠近理想模型的提升曲线,此外由挖掘图例(图6)可知分数为0.99,非常接近1,所以该模型性能非常好,且具有较高的预测准确率。
4.2.3 综合竞争力评估依赖关系
通过挖掘模型查看器进行模型挖掘,查看仓储物流企业综合竞争力评估主要强依赖关系如图7所示,在Wara_Logi_Comp_Eval(仓储物流企业评估表)中,若干字段包括Comp_Mana_Ability(企业经营能力)、Comp_Asset_Class(企业资产级别)、Comp_Empl_Size(企业员工规模)和Comp_Regi_Adva(企业区域优势),对仓储物流企业综合竞争力评估影响最大的是企业经营能力,其次是企业资产级别,对于较弱的依赖关系图中并没有显示出来,这是由于微软SQL Server 2008所提供的决策算法不同造成的,然而主要结论是一致的,那就是仓储物流企业综合竞争力评估主要依赖于企业经营能力和企业资产级别这两个因素。
