基于近红外光谱技术不同产地肉桂子模型的建立
2016-05-28熊陈诚王婷媛
熊陈诚,李 莉,王婷媛
(新疆医科大学药学院,乌鲁木齐 830011)
基于近红外光谱技术不同产地肉桂子模型的建立
熊陈诚,李莉*,王婷媛
(新疆医科大学药学院,乌鲁木齐830011)
摘要:目的采用近红外光谱技术结合化学计量学方法建立肉桂子药材的定性模型,达到快速鉴别不同产地肉桂子的目的。方法采用近红外漫反射光纤光谱结合SIMCA、主成分分析法、聚类分析等方法识别不同产地的肉桂子。结果对肉桂子药材原始光谱全波长进行主成分分析,前2个主成分累积方差贡献率为99%,很好地解释了原始光谱99%的信息,和田、喀什、伊宁和乌鲁木齐4个产地聚类效果较好,广西与越南2个产地部分样本出现混淆现象,基本可以区分6个产地样品;采用聚类分析法建立的肉桂子模型对样品进行预测时,正确率为100%;SIMCA法建立的模型对样品进行预测时,只有越南1个产地的样品没有被识别,总识别率为97.22%。结论近红外漫反射光谱技术结合化学计量学方法可以初步实现肉桂子药材的产地鉴别。
关键词:肉桂子;近红外光谱技术;快速检验;化学计量学
肉桂子(FructusCinnamomicassiaeimmaturi)是樟科(Lauraceae)植物肉桂(Cinnamomicassiaepresl)的干燥带宿萼未成熟的果实[1-2]。肉桂子是维吾尔族常用药材,名为达尔亲古丽[3],具有生干生热、祛寒补心、芳香开窍、温中开胃等药理活性,主要用于治疗湿寒性或黏液质心脏和肠胃疾病[4-6]。近来年人们开始关注产地对产品质量的影响。对于中药材来说,不同产地的气候、地质和土壤不同,会导致中药材含有的化学成分含量有差异,从而对药材质量产生一定的影响。
《中国药典》2010年版收载了肉桂,采用桂皮醛为指标成分进行薄层鉴别和含量测定,但肉桂子尚未被《中国药典》收录。本研究将光纤传感技术与近红
外光谱相结合,直接对肉桂子药材进行检测,建立快速无损鉴别肉桂子产地的新方法,促进新疆民族药材肉桂子的规范化使用。
1仪器与材料
1.1仪器和软件NIR Quest近红外光纤光谱仪,采用InGaAs检测器(美国海洋光学公司);QP600-2-VIS-NIR光纤(美国海洋光学公司);ISP-REF积分球,内置卤素灯(美国海洋光学公司);使用的光谱数据处理软件为Unscrambler X 10.2 (美国挪威公司)。
1.2材料肉桂子药材产地分别为越南、和田、喀什、伊宁、乌鲁木齐和广西,药材经新疆医科大学药学院帕丽达·阿布利孜教授鉴定为樟科(Lauraceae)植物肉桂(Cinnamomicassiaepresl)的干燥带宿萼未成熟的果实。样品信息见表1。样本随机分为校正集和预测集,校正集包括52个样品,预测集包括36个样品。
表1样品信息
Tab.1 Sample information
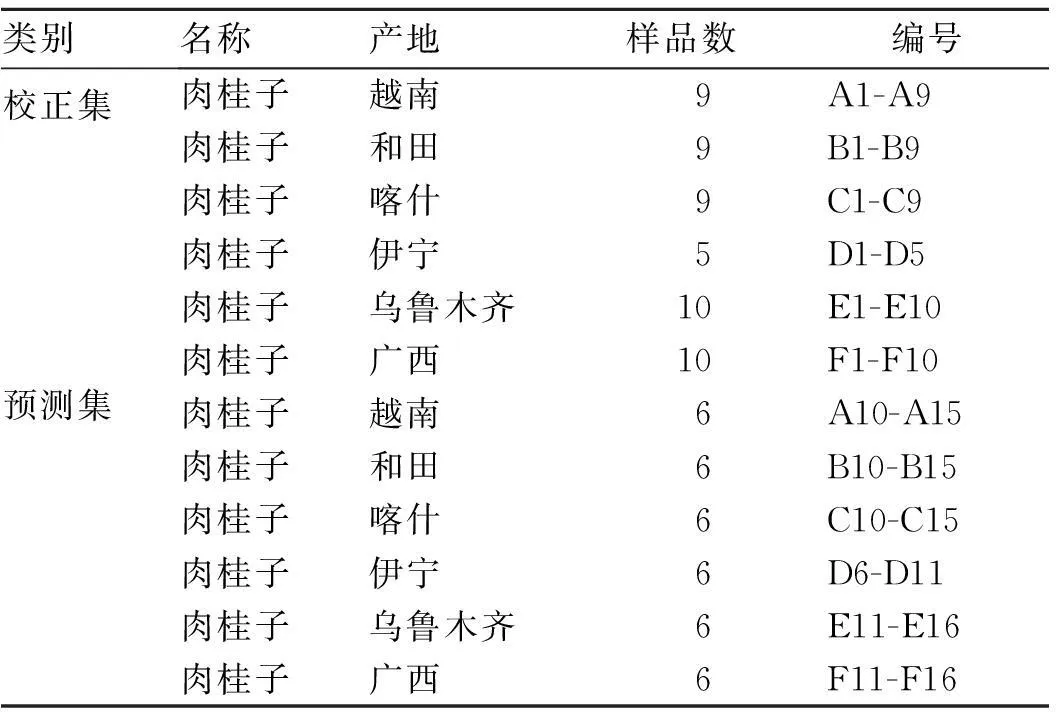
类别名称产地样品数编号校正集肉桂子越南9A1-A9肉桂子和田9B1-B9肉桂子喀什9C1-C9肉桂子伊宁5D1-D5肉桂子乌鲁木齐10E1-E10肉桂子广西10F1-F10预测集肉桂子越南6A10-A15肉桂子和田6B10-B15肉桂子喀什6C10-C15肉桂子伊宁6D6-D11肉桂子乌鲁木齐6E11-E16肉桂子广西6F11-F16
2方法
光谱采集:取样品粉碎,过60目筛,使用无色透明袋分装样品,压平,放在积分球样品口处,采集近红外光谱。光谱仪波长扫描范围为866~2 500 nm,积分时间为20 ms,扫描平均次数为20次。每个样品扫描3次,把平均光谱作为样品光谱。采集到肉桂子样品近红外漫反射原始光谱图,见图1。
3结果与分析
3.1主成分分析对88个肉桂子样品原始光谱进行主成分分析,见图2。从图2可知,前10个主成分的累积方差贡献率为99.92%,第1主成分方差贡献率为90%,第2主成分方差贡献率为9%。前2个主成分累积方差贡献率为99%,表明前2个主成分很好地解释了原始光谱99%的信息。图3为样品原始光谱全波长前2个主成分的分图,从图中可以看出和田、喀什、伊宁和乌鲁木齐4个产地的样本各自聚为一类,越南和广西2个产地的样本有部分重叠。和田产地的样本紧密聚在一起,都分布在左下角;喀什地区的样本紧密聚在一起,全部分布在右下角;伊宁和乌鲁木齐2类样本分布在右上角,各自聚为一类。总体来说PCA基本可以区分肉桂子产地,可以用于肉桂子的快速鉴别。

图1肉桂子近红外原始光谱图
Fig.1 Near infrared original spectra ofFructusCinnamomicassiaeimmaturi

图2样品原始光谱前10个主成分累积方差贡献率
Fig.2 Ten principal component cumulative variance contribution rate of sample original spectra
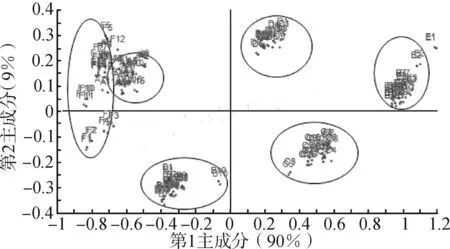
图3样品原始光谱前2个主成分的分图
Fig.3 Two principal component scores of sample original spectra
3.2聚类分析
3.2.1聚类分析模型的建立本文采用Ward算法以校正集52个样品建立聚类分析模型;以预测集36个样品检验模型的准确性。
3.2.2不同预处理方法对聚类分析模型的影响由于肉桂子样品粒径大小和均匀度、光谱测量中产生的噪声以及周围环境等因素都会对光的漫反射产生影响,从而使光谱产生波动。因此需要对光谱进行预处理,减少上述因素带来的干扰,达到使模型稳定性增强的目的。本研究采用表2所示预处理方法,建立模型。表2列出了校正集样品验证情况,以S-G smoothing为预处理方法时所建模型校正集,正确率为98.08%,高于其他方法,因此选择S-G smoothing建立聚类分析模型。
表2不同预处理方法聚类分析结果
Tab.2 The results of different pretreatment methods clustering analysis
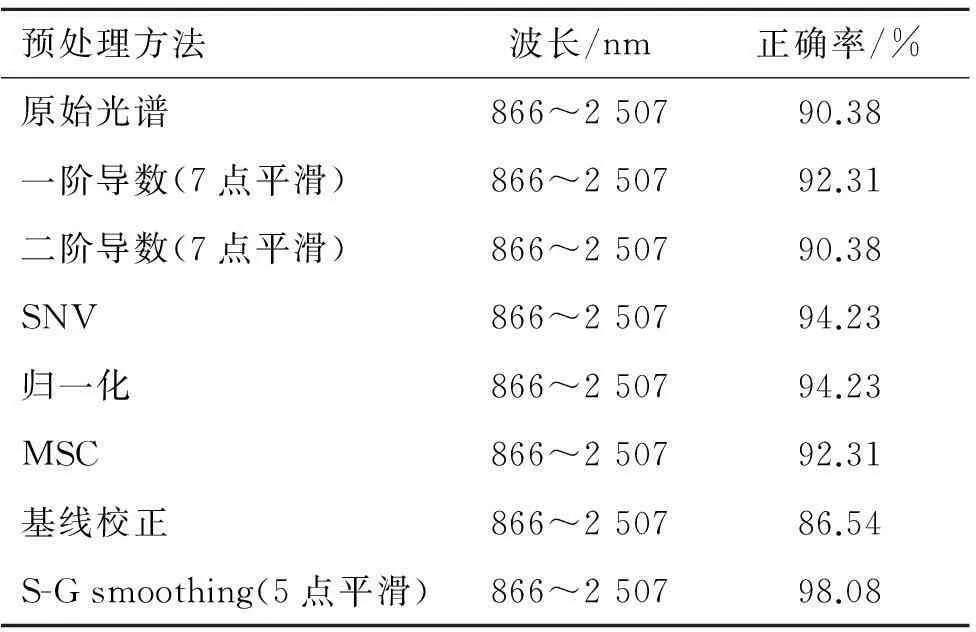
预处理方法波长/nm正确率/%原始光谱866~250790.38一阶导数(7点平滑)866~250792.31二阶导数(7点平滑)866~250790.38SNV866~250794.23归一化866~250794.23MSC866~250792.31基线校正866~250786.54S-Gsmoothing(5点平滑)866~250798.08
3.2.3不同波长范围对聚类分析的影响由于有些光谱数据并不能真实地反映样品信息,因此需要对光谱范围进行筛选,从而达到提高模型稳定性的目的[7]。以S-G smoothing方法预处理,考察不同波长范围对聚类分析模型的影响。表3列出了校正集样品验证情况,从表3可以看出,波长范围为960~1 204和1 522~2 507 nm时所建的模型最佳,校正集正确率为100%。从图4可以看出,不同产地的肉桂子各自聚为一类,校正集52个样品聚类全都正确。
表3不同波长聚类分析结果
Tab.3 The results of different wavelength range clustering
analysis
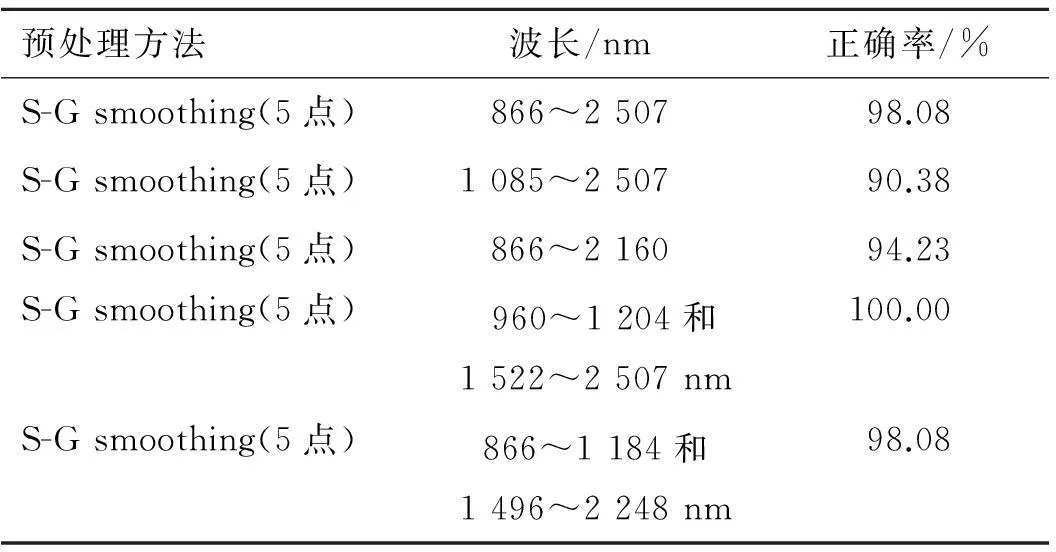
预处理方法波长/nm正确率/%S-Gsmoothing(5点)866~250798.08S-Gsmoothing(5点)1085~250790.38S-Gsmoothing(5点)866~216094.23S-Gsmoothing(5点) 960~1204和1522~2507nm100.00S-Gsmoothing(5点) 866~1184和 1496~2248nm98.08
3.2.4聚类分析模型的预测使用该模型对预测集36个样品进行预测,图5表明,36个预测集样品,全部判别正确。表明所建立的聚类分析对6类样品区分效果很好,可以用于不同产地肉桂子的快速识别。

图4S-G smoothing预处理960~1 204和1 522~2 507 nm聚类分析图
Fig.4 Clustering analysis diagram of S-G smoothing pretreatment at 960-1 204 and 1 522-2 507 nm
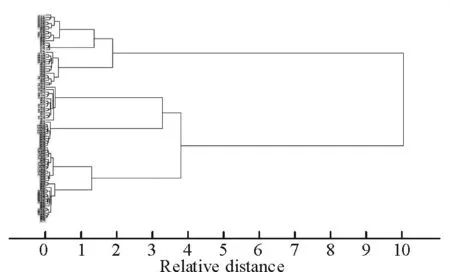
图5校正集与预测集-聚类分析图
Fig.5 Clustering analysis diagram of calibration set and prediction set
3.3SIMCA
3.3.1SIMCA模型的建立将全部校正集样品用于建立模型,预测集用于检验模型的准确性,通过识别率和拒绝率评判模型的优劣[8]。本实验通过校正集回判以及预测集样本用于检测模型的好坏。如果所建的模型对校正集和预测集均有很好的分类效果,表明所建模型良好,可以用于肉桂子的快速鉴别。
3.3.2不同处理方法对SIMCA判别模型的影响由于肉桂子样品粒径大小和均匀度、光谱测量中产生的噪声以及周围环境等因素都会对光的漫反射产生影响,从而使光谱产生波动。因此需要对光谱进行预处理,减少上述因素带来的干扰,达到使模型稳定性增强的目的。本研究采用表4所示预处理方法建立模型。表4列出了使用校正集样本建立的SIMCA模型对校正集样本进行验证的结果以及用模型对未知样本检测的结果。表4表明,在5%的显著水平下,SNV法优于其他预处理方法; SNV法建立的模型对未知样品进行预测时,预测集六类样品的拒绝率均为100%,和田、喀什、伊宁和乌鲁木齐4个产地的识别率为100%,越南和广西2个产地识别率均为83.33%。
3.3.3不同光谱范围对SIMCA判别模型的影响由于有些光谱数据并不能真实地反映样品信息,因此需要对光谱范围进行筛选,从而达到提高模型稳定性的目的[8]。使用SNV法,选择不同波段建立模型。由表5可知,波长范围为867~1 184和1 496~2 248 nm时建立的模型优于其他波段建模效果,其校正集识别率和拒绝率均为100%;模型对未知样品进行预测时6个产地的拒绝率均为100%,越南模型的识别率为83.33%,其他5个产地识别率均为100%。
表4不同预处理方法对建模效果的影响
Tab.4 Effects of different pretreatment methods on modeling
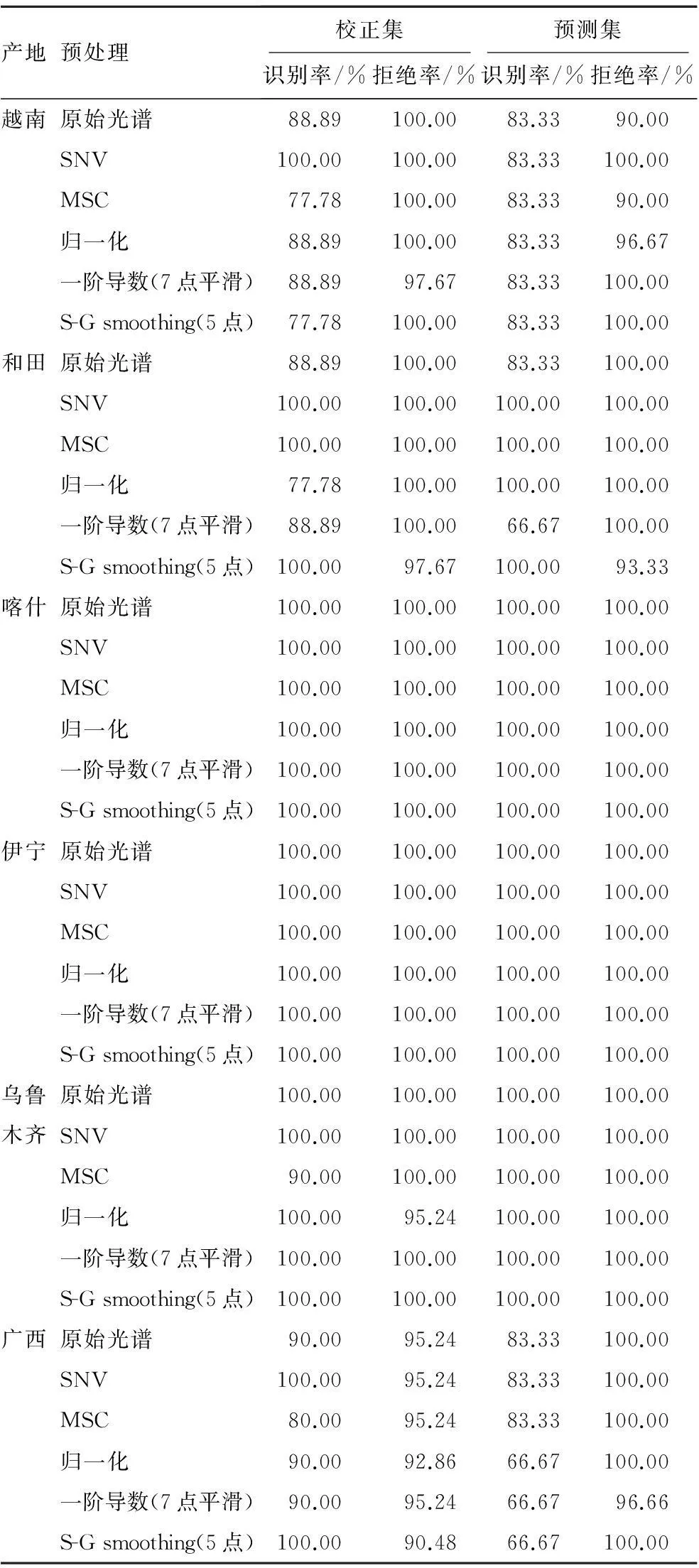
产地预处理校正集识别率/%拒绝率/%预测集识别率/%拒绝率/%越南原始光谱88.89100.0083.3390.00SNV100.00100.0083.33100.00MSC77.78100.0083.3390.00归一化88.89100.0083.3396.67一阶导数(7点平滑)88.8997.6783.33100.00S-Gsmoothing(5点)77.78100.0083.33100.00和田原始光谱88.89100.0083.33100.00SNV100.00100.00100.00100.00MSC100.00100.00100.00100.00归一化77.78100.00100.00100.00一阶导数(7点平滑)88.89100.0066.67100.00S-Gsmoothing(5点)100.0097.67100.0093.33喀什原始光谱100.00100.00100.00100.00SNV100.00100.00100.00100.00MSC100.00100.00100.00100.00归一化100.00100.00100.00100.00一阶导数(7点平滑)100.00100.00100.00100.00S-Gsmoothing(5点)100.00100.00100.00100.00伊宁原始光谱100.00100.00100.00100.00SNV100.00100.00100.00100.00MSC100.00100.00100.00100.00归一化100.00100.00100.00100.00一阶导数(7点平滑)100.00100.00100.00100.00S-Gsmoothing(5点)100.00100.00100.00100.00乌鲁木齐原始光谱100.00100.00100.00100.00SNV100.00100.00100.00100.00MSC90.00100.00100.00100.00归一化100.0095.24100.00100.00一阶导数(7点平滑)100.00100.00100.00100.00S-Gsmoothing(5点)100.00100.00100.00100.00广西原始光谱90.0095.2483.33100.00SNV100.0095.2483.33100.00MSC80.0095.2483.33100.00归一化90.0092.8666.67100.00一阶导数(7点平滑)90.0095.2466.6796.66S-Gsmoothing(5点)100.0090.4866.67100.00
表5不同波长范围对建模效果的影响
Tab. 5 Effects of wavelength range on the modeling

产地波长范围/nm校正集识别率/%拒绝率/%预测集识别率/%拒绝率/%越南866~2507100.00100.0083.33100.00866~216088.89100.0083.3396.671085~250788.89100.0066.67100.00960~1204和1522~2507100.00100.0083.33100.00867~1184和1496~2248100.00100.0083.33100.00和田866~2507100.00100.00100.00100.00866~2160100.00100.00100.00100.001085~2507100.00100.00100.00100.00960~1204和1522~2507100.00100.00100.00100.00867~1184和1496~2248100.00100.00100.00100.00喀什866~2507100.00100.00100.00100.00866~2160100.00100.00100.00100.001085~2507100.00100.00100.00100.00960~1204和1522~2507100.00100.00100.00100.00867~1184和1496~2248100.00100.00100.00100.00伊宁866~2507100.00100.00100.00100.00866~2160100.00100.00100.00100.001085~2507100.00100.00100.00100.00960~1204和1522~2507100.00100.00100.00100.00867~1184和1496~2248100.00100.00100.00100.00乌鲁木齐866~2507100.00100.00100.00100.00866~2160100.00100.00100.00100.001085~2507100.00100.00100.00100.00960~1204和1522~2507100.00100.00100.00100.00867~1184和1496~2248100.00100.00100.00100.00广西866~2507100.0095.2483.33100.00866~216090.00100.0083.33100.001085~250790.0097.6283.3393.33960~1204和1522~250790.00100.0083.3396.67867~1184和1496~2248100.00100.00100.00100.00
3.3.4模型的预测用全部校正集建立SIMCA模型,用校正集和预测集样本验证模型的准确性和稳定性。结果见表6。结果表明,越南产肉桂子对本类样品的识别率为83.33%;其他5个产地对自个样本识别率均为100%,6个产地模型拒绝率均为100%,用SNV法在波长范围为867~1 184和1 496~2 248 nm时建立SIMCA模型对肉桂子6个产地区分效果良好,可以用于不同产地肉桂子的快速鉴别。
表6模型预测结果
Tab.6 The results of the model prediction

产地预处理方法波长范围/nm校正集识别率/%拒绝率/%预测集识别率/%拒绝率/%越南SNV867~1184和1496~2248100.00100.0083.33100.00和田SNV867~1184和1496~2248100.00100.00100.00100.00喀什SNV867~1184和1496~2248100.00100.00100.00100.00伊宁SNV867~1184和1496~2248100.00100.00100.00100.00乌鲁木齐SNV867~1184和1496~2248100.00100.00100.00100.00广西SNV867~1184和1496~2248100.00100.00100.00100.00
4讨论
本文对肉桂子药材原始光谱全波长进行主成分分析,和田、喀什、伊宁和乌鲁木齐4个产地聚类效果较好,广西和越南2个产地部分样本出现混淆现象。基本可以区分6个产地样品。聚类分析法建立的肉桂子模型对预测集样品进行预测时,正确率达到100%;SIMCA法建立的模型对样品进行预测时,只有越南1个产地的样品没有被识别,其余样本判别正确,可以用于不同产地肉桂子的快速鉴别。但是,本研究建模样本数量有限,对药材鉴别时还需要收集大量药材。本研究结果初步表明,聚类分析方法可用于不同产地肉桂子药材的鉴别。
参考文献:
[1]中华人民共和国卫生部.卫生部颁药品标准:中药材:第一册[M].北京:人民卫生出版社,2010:36.
[2]胡曙晨,马雪红,李新霞,等.维药肉桂子体外抗氧化活性研究[J].安徽医药,2014,18(2):233-237.
[3]胡曙晨,马雪红,李新霞,等.肉桂子药材的薄层鉴别方法研究[J].西北药学杂志,2014,29(2):111-114.
[4]Amalaradjou M A,Narayanan A,Baskaran S A,et al.Antibiofilm effect of trans-cinnamaldehyde on uropathogenicEscherichiacoli[J]. J Urol,2010,184(1):358-363.
[5]胡曙晨,李莉,李新霞,等.正交实验优化肉桂子中超声提取桂皮醛的工艺[J].新疆医科大学学报,2013,36(9):1278-1281.
[6]熊梅,张正方,唐军.HS-SPME-GC-MS法分析肉桂子挥发性化学成分[J].中国调味品,2013,38(1):88-91.
[7]夏俊芳.基于近红外光谱的贮藏脐橙品质无损检测方法研究[D].武汉:华中农业大学,2007.
[8]严衍禄.近红外光谱分析基础与应用[M].北京:中国轻工业出版社,2005.
Establishment of a cinnamon habitat model based on near infrared spectroscopy
XIONG Chencheng,LI Li*,WANG Tingyuan
(School of Pharmacy, Xinjiang Medical University,Urumqi 830011,China)
Abstract:ObjectiveNear infrared spectroscopy with chemometrics was used to establish a qualitative identification model for Fructus Cinnamomi cassiae immaturi, by which the rapid identification of different origin Fructus Cinnamomi cassiae immaturi could be achieved. MethodsNear infrared diffuse reflection spectroscopy with principal component analysis, clustering analysis and SIMCA methods were used to identify the different origins of Fructus Cinnamomi cassiae immaturi. ResultsThe principal component analysis of the original full wavelength spectrum screened out two principal components′ whose cumulative variance proportion was 99%, which explained the clusters effect of Hotan,Kashgar,Yining and Urumqi was better than other habitat.Some samples of Guangxi and Vietnam were confused,and six origin samples could be distinguished. The accuracy of the model to forecast samples was 100%; Using SIMCA method to predict the samples,only Vietnam sample was not identified,the identification accuracy was 97.22%. ConclusionNear infrared diffuse reflectance spectroscopy combined with chemometrics could identify the origin of Fructus Cinnamomi cassiae immaturi quickly.
Key words:Fructus Cinnamomi cassiae immaturi;NIR;rapid analysis; chemometric methods
(收稿日期:2015-08-20)
中图分类号:R917
文献标志码:A
文章编号:1004-2407(2016)03-0221-05
doi:10.3969/j.issn.1004-2407.2016.03.001
*通信作者:李莉,女,博士,教授
作者简介:熊陈诚,女,在读硕士研究生
基金项目:国家自然科学基金项目(编号:81260485)
·中药及天然药物·
